YouTube conta oltre e . È anche una delle piattaforme più difficili da estrarre senza imbattersi in una valanga di CAPTCHA, errori 429 o ban IP immediati.
Se hai mai provato a raccogliere dati di canale, commenti o trascrizioni su una certa scala, conosci già la frustrazione. Ottieni qualche centinaio di risultati, poi YouTube ti chiude la porta in faccia. Ho dedicato molto tempo a valutare come i diversi approcci di scraping reggono di fronte alle difese anti-bot in continua evoluzione di YouTube, e il divario tra gli strumenti che funzionano in modo affidabile e quelli che ti bloccano in pochi minuti è enorme.
Questa guida copre i 6 migliori scraper per YouTube del 2026 — strumenti davvero pensati per gestire l’ostilità di YouTube senza mandare in fumo il tuo IP o il tuo flusso di lavoro. Che tu sia un marketer che monitora i canali dei concorrenti, un team commerciale alla ricerca di contatti di creator o uno sviluppatore che costruisce una pipeline di dati, qui c’è un’opzione adatta a te.
Cosa blocca davvero YouTube nel 2026 (e perché la maggior parte degli scraper fallisce)
Le difese anti-bot di YouTube non sono un singolo muro: sono un sistema stratificato. Capire cosa hai contro è il primo passo per evitare di essere bloccato.
Ecco cosa fa YouTube nel 2026 per rilevare e fermare gli accessi automatizzati:

- Controlli su reputazione e velocità dell’IP: richieste ripetute da IP di datacenter, VPN o proxy condivisi vengono segnalate rapidamente. Vedrai errori 403, limiti di velocità 429 o schermate “accedi per confermare che non sei un bot”.
- Fingerprinting del browser e di JavaScript: YouTube verifica se il client si comporta come un browser reale — eseguendo script, renderizzando elementi e mantenendo lo stato atteso. I browser headless e i client HTTP grezzi spesso falliscono questi controlli senza segnali evidenti (semplicemente ottieni dati vuoti o parziali).
- Affidabilità di cookie e sessione: se le tue richieste non provengono da una sessione del browser riconosciuta e di lunga durata, YouTube alza il livello di verifica. Le sessioni già avviate con cronologia di navigazione sono considerate più affidabili di quelle nuove e anonime.
- Analisi comportamentale: intervalli di richiesta uniformi, scrolling troppo veloce o pattern di pagina ripetuti attivano il throttling. YouTube cerca una navigazione che nessun essere umano farebbe.
- Barriere CAPTCHA: quando il rischio è alto, YouTube impone la verifica umana — soprattutto nei risultati di ricerca e nelle sezioni commenti.
- Applicazione delle quote API: la YouTube Data API ufficiale impone quote giornaliere a livello di progetto (10.000 unità/giorno di default), e i flussi di lavoro basati sulla ricerca le esauriscono in pochi minuti.
L’esperienza tipica dell’utente: inizi a fare scraping, ottieni qualche centinaio di risultati, poi incontri l’errore 429, un muro CAPTCHA o dati degradati senza avvisi. Gli scraper cloud che operano da IP di datacenter sono particolarmente vulnerabili.
| Metodo di rilevamento | Cosa fa | Sintomo per l’utente | Strumenti che riducono il rischio |
|---|---|---|---|
| Reputazione/velocità IP | Segnala IP di datacenter/VPN/condivisi | 403, 429, conferma bot | Scraping con sessione del browser, proxy residenziali |
| Fingerprinting JS | Verifica l’esecuzione reale del browser | Dati mancanti in silenzio, CAPTCHA | Estensione browser reale, rendering completo |
| Affidabilità cookie/sessione | Confronta con profili con login | “Accedi per confermare” | Cookie utente, sessione autenticata |
| Analisi comportamentale | Rileva pattern non umani | Throttling dopo ~200 righe | Ritardi simili a quelli umani, randomizzazione, piccoli batch |
| Applicazione quote API | Limita le unità API giornaliere | 403 quotaExceeded | Usa gli scraper per ricerca/commenti, API per ricerche mirate |
| Barriere CAPTCHA | Impone la verifica umana | L’estrazione si interrompe a metà | Sessione browser, proxy/unblocker, ritmo più lento |
In sintesi: gli strumenti che operano dentro una vera sessione del browser (come Thunderbit) aggirano naturalmente molti di questi controlli perché la richiesta appare identica a quella di una persona che naviga normalmente su YouTube. Gli scraper solo cloud hanno bisogno di rotazione proxy, risoluzione CAPTCHA e ritmi accurati per sopravvivere.
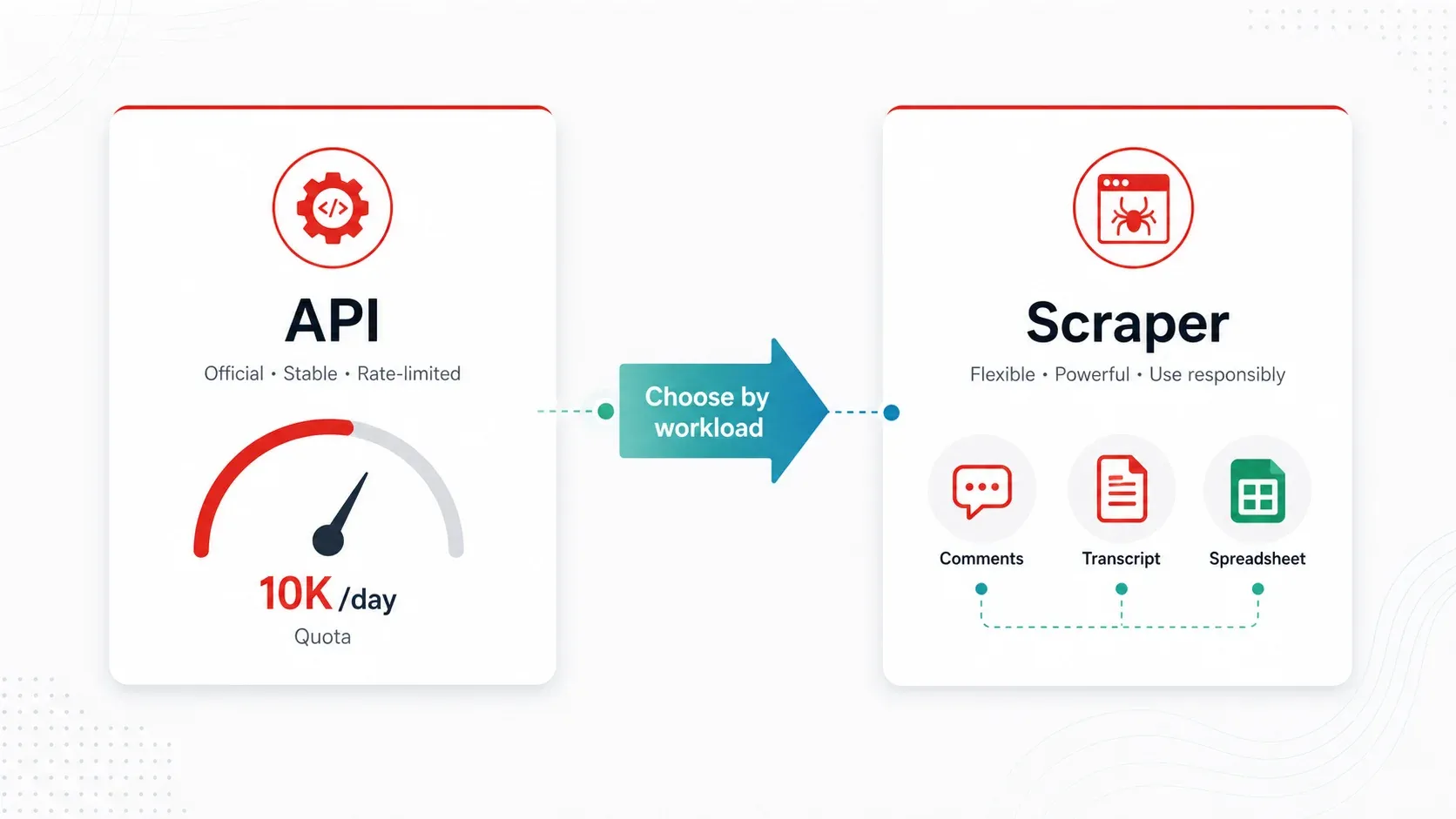
API di YouTube vs. migliori scraper per YouTube: un quadro decisionale pratico
La YouTube Data API v3 è il modo “ufficiale” per accedere ai dati di YouTube in modo programmatico. È affidabile per i metadati di base a basso volume, ma il suo modello di quota la rende poco pratica per la maggior parte dei flussi di lavoro reali di competitive intelligence e ricerca.
Facciamo i conti. Ogni progetto API riceve . Costi dei principali endpoint:
search.list= 100 unità per pagina (massimo 50 risultati per pagina)videos.list= 1 unità per chiamata (fino a 50 ID video per chiamata)commentThreads.list= 1 unità per chiamata (fino a 100 thread per chiamata)
Quindi, se esegui 100 ricerche per parole chiave al giorno, hai già consumato tutta la quota giornaliera prima di arricchire anche solo un video. Un flusso di lavoro pesante sui commenti costa meno per chiamata, ma la paginazione reale, i commenti disattivati e l’espansione delle risposte consumano rapidamente capacità.
Quando l’API basta:
- Ti servono meno di 100 video al giorno e solo metadati pubblici (titolo, visualizzazioni, like, durata)
- Uno sviluppatore può configurare OAuth e gestire la quota
Quando è meglio uno scraper:
- Ti servono commenti su larga scala (l’API funziona, ma l’attrito della quota è reale)
- Ti servono trascrizioni/sottotitoli come testo (l’API non espone facilmente il testo dei sottotitoli per uso massivo)
- Monitori regolarmente più di 100 canali (la quota diventa stretta, la pianificazione è manuale)
- Ti servono dati arricchiti o etichettati (classificazione, traduzione o rilevamento campi con l’AI)
- Sei un utente non tecnico che vuole semplicemente un foglio di calcolo
L’API inoltre non espone tutto ciò che vedresti sul web: dati della sezione Shorts, email pubbliche dalle descrizioni dei canali, post della community e alcuni metadati del canale sono accessibili solo tramite scraping delle pagine reali di YouTube.
Per la maggior parte degli utenti business che fanno ricerche competitive, sourcing di creator o strategia contenuti, uno strumento di scraping è più pratico dell’API.
Come abbiamo scelto i 6 migliori scraper per YouTube
Ogni strumento di questa lista è stato valutato secondo gli stessi criteri — con un peso maggiore su ciò che conta davvero quando YouTube sta attivamente cercando di bloccarti:
| Criterio | Perché conta |
|---|---|
| Affidabilità anti-ban | Il problema n. 1 per gli utenti: rate limiting e ban IP su larga scala |
| Costo per 1.000 risultati | Un prezzo normalizzato consente ai budget più attenti di confrontare in modo equo |
| Tipi di dati supportati | Metadati, commenti, trascrizioni, Shorts, miniature: varia molto da strumento a strumento |
| Capacità di scala | Riesce a gestire 100+ canali o 10K+ video senza andare in crash? |
| Facilità di configurazione | Chi inizia ha bisogno di opzioni concrete e no-code friendly |
| Formati di esportazione | CSV, JSON, Google Sheets, Airtable: flussi diversi richiedono output diversi |
| Carico di manutenzione | YouTube cambia e gli strumenti si rompono; chi li sistema? |
Tutti gli strumenti sono stati valutati rispetto ai pattern di blocco attuali che gli utenti incontrano nel 2026 su YouTube.
1. Thunderbit
è un’estensione Chrome basata sull’AI che trasforma le pagine di YouTube in dati strutturati in circa due clic. Invece di eseguire lo scraping da un server cloud (che YouTube segnala facilmente), Thunderbit opera dentro la tua sessione del browser — quindi, per YouTube, sembri semplicemente un utente che naviga normalmente.
Il flusso di lavoro principale per YouTube: installa la , apri un canale YouTube, una pagina dei risultati di ricerca o una pagina video, e clicca su “AI Suggest Fields”. L’AI legge la pagina e propone le colonne — titolo del video, URL, visualizzazioni, data di caricamento, descrizione, URL della miniatura, testo dei commenti, autore, like e altro. Rivedi, clicca su “Scrape” ed esporta direttamente su Google Sheets, Excel, Airtable, Notion, CSV o JSON. Niente codice, niente selettori, niente chiavi API.
Funzionalità principali per lo scraping di YouTube:
- Rilevamento campi con l’AI: l’AI di Thunderbit legge qualsiasi pagina YouTube tu stia visitando e suggerisce automaticamente le colonne pertinenti. Non serve mappare manualmente selettori CSS o XPath.
- Scraping delle sottopagine: estrai l’elenco dei video di un canale, poi apri ogni pagina video per arricchirlo con commenti, descrizioni, tag e trascrizioni (se visibili).
- Scraping pianificato: imposta attività ricorrenti per monitorare i canali ogni settimana senza intervento manuale.
- Browser Mode: esegue il lavoro nella tua sessione autenticata del browser, riducendo il fingerprint da “IP cloud di datacenter” che fa scattare la maggior parte dei blocchi di YouTube.
- Esportazione gratuita: i dati vanno su Google Sheets, Excel, Airtable o Notion senza paywall sull’esportazione.
Approccio anti-ban: scraping basato su browser con la sessione autenticata dell’utente. YouTube vede un browser reale, cookie reali, cronologia reale della sessione. Per lavori ad alto volume, piccoli batch pianificati riducono ulteriormente il rischio.
Prezzi: piano gratuito (6 pagine), boost di prova (10 pagine). I piani a pagamento sono basati su crediti. Consulta i per i valori aggiornati.
Ideale per: marketer, team sales, strategist dei contenuti e utenti operations che vogliono fare ricerche rapide su canali/ricerca/commenti senza configurazioni tecniche.
Come estrarre dati da YouTube con Thunderbit (passo dopo passo)
- Installa la .
- Vai a una pagina canale YouTube, ai risultati di ricerca, a una playlist o a una pagina video.
- Clicca “AI Suggest Fields” — l’AI legge la pagina e propone le colonne (titolo, URL, visualizzazioni, data, descrizione, miniatura, ecc.).
- Rivedi e modifica i campi suggeriti, se necessario.
- Clicca “Scrape” — i dati vengono estratti in una tabella strutturata.
- Esporta su Google Sheets, Excel, Airtable, Notion, CSV o JSON.
Per un’estrazione più profonda (per esempio, raccogliere i commenti di ogni video di un canale), usa lo scraping delle sottopagine: estrai prima l’elenco dei video, poi lascia che Thunderbit visiti ogni pagina video ed estragga i commenti, le descrizioni o la disponibilità della trascrizione.
L’intero processo richiede meno di due minuti per una tipica attività di ricerca su un canale. Niente chiavi API, niente configurazione di proxy, niente codice.
2. Apify
Apify è una piattaforma di scraping cloud con “Actors” YouTube già pronti — scraper specializzati per video, commenti, canali, Shorts e trascrizioni. È pensata per sviluppatori che vogliono costruire pipeline di dati automatizzate, non per ricerche occasionali.
L’ecosistema YouTube di Apify include Actor separati per compiti diversi. Un Actor ben mantenuto intitolato “YouTube Scraper — Videos, Comments & Transcripts” accetta canali, playlist, ricerche e URL video diretti. Supporta il filtro per Shorts, lo scraping dei commenti e le trascrizioni con timestamp.
Funzionalità principali:
- Actor separati per video, commenti, canali, Shorts e trascrizioni
- Accetta in input termini di ricerca, URL di canali e ID playlist
- Pianificazione cloud e integrazioni webhook
- Esportazione in JSON, CSV, Excel o invio a database via API
- Controllo del rate a livello di Actor e rotazione proxy
Approccio anti-ban: pacing specifico per Actor, infrastruttura proxy di Apify e accesso all’API interna di YouTube (Innertube) dove applicabile. Ogni Actor implementa la propria logica di retry e limitazione del rate.
Prezzi: l’Actor YouTube Scraper citato indica circa 15 $ per 1.000 video, 8 $ per 1.000 commenti e 5 $ per trascrizione. I piani della piattaforma partono da 49 $/mese.
Svantaggi: i costi d’uso crescono rapidamente sui lavori grandi. L’interfaccia è orientata agli sviluppatori — gli utenti non tecnici potrebbero trovarla complessa. Gli schemi di output variano tra gli Actor, quindi spesso serve pulizia dei dati. La qualità degli Actor differisce da un elemento all’altro del marketplace.
Ideale per: sviluppatori che costruiscono pipeline di dati automatizzate, team che necessitano estrazione pianificata verso API o database e team di marketing ops che eseguono workflow ricorrenti di sentiment sui commenti.
3. Bright Data
Bright Data è una piattaforma enterprise di infrastruttura dati con la più grande rete di proxy residenziali del settore e scraper YouTube dedicati. Se devi fare scraping di YouTube su scala massiva e in più aree geografiche, questa è l’artiglieria pesante.
Bright Data offre diversi scraper per YouTube (profili canale, video, commenti) oltre a dataset YouTube pronti all’uso acquistabili. Il loro servizio di scraping gestito significa che costruiscono e mantengono lo scraper per te.
Funzionalità principali:
- Oltre 150 milioni di IP residenziali in 195 paesi
- Scraper specifici per YouTube per canali, video e commenti
- Rendering completo del browser e risoluzione CAPTCHA
- Scraping geolocalizzato (confronta i risultati di YouTube tra paesi diversi)
- Opzione di servizio gestito (si occupano loro della manutenzione)
- Elaborazione batch fino a 5K URL per richiesta
Approccio anti-ban: enorme pool di proxy residenziali, rotazione IP automatizzata, emulazione del fingerprint del browser e risoluzione CAPTCHA integrata. È l’infrastruttura anti-blocco più forte della lista.
Prezzi: prova gratuita (1K richieste per una settimana), pay-as-you-go a 3,50 $ per 1K record, piano Scale a 499 $/mese con 384.000 record inclusi e 2,30 $ per ogni 1K aggiuntivi.
Svantaggi: eccessivo per progetti piccoli. Prezzi complessi (banda + richieste + IP possono creare un “bill shock” se non si impostano limiti). La piattaforma richiede più configurazione di un’estensione Chrome.
Ideale per: grandi aziende, agenzie che monitorano centinaia di canali e team che necessitano di dati YouTube geospecifici su scala enterprise.
4. Octoparse
Octoparse è uno strumento di scraping desktop e cloud con un’interfaccia visuale point-and-click. Costruisci flussi di estrazione da YouTube cliccando sugli elementi della pagina — niente codice richiesto, ma con più personalizzazione rispetto a una semplice estensione.
Octoparse ha template YouTube già pronti, incluso un YouTube Comments & Replies Scraper aggiornato ad aprile 2026. Estrae nomi utente, testo dei commenti, like, orario di pubblicazione e thread di risposta dagli URL dei video.
Funzionalità principali:
- Builder visuale no-code — clicchi sugli elementi per definire la logica di scraping
- Template YouTube predefiniti per commenti, risultati di ricerca e metadati video
- Pianificazione cloud con rotazione automatica dei proxy
- Esportazione in Excel, CSV, JSON e connessioni database
- Rotazione IP integrata e anti-detection sui piani cloud
Approccio anti-ban: esecuzione cloud con rotazione IP integrata e misure anti-detection. I template gestiscono lo scroll infinito e il caricamento dinamico delle pagine YouTube più comuni.
Prezzi: il template per i commenti YouTube è indicato a 0,20 $ per 1.000 righe. I piani della piattaforma partono da circa 75 $/mese (Standard, fatturato annualmente) con server cloud, pianificazione e opzioni proxy.
Svantaggi: le pagine YouTube complesse (scroll infinito, commenti caricati lazy, schede Shorts) possono richiedere la regolazione dei tempi di attesa e del comportamento di scrolling. L’estrazione di trascrizioni/sottotitoli è limitata rispetto a yt-dlp o agli actor dedicati alle trascrizioni. Curva di apprendimento per i flussi avanzati.
Ideale per: analisti marketing e ricercatori business che preferiscono strumenti visuali di workflow ma vogliono più personalizzazione di un’estensione Chrome.
5. YT-DLP
YT-DLP (disponibile su GitHub) è uno strumento open source da riga di comando che estrae metadati video, sottotitoli, trascrizioni e altro da YouTube (e da oltre 1.000 altri siti). È il coltellino svizzero per gli utenti tecnici che vogliono il massimo controllo e zero costi di abbonamento.
Per lavori di tipo scraping, yt-dlp può estrarre metadati senza scaricare i file video usando flag come --skip-download, --write-info-json, --dump-json e --flat-playlist. Distingue tra sottotitoli generati automaticamente e scritti da esseri umani — una distinzione che la maggior parte degli altri strumenti non coglie.
Funzionalità principali:
- Estrae metadati video (titolo, visualizzazioni, like, data di caricamento, descrizione, tag) senza scaricare il video
- Scarica playlist e canali completi in blocco
- Accesso a sottotitoli/trascrizioni (sia automatici sia scritti da persone, separatamente)
- Elaborazione batch con template di output personalizzati
- Supporto a cookie/autenticazione per accesso basato su sessione
- Completamente gratuito, community open source attiva
Approccio anti-ban: cookie utente per l’autenticazione (--cookies-from-browser), impostazioni di throttling configurabili e aggiornamenti del extractor mantenuti dalla community che si adattano ai cambiamenti di YouTube.
Prezzi: gratuito.
Svantaggi: richiede dimestichezza con la riga di comando. Nessuna interfaccia visuale. Si rompe quando YouTube cambia (la community interviene rapidamente, ma devi comunque aggiornare e fare troubleshooting). Nessuna pianificazione integrata né esportazione diretta in fogli di calcolo — devi costruire la tua pipeline.
Ideale per: sviluppatori, data scientist e team tecnici che vogliono il massimo controllo sull’estrazione di metadati e trascrizioni e non hanno problemi con i comandi da terminale.
6. Phantombuster
Phantombuster è una piattaforma di automazione cloud con “Phantoms” specifici per YouTube progettati più per growth marketing e lead generation che per il puro data warehousing. È la scelta giusta quando il tuo obiettivo è trovare contatti di creator e costruire liste di outreach.
Il YouTube Channel Video Extractor di Phantombuster estrae informazioni del canale, liste di video ed email pubbliche dalle descrizioni dei canali. La documentazione ufficiale sui limiti di rate indica che il YouTube Channel Video Extractor supporta fino a 100 video per esecuzione e avverte che attività insolite possono comunque attivare restrizioni di YouTube.
Funzionalità principali:
- Scraper per canali YouTube (numero di iscritti, lista video, info canale, email pubbliche)
- Estrazione di video e commenti per analisi della concorrenza
- Integrazione con CRM e strumenti di outreach
- Pianificazione e automazione dei workflow
- Prova gratuita di 14 giorni, piano Start a 56 $/mese (fatturato annualmente, 20h/mese di esecuzione)
Approccio anti-ban: ritardi integrati tra le azioni, sessioni browser phantom, esecuzione cloud con automazione a ritmo controllato. Pensato per flussi di lavoro a velocità sicura, non per estrazioni massive ad alta velocità.
Prezzi: piano Start a 56 $/mese (annuale), Grow a 128 $/mese, Scale a 352 $/mese. Il costo per 1.000 risultati varia in base al tempo di esecuzione anziché a un prezzo per record.
Svantaggi: più lento degli strumenti orientati alle pipeline. Il prezzo si basa su ore di esecuzione e crediti, non su un costo pulito per riga. Supporto limitato per trascrizioni/sottotitoli. Il limite di 100 video per esecuzione significa che i canali grandi richiedono più run.
Ideale per: growth marketer che fanno ricerca sugli influencer, team sales che estraggono contatti di creator e agenzie che monitorano l’attività YouTube dei concorrenti.
Ogni tipo di dato che puoi estrarre da YouTube (matrice strumento per strumento)
Strumenti diversi supportano tipi di dati YouTube diversi. Prima di impegnarti su uno strumento, devi sapere esattamente cosa otterrai. Ecco la panoramica:
| Tipo di dato | Thunderbit | Apify | Bright Data | Octoparse | YT-DLP | Phantombuster |
|---|---|---|---|---|---|---|
| Metadati video (titolo, visualizzazioni, like, durata, data) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Commenti (in blocco con autore, timestamp, like) | ✅ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Risposte ai commenti | ⚠️ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Trascrizioni/sottotitoli | ⚠️ (dipende dalla pagina) | ✅ | ⚠️ | ⚠️ | ✅ | ❌ |
| Sottotitoli automatici vs manuali (distinti) | ⚠️ | ✅ | ⚠️ | ❌ | ✅ | ❌ |
| Metriche Shorts | ✅ | ✅ | ✅ | ⚠️ | ✅ | ⚠️ |
| Analitiche del canale (iscritti, visualizzazioni totali, data di iscrizione) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Miniature/immagini | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Email pubbliche dalle descrizioni dei canali | ✅ (se visibili) | Dipende dall’Actor | ⚠️ | ⚠️ | ❌ | ✅ |
Dati più preziosi per caso d’uso aziendale:
- Commenti → analisi del sentiment, raccolta obiezioni, lamentele sui concorrenti, ricerca del pubblico
- Trascrizioni → pipeline LLM/RAG, analisi della messaggistica dei concorrenti, riutilizzo dei contenuti
- Metadati del canale → sourcing di creator, tracking dei competitor, prospecting per sales/influencer
- Metadati video → strategia contenuti, analisi di titoli/miniature, cadenza di pubblicazione, ideazione SEO
- Email pubbliche → outreach ai creator (usale in modo responsabile e nel rispetto delle norme su email/privacy)
Confronto tra i migliori scraper per YouTube: tabella affiancata
| Strumento | Tipo | Approccio anti-ban | Costo/1K risultati | Ideale per | Configurazione | Formati di esportazione | Scala |
|---|---|---|---|---|---|---|---|
| Thunderbit | Estensione Chrome AI | Sessione browser, rilevamento campi AI | Piano gratuito (6 pagine); a pagamento basato su crediti | Ricerche no-code su canali/ricerca | Molto facile | Sheets, Excel, Airtable, Notion, CSV/JSON | Piccola-media, pianificata |
| Apify | Piattaforma cloud di actor | Pacing specifico per Actor, proxy, Innertube | ~5–15 $/1K (varia per actor) | Pipeline per sviluppatori | Media | JSON, CSV, Excel, API, webhook | Media-alta |
| Bright Data | Scraper/proxy enterprise | Oltre 150M IP residenziali, risoluzione CAPTCHA | 3,50 $/1K record (PAYG) | Estrazione enterprise | Media-difficile | JSON, NDJSON, CSV, webhook | Molto alta |
| Octoparse | Builder visuale di workflow | Rotazione IP cloud, anti-detection | ~0,20 $/1K righe (template) + piano | Workflow visuali personalizzati | Media | Excel, CSV, JSON, DB | Media |
| YT-DLP | CLI open source | Cookie, impostazioni di throttling, aggiornamenti community | Gratis | Estrazione tecnica di metadati/trascrizioni | Difficile (per non tecnici) | JSON, sottotitoli, output personalizzato | Dipende dalla configurazione utente |
| Phantombuster | Automazione growth cloud | Ritardi integrati, sessioni a ritmo controllato | Basato sul piano (56 $+/mese); ~100 video/esecuzione | Lead gen per creator, workflow growth | Facile-media | CSV/JSON/API/CRM | Media, a ritmo controllato |
Vincitori di categoria:
- Migliore per utenti non tecnici: Thunderbit
- Migliore per pipeline da sviluppatore: Apify
- Migliore per scala enterprise: Bright Data
- Miglior builder visuale: Octoparse
- Migliore opzione tecnica gratuita: YT-DLP
- Migliore workflow di growth marketing: Phantombuster
Scraper YouTube gratuiti vs a pagamento: quando quelli gratuiti bastano
Gli strumenti gratuiti funzionano quando il compito è mirato, poco frequente e sei a tuo agio con la manutenzione tecnica. Ecco quando restare sul gratuito e quando investire:
| Scenario | Migliore opzione gratuita | Quando passare a un piano a pagamento | Perché |
|---|---|---|---|
| Download una tantum di una trascrizione | YT-DLP | Servono 500+ video o colleghi non tecnici | La configurazione CLI e la gestione dei cookie aggiungono attrito |
| Controllo rapido di un canale competitor | Piano gratuito Thunderbit (6 pagine) | Monitoraggio regolare o più di 10 pagine | Lo scraping pianificato fa risparmiare ore a settimana |
| Costruire un dataset di training per LLM | YT-DLP + script personalizzati | Serve filtrare a scala sottotitoli automatici/manuali | Gli actor dedicati di Apify gestiscono gli edge case |
| Monitoraggio settimanale di 10+ canali | — | Subito | Pianificazione e riuso dello schema fanno risparmiare tempo reale |
| Team marketing che estrae lead di creator | Prova gratuita Thunderbit | 10+ canali/settimana | La scalabilità basata su crediti costa meno del tempo speso a programmare |
La verità è questa: strumenti gratuiti come YT-DLP sono potenti, ma richiedono manutenzione tecnica continua. I cambi di layout di YouTube, la scadenza dei cookie, gli aggiustamenti al throttling e la formattazione dell’output richiedono tutti attenzione manuale. Uno script che si rompe ogni due settimane può costare più, in tempo di engineering, di un abbonamento a uno scraper a pagamento.
Gli strumenti basati sull’AI come Thunderbit rileggono le pagine da zero ogni volta e si adattano automaticamente ai cambi di layout. Quel costo nascosto di manutenzione è ciò che giustifica gli strumenti a pagamento per la maggior parte dei team business.
Come appare davvero un dato estratto da YouTube (esempi reali di output)
Una delle lacune più grandi nelle recensioni degli scraper è che nessuno mostra davvero cosa otterrai. Ecco esempi realistici di output estratto da YouTube:
Esempio 1: metadati del canale
| channel_name | handle | subscribers | total_views | video_count | join_date | description_snippet | public_email |
|---|---|---|---|---|---|---|---|
| Example SaaS Tutorials | @examplesaas | 184K | 22.4M | 412 | 2018-06-14 | Tutorial settimanali sui prodotti e guide ai flussi di lavoro | partnerships@example.com |
| Data Ops Weekly | @dataopsweekly | 92K | 8.7M | 215 | 2020-01-03 | Demo di analytics, automazione e workflow AI | Non visibile |
Esempio 2: export dei commenti
| video_url | timestamp | author | comment_text | likes | reply_count |
|---|---|---|---|---|---|
| youtube.com/watch?v=abc123 | 2026-04-18 | @workflowfan | Ha risposto alla domanda sul prezzo meglio della pagina del fornitore. | 28 | 3 |
| youtube.com/watch?v=abc123 | 2026-04-18 | @opslead | Mi piacerebbe un seguito che lo confronti con Apify. | 11 | 0 |
| youtube.com/watch?v=abc123 | 2026-04-19 | @examplesaas | Giusto, è quello che stiamo testando adesso. | 4 | 0 |
Esempio 3: estrazione della trascrizione
100:00:00.000 - 00:00:04.200 Oggi confrontiamo sei flussi di lavoro di scraping di YouTube per i marketer.
200:00:04.200 - 00:00:09.800 La differenza principale è se ti servono metadati, commenti o trascrizioni.
300:00:09.800 - 00:00:15.300 Per gli utenti non tecnici, uno scraper basato su browser è di solito più facile da mantenere.Problemi di pulizia comuni da aspettarsi:
- I conteggi delle visualizzazioni possono includere suffissi localizzati (K, M) o etichette non inglesi
- Le date di caricamento a volte sono relative (“3 anni fa”) invece che date ISO
- I commenti possono essere ordinati per Top invece che per Nuovi di default
- Le risposte nascoste e i commenti caricati lazy richiedono scrolling o paginazione
- I campi email pubbliche possono essere nascosti dietro interazioni o restrizioni dell’account
- Le trascrizioni possono essere non disponibili, generate automaticamente o in una lingua inattesa
Per Thunderbit in particolare, il flusso è: AI Suggest Fields → Scrape → Esporta in Google Sheets. L’AI gestisce il rilevamento dei campi, quindi non devi definire manualmente cosa siano “visualizzazioni” o “data di caricamento” nella pagina.
È legale fare scraping di YouTube nel 2026?
La versione breve: fare scraping di dati pubblicamente disponibili su YouTube è in genere meno rischioso rispetto all’accesso a dati privati, ma non è una zona franca legale.
I vietano esplicitamente l’accesso automatizzato, salvo per i motori di ricerca pubblici che rispettano robots.txt o con autorizzazione scritta preventiva di YouTube. Tuttavia, l’applicazione delle regole contro la ricerca aziendale legittima è rara — YouTube mira soprattutto ad abusi su larga scala, pirateria dei contenuti e violazioni della privacy.
Il precedente giuridico statunitense offre qualche chiarimento. La decisione del Ninth Circuit nel caso ha sollevato seri dubbi sul fatto che lo scraping di dati pubblicamente disponibili violi il CFAA. La che fare scraping di siti pubblici non è un crimine. Ma restano applicabili i ToS della piattaforma, il copyright, la privacy e le leggi anti-spam.
Linee guida pratiche:
- Raccogli solo dati pubblici che il tuo account è autorizzato a vedere
- Non fare scraping di dati personali su scala non necessaria
- Non aggirare controlli di accesso o paywall
- Rispetta il copyright — non ripubblicare trascrizioni o contenuti video in blocco
- Limita il rate dei job e non sovraccaricare i server di YouTube
- Per l’outreach, rispetta CAN-SPAM, GDPR e le norme locali
- Consulta un professionista legale per i casi d’uso ad alto rischio
Gli strumenti di questa lista includono tutti limitazione del rate e un ritmo rispettoso per progettazione. Non è solo una buona etica: è ciò che fa funzionare lo scraping nel lungo periodo.
Quale scraper per YouTube dovresti scegliere?
Ecco una guida rapida alla scelta:
- Thunderbit → Migliore per utenti non tecnici che vogliono scraping veloce e resistente ai ban di YouTube verso i fogli di calcolo. Parti da qui se sei marketer, addetto sales o content strategist.
- Apify → Migliore per sviluppatori che costruiscono pipeline automatizzate con job pianificati, webhook e delivery via API.
- Bright Data → Migliore per l’estrazione su scala enterprise in più aree geografiche con infrastruttura anti-blocco gestita.
- Octoparse → Migliore per analisti che vogliono costruire workflow visuali con più personalizzazione di un’estensione Chrome.
- YT-DLP → Migliore opzione gratuita per utenti tecnici che hanno bisogno del massimo controllo su metadati e trascrizioni.
- Phantombuster → Migliore per i growth marketer che fanno sourcing di creator e lead generation basata su YouTube.
La chiave per non essere bannati non è un trucco segreto: è scegliere uno strumento con anti-detection intelligente integrata. Scraping basato su sessione browser, rotazione proxy, pacing e piccoli batch pianificati riducono tutti il rischio. Forzare migliaia di richieste da un singolo IP cloud è ciò che porta al blocco.
Se vuoi vedere com’è lo scraping moderno di YouTube senza codice, prova il piano gratuito di . Due clic per arrivare ai dati strutturati. E se le tue esigenze sono più tecniche o di scala enterprise, gli altri strumenti di questa lista ti coprono. Per altri approcci allo scraping web, consulta le nostre guide sui e su . Puoi anche guardare tutorial sul .
FAQ
Quali dati si possono estrarre da un canale YouTube?
I dati pubblici estraibili includono titoli dei video, URL, miniature, visualizzazioni, like (dove visibili), date di caricamento, descrizioni, durata, commenti, risposte, nomi/handle dei commentatori, like ai commenti, trascrizioni/sottotitoli (generati automaticamente e scritti da persone), indicatori Shorts, nome del canale, handle, numero di iscritti, numero di video, visualizzazioni totali, descrizione, link ed email pubbliche se visibili nella pagina del canale.
Quanti video YouTube posso estrarre al giorno senza essere bannato?
Non esiste un numero universale. Gli strumenti basati su browser come Thunderbit hanno un rischio più basso per flussi simili a quelli umani perché operano dentro una sessione reale. Il YouTube Channel Video Extractor di Phantombuster supporta fino a 100 video per esecuzione. Le piattaforme cloud con rotazione proxy possono gestire migliaia di richieste con il pacing giusto. Gli script grezzi da server cloud senza limitazione del rate verranno bloccati rapidamente. L’approccio più sicuro sono piccoli batch pianificati, non un unico run enorme.
Posso fare scraping dei commenti di YouTube per l’analisi del sentiment?
Sì. Thunderbit, Apify, Bright Data e Octoparse supportano tutti l’estrazione massiva dei commenti con autore, timestamp, like e numero di risposte. Esporta in Google Sheets o CSV per l’analisi. L’actor YouTube di Apify supporta esplicitamente un numero massimo configurabile di commenti per video per questo caso d’uso.
Esiste uno scraper gratuito per YouTube che funziona davvero nel 2026?
YT-DLP è la migliore opzione gratuita per utenti tecnici — soprattutto per metadati e trascrizioni. Thunderbit offre un piano gratuito per utenti non tecnici (6 pagine, con un boost di prova a 10) che esporta direttamente in Google Sheets. Entrambi funzionano, ma YT-DLP richiede competenze da riga di comando mentre Thunderbit richiede solo un browser.
Come fanno gli scraper di YouTube a evitare di essere bloccati?
Strumenti diversi usano approcci diversi: lo scraping basato su sessione browser (Thunderbit) usa il contesto autenticato del browser dell’utente; la rotazione di proxy residenziali (Bright Data, Apify) distribuisce le richieste su milioni di IP; l’autenticazione con cookie (YT-DLP) mantiene la fiducia della sessione; ritardi e pacing integrati (Phantombuster) evitano il rilevamento comportamentale. L’approccio più affidabile combina un contesto browser reale con un pacing prudente e job piccoli pianificati.
Scopri di più