Non scorderò mai la prima volta che ho provato a raccogliere dati da una trentina di pagine prodotto per un mio progetto. Avevo il caffè, il foglio Excel aperto e tanta voglia di fare. Dopo due ore, però, ero ancora lì a copiare e incollare, con lo sguardo perso e le dita stanche dal troppo Ctrl+C/Ctrl+V. Se anche tu ti sei mai trovato a dover raccogliere informazioni da una lunga lista di pagine web, sai bene quanto sia snervante: è lento, pieno di errori e ti fa davvero mettere in dubbio le tue scelte di vita.
Ecco perché sono un vero fan del bulk scrape—ed è anche il motivo per cui, in , ci siamo messi d’impegno per rendere l’estrazione di dati da tanti URL il più semplice possibile. In questa guida ti racconto cos’è il bulk scrape, perché è fondamentale per chi lavora con i dati, come si è evoluto e come puoi usare Thunderbit per passare da “Ho una lista di 200 URL” a “Ecco il mio file pronto” in pochi clic. Niente codice, niente modelli, niente stress.
Cos’è il Bulk Scrape? Le Basi dell’Estrattore Web su Lista
Partiamo dalle basi. Il bulk scrape (conosciuto anche come list crawling o URL scraping) è il processo che ti permette di estrarre dati da un’intera lista di pagine web—invece di lavorare una pagina alla volta. Invece di aprire ogni link, copiare le informazioni e incollarle in un foglio (ripetendo fino allo sfinimento), con il bulk scrape basta dare una lista di URL a uno strumento che fa tutto per te.
In pratica, il bulk scrape è come avere un assistente super veloce che visita ogni link della tua lista e copia le informazioni utili in un foglio. È estrattore web, ma su larga scala. Diversamente dal classico estrattore web, che spesso si concentra su una singola pagina o su un sito alla volta, con l’URL scraping dici allo strumento: “Ecco la mia lista—vai a prendere i dati da ognuna di queste pagine.”
Per fare un paragone pratico, è come la differenza tra copiare una riga di un foglio e importare tutto il file in un colpo solo. Il bulk scrape è quel pulsante “importa” applicato al web.
Se vuoi approfondire, dai un’occhiata a .
Perché il Bulk Scraping è Fondamentale per le Aziende
Diciamolo chiaro: nessuno si sveglia felice di dover copiare dati da 100 pagine web. Eppure, per chi si occupa di vendite, ecommerce, operations o ricerca, raccogliere dati dal web è una necessità quotidiana. Il bulk scrape non è solo una parola di moda—è un vero turbo per la produttività.
Ecco perché fa la differenza:
- Velocità: Quello che prima richiedeva ore (o giorni) ora si fa in pochi minuti o secondi ().
- Precisione: L’automazione riduce gli errori umani e garantisce coerenza nei dati raccolti.
- Scalabilità: Devi estrarre dati da 200 pagine prodotto? O da 500 annunci immobiliari? Il bulk scrape lo rende possibile.
- ROI: Le aziende che usano estrattori web moderni e basati su AI risparmiano il 30–40% del tempo dedicato all’estrazione dati ().
Ecco qualche esempio concreto:
| Caso d’uso | Problema (Manuale) | Vantaggio del Bulk Scraping |
|---|---|---|
| Lead Generation | Copiare i contatti uno a uno è lento | Raccogli migliaia di lead in una volta sola, compilando nomi, email, telefoni |
| Monitoraggio Prezzi Competitor | Controllo manuale quotidiano dei siti concorrenti | Monitora tutti gli URL dei prodotti per variazioni di prezzo, reagendo rapidamente |
| Ricerca di Mercato/Contenuti | Leggere manualmente tanti articoli/recensioni | Estrai dati da più articoli o recensioni in una volta sola per dataset più ampi e aggiornati |
| Gestione Dati Prodotto | Unire info da fonti diverse è rischioso | Raccogli specifiche, stock, ecc. da tutti i fornitori in un unico file, con formato uniforme |
| Annunci Immobiliari | Aggregare manualmente gli annunci richiede ore | Raccogli decine di annunci da vari siti per una panoramica aggiornata |
In sintesi: il bulk scraping con estrattore web aumenta la produttività e migliora le decisioni basate sui dati in ambito vendite, marketing, operations e altro ancora ().
Confronto tra Soluzioni di Bulk Scraping: Dal Manuale all’AI
Il bulk scrape ha fatto tanta strada. Vediamo i principali approcci, dai metodi “vecchia scuola” agli strumenti AI di oggi—e perché Thunderbit è diverso.
Bulk Scraping Manuale: Il Metodo Classico
Ricordi la mia maratona di copia-incolla? Ecco, quello è il bulk scraping manuale. Apri ogni pagina, copi le informazioni, le incolli in Excel e ripeti. Funziona per cinque URL. Per cinquanta? Decisamente no. È lento, noioso e rischi di commettere errori o perdere aggiornamenti ().
Bulk Scraping con Script o Modelli
Poi ci sono gli script (tipo Python con BeautifulSoup) e gli strumenti basati su modelli. Se sai programmare, puoi scrivere uno script che scorre la tua lista di URL ed estrae ciò che ti serve. Potente, ma serve competenza tecnica—e ogni volta che il sito cambia, lo script può rompersi. La manutenzione è impegnativa.
Gli strumenti a modelli ti permettono di selezionare visivamente i campi su una pagina e applicare quel “modello” a una lista di pagine simili. Ottimo per chi non programma, ma devi comunque creare un modello per ogni sito o tipo di pagina. Se la tua lista di URL arriva da siti diversi o le pagine non sono strutturate allo stesso modo, le cose si complicano.
Il Vantaggio del Bulk Scraping One-Click di Thunderbit
Qui entra in gioco Thunderbit. Il nostro approccio è semplice: incolla la tua lista di URL, clicca una volta e ottieni dati strutturati—senza modelli, senza codice, senza configurazioni. L’AI capisce cosa estrarre in base ai nomi delle colonne o ai tuoi suggerimenti. Anche se le pagine sono diverse tra loro, Thunderbit si adatta.
Ecco un confronto:
| Metodo | Facilità d’uso | Flessibilità | Competenze Tecniche Necessarie | Tempo di Setup | Velocità | Gestisce Pagine Diverse? |
|---|---|---|---|---|---|---|
| Copia-Incolla Manuale | Bassa | Alta | Nessuna | Alto | Lenta | Sì (ma faticoso) |
| Script | Bassa | Molto Alta | Alta | Alto | Veloce | Sì (se programmato) |
| Strumento a Modelli | Media | Media | Bassa | Media | Veloce | Solo se simili |
| Thunderbit (AI Bulk) | Molto Alta | Alta | Nessuna | Basso | Molto Veloce | Sì |
Un esempio pratico: estrarre dati da 100 URL di prodotti richiederebbe ore manualmente, forse un’ora con uno strumento a modelli, ma solo pochi minuti con Thunderbit ().
Guida Pratica: Come Fare Bulk Scraping di URL con Thunderbit
Passiamo alla pratica. Ecco come puoi estrarre dati da una lista di URL usando —senza alcuna competenza tecnica.
Passo 1: Installa l’Estensione Chrome di Thunderbit
Per prima cosa, scarica l’. Cerca “Thunderbit AI Web Scraper” nel Chrome Web Store, oppure vai sul nostro . Clicca su “Aggiungi a Chrome”, conferma e sei pronto. Oltre già si affidano a Thunderbit, quindi sei in buona compagnia.
Potresti dover creare un account o accedere—tranquillo, la versione gratuita ti permette di provare subito il bulk scrape.
Passo 2: Prepara la Tua Lista di URL per il Bulk Scraping
Ora raccogli i tuoi URL. Puoi:
- Esportarli da un CRM o da un foglio di calcolo
- Copiare i link delle pagine prodotto da un sito concorrente
- Raccogliere URL di profili LinkedIn per la generazione di lead
- Copiare manualmente i link che vuoi estrarre
Formatta la lista con un URL per riga, in un file di testo o in un foglio di calcolo. Ad esempio:
1https://www.example.com/product/123
2https://www.example.com/product/456
3https://www.example.com/product/789Consiglio: elimina i duplicati e assicurati che gli URL siano accessibili (se una pagina richiede login, anche Thunderbit dovrà essere loggato).
Passo 3: Incolla gli URL e Avvia il Bulk Scrape
Qui inizia il bello:
- Clicca sull’icona di Thunderbit nella barra di Chrome.
- Imposta la fonte dati su “URL” o “Lista di URL”.
- Incolla la tua lista di URL nel box (o carica un CSV se preferisci).
- Clicca su “AI Suggerisci Colonne”—l’AI di Thunderbit analizzerà una delle pagine e proporrà i campi rilevanti (come “Nome Prodotto”, “Prezzo”, “Email”, ecc.).
- Modifica le colonne suggerite se necessario, o aggiungi le tue.
- Clicca su “Estrai”. Thunderbit visiterà ogni URL, estrarrà i dati e li organizzerà in una tabella.
Puoi continuare a lavorare su altre schede mentre Thunderbit lavora. Per liste molto lunghe, Thunderbit usa più thread e rispetta i limiti di velocità dei siti per evitare blocchi.
Passo 4: Rivedi ed Esporta i Dati Estratti
Quando l’estrazione è completata, Thunderbit mostra i risultati in una tabella. Puoi visualizzare i dati—ogni riga corrisponde a una pagina, ogni colonna a un campo che hai definito.
Le opzioni di esportazione includono:
- Copia negli appunti o scarica come CSV (perfetto per Excel o Google Sheets)
- Esporta direttamente su Google Sheets, Airtable o Notion (con un clic)
- Scarica come JSON (per sviluppatori o flussi avanzati)
Puoi anche salvare il modello di estrazione per usi futuri.
Passo 5: Consigli e Soluzioni ai Problemi più Comuni
Anche con l’AI, l’estrattore web può incontrare ostacoli. Ecco qualche dritta:
- Alcuni URL non vengono estratti? Controlla se richiedono login o hanno strutture particolari. Prova la “modalità browser” di Thunderbit per le pagine più complesse.
- Mancano dati in una colonna? Rendi il nome della colonna più esplicito, oppure usa la funzione “Istruzione Personalizzata” di Thunderbit per guidare l’AI.
- Liste molto grandi sono lente? Suddividile in blocchi (es. 200 URL alla volta) o usa l’opzione di scraping cloud di Thunderbit.
- Evita i blocchi: Non estrarre troppo velocemente. Usa intervalli ragionevoli e rispetta il
robots.txte i termini di servizio dei siti. - Vuoi dati anche da sottopagine? Attiva lo scraping delle sottopagine per seguire link interni (come recensioni prodotto o profili autore).
Per ulteriori dettagli, consulta la o contatta il supporto.
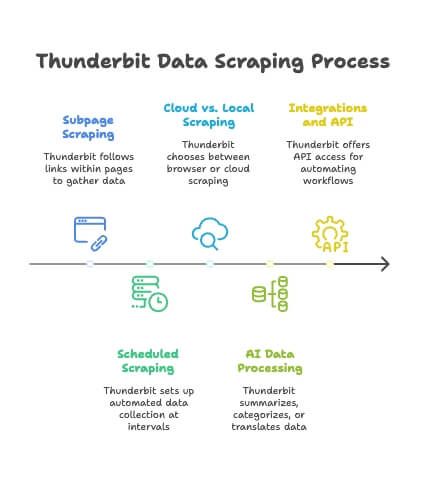
Funzionalità Avanzate: Sottopagine, Pianificazione e Altro
Thunderbit non si limita alle estrazioni una tantum. Ecco alcune funzioni avanzate che rendono il bulk scrape ancora più potente:
- Scraping di Sottopagine: Thunderbit può seguire i link interni di ogni pagina (come tab “Recensioni” o profili autore) e unire quei dati alla tabella principale. L’AI si adatta a layout diversi—senza configurazioni extra ().
- Scraping Programmato: Vuoi dati aggiornati ogni giorno? Imposta uno scraping pianificato (ogni ora, giorno o settimana). Il tuo Google Sheet o database si aggiornerà da solo—senza interventi manuali.
- Scraping Cloud vs. Locale: Di default, Thunderbit lavora nel browser, ma puoi anche usare lo scraping cloud per lavori più rapidi e su larga scala.
- Elaborazione Dati AI: Thunderbit può riassumere, categorizzare o tradurre i dati mentre li estrae, così ottieni dataset arricchiti senza passaggi aggiuntivi.
- Integrazioni e API: Per utenti avanzati, Thunderbit offre API e integrazioni per automatizzare i flussi di scraping.
Per saperne di più, consulta la nostra .
Bulk Scraping per Team Diversi: Vendite, Ecommerce, Immobiliare e Oltre
Il bulk scrape non è solo per i fanatici dei dati (anche se siamo una bella compagnia). Ecco come lo usano diversi reparti:
- Vendite: Estrai profili LinkedIn o directory per trovare lead. Crea una lista di potenziali clienti con nomi, ruoli, email e altro—pronta da importare nel CRM.
- Ecommerce: Monitora prezzi, stock e dettagli dei prodotti dei concorrenti su centinaia di pagine. Pianifica estrazioni regolari per mantenere la strategia prezzi sempre aggiornata.
- Ricerca di Mercato: Aggrega articoli, recensioni o post da forum per analizzare trend. Dataset più ampi e freschi portano a insight migliori.
- Operations: Raccogli specifiche, info di conformità o dati fornitori da più siti—automaticamente e su base programmata.
- Immobiliare: Aggrega annunci da siti come Zillow o . Ottieni una panoramica completa del mercato in un unico foglio.
Consiglio pratico: per attività ricorrenti, salva i tuoi modelli e pianifica le estrazioni. Per ricerche una tantum, incolla la lista di URL e via.
Best Practice: Organizzazione e Conformità nel Bulk Scraping
Con grandi poteri di scraping arrivano grandi responsabilità. Ecco come restare organizzati ed etici:
- Organizza i tuoi dati: Usa nomi file chiari (es.
lead_estratti_Ago2025.csv), aggiungi date e tieni traccia delle fonti. - Pulisci e deduplica: Rimuovi i duplicati, controlla la qualità dei dati e correggi errori evidenti prima dell’analisi.
- Rispetta i termini dei siti: Estrai solo dati pubblici e controlla sempre i termini di servizio e il
robots.txtdel sito. - Gestisci con attenzione i dati personali: Se raccogli email o nomi, rispetta le normative sulla privacy come il GDPR. Non abusare di informazioni sensibili.
- Sii corretto: Non sovraccaricare i siti—usa velocità di scraping ragionevoli e pianifica le estrazioni in orari non di punta.
Per approfondire, leggi la .
Conclusioni e Punti Chiave
Il bulk scrape è passato dall’essere un “nice to have” a una vera necessità per chiunque abbia bisogno di dati web su larga scala. Con Thunderbit, non serve essere programmatori, esperti di modelli o maghi dei fogli di calcolo. Basta incollare gli URL, cliccare e vedere i dati arrivare.
I vantaggi principali del bulk scrape con Thunderbit:
- Semplicità: Nessuna competenza tecnica richiesta—incolla e vai ().
- Velocità e scala: Raccogli migliaia di dati in pochi minuti, non ore ().
- Flessibilità: Funziona su quasi tutti i siti, con l’AI che si adatta a layout diversi ().
- Qualità dei dati: L’estrazione guidata dall’AI garantisce dati più precisi e pronti all’uso ().
- Empowerment dei team: Vendite, marketing, operations e ricerca possono ottenere i dati di cui hanno bisogno—senza dipendere dall’IT ().
Vuoi provarlo? , così puoi sperimentare il bulk scrape su piccola scala e vedere i risultati con i tuoi occhi. Pensa a un problema di dati che hai—una lista di URL da cui vorresti estrarre informazioni rapidamente—e mettilo alla prova. Potresti risolvere in pochi minuti un compito che ti porti dietro da settimane.
Sfruttare i dati web su larga scala è un vero vantaggio competitivo. Con il bulk scrape e strumenti come Thunderbit, questo vantaggio è finalmente accessibile a tutti. Buon scraping—e che i giorni di Ctrl+C/Ctrl+V restino solo un ricordo.
Vuoi saperne di più su estrattore web, list crawling o tecniche avanzate? Visita il e i nostri approfondimenti:
E se vuoi vedere Thunderbit in azione, iscriviti al nostro per tutorial e consigli.
Domande Frequenti
1. Cos’è il bulk web scraping e in cosa si differenzia dal web scraping tradizionale?
Il bulk web scraping, chiamato anche URL scraping o list crawling, consiste nell’estrarre dati da una lista predefinita di pagine web tutte insieme. A differenza dello scraping tradizionale, che di solito si concentra su un sito intero o su una pagina alla volta, il bulk scrape permette di incollare una lista di URL ed estrarre direttamente i campi desiderati da ogni link—ideale per pagine prodotto, annunci o directory.
2. Chi trae maggior beneficio dal bulk scraping?
Il bulk scrape è utile per tanti team e ruoli diversi. I team di vendita lo usano per generare lead estraendo contatti da LinkedIn o directory. Le aziende ecommerce lo sfruttano per monitorare prezzi e stock dei concorrenti. Gli agenti immobiliari aggregano annunci, mentre i ricercatori raccolgono recensioni o articoli in massa. In sostanza, chiunque abbia bisogno di dati strutturati da più URL ne trae vantaggio.
3. In cosa Thunderbit è diverso dagli altri strumenti di bulk scraping?
Thunderbit si distingue per l’esperienza no-code e l’uso dell’AI. A differenza degli strumenti tradizionali che richiedono codice o modelli, Thunderbit permette di incollare una lista di URL e cliccare una sola volta per ottenere dati strutturati. Gestisce pagine diverse, suggerisce automaticamente i campi, supporta lo scraping di sottopagine e si integra direttamente con Google Sheets, Airtable e Notion.
4. Che tipo di dati può estrarre Thunderbit durante un bulk scrape?
Thunderbit può estrarre nomi prodotto, prezzi, disponibilità, contatti (email, telefoni), titoli, recensioni, specifiche e molto altro. L’AI rileva automaticamente i campi rilevanti in base alle colonne suggerite o alla struttura della pagina. Puoi anche estrarre dati da sottopagine, tradurre contenuti o riassumere informazioni durante l’estrazione.
5. Il bulk scraping è legale e sicuro per le aziende?
Il bulk scrape è legale se fatto in modo responsabile ed etico. Bisogna estrarre solo dati pubblici, rispettare il file robots.txt e i termini di servizio dei siti, ed evitare di raccogliere dati personali senza consenso. Thunderbit promuove la conformità limitando la velocità di scraping, supportando l’accesso autenticato quando necessario e offrendo strumenti per gestire i dati in modo responsabile.