

Negli uffici di mezzo mondo sta succedendo qualcosa, e non c’entrano né il calcetto né il kombucha alla spina. Sta prendendo piede l’“easy web extract”: l’idea che chiunque — non solo chi mastica codice — possa tirare fuori dati utili dal web in pochi minuti, invece che in giorni. Ti sarà capitato di guardare un sito pensando “magari potessi prendere questi nomi, questi prezzi, queste email e buttarli in un foglio di calcolo”. Non sei certo l’unico. Parlando con commerciali, marketer e gente che manda avanti le operations, sento sempre la stessa frase: “Ma perché deve essere ancora così complicato?”
E la domanda di scraping facile sta letteralmente esplodendo. Lo dice McKinsey's State of AI 2025: il 71% delle aziende usa ormai l’AI generativa in almeno una funzione, contro il 65% di inizio 2024, e l’estrazione di dati dal web è una delle applicazioni che cresce più in fretta. Il mercato dello scraping è stimato a 1,17 miliardi di dollari nel 2026 e a 2,23 miliardi entro il 2031, con gli utenti business — quelli senza un background tecnico, soprattutto — a fare da motore: vogliono strumenti che rendano l’estrazione dati semplice come un copia e incolla. Ma cosa vuol dire concretamente “easy web extract” e come ti torna utile nel lavoro di tutti i giorni? Andiamo a vederlo.
Prova l’easy web extract con Thunderbit (gratis)
Easy web extract per chi non è tecnico: zero codice, zero ansia
Cominciamo dalle fondamenta: cosa intendiamo per “easy web extract”? In sostanza, vuol dire prendere il web — caotico e in continuo movimento — e trasformarlo in tabelle pulite e ordinate, senza scrivere una sola riga di codice. Per chi lavora nel business e non è uno sviluppatore, è una svolta vera. Niente più ticket all’IT che restano nel dimenticatoio, niente più battaglie con gli script Python, niente più progetti abbandonati perché un sito ha cambiato layout dalla sera alla mattina.
Perché proprio adesso pesa così tanto? Perché il web è più mosso che mai. Scroll infinito, popup, JavaScript a non finire: roba che fa cadere gli scraper tradizionali come birilli. E allo stesso tempo, ai team aziendali viene chiesto di sfornare insight a una velocità mai vista. Nel retail e nell’ecommerce, il 98% delle organizzazioni considera i dati web pubblici cruciali o molto importanti per il proprio lavoro, e più della metà li usa ogni giorno.
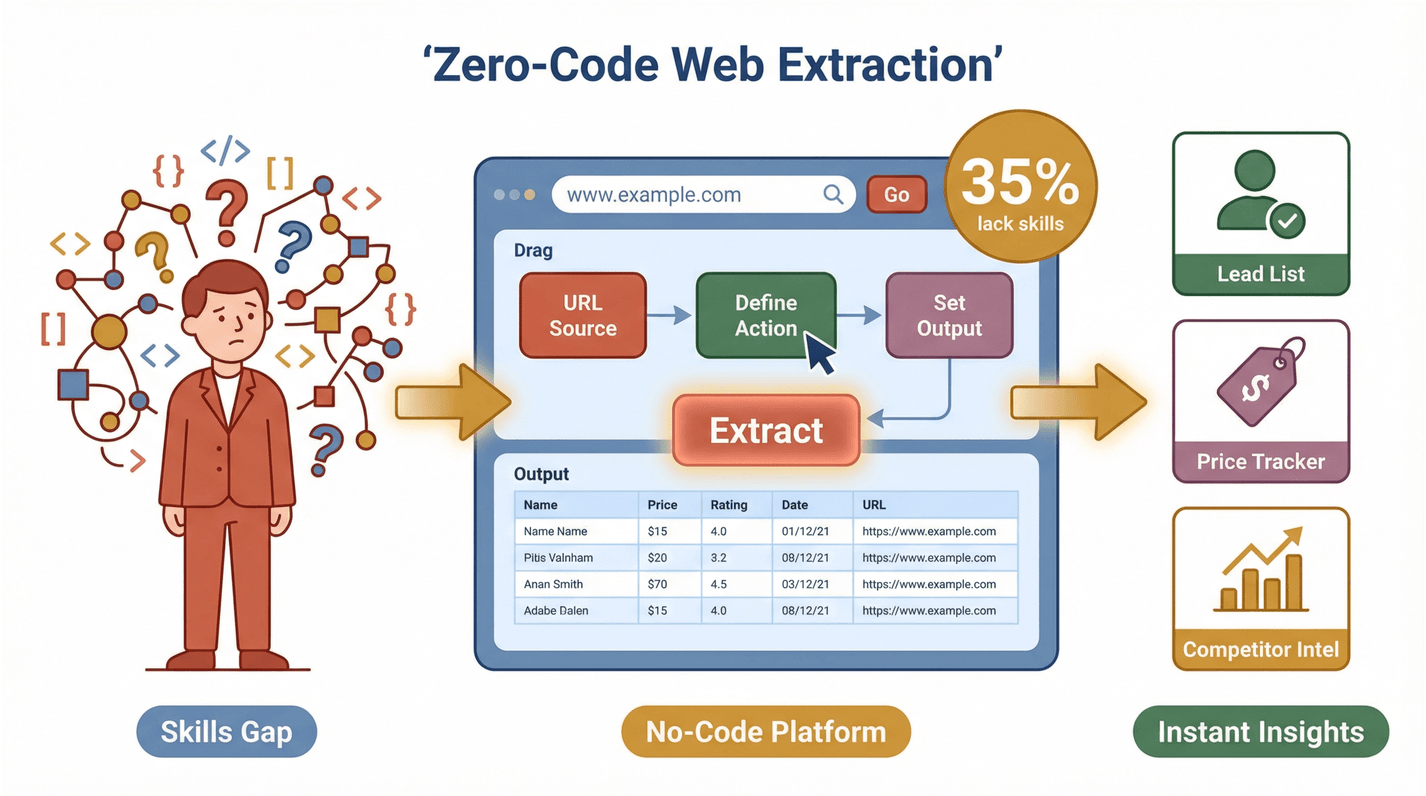
Il punto, però, è questo: la maggior parte di questi team non è tecnica. Un’indagine recente ha fatto emergere che il 35% delle aziende non ha le competenze adatte all’estrazione di dati web, e che il 33% non ha gli strumenti giusti. Una voragine enorme — e una grossa occasione per le soluzioni zero-code. Quando chiunque è in grado di estrarre e usare dati dal web, si apre un altro livello di produttività: che tu stia mettendo insieme una lista di lead, tenendo d’occhio i concorrenti o controllando i prezzi.
Il movimento no-code/low-code: perché ci riguarda
L’avanzata degli strumenti no-code e low-code parla di una cosa sola: rendere la tecnologia alla portata di tutti. Non è una parola d’ordine partorita nella Silicon Valley, è un cambiamento concreto nel modo di lavorare. Nel mondo dello scraping si traduce così:
- Zero codice: estrae dati chiunque, non solo gli ingegneri.
- Velocità: risultati in minuti, non in giorni.
- Flessibilità: ti adatti al volo a nuovi siti e a nuove esigenze.
- Meno errori: l’automazione taglia gli sbagli da copia e incolla.
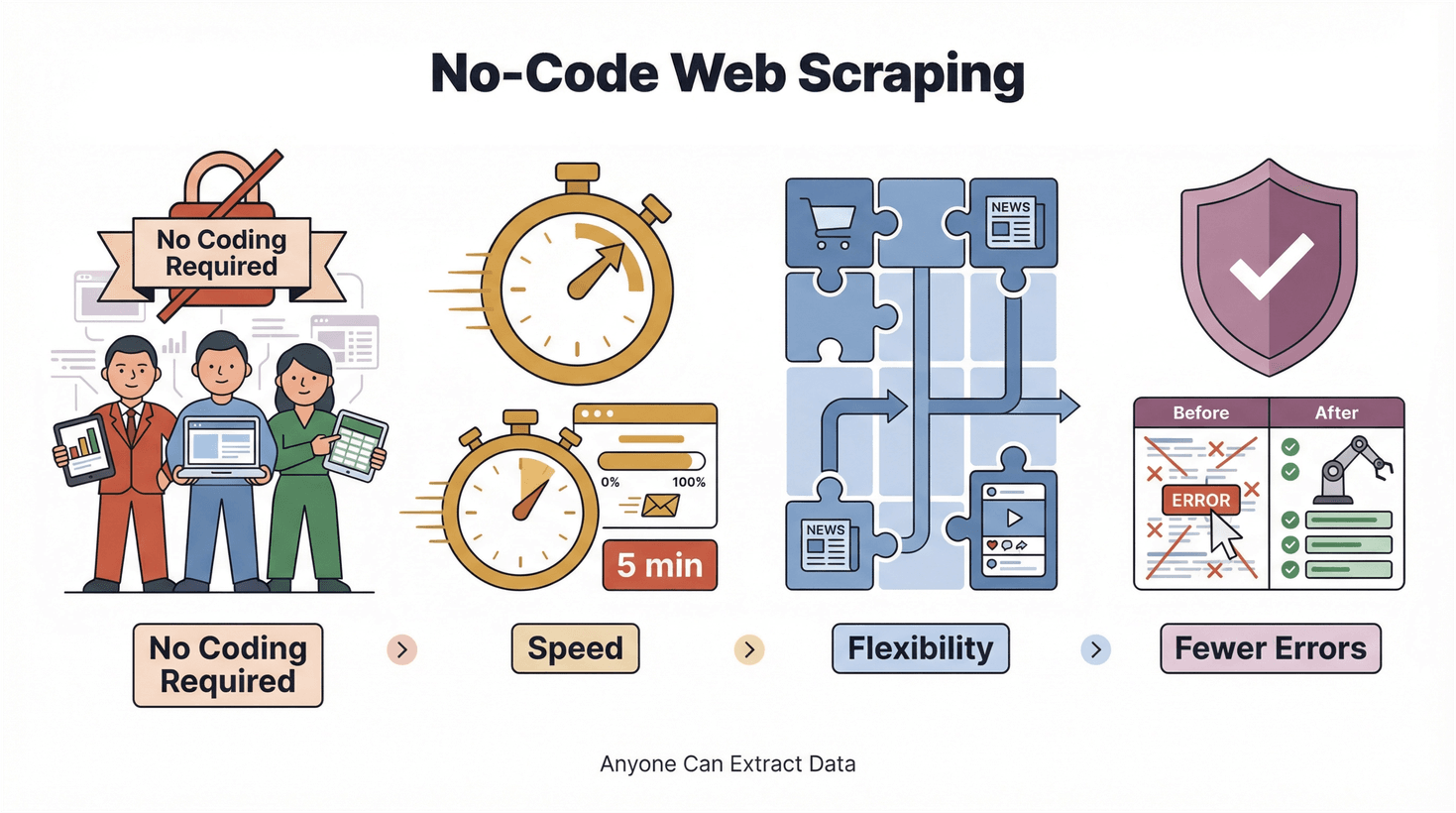
E la cosa migliore? Per partire non devi diventare un mago della tecnologia.
Perché gli scraper tradizionali fanno venire il mal di testa
Diciamolo apertamente: gli strumenti di scraping classici sembrano fatti dagli sviluppatori per gli sviluppatori, non per chi lavora nel business. L’ho visto succedere mille volte: il team parte carico su un progetto nuovo e sbatte contro il muro appena lo strumento chiede selettori CSS, XPath o espressioni regolari. Da lì in poi, sguardi nel vuoto ed email del tipo “magari ci riproviamo il prossimo trimestre”.
In genere la storia va così:
- Bisogna programmare: tanti strumenti datati pretendono che tu scriva script o configuri template intricati.
- Configurazione interminabile: mappare ogni singolo campo, gestire i login, impostare i proxy per non farti bloccare.
- Logica fragile: il sito cambia layout e lo scraper si pianta. E così finisci a fare debug del codice invece del tuo vero lavoro.
- Manutenzione senza fine: a ogni aggiornamento del sito, si ricomincia da capo.
Non stupisce che gli stessi team che lamentano un buco di competenze ne segnalino anche uno di strumenti: un sondaggio di Bright Data del 2024 ha rilevato che il 35% delle organizzazioni non ha le competenze giuste e il 33% non ha gli strumenti giusti per lavorare con i dati web pubblici. E pure i team più attrezzati faticano a stare al passo con ban degli IP, contenuti dinamici e CAPTCHA.
Intanto a chi lavora nel business basterebbe un modo semplice e affidabile per portare i dati dentro i propri fogli o nel CRM. Ed è proprio qui che entrano in scena l’easy web extract e i metodi di scraping alla portata di tutti.
Come Thunderbit rende reale l’easy web extract
Estrai dati da qualsiasi sito web con l’AI Get Started Free
Ed è qui che mi accendo, perché è esattamente il problema che volevamo togliere di mezzo con Thunderbit. La nostra missione è una sola: rendere lo scraping così semplice che possa farlo chiunque, qualunque sia il suo background tecnico.
Thunderbit è un’estensione Chrome AI Web Scraper che riduce l’estrazione web a due clic. Funziona così:
- Spiega cosa ti serve: in linguaggio naturale dici a Thunderbit quali dati vuoi. Per esempio: “Estrai tutti i nomi e i prezzi dei prodotti da questa pagina”.
- Clicca su “AI Suggest Fields”: l’AI di Thunderbit legge la pagina e ti propone le colonne migliori, tipo “Nome”, “Prezzo”, “Email” o “Immagine”.
- Clicca su “Scrape”: al resto pensa Thunderbit, paginazione, sottopagine e perfino contenuti dietro login se serve.
Tutto qua. Niente codice, niente template, niente configurazioni cervellotiche. L’interfaccia è pensata per chi lavora nel business — vendite, marketing, ecommerce, immobiliare — e vuole solo arrivare al risultato.
Il flusso guidato dall’AI di Thunderbit: più sveglio, non più faticoso
La magia vera sta nell’AI. Thunderbit non tira a indovinare cosa vuoi: legge la pagina, ne coglie il contesto e struttura i dati da sola. Se vuoi spingerti oltre, puoi dare istruzioni su misura per ogni campo (tipo “classifica questa colonna” o “traduci in inglese”), ma la maggior parte delle persone clicca e via.
Con questo approccio basato sull’AI ottieni:
- Meno errori: l’AI si adatta a layout diversi, quindi i risultati restano coerenti anche quando i siti cambiano.
- Configurazione lampo: niente template da costruire né script da scrivere.
- Dati pronti all’uso: Thunderbit può etichettare, categorizzare e perfino arricchire i dati mentre li raccoglie.
Se vuoi scendere nel dettaglio, dai un’occhiata alla documentazione di Thunderbit o all’articolo sul data scraping automatizzato. Sul blog di Thunderbit trovi anche altre guide, come Come estrarre dati da qualsiasi sito web con l’AI e Cos’è il data scraping e come farlo nel 2025.
Le funzioni di Thunderbit che rendono lo scraping davvero semplice
A distinguere Thunderbit non è solo l’AI, ma tutto il flusso, costruito attorno a esigenze aziendali reali. Ecco le funzionalità che i nostri utenti citano più spesso:
- Paginazione automatica: Thunderbit se la cava con siti multipagina e scroll infinito senza alcuna configurazione.
- Estrazione delle sottopagine: ti servono più dettagli? Thunderbit visita ogni sottopagina (schede prodotto, profili LinkedIn) e arricchisce il dataset in automatico.
- Esporti dove vuoi: mandi i dati dritti in Excel, Google Sheets, Airtable, Notion, oppure li scarichi in CSV/JSON. Basta con le maratone di copia e incolla.
- Funziona dietro login: estrai da siti che richiedono l’accesso — Thunderbit gira nel browser, quindi vede quello che vedi tu.
- Etichettatura e categorizzazione con AI: aggiungi istruzioni per classificare, taggare o tradurre i dati mentre li estrai.
- Scraping pianificato: imposti attività ricorrenti per tenere i dati sempre freschi, perfetto per monitorare prezzi o lead.
E sì, tutto questo è in uno strumento su cui contano oltre 100.000 utenti nel mondo.
Paginazione automatica ed estrazione delle sottopagine
Una delle seccature più grosse dello scraping è gestire le liste paginate o le pagine di dettaglio annidate. Con Thunderbit te ne dimentichi. L’AI riconosce la paginazione — che sia un pulsante “Avanti” o uno scroll infinito — e segue da sola i link verso le sottopagine. Risultato: estrai centinaia o migliaia di record in una passata, senza un clic manuale.
Mettiamo che tu stia raccogliendo un elenco di prodotti da Amazon: Thunderbit prende tutti i prodotti su più pagine e poi entra in ogni scheda per recuperare recensioni, valutazioni o informazioni sul venditore. È come avere un assistente che non si stanca e non si annoia mai.
Esportazione in più formati e integrazione con i CRM
I dati servono solo se poi riesci davvero a usarli. Thunderbit ti lascia esportare i risultati nel formato che fa comodo al tuo team — Excel, Google Sheets, Airtable, Notion o CSV/JSON. Puoi anche mandare i dati direttamente nel CRM o negli strumenti di lavoro, così sales e operations hanno sempre sotto mano le informazioni più recenti.
Questa integrazione diretta fa risparmiare un sacco di tempo. Niente più pulizia di export sgangherati o colonne da riformattare: ci pensa l’AI di Thunderbit.
Casi d’uso concreti dell’easy web extract
Dove fa la differenza più grande l’easy web extract? Ecco alcune situazioni reali che ho visto tra gli utenti di Thunderbit:
Estrazione di lead per le vendite
I team commerciali campano sulle loro liste di lead. Con Thunderbit raccogli in pochi minuti i contatti da LinkedIn, Google Maps o directory aziendali. Apri la pagina, clicchi su “AI Suggest Fields” e lasci che Thunderbit ti porti nomi, email, numeri di telefono e dettagli aziendali in un foglio già pronto.
Un sales manager mi ha raccontato che prima passava ore ogni settimana a copiare e incollare lead. Adesso, con Thunderbit, costruisce liste mirate in una frazione del tempo — e il team può dedicarsi all’outreach invece che all’inserimento dati.
Ecommerce e monitoraggio del mercato
I team ecommerce usano Thunderbit per tenere d’occhio SKU, prezzi e recensioni dei concorrenti su Amazon, Shopify e altre piattaforme. Vuoi seguire le variazioni di prezzo o i nuovi lanci? Imposti uno scraping pianificato e ogni mattina ti ritrovi i dati aggiornati nel tuo Google Sheet.
Qui l’estrazione delle sottopagine di Thunderbit dà il meglio: recuperi dettagli prodotto, immagini e perfino recensioni dei clienti senza muovere un dito.
Raccolta di dati immobiliari
Chi lavora nell’immobiliare usa Thunderbit per raccogliere annunci, prezzi e informazioni sugli agenti da siti come Zillow o Realtor.com. L’AI gestisce paginazione e sottopagine, così ottieni una fotografia completa e aggiornata del mercato — perfetta per analisi o report ai clienti.
Un analista immobiliare mi ha detto che ciò che prima gli portava via un pomeriggio intero ora si fa in pochi clic. È questa la forza dello scraping alla portata di tutti.
Metodi tradizionali contro metodi semplici di scraping, a confronto
Mettiamo tutto in fila, uno accanto all’altro:
| Caratteristica | Scraper tradizionali | Easy Web Extract (Thunderbit) |
|---|---|---|
| Serve programmare | Sì (script, selettori) | No (AI + linguaggio naturale) |
| Tempo di configurazione | Alto (template, configurazione) | Basso (2 clic) |
| Manutenzione | Frequente (si rompe quando il sito cambia) | Minima (l’AI si adatta) |
| Gestione della paginazione | Configurazione manuale | Automatica |
| Estrazione di sottopagine | Logica complessa | 1 clic |
| Formati di esportazione | Spesso limitati | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Funziona dietro login | A volte (con configurazione) | Sì (gira nel browser) |
| Etichettatura/categorizzazione dei dati | Post-elaborazione manuale | Integrata, con AI |
| Pianificazione/monitoraggio | A volte (avanzato) | Sì (configurazione facile) |
Lo scarto è abissale. Con Thunderbit chiunque può estrarre, organizzare e usare dati web — senza competenze tecniche.
Dove va l’easy web extract: le tendenze in arrivo
A guardare avanti, il futuro dell’easy web extract è roseo. L’AI diventa ogni giorno più sveglia e la richiesta di strumenti zero-code corre veloce. Sempre secondo McKinsey's State of AI 2025, l’88% delle organizzazioni usa ormai l’AI con regolarità in almeno una funzione, contro il 78% dell’anno prima, e i sistemi agentici — strumenti AI capaci di gestire flussi web in più passaggi — stanno crescendo a vista d’occhio.
Cosa cambia per chi lavora nel business? Più potenza, meno fatica. Con l’AI che continua a migliorare, ci aspettiamo:
- Rilevamento dei campi ancora più sveglio: l’AI capirà dati e relazioni più complessi.
- Integrazione migliore: collegamenti diretti con più strumenti e piattaforme aziendali.
- Affidabilità più alta: meno rotture e risultati più coerenti, anche su siti dinamici o protetti.
- Più accessibilità: estrarre dati dal web diventerà una competenza di base per tutti, non solo per i tecnici.
E sì, Thunderbit sta proprio in prima fila in questo movimento.
In sintesi: i punti da portare a casa
Scopri i piani e i crediti di Thunderbit Get Started Free
Il web è il più grande database del pianeta — ma fino a poco fa solo chi sapeva programmare riusciva a sfruttarlo davvero. Ora le cose stanno cambiando in fretta. Con l’easy web extract e i metodi di scraping alla portata di tutti, chiunque può trasformare i siti in dati pronti all’uso in pochi minuti.
Ecco cosa ho imparato, e cosa spero ti resti:
- L’estrazione web zero-code è qui per restare: strumenti come Thunderbit mettono in mano a chiunque la raccolta e l’uso dei dati web, senza competenze tecniche.
- L’AI è l’ingrediente segreto: automatizzando selezione dei campi, paginazione, estrazione delle sottopagine ed etichettatura, gli scraper con AI fanno risparmiare tempo e tagliano gli errori.
- L’impatto sul business è reale: i team di sales, ecommerce e immobiliare stanno già raccogliendo più produttività, dati più freschi e decisioni migliori.
- Il bello deve ancora venire: con l’AI e gli strumenti no-code in piena evoluzione, estrarre dati dal web diventerà comune come mandare un’email.
Se sei stufo del copia e incolla a mano, esasperato dagli scraper che si rompono o anche solo curioso di scoprire cosa si può fare, prova Thunderbit. Puoi scaricare l’estensione Chrome e iniziare a estrarre dati gratis — niente configurazione, niente codice, zero ansia.
E se ti va di approfondire, fai un salto sul blog di Thunderbit per altre guide, consigli ed esempi concreti.
FAQ
1. Cos’è l’“easy web extract” e a chi serve?
L’easy web extract indica i metodi di scraping zero-code, basati sull’AI, che permettono a chiunque — soprattutto a chi lavora nel business e non è tecnico — di estrarre dati strutturati dai siti in modo rapido e indolore. È l’ideale per team di sales, marketing, ecommerce e operations che vogliono dati pronti all’uso senza grattacapi tecnici.
2. In cosa Thunderbit si distingue dagli scraper tradizionali?
Thunderbit usa l’AI per automatizzare selezione dei campi, paginazione ed estrazione delle sottopagine. A differenza degli scraper classici, che vogliono codice o template complicati, con Thunderbit descrivi quello che ti serve in linguaggio naturale ed estrai i dati in due clic.
3. Thunderbit funziona con siti dinamici o multipagina?
Sì. Thunderbit riconosce e gestisce in automatico la paginazione — scroll infinito incluso — e può seguire i link alle sottopagine per un’estrazione più profonda, con una configurazione minima.
4. Quali opzioni di esportazione offre Thunderbit?
Thunderbit esporta i dati direttamente in Excel, Google Sheets, Airtable, Notion, CSV o JSON. Puoi anche integrarlo con CRM e altri strumenti di lavoro per processi aziendali senza intoppi.
5. Usare strumenti di easy web extract come Thunderbit è sicuro ed etico?
Thunderbit promuove uno scraping responsabile ed etico. Rispetta sempre i termini di servizio dei siti, evita di raccogliere dati personali senza consenso e usa il rate limiting per non sovraccaricare i servizi. Per approfondire le buone pratiche, consulta la guida di Thunderbit allo scraping.
Pronto a sbloccare la potenza dei dati web? Prova Thunderbit oggi stesso e scopri quanto l’easy web extract può cambiarti il modo di lavorare.
Prova Thunderbit per l’easy web extract
Prova Thunderbit AI Web Scraper Get Started Free
Scopri di più




