

La mia dashboard di OpenRouter segnava 47 $ spesi prima di pranzo, di martedì. Avevo fatto forse una dozzina di task di coding — niente di assurdo, giusto un po’ di refactoring e qualche bug fix. È stato lì che ho capito che le impostazioni predefinite di OpenClaw stavano instradando in silenzio ogni singola interazione, compresi i ping di heartbeat in background, attraverso Claude Opus a oltre 15 $ per milione di token.
Se ti è mai capitato di ritrovarti davanti a sorprese del genere — e dai forum sembra che succeda a parecchie persone («spendo già 40 dollari e non lo uso nemmeno così tanto», ha scritto un utente) — questa guida ti porta passo dopo passo nel processo completo di audit e ottimizzazione che ho usato per tagliare la spesa mensile di circa il 90%. Non è solo un semplice «passa a un modello più economico», ma un’analisi sistematica di dove finiscono davvero i token, come monitorarli, quali modelli economici reggono sul lavoro agentico reale e tre configurazioni pronte da copiare che puoi usare subito. L’intero processo mi è costato un pomeriggio.
Cos’è il consumo di token di OpenClaw e perché è così alto per default?
I token sono l’unità di fatturazione di ogni interazione AI in OpenClaw. Pensali come piccoli pezzi di testo — circa 4 caratteri inglesi per token. Ogni messaggio inviato, ogni risposta ricevuta, ogni processo in background: tutto viene conteggiato in token.
Il problema è che le impostazioni predefinite di OpenClaw sono pensate per tirare fuori il massimo delle prestazioni, non per contenere i costi. Appena installato, il modello principale è impostato su anthropic/claude-opus-4-5 — cioè l’opzione più costosa disponibile. I ping di heartbeat? Vanno pure loro su Opus. I sotto-agenti che partono per gestire task secondari? Ancora Opus. Usare Opus per un ping di heartbeat è come chiamare un neurochirurgo per mettere un cerotto. Tecnicamente perfetto, economicamente fuori di testa.
Molti utenti non si accorgono di stare pagando tariffe premium per attività banali in background. La configurazione di default, in pratica, dà per scontato che tu voglia il modello migliore per tutto, sempre — e ti presenta il conto di conseguenza.
Perché ridurre il consumo di token di OpenClaw fa risparmiare più dei soli soldi
Il vantaggio più ovvio è il risparmio economico. Ma ci sono anche benefici indiretti che si sommano nel tempo.
I modelli più economici sono spesso più veloci. Gemini 2.5 Flash-Lite gira a circa 214 token al secondo contro gli ~51 di Opus — quindi un miglioramento di 4x in ogni interazione. GPT-OSS-120B su Cerebras arriva a 1.917 token al secondo, cioè circa 35x più veloce di Opus. In un loop agentico con 50+ passaggi di tool-calling, questa differenza vuol dire chiudere in pochi minuti invece di restare inchiodati al doloroso time-to-first-token di 13,6 secondi di Opus a ogni andata e ritorno.
In più ottieni più margine prima di arrivare ai rate limit, meno sessioni rallentate e spazio per scalare l’uso senza far crescere allo stesso ritmo l’ansia da fattura.
Risparmio stimato in base a diversi profili d’uso:
| Profilo utente | Spesa mensile stimata (Default) | Dopo ottimizzazione completa | Risparmio mensile |
|---|---|---|---|
| Leggero (~10 query/giorno) | ~$100 | ~$12 | ~88% |
| Medio (~50 query/giorno) | ~$500 | ~$90 | ~82% |
| Intensivo (~200+ query/giorno) | ~$1,750 | ~$220 | ~87% |
Non è teoria. Un developer ha documentato il passaggio da $600–750/mese a $3–4/giorno — un taglio reale del 90% — combinando il routing dei modelli con le ottimizzazioni sui costi nascosti che vedremo più avanti.
Anatomia del consumo token di OpenClaw: dove vanno davvero tutti i token
Questa è la parte che molte guide di ottimizzazione saltano, ed è anche quella che conta di più. Non puoi sistemare quello che non riesci a vedere.
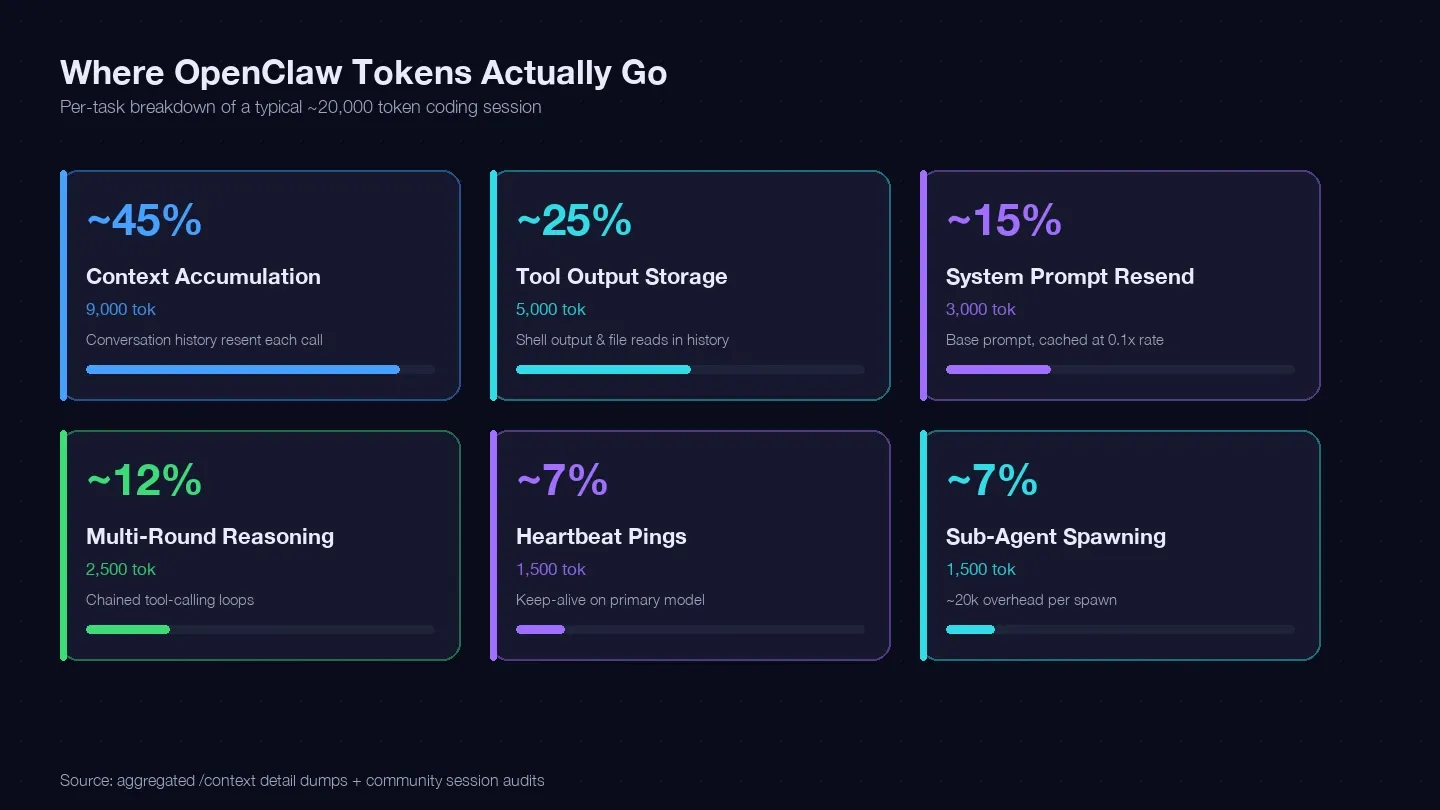
Ho analizzato diverse sessioni e le ho confrontate con la guida di ottimizzazione dei costi di LaoZhang e con i dump /context della community per costruire un registro token di una tipica attività di coding singola. Ecco dove sono finiti, più o meno, 20.000 token:
| Categoria token | % tipica del totale | Esempio (1 task di coding) | La puoi controllare? |
|---|---|---|---|
| Accumulo del contesto (cronologia della conversazione reinviata a ogni chiamata) | ~40–50% | ~9.000 token | Sì — /clear, /compact, sessioni più brevi |
| Memorizzazione output dei tool (output shell, letture file mantenute nella cronologia) | ~20–30% | ~5.000 token | Sì — letture più piccole, scope dei tool più stretto |
| Reinvio del system prompt (~15K base) | ~10–15% | ~3.000 token | In parte — letture cache a tariffa 0,1x |
| Ragionamento multi-round (loop concatenati di tool-calling) | ~10–15% | ~2.500 token | Scelta del modello + prompt migliori |
| Ping di heartbeat / keep-alive | ~5–10% | ~1.500 token | Sì — cambio configurazione |
| Chiamate ai sotto-agenti | ~5–10% | ~1.500 token | Sì — routing dei modelli |
La voce più pesante in assoluto — l’accumulo del contesto — è la cronologia della conversazione che viene reinviata a ogni chiamata API. Un dump reale di sessione mostrava 185.400 token solo nel bucket Messages, ancora prima che il modello rispondesse. Il system prompt e i tool aggiungevano altri ~35.800 token di overhead fisso.
Il punto chiave: se non chiudi le sessioni tra attività scollegate, stai pagando per rimandare tutta la cronologia della conversazione a ogni singolo turno.
Come monitorare il consumo di token di OpenClaw (non puoi tagliare ciò che non vedi)
Prima di cambiare qualsiasi cosa, devi capire dove stanno andando i token. Saltare subito a «usa un modello più economico» senza monitoraggio è come cercare di dimagrire senza mai salire su una bilancia.
Controlla la dashboard di OpenRouter
Se instradi tramite OpenRouter, la pagina Activity è il dashboard più semplice da usare senza configurazioni. Puoi filtrare per modello, provider, API key e intervallo di tempo. La vista Usage Accounting separa prompt, completion, reasoning e cached token per ogni richiesta. C’è anche un pulsante Export (CSV o PDF) per analisi più ampie.
Cosa guardare: quale modello ha consumato più token e se le request di heartbeat o dei sotto-agenti compaiono come voci insolitamente grandi.
Analizza i log della tua API locale
OpenClaw salva i dati di sessione in ~/.openclaw/agents.main/sessions/sessions.json, che include totalTokens per sessione. Puoi anche eseguire openclaw logs --follow --json per avere il logging in tempo reale di ogni richiesta.
Un avviso importante: sessions.json totalTokens non viene aggiornato dopo la compattazione, quindi il dashboard può mostrare valori vecchi pre-compattazione. Dai più fiducia a /status e /context detail rispetto ai totali salvati.
Usa strumenti di tracking di terze parti (per utenti medi o intensivi)
LiteLLM proxy ti offre un endpoint compatibile OpenAI davanti a oltre 100 provider e registra automaticamente la spesa per chiave virtuale, modello, utente e team. La funzione più utile: budget rigidi per chiave che resistono a /clear — un sotto-agente fuori controllo non può superare il tetto che hai impostato.
Helicone è ancora più semplice — basta cambiare la base URL in una sola riga e ottieni una vista Sessions che raggruppa le richieste collegate. Un singolo prompt «fix this bug» che si espande in 8+ chiamate a sotto-agenti appare come una sola riga di sessione con il costo totale reale. Piano gratuito: 10.000 richieste/mese.
Controlli rapidi direttamente in OpenClaw
Per il monitoraggio quotidiano, questi quattro comandi in sessione fanno il lavoro:
/status— mostra uso del contesto, ultimi token input/output, costo stimato/usage full— riepilogo dell’utilizzo per risposta/context detail— ripartizione per file, skill e tool/compact [guidance]— forza la compattazione con una stringa di focus opzionale
Esegui /context detail prima e dopo aver cambiato la configurazione. È così che capisci se le ottimizzazioni hanno davvero funzionato.
La sfida del modello più economico di OpenClaw: quali LLM economici reggono davvero il lavoro agentico
Molte guide qui prendono una cantonata. Ti mostrano una tabella prezzi, indicano la riga più economica e fine lì. I benchmark non raccontano le prestazioni reali nei contesti agentici — un punto che la community ha ribadito forte e chiaro. Come ha detto un utente: «i benchmark non aiutano davvero a capire quale funzioni meglio per l’AI agentica».
L’idea chiave è questa: il modello più economico non è sempre il risultato più economico. Un modello che fallisce e riprova quattro volte costa più di un modello di fascia media che riesce al primo colpo. Nei sistemi agentici in produzione, considera un tasso di retry del 5–10% — e se cinque chiamate LLM sono in catena e fallisce il passaggio quattro, un retry ingenuo rilancia tutti e cinque i passaggi.
Ecco la mia matrice delle capacità, con un “Real Agentic Score” basato su report reali degli utenti e non su benchmark sintetici:
| Modello | Input $/1M | Output $/1M | Affidabilità tool-calling | Ragionamento multi-step | Real Agentic Score (1–5) | Ideale per |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Mista — qualche loop occasionale | Base | ⭐2.5 | Heartbeat, ricerche semplici |
| GPT-OSS-120B | $0.04 | $0.19 | Adeguata | Adeguato | ⭐3.0 | Sperimentazione economica, scenari dove la velocità conta |
| DeepSeek V3.2 | $0.26 | $0.38 | Incostante (6 issue aperte) | Buono | ⭐3.0 | Molto ragionamento, poco tool calling |
| Kimi K2.5 | $0.38 | $1.72 | Buona (via :exacto) | Adeguato | ⭐3.5 | Coding semplice o medio |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Buona | Buono | ⭐4.0 | Modello quotidiano per coding generale |
| Claude Haiku 4.5 | $1.00 | $5.00 | Eccellente | Buono | ⭐4.5 | Fallback mid-tier affidabile |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Eccellente | Eccellente | ⭐5.0 | Task complessi multi-step |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Eccellente | Eccellente | ⭐5.0 | Da tenere solo per i problemi più difficili |
Un avvertimento su DeepSeek e Gemini Flash per il tool calling
DeepSeek V3.2 sulla carta sembra fortissimo — 72–74% su SWE-Bench, da 11 a 36 volte più economico di Sonnet. Nella pratica, sei issue GitHub separate su Cline, Roo Code, Continue e NVIDIA NIM documentano comportamenti di tool-calling rotti. Il verdetto di Composio nel confronto diretto: «DeepSeek V3.2 ha costruito parti dell’app ma ha vacillato su esecuzione, velocità e affidabilità.» La sintesi di Zvi Mowshowitz: «okay and cheap, but.»
Gemini 2.5 Flash mostra un problema simile. Un thread del Google AI Developers Forum intitolato “Very frustrating experience with Gemini 2.5 function calling performance” si apre con: «il comportamento di function calling dei modelli Gemini è diventato completamente inaffidabile e imprevedibile.»
OpenRouter ha segnalato una sfumatura importante: «la propensione di un modello a chiamare tool e la precisione di quelle chiamate possono variare drasticamente tra host con gli stessi pesi.» Se instradi modelli economici tramite OpenRouter, cerca il tag :exacto — un cambio silenzioso di provider può trasformare da un giorno all’altro un modello economico affidabile in un costoso loop di retry.
Quando usare ciascun modello
- Gemini Flash-Lite: heartbeat, keep-alive ping, Q&A semplice. Mai per tool calling multi-step.
- MiniMax M2.5/M2.7: il tuo modello quotidiano per task di coding generali. SWE-Pro 56.22, Terminal-Bench 2 57,0% a una frazione del prezzo di Sonnet.
- Claude Haiku 4.5: il fallback affidabile quando i modelli economici vanno in crisi con i tool. Affidabilità del tool calling eccellente a circa 3x meno di Sonnet.
- Claude Sonnet 4.6: lavoro agentico complesso multi-step. È qui che ottieni davvero valore per quello che spendi.
- Claude Opus: tienilo per i problemi più duri. Non lasciarlo essere il tuo default per niente.
(I prezzi dei modelli cambiano spesso — verifica le tariffe correnti su OpenRouter o sulle pagine dirette dei provider prima di fissare una configurazione.)
I drenaggi nascosti di token che la maggior parte delle guide ignora
Gli utenti dei forum segnalano che disattivare certe funzioni riduce parecchio i costi, ma nessuna guida che ho trovato offre una checklist unica di tutti i drenaggi nascosti con il loro impatto reale in token. Ecco l’analisi completa:
| Drenaggio nascosto | Costo in token per occorrenza | Come risolvere | Chiave di configurazione |
|---|---|---|---|
| Heartbeat di default su Opus | ~100.000 token/run senza isolamento | Override con Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Avvio dei sotto-agenti | ~20.000 token per avvio ancora prima del lavoro | Instrada i sotto-agenti su Haiku | subagents.model |
| Caricamento del contesto dell’intera codebase | ~3.000–15.000 token per auto-explore | .clawignore per node_modules, dist, lockfile | .clawrules + .clawignore |
| Auto-sintesi della memoria | ~500–2.000 token/sessione | Disattiva o riduci la frequenza | memory: false oppure memory.max_context_tokens |
| Accumulo della cronologia conversazionale | ~500+ token/turno (cumulativi) | Inizia nuove sessioni tra attività scollegate | disciplina con /clear |
| Overhead dei tool del server MCP | ~7.000 token per 4 server; 50.000+ per 5 o più | Mantieni MCP al minimo | Rimuovi i MCP non usati |
| Inizializzazione skill/plugin | 200–1.000 token per skill caricata | Disattiva le skill non usate | skills.entries.<name>.enabled: false |
| Agent Teams (modalità plan) | ~7x il costo di una sessione standard | Usali solo per lavoro davvero parallelo | Preferisci il sequenziale |
Il drenaggio dovuto agli heartbeat merita una nota a parte. Di default, gli heartbeat girano sul modello principale (Opus) ogni 30 minuti. Impostando isolatedSession: true si passa da ~100.000 token per esecuzione a 2.000–5.000 token — una riduzione del 95–98% su questa singola voce.
Tre vittorie rapide che fanno risparmiare più token in meno di due minuti
Sono tutte a rischio zero e richiedono meno di due minuti:
-
/cleartra attività non correlate (5 secondi). È il risparmio token più grosso in assoluto. Il consenso nei forum lo indica come riduzione del 50–70% semplicemente cancellando la cronologia della sessione prima di iniziare un nuovo lavoro. Ti ricordi il bucket Messages da 185k token del dump /context?/clearlo azzera. -
/model haiku-4.5per il lavoro pesante e ripetitivo (10 secondi). Il cambio tattico di modello porta a una riduzione del 60–80% dei costi sulle attività di routine. Haiku gestisce molto bene coding semplice, lookup dei file e commit message. -
Riduci
.clawrulesa meno di 200 righe + aggiungi.clawignore(90 secondi). Il file delle regole viene caricato a ogni singolo messaggio. Con 200 righe siamo a circa 1.500–2.000 token per turno; con 1.000 righe arrivi a 8.000–10.000 token che pesano in modo permanente su ogni richiesta. Insieme a un.clawignoreche escludenode_modules/,dist/, i lockfile e il codice generato, un developer sostiene di aver ottenuto una riduzione del 92% dei token solo con questa disciplina.
Passo dopo passo: tre configurazioni pronte da copiare per ridurre il consumo di token di OpenClaw

Qui sotto trovi tre configurazioni complete e annotate di openclaw.json — da «parto e basta» a «stack di ottimizzazione completo». Ogni esempio include commenti inline e stime di costo mensile.
Prima di iniziare:
- Difficoltà: Principiante (Config A) → Intermedio (Config B) → Avanzato (Config C)
- Tempo necessario: ~5 minuti per Config A, ~15 minuti per Config C
- Cosa ti serve: OpenClaw installato, un editor di testo, accesso a
~/.openclaw/openclaw.json
Config A: Principiante — risparmiare solo soldi
Cinque righe. Zero complicazioni. Sostituisce il modello di default da Opus a Sonnet, disattiva l’overhead della memoria e isola gli heartbeat su Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // prima era Opus — risparmio immediato 3-5x
"heartbeat": {
"every": "55m", // allinea al TTL cache di 1h per massimizzare i cache hit
"model": "anthropic/claude-haiku-4-5", // Haiku per i ping, non Opus
"isolatedSession": true // ~100k → 2-5k token per run
}
}
},
"memory": { "enabled": false } // risparmia ~500-2k token/sessione
}
Cosa dovresti vedere dopo l’applicazione: esegui /status prima e dopo. Il costo per richiesta dovrebbe scendere in modo evidente e le voci heartbeat nella tua pagina Activity di OpenRouter dovrebbero mostrare Haiku invece di Opus.
| Livello d’uso | Default (Opus) | Config A (Sonnet + heartbeat Haiku) | Risparmio |
|---|---|---|---|
| Leggero (~10 query/giorno) | ~$100 | ~$35 | 65% |
| Medio (~50 query/giorno) | ~$500 | ~$250 | 50% |
| Intensivo (~200 query/giorno) | ~$1,750 | ~$900 | 49% |
Config B: Intermedio — routing intelligente a tre livelli
Sonnet come principale per il lavoro vero. Haiku per sotto-agenti e compattazione. Gemini Flash-Lite come fallback economico quando Claude rallenta. Le catene di fallback gestiscono automaticamente i problemi del provider.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // se Sonnet viene throttled
"google/gemini-2.5-flash-lite" // ultima scelta ultra-economica
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55min < TTL cache 1h = cache hit
"model": "google/gemini-2.5-flash-lite", // spiccioli per ping
"isolatedSession": true,
"lightContext": true // contesto minimo nelle chiamate heartbeat
},
"subagents": {
"maxConcurrent": 4, // ridotto da 8 di default
"model": "anthropic/claude-haiku-4-5" // i sotto-agenti non hanno bisogno di Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // riepiloghi di compattazione via Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Risultato atteso: nei log vedrai che le voci dei sotto-agenti ora usano il prezzo di Haiku. Gli heartbeat dovrebbero costare quasi nulla. La catena di fallback evita che un outage di Claude blocchi la sessione — degrada in modo ordinato verso Gemini.
| Livello d’uso | Default | Config B | Risparmio |
|---|---|---|---|
| Leggero | ~$100 | ~$20 | 80% |
| Medio | ~$500 | ~$150 | 70% |
| Intensivo | ~$1,750 | ~$500 | 71% |
Config C: Power user — stack completo di ottimizzazione
Assegnazione del modello per singolo sotto-agente, compattazione del contesto fissata su Haiku, routing delle immagini a Gemini Flash, .clawrules + .clawignore molto stretti, skill inutilizzate disattivate. Questa è la configurazione che ti porta nella fascia di risparmio dell’85–90%.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // provider diverso come backup
"minimax/minimax-m2-7", // fallback economico per uso quotidiano
"anthropic/claude-haiku-4-5" // ultima risorsa
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // niente heartbeat durante la notte
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // ridotto da 20000 di default
"imageModel": "google/gemini-3-flash" // task visivi tramite modello economico
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // memoria minima
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Esempio di override per singolo sotto-agente — incolla in ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Esegue controlli di lint/format e applica correzioni banali
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
.clawignore minimo ma efficace — da solo riduce i bootstrap tipici da 150k caratteri verso 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Livello d’uso | Default | Config C | Risparmio |
|---|---|---|---|
| Leggero | ~$100 | ~$12 | 88% |
| Medio | ~$500 | ~$90 | 82% |
| Intensivo | ~$1,750 | ~$220 | 87% |
Questi numeri sono coerenti con due report indipendenti di utenti reali: il caso documentato di Praney Behl da $600–750/mese a $3–4/giorno (taglio del 90%) e i case study di LaoZhang che mostrano $943 → $347 (63%), $1.750 → $1.000 (64%), $200 → $70 (65%) con ottimizzazione parziale.
Usare il comando /model per controllare al volo il consumo di token di OpenClaw
Il comando /model cambia il modello attivo per il turno successivo mantenendo il contesto della conversazione — nessun reset, nessuna perdita di cronologia. È l’abitudine quotidiana che, nel tempo, fa accumulare risparmi.
Flusso pratico:
- Stai lavorando a un refactor complesso su più file? Rimani su Sonnet.
- Domanda veloce tipo «che cosa fa questa regex?»
/model haiku, fai la domanda, poi/model sonnetper tornare indietro. - Commit message o rifinitura della documentazione?
/model flash-lite, fatto.
Puoi configurare alias in openclaw.json sotto commands.aliases per associare nomi brevi (haiku, sonnet, opus, flash) alle stringhe complete del provider. Ti fa risparmiare qualche tasto a ogni switch.
La matematica: 50 query al giorno su Sonnet sono circa 3 $/giorno. Le stesse 50 query distribuite 70/20/10 tra Haiku/Sonnet/Opus costano circa 1,10 $/giorno. In un mese diventano 90 $ → 33 $ — 63% in meno senza cambiare strumenti, solo abitudini.
Bonus: monitorare i prezzi dei modelli OpenClaw tra provider con Thunderbit
Monitora i prezzi dei modelli tra i provider con l’AI Get Started Free
Con così tanti modelli e provider — OpenRouter, API diretta Anthropic, Google AI Studio, DeepSeek, MiniMax — i prezzi cambiano di continuo. Anthropic ha tagliato da un giorno all’altro il prezzo di output di Opus di circa il 67%. Google ha ridotto i limiti del free tier di Gemini del 50–80% nel dicembre 2025. Tenere aggiornato a mano un foglio statico dei prezzi è una battaglia persa.
Thunderbit risolve tutto questo senza scrivere codice di scraping. È un estensione Chrome di AI web scraper costruita proprio per questo tipo di estrazione strutturata di dati.
Il flusso che uso io:
- Apro la pagina dei modelli OpenRouter in Chrome e clicco su Thunderbit “AI Suggest Fields”. Legge la pagina e propone le colonne — nome modello, prezzo input, prezzo output, context window, provider.
- Premo Scrape, poi esporto direttamente su Google Sheets.
- Imposto uno scraping pianificato in linguaggio naturale — “ogni lunedì alle 9, riscrapa la lista modelli OpenRouter” — e parte da solo nel cloud.
Da lì in poi, il tuo tracker dei prezzi si aggiorna automaticamente. Qualsiasi modello che cala improvvisamente del 30% — o qualsiasi provider che riceve un tag Exacto — comparirà nel foglio del lunedì mattina senza che tu debba muovere un dito. Abbiamo scritto di più su AI data extraction per il business nel nostro blog.
Devi confrontare i prezzi tra le pagine dirette dei provider (Anthropic, Google, DeepSeek)? Lo scraping delle sottopagine di Thunderbit segue ogni link del modello nella pagina dettagliata e recupera le tariffe per provider — utile quando vuoi capire se instradare Kimi K2.5 tramite OpenRouter costa meno che passare direttamente da NVIDIA Build. Controlla i prezzi di Thunderbit per i dettagli su piano gratuito e abbonamenti.
Punti chiave per ridurre il consumo di token di OpenClaw
Il metodo è: Capire → Monitorare → Instradare → Ottimizzare.
Azioni con il maggiore impatto, in ordine:
- Non usare Opus come default. Sposta il modello principale su Sonnet o MiniMax M2.7. Da solo vale un taglio dei costi di 3–5x.
- Isola gli heartbeat. Imposta
isolatedSession: truee instrada gli heartbeat su Gemini Flash-Lite. Trasformi un drenaggio da ~100k token in ~2–5k. - Instrada i sotto-agenti su Haiku. Ogni avvio carica ~20k token di contesto prima di fare qualsiasi cosa. Non lasciarlo accadere su Opus.
- Usa
/clearin modo rigoroso. È gratis, richiede 5 secondi e secondo il consenso della community fa risparmiare più di qualsiasi altra singola azione. - Aggiungi
.clawignore. Escluderenode_modules, lockfile e artefatti di build riduce parecchio il contesto di bootstrap. - Monitora con
/context detailprima e dopo i cambiamenti. Se non puoi misurarlo, non puoi migliorarlo.
Il modello più economico dipende dal task. Gemini Flash-Lite per gli heartbeat. MiniMax M2.7 per il coding quotidiano. Haiku per il tool calling affidabile. Sonnet per il lavoro complesso multi-step. Opus solo per i problemi davvero più difficili — e nient’altro.
La maggior parte dei lettori può vedere un risparmio del 50–70% in un solo pomeriggio con Config A o B. L’85–90% completo richiede di combinare tutto il resto — routing dei modelli, correzione dei drenaggi nascosti, .clawignore, disciplina sulle sessioni — ma è raggiungibile, e dura nel tempo.
FAQ
1. Quanto costa OpenClaw al mese?
Dipende tutto dalla configurazione, dal volume d’uso e dai modelli scelti. Gli utenti leggeri (~10 query/giorno) spendono in genere 5–30 $/mese con ottimizzazione, oppure 100+ $ con le impostazioni default. Gli utenti medi (~50 query/giorno) vanno da 90 a 400 $/mese. Gli utenti intensivi possono arrivare a 600–2.000+/mese con le impostazioni predefinite — un caso estremo documentato ha toccato 5.623 $ in un solo mese. La telemetria interna di Anthropic suggerisce persino una mediana di 13 $/developer/giorno attivo.
2. Qual è il modello OpenClaw più economico che funziona ancora bene per il coding?
MiniMax M2.5/M2.7 è il miglior modello quotidiano generale — buona affidabilità nel tool calling, SWE-Pro 56.22, a circa 0,28/1,10 $ per milione di token. Per heartbeat e ricerche semplici, Gemini 2.5 Flash-Lite a 0,10/0,40 $ è difficilissimo da battere. Claude Haiku 4.5 a 1/5 $ è il fallback mid-tier affidabile quando ti serve un ottimo tool calling senza pagare i prezzi di Sonnet.
3. Posso usare modelli free-tier con OpenClaw?
Tecnicamente sì. GPT-OSS-120B è gratuito con il tag :free di OpenRouter e su NVIDIA Build. Gemini Flash-Lite ha un free tier (15 RPM, 1.000 richieste/giorno). DeepSeek offre 5 milioni di token gratuiti alla registrazione. Ma i free tier hanno rate limit aggressivi, velocità più basse e disponibilità meno affidabile. I modelli economici a pagamento — pochi centesimi per milione di token — sono molto più affidabili per un uso regolare.
4. Cambiare modello a metà conversazione con /model mi fa perdere il contesto?
No. /model conserva l’intero contesto della sessione — il turno successivo viene instradato al nuovo modello con tutta la cronologia intatta. Questo è confermato nella documentazione concettuale di OpenClaw e funziona allo stesso modo in Claude Code. Puoi passare liberamente da Haiku per le domande rapide a Sonnet per il lavoro complesso senza perdere nulla.
5. Qual è il modo più veloce per ridurre la bolletta di OpenClaw oggi?
Digita /clear tra attività non correlate. È gratis, richiede cinque secondi e cancella la cronologia della conversazione che viene reinviata a ogni chiamata API. Una sessione reale mostrava 185.000 token di storico messaggi accumulato — tutto ritrasmesso e rifatturato a ogni singolo turno. Cancellarlo prima di iniziare un nuovo lavoro è l’abitudine con il ROI più alto che puoi costruire.
Prova Thunderbit per l’AI Web Scraping Get Started Free




