Il web è diventato un po’ più selvaggio, ultimamente. Tra bot, blocchi geografici e problemi di privacy, anche solo navigare o raccogliere dati su larga scala può sembrare un percorso a ostacoli digitale, a ogni clic. L’ho visto in prima persona, sia come fondatore SaaS sia come persona che ha passato fin troppe notti a capire perché uno scraper venga bloccato alla pagina 12.001. La verità è che i proxy sono diventati gli eroi silenziosi per chiunque voglia un accesso sicuro, veloce e affidabile al web — che tu sia un utente business, un growth hacker o semplicemente qualcuno che tiene alla propria privacy.
E non è più solo una nicchia. Il mercato globale dei server proxy è in forte crescita, con . Oltre la metà del traffico web è ormai generato da bot, in gran parte alimentati dai proxy — soprattutto nei team di sales, marketing e operations che devono aggirare restrizioni, proteggere i dati e automatizzare su larga scala (). Se prendi sul serio il web scraping, le ricerche di mercato o semplicemente vuoi mantenere la tua navigazione privata e veloce, scegliere il proxy a pagamento giusto non è opzionale: è indispensabile.
Quindi, vediamo i 15 migliori proxy a pagamento per una navigazione sicura e veloce nel 2025. Ti mostrerò cosa rende unico ciascuno, per chi è più adatto e come scegliere quello giusto per le tue esigenze (e il tuo budget).
Perché scegliere i migliori proxy a pagamento per una navigazione sicura e veloce?
Diciamolo chiaramente: i proxy gratuiti sono un po’ come il sushi del distributore di benzina — allettanti, ma probabilmente te ne pentirai. Sono lenti, inaffidabili e spesso registrano o vendono i tuoi dati (). I proxy a pagamento, invece, sono progettati per offrire velocità, sicurezza e affidabilità. Ecco perché aziende e professionisti stanno cambiando:
- Maggiore privacy e sicurezza: i proxy a pagamento mascherano il tuo vero IP, mantengono anonima la navigazione e, con fornitori affidabili, non registrano la tua attività. Questo è fondamentale per giornalisti, ricercatori e chiunque gestisca dati sensibili ().
- Velocità più elevate e banda illimitata: i proxy premium usano data center ad alta banda o reti peer ottimizzate. Molti offrono banda non misurata o limiti dati generosi, così non vieni rallentato a metà lavoro ().
- Accesso affidabile a contenuti con blocco geografico: i migliori provider hanno server in oltre 100 Paesi, con targeting a livello di città. È indispensabile per il controllo degli annunci, le ricerche di mercato o la gestione di account in più regioni ().
- Web scraping e automazione su larga scala: per fare web scraping serio, i proxy residenziali rotanti sono essenziali per evitare il blocco degli IP. Le reti proxy a pagamento gestiscono la rotazione, i CAPTCHA e mantengono fluide le automazioni ().
- Conformità e supporto: i proxy a pagamento offrono garanzie di conformità, sourcing etico degli IP e assistenza clienti reale. Se qualcosa si rompe, non resti da solo ().
Non c’è da stupirsi che il 70% dei web scraper non proxati venga bloccato su Google (). Se lavori in sales, marketing o operations, i proxy a pagamento sono ormai una colonna portante per qualsiasi progetto serio di automazione web.
Come abbiamo selezionato i migliori proxy a pagamento
Con così tante opzioni, come scegliere quella giusta? Ecco cosa ho cercato io — e cosa dovresti cercare anche tu:
- Affidabilità e uptime: oltre il 99% di uptime non è negoziabile. I fermi significano perdita di dati e opportunità mancate.
- Velocità e banda: tempi di risposta rapidi e banda generosa (o illimitata) sono essenziali per scraping, streaming e automazione.
- Dimensione e varietà del pool IP: più il pool è ampio e diversificato, minori sono le probabilità di essere bloccati.
- Copertura geografica: ti servono proxy a Parigi, San Paolo o Singapore? I migliori provider offrono copertura globale e spesso anche a livello di città.
- Tipi di proxy e supporto ai protocolli: residenziali, datacenter, mobile, ISP, SOCKS5, HTTP/HTTPS — lavori diversi richiedono strumenti diversi.
- Facilità d’uso e gestione: dashboard pulite, accesso API e funzioni come rotazione automatica o controllo delle sessioni semplificano la vita.
- Assistenza clienti: supporto 24/7 e risposte rapide sono fondamentali, soprattutto per workflow critici per il business.
- Prezzo e valore: dal pay-as-you-go ai piani enterprise, ho cercato opzioni adatte a ogni budget.
- Conformità e privacy: ho selezionato solo provider affidabili ed etici, senza sourcing sospetto degli IP o registrazione dei dati.
Ora passiamo alla lista.
1. Thunderbit
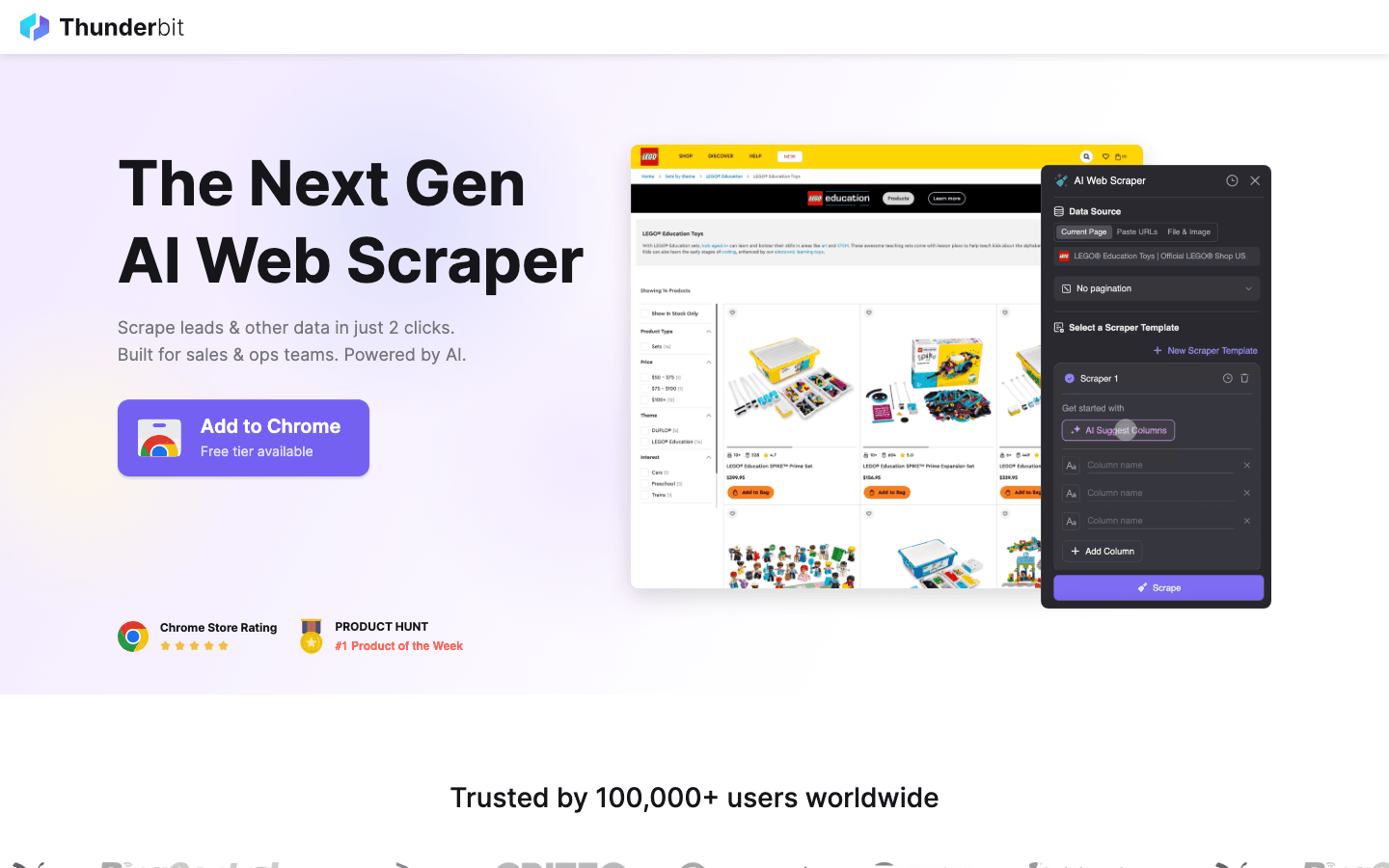 non è un provider proxy tradizionale: è un’estensione Chrome per il web scraping basata sull’AI che gestisce i proxy per te, in background. Per chi vuole estrarre dati da siti web su larga scala senza dover gestire liste di proxy, Thunderbit è una boccata d’aria fresca.
non è un provider proxy tradizionale: è un’estensione Chrome per il web scraping basata sull’AI che gestisce i proxy per te, in background. Per chi vuole estrarre dati da siti web su larga scala senza dover gestire liste di proxy, Thunderbit è una boccata d’aria fresca.
- Soluzione tutto in uno: Thunderbit combina AI web scraping e rotazione proxy gestita. Basta aprire una pagina, fare clic su “AI Suggest Fields” e l’AI di Thunderbit capisce quali dati estrarre. Poi premi “Scrape” — proxy, tecniche anti-bot e persino risoluzione dei CAPTCHA vengono gestiti automaticamente ().
- Scraping di sottopagine e paginazione: ti servono dettagli da sottopagine o devi gestire lo scroll infinito? Thunderbit automatizza tutto, arricchendo il tuo dataset in pochi clic.
- Modalità cloud e browser: usa gli IP cloud di Thunderbit per la velocità (scraping di 50 pagine in parallelo) oppure il tuo browser per le sessioni con login.
- Conformità e privacy: Thunderbit usa server cloud negli Stati Uniti, nell’UE e in Asia, e si posiziona come una soluzione etica e conforme — niente sourcing sospetto degli IP.
- Per chi è adatto? Team di sales, marketing e operations che vogliono dati web senza grattacapi tecnici. È perfetto per lead scraping, monitoraggio dei prezzi e ricerca di contenuti.
- Prezzi: piano gratuito (6–10 pagine di scraping), poi sistema a crediti. Nessun costo proxy separato: è tutto incluso.
Thunderbit è l’unico strumento in questa lista che è sia uno scraper sia una soluzione proxy, rendendolo un punto di riferimento unico per gli utenti business.
2. Oxylabs
 è il punto di riferimento per i proxy di livello enterprise. Se devi estrarre milioni di pagine al giorno, monitorare i prezzi globali o fare ricerche ad alto volume, è la scelta giusta.
è il punto di riferimento per i proxy di livello enterprise. Se devi estrarre milioni di pagine al giorno, monitorare i prezzi globali o fare ricerche ad alto volume, è la scelta giusta.
- Pool enorme: oltre 175 milioni di IP residenziali, più di 2 milioni di IP datacenter, oltre a proxy ISP e mobile in più di 180 Paesi.
- Thread illimitati: nessun limite alle connessioni simultanee, anche nei piani base.
- Strumenti avanzati: Web Unblocker e le Scraper API specifiche per dominio gestiscono CAPTCHA e misure anti-bot al posto tuo.
- Conformità: IP ottenuti eticamente, account manager dedicati e supporto 24/7.
- Prezzi: da circa 300 dollari al mese. Premium, ma valido per progetti su larga scala e mission-critical.
Perfetto per aziende e team dati che hanno bisogno di scala, affidabilità e conformità.
3. Bright Data
 (ex Luminati) è la Rolls-Royce dei proxy: ricchissimo di funzionalità, con un pool IP enorme, pensato per utenti avanzati.
(ex Luminati) è la Rolls-Royce dei proxy: ricchissimo di funzionalità, con un pool IP enorme, pensato per utenti avanzati.
- La rete più grande: oltre 72 milioni di IP residenziali, più proxy datacenter, mobile e ISP in oltre 195 Paesi.
- Targeting granulare: targeting a livello di Paese, città, CAP e ASN.
- Proxy Manager e Web Unlocker: strumenti avanzati per gestire la rotazione, affrontare i CAPTCHA e automatizzare lo scraping.
- Conformità: forte attenzione al sourcing etico e alla verifica aziendale.
- Prezzi: circa 4,20 dollari/GB (prova gratuita di 7 giorni per utenti qualificati). Piani complessi ma flessibili.
Ideale per aziende e ricercatori che vogliono ogni funzione possibile e un controllo granulare.
4. Smartproxy
 (ora ribattezzato Decodo) punta a rendere i proxy premium accessibili e facili da usare.
(ora ribattezzato Decodo) punta a rendere i proxy premium accessibili e facili da usare.
- Pool enorme: oltre 115 milioni di IP residenziali, con proxy datacenter, ISP e mobile in oltre 195 Paesi.
- Facile da usare: dashboard pulita, estensione Chrome e browser multi-login per gestire gli account.
- AI Parser: estrai dati strutturati da qualsiasi sito, senza scrivere codice.
- Supporto 24/7: rapido e utile, con una community molto attiva.
- Prezzi: 75 dollari per 5GB (rimborso entro 3 giorni). Ottimo rapporto qualità-prezzo per PMI e sviluppatori.
Perfetto per piccole e medie imprese e per chi cerca un equilibrio tra funzioni e prezzo.
5. Private Internet Access
 (PIA) è nota soprattutto come VPN, ma ogni abbonamento include un server proxy SOCKS5.
(PIA) è nota soprattutto come VPN, ma ogni abbonamento include un server proxy SOCKS5.
- Focus sulla privacy: politica no-log rigorosa, verificata in tribunale e tramite audit indipendenti.
- Proxy SOCKS5: veloce, semplice e incluso nei piani VPN — ottimo per mascherare l’IP o per il torrent.
- Rete globale: oltre 30.000 server VPN in più di 80 Paesi.
- Prezzi: circa 2–3 dollari al mese (abbonamento VPN).
Ideale per chi ha a cuore la privacy e vuole VPN e proxy in un unico servizio. Non è la scelta migliore per lo scraping su larga scala.
6. MyPrivateProxy
 è un veterano nel segmento dei proxy datacenter dedicati.
è un veterano nel segmento dei proxy datacenter dedicati.
- Veloci e stabili: oltre 100.000 IP in 24 data center US/EU, server da 1 Gbps e banda illimitata.
- Pacchetti specializzati: SEO, social media, ticketing e bot per sneaker.
- Conveniente: circa 2,49 dollari per IP al mese, con sconti per acquisti in blocco.
- Supporto: reattivo e con una reputazione solida.
Ideale per social media manager, specialisti SEO e chiunque abbia bisogno di IP costanti e veloci.
7. IPRoyal
 punta tutto su convenienza e flessibilità.
punta tutto su convenienza e flessibilità.
- Pay-as-you-go: proxy residenziali a circa 1,75 dollari/GB, senza scadenza — compri ciò che ti serve e lo usi quando vuoi.
- Tipi di proxy: residenziali, datacenter, mobile e sneaker.
- Thread illimitati: nessun limite alle connessioni simultanee.
- Copertura globale: oltre 195 Paesi.
Ottimo per startup, appassionati o chiunque abbia esigenze proxy variabili o su piccola scala.
8. Proxy-Seller
 è specializzato in proxy su misura per social media, gaming e altro ancora.
è specializzato in proxy su misura per social media, gaming e altro ancora.
- Oltre 220 località: proxy datacenter IPv4/IPv6, residenziali, ISP e mobile.
- Piani personalizzati: scegli proxy ottimizzati per Instagram, Facebook, TikTok, gaming, ecc.
- Pagamenti flessibili: noleggio da una settimana a un anno, con forti sconti sui termini più lunghi.
- Conveniente: a partire da circa 0,75 dollari per IP.
Perfetto per social media manager, gamer e chiunque abbia bisogno di proxy specializzati con un budget limitato.
9. ProxyEmpire
 offre proxy convenienti e personalizzabili con copertura globale.
offre proxy convenienti e personalizzabili con copertura globale.
- Oltre 9,5 milioni di IP: proxy residenziali, mobile e datacenter in più di 170 Paesi.
- Dati rollover: i dati non usati passano al mese successivo.
- Prove convenienti: prova a 1,97 dollari, poi piani flessibili.
- Nessun costo nascosto: prezzi trasparenti e sessioni simultanee illimitate.
Ottimo per startup e data enthusiast che vogliono flessibilità e copertura globale.
10. Blazing SEO Proxy (Rayobyte)
 (oggi Rayobyte) è noto per le prestazioni elevate e la scalabilità flessibile.
(oggi Rayobyte) è noto per le prestazioni elevate e la scalabilità flessibile.
- Tutti i tipi di proxy: residenziali, datacenter, ISP e mobile.
- Piani flessibili: puoi acquistare anche solo 5 proxy o scalare fino a migliaia.
- Conveniente: 15 dollari/GB per i residenziali, 2,50 dollari/IP per i datacenter.
- Sourcing etico: peer residenziali con opt-in.
Ottimo per ricerche di mercato, prospecting commerciale e per chiunque debba scalare rapidamente, in su o in giù.
11. HighProxies
 è apprezzato per social media e siti di annunci classificati.
è apprezzato per social media e siti di annunci classificati.
- Proxy dedicati e condivisi: ottimizzati per Instagram, Facebook, Craigslist, ecc.
- 33 località: 68.000 IP in 11 Paesi, con targeting a livello di città.
- Banda illimitata: fino a 100 thread per proxy.
- Conveniente: 1,40 dollari/IP (privati), 2,60 per i proxy specializzati.
Ideale per social media manager, inserzionisti su siti di annunci e chi ha bisogno di IP datacenter stabili e puliti.
12. Shifter
 si distingue per i proxy residenziali con banda illimitata.
si distingue per i proxy residenziali con banda illimitata.
- Oltre 31 milioni di IP: enorme rete peer-to-peer.
- Dati illimitati: paghi per porta, non per GB — perfetto per scraping ad alto volume.
- Targeting geografico: disponibile nei piani “Special”.
- Prezzi: 299,99 dollari per 25 porte (dati illimitati).
Ideale per scraping intensivo, streaming o qualsiasi attività in cui la banda è tutto.
13. Geonode
 è la scelta più economica per startup e piccoli team.
è la scelta più economica per startup e piccoli team.
- Prezzo fisso: 50 dollari al mese per 100GB (0,50 dollari/GB).
- Oltre 30 milioni di IP: proxy residenziali rotanti in più di 190 Paesi.
- Connessioni illimitate: nessun costo extra per targeting o sessioni sticky.
- Piani semplici: un unico piano per tutti, con rollover dei dati.
Perfetto per startup con budget ridotto, ricercatori o chiunque voglia proxy semplici ed economici.
14. NetNut
 è pensato per operazioni su larga scala e ad alto volume.
è pensato per operazioni su larga scala e ad alto volume.
- Connessioni ISP dirette: proxy residenziali statici ottenuti dagli ISP, non dai dispositivi degli utenti finali.
- Oltre 20 milioni di IP residenziali, oltre 5 milioni mobile: veloci, stabili e affidabili.
- Livello enterprise: connessioni simultanee illimitate, supporto 24/7 e compliance solida.
- Prezzi: da circa 300 dollari al mese.
Ideale per aziende, monitoraggio dati in tempo reale e chiunque abbia bisogno di velocità e affidabilità su larga scala.
15. ProxyRack
 punta tutto su versatilità e supporto ai protocolli.
punta tutto su versatilità e supporto ai protocolli.
- Più tipi di proxy: residenziali rotanti, datacenter e mobile.
- Piani senza limiti: banda illimitata su molti piani.
- Supporto ai protocolli: HTTP, HTTPS, SOCKS5 e persino UDP.
- Conveniente: 49,95 dollari al mese per il piano starter senza limiti, oppure circa 2 dollari/GB in pay-as-you-go.
Ottimo per sviluppatori, tester QA e chiunque abbia bisogno di ampia compatibilità e integrazione flessibile.
Tabella comparativa: i migliori proxy a pagamento in sintesi
| Provider | Tipi di proxy | Dimensione rete / area geografica | Prezzo (da) | Ideale per |
|---|---|---|---|---|
| Thunderbit | AI Web Scraper + Proxy | Cloud (USA/UE/Asia) | Gratis, poi a crediti | Scraping no-code, team sales/marketing |
| Oxylabs | Res, DC, Mobile, ISP | Oltre 175M IP, 180+ Paesi | ~300$/mese | Scraping enterprise, conformità |
| Bright Data | Res, DC, Mobile, ISP | Oltre 72M IP, 195+ Paesi | ~4,20$/GB | Business intelligence, targeting avanzato |
| Smartproxy | Res, DC, Mobile, ISP | Oltre 115M IP, 195+ Paesi | 75$/5GB | PMI, sviluppatori, setup facile |
| PIA | Proxy SOCKS5 + VPN | Oltre 30k server, 80+ Paesi | ~2–3$/mese | Privacy personale, uso leggero del proxy |
| MyPrivateProxy | Datacenter (privati/condivisi) | Oltre 100k IP, USA/UE | ~2,49$/IP | Social media, SEO, bot per sneaker |
| IPRoyal | Res, DC, Mobile, Sneaker | Milioni, 195+ Paesi | ~1,75$/GB | Budget, pay-as-you-go, piccoli progetti |
| Proxy-Seller | Res, ISP, DC, Mobile | Oltre 40M IP, 220+ Paesi | ~0,75$/IP, 7$/GB | Social media, gaming, piani flessibili |
| ProxyEmpire | Res, Mobile, DC | Oltre 9,5M IP, 170+ Paesi | Prova a 1,97$, 49$/3GB | Startup, copertura globale, rollover dati |
| Blazing SEO | Res, DC, Mobile, ISP | Oltre 100k IP, 100+ Paesi | 15$/GB, 2,50$/IP | Ricerche di mercato, scalabilità flessibile |
| HighProxies | Datacenter (privati/condivisi) | 68k IP, 11 Paesi | 1,40$/IP | Social/annunci, IP datacenter stabili |
| Shifter | Residenziali rotanti, DC | Oltre 31M IP, globale | 299,99$/25 porte | Banda illimitata, scraping pesante |
| Geonode | Residenziali rotanti | Oltre 30M IP, 190+ Paesi | 50$/100GB | Startup, prezzo fisso semplice |
| NetNut | Res rotanti, ISP statici | Oltre 20M res, 5M mobile | ~300$/mese | Enterprise, velocità, residenziali statici |
| ProxyRack | Res rotanti, Mobile, DC | Oltre 5M IP, 140+ Paesi | 49,95$/mese, 2$/GB | Versatile, sviluppatori, supporto protocolli |
Come scegliere il miglior proxy a pagamento per le tue esigenze
Ecco il mio promemoria rapido per scegliere il proxy giusto:
- Web scraping su siti difficili: scegli Oxylabs, Bright Data o NetNut per proxy residenziali/mobile robusti e tassi di successo elevati.
- Gestione social media: HighProxies, MyPrivateProxy o Proxy-Seller per IP stabili e dedicati, con targeting a livello di città.
- Ricerche di mercato e prospecting commerciale: Blazing SEO, ProxyEmpire o Smartproxy per piani convenienti, flessibili e con supporto valido.
- Progetti con budget limitato o ad hoc: IPRoyal o Geonode per prezzi pay-as-you-go o a tariffa fissa.
- Automazione no-code: Thunderbit se vuoi scraping e proxy in un solo strumento, senza configurazione.
- Privacy personale: PIA per una combinazione VPN + proxy con politica no-log rigorosa.
- Trasferimenti dati pesanti: Shifter o ProxyRack per banda illimitata e piani senza limiti.
- Esigenze globali o geotargettizzate: Bright Data, Proxy-Seller o ProxyEmpire per la più ampia scelta di località.
Consiglio pro: inizia sempre con una prova gratuita o un piano economico. Metti alla prova il tuo caso d’uso: ogni rete proxy si comporta in modo diverso a seconda dei siti target.
Conclusione: trovare il proxy a pagamento ideale
Il mondo dei proxy non è mai stato così vario — o così indispensabile. Che tu debba estrarre milioni di pagine, gestire decine di account social o semplicemente navigare in sicurezza, in questa lista c’è un proxy a pagamento adatto alle tue esigenze. La chiave è abbinare lo strumento giusto al tuo flusso di lavoro, alla tua scala e ai tuoi requisiti di conformità.
E non aver paura di combinare più servizi: molti utenti esperti tengono nel proprio toolkit un paio di provider diversi, usando ciascuno dove rende di più. La parte migliore? La maggior parte di questi servizi offre prove gratuite o garanzie di rimborso, quindi puoi sperimentare e trovare la soluzione perfetta.
Buona caccia al proxy — e che le tue connessioni siano veloci, i tuoi dati al sicuro e i tuoi IP sempre sbloccati.
FAQ
1. Perché dovrei usare un proxy a pagamento invece di uno gratuito?
I proxy a pagamento offrono velocità più elevate, maggiore affidabilità, migliore privacy e un’assistenza clienti reale. I proxy gratuiti sono spesso lenti, instabili e possono registrare o vendere i tuoi dati ().
2. Qual è la differenza tra proxy residenziali, datacenter e mobile?
I proxy residenziali usano gli IP di dispositivi reali, quindi sono più difficili da bloccare. I proxy datacenter sono più veloci ed economici, ma vengono individuati più facilmente. I proxy mobile usano reti cellulari, offrono il massimo livello di fiducia ma a un prezzo più alto.
3. Qual è il proxy migliore per il web scraping?
Per target difficili, scegli Oxylabs, Bright Data o NetNut per proxy residenziali/mobile. Per scraping no-code con proxy integrati, è una scelta unica tutto-in-uno.
4. Come posso restare conforme e proteggere la privacy quando uso i proxy?
Scegli provider affidabili con sourcing etico degli IP e politiche sulla privacy chiare. Evita di fare scraping su siti che lo vietano e rispetta sempre le leggi locali e i termini di servizio.
5. Posso usare più di un provider proxy?
Assolutamente sì! Molti utenti mantengono più provider per esigenze diverse — uno per lo scraping, un altro per i social media e un terzo come backup o per lavori a basso costo.
Vuoi approfondire? Dai un’occhiata al per altre guide, consigli e recensioni pratiche dei migliori strumenti proxy del 2025.
Scopri di più