I dati che troviamo online sono diventati il vero oro digitale—ma sono sparpagliati su una marea di siti, nascosti in HTML caotici e protetti da CAPTCHAs e sistemi anti-bot sempre più furbi. Se ti è mai capitato di copiare a mano prezzi, info sui competitor o lead, sai che è un lavoro infinito e rischi di lasciarti scappare occasioni importanti. Ecco perché il web scraping è ormai una skill fondamentale per chi lavora in azienda. Basti pensare che il mercato dei dati alternativi (dove rientra anche il web scraping) valeva e continua a crescere a vista d’occhio.

E qui arriva la sorpresa: anche se Python è la scelta più gettonata per chi inizia, Go (o Golang, come lo chiamano in tanti) è il motore silenzioso dietro alcuni degli estrattori web più veloci e affidabili in circolazione. Il punto di forza di Go? Concorrenza integrata, una libreria standard solidissima e prestazioni che fanno impazzire chi lavora nel backend. Ho visto team tagliare i tempi di scraping a metà solo passando a Go—e con gli strumenti giusti, non serve essere un super ingegnere per partire.
Vuoi trasformare Go nel tuo asso nella manica per il web scraping? Ecco i cinque step fondamentali—dalla configurazione alle tecniche avanzate—con esempi pratici, dritte utili e uno sguardo a come strumenti AI come possono portare il tuo workflow a un altro livello.
Perché Scegliere Go per il Web Scraping? Il Vantaggio per le Aziende
Parliamoci chiaro: quando devi estrarre dati da migliaia (o milioni) di pagine, ogni secondo è prezioso. Go è stato pensato proprio per gestire carichi pesanti. Ecco perché sempre più aziende puntano su Go per il web scraping:
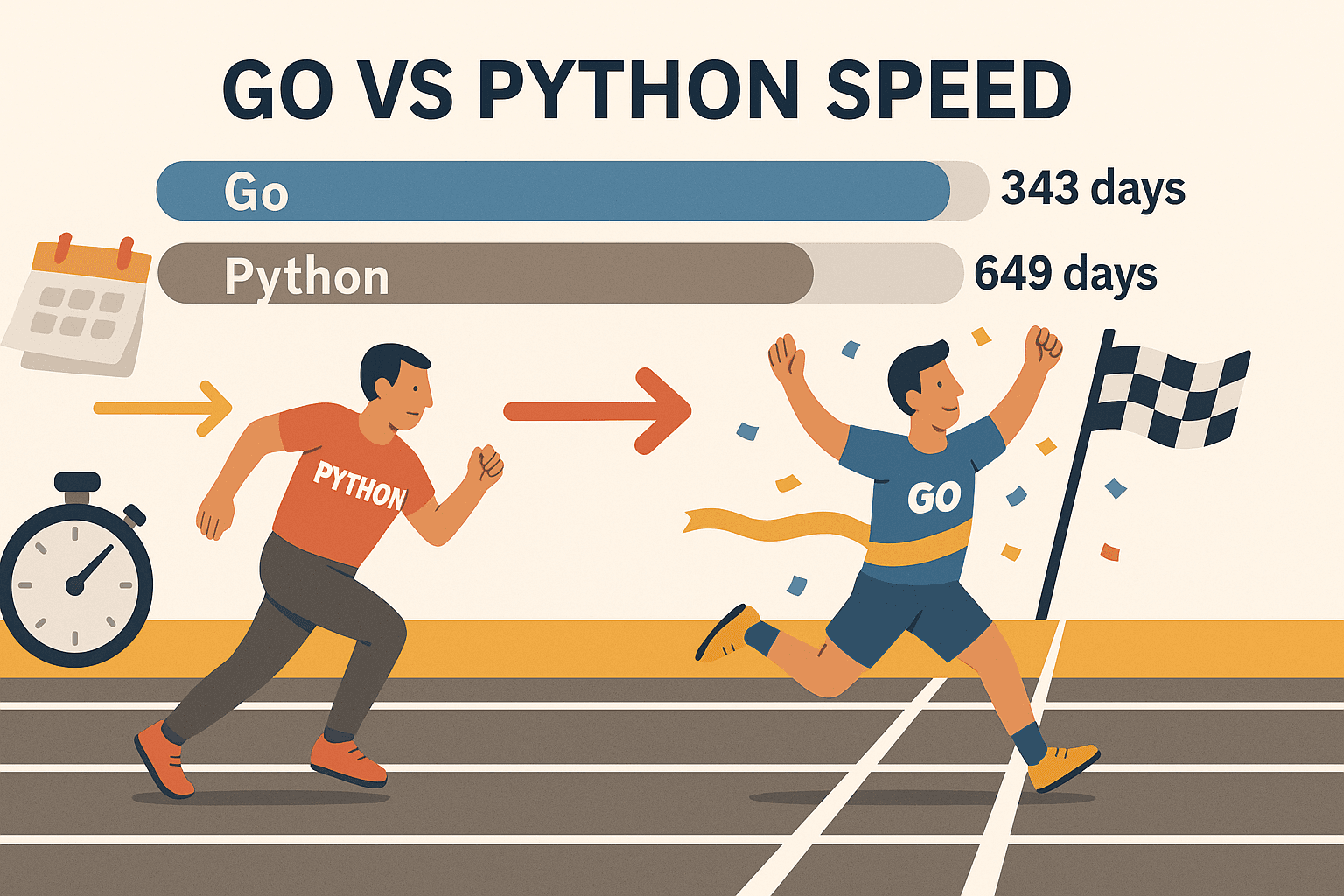
- Concorrenza che scala: Le goroutine di Go (thread leggerissimi) ti permettono di estrarre dati da centinaia di pagine in parallelo—senza mandare in tilt il computer. In un test, Go ha estratto , mentre Python ci ha messo 649 giorni per lo stesso lavoro. Non è solo più veloce—gioca proprio in un’altra categoria.
- Stabilità e affidabilità: Il tipaggio forte e la gestione della memoria di Go sono perfetti per scraper che devono girare a lungo e su larga scala. Basta svegliarsi e scoprire che lo script si è piantato nel cuore della notte.
- Networking di alto livello: La libreria standard di Go ha già tutto quello che ti serve per richieste HTTP, parsing HTML e gestione JSON—senza dover impazzire con mille pacchetti esterni.
- Distribuzione semplice: Go compila tutto in un unico eseguibile, così puoi far girare il tuo scraper ovunque—niente virtualenv, niente rogne di dipendenze.
- Adozione nel settore: Go oggi è il (ha superato Node.js) e lo usano colossi come Google, Uber e Netflix.
Certo, Python resta ottimo per lavori veloci o quando servono librerie di machine learning. Ma se vuoi velocità, scalabilità e affidabilità, Go è imbattibile—soprattutto con librerie come Colly e Goquery.
Passo 1: Configurare l'Ambiente Go per il Web Scraping
Prima di iniziare a estrarre dati, devi installare e configurare Go. La buona notizia? È davvero una passeggiata.
1. Installa Go
- Vai sulla e scarica l’installer per il tuo sistema operativo (Windows, macOS o Linux).
- Installa e segui le istruzioni. Su Linux puoi anche usare il gestore pacchetti.
- Apri il terminale e digita:
Se vedi qualcosa tipo1go versiongo version go1.21.0 darwin/amd64, sei a posto.
Se hai problemi: Se go non viene trovato, controlla che il PATH sia impostato bene. Su Linux/macOS, potresti dover aggiungere export PATH=$PATH:/usr/local/go/bin al tuo ~/.bash_profile o ~/.zshrc.
2. Inizializza un nuovo progetto Go
- Crea una nuova cartella per il tuo scraper:
1mkdir my-scraper && cd my-scraper - Inizializza un modulo Go:
Così crei il file1go mod init github.com/tuonome/my-scrapergo.modper gestire le dipendenze.
3. Scegli un editor
- con l’estensione Go è super comodo (auto-completamento, linting e debug inclusi).
- JetBrains GoLand è molto amato dai professionisti Go.
- Vim/Neovim con plugin Go va benissimo se preferisci lo stile old school.
4. Testa la configurazione
Crea un veloce main.go:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go è installato e funzionante!")
5}Esegui:
1go run main.goSe vedi il messaggio, sei pronto a partire.
Passo 2: Effettuare la Prima Richiesta HTTP in Go
È il momento di recuperare la tua prima pagina web! Il pacchetto net/http di Go rende tutto molto semplice.
Esempio base di HTTP GET:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Errore nel recupero dell’URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Errore nella lettura della risposta:", err)
17 return
18 }
19 fmt.Println(string(body))
20}Cose da ricordare:
- Controlla sempre gli errori dopo
http.Get. - Usa
defer resp.Body.Close()per non lasciare risorse aperte. - Usa
io.ReadAllper leggere tutta la risposta.
Tips avanzati:
- Per impostare header personalizzati (tipo User-Agent), usa
http.NewRequest:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) - Controlla sempre
resp.StatusCode—200 è ok, 403 o 404 vuol dire che sei stato bloccato o la pagina non esiste.
Passo 3: Analizzare l’HTML ed Estrarre Dati con Go
Recuperare l’HTML è solo il primo passo. Ora devi tirare fuori le info che ti servono—nomi prodotti, prezzi, link e così via.
Goquery: Una libreria Go che ti permette di usare selettori in stile jQuery per il parsing HTML.
Installa Goquery:
1go get github.com/PuerkitoBio/goqueryEsempio: Estrazione di nomi e prezzi dei prodotti
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Prodotto %d: %s - %s\n", i+1, name, price)
21 })
22}Come funziona:
doc.Find("div.product")seleziona tutti i box dei prodotti.- Dentro,
s.Find("h2").Text()prende il nome es.Find(".price").Text()il prezzo.
Espressioni regolari: Per pattern semplici (tipo email), il pacchetto regexp di Go è veloce e pratico. Per casi più complessi, meglio affidarsi a Goquery.
Passo 4: Potenzia il Tuo Scraper con le Librerie Go (Colly & Gocolly)
Vuoi fare il salto di qualità? è il framework di riferimento per il web scraping con Go. Gestisce crawling, concorrenza, cookie e molto altro—così puoi concentrarti sui dati, non sulla parte tecnica.
Perché Colly è una bomba:
- API semplice: Registra callback sugli elementi che vuoi estrarre.
- Concorrenza: Estrai centinaia di pagine in parallelo con
colly.Async(true). - Crawling automatico: Segui i link e gestisci la paginazione senza fatica.
- Funzioni anti-bot: Imposta header personalizzati, ruota user agent e gestisci i cookie.
- Gestione errori: Hook integrati per richieste che falliscono.
Installa Colly:
1go get github.com/gocolly/colly/v2Esempio base di scraper con Colly:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Prodotto: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Richiesta fallita:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}Confronto funzionalità: Goquery vs. Colly
| Funzionalità | Goquery | Colly |
|---|---|---|
| Parsing HTML | Sì | Sì (usa Goquery internamente) |
| Richieste HTTP | Manuale | Integrato |
| Concorrenza | Manuale (goroutine) | Facile (Async(true)) |
| Crawling/Link follow | Manuale | Automatico |
| Funzioni anti-bot | Manuale | Integrate |
| Gestione errori | Manuale | Integrata |
Colly ti fa risparmiare un sacco di tempo per tutto quello che va oltre lo scraping più semplice.
Passo 5: Affrontare le Sfide Reali del Web Scraping in Go
Fare web scraping nella realtà non è sempre una passeggiata. Ecco come gestire le difficoltà più comuni:
1. Blocco IP
- Ruota i proxy usando
http.Transportdi Go o il supporto proxy di Colly. - Rallenta le richieste con ritardi casuali.
2. User-Agent e header
- Imposta sempre uno User-Agent realistico (tipo Chrome o Firefox).
- Simula gli header di un vero browser (Accept-Language, ecc.).
3. CAPTCHAs
- Se becchi un CAPTCHA, probabilmente stai estraendo dati troppo in fretta o in modo troppo “robotico”.
- Usa browser headless (come ) per siti che richiedono JavaScript o interazione visiva.
- Per siti con difese anti-bot toste, valuta servizi di risoluzione CAPTCHA.
4. Paginazione
- Con Colly puoi seguire automaticamente i link “Next”:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. Contenuti dinamici (JavaScript)
- Le librerie HTTP di Go non eseguono JS. Usa un browser headless (Rod, chromedp) o prova a estrarre i dati direttamente dagli endpoint API.
6. Quando diventa troppo complicato… Usa Thunderbit
A volte ti trovi davanti a un muro—magari il sito è troppo dinamico o hai bisogno dei dati subito senza scrivere codice. Qui entra in gioco . Thunderbit è un Estrattore Web AI per Chrome che:
- Usa l’AI per individuare e estrarre i campi—basta cliccare su “AI Suggerisci Colonne”.
- Gestisce in automatico la navigazione tra sottopagine e la paginazione.
- Funziona in un vero browser (o nel cloud), quindi va alla grande anche su siti pieni di JavaScript e la maggior parte delle difese anti-bot.
- Esporta direttamente su Excel, Google Sheets, Airtable o Notion—senza scrivere una riga di codice.
- Ti permette di programmare scraping e automatizzare la raccolta dati per il tuo team.
Thunderbit è la soluzione perfetta per chi lavora in business, team commerciali o chiunque abbia bisogno di dati ordinati senza dover programmare. E sì, sono di parte—l’abbiamo creato proprio per risolvere questi problemi.
Unire Go e Thunderbit per la Massima Produttività
Ecco il trucco: non devi scegliere tra Go e Thunderbit. I team più smart usano entrambi.
Esempio di flusso di lavoro:
- Usa Go (con Colly) per scansionare una grande lista di URL o raccogliere dati di base su larga scala.
- Passa gli URL a Thunderbit per estrarre info dettagliate e strutturate—soprattutto quando devi gestire sottopagine, contenuti dinamici o difese anti-bot toste.
- Esporta i dati da Thunderbit su Google Sheets o CSV.
- Usa di nuovo Go per elaborare, unire o analizzare i dati come ti serve.
Questo approccio ibrido ti dà la velocità e il controllo di Go, più la flessibilità e l’intelligenza artificiale di Thunderbit. È come avere sia un coltellino svizzero che un trapano elettrico nella tua cassetta degli attrezzi.
Confronto tra Soluzioni di Web Scraping in Go: Go Puro vs. Colly vs. Thunderbit
Ecco una panoramica per aiutarti a scegliere lo strumento giusto:
| Aspetto | Go puro (net/http + html) | Go + Colly (Libreria) | Thunderbit (AI No-Code) |
|---|---|---|---|
| Configurazione e apprendimento | Ripida (serve codice) | Media (API più semplice) | Facilissima (no code, AI) |
| Concorrenza | Manuale (goroutine) | Integrata (Async(true)) | Parallelismo cloud/browser |
| Contenuti dinamici (JS) | Serve browser headless | Supporto JS parziale, o Rod | Browser completo, gestisce JS |
| Gestione anti-bot | Manuale (proxy, header) | Funzioni integrate | Quasi automatica, IP cloud |
| Strutturazione dati | Codice personalizzato | Callback, struct personalizzate | AI suggerisce, formattazione automatica |
| Opzioni di esportazione | Personalizzate (CSV, DB) | Personalizzate | Excel, Sheets, Notion, Airtable |
| Manutenzione | Alta (codice da aggiornare) | Media | Bassa (AI si adatta ai cambiamenti) |
| Ideale per | Dev, pipeline custom | Dev, prototipi rapidi | Non programmatori, utenti business |
Consiglio: Usa Go/Colly per progetti su misura, su larga scala o integrati nel backend. Scegli Thunderbit quando vuoi velocità, semplicità o devi gestire siti complessi lato front-end.
Riepilogo: Come Iniziare con il Web Scraping in Go
- Go è una bomba per il web scraping—soprattutto se vuoi velocità, concorrenza e affidabilità.
- Parti facile: Configura l’ambiente Go, fai richieste HTTP e analizza l’HTML con Goquery.
- Potenzia con Colly: Per crawling, concorrenza e tecniche anti-bot, Colly è il tuo alleato.
- Affronta le sfide reali: Ruota proxy, imposta header e usa browser headless o Thunderbit per i siti più tosti.
- Combina gli strumenti: Non aver paura di usare insieme Go e Thunderbit per ottenere il meglio da entrambi.
Il web scraping è un vero moltiplicatore di risultati per team sales, operations e ricerca. Con Go, le librerie giuste (e un pizzico di AI), puoi automatizzare le attività ripetitive e concentrarti sulle analisi che fanno davvero crescere il business.
Risorse Utili per il Web Scraping con Go
Vuoi approfondire? Ecco alcune delle mie risorse preferite:
Buon scraping—che i tuoi dati siano sempre ordinati, i tuoi scraper velocissimi e il caffè bello forte.
Domande Frequenti
1. Perché dovrei usare Go per il web scraping invece di Python o JavaScript?
Go offre concorrenza, velocità e affidabilità superiori—soprattutto per scraping su larga scala o di lunga durata. È perfetto quando devi estrarre dati da migliaia di pagine in fretta e vuoi un eseguibile portabile.
2. Qual è il modo più semplice per analizzare HTML in Go?
Usa la libreria . Offre selettori simili a jQuery per navigare facilmente il DOM ed estrarre dati.
3. Come gestisco siti con contenuti generati da JavaScript in Go?
Serve una libreria per browser headless come o . In alternativa, usa per un approccio no-code che gestisce JS nativamente.
4. Qual è il modo migliore per evitare di essere bloccati durante lo scraping?
Ruota User-Agent, usa proxy, aggiungi ritardi tra le richieste e simula il comportamento di un vero browser. Colly semplifica queste tecniche e Thunderbit gestisce automaticamente la maggior parte delle difese anti-bot.
5. Posso combinare Go e Thunderbit nel mio flusso di lavoro?
Assolutamente sì! Usa Go per crawling su larga scala o integrazione backend, e Thunderbit per estrazione AI, scraping di sottopagine ed esportazione verso strumenti business. È una combinazione super sia per sviluppatori che per utenti business.
Vuoi portare il tuo web scraping al livello successivo? Prova o visita il per altri consigli, tutorial e approfondimenti su scraping, automazione e AI.