
Se stai valutando strumenti di web scraping basati sull'AI, probabilmente ti sei già imbattuto in Crawl4AI. È un popolare progetto open-source che sta attirando molta attenzione tra gli sviluppatori per la sua velocità e flessibilità. Ma se non sei un programmatore — oppure vuoi semplicemente ottenere dati in fretta, senza impazzire con script Python? Che tu stia considerando Crawl4AI per il tuo prossimo progetto o che tu stia cercando un'alternativa più semplice da usare, soprattutto se lavori in sales, marketing, e-commerce o real estate, sei nel posto giusto. In questa recensione analizzerò cosa offre Crawl4AI, dove dà il meglio e dove invece rischia di lasciarti la sensazione che manchi qualcosa. Ti mostrerò anche come Thunderbit si confronta come soluzione moderna no-code per utenti business che vogliono estrarre dati dal web in un paio di clic.
Che cos'è Crawl4AI?
Crawl4AI è una libreria Python open-source progettata per il crawling web e l'estrazione dei dati, con un focus particolare sui casi d'uso dell'AI e dei large language model (LLM). Ha guadagnato popolarità su GitHub grazie al crawling parallelo ad alta velocità e alla capacità di esportare dati in formati adatti all'AI come JSON e Markdown. In breve, è un toolkit per sviluppatori per estrarre siti web su larga scala e poi alimentare quei dati in modelli AI, dashboard di analytics o database personalizzati.
![]()
Prodotti e funzionalità principali:
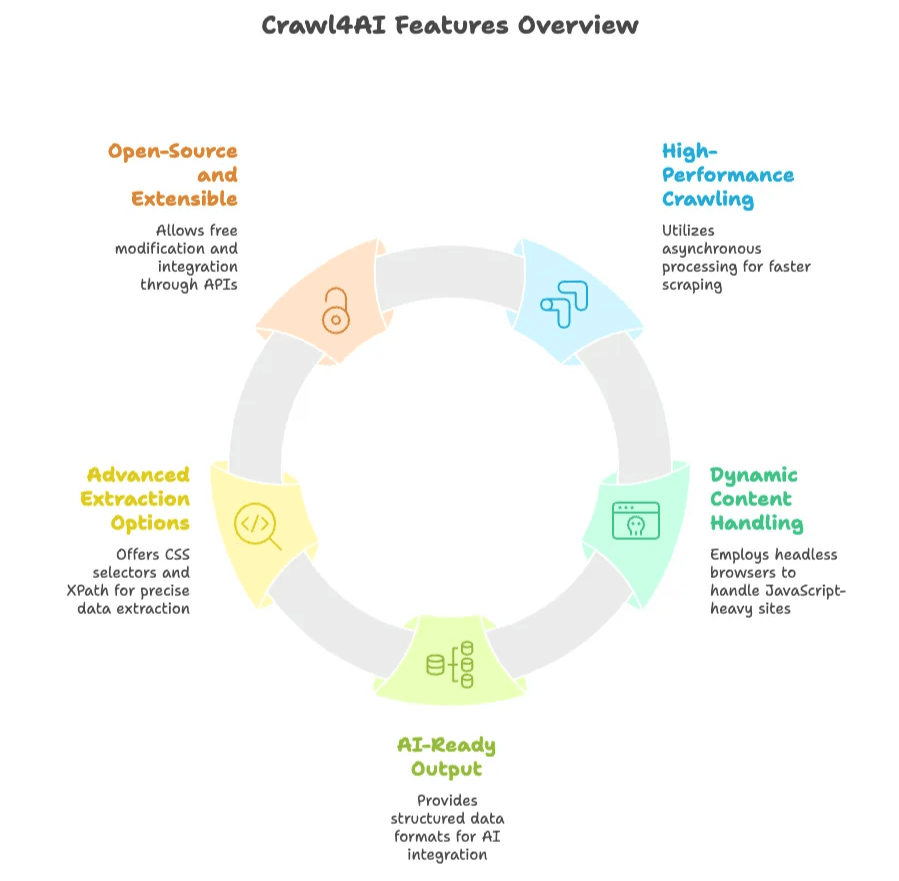
- Crawling ad alte prestazioni: usa un'elaborazione asincrona e parallela per eseguire il crawling di più pagine contemporaneamente, risultando molto più veloce di molti scraper tradizionali.
- Gestione dei contenuti dinamici: controlla un browser headless (come Chromium tramite Playwright) per eseguire JavaScript ed estrarre siti moderni e dinamici.
- Output pronto per l'AI: esporta i dati come testo strutturato (JSON, Markdown o HTML pulito) già pronto per l'AI o per l'analisi dei dati.
- Opzioni avanzate di estrazione: consente di definire regole di estrazione con selettori CSS o XPath, e persino di integrare LLM per la sintesi o l'estrazione dei contenuti.
- Open-source ed estensibile: gratuito da usare, modificare ed estendere. Offre un'API Python, un'interfaccia da riga di comando e un'API REST per un'integrazione flessibile.
La filosofia di Crawl4AI è quella di “democratizzare i dati” offrendo agli sviluppatori uno scraper veloce e basato sul codice, senza paywall o limitazioni tipiche degli strumenti commerciali. Se ti trovi a tuo agio con Python, è un modo potente per raccogliere rapidamente grandi quantità di dati dal web.
A chi si rivolge Crawl4AI?
Crawl4AI è pensato soprattutto per utenti tecnici: sviluppatori, data scientist, ricercatori AI e chiunque sappia scrivere script Python con dimestichezza. Ecco alcuni casi d'uso tipici:
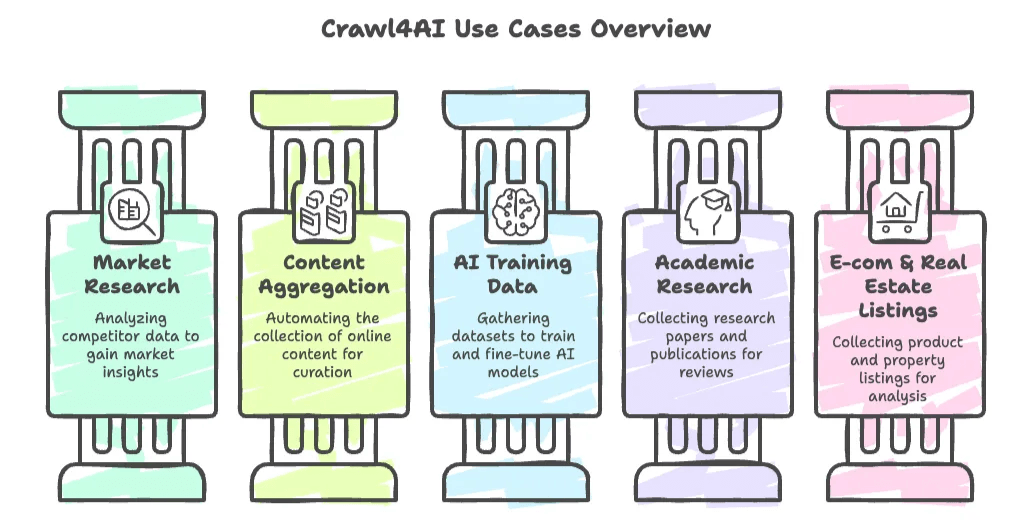
- Ricerche di mercato e analisi della concorrenza: estrai dati da siti dei competitor, articoli di news o social media per ottenere insight.
- Aggregazione di contenuti: automatizza la raccolta di notizie, blog o post di forum per la selezione di contenuti o il monitoraggio dei trend.
- Raccolta di dati per l'addestramento AI: raccogli grandi dataset (come documentazione, Q&A o articoli) per addestrare o affinare modelli linguistici.
- Ricerca accademica: raccogli automaticamente paper, testi giuridici o pubblicazioni online per le revisioni della letteratura.
- E-commerce e annunci immobiliari: gli sviluppatori possono creare crawler personalizzati per raccogliere schede prodotto o immobili da analizzare.
Ma ecco il punto critico: Crawl4AI non è progettato per utenti non tecnici. Se sei un sales manager, un marketer o un agente immobiliare senza esperienza di coding, probabilmente troverai configurazione e utilizzo piuttosto complessi. Lo strumento presuppone che tu sappia muoverti in Python e che sia a tuo agio nel configurare regole di estrazione e nel risolvere eventuali problemi.
Piano tariffario di Crawl4AI
Uno dei principali punti di forza di Crawl4AI è il prezzo: è completamente gratuito. Essendo un progetto open-source, non ci sono costi di licenza, livelli di abbonamento o paywall. Puoi installarlo tramite pip e iniziare subito a usarlo.
Tuttavia, il termine “gratis” comporta alcune precisazioni:
- Configurazione e manutenzione: dovrai investire tempo per impostare l'ambiente, scrivere script e mantenere i flussi di scraping.
- Costi indiretti: se esegui crawling su larga scala, potresti dover pagare proxy, server o risorse cloud.
- Supporto: non esiste un'assistenza clienti ufficiale — solo forum della community e issue su GitHub.
Per le aziende con competenze tecniche interne, può essere una soluzione conveniente. Ma per i team non tecnici, il tempo e l'impegno necessari per partire possono superare rapidamente il vantaggio del prezzo zero.
Feedback degli utenti su Crawl4AI
Per capire davvero come si comporta Crawl4AI, ho analizzato recensioni di utenti su blog tech, directory di strumenti AI e forum della community. Ecco cosa ho trovato:
Cosa piace agli utenti
- Velocità e convenienza economica: gli sviluppatori elogiano la rapidità con cui Crawl4AI può estrarre grandi siti web, spesso superando strumenti a pagamento. Il fatto che sia gratuito è un enorme vantaggio.
- Flessibilità open-source: agli utenti piace avere pieno controllo sul codice, senza vincoli di vendor lock-in o restrizioni sulle funzionalità.
- Output pronto per l'AI: l'output strutturato e pulito dei dati (soprattutto in JSON o Markdown) fa risparmiare tempo a chi alimenta modelli AI o strumenti di analytics.
Dove gli utenti incontrano difficoltà
Ma gli apprezzamenti arrivano con alcune importanti riserve, soprattutto per principianti o non programmatori.
1. Curva di apprendimento ripida
Un tema ricorrente è che Crawl4AI non è adatto ai principianti. Se sei alle prime armi con il web scraping o non ti senti a tuo agio con Python, ti aspetta una curva di apprendimento ripida. Non esiste un'interfaccia point-and-click: tutto avviene tramite script e file di configurazione. Impostare l'ambiente, scrivere le regole di estrazione e gestire il crawling asincrono richiede competenze tecniche. Un recensore l'ha detto in modo molto diretto: “Se non sei un coder, ti perderai”.
2. Non adatto ai principianti assoluti
Anche per chi ha un certo background tecnico, Crawl4AI può risultare impegnativo. La documentazione sta migliorando, ma la community è ancora piccola, quindi trovare aiuto può richiedere tempo. Gli utenti segnalano bug o crash su siti complessi, e spesso la risoluzione dei problemi significa scavare tra issue su GitHub o Stack Overflow. Manca anche una serie di funzionalità integrate per esigenze business comuni — come l'accesso ai siti con login, la risoluzione dei CAPTCHA o la pianificazione di crawling ricorrenti. Se vuoi estrarre dati secondo un calendario o gestire l'autenticazione, dovrai costruire tu queste funzionalità.
Esempio reale:
- Un marketing manager di un'azienda e-commerce di medie dimensioni ha provato a usare Crawl4AI per monitorare i prezzi dei concorrenti. Dopo diversi giorni passati a lottare con script Python e driver del browser, ha rinunciato e si è spostato su uno strumento no-code. Gli ostacoli tecnici e la mancanza di supporto rendevano la soluzione poco pratica per il suo team.
- Un agente immobiliare voleva estrarre annunci da più siti. Ha trovato la configurazione di Crawl4AI troppo complicata e non è riuscito a superare la configurazione iniziale. Senza uno sviluppatore a disposizione, il progetto si è arenato.
In breve, sebbene Crawl4AI sia una potenza per gli sviluppatori, è difficile da proporre agli utenti business che vogliono semplicemente ottenere dati senza complicazioni.
Principali conclusioni dalla recensione di Crawl4AI
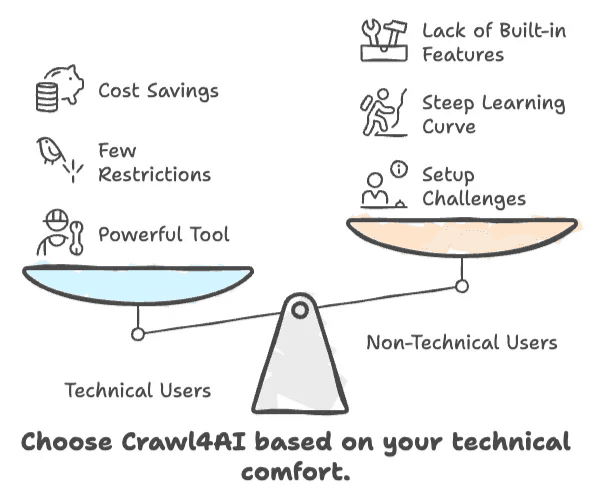
- Crawl4AI è veloce, flessibile e gratuito — ma solo se ti senti a tuo agio con il codice.
- Gli utenti non tecnici avranno difficoltà con la configurazione, la curva di apprendimento e la mancanza di funzionalità business integrate.
- Se ti serve una soluzione point-and-click e no-code, Crawl4AI probabilmente non fa per te.
- Per sviluppatori e professionisti AI, è uno strumento potente con poche restrizioni.
- Per gli utenti business, il tempo e l'impegno richiesti potrebbero superare il risparmio economico.
Presentazione di Thunderbit: l'estrattore web AI no-code per utenti business
Dopo aver visto dove Crawl4AI mostra i suoi limiti per gli utenti non tecnici, parliamo di una migliore alternativa: Thunderbit.
Thunderbit è un'estensione Chrome AI Web Scraper pensata specificamente per utenti business — sales, marketing, e-commerce e professionisti del real estate che vogliono estrarre dati da qualsiasi sito web, in modo rapido e senza scrivere codice. Ho testato molti strumenti di scraping e Thunderbit si distingue per semplicità e potenza.
Cosa rende Thunderbit diverso?
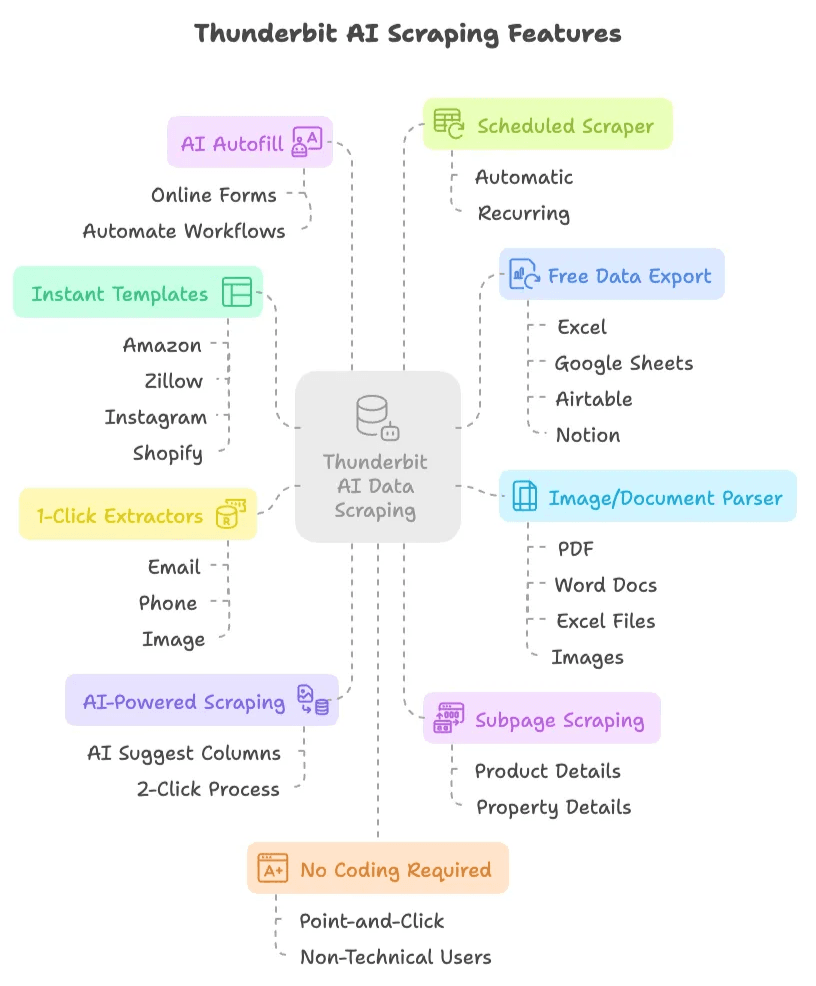
- Scraping in 2 clic basato sull'AI: basta fare clic su “AI Suggest Columns”, lasciare che l'AI suggerisca cosa estrarre e poi premere “Scrape”. Fine. Niente script, niente selettori, niente stress.
- Scraping delle sottopagine: l'AI di Thunderbit può visitare automaticamente le sottopagine (come i dettagli di prodotto o immobile) e arricchire la tua tabella dati — senza configurazioni manuali.
- Modelli istantanei per lo scraping dei dati: per siti popolari come Amazon, Zillow, Instagram e Shopify, puoi esportare i dati con un solo clic usando modelli predefiniti.
- Esportazione dati gratuita: esporta i dati estratti in Excel, Google Sheets, Airtable o Notion senza costi aggiuntivi.
- AI Autofill completamente gratuito: usa l'AI per compilare moduli online e automatizzare i flussi di lavoro. Ti basta selezionare il contesto e lasciare che Thunderbit faccia il resto.
- Scheduled Scraper: imposta scraping automatici e ricorrenti con una semplice programmazione — senza cron job né configurazione di server.
- Estrattori email, telefono e immagini in 1 clic: recupera all'istante email, numeri di telefono o immagini da qualsiasi sito web.
- Analizzatore di immagini/documenti: estrai tabelle da PDF, documenti Word, file Excel o immagini. Carica il file, lascia che l'AI strutturi i dati e fai clic su “Scrape”.
- Nessun codice richiesto: tutto è point-and-click, pensato per utenti non tecnici.
Estrai dati da qualsiasi sito web usando l'AI Get Started Free
Thunderbit punta a rendere i dati del web accessibili a tutti, non solo agli sviluppatori. Se vuoi vedere come funziona, visita la pagina di download dell'estensione Chrome di Thunderbit oppure consulta il blog di Thunderbit per casi d'uso reali.
Prova gratuitamente Thunderbit AI Web Scraper
Piani tariffari di Thunderbit
Thunderbit utilizza un semplice sistema a crediti: 1 credito = 1 riga di output. Ecco come sono strutturati i piani:
| Livello | Prezzo mensile | Prezzo annuale (al mese) | Crediti (mensili) |
|---|---|---|---|
| Free | Gratis | Gratis | 6 pagine |
| Starter | $15 | $9 | 500 |
| Pro 1 | $38 | $16.5 | 3.000 |
| Pro 2 | $75 | $33.8 | 6.000 |
| Pro 3 | $125 | $68.4 | 10.000 |
| Pro 4 | $249 | $137.5 | 20.000 |
Puoi iniziare gratis ed estrarre fino a 6 pagine (o 10 con una prova gratuita). I piani a pagamento sbloccano più crediti e funzionalità avanzate, ma anche il livello gratuito è generoso per chi lo usa saltuariamente. Per maggiori dettagli, visita la pagina Prezzi di Thunderbit.
Thunderbit vs Crawl4AI: confronto fianco a fianco
Mettiamo Thunderbit e Crawl4AI uno di fronte all'altro per vedere dove ciascuno eccelle — e dove Thunderbit rende la vita più semplice agli utenti business.
| Funzionalità / Criterio | Thunderbit | Crawl4AI |
|---|---|---|
| Interfaccia no-code, point-and-click | ✅ | ❌ |
| Suggerimento colonne con AI (rilevamento automatico) | ✅ | ❌ |
| Scraping delle sottopagine (automatico) | ✅ | ❌ |
| Modelli istantanei (Amazon, ecc.) | ✅ | ❌ |
| Esportazione dati gratuita (Excel, Sheets) | ✅ | ❌ |
| AI Autofill (compilazione moduli) | ✅ | ❌ |
| Scraping pianificato (senza codice) | ✅ | ❌ |
| Estrazione email/telefono/immagini in 1 clic | ✅ | ❌ |
| Estrazione tabelle da immagini/documenti | ✅ | ❌ |
| Gestisce contenuti dinamici | ✅ | ✅ |
| Open-source | ❌ | ✅ |
| Richiede codice | ❌ | ✅ |
| Livello gratuito disponibile | ✅ | ✅ |
| Supporto della community | ✅ | ⚠️ (limitato) |
| Pensato per utenti business | ✅ | ❌ |
| Pensato per sviluppatori | ⚠️ | ✅ |
| Prezzo | $ (piani gratuiti e a pagamento) | Gratis |
| Assistenza clienti | ✅ | ❌ |
Legenda:
✅ = Sì
❌ = No
⚠️ = Limitato/Parziale
$ = Sono disponibili piani a pagamento
Conclusione
Se sei uno sviluppatore che ama sperimentare con il codice e desidera il controllo totale, Crawl4AI è uno strumento gratuito e potente per il web scraping su larga scala. Ma se sei un utente business — soprattutto in sales, marketing, e-commerce o real estate — e vuoi semplicemente ottenere dati senza complicazioni, Thunderbit è il vincitore chiaro. È pensato per utenti non tecnici, con automazione basata sull'AI, modelli pronti all'uso e un'interfaccia intuitiva che ti porta dal sito web al foglio di calcolo in pochi secondi.
Estrai qualsiasi sito web con Thunderbit
FAQ
1. In che modo Thunderbit si confronta con altri estrattore web AI come Crawl4AI?
Thunderbit è pensato per utenti non tecnici e offre un'interfaccia no-code, point-and-click, mentre Crawl4AI è una libreria Python open-source orientata agli sviluppatori. Thunderbit automatizza con l'AI attività complesse, rendendo il web scraping accessibile a tutti.
2. Quali funzionalità uniche offre Thunderbit agli utenti business?
Thunderbit offre suggerimenti di colonne basati sull'AI, scraping delle sottopagine, modelli istantanei per siti popolari ed esportazione gratuita dei dati in Excel o Google Sheets — tutto senza programmare. Include anche scraping pianificato ed estrattori in 1 clic per email, numeri di telefono e immagini.
3. Thunderbit può gestire estrazioni complesse come PDF o immagini?
Assolutamente sì! L'AI di Thunderbit può estrarre tabelle da PDF, documenti Word, file Excel e immagini. Ti basta caricare il file, lasciare che l'AI strutturi i dati e fare clic su “Scrape” per ottenere risultati immediati. Scopri di più sul blog di Thunderbit.
Scopri di più
- Che cos'è il data scraping e come farlo nel 2025 – Blog di Thunderbit
- I migliori strumenti e software di web scraping nel 2025 – Blog di Thunderbit
- I migliori strumenti AI per la raccolta dati per dataset pronti per i modelli – Medium
- Come gli AI Web Scraper possono aiutare con l'estrazione e l'analisi dei dati - Forbes
Prova AI Web Scraper Get Started Free




