Lascia che ti racconti una cosa: il web è come la più grande biblioteca che esista, ma la maggior parte dei libri ha le pagine incollate tra loro. Ogni giorno mi capita di parlare con imprenditori, marketer e team commerciali che sanno bene che tra le righe dei siti si nascondono vere e proprie miniere d’oro—specifiche di prodotto, prezzi dei concorrenti, recensioni dei clienti, contatti—ma quando si tratta di estrarre queste informazioni? Qui iniziano i problemi. Dopo anni passati nel mondo SaaS e dell’automazione, ne ho viste di tutti i colori: dalle “maratone di copia-incolla” alle “avventure Python fatte in casa”. La bella notizia? Oggi estrai testo da sito web è molto più facile (e meno snervante) grazie ai nuovi estrattori web AI e alle estensioni smart per browser.
In questa guida ti racconto tutti i metodi pratici che conosco—dal classico copia-incolla alle soluzioni più evolute basate su AI come (sì, è il nostro prodotto, ma ti dirò pro e contro senza filtri). Che tu sia un mago di Excel, uno sviluppatore o semplicemente stufo di perdere tempo sulle pagine web, qui troverai la strada giusta per te. Preparati a “sfogliare” questi libri digitali e a portarti a casa il testo che ti serve.
Cosa vuol dire estrarre testo da un sito web?
Quando si parla di “estrarre testo da un sito web”, si intende recuperare le informazioni visibili (e a volte anche quelle nascoste) da una pagina web e trasformarle in un formato utilizzabile—come un file Excel, un database o anche solo un documento Word ordinato. Ma non tutto il testo online è uguale:
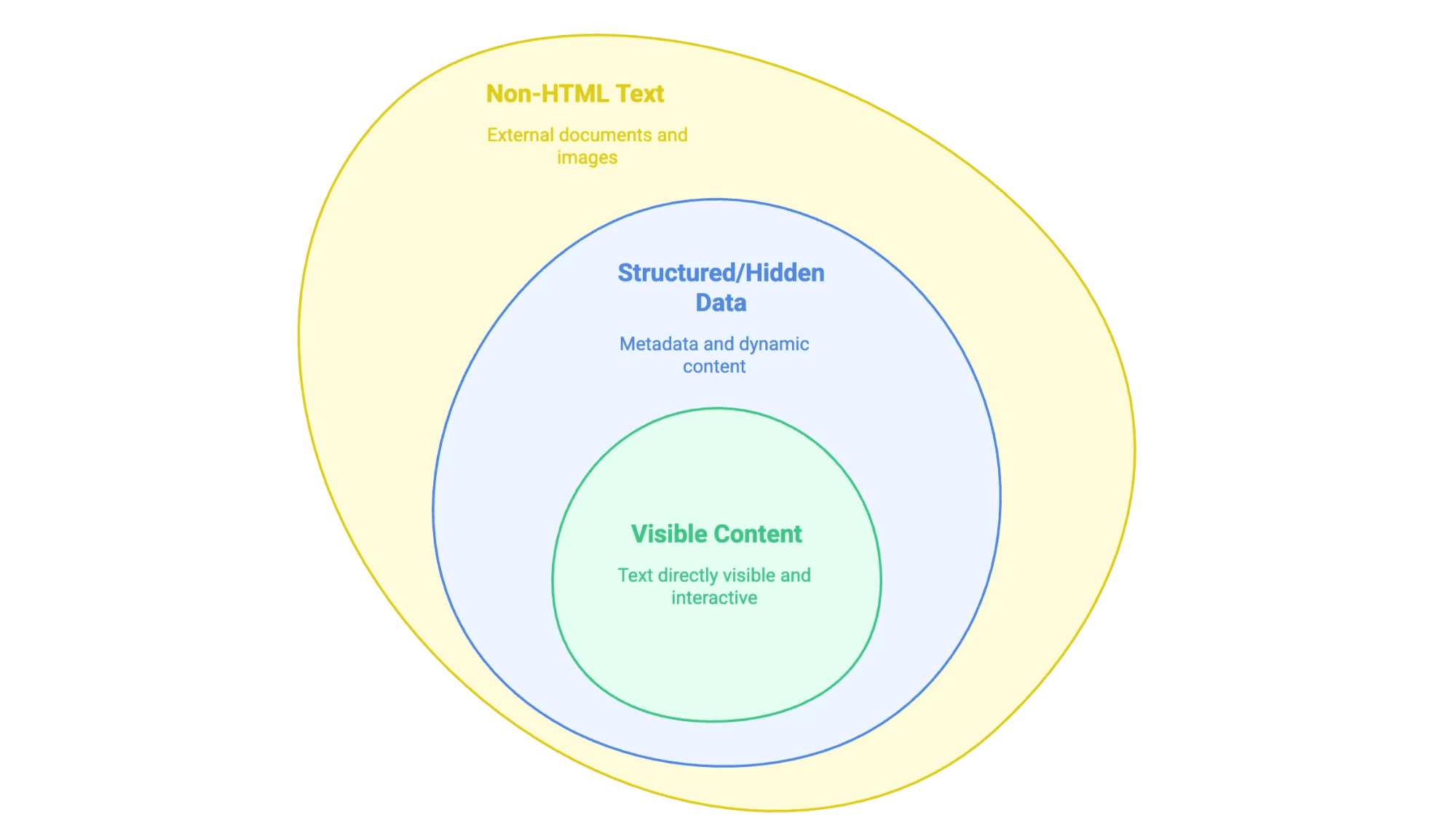
- Contenuto visibile: Quello che puoi selezionare con il mouse—testi, titoli, elenchi, tabelle, descrizioni prodotto, articoli di blog, ecc.
- Dati strutturati o nascosti: Ad esempio i metadati nei tag
<meta>, script JSON-LD o informazioni caricate via JavaScript che compaiono solo dopo un click o uno scroll. - Testo non-HTML: PDF, documenti Word e persino immagini con testo (come contratti scansionati o infografiche) collegati o incorporati nel sito.
Il trucco è capire che tipo di testo ti serve, perché ogni situazione richiede un approccio diverso.
Perché estrarre testo da un sito web? Vantaggi e usi pratici
Diciamolo chiaro: nessuno si mette a estrarre testo dai siti per hobby (a meno che tu non abbia passioni davvero particolari). Le aziende lo fanno perché il ritorno è concreto. Il mercato dei software di data extractor ha superato , e la crescita non si ferma. Ecco perché:
| Team | Esempio di Utilizzo | Vantaggio |
|---|---|---|
| Vendite | Estrazione di elenchi e contatti da directory | Prospecting più rapido e ricco |
| Marketing | Raccolta di articoli dei competitor e dati SEO | Analisi dei contenuti, individuazione trend |
| Operations | Monitoraggio prezzi su e-commerce | Prezzi dinamici, controllo scorte |
| Immobiliare | Aggregazione annunci e dettagli immobili | Analisi di mercato, generazione lead |
| Supporto | Raccolta recensioni e Q&A dai forum | Analisi sentiment, individuazione problemi |
Qualche esempio concreto:

- Lead Generation: Un’azienda di forniture per ristoranti ha in pochi minuti invece che in giorni.
- Monitoraggio competitor: Retailer come John Lewis hanno grazie ai dati sui prezzi estratti dal web.
- Analisi SEO: I team estraggono meta tag e keyword per .
E con gli strumenti AI, le aziende risparmiano rispetto ai metodi tradizionali.
Metodi manuali: le basi del copia-incolla dal sito
Partiamo dalle basi. A volte basta copiare un’informazione al volo—senza strumenti particolari.
Come estrarre testo manualmente
- Copia e incolla: Apri la pagina, seleziona il testo, premi Ctrl+C (o tasto destro > Copia). Poi incolla dove ti serve.
- Salva pagina come: Dal browser, vai su File > Salva pagina con nome. Scegli “Solo HTML” per il codice sorgente, oppure .txt per il solo testo.
- Stampa in PDF: Usa la funzione di stampa del browser per “Salva come PDF”. Poi apri il PDF e copia il testo (o usa la funzione “Salva come testo” del lettore PDF).
- Strumenti sviluppatore: Tasto destro > Ispeziona o F12 per aprire DevTools. Puoi vedere il codice HTML, trovare meta tag o JSON nascosti e copiare ciò che ti serve.
Limiti
L’estrazione manuale va bene per lavori occasionali, ma è un incubo se devi fare le cose in grande. È . Ho visto stagisti passare giorni a copiare tabelle riga per riga—nessuno vuole quel lavoro.
Estensioni browser e strumenti online per estrarre testo dai siti
Vuoi fare un salto di qualità? Le estensioni browser e gli strumenti online sono la soluzione perfetta per la maggior parte degli utenti business: niente codice, niente stress, solo pochi click.
Perché usare questi strumenti?

- Più veloci del copia-incolla manuale
- Non serve programmare
- Gestiscono tabelle, elenchi e a volte anche file
- Esportano su Excel, Google Sheets, CSV, ecc.
Vediamo le opzioni più diffuse.
Thunderbit: estrattore web AI per testo veloce e preciso
Ok, sono di parte, ma è davvero pensato per rendere l’estrazione del testo dal web semplice come ordinare una pizza. Ecco come funziona:
Passaggi: estrai testo con Thunderbit
- Installa l’estensione Chrome: dal Chrome Web Store.
- Apri il sito: Vai sulla pagina da cui vuoi estrarre il testo.
- Clicca su “AI Suggerisci Campi”: L’AI di Thunderbit analizza la pagina e suggerisce quali campi (colonne) estrarre—ad esempio nome prodotto, prezzo, descrizione, ecc.
- Rivedi e modifica: Puoi modificare i campi suggeriti o aggiungerne di nuovi.
- Clicca su “Estrai”: Thunderbit raccoglie i dati, anche da sottopagine o elenchi paginati se necessario.
- Esporta: Scarica i dati su Excel, Google Sheets, Airtable, Notion o in formato CSV/JSON. Nessun costo extra per l’export.
Cosa rende Thunderbit diverso?
- Suggerimento campi con AI: Non serve impostare selettori o scrivere codice. L’AI individua ciò che conta nella pagina.
- Gestione sottopagine e paginazione: Vuoi i dettagli di ogni prodotto in una categoria? Thunderbit naviga in automatico.
- Estrazione da PDF, immagini e documenti: Hai un manuale PDF o una scheda prodotto in immagine? L’OCR integrato di Thunderbit estrae anche da questi.
- Supporto multilingua: Funziona in 34 lingue (niente Klingon per ora, ma ci stiamo lavorando).
- Export gratuito: Nessun paywall per scaricare i tuoi dati.
- Casi d’uso: Descrizioni prodotto, contatti, contenuti blog, liste lead, e molto altro.
Vuoi vedere Thunderbit in azione? Dai un’occhiata al nostro per guide come .
Altre estensioni e strumenti online
Ecco una panoramica veloce di altri strumenti che potresti incontrare:
- Estrattore Web (): Gratuito, punta e clicca, ma serve un po’ di pratica. Ottimo per chi ha un po’ di dimestichezza tecnica, ma bisogna configurare “sitemap” e selettori. Gestisce la paginazione, ma non PDF o immagini. .
- CopyTables: Semplicissimo—copia le tabelle HTML negli appunti o su Excel. Perfetto per estrazioni rapide di tabelle, ma funziona solo su una pagina alla volta e solo per le tabelle. .
- ScraperAPI (): Per sviluppatori. Invi una URL, ricevi l’HTML (gestisce proxy, blocchi, ecc.), ma devi comunque estrarre il testo da solo. .
Quando usare quale strumento?
- Thunderbit: Se vuoi velocità, AI e supporto per più formati (inclusi PDF/immagini).
- Estrattore Web: Se ti piace smanettare e vuoi più controllo.
- CopyTables: Se ti serve solo una tabella, subito.
- ScraperAPI: Se stai sviluppando un tuo estrattore in codice.
Estrazione automatica: soluzioni di programmazione per il testo web
Se sei uno sviluppatore (o ne hai uno a disposizione), creare un tuo estrattore ti dà il massimo controllo. Ecco il flusso base:
- Invia una richiesta HTTP: Usa
requestsdi Python o simili per scaricare la pagina. - Analizza l’HTML: Usa
BeautifulSoup,lxmloScrapyper trovare il testo che ti interessa. - Estrai ed esporta: Recupera il testo, puliscilo e salvalo in CSV, JSON o database.
Esempio: Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)Pro e contro
- Pro: Massima flessibilità, puoi gestire qualsiasi sito o tipo di dato, integrazione con i tuoi sistemi.
- Contro: Richiede competenze di programmazione, manutenzione continua e gestione di eventuali blocchi anti-bot.
Quando scegliere questa strada
- Devi estrarre dati da migliaia (o milioni) di pagine.
- Il sito è complesso (login, form multi-step).
- Vuoi integrare l’estrazione direttamente nelle tue app o flussi di lavoro.
Estrazione da formati non-HTML: PDF, Word e immagini
I siti non sono solo HTML—spesso contengono PDF, documenti Word e immagini con testo prezioso. Ecco come recuperarli:
- PDF testuali: Usa strumenti come Adobe Acrobat o librerie come
PDFMineroPyPDF2per estrarre il testo. - PDF scansionati: Usa strumenti OCR (riconoscimento ottico dei caratteri) come Tesseract, o .
Documenti Word/Excel
- Word: Usa
python-docxper leggere file .docx. - Excel: Usa
openpyxlopandasper file .xlsx.
Immagini
- Strumenti OCR: Tesseract per l’open source, oppure servizi cloud per maggiore precisione. Immagini di buona qualità (150–300 DPI) danno risultati migliori.
L’approccio di Thunderbit
La funzione “Image/Document Parser” ti permette di caricare o collegare un PDF, un’immagine o un documento, e l’AI estrarrà il testo (e suggerirà colonne se trova una tabella). Niente più strumenti separati—gestisci i file come fossero pagine web.
Confronto tra i metodi: quale soluzione di estrazione testo scegliere?
Ecco una tabella di confronto per aiutarti a decidere:
| Metodo | Facilità d’Uso | Scalabilità | Competenze Tecniche | Tipi di Dati Supportati | Ideale per |
|---|---|---|---|---|---|
| Manuale (Copia-Incolla) | Molto Facile | Bassa | Nessuna | Solo testo visibile | Lavori piccoli, una tantum |
| Estensioni/Strumenti | Facile–Media | Media | Basse–Medie | HTML, alcune tabelle | Non tecnici, lavori piccoli–medi |
| Strumenti AI (Thunderbit) | Molto Facile | Alta | Nessuna | HTML, PDF, immagini, altro | Aziende, contenuti misti |
| Programmazione (Codice) | Difficile | Molto Alta | Alte | Qualsiasi (con le librerie giuste) | Sviluppatori, grandi progetti |
| Estrazione Non-HTML (OCR) | Media | Bassa–Media | Medie | PDF, immagini, documenti | Quando file/immagini sono centrali |
Se cerchi la soluzione più rapida, flessibile e senza stress—soprattutto in ambito business—gli strumenti AI come Thunderbit sono imbattibili. Ma se hai bisogno di controllo totale o lavori su larga scala, sviluppare un tuo estrattore può essere la scelta giusta.
Riepilogo: inizia subito a estrarre testo dai siti web
- Il web è pieno di dati testuali preziosi, ma non sempre sono facilmente accessibili.
- I metodi manuali vanno bene solo per lavori minuscoli, ma non sono scalabili.
- Estensioni browser e estrattori web AI come rendono l’estrazione del testo veloce, precisa e accessibile a tutti—senza bisogno di programmare.
- Per contenuti non-HTML (PDF, immagini), scegli strumenti con OCR e parser documentali integrati.
- Scegli il metodo in base alle competenze del tuo team, alla dimensione del progetto e ai tipi di dati che ti servono.
Buona estrazione—e che i tuoi giorni di Ctrl+C siano sempre meno! Con gli strumenti giusti, raccogliere dati dal web diventa un processo automatico che ti libera tempo per attività più strategiche. Basta ore perse a copiare e incollare: ora puoi lavorare in modo più intelligente, rapido ed efficiente. È il momento di dire addio alla fatica manuale e abbracciare un futuro più produttivo!
Domande Frequenti
D1: Posso estrarre dati da qualsiasi sito web?
R1: Non sempre. Alcuni siti bloccano gli estrattori o vietano l’estrazione nei termini d’uso. Controlla sempre le policy del sito.
D2: Quanto sono precisi gli estrattori web basati su AI?
R2: Gli estrattori AI come Thunderbit sono molto precisi, ma potrebbero richiedere qualche aggiustamento su pagine particolarmente complesse o dinamiche.
D3: Serve saper programmare per usare gli strumenti di web scraping?
R3: No, strumenti come Thunderbit e molte estensioni browser sono pensati per utenti non tecnici e non richiedono competenze di programmazione.
D4: Che tipo di dati posso estrarre da PDF o immagini?
R4: Gli strumenti OCR possono estrarre testo, tabelle e anche dati nascosti da PDF scansionati e immagini, rendendo l’estrazione molto versatile.
Approfondisci