

Ottimizzare le query delle liste in Apollo non è solo una questione tecnica: è una capacità indispensabile per chiunque si basi su dati news in tempo reale, sull’estrazione automatica di notizie o su flussi di lavoro commerciali e operativi ad alta velocità. L’ho visto con i miei occhi: una query lenta può trasformare una dashboard pulita e ordinata in un vero collo di bottiglia, lasciando i team sales a fissare schermate di caricamento infinite e i colleghi operations a improvvisare soluzioni di fortuna nei fogli di calcolo. In un contesto in cui il 60% del tempo dei sales rep è già assorbito da attività non legate alla vendita, ogni millisecondo conta davvero.
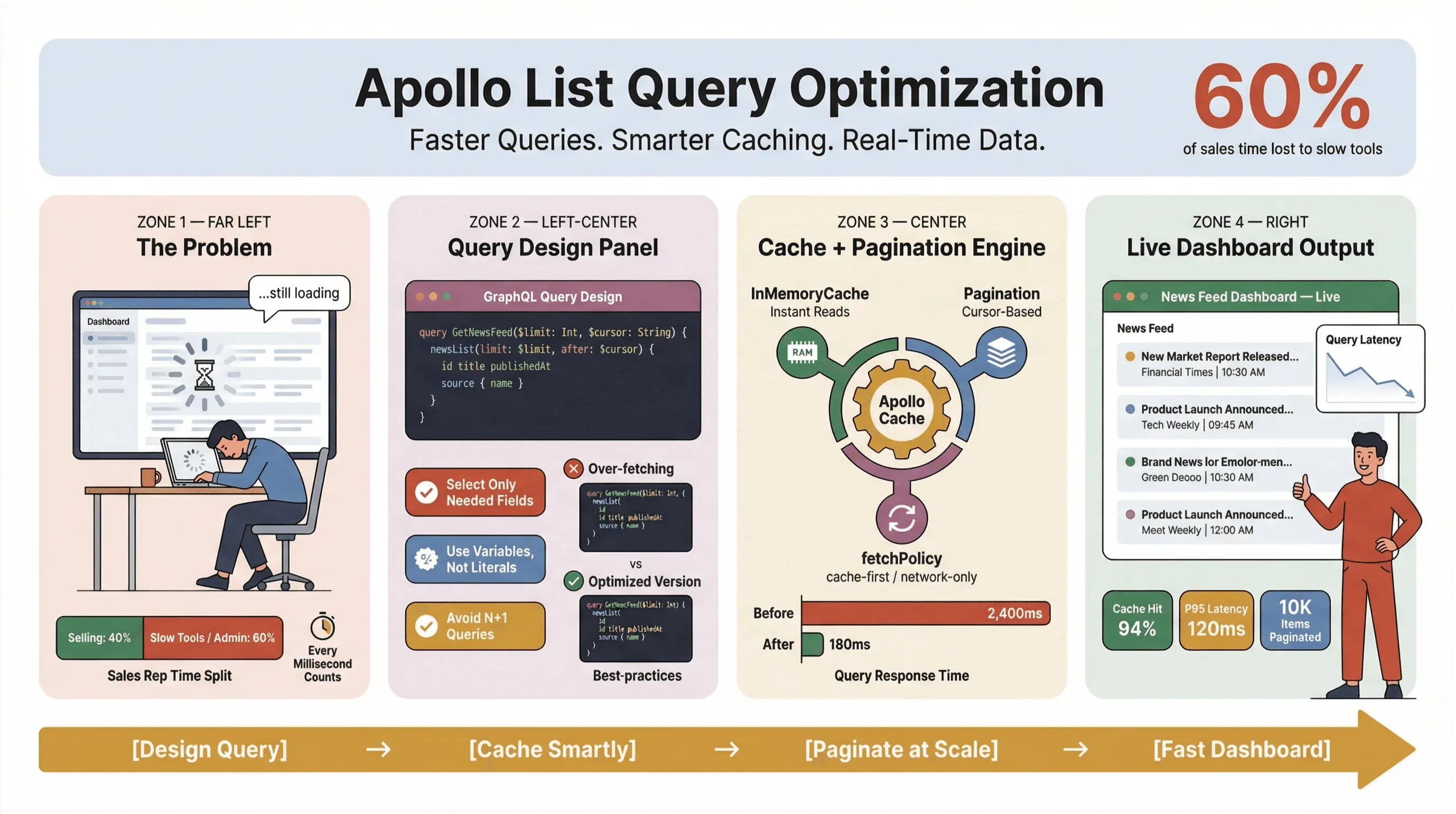
Quindi, come si fa a mantenere veloci, affidabili e coerenti su larga scala le query di lista in Apollo Client — soprattutto quando si estraggono notizie, si tracciano lead o si alimentano dashboard mission-critical? In questa guida ti mostrerò le pratiche che funzionano davvero in produzione: progettazione delle query, caching, paginazione e integrazione di strumenti no-code come Thunderbit per automatizzare il lavoro pesante dell’estrazione notizie.
--- Se sei uno sviluppatore, un product manager o semplicemente la persona a cui tutti danno la colpa quando la dashboard rallenta, questa è la tua guida pratica alle performance delle liste in Apollo GraphQL.
Prova Thunderbit per l’estrazione automatica di notizie
Perché ottimizzare le query di lista in Apollo? (apollo client list performance, optimize apollo list queries)
Diciamolo chiaramente: nessuno ha voglia di aspettare il caricamento delle ultime notizie o dei lead di vendita. Nei contesti aziendali — soprattutto quando si fa affidamento su estrazione automatica di notizie o dati in tempo reale — le query lente in Apollo non si limitano a dare fastidio agli utenti: fanno perdere soldi, rallentano le decisioni e riportano le persone verso processi manuali. Ricerche ricorrenti di Slack Workforce Lab mostrano con costanza che i knowledge worker spendono circa un terzo — e nei report più recenti quasi il 40% — della giornata in attività ripetitive e a basso valore, spesso perché gli strumenti frammentano il lavoro su superfici lente.
Ecco cosa succede quando le query di lista non sono ottimizzate:
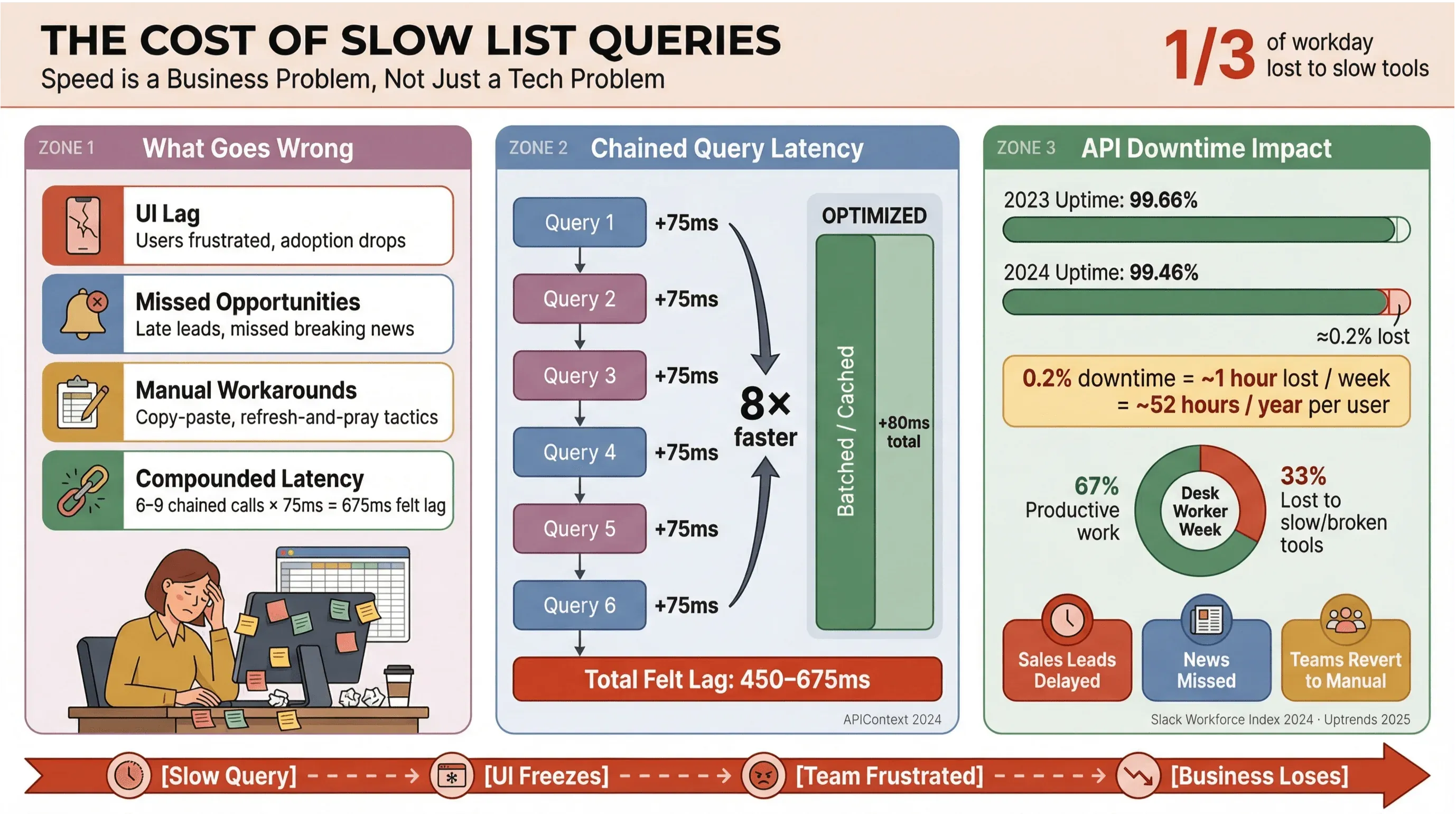
- Interfaccia lenta: gli utenti percepiscono ritardi, con conseguente frustrazione e minore adozione.
- Opportunità perse: nelle vendite o nel monitoraggio delle news, anche pochi secondi possono bastare per perdere un lead caldo o una notizia importante.
- Soluzioni manuali: i team tornano a copiare e incollare, usare fogli di calcolo o affidarsi alla strategia del “aggiorna e spera”.
- Latenza cumulativa: ogni chiamata API lenta si somma alle altre — se il workflow attiva 6–9 query dipendenti, un ritardo di soli 75 ms per chiamata può gonfiarsi fino a un lag percepito di 450–675 ms (APIContext).
E non si tratta solo di velocità. I downtime delle API sono in aumento, con l’uptime medio sceso dal 99,66% al 99,46% in appena un anno: per le applicazioni che gestiscono molte liste, questo si traduce in quasi un’ora di produttività persa a settimana. Quando il tuo business dipende da dati news in tempo reale, è un rischio che non puoi ignorare.
Scegliere la struttura dati e i campi giusti (apollo graphql list best practices)
Uno degli errori più comuni che vedo — e sì, l’ho fatto anch’io — è trattare ogni query di lista come se fosse una query di dettaglio. In GraphQL hai il vantaggio di recuperare esattamente ciò che ti serve: sfruttalo. Recuperare troppi dati è il peggior nemico delle performance, soprattutto negli strumenti di news scraping e nelle dashboard in tempo reale.
Adattare i campi per l’estrazione automatica di notizie
Immagina di costruire un feed news. Ti servono davvero il testo completo dell’articolo, tutti i tag, i commenti e la bio dell’autore nella query di lista? Probabilmente no. Ecco la differenza:
Query di lista efficiente:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Query di lista inefficiente (da evitare):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
La prima query è leggera ed efficace — perfetta per ordinare, filtrare e renderizzare righe. La seconda? È una query di dettaglio travestita, che recupera payload enormi e rallenta tutto (specifica GraphQL, best practice Apollo).
Consiglio pratico: adotta un approccio a due livelli — recupera solo campi leggeri nella lista e carica i dettagli pesanti (come testo completo o arricchimento NLP) solo quando l’utente apre un elemento o ci passa sopra con il mouse.
Sfruttare la cache di Apollo Client per query più veloci (apollo client list performance)
La cache di Apollo Client è la leva più potente che hai per migliorare le performance delle query di lista. Se configurata bene, ti permette di:
- Servire le query ripetute all’istante (senza round-trip di rete)
- Ridurre il carico sul server e i costi API
- Consentire una navigazione avanti/indietro fluida e cambi filtro senza attriti
Ma la cache non fa miracoli: richiede un minimo di configurazione e disciplina.
Impostare policy di cache efficaci
Apollo supporta diverse fetch policy:
| Policy | Cosa fa | Caso d’uso migliore per liste news |
|---|---|---|
| cache-first | Legge dalla cache e interroga la rete solo se manca | Riapertura di liste, cambio filtri, navigazione avanti/indietro |
| network-only | Recupera sempre dalla rete | Refresh manuale, “ultime notizie” |
| cache-and-network | Mostra prima la cache e poi aggiorna con la risposta di rete | Primo rendering rapido + aggiornamento in background (ottimo per i feed news) |
| no-cache | Recupera sempre, senza mai salvare in cache | Query sensibili e isolate (rare per le liste) |
Per i dati news in tempo reale, io preferisco cache-and-network: offre risultati immediati agli utenti e poi si aggiorna in background. Attenzione però al flicker dell’interfaccia se i dati cambiano ordine al refresh (issue GitHub).
Suggerimenti per la configurazione della cache:
- Usa ID stabili (
ido_id) per la normalizzazione (documentazione cache Apollo). - Ottimizza dimensione della cache e garbage collection per liste molto grandi (gestione memoria).
- Evita di salvare grossi blob non normalizzati sotto
ROOT_QUERY: possono bloccare l’app (segnalazione della community).
Implementare la paginazione e limitare il numero di elementi (apollo graphql list best practices)
Se carichi centinaia o migliaia di articoli news o lead commerciali in una volta sola, stai andando incontro ai problemi. La paginazione non è solo una funzione UX: è una necessità prestazionale.
Apollo supporta sia la paginazione basata su offset sia quella basata su cursor. Ecco come si confrontano:
| Tipo di paginazione | Vantaggi | Svantaggi | Ideale per |
|---|---|---|---|
| Basata su offset | Semplice, facile da implementare | Può saltare o duplicare elementi se i dati cambiano | Liste piccole o immutabili |
| Basata su cursor | Più stabile, gestisce bene le variazioni dei dati | Leggermente più complessa | Feed news, liste grandi |
Per la maggior parte delle liste news o lead in tempo reale, la scelta migliore è la paginazione basata su cursor. Mantiene i dati coerenti anche quando arrivano nuovi elementi o vengono eliminati quelli vecchi (GraphQL Foundation).
Suggerimenti per la paginazione in Apollo:
- Configura
keyArgsper controllare le chiavi cache dei campi paginati (documentazione). - Implementa una funzione
mergeper unire le pagine nella cache. - Usa
fetchMoreper caricare altre pagine senza sovrascrivere i risultati precedenti.
Pattern pratici di paginazione per strumenti di news scraping
Una tipica interfaccia di news scraping:
- Mostra le ultime 20–50 notizie (solo campi essenziali)
- Carica altri risultati con scroll o clic su “pagina successiva”
- Recupera i dettagli solo quando servono
Così l’interfaccia resta veloce, l’API respira meglio e gli utenti lavorano in modo più efficiente.
Integrare Thunderbit per l’estrazione automatica di notizie
Parliamo ora dell’elefante nella stanza: da dove arrivano tutti questi dati news strutturati, in primo luogo? È qui che entra in gioco Thunderbit.
Ottieni l’estensione Chrome di Thunderbit Get Started Free
Thunderbit è un’estensione Chrome no-code di AI web scraper capace di estrarre titoli di notizie, URL, fonti, autori, date di pubblicazione, riepiloghi e immagini praticamente da qualsiasi sito, senza bisogno di programmare. Ho visto team usare Thunderbit per automatizzare l’intero processo di estrazione delle news, trasformando pagine web non strutturate in dati puliti e strutturati, pronti per essere inseriti direttamente in un database o in una GraphQL API.
Unire Thunderbit e Apollo per dati news in tempo reale
Ecco un workflow che adoro per i team sales e operations che hanno bisogno di notizie sempre aggiornate:
- Livello di estrazione: usa il template News Scraper di Thunderbit per raccogliere dati news strutturati dai siti target secondo una pianificazione.
- Livello di archiviazione: salva i dati estratti in un database ottimizzato per il recupero rapido.
- Livello GraphQL: esponi un campo lista
newsFeede un campo dettaglionewsArticle(id)tramite la tua API. - Livello client: usa Apollo Client per recuperare la lista (campi leggeri, con paginazione) e i dettagli solo quando servono.
Questo flusso “estrai → salva → interroga” fa sì che le query Apollo lavorino sempre su dati freschi e strutturati, senza copy-paste manuale o script fragili.
Bonus: Thunderbit può anche arricchire le tue liste con campi aggiuntivi (come sentiment o categoria) grazie ai suggerimenti di campo basati su AI, rendendo il tuo feed news ancora più intelligente.
Guida passo passo: ottimizzare le query di lista in Apollo
Pronto a passare all’azione? Ecco la mia checklist di riferimento per ottimizzare le query di lista in Apollo:
-
Snellisci le query
- Richiedi solo i campi necessari per renderizzare la lista (titolo, URL, timestamp, ecc.).
- Sposta i campi pesanti (testo completo, immagini, arricchimenti) nelle query di dettaglio.
-
Implementa la paginazione
- Usa la paginazione basata su cursor per liste grandi o dinamiche.
- Configura
keyArgse funzionimergeper garantire la correttezza della cache.
-
Sfrutta la cache di Apollo
- Normalizza le entità con ID stabili.
- Scegli la fetch policy giusta (
cache-and-networkè ottima per le news). - Ottimizza dimensione della cache e garbage collection in base al volume dei dati.
-
Integra l’estrazione automatica
- Usa Thunderbit per automatizzare lo scraping delle news e mantenere i dati aggiornati.
- Esporta i dati strutturati direttamente nel database o in un foglio di calcolo.
-
Monitora e risolvi i problemi
- Usa Apollo Client Devtools per ispezionare query, cache e performance.
- Tieni d’occhio scritture di cache troppo grandi, query osservate in eccesso e rallentamenti dell’interfaccia.
- Monitora la latenza p95/p99 e i tassi di errore (New Relic, Uptrends).
Monitoraggio e troubleshooting delle performance delle query
Gli strumenti Devtools di Apollo sono un vero salvavita in questo contesto. Ti permettono di:
- Ispezionare query attive e stato della cache
- Individuare query duplicate o watcher eccessivi
- Rilevare blob di cache troppo grandi o problemi di normalizzazione
Se noti lag nell’interfaccia o aggiornamenti lenti, controlla:
- Query di lista troppo pesanti (snelliscile)
- Normalizzazione della cache inefficace (correggi gli ID)
- Problemi di merge nella paginazione (verifica
keyArgsemerge)
E non dimenticare di misurare la tail latency, non solo le medie: è lì che si nasconde il vero disagio per gli utenti.
Confronto tra approcci tradizionali e AI per lo scraping delle news
Siamo onesti: in passato estrarre dati news significava scrivere script personalizzati, gestire browser headless e sperare che il layout del sito non cambiasse durante la notte. Oggi, con strumenti basati su AI come Thunderbit, puoi automatizzare l’intero processo — senza codice, senza drammi.
| Approccio | Punti di forza | Limiti per utenti business |
|---|---|---|
| Scraping con script | Completamente personalizzabile, economico su larga scala | Richiede manutenzione elevata e tempo di sviluppo |
| Piattaforme di scraping gestite | Facili da avviare, gestiscono l’anti-bot | Richiedono comunque configurazione, i costi crescono con l’uso |
| Estrazione guidata dall’AI (Thunderbit) | Gestisce layout disordinati, non richiede codice | L’output va verificato e integrato con lo schema |
| Scraper visuali no-code | Accessibili anche ai non tecnici | Possono rompersi con cambiamenti dell’interfaccia, scalabilità limitata |
| Infrastruttura proxy/unlocker | Aggira i blocchi, supporta alti volumi | Serve comunque la logica di estrazione, con rischi di compliance |
Nota legale: in generale, estrarre dati pubblici è legale, ma è sempre importante rispettare i termini di servizio e i limiti di frequenza (Reuters).
Principali punti chiave per le best practice delle liste in Apollo GraphQL
Ricapitoliamo gli elementi essenziali:
- Ottimizza per velocità e chiarezza: snellisci le query di lista, implementa la paginazione e usa la cache in modo aggressivo.
- La struttura conta: recupera solo ciò che serve e sposta i campi pesanti nelle query di dettaglio.
- La cache è tua alleata: sfrutta normalizzazione e fetch policy di Apollo per servire i dati all’istante.
- Automatizza l’estrazione: strumenti come Thunderbit rendono scraping news e arricchimento delle liste accessibili a tutti.
- Monitora e migliora: usa Devtools e dashboard di osservabilità per individuare i colli di bottiglia in anticipo.
Per i team sales, operations e news, queste best practice significano meno tempo ad aspettare e più tempo ad agire — e molti meno messaggi su Slack del tipo “ma perché è così lento?”.
Conclusione: prossimi passi per ottimizzare le query di lista in Apollo
Se stai ancora usando query di lista pesanti, non paginated o poco compatibili con la cache, è il momento di fare un audit e migliorare. Parti in piccolo: riduci i campi, aggiungi la paginazione e ottimizza la cache. Poi fai un salto di qualità integrando strumenti di estrazione automatica come Thunderbit per mantenere i dati freschi e davvero utilizzabili.
Vuoi approfondire? Dai un’occhiata alla documentazione Apollo, al Thunderbit Blog oppure unisciti alla Apollo Community per consigli pratici e soluzioni ai problemi più comuni. E se vuoi automatizzare davvero la tua estrazione news, prova il template News Scraper di Thunderbit: è una svolta per chi ha bisogno di dati in tempo reale senza complicazioni.
Usa il template News Scraper di Thunderbit
Se dopo aver letto questo articolo non fai altro, fai almeno queste tre cose: riduci i campi selezionati nella query di lista, aggiungi la paginazione basata su cursor e scegli una fetch policy sensata. Già solo queste tre modifiche portano di solito una query da un lag “visibile” a uno “impercettibile” — liberandoti così di concentrarti sui dati, non sullo stato di caricamento.
FAQ
1. Perché le query di lista in Apollo rallentano nelle dashboard news o sales in tempo reale?
Le query di lista possono diventare lente se recuperano troppi dati, non hanno paginazione o non sono memorizzate correttamente nella cache. Nei workflow ad alta frequenza, come il monitoraggio delle notizie, anche piccoli ritardi si accumulano, causando rallentamenti dell’interfaccia e perdita di produttività.
2. Qual è il modo migliore per strutturare le query di lista in Apollo per l’estrazione automatica di notizie?
Richiedi solo i campi necessari a visualizzare la lista (ad esempio titolo, URL, timestamp). Sposta i campi pesanti (come il testo completo dell’articolo o le immagini) nelle query di dettaglio e usa la paginazione per mantenere payload piccoli e veloci.
3. In che modo la cache di Apollo Client migliora le performance delle liste?
La cache di Apollo conserva i dati già recuperati, consentendo risposte immediate alle query ripetute. Una corretta normalizzazione della cache e policy di fetch adeguate (come cache-and-network) possono accelerare notevolmente le viste di lista e ridurre il carico sul server.
4. Come può Thunderbit aiutare nello scraping delle news e nell’integrazione con Apollo?
Thunderbit è un AI web scraper no-code che estrae dati news strutturati da qualsiasi sito. Puoi usarlo per automatizzare l’estrazione delle notizie e poi inviare quei dati al tuo database o alla tua GraphQL API per usarli con Apollo Client.
5. Quali strumenti posso usare per monitorare e risolvere i problemi di performance delle query di lista in Apollo?
I Apollo Client Devtools ti permettono di ispezionare query, stato della cache e performance in tempo reale. Abbinali a dashboard di osservabilità (come New Relic o Uptrends) per monitorare latenza e tassi di errore, e perfeziona la progettazione delle query per ottenere risultati ottimali.
Vuoi altri consigli su web scraping, automazione e workflow dati in tempo reale? Visita il Thunderbit Blog per approfondimenti, tutorial e le ultime novità sulla produttività alimentata dall’AI.
Prova Thunderbit AI Web Scraper Get Started Free
Scopri di più
- Come ottimizzare le liste Apollo per una gestione lead efficace
- Apollo Data Enrichment: funzionalità, vantaggi e spinta dell’AI
- Come padroneggiare Apollo Prospecting: guida passo passo
- Come usare la paginazione nello web scraper per un’estrazione efficiente
- Come usare la paginazione nello web scraper per un’estrazione efficiente




