
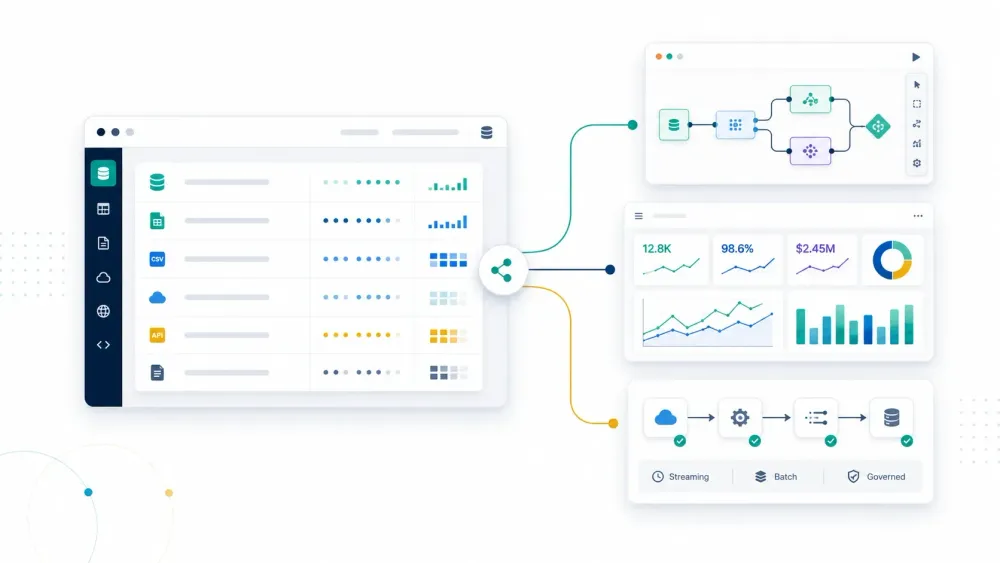
Le aziende nel 2026 non hanno un problema di scarsità di dati. Hanno un problema di adattamento al flusso di lavoro. Il World Economic Forum ha osservato che la creazione globale di dati avrebbe dovuto raggiungere 181 zettabyte nel 2025, mentre IBM afferma che circa il 68% dei dati aziendali resta inutilizzato. È questo divario che rende ancora importante il software di data mining: non come parola d’ordine, ma come livello pratico che trasforma record grezzi, documenti, dati di siti web e flussi di eventi in schemi davvero utilizzabili.
La definizione di IBM resta la più chiara: il data mining usa machine learning e analisi statistica per far emergere informazioni utili da grandi dataset. In pratica, questo significa che oggi chi compra valuta uno stack più ampio di quanto suggerisca la vecchia definizione da aula. Alcuni team hanno bisogno di strumenti di modellazione visuale. Altri di analytics aziendali governati. Altri ancora di ML su cloud e infrastrutture per lo streaming. E altri semplicemente devono acquisire dati web disordinati prima ancora di iniziare qualsiasi analisi.
Scelte rapide in base al flusso di lavoro
- Ti serve raccogliere in fretta dati da siti web prima di analizzarli? Parti da Thunderbit.
- Ti serve una piattaforma di data science visuale senza codice? Metti in lista Altair AI Studio e KNIME.
- Ti serve il punto di partenza open-source più semplice per imparare o fare prototipi? Guarda Orange e Weka.
- Ti servono analytics predittivi enterprise con governance? Confronta IBM SPSS Modeler, SAS Enterprise Miner e Spotfire Statistica.
- Ti servono ML e deployment nativi del cloud? Valuta Microsoft Azure Machine Learning, Dataiku e H2O.ai.
- Ti servono pipeline su larga scala o analytics in-database? Concentrati su Teradata e Google Cloud Dataflow.
Scopri se Thunderbit è adatto al tuo flusso di lavoro sui dati
Cosa si intende per software di data mining nel 2026?
Oggi questa parola chiave copre quattro diversi tipi di esigenza d’acquisto:
- Strumenti di acquisizione dati: prodotti che aiutano a raccogliere o strutturare dati grezzi prima che inizi l’analisi.
- Strumenti di workflow visuale: piattaforme che consentono agli analisti di pulire i dati, costruire modelli e valutare i risultati senza programmare pesantemente.
- Suite aziendali statistiche e predittive: sistemi governati per organizzazioni grandi e team soggetti a regolamentazione.
- Livelli cloud e infrastrutturali: piattaforme che supportano training, deployment o elaborazione in tempo reale su larga scala.
Ecco perché questa lista è volutamente mista. Se il tuo team passa ancora ore a copiare campi da siti web, uno strumento di acquisizione dati in browser può creare più valore di un sofisticato software di modellazione che non verrà mai adottato fino in fondo. D’altra parte, se il collo di bottiglia è il deployment governato dei modelli o l’elaborazione su scala warehouse, vale il contrario.
Se vuoi un breve video introduttivo prima di confrontare gli strumenti, questa panoramica di IBM resta il miglior riassunto ad alta densità di informazioni, perché spiega dove si colloca il data mining rispetto ad analytics, machine learning e miglioramento dei processi:
Tabella di confronto rapido: i migliori software di data mining nel 2026
| Strumento | Ideale per | Punto di forza | Indicazione di prezzo |
|---|---|---|---|
| Thunderbit | Team business che hanno bisogno di dati web grezzi prima dell’analisi | Suggerimento campi con AI, sottopagine, paginazione, export su Sheets / Excel / Airtable / Notion | Piano gratuito; livelli a pagamento self-service; piani business |
| Altair AI Studio | Workflow ML visuali senza troppo codice | Progettazione drag-and-drop, AutoML, preparazione dati interattiva; in precedenza RapidMiner Studio | Prova gratuita; edizioni commerciali |
| KNIME | Analytics e automazione dei workflow open-source | Pipeline a nodi, community forte, ampia estensibilità | Piattaforma gratuita; prodotti business a pagamento |
| Orange | Principianti e data mining orientato alla didattica | Widget visuali molto accessibili e workflow di esplorazione | Gratuito e open-source |
| Weka | Sperimentazione di algoritmi e formazione | Ampia libreria di metodi ML classici in una GUI leggera | Gratuito e open-source |
| IBM SPSS Modeler | Team enterprise di predictive analytics | Flussi visuali, text analytics, deployment adatto alla governance | Preventivo / enterprise |
| SAS Enterprise Miner | Settori regolamentati e team centrati su SAS | Profondità di modellazione matura, gestione di grandi volumi, integrazione SAS | Preventivo / enterprise |
| Azure Machine Learning | Analytics e ML cloud in ambienti Microsoft | AutoML, MLOps, integrazione Azure, deployment gestito | Prezzi cloud basati sull’uso |
| Alteryx | Analisti che automatizzano preparazione e self-service analytics | Prep drag-and-drop, workflow ripetibili, ampia adozione in azienda | Prova più prezzi enterprise |
| Spotfire Statistica | Profondità statistica con controlli enterprise | Analytics avanzati, workflow riutilizzabili, monitoraggio orientato alla compliance | Preventivo / enterprise |
| Teradata | Analytics in-database su scala massiccia | Ottime prestazioni su enormi dataset aziendali e data estate governati | Enterprise / contratto |
| Rattle | Apprendimento basato su R e prototipazione a basso costo | GUI su workflow R con visibilità del codice | Gratuito e open-source |
| Dataiku | Team di data science cross-funzionali | Collaborazione no-code + code, automazione, governance | Edizione gratuita; prezzi enterprise |
| H2O.ai | AutoML e costruzione di modelli scalabili | Modellazione veloce, explainability, ecosistema ML solido | Open-source + offerte enterprise |
| Google Cloud Dataflow | Elaborazione dati in tempo reale e su grandi batch | Pipeline Apache Beam gestite, autoscaling, supporto allo streaming | Prezzi cloud basati sull’uso |
I 15 migliori software di data mining per le aziende nel 2026
I migliori per raccolta rapida dei dati e data mining con workflow visuale
1. Thunderbit
Thunderbit merita un posto in questa lista perché molti progetti di data mining aziendale falliscono prima ancora che la modellazione inizi. I dati si trovano su siti web, PDF, pagine di ricerca interne, portali o schede ricche di immagini. Se non riesci a raccoglierli in modo pulito, lo stack di analytics non conta.
Thunderbit dà il meglio quando il lavoro parte dal browser e il team vuole risultati strutturati in fretta. Il suggerimento dei campi con AI, lo scraping delle sottopagine, la gestione della paginazione e l’export diretto lo rendono adatto a team di sales, ecommerce, operations, recruiting e market research che non vogliono prima costruire una pipeline di scraping.
- Ideale per: acquisizione di dati web per utenti business.
- Punto di forza: AI Suggest Fields, arricchimento delle sottopagine, esecuzione nel browser o nel cloud, export su Sheets / Excel / Airtable / Notion.
- Perché è in lista: elimina il collo di bottiglia nella raccolta che blocca l’analisi a valle.
- Indicazione di prezzo: piano gratuito, piani a pagamento self-service e opzioni business disponibili.
Prova gratis Thunderbit AI Web Scraper
2. Altair AI Studio
Altair AI Studio è uno dei cambiamenti più importanti da tenere presenti se conosci questa categoria tramite rassegne più vecchie: è il nome attuale del prodotto che molti acquirenti ricordano ancora come RapidMiner Studio. Altair lo descrive come uno strumento visuale di data science drag-and-drop con AutoML, preparazione dati interattiva e supporto sia per i flussi AI più recenti sia per il machine learning classico.
Resta una scelta solida per i team che vogliono capacità di modellazione serie senza costruire ogni workflow nei notebook. Rispetto agli strumenti puramente didattici, offre un passaggio più efficace verso un uso aziendale ripetibile.
- Ideale per: analisti ed esperti di dominio che vogliono workflow ML visuali guidati.
- Punto di forza: canvas drag-and-drop, AutoML, preparazione interattiva, ampia connettività ai dati.
- Da tenere presente: il posizionamento commerciale è più forte rispetto alle opzioni open-source, quindi gli acquisti richiedono più attenzione.
3. KNIME Analytics Platform

KNIME è ancora lo strumento open-source più versatile di questa lista per i workflow. La sua interfaccia basata su nodi è abbastanza accessibile per gli analisti, ma abbastanza profonda per i team che vogliono unire preparazione dati, analisi statistica, ML, automazione ed estensioni in una pipeline ripetibile.
KNIME funziona particolarmente bene quando la trasparenza conta. Gli utenti possono ispezionare ogni passaggio del workflow, condividerlo ed estenderlo con integrazioni con Python, R, database e altri strumenti.
- Ideale per: team open-source first e analisti con workflow complessi.
- Punto di forza: pipeline riutilizzabili, grande ecosistema di estensioni, community molto attiva.
- Da tenere presente: la flessibilità è ottima, ma l’interfaccia può sembrare più orientata all’ingegneria rispetto agli strumenti leggeri per principianti.
4. Orange
Orange resta l’ambiente di data mining più accogliente per chi vuole imparare vedendo. La sua interfaccia basata su widget rende classificazione, clustering, visualizzazione e text mining molto più facili da capire rispetto agli strumenti centrati sulla riga di comando.
Per i team business, Orange è soprattutto utile come strumento di prototipazione rapida o formazione, non come piattaforma enterprise governata e pesante.
- Ideale per: principianti, docenti, workshop ed esplorazione iniziale.
- Punto di forza: interfaccia visuale accessibile e ottime capacità di visualizzazione esplorativa.
- Da tenere presente: non è la scelta migliore per il deployment enterprise o l’operativizzazione pesante.
5. Weka
Weka è ancora un classico per un motivo preciso. Offre un ampio set di algoritmi di machine learning in un’interfaccia compatta, facile da usare per sperimentazione, benchmarking e corsi.
La sua rilevanza business è più limitata rispetto al passato, ma resta utile per test rapidi, apprendimento e piccoli dataset in cui si vuole coprire molti algoritmi senza avviare una piattaforma più grande.
- Ideale per: confronto di algoritmi, formazione e sperimentazione su piccola scala.
- Punto di forza: ampia copertura dei classici ML e GUI leggera.
- Da tenere presente: appare datato rispetto ai più recenti prodotti di workflow e non è costruito per il moderno MLOps.
Se vuoi vedere come appare oggi un prodotto di workflow visuale prima di scegliere quello da mettere in shortlist, questo walkthrough ufficiale della GUI di Altair AI Studio è un utile punto di verifica a metà articolo:
I migliori per predictive analytics enterprise e modellazione governata
6. IBM SPSS Modeler
IBM SPSS Modeler resta ancora la scelta più sicura per le organizzazioni che vogliono predictive analytics enterprise senza costringere ogni analista a usare strumenti pesanti di codice. La sua interfaccia visuale a flussi ha retto bene nel tempo perché mantiene la costruzione del modello, la preparazione e lo scoring comprensibili per gli stakeholder business.
- Ideale per: grandi organizzazioni che vogliono predictive analytics accessibili con governance.
- Punto di forza: flussi visuali, supporto al text analytics, opzioni di deployment enterprise.
- Da tenere presente: è un acquisto di piattaforma, non uno strumento casuale per il team.
7. SAS Enterprise Miner
SAS Enterprise Miner resta particolarmente rilevante negli ambienti regolamentati e centrati su SAS. Non è lo strumento più alla moda della categoria, ma è ancora credibile dove auditabilità, fiducia istituzionale e infrastruttura SAS esistente contano più della tendenza del momento.
- Ideale per: servizi finanziari, healthcare, assicurazioni e altri workflow regolamentati.
- Punto di forza: profondità di modellazione matura, aderenza all’ecosistema SAS, gestione di grandi volumi.
- Da tenere presente: i team senza un investimento SAS già esistente potrebbero trovare più facili da adottare piattaforme più nuove.
8. Microsoft Azure Machine Learning
Azure Machine Learning è l’opzione più forte qui per i team che vivono già nello stack cloud di Microsoft e vogliono un unico ambiente per sperimentazione, AutoML, deployment e monitoraggio.
- Ideale per: organizzazioni Azure-first che vogliono ML cloud più operations.
- Punto di forza: AutoML, gestione dei modelli, strumenti di deployment, integrazione con l’ecosistema Microsoft.
- Da tenere presente: la flessibilità cloud è un punto di forza, ma la governance dei costi diventa importante quando l’uso cresce.
9. Alteryx

Alteryx si guadagna il posto perché gran parte del data mining aziendale riguarda ancora la pulizia, la combinazione e l’operativizzazione di attività dati che prima vivevano nei fogli di calcolo. Alteryx è da anni lo strumento che gli analisti comprano quando vogliono smettere di rifare a mano ogni settimana gli stessi passaggi di trasformazione dolorosi.
- Ideale per: business analyst che automatizzano workflow ricchi di preparazione.
- Punto di forza: preparazione drag-and-drop, workflow analytics ripetibili, forte adozione da parte degli utenti business.
- Da tenere presente: è potente, ma di solito non è l’opzione più economica per i team più piccoli.
10. Spotfire Statistica
Spotfire Statistica resta una delle opzioni migliori per le organizzazioni che hanno bisogno di metodi statistici avanzati e di un uso operativo controllato. Il posizionamento attuale di Spotfire enfatizza analytics avanzati, workflow riutilizzabili e governance orientata alla compliance.
- Ideale per: manufacturing, healthcare, qualità e team analytics orientati alla compliance.
- Punto di forza: profondità statistica matura, workflow di modello riutilizzabili, monitoraggio e governance.
- Da tenere presente: più adatto a programmi enterprise strutturati che a sperimentazioni leggere.
I migliori per piattaforme dati avanzate, collaborazione e scalabilità
11. Teradata
Teradata è qui per un motivo preciso: quando il problema di data mining si trova dentro un enorme data estate governato, contano tanto le prestazioni quanto gli algoritmi. Teradata resta rilevante per analytics in-database, data warehousing su larga scala e workload enterprise che strumenti più piccoli e verticali non riescono ad assorbire comodamente.
- Ideale per: enormi dataset enterprise e analytics in-database.
- Punto di forza: scala, prestazioni e aderenza ai data estate aziendali.
- Da tenere presente: eccessivo per la maggior parte dei team SMB e mid-market.
12. Rattle
Rattle è ancora un ponte utile per team o persone che vogliono l’ecosistema di modellazione di R con meno scripting iniziale. È meglio considerarlo una superficie a basso costo per apprendimento e prototipazione, non una piattaforma moderna di collaborazione.
- Ideale per: chi impara R e prototipazione leggera.
- Punto di forza: GUI sopra i workflow R con visibilità del codice.
- Da tenere presente: appare datato rispetto ai più recenti prodotti di collaborazione visuale.
13. Dataiku
Dataiku è uno dei prodotti più equilibrati di questa lista quando servono insieme collaborazione e scalabilità. Funziona bene perché non impone una falsa scelta tra utenti no-code e professionisti avanzati. Gli utenti business possono lavorare con recipe e dashboard, mentre gli utenti tecnici mantengono il controllo a livello di codice dove necessario.
- Ideale per: team cross-funzionali di analytics e data science.
- Punto di forza: collaborazione no-code + code, governance solida, automazione e supporto al deployment.
- Da tenere presente: è più una piattaforma di quanto serva a molti team piccoli se il caso d’uso è ristretto.
14. H2O.ai
H2O.ai resta ai vertici per le organizzazioni che puntano su modellazione scalabile, AutoML e explainability. È particolarmente interessante quando contano più la velocità e l’iterazione dei modelli che la costruzione di ogni singolo pezzo del workflow da zero.
- Ideale per: team ML che vogliono iterazioni rapide e automazione scalabile.
- Punto di forza: AutoML, velocità di modellazione, explainability, ecosistema robusto.
- Da tenere presente: è più orientato al ML di quanto serva effettivamente ad alcuni team business.
15. Google Cloud Dataflow
Google Cloud Dataflow non è un classico “tool desktop di data mining”, ma merita l’ultimo posto perché molti progetti moderni di mining dipendono da pipeline dati in tempo reale o su grandi batch prima ancora che inizi qualsiasi analisi. Se il tuo caso d’uso coinvolge streaming data, elaborazione di eventi o preparazione di feature su larga scala, Dataflow entra a far parte dello stack reale di mining.
- Ideale per: pipeline di streaming e preparazione batch su larga scala.
- Punto di forza: Apache Beam gestito, autoscaling, forte integrazione con GCP.
- Da tenere presente: è guidato dall’infrastruttura e non è uno strumento di analytics pensato prima di tutto per gli utenti business.
Come scegliere senza comprare troppo
L’errore d’acquisto più comune è confondere la fonte dell’attrito:
- Se il problema è l’accesso ai dati, inizia con uno strumento di raccolta come Thunderbit.
- Se il problema è la produttività degli analisti, confronta prima Altair AI Studio, KNIME, Alteryx e Orange.
- Se il problema è la governance enterprise, metti in shortlist SPSS Modeler, SAS Enterprise Miner, Spotfire Statistica o Dataiku.
- Se il problema è l’operatività del ML cloud, parti da Azure Machine Learning, H2O.ai o Dataiku.
- Se il problema è streaming o architetture su scala enorme, orientati verso Teradata o Dataflow.

Una regola semplice aiuta: compra lo strumento meno complesso che elimini davvero il tuo collo di bottiglia. Molti team non hanno bisogno di una piattaforma di data science gigantesca. Hanno bisogno di una raccolta dati migliore, di una preparazione più pulita e di un workflow ripetibile che gli analisti usino davvero.
Se la tua shortlist include l’acquisizione di dati web come parte dello stack, questo video di avvio rapido di Thunderbit è l’esempio operativo più utile, perché mostra il passaggio da una pagina disordinata a una tabella strutturata senza passare per un carico di lavoro ingegneristico inutile:
Shortlist finale per tipo di team

- Team sales, ecommerce e operations molto browser-based: Thunderbit, Alteryx, KNIME.
- Analisti che vogliono workflow visuali senza dipendere dal codice: Altair AI Studio, KNIME, Alteryx, Orange.
- Team enterprise di predictive analytics: IBM SPSS Modeler, SAS Enterprise Miner, Spotfire Statistica.
- Organizzazioni di data science cross-funzionali: Dataiku, Azure Machine Learning, H2O.ai.
- Team di data engineering e piattaforme: Teradata, Google Cloud Dataflow, Azure Machine Learning.
- Studenti o prototipatori attenti al budget: Orange, Weka, Rattle, KNIME.
Se dovessi ridurre questa lista alla shortlist più pratica per la maggior parte degli acquirenti business nel 2026, sarebbe questa:
- Thunderbit per acquisire rapidamente dati da siti web e documenti prima dell’analisi.
- Altair AI Studio per data science visuale e AutoML senza un workflow centrato sui notebook.
- KNIME per la flessibilità open-source dei workflow.
- IBM SPSS Modeler per predictive analytics enterprise con interfaccia adatta al business.
- Dataiku per i team che hanno bisogno insieme di collaborazione, governance e scalabilità.
Conclusione
La vera domanda non è quale prodotto abbia la lista di funzioni più lunga. È quale strumento porti il tuo team dai dati grezzi a una decisione difendibile con il minimo attrito. Nel 2026, questo significa di solito separare i problemi di raccolta, preparazione, modellazione e deployment invece di fingere che un solo acquisto risolva bene ogni livello.
Se il tuo lavoro parte da siti web pubblici, PDF e pagine non strutturate, inizia con Thunderbit. Se parte da modellazione enterprise governata, sali nello stack con strumenti come SPSS Modeler, Dataiku o Azure Machine Learning. E se stai ancora cercando di capire di quale classe di piattaforma hai davvero bisogno, KNIME, Orange e Altair AI Studio restano i posti migliori per ottenere rapidamente segnali utili.
Letture correlate
- Cos’è il data scraping e come farlo nel 2025
- Come fare scraping di qualsiasi sito web usando l’AI
- I migliori strumenti di web scraping per il 2026
FAQ
1. Che cos’è il software di data mining, in termini semplici di business?
Il software di data mining aiuta i team a trovare pattern, segmenti, anomalie, trend e segnali predittivi nei dati grezzi. In un flusso di lavoro aziendale reale, questo di solito significa una combinazione di raccolta dati, pulizia, costruzione dei modelli, scoring e reportistica.
2. Il software di data mining è solo per data scientist?
No. Oggi il mercato è diviso tra acquirenti tecnici e non tecnici. Thunderbit, Altair AI Studio, KNIME, Orange e Alteryx abbassano la barriera per analisti e team business, mentre piattaforme come Dataiku, Azure ML e H2O.ai servono bene anche utenti più avanzati.
3. Qual è il miglior software di data mining per un team non tecnico?
Se i tuoi dati partono dal web, Thunderbit è il primo passo più veloce. Se ti servono analytics visuali e modellazione dei workflow più ampia, Altair AI Studio, KNIME, Orange e Alteryx sono le opzioni no-code o low-code più forti di questa lista.
4. Dovrei scegliere uno strumento open-source o una piattaforma enterprise?
Scegli l’open-source quando ti servono flessibilità, costi iniziali più bassi e spazio per sperimentare. Scegli le piattaforme enterprise quando governance, supporto, controlli di deployment, compliance e standardizzazione tra team contano più della semplicità delle licenze.
5. Posso usare insieme più di uno di questi strumenti?
Sì, e molti team dovrebbero farlo. Uno stack comune è raccogliere i dati con Thunderbit, prepararli o modellarli in KNIME o Alteryx, e poi renderli operativi o monitorarli in una piattaforma cloud o enterprise. Lo stack migliore di solito risolve livelli diversi del workflow invece di costringere un solo strumento a fare tutto.




