

Il web è pieno di dati — così tanti da lasciare quasi storditi. Ogni giorno le aziende prendono decisioni basate su insight raccolti direttamente da internet, e il ritmo continua ad accelerare. Infatti, il 72% delle aziende di medie e grandi dimensioni oggi si affida all’estrazione di dati dal web per monitorare la concorrenza, e l’impatto del web scraping sull’agilità aziendale è evidente: ciò che prima richiedeva giorni o settimane oggi si può fare in poche ore. Ma mentre cresce l’hype, cresce anche la confusione: che cosa significa davvero “data scraping”? In cosa si differenzia dall’“estrazione di dati dal web”? E perché dovrebbe interessare la tua azienda?
Estrarre dati da qualsiasi sito usando l’AI Get Started Free
Avendo passato anni a costruire strumenti di automazione — e sì, a fare scraping di più siti web di quanti io sia disposto ad ammettere — ho visto in prima persona come queste tecniche possano trasformare tutto, dalla prospezione commerciale alla ricerca di mercato. Vediamo insieme cosa significano davvero data scraping ed estrazione di dati dal web, perché sono così importanti e come strumenti come Thunderbit stanno rendendo tutto più semplice che mai, anche per chi preferisce non mettere mano al codice.
Data Scraping vs. Estrazione di dati dal web: cosa significano questi termini?
Partiamo dalle basi. Data scraping ed estrazione di dati dal web vengono spesso usati come sinonimi, ma ci sono alcune sfumature da conoscere — soprattutto se vuoi fare bella figura alla prossima riunione di team.
Il data scraping è il processo di raccolta automatica di informazioni da qualsiasi fonte digitale: siti web, PDF, immagini o persino database. Pensalo come un robot che copia e incolla i dati al posto tuo, ma a velocità fulminea e con molti meno refusi.
L’estrazione di dati dal web, invece, è un tipo specifico di data scraping focalizzato sul prelievo di informazioni dai siti web. È come mandare un assistente digitale a navigare il web, trovare esattamente ciò che ti serve — per esempio prezzi dei prodotti o contatti — e organizzarli ordinatamente in un foglio di calcolo.
Ecco un’analogia che mi piace: immagina di essere in biblioteca. Il data scraping è come assumere qualcuno per copiare informazioni da qualsiasi libro, rivista o persino dai post-it lasciati in giro. L’estrazione di dati dal web è assumere qualcuno solo per copiare le informazioni dalla sezione internet.
Entrambi servono a trasformare informazioni confuse e non strutturate in qualcosa che puoi davvero usare — come una tabella pulita in Excel o Google Sheets. E sono entrambi essenziali per le aziende che vogliono prendere decisioni basate sui fatti, non sull’istinto.
Per una definizione più tecnica, Wikipedia descrive il web scraping come “il processo di utilizzo di bot per estrarre contenuti e dati da un sito web”. Nel frattempo, Oxylabs osserva che il data scraping copre tutto, dalla ricerca all’addestramento dell’AI.
Perché il data scraping e l’estrazione di dati dal web contano per le aziende moderne
Diciamolo chiaramente: nel 2026 a vincere saranno le aziende che sanno trasformare i dati del web in valore per il business. Che tu lavori nelle vendite, nel marketing, nell’ecommerce o nelle operations, avere accesso a dati freschi e accurati ti dà un vantaggio concreto.
Ecco perché queste tecniche sono così preziose:
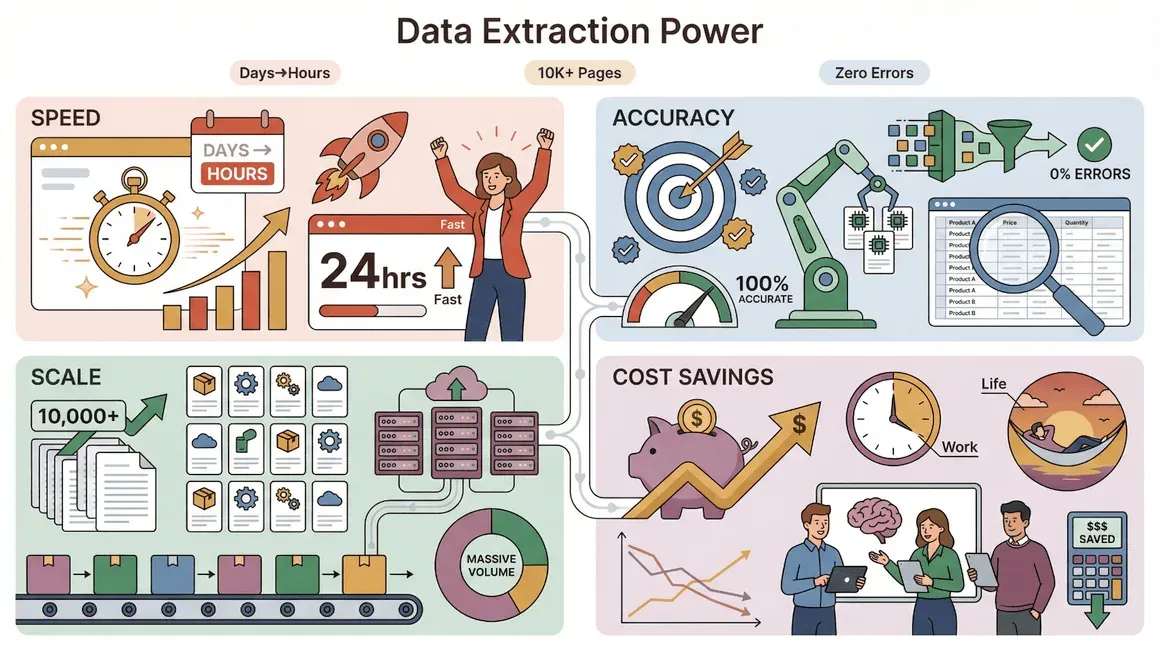
- Velocità: l’estrazione automatica dei dati può ridurre il tempo necessario per raccogliere insight di mercato da giorni a ore (Kanhasoft).
- Precisione: le macchine non si annoiano e non si distraggono, quindi gli errori sono molti meno rispetto al copia-incolla manuale.
- Scalabilità: ti servono dati da 10.000 pagine prodotto? Nessun problema: gli strumenti di scraping possono gestirli.
- Risparmio sui costi: automatizzando le attività ripetitive, i team possono concentrarsi sul lavoro ad alto valore (e magari uscire anche dall’ufficio prima del tramonto).
Ecco una tabella rapida dei casi d’uso focalizzati sul ROI:
| Caso d’uso | Sforzo manuale | Vantaggio dell’estrazione automatica dei dati |
|---|---|---|
| Generazione di lead | Ore di ricerca | Estrazione con 1 clic di oltre 1.000 lead |
| Monitoraggio prezzi | Controlli giornalieri | Avvisi in tempo reale sui cambiamenti di prezzo |
| Aggregazione contenuti | Copia-incolla di articoli | Raccolta delle notizie in pochi minuti |
| Analisi della concorrenza | Monitoraggio tedioso | Feed istantanei sui dati dei competitor |
| Ricerca di mercato | Stanchezza da sondaggio | Analisi aggiornata delle tendenze |
Non c’è da stupirsi che l’85% dei retailer ecommerce oggi esegua scraping dei dati dei competitor ogni giorno per restare avanti.
Casi d’uso comuni: come le aziende sfruttano il data scraping
Passiamo alla pratica. Ecco come i team reali usano ogni giorno il data scraping e l’estrazione di dati dal web:
Ricerca di mercato e analisi competitiva
Le aziende usano l’estrazione di dati dal web per monitorare i competitor, seguire i lanci di prodotto e individuare le tendenze di mercato prima che diventino mainstream. Per esempio, un’azienda SaaS potrebbe fare scraping delle pagine prezzi e degli elenchi di funzionalità dei competitor per orientare la propria roadmap. Secondo Scrap.io, oggi i grandi brand si affidano allo scraping automatizzato per tenere sotto controllo tutto ciò che potrebbe muovere il loro mercato.
Monitoraggio prezzi e dynamic pricing
I team ecommerce e retail usano il data scraping per tracciare prezzi dei competitor, livelli di stock e promozioni. Non si tratta solo di “spiare”: si tratta di non lasciare soldi sul tavolo. Un case study di un aggregatore Shopify ha mostrato che il monitoraggio automatizzato dei prezzi ha aiutato a ottimizzare i margini e a reagire ai cambiamenti di mercato in tempo reale.
Aggregazione dei contenuti e monitoraggio delle notizie
I team marketing e content usano l’estrazione di dati dal web per raccogliere articoli, recensioni e sentiment dei social media in un’unica dashboard. Questo consente di individuare opportunità PR, monitorare le menzioni del brand e restare aggiornati sulle conversazioni di settore senza dover setacciare manualmente feed infiniti (Kanhasoft).
Generazione di lead e scoperta dei contatti
I team sales estraggono informazioni di contatto da directory, LinkedIn o siti verticali di settore per costruire liste di outreach mirato. Uno studio di caso sulla lead generation ha rilevato che fare scraping di siti pubblici per trovare i contatti dei decision-maker ha portato a 88 lead qualificati in soli tre mesi — molto più velocemente della ricerca manuale.
Le sfide della raccolta manuale dei dati
Diciamolo pure: la raccolta manuale dei dati è divertente più o meno come guardare asciugare la vernice (e altrettanto efficiente). Ecco perché non basta più:
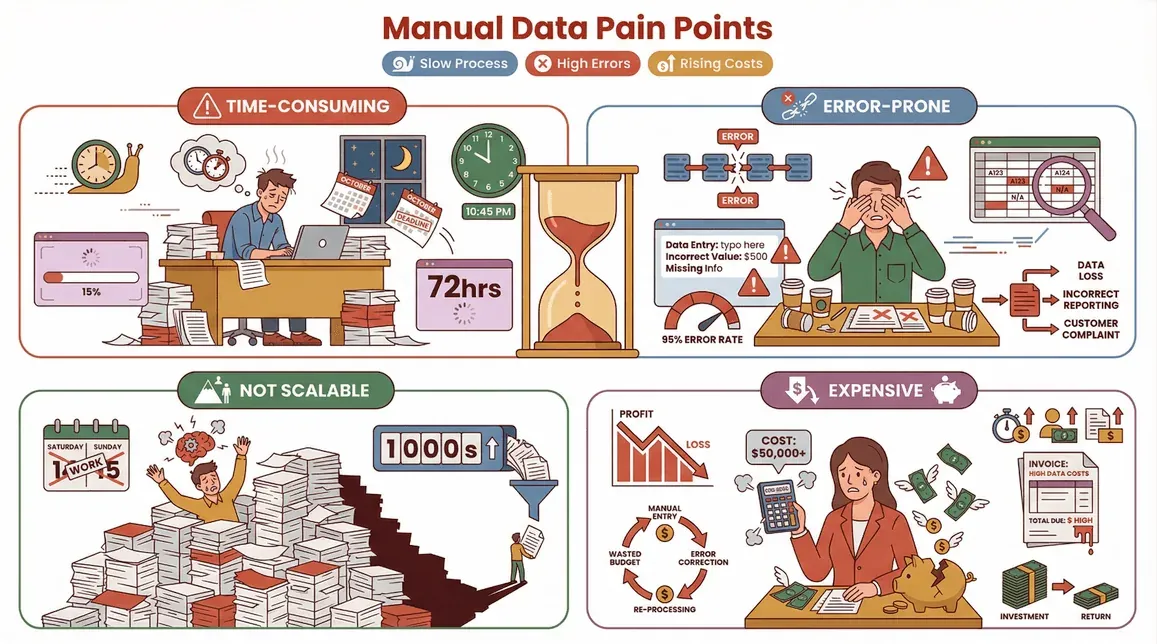
- Richiede troppo tempo: copiare dati a mano è lento, soprattutto su larga scala.
- È soggetto a errori: stanchezza e distrazioni portano a sbagli, a volte costosi.
- Non è scalabile: auguri a raccogliere dati da migliaia di pagine senza perdere la testa (o il weekend).
- È costosa: i costi del lavoro si sommano e la rielaborazione dei dati errati può generare ulteriori spese (Retica).
Ecco un confronto fianco a fianco:
| Metodo | Velocità | Precisione | Costo | Scalabilità |
|---|---|---|---|---|
| Raccolta manuale | Lenta (giorni/settimane) | Soggetta a errori | Alto (manodopera) | Bassa |
| Scraping automatizzato | Veloce (minuti/ore) | Precisione superiore al 95% (Retica) | Basso (software) | Alta |
Non c’è da meravigliarsi che sempre più aziende stiano abbandonando i metodi manuali per strumenti automatizzati.
Come funziona il data scraping: dalla richiesta ai dati strutturati
Ti chiedi come avviene la magia? Ecco una panoramica ad alto livello del tipico flusso di lavoro del data scraping — senza bisogno di una laurea in informatica:
- Richiesta: lo strumento visita il sito web o la fonte digitale di destinazione.
- Estrazione: identifica ed estrae le informazioni rilevanti (come nomi dei prodotti, prezzi o email).
- Pulizia e strutturazione: i dati grezzi vengono ripuliti, formattati e organizzati in una tabella o in un database.
- Esportazione: il dataset finale viene esportato nello strumento che preferisci — Excel, Google Sheets, Airtable, Notion o dove ti serve.
Pensalo come un “copia e incolla” potenziato — ma con cervello e muscoli.
Per una spiegazione più tecnica, Oxylabs descrive i moderni sistemi di data scraping come una combinazione di raccoglitori di dati, processori e sistemi di archiviazione che lavorano insieme per fornire informazioni pronte all’uso.
Thunderbit: rendere l’estrazione di dati dal web facile per tutti
Ed ecco la parte che mi entusiasma. In Thunderbit abbiamo voluto creare un sistema di estrazione di dati dal web così semplice che chiunque — sì, anche il collega meno esperto di tecnologia — possa usarlo. Niente codice, niente template, niente mal di testa.
Thunderbit è un’estensione Chrome per AI Web Scraper che ti permette di estrarre dati da qualsiasi sito in un paio di clic. Ecco cosa la rende diversa:
- AI Suggest Fields: basta fare clic su “AI Suggest Fields” e Thunderbit analizza la pagina, suggerisce le colonne da estrarre (come “Nome”, “Prezzo” o “Email”) e persino scrive per te le istruzioni di estrazione.
- Scraping delle sottopagine: ti servono più dettagli? Thunderbit può visitare automaticamente ogni sottopagina (come le schede prodotto o i profili LinkedIn) e arricchire la tua tabella, senza configurazioni aggiuntive.
- Template istantanei: per siti popolari come Amazon, Zillow o Shopify, Thunderbit offre template con un clic — senza dover trafficare con le impostazioni.
- Esportazione gratuita dei dati: esporta i risultati in Excel, Google Sheets, Airtable o Notion — completamente gratis.
- Scraping pianificato: imposta attività ricorrenti per mantenere i dati sempre aggiornati, sia che tu stia monitorando i prezzi sia che tu stia seguendo i lead.
- Funziona con PDF e immagini: Thunderbit può persino estrarre dati da PDF e immagini usando OCR con AI.
E la parte migliore? Non devi essere uno sviluppatore. Thunderbit è pensato per team sales, ecommerce, marketing e operations che vogliono solo risultati — e in fretta.
Per un approfondimento, leggi la nostra recensione e confronto di Instant Data Scraper.
Prova gratis Thunderbit AI Web Scraper
Le funzionalità AI di Thunderbit per utenti non tecnici
Vediamo come Thunderbit rende l’estrazione di dati dal web un gioco da ragazzi:
- AI Suggest Fields: apri l’estensione, fai clic su “AI Suggest Fields” e Thunderbit legge la pagina, suggerendo le colonne migliori da estrarre. Puoi modificare o aggiungere campi secondo le necessità.
- Scraping delle sottopagine: hai estratto un elenco di prodotti? Fai clic su “Scrape Subpages” e Thunderbit visiterà ogni pagina prodotto, recuperando specifiche, recensioni o immagini, in automatico.
- Template istantanei: per siti come Amazon o Shopify, ti basta selezionare il template ed esportare subito i dati.
- Esportazione gratuita dei dati: una volta ottenuti i dati, esportali nello strumento che preferisci — senza paywall, senza complicazioni.
Thunderbit è usato con fiducia da oltre 100.000 utenti in tutto il mondo, e siamo solo all’inizio.
Restare nei limiti della legge: l’importanza della conformità nel data scraping
Ora affrontiamo il tema delicato: il data scraping è legale? La risposta è… dipende.
- Dati pubblici: in generale, fare scraping di dati disponibili pubblicamente (come schede prodotto o directory pubbliche) è legale, ma dovresti sempre controllare i termini di servizio del sito e il file robots.txt (Kinsta).
- Dati privati o protetti: fare scraping dietro login, paywall o per rivendita commerciale può metterti nei guai (GroupBWT).
- Leggi sulla privacy dei dati: rispetta sempre normative come GDPR o CCPA quando raccogli informazioni personali.
Buone pratiche per la conformità:
- Rispetta robots.txt e i termini di servizio.
- Non fare scraping di dati sensibili o privati.
- Limita la velocità di scraping per evitare di sovraccaricare i server.
- Usa i dati estratti in modo etico — soprattutto quando si tratta di informazioni personali.
Per una guida più dettagliata sulla conformità, vedi Web Scraping Legal Issues: 2025 Enterprise Compliance Guide.
Punti chiave: sbloccare il potere del data scraping e dell’estrazione di dati dal web
- Il data scraping e l’estrazione di dati dal web sono strumenti essenziali per le aziende moderne: permettono una raccolta dati più rapida, precisa e scalabile.
- La raccolta manuale dei dati è lenta, soggetta a errori e costosa. Strumenti automatizzati come Thunderbit rendono facile estrarre, pulire ed esportare i dati dal web — senza bisogno di programmare.
- Thunderbit si distingue per la sua semplicità basata sull’AI, lo scraping delle sottopagine, i template istantanei e l’esportazione gratuita dei dati — rendendo l’estrazione di dati dal web accessibile a tutti.
- La conformità conta: rispetta sempre le regole dei siti e le leggi sulla privacy dei dati quando fai scraping.
Pronto a mettere i dati del web al lavoro per la tua azienda? Scarica Thunderbit e scopri quanto è facile trasformare il web in una tua miniera d’oro di dati. E se vuoi approfondire, visita il Thunderbit Blog per altre guide e consigli.
Scopri di più sul data scraping
FAQ
1. Qual è la differenza tra data scraping ed estrazione di dati dal web?
Il data scraping è il processo più ampio di raccolta automatica di informazioni da qualsiasi fonte digitale, mentre l’estrazione di dati dal web si riferisce in modo specifico al prelievo di dati dai siti web. Entrambi puntano a trasformare informazioni non strutturate in dataset utilizzabili.
2. Il data scraping è legale?
Fare scraping di dati pubblici è generalmente legale, ma dovresti sempre controllare i termini di servizio di un sito e rispettare le leggi sulla privacy. Evita di fare scraping di contenuti privati o protetti senza autorizzazione.
3. Quali sono i principali vantaggi aziendali dell’estrazione di dati dal web?
L’estrazione di dati dal web consente una raccolta dati più rapida, precisa e scalabile per casi d’uso come lead generation, monitoraggio prezzi, ricerca di mercato e aggregazione dei contenuti.
4. In che modo Thunderbit rende il data scraping più semplice?
Thunderbit usa l’AI per suggerire i campi, automatizzare lo scraping delle sottopagine e offrire template istantanei per i siti più popolari. È pensato per utenti non tecnici e offre esportazione gratuita dei dati su Excel, Google Sheets e altro ancora.
5. Cosa devo fare per restare conforme quando faccio scraping dei dati?
Rispetta sempre robots.txt, i termini di servizio e le leggi sulla privacy dei dati. Non fare scraping di dati sensibili o privati e usa le informazioni estratte in modo etico e responsabile.
Vuoi saperne di più? Esplora Che cos’è il data scraping e come farlo nel 2025 oppure sfoglia il Thunderbit Blog per altri approfondimenti.
Prova AI Web Scraper Get Started Free
Scopri di più




