Il web è una vera e propria miniera d’oro di dati, ma spesso le informazioni non sono pensate per essere scaricate in modo semplice. Nel 2025, l’estrazione dei dati dal web è diventata una competenza fondamentale per chi tiene d’occhio prezzi, offerte di lavoro, annunci immobiliari e movimenti dei concorrenti. Il problema? Su Github ci sono una marea di progetti di scraping: alcuni sono ben fatti, altri sono un incubo da usare, molti sono fermi da anni. Come scegliere quello giusto, soprattutto se non sei uno sviluppatore esperto?
In questa guida ti porto alla scoperta dei 15 migliori progetti di web scraping github per il 2025. Non troverai solo una lista: per ogni progetto ti spiego quanto è facile da installare, per quali casi d’uso è perfetto, se gestisce contenuti dinamici, quanto è mantenuto, come esporta i dati e a chi si rivolge. E se sei stufo di impazzire con il codice, ti mostro perché strumenti no-code e AI come stanno cambiando le regole del gioco anche per chi non ha competenze tecniche.
Come abbiamo scelto i 15 migliori progetti di web scraping github
Diciamolo senza giri di parole: non tutti i progetti su Github sono uguali. Alcuni sono testati da migliaia di utenti, altri sono rimasti esperimenti del fine settimana. Per questa selezione ho scelto solo progetti che rispettano questi criteri:
- Stelle e Community su Github: Progetti con una solida base di utenti (da qualche migliaio a oltre 90k stelle) e contributori attivi.
- Attività recente: Strumenti ancora aggiornati nel 2025, non “fossili digitali”.
- Documentazione e facilità d’uso: Guide chiare, esempi pratici e una curva di apprendimento ragionevole.
- Utilizzo reale: Usati davvero in aziende o ricerca, non solo per demo “hello world”.
Visto che ogni esigenza di estrazione dati è diversa, ogni progetto viene valutato su:
- Facilità di installazione e configurazione: Parti in pochi minuti o devi impazzire con driver e dipendenze?
- Casi d’uso: È pensato per e-commerce, news, ricerca o altro?
- Supporto a pagine dinamiche: Gestisce siti moderni pieni di JavaScript?
- Salute del progetto: È mantenuto attivamente o è fermo da anni?
- Esportazione dei dati: Ti dà dati già pronti o solo HTML grezzo?
- Pubblico ideale: È adatto a chi inizia con Python, a data engineer o a team non tecnici?
Ogni progetto ha dei tag rapidi per questi criteri, così trovi subito quello che fa per te, sia che tu sia uno smanettone del codice sia che tu voglia solo i dati su Google Sheet.

Difficoltà di installazione: quanto è semplice iniziare a fare scraping?
Diciamolo chiaramente: per molti il vero scoglio è solo far partire un estrattore web. Ecco come ho diviso la difficoltà di setup:
- Plug & Play (Zero Configurazione): Installi e sei subito operativo. Perfetto per chi parte da zero.
- Media (Command Line, un po’ di codice): Serve qualche riga di codice o il terminale, ma nulla di impossibile se hai già scritto qualche script.
- Avanzata (Driver, Anti-bot, Codice complesso): Richiede configurazioni, driver per browser o solide basi in Python/JS.
Ecco dove si posizionano i principali progetti:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (per utenti finali, dopo il deploy)
- Media: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Avanzata: Heritrix, Apache Nutch (richiedono Java, file di configurazione o stack big data)
Se non sei uno sviluppatore, le opzioni “Plug & Play” o no-code sono le più adatte. Per gli altri, “Media” vuol dire che dovrai scrivere un po’ di codice, ma niente di traumatico—tranne se odi le parentesi graffe.
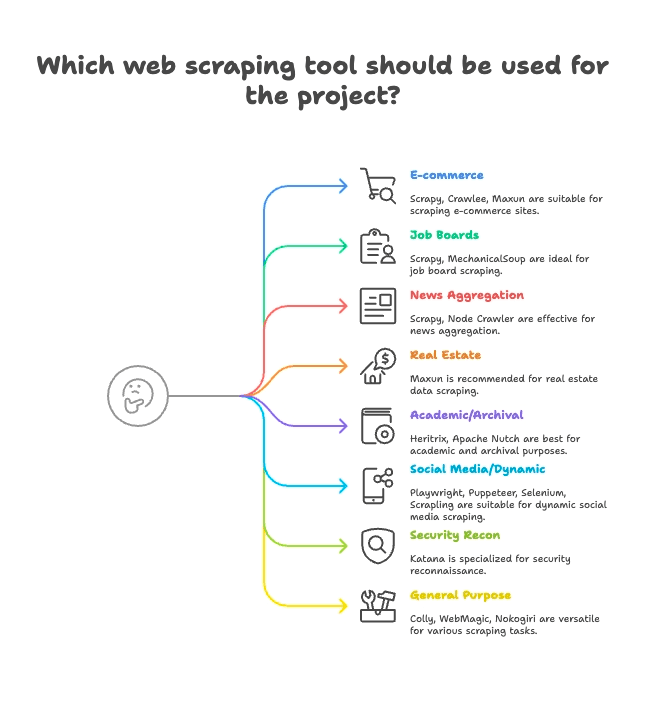
Raggruppamento per casi d’uso: trova l’estrattore web giusto per il tuo settore
Non tutti gli estrattori web sono pensati per lo stesso scopo. Ecco come ho suddiviso i 15 migliori in base al loro utilizzo ideale:
E-commerce e monitoraggio prezzi
- Scrapy: Estrazione massiva di prodotti e pagine multiple
- Crawlee: Versatile, va bene sia per siti statici che dinamici di e-commerce
- Maxun: No-code, perfetto per estrarre velocemente liste di prodotti
Portali lavoro e recruiting
- Scrapy: Gestisce paginazione e annunci strutturati
- MechanicalSoup: Ottimo per portali con login
News e aggregazione contenuti
- Scrapy: Ideale per il crawling di siti di notizie su larga scala
- Node Crawler: Veloce per aggregare news da siti statici
Immobiliare
- Thunderbit: Estrazione AI di annunci e dettagli da sottopagine
- Maxun: Selezione visiva dei dati immobiliari
Ricerca accademica e archiviazione web
- Heritrix: Archiviazione completa di siti (file WARC)
- Apache Nutch: Crawling distribuito per dataset di ricerca
Social media e contenuti dinamici
- Playwright, Puppeteer, Selenium: Scraping di feed dinamici, simulazione login
- Scrapling: Scraping stealth per siti con difese anti-bot
Sicurezza e ricognizione
- Katana: Scoperta rapida di URL e crawling per la sicurezza
Multiuso / Generico
- Colly: Scraping ad alte prestazioni in Go per qualsiasi sito
- WebMagic: Flessibile, basato su Java, adatto a molti domini
- Nokogiri: Parsing HTML in Ruby per script personalizzati
Supporto a pagine dinamiche: questi progetti github gestiscono i siti moderni?
I siti di oggi sono pieni di JavaScript. React, Vue, scroll infinito, AJAX—se hai mai provato a estrarre dati e ti sei trovato con una pagina vuota, sai di cosa parlo.
Ecco come ogni progetto affronta i contenuti dinamici:
- Supporto completo JS (Browser headless):
- Selenium: Controlla browser veri, esegue tutto il JS
- Playwright: Multi-browser, multi-linguaggio, ottimo con JS
- Puppeteer: Headless Chrome/Firefox, rendering JS completo
- Crawlee: Passa da HTTP a browser (via Puppeteer/Playwright)
- Katana: Modalità headless opzionale per parsing JS
- Scrapling: Integra Playwright per scraping stealth JS
- Maxun: Usa il browser internamente per contenuti dinamici
- Nessun supporto JS nativo (solo HTML statico):
- Scrapy: Serve plugin Selenium/Playwright per JS
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: Tutti estraggono solo HTML, non gestiscono JS di default
L’AI di Thunderbit fa la differenza: rileva e estrae automaticamente i contenuti dinamici—senza configurazioni manuali, plugin o selettori complicati. Basta cliccare su “AI Suggerisci Campi” e lasciare che faccia tutto, anche su siti complessi in React. Per saperne di più, leggi la .
Salute e affidabilità dei progetti: questo estrattore web funzionerà anche l’anno prossimo?
Non c’è niente di peggio che costruire un flusso di lavoro su uno strumento e poi scoprire che è stato abbandonato. Ecco lo stato dei principali progetti:
- Manutenzione attiva (aggiornamenti frequenti):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- Stabili ma aggiornamenti lenti:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- Modalità manutenzione (specializzati, aggiornamenti lenti):
- Heritrix:
- Apache Nutch:
Thunderbit è un servizio gestito: non devi preoccuparti di codice abbandonato. Il nostro team aggiorna costantemente AI, template e integrazioni—e se hai bisogno di aiuto, ci sono onboarding, tutorial e supporto.
Gestione ed esportazione dei dati: da HTML grezzo a dati pronti per il business
Ottenere i dati è solo metà del lavoro. Serve che siano in un formato utilizzabile dal tuo team—CSV, Excel, Google Sheets, Airtable, Notion o anche tramite API.
- Esportazione strutturata integrata:
- Scrapy: Esporta in CSV, JSON, XML
- Crawlee: Dataset e storage flessibili
- Maxun: CSV, Excel, Google Sheets, API JSON
- Thunderbit:
- Gestione manuale dei dati (definita dall’utente):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: Devi scrivere tu il codice per salvare/esportare i dati
- Esportazione specializzata:
- Heritrix: WARC (file archivio web)
- Apache Nutch: Contenuto grezzo su storage/indice
Le esportazioni strutturate e le integrazioni di Thunderbit fanno risparmiare tempo ai team business. Niente più CSV da sistemare o codice “collante”—basta un click e i dati sono pronti all’uso.
Pubblico ideale: a chi si rivolge ogni progetto di web scraping github?
Non tutti gli strumenti sono per tutti. Ecco a chi consiglio ciascuno:
- Principianti Python: MechanicalSoup, Scrapling (se vuoi sperimentare)
- Data engineer: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- QA e automazione: Selenium, Playwright, Puppeteer
- Ricercatori sicurezza: Katana
- Sviluppatori Ruby: Nokogiri
- Sviluppatori Java: WebMagic, Heritrix, Apache Nutch
- Utenti non tecnici / team business: Maxun, Thunderbit
- Growth hacker, analisti: Maxun, Thunderbit
Se non ami il codice o vuoi risultati rapidi, Thunderbit e Maxun sono le scelte migliori. Per tutti gli altri, scegli lo strumento che si adatta al tuo linguaggio e caso d’uso.
I 15 migliori progetti di web scraping github: confronto dettagliato
Ecco una panoramica di ogni progetto, raggruppati per caso d’uso, con tag e punti di forza.
E-commerce, monitoraggio prezzi e crawling generico
— 57.1k stelle, aggiornato giugno 2025

- Descrizione: Framework Python asincrono per crawling e scraping su larga scala.
- Setup: Medio (richiede codice Python, framework async)
- Casi d’uso: E-commerce, news, ricerca, spider multipagina
- Supporto JS: No (serve plugin Selenium/Playwright)
- Salute progetto: Manutenzione attiva
- Esportazione dati: CSV, JSON, XML integrati
- Pubblico: Sviluppatori, data engineer
- Punti di forza: Scalabile, robusto, molti plugin. Curva di apprendimento ripida per chi inizia.
— 17.9k stelle, 2025

- Descrizione: Libreria Node.js completa per scraping statico e dinamico.
- Setup: Medio (codice Node/TS)
- Casi d’uso: E-commerce, social media, automazione
- Supporto JS: Sì (integrazione Puppeteer/Playwright)
- Salute progetto: Molto attivo
- Esportazione dati: Flessibile (dataset, storage)
- Pubblico: Team di sviluppo JS/TS
- Punti di forza: Toolkit anti-blocco, facile passaggio HTTP/browser.
— 13k stelle, giugno 2025

- Descrizione: Piattaforma open-source no-code per estrazione dati web con interfaccia visuale.
- Setup: Medio (deploy server), Facile (per utenti finali)
- Casi d’uso: Generico, e-commerce, scraping business
- Supporto JS: Sì (browser integrato)
- Salute progetto: Attivo e in crescita
- Esportazione dati: CSV, Excel, Google Sheets, API JSON
- Pubblico: Utenti non tecnici, analisti, team
- Punti di forza: Scraping punta-e-clicca, navigazione multilivello, self-hosting.
Portali lavoro, recruiting e interazioni semplici
— 4.8k stelle, 2024

- Descrizione: Libreria Python per automatizzare form e navigazione semplice.
- Setup: Plug & Play (Python, poco codice)
- Casi d’uso: Portali lavoro con login, siti statici
- Supporto JS: No
- Salute progetto: Maturo, aggiornamenti sporadici
- Esportazione dati: Nessuna integrata (manuale)
- Pubblico: Principianti Python, script veloci
- Punti di forza: Simula sessioni browser in poche righe. Non adatto a siti dinamici.
Aggregazione news e contenuti statici
— 6.8k stelle, 2024

- Descrizione: Crawler server-side veloce e concorrente con parsing Cheerio.
- Setup: Medio (callback/async Node)
- Casi d’uso: News, scraping statico ad alta velocità
- Supporto JS: No (solo HTML)
- Salute progetto: Attività moderata (v2 beta)
- Esportazione dati: Nessuna integrata (definita dall’utente)
- Pubblico: Dev Node.js, esigenze alta concorrenza
- Punti di forza: Crawling asincrono, rate limiting, API simile a jQuery.
Immobiliare, annunci e scraping di sottopagine

- Descrizione: Estrattore Web AI, no-code, pensato per utenti business.
- Setup: Plug & Play (estensione Chrome, 2 click)
- Casi d’uso: Immobiliare, e-commerce, vendite, marketing, qualsiasi sito
- Supporto JS: Sì (AI rileva contenuti dinamici)
- Salute progetto: Aggiornato costantemente, servizio gestito
- Esportazione dati: Un click su Sheets, Airtable, Notion, CSV, JSON
- Pubblico: Utenti non tecnici, team business, vendite, marketing
- Punti di forza: “AI Suggerisci Campi”, scraping sottopagine, esportazione istantanea, onboarding, template, .
Ricerca accademica e archiviazione web
— 3k stelle, 2023

- Descrizione: Crawler per archiviazione web su larga scala dell’Internet Archive.
- Setup: Avanzato (app Java, file di configurazione)
- Casi d’uso: Archiviazione web, crawling di interi domini
- Supporto JS: No (solo fetch)
- Salute progetto: Mantenuto (lento ma costante)
- Esportazione dati: WARC (file archivio web)
- Pubblico: Archivi, biblioteche, istituzioni
- Punti di forza: Scalabile, robusto, conforme agli standard. Non adatto a scraping mirato.
— 3k stelle, 2024

- Descrizione: Crawler open-source per big data e motori di ricerca.
- Setup: Avanzato (Java+Hadoop per scalabilità)
- Casi d’uso: Crawling per motori di ricerca, big data
- Supporto JS: No (solo HTTP)
- Salute progetto: Attivo (Apache)
- Esportazione dati: Contenuto grezzo su storage/indice
- Pubblico: Aziende, big data, ricerca accademica
- Punti di forza: Architettura a plugin, crawling distribuito.
Social media, contenuti dinamici e automazione
— ~30k stelle, 2025

- Descrizione: Automazione browser per scraping e test, supporta tutti i principali browser.
- Setup: Medio (driver, multi-linguaggio)
- Casi d’uso: Siti ricchi di JS, test, social media
- Supporto JS: Sì (automazione browser completa)
- Salute progetto: Attivo, maturo
- Esportazione dati: Nessuna (manuale)
- Pubblico: QA engineer, sviluppatori
- Punti di forza: Multi-linguaggio, simula comportamento reale utente.
— 73.5k stelle, 2025

- Descrizione: Automazione browser moderna per scraping e test E2E.
- Setup: Medio (script multi-linguaggio)
- Casi d’uso: Web app moderne, social media, automazione
- Supporto JS: Sì (headless o browser reale)
- Salute progetto: Molto attivo
- Esportazione dati: Nessuna (gestita dall’utente)
- Pubblico: Sviluppatori che cercano controllo avanzato del browser
- Punti di forza: Cross-browser, auto-wait, intercettazione rete.
— 90.9k stelle, 2025

- Descrizione: API di alto livello per automazione Chrome/Firefox.
- Setup: Medio (script Node)
- Casi d’uso: Scraping headless Chrome, contenuti dinamici
- Supporto JS: Sì (Chrome/Firefox)
- Salute progetto: Attivo (team Chrome)
- Esportazione dati: Nessuna (custom in codice)
- Pubblico: Dev Node.js, front-end
- Punti di forza: Controllo browser avanzato, screenshot, PDF, intercettazione rete.
— 5.4k stelle, giugno 2025

- Descrizione: Scraping stealth ad alte prestazioni con funzioni anti-bot.
- Setup: Medio (codice Python)
- Casi d’uso: Scraping stealth, anti-bot, siti dinamici
- Supporto JS: Sì (integrazione Playwright)
- Salute progetto: Attivo, all’avanguardia
- Esportazione dati: Nessuna integrata (manuale)
- Pubblico: Dev Python, hacker, data engineer
- Punti di forza: Stealth, proxy, anti-blocco, async.
Ricognizione sicurezza
— 13.8k stelle, 2025

- Descrizione: Crawler web veloce per sicurezza, automazione e scoperta link.
- Setup: Medio (CLI o libreria Go)
- Casi d’uso: Crawling sicurezza, scoperta endpoint
- Supporto JS: Sì (modalità headless opzionale)
- Salute progetto: Attivo (ProjectDiscovery)
- Esportazione dati: Output testuale (liste URL)
- Pubblico: Ricercatori sicurezza, dev Go
- Punti di forza: Velocità, concorrenza, parsing JS headless.
Scraping generico / multiuso
— 24.3k stelle, 2025

- Descrizione: Framework di scraping veloce ed elegante per Go.
- Setup: Medio (codice Go)
- Casi d’uso: Scraping ad alte prestazioni, generico
- Supporto JS: No (solo HTML)
- Salute progetto: Attivo, commit recenti
- Esportazione dati: Nessuna integrata (definita dall’utente)
- Pubblico: Dev Go, focus su performance
- Punti di forza: Async, rate limiting, scraping distribuito.
— 11.6k stelle, 2023

- Descrizione: Framework Java flessibile per crawling, stile Scrapy.
- Setup: Medio (Java, API semplice)
- Casi d’uso: Scraping web generico in Java
- Supporto JS: No (estendibile con Selenium)
- Salute progetto: Community attiva
- Esportazione dati: Pipeline pluggabili
- Pubblico: Dev Java
- Punti di forza: Thread pool, scheduler, anti-blocco.
— 6.2k stelle, 2025

- Descrizione: Parser HTML/XML veloce e nativo per Ruby.
- Setup: Plug & Play (gem Ruby)
- Casi d’uso: Parsing HTML/XML in app Ruby
- Supporto JS: No (solo parsing)
- Salute progetto: Attivo, aggiornato con Ruby
- Esportazione dati: Nessuna (usa Ruby per formattare)
- Pubblico: Rubyist, dev Rails
- Punti di forza: Velocità, compliance, sicurezza di default.
Tabella di confronto rapido delle funzionalità
Ecco una tabella di confronto veloce—con anche Thunderbit per il paragone:
| Progetto | Difficoltà Setup | Casi d’uso | Supporto JS | Manutenzione | Esportazione dati | Pubblico | Stelle Github |
|---|---|---|---|---|---|---|---|
| Scrapy | Media | E-commerce, news | No | Attivo | CSV, JSON, XML | Dev, data engineer | 57.1k |
| Crawlee | Media | Versatile, automazione | Sì | Molto attivo | Dataset flessibili | Team JS/TS | 17.9k |
| MechanicalSoup | Plug & Play | Statico, form | No | Maturo | Nessuna (manuale) | Principianti Python | 4.8k |
| Node Crawler | Media | News, statico | No | Moderata | Nessuna (manuale) | Dev Node.js | 6.8k |
| Selenium | Media | JS-heavy, test | Sì | Attivo | Nessuna (manuale) | QA, dev | ~30k |
| Heritrix | Avanzato | Archiviazione, ricerca | No | Mantenuto | WARC | Archivi, istituzioni | 3k |
| Apache Nutch | Avanzato | Big data, search | No | Attivo | Contenuto grezzo | Aziende, ricerca | 3k |
| WebMagic | Media | Java, generico | No | Community attiva | Pipeline pluggabili | Dev Java | 11.6k |
| Nokogiri | Plug & Play | Parsing Ruby | No | Attivo | Nessuna (manuale) | Rubyist | 6.2k |
| Playwright | Media | Dinamico, automazione | Sì | Molto attivo | Nessuna (manuale) | Dev, QA | 73.5k |
| Katana | Media | Sicurezza, discovery | Sì | Attivo | Output testuale | Sicurezza, dev Go | 13.8k |
| Colly | Media | High-perf, generico | No | Attivo | Nessuna (manuale) | Dev Go | 24.3k |
| Puppeteer | Media | Dinamico, automazione | Sì | Attivo | Nessuna (manuale) | Dev Node.js | 90.9k |
| Maxun | Facile (utente) | No-code, business | Sì | Attivo | CSV, Excel, Sheets, API | Non-tech, analisti | 13k |
| Scrapling | Media | Stealth, anti-bot | Sì | Attivo | Nessuna (manuale) | Dev Python, hacker | 5.4k |
| Thunderbit | Plug & Play | No-code, business | Sì | Gestito, aggiornato | Sheets, Airtable, Notion | Non-tech, business | N/A |
Perché Thunderbit è la scelta migliore per utenti business e non tecnici
La verità è che la maggior parte dei progetti open-source su Github sono pensati da sviluppatori per sviluppatori. Questo vuol dire che dovrai occuparti di setup, manutenzione e risoluzione problemi. Se sei un utente business, marketing, sales ops o semplicemente vuoi risultati—senza impazzire con le regex—Thunderbit è pensato per te.
Ecco perché Thunderbit fa la differenza:
- Semplicità no-code e AI: Installa l’, clicca su “AI Suggerisci Campi” e sei subito operativo. Niente Python, niente selettori, niente “pip install”.
- Supporto pagine dinamiche: L’AI di Thunderbit legge ed estrae dati anche da siti moderni pieni di JavaScript (React, Vue, AJAX) senza configurazioni manuali.
- Scraping di sottopagine: Vuoi estrarre dettagli da ogni prodotto o annuncio? L’AI di Thunderbit può navigare tra le sottopagine e unire i dati in una sola tabella—senza codice custom.
- Esportazione pronta per il business: Un click per esportare su Google Sheets, Airtable, Notion, CSV o JSON. Perfetto per lead, monitoraggio prezzi o aggregazione contenuti.
- Aggiornamenti e supporto continui: Thunderbit è un servizio gestito—niente rischio di “abandonware”. Hai onboarding, tutorial e una libreria di template in crescita.
- Pubblico ideale: Thunderbit è pensato per utenti non tecnici, team business e chiunque voglia velocità e affidabilità senza smanettare con il codice.
Non devi credermi sulla parola—Thunderbit è già scelto da oltre 30.000 utenti in tutto il mondo, inclusi team di Accenture, Grammarly e Puma. E sì, siamo stati anche il #1 su Product Hunt.
Vuoi vedere quanto è facile fare scraping? .
Conclusione: come scegliere la soluzione di web scraping giusta nel 2025
In sintesi: Github è una miniera di strumenti potenti per lo scraping, ma la maggior parte è pensata per sviluppatori. Se ami programmare, framework come Scrapy, Crawlee, Playwright e Colly ti danno il massimo controllo. Se lavori in ambito accademico o sicurezza, Heritrix, Nutch e Katana sono le scelte giuste.
Ma se sei un utente business, un analista o semplicemente vuoi dati—subito, strutturati e pronti all’uso—Thunderbit è la soluzione ideale. Niente setup, niente manutenzione, niente codice. Solo risultati.
Cosa fare ora? Se sei curioso, prova un progetto github adatto alle tue competenze e necessità. Oppure, se vuoi saltare la curva di apprendimento e vedere risultati in pochi minuti, e inizia subito a estrarre dati.
E se vuoi approfondire il mondo dell’estrazione dati dal web, dai un’occhiata agli altri articoli sul , come o .
Buon scraping—che i tuoi dati siano sempre puliti, ordinati e subito pronti da usare. E se ti blocchi, ricorda: probabilmente c’è già un repo github che fa al caso tuo… oppure puoi lasciare che l’AI di Thunderbit faccia tutto il lavoro per te.