Se hai mai provato a estrarre dati da un sito web moderno — per esempio un portale immobiliare, un negozio ecommerce o persino il feed dei tuoi social preferiti — probabilmente ti sei trovato davanti a un muro. Apri la pagina, guardi l’HTML e… niente. I dettagli che ti interessano davvero (prezzi, annunci, recensioni) semplicemente non ci sono. Questo perché il web di oggi non è più fatto solo di HTML: gira su JavaScript, e ormai quasi il 99% di tutti i siti web usa script lato client per mostrare i contenuti (). I crawler tradizionali sono un po’ come cercare di seguire un film leggendo solo la sceneggiatura: si perdono tutta l’azione che succede sul momento.
Ho passato anni nel mondo SaaS e dell’automazione, e ho visto in prima persona come questo cambiamento abbia lasciato spiazzati utenti business, team commerciali e ricercatori. Ma ecco la buona notizia: oggi padroneggiare il crawling JavaScript non è più solo roba da sviluppatori. Con l’approccio giusto — e con un piccolo aiuto da strumenti AI come — chiunque può estrarre dati anche dai siti più dinamici e interattivi. Vediamo cos’è il crawling JavaScript, perché conta e come iniziare — senza scrivere codice.
Cos’è il crawling JavaScript? Perché è importante per l’estrazione dei dati web moderni?
Partiamo dalle basi. Con crawling JavaScript si intende l’uso di uno strumento o di un bot capace di caricare una pagina web, eseguire tutto il JavaScript e poi estrarre i contenuti che compaiono dopo l’esecuzione degli script. È un bel salto rispetto al vecchio scraping HTML, che si limita a leggere il codice sorgente grezzo inviato dal server. Nel web di oggi, quell’HTML grezzo è spesso solo uno scheletro: il contenuto vero — schede prodotto, recensioni, prezzi — viene caricato dal JavaScript, a volte solo dopo uno scroll, un clic o un’interazione.
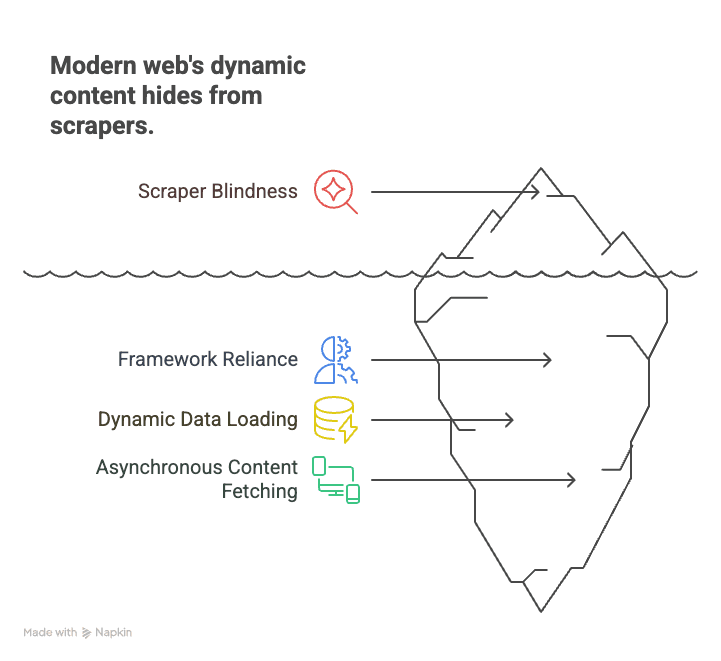
Perché è importante? Perché il web moderno si basa su framework come React, Angular e Vue. Queste single-page application (SPA) caricano i dati al volo, rendendo gli scraper statici “ciechi” davanti a gran parte dei contenuti. Per esempio:
- Ecommerce: prezzi e disponibilità dei prodotti si caricano solo dopo uno scroll o la selezione di un filtro.
- Immobiliare: gli annunci compaiono man mano che scorri verso il basso, con i dettagli caricati in modo dinamico.
- Social media: post, commenti e like vengono recuperati in modo asincrono e non sono visibili nell’HTML iniziale.
I crawler tradizionali scaricano la pagina, trovano una shell vuota e si perdono tutto ciò che conta. Il crawling JavaScript, invece, è come aprire la pagina in Chrome, lasciare che tutti gli script vengano eseguiti e poi prendere ciò che vedi — esattamente come farebbe una persona.
In breve: se vuoi estrarre dati da quasi qualsiasi sito web moderno nel 2025, devi padroneggiare il crawling JavaScript. Altrimenti, ti perdi gran parte dell’azione ().
Le principali sfide del crawling JavaScript (e come superarle)
Il crawling JavaScript non è semplicemente “scraping, ma con più passaggi”. Ha una serie di ostacoli tutti suoi. Ecco con cosa devi fare i conti — e come superare ogni sfida.
Rendering dinamico dei contenuti
La sfida: la maggior parte dei contenuti non è affatto nell’HTML. Viene caricata via JavaScript dopo l’apertura della pagina — a volte dopo uno scroll, un clic o una chiamata di rete. Se ti limiti a recuperare l’HTML, ottieni segnaposto o contenitori vuoti.
La soluzione: usa un browser headless — uno strumento che simula un browser reale, esegue tutti gli script e aspetta che il contenuto appaia. Strumenti come e sono gli standard del settore. Ti permettono di:
- Aprire una pagina e lasciare che JavaScript venga eseguito.
- Attendere il caricamento di elementi specifici (ad esempio “.product-list”).
- Estrarre il contenuto completamente renderizzato dal DOM.
Questo approccio è ormai il riferimento per estrarre dati da siti dinamici ().
Barriere anti-bot e di automazione
La sfida: i siti web stanno diventando sempre più bravi a bloccare i bot. Aspettati di incontrare:
- CAPTCHA
- blocchi IP o limitazioni di velocità
- fingerprinting del browser (controlli per capire se sei un utente reale)
- trappole honeypot (falsi link creati per catturare i bot)
La soluzione: fai crawling in modo responsabile e imita il comportamento umano:
- Rispetta robots.txt e i termini di servizio.
- Limita le richieste: aggiungi ritardi casuali e non martellare il server.
- Ruota gli IP se estrai dati su larga scala (ma fallo in modo etico).
- Usa header realistici del browser ed evita firme tipiche dei bot.
- Non estrarre dati dietro login né aggirare i CAPTCHA senza permesso.
Thunderbit, per esempio, incoraggia gli utenti a estrarre solo dati accessibili pubblicamente e integra le best practice per la conformità ().
Scroll infinito ed eventi attivati dall’utente
La sfida: molti siti usano lo scroll infinito oppure richiedono clic per caricare altri dati. Se il tuo scraper prende solo ciò che è visibile all’inizio, perderai gran parte del contenuto.
La soluzione: usa l’automazione del browser per:
- Simulare lo scroll (caricare più risultati come farebbe un utente).
- Cliccare pulsanti “Carica altro” o schede.
- Attendere che compaia nuovo contenuto prima di estrarlo.
L’AI di Thunderbit può riconoscere questi schemi e gestire per te scroll o paginazione, così non devi scrivere script personalizzati ().
Mantenere prestazioni e scalabilità
La sfida: eseguire un browser headless per ogni pagina richiede molte risorse. Estrarre centinaia o migliaia di pagine può essere lento e pesante per il computer.
La soluzione: usa il crawling concorrente — esegui più browser o schede in parallelo. Oppure, meglio ancora, scarica il lavoro sul cloud. L’acceleratore di scraping cloud di Thunderbit (alias Lightning Network) può estrarre fino a 50 pagine alla volta, velocizzando enormemente i lavori su larga scala ().
Thunderbit: rendere il crawling JavaScript semplice e potente
Diciamolo chiaramente: la maggior parte degli utenti business non vuole scrivere codice, fare debug dei selettori o controllare gli script a mano. Ecco perché abbiamo creato — uno scraper web con AI pensato per chi non sviluppa ma ha bisogno di dati da siti dinamici e ricchi di JavaScript.
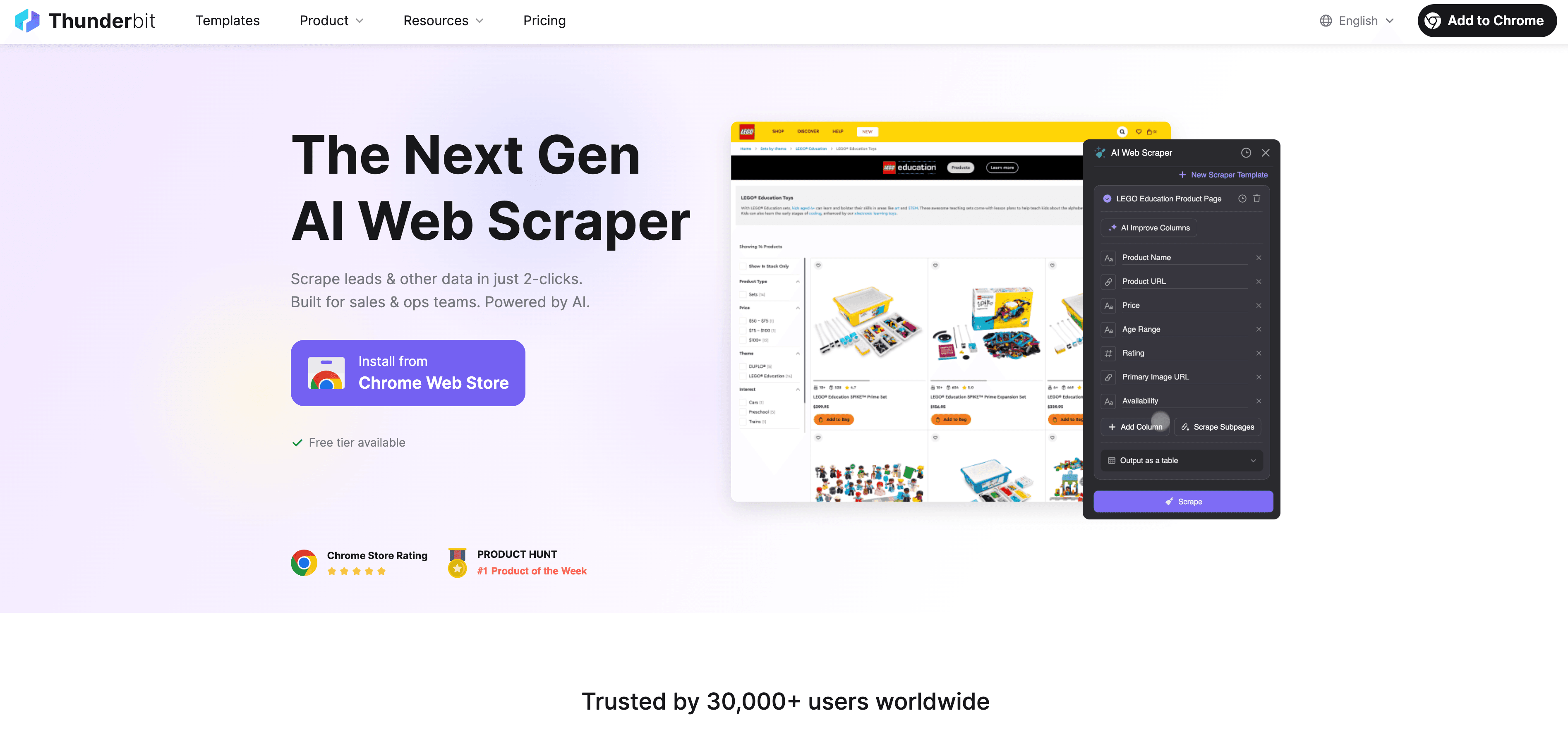
Ecco come Thunderbit elimina la fatica dal crawling JavaScript:
- AI Suggest Fields: basta cliccare su “AI Suggest Fields” e l’AI di Thunderbit analizza la pagina, suggerisce le colonne migliori da estrarre e imposta i tipi di dati corretti. Niente più tentativi o supposizioni.
- Estrazione in linguaggio naturale: descrivi ciò che vuoi in inglese semplice (“Prendi nome prodotto, prezzo e valutazione”) e Thunderbit capisce come ottenerlo.
- Gestione dei contenuti dinamici: Thunderbit gira in un browser reale (il tuo Chrome o il cloud), quindi esegue tutto il JavaScript e aspetta il caricamento dei contenuti — proprio come farebbe una persona.
- Supporto per sottopagine e paginazione: devi estrarre più pagine o seguire link verso sottopagine (come i dettagli di un prodotto)? Thunderbit lo fa automaticamente, combinando tutti i dati in un’unica tabella.
- Accelerazione cloud: per lavori grandi, Lightning Network di Thunderbit estrae fino a 50 pagine alla volta nel cloud, così il tuo computer non si affatica.
- Interfaccia no-code e intuitiva: se sai usare Excel, sai usare Thunderbit. È tutto point-and-click, senza configurazioni tecniche.
- Esportazione gratuita dei dati: esporta i dati in Excel, Google Sheets, Airtable, Notion o JSON — senza costi aggiuntivi.
Thunderbit è usato da oltre 30.000 persone in tutto il mondo, dai team sales agli operatori ecommerce fino ai professionisti del real estate ().
AI Suggest Fields ed estrazione in linguaggio naturale
Qui Thunderbit dà davvero il meglio. Invece di perderti nell’HTML o scrivere selettori XPath, ti basta cliccare un pulsante e l’AI di Thunderbit fa il lavoro pesante. Legge la pagina, ne capisce la struttura e ti suggerisce esattamente cosa estrarre. Se ti serve qualcosa di specifico, scrivilo in inglese semplice: l’AI di Thunderbit mapperà la richiesta agli elementi giusti.
Per chi inizia, questo cambia tutto. Non devi sapere nulla di HTML, CSS o JavaScript. Dì semplicemente cosa vuoi e lascia che sia l’AI a occuparsi del resto ().
Crawling di paginazione e sottopagine
Thunderbit non è solo uno strumento per una sola pagina. Può:
- Rilevare e gestire la paginazione (cliccando “Avanti” o scorrendo per caricare altro).
- Estrarre sottopagine (come dettagli prodotto, profili autore o recensioni) e unire i dati nella tabella principale.
- Gestire lo scroll infinito simulando le azioni dell’utente, così ottieni tutti i dati, non solo quelli visibili all’inizio.
Per esempio, vuoi estrarre una categoria ecommerce con 20 pagine di prodotti? Thunderbit cliccherà automaticamente ogni pagina e combinerà i risultati. Ti servono i dettagli di ogni pagina prodotto? Usa l’estrazione delle sottopagine e Thunderbit visiterà ogni link, raccoglierà le informazioni aggiuntive e arricchirà il tuo dataset ().
Lightning Network e accelerazione cloud: scalare il tuo crawling JavaScript
Quando devi estrarre centinaia o migliaia di pagine, farlo una per una semplicemente non è pratico. È qui che entra in gioco la Lightning Network di Thunderbit.
- Scraping cloud: scarica il lavoro pesante sui server cloud di Thunderbit (negli USA, in UE e in Asia). Il cloud può estrarre fino a 50 pagine alla volta, accelerando enormemente i lavori grandi.
- Crawling concorrente: invece di aspettare che ogni pagina si carichi nel browser, il cloud di Thunderbit suddivide il lavoro tra più worker. Devi estrarre 1.000 pagine prodotto? Il cloud può finire in pochi minuti, non in ore.
- Estrazione programmata: devi monitorare prezzi o annunci ogni giorno? Imposta un’estrazione programmata in linguaggio naturale (“ogni giorno alle 9”) e Thunderbit eseguirà il lavoro automaticamente, esportando i dati nel tuo Google Sheet o database ().
È una manna per i team sales, ecommerce e operations che hanno bisogno di dati aggiornati su larga scala — senza assumere uno sviluppatore né gestire server.
Estrazione di dati mult pagina e bulk
Thunderbit rende semplice:
- Estrarre interi elenchi o cataloghi (per esempio tutti i prodotti di una categoria, tutti gli annunci di una regione).
- Esportare i risultati in Excel, Google Sheets, Airtable o Notion con un clic.
- Risparmiare ore (o giorni) di lavoro manuale — un utente ha estratto centinaia di annunci immobiliari, completi di dettagli dell’agente, in meno di 10 minuti.
Guida passo passo: come iniziare il crawling JavaScript con Thunderbit
Pronto a provarlo? Ecco come iniziare con Thunderbit, anche se non hai mai estratto dati da un sito web prima d’ora.
Configurare la tua prima estrazione
- Installa Thunderbit: scarica la . Crea un account gratuito.
- Scegli il target: vai sul sito da cui vuoi estrarre i dati. Se richiede login, accedi prima (Thunderbit funziona nel contesto del tuo browser).
- Apri Thunderbit: fai clic sull’icona di Thunderbit nella barra degli strumenti di Chrome. Scegli la fonte dei dati (pagina corrente, elenco di URL o caricamento file).
- Scegli la modalità di esecuzione: per lavori piccoli o siti che richiedono login, usa la modalità Browser. Per lavori su larga scala, passa alla modalità Cloud per lo scraping parallelo.
- AI Suggest Fields: clicca su “AI Suggest Fields”. L’AI di Thunderbit analizzerà la pagina e consiglierà le colonne da estrarre (come “Nome prodotto”, “Prezzo”, “URL immagine”).
- Regola le colonne: rinomina, aggiungi o rimuovi campi secondo necessità. Aggiungi istruzioni AI personalizzate se vuoi formattare o categorizzare i dati.
- Configura paginazione/scroll: se il sito usa paginazione o scroll infinito, abilita l’opzione corrispondente nelle impostazioni di Thunderbit.
- Clicca “Scrape”: Thunderbit caricherà la/le pagina/e, eseguirà tutto il JavaScript ed estrarrà i dati in una tabella.
Estrarre ed esportare i dati
- Anteprima dei risultati: Thunderbit mostra i dati in una tabella. Controlla rapidamente completezza e accuratezza.
- Esporta: clicca “Esporta” per scaricare in Excel, CSV, JSON oppure inviare direttamente a Google Sheets, Airtable o Notion.
- Verifica: confronta alcune righe con il sito live per assicurarti che tutto corrisponda.
- Risoluzione dei problemi: se mancano dati, prova prima a scorrere la pagina, ad adattare le istruzioni AI o a passare alla modalità Cloud per migliori prestazioni.
Per una guida più dettagliata, consulta i o il .
Best practice per un crawling JavaScript sicuro e conforme
Da un grande potere di scraping derivano grandi responsabilità. Ecco come restare dalla parte giusta della legge (e dell’etica):
- Rispetta robots.txt e i Termini di servizio: verifica sempre se il sito consente lo scraping. Se dice “niente bot”, non forzare la mano ().
- Evita di estrarre dati personali: GDPR e CCPA trattano nomi, email e profili come dati protetti, anche se pubblici. Estrai informazioni personali solo se hai un motivo legittimo e il consenso.
- Non aggirare login o CAPTCHA: è una zona grigia dal punto di vista legale (o peggio). Attieniti ai dati pubblici.
- Limita le richieste: non sovraccaricare i server. La modalità Cloud di Thunderbit distribuisce le richieste nel tempo e ruota gli IP per evitare blocchi.
- Usa i dati in modo etico: non ripubblicare contenuti protetti da copyright né abusare delle informazioni estratte.
- Cancella su richiesta: se qualcuno ti chiede di rimuovere i suoi dati, fallo.
Thunderbit è progettato per favorire la conformità: solo dati pubblici, niente hacking e opzioni di esportazione chiare per un uso responsabile.
Evitare i rischi legali
- Limita l’attività a dati pubblici e non personali.
- Non estrarre dati da siti che lo vietano espressamente.
- In caso di dubbi, chiedi il permesso o usa l’API ufficiale del sito.
- Conserva i log di ciò che hai estratto e quando.
- Rispetta immediatamente eventuali diffide o richieste di cessazione.
Per un approfondimento, vedi .
Confronto tra soluzioni di crawling JavaScript: Thunderbit vs strumenti tradizionali
| Aspetto | Puppeteer/Playwright (codice) | Sitebulb (crawler SEO) | Thunderbit (AI no-code) |
|---|---|---|---|
| Tempo di configurazione | Ore (serve codice) | Medio (configurazione) | Minuti (point & click) |
| Competenze richieste | Alte (solo sviluppatori) | Medie | Basse (chiunque) |
| Gestione contenuti JS | Sì (script manuali) | Sì (per SEO) | Sì (AI, automatico) |
| Paginazione/sottopagine | Script manuali | Limitato | Automatico (AI rileva) |
| Manutenzione | Alta (si rompe ai cambiamenti) | Media | Bassa (l’AI si adatta) |
| Scalabilità | Manuale (scrivi codice) | Limitata | Cloud integrato (50x) |
| Opzioni di export | Manuale (scrivi codice) | CSV/Excel | Excel, Sheets, Notion |
| Ideale per | Sviluppatori, flussi personalizzati | Audit SEO | Utenti business, analisti |
Thunderbit è la scelta più chiara per gli utenti business che vogliono risultati rapidi, senza grattacapi tecnici ().
Conclusione e punti chiave
Il crawling JavaScript non è più una competenza di nicchia: nel 2025 è indispensabile per chiunque abbia bisogno di dati web. Con quasi il 99% dei siti che esegue script lato client, lo scraping tradizionale non è più sufficiente (). La buona notizia? Non devi essere uno sviluppatore per padroneggiarlo.
Da ricordare:
- I contenuti dinamici sono ovunque: se vuoi estrarre dati da siti moderni, ti serve uno strumento che possa eseguire JavaScript.
- Le sfide sono reali, ma si possono risolvere: browser headless, attese intelligenti e accelerazione cloud rendono possibile estrarre anche i dati più complessi.
- Thunderbit semplifica tutto: con suggerimenti AI per i campi, estrazione in linguaggio naturale, supporto per sottopagine e paginazione, e accelerazione cloud, Thunderbit mette un crawling JavaScript potente nelle mani di tutti.
- Resta conforme: rispetta sempre le regole del sito, le leggi sulla privacy e le linee guida etiche.
- Inizia oggi: installa Thunderbit, scegli un sito e scopri quanti dati puoi sbloccare in pochi clic.
Vuoi approfondire? Dai un’occhiata al per altre guide, oppure guarda i nostri per demo passo passo.
Buon crawling — e che i tuoi dati siano sempre dinamici, completi e pronti all’azione.
FAQ
1. Cos’è il crawling JavaScript e in cosa si differenzia dallo scraping tradizionale?
Il crawling JavaScript usa uno strumento che carica una pagina web, esegue tutto il suo JavaScript ed estrae i contenuti che compaiono dopo l’esecuzione degli script. Lo scraping tradizionale si limita a prendere l’HTML grezzo, perdendo gran parte dei contenuti dei siti moderni.
2. Perché mi serve il crawling JavaScript per l’estrazione di dati business?
Perché quasi tutti i siti web moderni usano JavaScript per caricare contenuti in modo dinamico. Senza crawling JavaScript, perderesti schede prodotto, recensioni, prezzi e altri dati chiave.
3. In che modo Thunderbit semplifica il crawling JavaScript per i principianti?
Thunderbit usa l’AI per suggerire i campi, gestire i contenuti dinamici e automatizzare la paginazione e l’estrazione delle sottopagine. Puoi descrivere ciò che vuoi in inglese semplice — non serve scrivere codice.
4. Il crawling JavaScript è legale? A cosa devo fare attenzione?
Il crawling JavaScript è legale se eseguito in modo responsabile: usa solo dati pubblici, rispetta robots.txt e i termini di servizio ed evita di estrarre informazioni personali senza consenso. Thunderbit promuove conformità e uso responsabile.
5. Come posso scalare il mio crawling JavaScript per lavori di grandi dimensioni?
La Lightning Network di Thunderbit (scraping cloud) ti permette di estrarre fino a 50 pagine alla volta, rendendo facile gestire lavori grandi come il monitoraggio dei prezzi o la generazione di lead su migliaia di pagine.
Scopri di più: