Il web si evolve a una velocità che fa sembrare lenta persino la moka della colazione—e ti assicuro che io il caffè lo bevo in un lampo. Nel 2026, l’estrazione di dati dal web non è più una chicca solo per i nerd: è la marcia in più che spinge la ricerca di nuovi clienti, il monitoraggio prezzi nell’ecommerce, le analisi di mercato e persino le valutazioni immobiliari. Con , scegliere la libreria giusta può fare la differenza tra ore di lavoro manuale e un file pieno di dati utili—pronto prima ancora che la concorrenza abbia finito il pranzo.
La cosa bella? Nel 2026 le librerie di web scraping sono disponibili in ogni formato: dalle estensioni AI per Chrome senza una riga di codice ai framework avanzati per sviluppatori. Che tu sia un commerciale che vuole solo i lead in Excel, un responsabile operation che gestisce 500 prodotti, o uno sviluppatore Python che costruisce crawler su misura, c’è la soluzione perfetta per te. Dopo anni nel mondo SaaS e automazione (e più nottate davanti al PC di quante ne vorrei ammettere), ho selezionato le 10 migliori librerie di web scraping che dovresti conoscere quest’anno—e ti spiego come scegliere quella che ti semplificherà davvero la vita.
Cosa Rende una Libreria di Web Scraping Davvero Potente nel 2026?
Prima di buttarti nella classifica, vediamo cosa conta davvero quando scegli una libreria di web scraping. Per esperienza, i migliori strumenti del 2026 hanno alcune caratteristiche in comune:
- Facilità d’uso: Un non programmatore riesce a ottenere risultati in pochi minuti? O serve una laurea in Python?
- Gestione di contenuti dinamici: Sa estrarre dati da siti moderni pieni di JavaScript? O si blocca appena trova qualcosa di più complicato dell’HTML statico?
- Compatibilità con linguaggi e piattaforme: Funziona nel tuo linguaggio preferito—Python, JavaScript, Java—o addirittura direttamente dal browser?
- Scalabilità: Può gestire centinaia (o migliaia) di pagine senza andare in crisi?
- Integrazione ed esportazione: Si collega facilmente a Excel, Google Sheets, Notion o alla tua pipeline dati?
- AI e automazione: Nel 2026, gli strumenti guidati dall’AI che funzionano con semplici comandi in linguaggio naturale sono un vantaggio enorme—soprattutto per chi non vuole scrivere codice.
La verità? I team aziendali cercano velocità, precisione e il minimo sforzo possibile. Meno tempo passi a sistemare scraper rotti o a litigare col codice, più tempo hai per lavorare davvero sui dati. E con l’arrivo dell’AI e dell’automazione da browser, anche chi non è tecnico può estrarre dati che prima richiedevano l’intervento di uno sviluppatore ().
Ok, passiamo alle cose pratiche.
Le 10 Librerie di Web Scraping Più Potenti da Usare nel 2026
- per il web scraping AI senza codice direttamente dal browser
- per il parsing HTML semplice e la pulizia dati in Python
- per crawling su larga scala e pipeline ad alte prestazioni
- per l’automazione del browser e l’estrazione da siti dinamici e ricchi di JavaScript
- per il parsing XML/HTML ultra-veloce in Python
- per la selezione HTML in stile jQuery in Python
- per HTTP, parsing HTML e rendering JS tutto in uno in Python
- per automatizzare form e semplici task browser in Python
- per l’automazione headless di Chrome in Node.js
- per il parsing HTML robusto in Java
1. Thunderbit
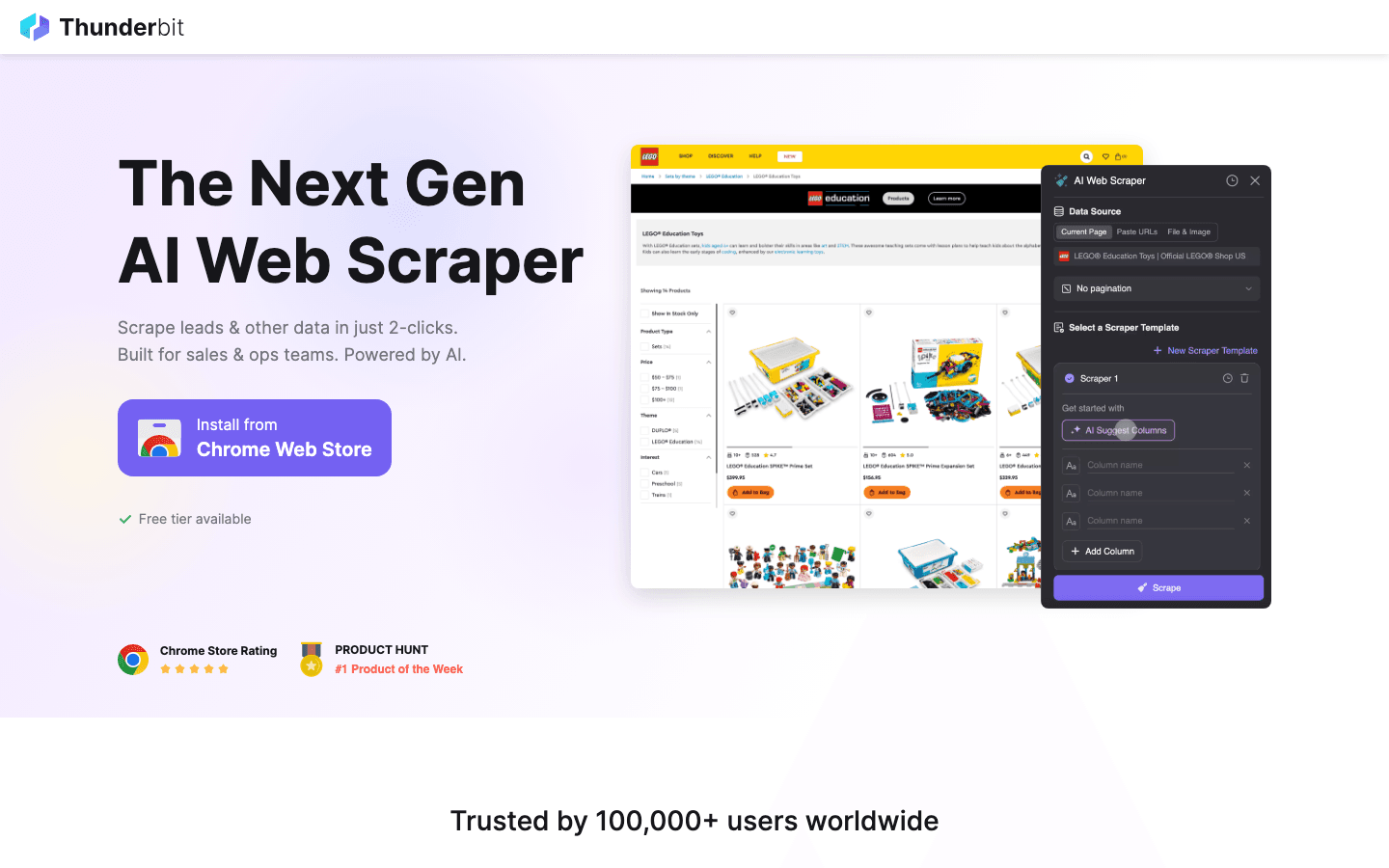
è la mia prima scelta per chiunque voglia estrarre dati dal web senza scrivere una riga di codice. Questa ti permette di descrivere quello che vuoi (“Recupera tutti i nomi prodotto, prezzi e immagini da questa pagina”) e l’AI fa tutto il resto. Niente template, nessuna configurazione—basta cliccare su “AI Suggerisci Campi”, regolare se serve, e avviare lo scraping.
Perché Thunderbit spicca nel 2026:
- Interfaccia no-code e linguaggio naturale: Tutti possono usarlo—commerciali, operation, marketing, immobiliare. Nessuna conoscenza Python richiesta.
- AI Suggerisci Campi: L’AI analizza la pagina e suggerisce le colonne migliori da estrarre.
- Estrazione da sottopagine: Vuoi più dettagli? Thunderbit può visitare ogni sottopagina (come pagine prodotto o profili) e arricchire la tua tabella in automatico ().
- Template pronti per i siti più usati: Amazon, Zillow, Shopify e altri—estrai dati con un click.
- Esporta su Excel, Google Sheets, Notion, Airtable: I dati arrivano dove servono al tuo team.
- Supporta 34 lingue: Perfetto per team internazionali.
- Scraping cloud o da browser: Scegli la modalità che preferisci—il cloud è velocissimo per siti pubblici, il browser gestisce login e sessioni.
Thunderbit è già scelto da oltre 30.000 utenti nel mondo, e il piano gratuito ti permette di estrarre dati da 6 pagine (o 10 con il boost di prova). Se vuoi vedere come si fa web scraping oggi, questo è il punto di partenza.
2. Beautiful Soup

è una libreria Python storica, amatissima da data scientist e analisti per la sua semplicità e potenza nel gestire HTML disordinato. Se ti è mai capitato di dover estrarre dati da una pagina con tag rotti o formattazione strana, Beautiful Soup è la soluzione.
Cosa rende Beautiful Soup speciale:
- Gestisce HTML irregolare: Perfetta per ripulire ed estrarre dati da pagine “brutte” ().
- Facile da imparare: Anche chi è alle prime armi con Python può iniziare subito.
- Flessibile: Funziona bene con client HTTP come Requests e si può combinare con lxml per maggiore velocità.
- Ideale per: Estrazioni rapide, pulizia dati web, integrazione in piccoli script.
Se lavori con pagine statiche o markup disordinato, Beautiful Soup è una scelta affidabile.
3. Scrapy

è il gigante del web scraping in Python. Un framework completo per costruire crawler scalabili e pipeline di dati. Se devi estrarre dati da migliaia di pagine, seguire link e processare dati su larga scala, Scrapy è pensato per te.
Perché Scrapy è tra i migliori:
- Altamente modulare: Costruisci spider complessi, pipeline e middleware ().
- Gestisce grandi progetti: Perfetto per ricerche di mercato, analisi della concorrenza o qualsiasi attività che richieda crawling massivo.
- Asincrono e veloce: Progettato per efficienza e rapidità.
- Comunità ampia: Tantissimi plugin, tutorial e supporto.
Scrapy richiede un po’ di apprendimento, ma per i progetti importanti è una vera potenza.
4. Selenium

è lo strumento di riferimento per l’automazione dei browser. Usato sia per testare applicazioni web che per estrarre dati da siti che richiedono login, click o gestione di pop-up. Se devi interagire con siti dinamici o ricchi di JavaScript, Selenium può simulare un utente reale ().
I punti di forza di Selenium:
- Automatizza browser reali: Chrome, Firefox, Safari, Edge—scegli tu.
- Gestisce login, pop-up e azioni utente: Ottimo per scraping dopo autenticazione o flussi multi-step.
- Supporto multi-linguaggio: Python, Java, C# e altri.
- Ideale per: Siti che bloccano gli scraper semplici o quando serve simulare il comportamento umano.
È più pesante delle librerie solo HTTP, ma a volte serve proprio un browser vero.
5. lxml
è un parser XML e HTML ad alte prestazioni per Python. Se la velocità è la tua priorità (ad esempio: parsing di migliaia di documenti grandi), lxml è imbattibile ().
Perché lxml è tra i preferiti:
- Velocissimo: Supera la maggior parte degli altri parser Python, soprattutto su file grandi.
- Robusto: Gestisce sia XML che HTML e si integra bene con altri strumenti.
- Ideale per: Processare grandi moli di dati, combinare con Beautiful Soup o Scrapy per maggiore potenza.
Se lavori su larga scala o con file enormi, lxml non può mancare nella tua cassetta degli attrezzi.
6. PyQuery
porta la potenza dei selettori jQuery in Python. Se ami la semplicità di $('.classe') in jQuery, PyQuery ti permette di fare lo stesso nei tuoi script di scraping ().
I punti forti di PyQuery:
- Selettori in stile jQuery: Intuitivo per chi viene dallo sviluppo front-end.
- Codice conciso e leggibile: Selezioni complesse diventano semplici.
- Integrazione con lxml: Veloce ed efficiente sotto il cofano.
- Ideale per: Progetti dove vuoi manipolare HTML in Python in modo rapido e simile a jQuery.
È il ponte perfetto per chi passa dallo sviluppo web all’estrazione dati.
7. Requests-HTML
è una libreria Python che unisce la semplicità di Requests (per HTTP) con parsing HTML integrato e persino il rendering JavaScript.
Cosa distingue Requests-HTML:
- Tutto in uno: Scarica pagine, analizza HTML e renderizza JavaScript in un unico pacchetto.
- Facile per principianti: Perfetta per progetti di scraping piccoli e medi.
- Ideale per: Script rapidi, siti con un po’ di contenuto dinamico e chi cerca semplicità.
Se sei agli inizi o ti serve uno strumento flessibile per lavori agili, Requests-HTML è una scelta vincente.
8. MechanicalSoup

è una libreria Python che automatizza form web e semplici interazioni browser. Basata su Beautiful Soup e Requests, rende facile loggarsi, compilare form e navigare flussi basilari ().
Perché MechanicalSoup è utile:
- Automatizza form e login: Ottima per estrarre dati dietro autenticazione.
- API semplice: Facile da imparare anche per chi inizia.
- Ideale per: Task browser ripetitivi, flussi semplici e siti dove Selenium sarebbe eccessivo.
Non è potente come Selenium per siti complessi, ma è molto più leggera e immediata per le esigenze di base.
9. Puppeteer
è una libreria Node.js per controllare Chrome o Chromium in modalità headless. È la preferita per estrarre dati da siti ricchi di JavaScript e altamente interattivi ().
I superpoteri di Puppeteer:
- Automazione browser completa: Click, scroll, compilazione form e interazione come un vero utente.
- Gestisce contenuti dinamici: Perfetta per siti che caricano dati via JavaScript.
- Ideale per: Ecommerce, social media o qualsiasi sito dove gli scraper tradizionali falliscono.
Se sei uno sviluppatore JavaScript o devi estrarre dati dal “web moderno”, Puppeteer è indispensabile.
10. Jsoup
è lo standard per il parsing HTML in Java. È come Beautiful Soup, ma per chi sviluppa in Java ().
Perché i team Java amano Jsoup:
- API semplice e potente: Estrai e manipola dati con poche righe di codice.
- Gestisce HTML disordinato: Ripulisce e analizza anche pagine mal formattate.
- Ideale per: Integrare lo scraping in applicazioni Java aziendali o flussi backend.
Se il tuo stack è Java, Jsoup è la scelta naturale.
Tabella Comparativa delle Librerie di Web Scraping
Ecco una panoramica rapida delle 10 librerie a confronto:
| Libreria | Linguaggio | Facilità d’uso | Contenuti Dinamici | AI/No-Code | Casi d’uso tipici | Ideale per |
|---|---|---|---|---|---|---|
| Thunderbit | Est. Chrome | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Sì | Vendite, operation, ricerca, immobiliare | Non tecnici, utenti business |
| Beautiful Soup | Python | ⭐⭐⭐⭐ | ⭐ | No | Parsing HTML, pulizia dati | Principianti Python, analisti |
| Scrapy | Python | ⭐⭐⭐ | ⭐⭐ | No | Crawling su larga scala, pipeline | Sviluppatori, big data |
| Selenium | Multi | ⭐⭐ | ⭐⭐⭐⭐⭐ | No | Automazione browser, login | QA, scraping siti dinamici |
| lxml | Python | ⭐⭐⭐ | ⭐ | No | Parsing veloce, file grandi | Power user, grandi dataset |
| PyQuery | Python | ⭐⭐⭐⭐ | ⭐ | No | Selezione stile jQuery | Web dev, script concisi |
| Requests-HTML | Python | ⭐⭐⭐⭐ | ⭐⭐ | No | Script rapidi, rendering JS | Principianti, piccoli progetti |
| MechanicalSoup | Python | ⭐⭐⭐⭐ | ⭐⭐ | No | Automazione form, login | Task browser semplici |
| Puppeteer | Node.js | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | No | Siti JS-heavy, automazione | Dev JS, scraping web dinamico |
| Jsoup | Java | ⭐⭐⭐⭐ | ⭐ | No | Parsing HTML in Java | Team Java, workflow backend |
Come Scegliere la Libreria di Web Scraping Giusta per la Tua Azienda
Quale libreria scegliere? Ecco i miei consigli, frutto di anni di tentativi, errori e qualche notte insonne di debug:
- Non tecnici o utenti business: Parti da Thunderbit. L’approccio AI/no-code ti permette di ottenere risultati in pochi minuti, non giorni. Se il tuo team vuole solo i dati in Excel o Sheets, non complicarti la vita.
- Sviluppatori Python: Beautiful Soup e Requests-HTML sono ottimi per lavori piccoli. Scrapy è il top per progetti grandi. Combinali con lxml o PyQuery per più potenza.
- Devi gestire login o contenuti dinamici? Selenium (multi-linguaggio) o Puppeteer (Node.js) sono le scelte migliori.
- Team Java: Jsoup è la soluzione ideale per integrare lo scraping nelle app Java.
- Automatizzare form o flussi semplici? MechanicalSoup è leggero e facilissimo da usare.
Fattori chiave da valutare:
- Livello tecnico: Strumenti no-code come Thunderbit sono perfetti per team non tecnici. Gli sviluppatori preferiranno la flessibilità delle librerie a codice.
- Complessità dei dati: Per pagine semplici e statiche, Beautiful Soup o Jsoup vanno benissimo. Per siti dinamici e ricchi di JavaScript, meglio Selenium o Puppeteer.
- Scalabilità: Scrapy e lxml sono ideali per lavori su larga scala e ad alta velocità.
- Integrazione: L’export diretto di Thunderbit su Sheets, Notion e Airtable fa risparmiare tempo nei flussi aziendali.
Per approfondire la scelta dello strumento giusto, dai un’occhiata alla .
Conclusione: Sblocca il Potenziale dei Dati Web con gli Strumenti Giusti
Nel 2026 il web scraping non è più solo per sviluppatori o data scientist. Grazie all’esplosione di strumenti AI e no-code, ogni team—dalle vendite alla ricerca—può accedere facilmente al tesoro di dati del web. La libreria giusta può farti risparmiare centinaia di ore all’anno (), aumentare la precisione e dare un vero vantaggio competitivo alla tua azienda.
Il mio consiglio? Parti dai tuoi bisogni—velocità, scala, livello tecnico—e prova qualche soluzione. è perfetto per iniziare, e le librerie open source come Beautiful Soup o Scrapy sono sempre disponibili se vuoi metterti alla prova con il codice.
Vuoi approfondire? Dai un’occhiata al per altre guide, o iscriviti al nostro per tutorial pratici.
Buon scraping—che i tuoi dati siano sempre puliti, ordinati e subito pronti all’uso.
Domande Frequenti
1. Qual è la libreria di web scraping più semplice per chi non programma nel 2026?
è la scelta migliore per chi non sa programmare. La sua estensione Chrome con AI permette di estrarre dati usando semplici comandi in linguaggio naturale—senza scrivere codice.
2. Quale libreria è ideale per estrarre dati da siti dinamici o ricchi di JavaScript?
(Node.js) e (multi-linguaggio) sono le migliori per siti dinamici e generati da JavaScript. Automatizzano browser reali e gestiscono interazioni complesse.
3. Che differenza c’è tra Beautiful Soup e Scrapy?
è ottima per estrarre dati da singole pagine o piccoli progetti, soprattutto con HTML disordinato. è un framework completo per costruire crawler scalabili e processare grandi quantità di dati.
4. Posso esportare i dati estratti direttamente su Google Sheets o Notion?
Sì— offre l’export diretto su Google Sheets, Notion, Airtable ed Excel. La maggior parte delle librerie a codice richiede invece di scrivere la logica di esportazione.
5. Come scelgo la libreria di web scraping giusta per la mia azienda?
Valuta le tue competenze tecniche, la complessità dei siti da estrarre, il volume di dati e le esigenze di integrazione. Gli strumenti no-code come Thunderbit sono ideali per i team aziendali, mentre gli sviluppatori possono preferire Scrapy, Beautiful Soup o Puppeteer per un controllo maggiore.
Approfondisci