
Sintesi esecutiva
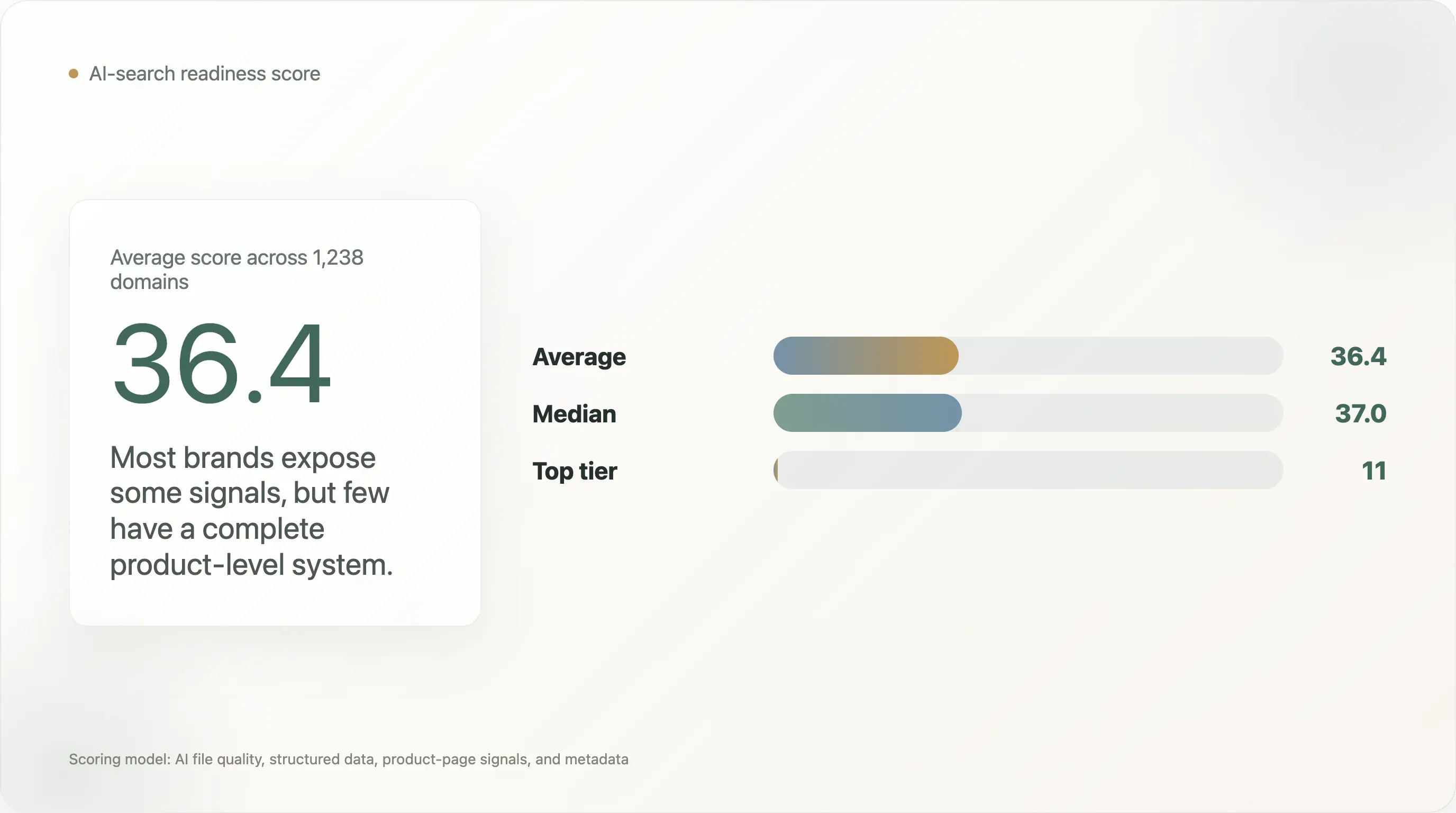
Questa ricerca valuta 1.238 domini DTC in base alla preparazione per la ricerca AI su quattro livelli: qualità dei file AI, dati strutturati generali, segnali strutturati delle pagine prodotto e metadati. Il punteggio medio è 36,4 su 100 e la mediana è 37,0. Solo 11 domini hanno raggiunto la fascia ai_ready secondo questo modello di scoring.
La scoperta più importante è il divario tra reperibilità superficiale e comprensione a livello di prodotto. Il bucket di qualità llms.txt più grande è platform_default, con 629 domini. Questo significa che molti brand hanno un file di base leggibile dall’AI perché generato dalla loro piattaforma. Ma lo schema Product nella homepage compare solo nello 0,9% dei domini valutati, mentre lo schema Product nelle pagine prodotto compare nel 39,2% dei domini in cui è stata tentata l’analisi delle pagine prodotto. I segnali di prezzo nelle pagine prodotto compaiono nel 48,1%, e i segnali di recensione o valutazione nel 43,5%.
La distribuzione delle fasce mostra quanto il mercato sia ancora agli inizi:
| Fascia di preparazione AI | Domini |
|---|---|
| Non pronto | 435 |
| Parzialmente pronto | 425 |
| Reperibilità di base | 367 |
| Pronto per l’AI | 11 |
Questa suddivisione è utile perché separa tre idee che spesso vengono confuse. Un brand può essere reperibile. Un brand può avere metadati. Un brand può avere llms.txt. Ma essere reperibile non è la stessa cosa che essere comprensibile a livello di prodotto.
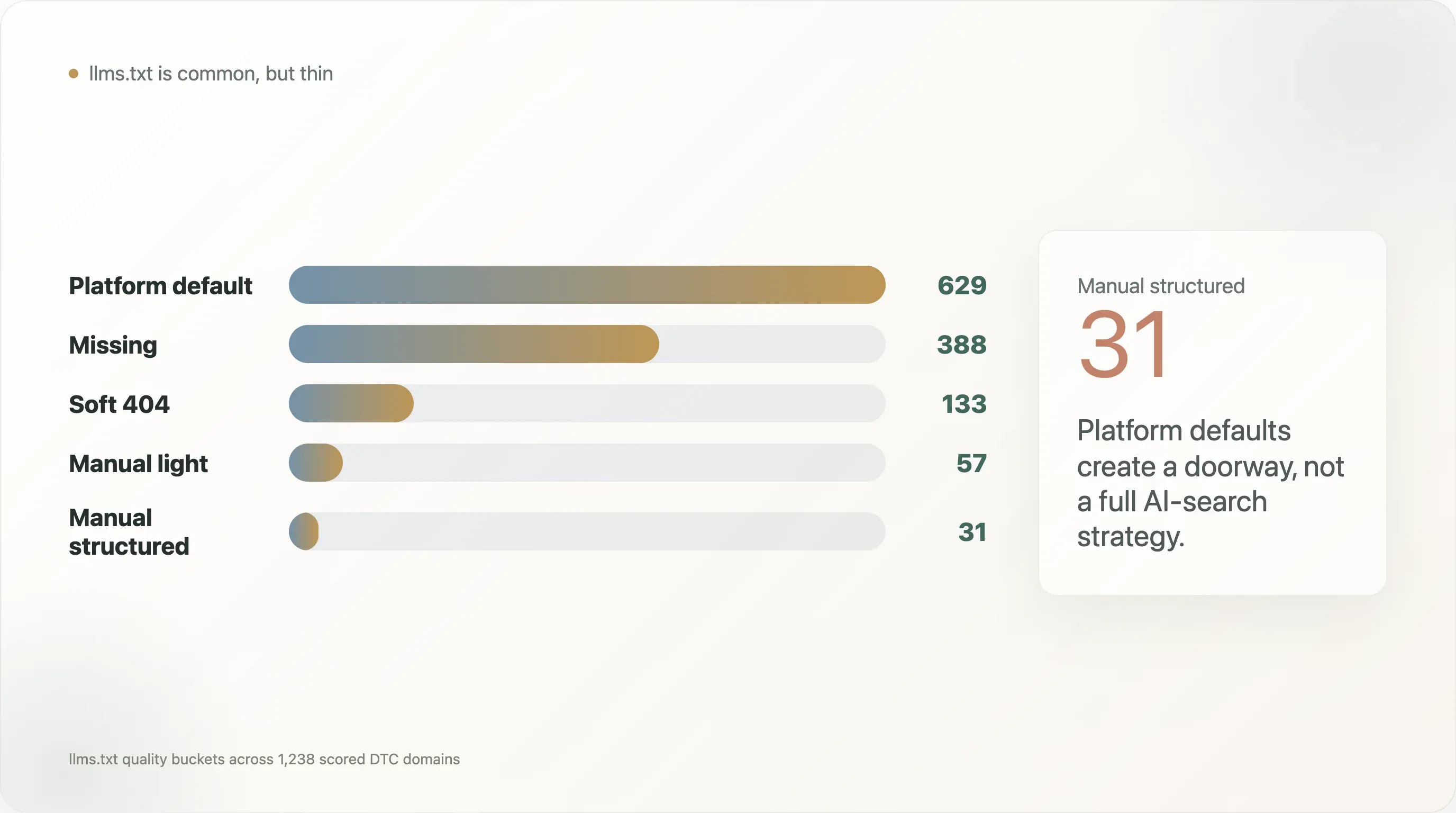
La distribuzione della qualità di llms.txt rende il punto ancora più chiaro:
| Bucket di qualità llms.txt | Domini |
|---|---|
| Predefinito della piattaforma | 629 |
| Mancante | 388 |
| Soft 404 | 133 |
| Manuale leggero | 57 |
| Manuale strutturato | 31 |
Quindi l’angolo più forte del report non è "i brand DTC hanno llms.txt". Quel messaggio è troppo superficiale. L’angolo migliore è: i valori predefiniti delle piattaforme hanno creato un primo strato sottile di reperibilità per l’AI, ma la maggior parte dei brand DTC non ha costruito lo strato di dati strutturati a livello di prodotto necessario per lo shopping AI e i motori di risposta.
Gli esempi positivi mostrano come può apparire una migliore preparazione. La fascia ai_ready include brand come Mokobara, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, La Maison Convertible, Unbloat, NuRange Coffee, Three Ships Beauty e Manukora. Questi esempi contano perché dimostrano che la preparazione per l’AI non è riservata a una sola categoria o a un solo tipo di brand. Food, beauty, wellness, arredamento, abbigliamento e commercio di nicchia possono tutti migliorare il loro livello di prodotto leggibile dalle macchine.
Le evidenze più condivisibili
-
Il punteggio medio di preparazione AI del DTC è solo 36,4/100.
-
Solo 11 dei 1.238 domini valutati hanno raggiunto la fascia
ai_ready. -
llms.txt è diffuso, ma per lo più generato dalla piattaforma. Il bucket di qualità più grande è quello predefinito della piattaforma, con 629 domini.
-
llms.txt manuale strutturato è raro. Solo 31 domini rientrano nel bucket manuale strutturato.
-
Lo schema Product nella homepage è quasi assente. Compare solo nello 0,9% dei domini valutati.
-
Lo schema Product nelle pagine prodotto è migliore, ma ancora incompleto. Compare nel 39,2% dei domini in cui è stata tentata l’analisi delle pagine prodotto.
-
La preparazione per lo shopping AI richiede fatti di prodotto, non solo accesso del crawler. Prezzo, offerta, recensioni, disponibilità e segnali di schema Product contano più di un semplice file sottile.
1. Perché la preparazione alla ricerca AI è diversa dalle basi SEO
La SEO tradizionale chiede se una pagina può essere scansionata, indicizzata, posizionata e cliccata. La ricerca AI aggiunge un livello diverso: il sistema riesce a comprendere il brand, il prodotto, l’offerta, il prezzo, le recensioni, la disponibilità, le policy e le relazioni tra entità abbastanza bene da rispondere alle domande o consigliare prodotti?
Questa differenza è importante per il DTC perché le pagine ecommerce sono piene di dettagli che possono essere facili per una persona e disordinati per una macchina. Un acquirente può guardare una pagina prodotto e capire nome del prodotto, prezzo, taglia, opzione in abbonamento, sconto, recensioni, stato delle scorte e politica di reso. Un crawler o un agente AI ha bisogno che questi dati siano espressi in modo coerente.
I metadati aiutano. Open Graph aiuta. I tag canonici aiutano. llms.txt può aiutare i crawler a trovare i contenuti importanti. Ma la struttura a livello di prodotto è la vera prova. Se un assistente shopping AI sta confrontando cinque proteine in polvere, prodotti per la skincare, candele, abiti o abbonamenti di caffè, ha bisogno di fatti strutturati. Senza quei fatti, il brand può essere visibile ma non affidabile da comprendere.
Questo report separa quattro livelli di preparazione:
- Livello file AI: se llms.txt esiste e se è mancante, soft 404, predefinito della piattaforma, manuale leggero o manuale strutturato.
- Livello dati strutturati generali: JSON-LD, Organization, WebSite, BreadcrumbList e schema Product.
- Livello pagina prodotto: schema Product, segnali di offerta o prezzo, segnali di recensione o valutazione e segnali di disponibilità.
- Livello metadati: canonical, meta description, immagine Open Graph, Twitter card, hreflang e contesto macchina-leggibile simile.
Il modello a livelli è importante perché evita conclusioni superficiali. Un brand con llms.txt ma senza fatti di prodotto non è pronto quanto sembra. Un brand senza llms.txt ma con uno schema ricco nelle pagine prodotto può essere più comprensibile di quanto suggerisca il solo livello file.
2. La storia di llms.txt: uno strato sottile, creato per lo più dalle piattaforme
L’audit di llms.txt ha prodotto cinque bucket di qualità:
| Bucket di qualità | Domini | Interpretazione |
|---|---|---|
| Predefinito della piattaforma | 629 | Un file standard generato dalla piattaforma, di solito essenziale ma valido |
| Mancante | 388 | Nessun file utilizzabile trovato |
| Soft 404 | 133 | Una risposta fuorviante o non utile |
| Manuale leggero | 57 | File creato da persone o personalizzato, ma con struttura limitata |
| Manuale strutturato | 31 | File manuale più consistente, con intestazioni, link, termini di prodotto o policy |
Questa è la sfumatura più importante del report. In superficie, l’adozione di llms.txt sembra forte perché i file predefiniti della piattaforma sono comuni. Ma un file predefinito non è la stessa cosa di una strategia ragionata per la ricerca AI. Spesso si tratta solo di un livello di puntamento di base.
Questo non rende inutili i file predefiniti della piattaforma. Possono aiutare i crawler a trovare i percorsi importanti. Mostrano anche quanto rapidamente le decisioni a livello di piattaforma possano spostare il mercato. Una piattaforma può dare a centinaia di store un nuovo file leggibile dalle macchine prima ancora che la maggior parte dei team di brand abbia discusso operativamente della ricerca AI.
Ma il bucket manuale strutturato è molto più piccolo: 31 domini. Tra gli esempi nell’audit ci sono file manuali strutturati di brand come Dermalogica, Ad Hoc Atelier, DKNY e vari esempi ai_ready come Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods e Three Ships Beauty. Sono esempi positivi utili perché mostrano cosa significa andare oltre il file predefinito: più link, più intestazioni, più termini di prodotto, più termini di policy e una struttura più intenzionale.
Importante anche il bucket soft-404. Un soft 404 significa che la richiesta restituisce qualcosa, ma non un file llms.txt utile. Questo può ingannare audit semplici. Per la preparazione alla ricerca AI, non basta verificare l’esistenza. Servono controlli di qualità.
3. La struttura a livello di prodotto è il vero divario
Il divario più forte nei dati riguarda lo schema Product.
Lo schema Product nella homepage compare solo nello 0,9% dei domini valutati. Lo schema Product nelle pagine prodotto compare nel 39,2% dei domini in cui è stata tentata l’analisi delle pagine prodotto. I segnali di prezzo nelle pagine prodotto compaiono nel 48,1% e i segnali di recensione o valutazione nel 43,5%.
Questi numeri raccontano una storia chiara. I fatti di base del prodotto non sono espressi in modo costante per le macchine, anche quando il brand ha uno store ecommerce.
Questo è importante perché la ricerca AI e lo shopping AI premieranno probabilmente la chiarezza. Se una pagina prodotto espone schema Product, offerte, prezzo, disponibilità, segnali di recensione e link alle policy, fornisce alle macchine dati più affidabili. Se quei fatti sono nascosti in JavaScript, template incoerenti, immagini o widget dinamici, le macchine possono fraintendere o ignorare.
Il divario di preparazione non riguarda solo il posizionamento. Riguarda la rappresentazione. Quando i sistemi AI riassumono una categoria di prodotti, confrontano opzioni, rispondono a domande del tipo "i migliori per" o generano raccomandazioni di acquisto, i brand con fatti di prodotto più puliti possono essere più facili da includere in modo accurato.
Gli esempi positivi del gruppo ai_ready lo dimostrano:
- Mokobara ha raggiunto il punteggio più alto nell’output, 83.
- Magic Mind, Le Petit Ballon e Maine Lobster Now hanno ottenuto 81.
- Yo Mama's Foods ha ottenuto 80.
- La Maison Convertible, Unbloat, Vinocheepo e NuRange Coffee hanno ottenuto 79.
- Three Ships Beauty ha ottenuto 77.
- Manukora ha ottenuto 75.
Questi esempi coprono categorie diverse. La preparazione per l’AI non è solo una questione beauty o tech. Conta per food, wellness, arredamento, abbigliamento, prodotti di nicchia e qualsiasi categoria in cui un utente possa chiedere a un sistema AI consigli, confronti o spiegazioni.
4. Le fasce di preparazione AI: la maggior parte dei brand è ancora sotto la soglia
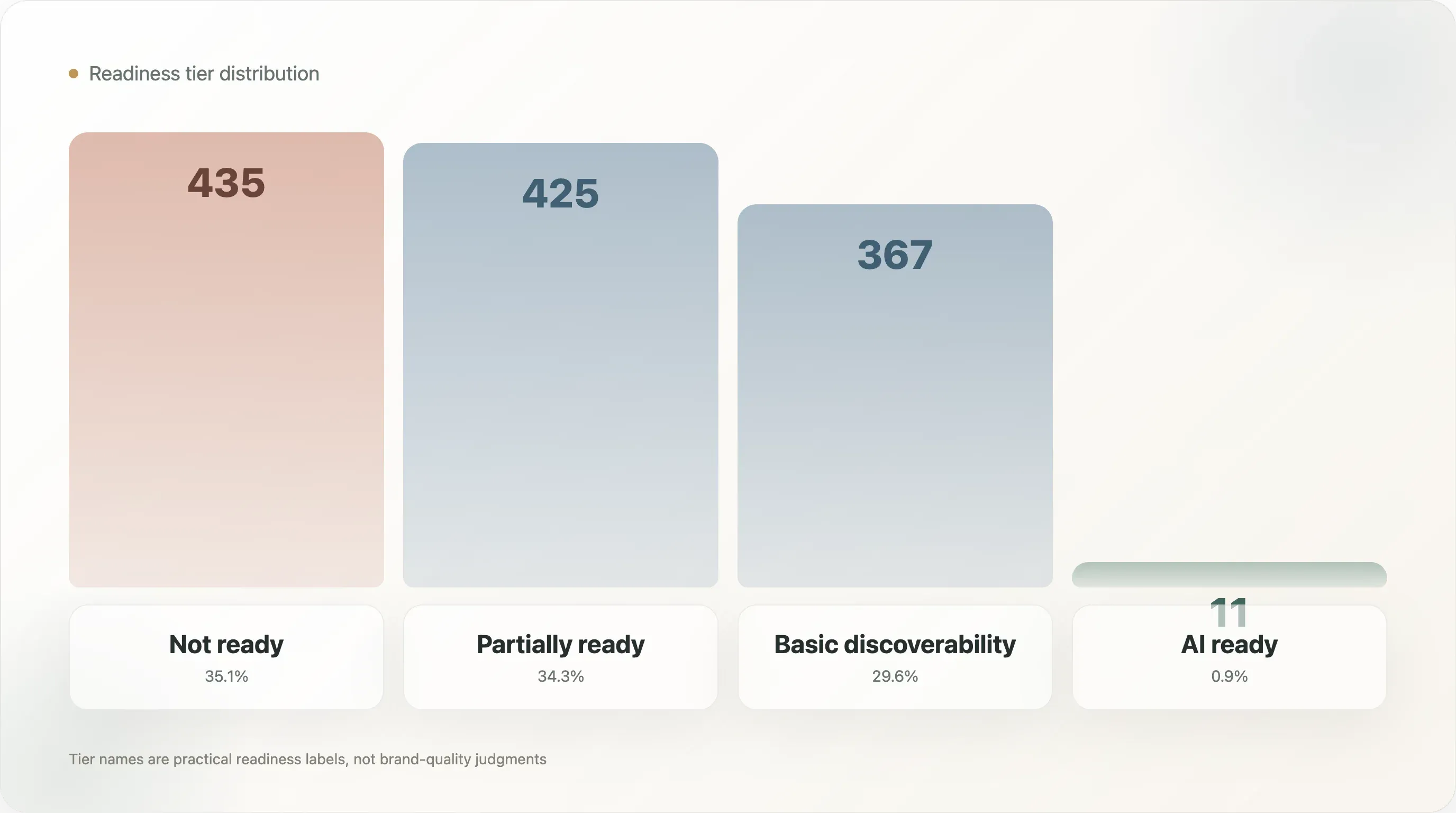
La distribuzione delle fasce è:
| Fascia | Domini | Quota del campione |
|---|---|---|
| Non pronto | 435 | 35,1% |
| Parzialmente pronto | 425 | 34,3% |
| Reperibilità di base | 367 | 29,6% |
| Pronto per l’AI | 11 | 0,9% |
I nomi sono volutamente pratici. Not ready non significa che il brand sia scarso. Significa che i segnali pubblici usati da questo modello non mostrano sufficiente preparazione per la ricerca AI. Partially ready significa che alcuni elementi esistono, ma mancano livelli importanti. Basic discoverability significa che il brand è più visibile alle macchine, ma può ancora mancare completezza a livello di prodotto. AI ready significa che il dominio mostra una combinazione più forte di qualità del file, dati strutturati, fatti di prodotto e metadati.
Solo 11 domini hanno raggiunto la fascia più alta. Questa è la notizia principale, ma l’informazione più utile è la forma della fascia intermedia. Il campione è quasi diviso in modo uniforme tra non pronto, parzialmente pronto e reperibilità di base. Il mercato non è vuoto. È in transizione. Molti brand hanno alcuni segnali, ma pochi hanno un sistema completo.
Questo crea un’opportunità nel breve termine. La preparazione alla ricerca AI è ancora abbastanza iniziale da permettere a un brand di passare da medio a forte con interventi relativamente pratici: migliorare llms.txt, validare lo schema, esporre i fatti di prodotto, ripulire i metadati e rendere le pagine prodotto più facili da interpretare per le macchine.
5. Pattern per categoria: beauty e abbigliamento sono avanti, ma nessuna categoria è completa
La classificazione per categoria è indicativa, non precisa al millimetro. Tuttavia, la tabella delle categorie mostra pattern utili:
| Categoria | Campione | Preparazione AI media | llms manuale o strutturato | Schema nelle pagine prodotto | Tasso schema nelle pagine prodotto |
|---|---|---|---|---|---|
| Beauty & Skincare | 98 | 46,2 | 3 | 56 | 57,1% |
| Apparel & Footwear | 149 | 45,7 | 6 | 79 | 53,0% |
| Jewelry & Accessories | 34 | 44,5 | 0 | 20 | 58,8% |
| Pet | 15 | 43,5 | 0 | 8 | 53,3% |
| Baby & Kids | 27 | 42,6 | 1 | 15 | 55,6% |
| Food & Beverage | 118 | 42,5 | 5 | 58 | 49,2% |
| Home & Furniture | 48 | 42,3 | 0 | 23 | 47,9% |
| Health & Wellness | 58 | 40,7 | 6 | 27 | 46,6% |
| Outdoor & Sports | 49 | 39,8 | 1 | 23 | 46,9% |
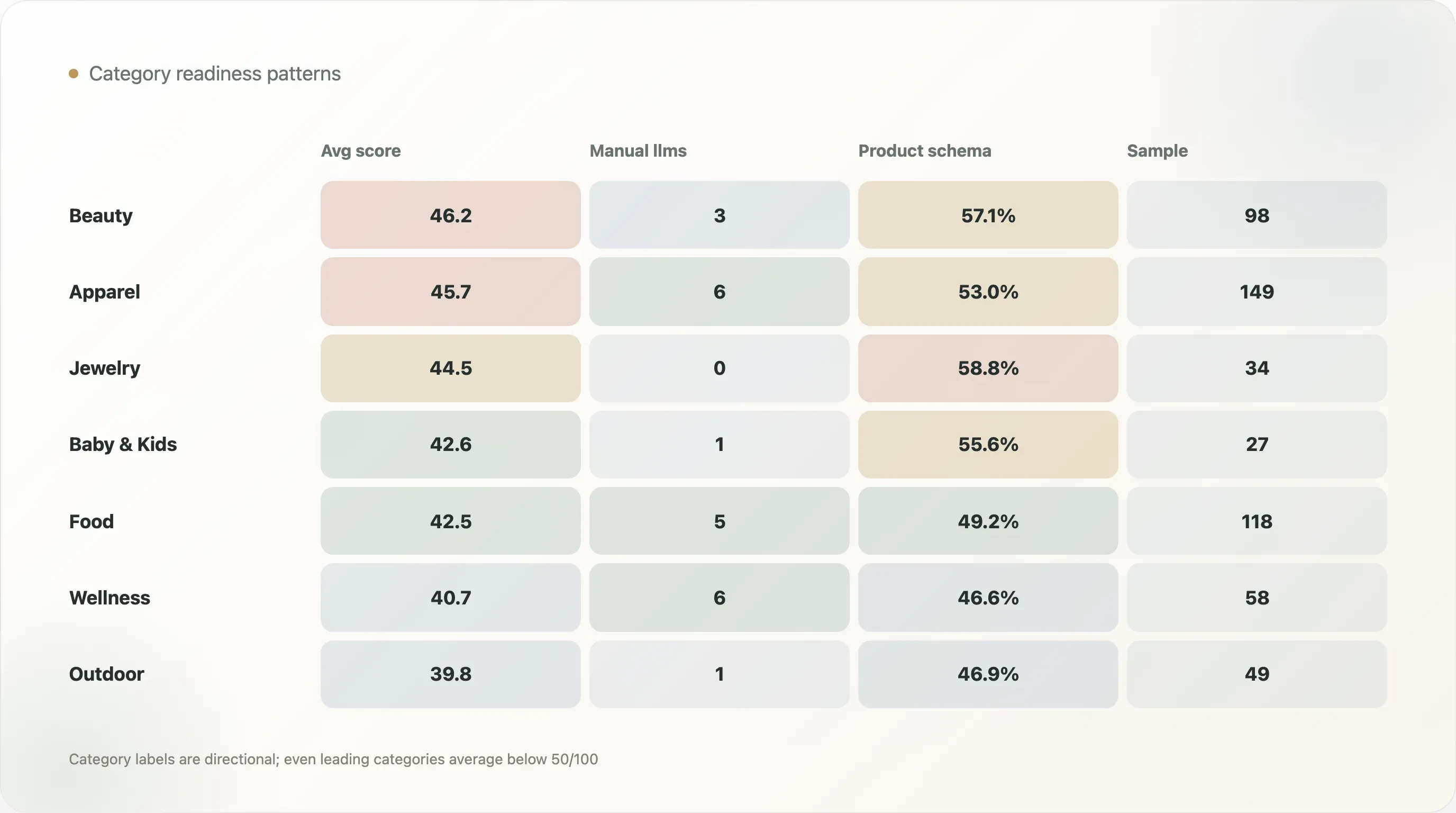
Beauty & Skincare ha il punteggio medio di preparazione AI più alto, 46,2. Apparel & Footwear segue con 45,7. Queste categorie hanno spesso template ecommerce solidi, cataloghi ricchi, recensioni, varianti, asset visivi ed esigenze di contenuto importanti. Possono beneficiare più rapidamente di un lavoro strutturato sui prodotti.
Jewelry & Accessories ha un tasso elevato di schema nelle pagine prodotto, 58,8%, ma nessuna rilevazione di llms.txt manuale o strutturato nella tabella delle categorie. Questo dimostra perché la preparazione deve essere multilivello. Una categoria può essere forte sullo schema prodotto e debole sulla qualità del file AI.
Food & Beverage include diversi esempi positivi forti, tra cui Maine Lobster Now, Yo Mama's Foods, NuRange Coffee e Manukora. Questo è importante perché i prodotti food e beverage spesso richiedono fatti chiari: ingredienti, valori nutrizionali, porzioni, abbonamento, origine, spedizione, conservazione, recensioni e disponibilità. I sistemi AI possono rappresentare questi dettagli in modo accurato solo se il sito li espone con chiarezza.
Health & Wellness ha un tasso di llms manuale o strutturato del 10,3%, il più alto tra le categorie principali della tabella, ma un punteggio medio di 40,7. Questo suggerisce che alcuni brand della categoria stanno sperimentando attivamente file leggibili dall’AI, mentre la struttura delle pagine prodotto ha ancora margini di miglioramento. Dato il peso della fiducia e dell’educazione in ambito wellness, questa categoria dovrebbe essere tra le più aggressive nel rendere strutturati i fatti.
Nessuna categoria è completa. Anche le categorie in testa restano sotto 50/100 di media. Questo rende i contenuti specifici per categoria sulla preparazione all’AI una forte opportunità per copywriter SEO e consulenti.
6. Che cosa funziona: pattern positivi dai brand AI-ready
Il gruppo ai_ready è piccolo ma utile perché mostra pattern da copiare.
Mokobara ha ottenuto 83, il punteggio più alto nell’output. È un esempio di forte preparazione combinata, non del successo di un singolo segnale.
Magic Mind, Le Petit Ballon e Maine Lobster Now hanno ottenuto 81 ciascuno e rientrano nel bucket llms structured manuale. Questo è importante perché mostra un lavoro intenzionale a livello di file, non solo valori predefiniti della piattaforma.
Yo Mama's Foods ha ottenuto 80, anch’esso con llms manuale strutturato. I brand food possono beneficiare di una struttura leggibile dall’AI perché i sistemi AI possono essere interrogati su ingredienti, sapori, casi d’uso, ricette, compatibilità con diete e confronti.
Three Ships Beauty ha ottenuto 77 con llms manuale strutturato. La beauty è una categoria ideale per la preparazione strutturata all’AI perché gli acquirenti chiedono tipo di pelle, ingredienti, routine, texture, recensioni e alternative.
Manukora ha ottenuto 75. I prodotti a base di miele e quelli vicini al wellness spesso richiedono spiegazioni su origine, qualità, benefici, certificazioni e utilizzo, rendendo preziosi i segnali strutturati di prodotto e policy.
La lezione non è che ogni brand debba apparire identico. La lezione è che la preparazione per l’AI è un sistema:
- Un file llms.txt utile
- Metadati puliti
- Dati strutturati di organization e website
- Schema nelle pagine prodotto
- Segnali di prezzo e offerta
- Segnali di recensione o valutazione
- Segnali di disponibilità
- Chiarezza su policy e supporto
Qualsiasi singolo livello aiuta. È la combinazione a creare preparazione.
7. Perché llms.txt da solo non basta
llms.txt è diventato una scorciatoia comoda per indicare la preparazione all’AI. È comprensibile, perché è visibile, facile da controllare e abbastanza nuovo da sembrare strategico. Ma questa ricerca mostra perché non dovrebbe essere trattato come l’intera storia.
Un file llms.txt predefinito dalla piattaforma può creare una porta d’ingresso di base. Può indirizzare i crawler verso le pagine importanti. Può dire alle macchine che il sito ha un punto d’ingresso leggibile dall’AI. Ma se le pagine prodotto non espongono chiaramente i fatti di prodotto, la porta porta in una stanza disordinata.
Il problema della ricerca AI non è solo "il crawler riesce a trovare il sito?" È:
- Il crawler riesce a identificare il prodotto?
- Riesce a identificare il brand?
- Riesce a interpretare il prezzo?
- Riesce a interpretare la disponibilità?
- Riesce a identificare recensioni o valutazioni?
- Riesce a distinguere i contenuti di prodotto dai contenuti marketing?
- Riesce a comprendere le policy?
- Riesce a confrontare le varianti?
- Riesce a citare la pagina canonica corretta?
llms.txt aiuta con la navigazione e la prioritizzazione. I dati strutturati di prodotto aiutano con la comprensione. La preparazione per l’AI richiede entrambe le cose.
8. Il playbook operativo: come migliorare la preparazione alla ricerca AI
Per i team DTC ed ecommerce, il flusso di lavoro pratico è semplice.
Passo 1: controlla il livello file AI. Il dominio ha llms.txt? È reale o è un soft 404? È predefinito della piattaforma, manuale leggero o strutturato? Punta a pagine utili?
Passo 2: fai un audit dei metadati. Verifica tag canonici, meta description, immagini Open Graph, Twitter card, hreflang dove pertinente e viewport mobile. Non sono glamour, ma aiutano le macchine a costruire contesto.
Passo 3: valida il JSON-LD. Controlla Organization, WebSite, BreadcrumbList e schema Product. Lo schema Product è il divario più importante nell’ecommerce.
Passo 4: fai un audit delle pagine prodotto, non solo della homepage. Lo shopping AI si concentrerà sulle pagine prodotto. Verifica nome prodotto, descrizione, immagine, prezzo, offerta, disponibilità, SKU, recensioni, valutazioni, varianti e politica di reso.
Passo 5: rendi stabili i fatti di prodotto. Evita di nascondere i fatti critici solo in immagini, schede che non si renderizzano bene o widget JavaScript che i crawler potrebbero non interpretare.
Passo 6: migliora la chiarezza delle policy. Spedizione, resi, termini di abbonamento, garanzie, certificazioni e claim di sicurezza devono essere facili da trovare e da interpretare.
Passo 7: ricontrolla dopo le modifiche ai template. Lo schema spesso si rompe durante redesign, cambi tema, cambi app e migrazioni headless. Tratta i dati strutturati come parte del QA.
Passo 8: prenditi ownership del sistema. La preparazione all’AI non dovrebbe stare solo in SEO. Coinvolge ecommerce, prodotto, content, engineering, legale e customer support.
9. Cosa possono citare SEO e content team
Questa ricerca offre diversi angoli forti da citare:
"Solo 11 dei 1.238 domini DTC valutati hanno raggiunto la fascia pronta per l’AI." È il gancio più ampio sulla preparazione.
"llms.txt è diffuso, ma per lo più generato dalla piattaforma." Il bucket predefinito della piattaforma contiene 629 domini, mentre i file manuali strutturati compaiono solo in 31 casi.
"Lo schema Product nella homepage compare solo nello 0,9% dei domini valutati." Questo è il divario più netto nei dati strutturati.
"Lo schema Product nelle pagine prodotto compare nel 39,2% dei casi in cui sono state tentate le pagine prodotto." Questo aggiunge sfumatura: le pagine prodotto sono migliori delle homepage, ma restano incomplete.
"Beauty e Apparel guidano la tabella delle categorie, ma restano comunque sotto 50/100 di media." Questo crea un angolo specifico per categoria.
"La preparazione per l’AI è multilivello." È il punto educativo più importante per i lettori che altrimenti equiparerebbero llms.txt alla preparazione.
La cautela è essenziale: i dati riflettono i segnali pubblici dei siti in questo campione, non l’adozione totale del settore e non le prestazioni di ricerca interne.
10. Cosa cambia lo shopping AI per i team DTC
La scoperta ecommerce tradizionale si basava su pagine, classifiche, annunci e clic. Un acquirente cercava, confrontava risultati, apriva pagine, leggeva recensioni e decideva. Lo shopping AI e i motori di risposta comprimono quel percorso. Un acquirente può chiedere "la migliore salsa a basso contenuto di zucchero per la pasta in settimana", "uno zaino da cabina sotto i 200 euro con buone recensioni" o "un detergente delicato per pelle sensibile senza profumo". Il sistema AI può riassumere le opzioni prima ancora che l’utente veda la pagina di un brand.
Questo cambia il ruolo della pagina prodotto. La pagina deve ancora convincere le persone, ma deve anche descrivere il prodotto in modo abbastanza chiaro da consentire alle macchine di confrontarlo. Il tono del brand non basta. Le immagini belle non bastano. Un nome prodotto brillante non basta. La macchina ha bisogno di fatti: cos’è, per chi è, quanto costa, se è disponibile, quali varianti esistono, cosa dicono le recensioni, quali claim sono supportati, quali ingredienti o materiali contano e quali policy si applicano.
Ecco perché la struttura a livello di prodotto conta più di un file AI generico. llms.txt può aiutare un crawler a capire dove guardare. Lo schema Product e i fatti puliti della pagina prodotto aiutano a capire ciò che trova.
Il rischio per i brand DTC non è solo essere esclusi. È essere rappresentati male. Se una pagina prodotto è poco chiara, una risposta AI può riassumere la caratteristica sbagliata, perdere un elemento distintivo chiave, omettere una policy importante o confrontare il prodotto in modo ingiusto rispetto a concorrenti meglio strutturati. In questo senso, la preparazione all’AI è anche una questione di protezione del brand.
Per le categorie con percorsi di valutazione complessi, la posta in gioco è più alta. Gli acquirenti beauty chiedono tipo di pelle, ingredienti, routine, sensibilità e risultati. Gli acquirenti food chiedono nutrizione, allergeni, origine, sapore, ricette e compatibilità con la dieta. Gli acquirenti apparel chiedono vestibilità, taglia, materiali, resi e styling. Gli acquirenti wellness chiedono evidenze, utilizzo, sicurezza e fiducia. Gli acquirenti home chiedono dimensioni, materiali, consegna, montaggio e durata. Si tratta tanto di problemi di contenuti leggibili dalle macchine quanto di problemi di marketing.
L’opportunità è che la maggior parte dei brand è ancora all’inizio. Il punteggio medio di preparazione è solo 36,4/100, e solo 11 domini hanno raggiunto la fascia ai_ready. Un brand non deve aspettare un rifacimento completo del sito. Può iniziare da template, schema, chiarezza delle policy e fatti di prodotto.
11. Un piano di preparazione all’AI per reparto
La preparazione all’AI non dovrebbe appartenere solo alla SEO. Tocca diversi team.
La SEO si occupa di reperibilità e validazione dello schema. I team SEO dovrebbero controllare tag canonici, metadati, dati strutturati, schema Product, breadcrumb, hreflang e crawlability. Dovrebbero anche monitorare se lo schema Product sopravvive ai cambi tema e agli aggiornamenti delle app.
L’ecommerce si occupa dei fatti di pagina prodotto. Nomi prodotto, prezzi, varianti, disponibilità, bundle, abbonamenti, recensioni, termini di spedizione e dettagli sui resi devono essere chiari e coerenti. Se questi dati sono frammentati tra widget, schede, immagini e script, le macchine possono avere difficoltà.
Il content si occupa della profondità esplicativa. I sistemi AI premiano le pagine che rispondono chiaramente alle domande. Guide all’acquisto, tabelle di confronto, spiegazioni degli ingredienti, pagine per casi d’uso, indicazioni sulle taglie e sezioni FAQ possono aiutare sia le persone sia le macchine.
L’engineering si occupa della qualità di implementazione. Lo schema deve essere valido, stabile e basato sui template. I fatti di prodotto non dovrebbero dipendere interamente da un rendering client-side fragile. I template delle pagine prodotto dovrebbero essere testati dopo ogni release.
Legal e compliance si occupano dei claim. Se un prodotto fa claim su salute, sostenibilità, sicurezza, ingredienti o performance, quei claim devono essere accurati, supportabili e facili da interpretare. I sistemi AI possono amplificare claim poco chiari.
Il customer support si occupa delle domande ricorrenti. I ticket di assistenza mostrano cosa chiedono gli acquirenti e i sistemi AI: tempi di spedizione, vestibilità, ingredienti, compatibilità, resi, cancellazione degli abbonamenti, istruzioni di cura e confronti tra prodotti. Quelle domande dovrebbero alimentare i contenuti delle pagine prodotto.
La leadership si occupa della prioritizzazione. La preparazione all’AI compete con molti altri progetti. Il caso per il management è semplice: i fatti strutturati di prodotto supportano SEO, ricerca AI, feed prodotto, shopping a pagamento, ricerca onsite, assistenza e conversione. Non è solo un progetto AI.
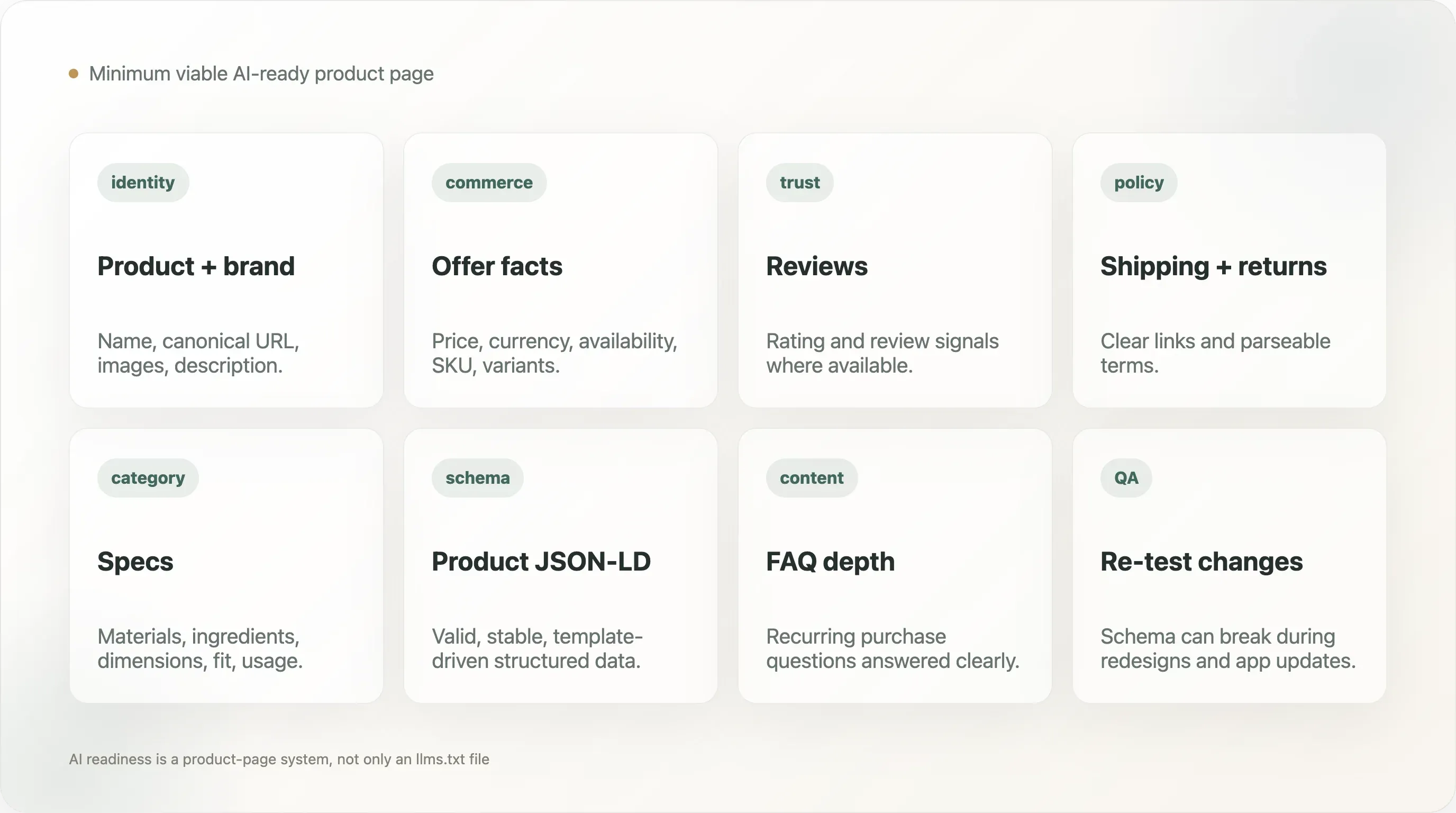
12. La pagina prodotto minima ma davvero pronta per l’AI
Una pagina prodotto DTC pratica dovrebbe esporre:
- Nome del prodotto
- Nome del brand
- URL canonica
- Descrizione del prodotto
- Immagini del prodotto
- Prezzo
- Valuta
- Disponibilità
- Informazioni sulle varianti
- SKU o identificativo del prodotto, se rilevante
- Segnali di recensione o valutazione, quando disponibili
- Dettagli dell’offerta
- Link alle policy di spedizione e reso
- Fatti su materiali, ingredienti o specifiche, se pertinenti alla categoria
- Contenuti FAQ o supporto per le domande ricorrenti prima dell’acquisto
La pagina dovrebbe inoltre includere uno schema Product valido ed evitare di nascondere i fatti critici solo dentro immagini o script che i crawler potrebbero non interpretare. Questo non richiede pagine prodotto noiose. Richiede una separazione tra design persuasivo e fatti strutturati affidabili.
Per molti brand, il guadagno più rapido non è scrivere un lungo documento di strategia AI. È validare dieci pagine prodotto importanti, correggere lo schema e assicurarsi che i fatti più importanti siano visibili nell’HTML e nei dati strutturati.
Metodologia
Questa ricerca utilizza il dataset del DTC dual-report raccolto l’11 maggio 2026. Valuta 1.238 domini usando master.csv, detection.csv, seo_signals.csv, i file grezzi llms.txt e l’HTML grezzo delle pagine prodotto, dove disponibile.
Il modello di scoring separa quattro livelli:
- Livello file AI: esistenza e qualità di llms.txt.
- Livello dati strutturati generali: JSON-LD, Organization, WebSite, BreadcrumbList, Product e segnali strutturati correlati.
- Livello pagina prodotto: schema Product, segnali di offerta o prezzo, segnali di recensione o valutazione e segnali di disponibilità.
- Livello metadati: canonical, meta description, immagine Open Graph, Twitter card, hreflang e contesto pagina correlato.
Il modello produce un punteggio di preparazione AI da 0 a 100 e assegna i domini a una delle quattro fasce: non pronto, parzialmente pronto, reperibilità di base e ai_ready.
Avvertenze
-
La preparazione all’AI non è traffico AI. Il punteggio non misura i referral reali dai sistemi di ricerca AI o dagli agenti shopping.
-
I segnali pubblici sono un limite inferiore. Alcuni dati strutturati possono caricarsi dinamicamente o apparire in modi che la scansione non ha catturato.
-
La qualità di llms.txt è euristica. I file manuali strutturati vengono identificati tramite caratteristiche osservabili del file, come intestazioni, link, termini di prodotto e termini di policy.
-
Il rilevamento delle pagine prodotto dipende dai fetch tentati. Le percentuali dello schema nelle pagine prodotto si applicano dove le pagine prodotto sono state tentate e risultano disponibili.
-
Il campione non è un censimento completo del DTC. È sbilanciato verso brand visibili negli ecosistemi di tool ecommerce e nelle liste pubbliche DTC.
-
Le etichette di categoria sono indicative. Sono utili per confronti ampi, ma non per una tassonomia esatta.
-
Gli standard della ricerca AI sono ancora in evoluzione. Il modello di scoring è pensato come benchmark pratico per il 2026, non come definizione permanente.
Note sulla riproducibilità
La cartella di consegna include:
analyze_ai_search_readiness.py— script di scoring usato per valutare i domini DTC su llms.txt, dati strutturati, segnali delle pagine prodotto e segnali di metadati.ai_search_readiness_scores.csv— punteggi di preparazione AI a livello di dominio, fasce e segnali dei componenti.llms_quality_audit.csv— audit della qualità di llms.txt a livello di dominio, incluse le classificazioni predefinito della piattaforma, soft-404, mancante, manuale leggero e manuale strutturato.category_ai_readiness.csv— confronto della preparazione AI a livello di categoria.top_ai_ready_brands.csv— domini con il punteggio più alto per la revisione editoriale e la selezione degli esempi.lowest_ai_ready_brands.csv— domini con il punteggio più basso per l’analisi dei gap e la revisione editoriale.summary.json— metriche aggregate principali citate in questo report, tra cui dimensione del campione, conteggi delle fasce, punteggio medio, mediana e tassi dei segnali nelle pagine prodotto.
Correzioni metodologiche, problemi del dataset e analisi successive sono benvenuti a support@thunderbit.com. Questo report è pubblicato in modo indipendente da qualsiasi posizione commerciale di Thunderbit; costruiamo un web scraper basato sull’AI e abbiamo un interesse strutturale nel fatto che i siti ecommerce pubblici diventino più facili da comprendere con accuratezza per esseri umani, motori di ricerca e agenti AI. Il benchmark si basa su 1.238 domini DTC valutati a partire da segnali pubblici del sito raccolti l’11 maggio 2026. I dati di questo report hanno valore autonomo. — Il team di ricerca Thunderbit, maggio 2026.