Il mio primo progetto di scraping prevedeva uno script Python scritto a mano, un proxy condiviso e una preghiera. Si rompeva ogni tre giorni.
Nel 2026, le api di scraping si occupano delle parti più complicate — proxy, rendering, CAPTCHA, tentativi di nuovo invio — così non devi farlo tu. Sono la spina dorsale di tutto, dal monitoraggio dei prezzi alle pipeline di dati per l’addestramento dell’IA.
Ma c’è una novità: strumenti basati sull’IA come stanno rendendo inutili molti casi d’uso delle API per chi non sviluppa. Più avanti ne parlo meglio.
Ecco 10 API di scraping che ho usato o valutato — cosa fanno bene, dove mostrano i loro limiti e quando potresti non aver bisogno di un’API affatto.
Perché considerare Thunderbit AI invece delle tradizionali API di Web Scraping?
Prima di entrare nella lista delle API, parliamo dell’elefante nella stanza: l’automazione basata sull’IA. Ho passato anni ad aiutare i team ad automatizzare i lavori noiosi e posso dirti che c’è un motivo se sempre più aziende stanno saltando le API complesse e andando dritte verso agenti IA come Thunderbit.
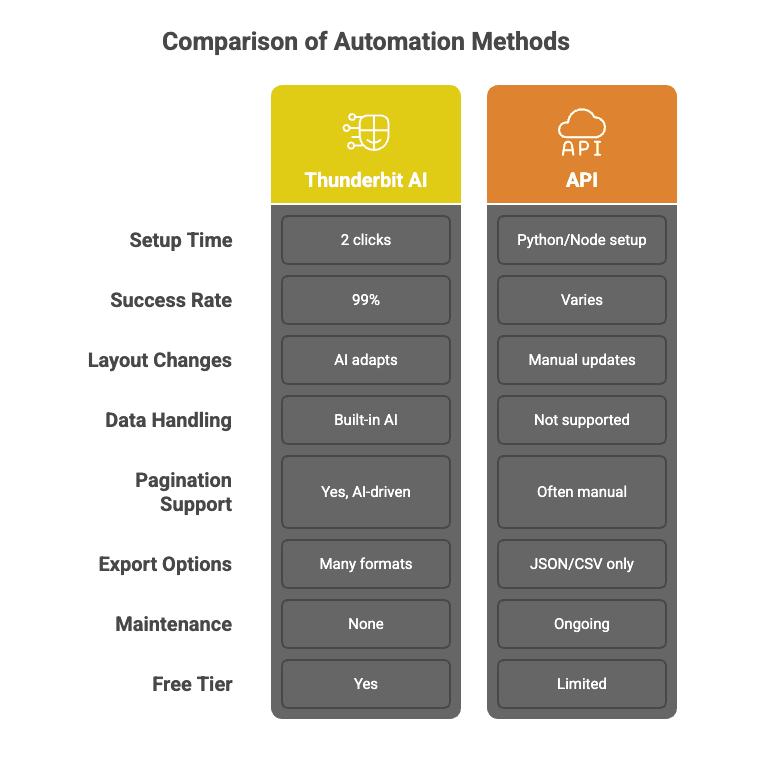
Ecco cosa distingue Thunderbit dalle tradizionali API di web scraping:
-
Chiamate API in stile waterfall per una riuscita del 99%
L’IA di Thunderbit non si limita a chiamare una sola API sperando nel meglio. Usa un approccio a cascata, selezionando automaticamente il metodo di scraping migliore per ogni lavoro, ritentando quando serve e garantendo un tasso di successo del 99%. Ottieni i dati, non i mal di testa.
-
Configurazione no-code in due clic
Dimentica script Python o la consultazione ossessiva della documentazione API. Con Thunderbit, ti basta cliccare “AI Suggerisci Campi” e “Estrai”. Fine. Anche mia madre riuscirebbe a usarlo (e pensa ancora che “il cloud” sia solo brutto tempo).
-
Scraping in batch: veloce e preciso
Il modello IA di Thunderbit può elaborare migliaia di siti diversi in parallelo, adattandosi al layout di ciascuno in tempo reale. È come avere un esercito di stagisti — solo che non chiedono pause caffè.
-
Nessuna manutenzione
I siti web cambiano di continuo. Le API tradizionali? Si rompono. Thunderbit? L’IA legge ogni volta la pagina da zero, quindi non devi aggiornare il codice quando un sito modifica il layout o aggiunge un nuovo pulsante.
-
Estrazione dati personalizzata e post-elaborazione
Hai bisogno che i dati vengano ripuliti, etichettati, tradotti o riassunti? Thunderbit può farlo durante l’estrazione — immaginalo come buttare 10.000 pagine web in ChatGPT e ricevere in cambio un dataset perfettamente strutturato.
-
Scraping di sottopagine e paginazione
L’IA di Thunderbit può seguire i link, gestire la paginazione e persino arricchire la tua tabella con dati provenienti dalle sottopagine — tutto senza codice personalizzato.
-
Esportazione dati e integrazioni gratuite
Esporta su Excel, Google Sheets, Airtable, Notion, oppure scarica in CSV/JSON — senza paywall, senza complicazioni.
Ecco un confronto rapido per fissare bene il concetto:
Vuoi vederlo in azione? Dai un’occhiata all’.
Che cos’è un’API di scraping dati?
Torniamo un attimo alle basi. Un’api di scraping dati è uno strumento che ti permette di estrarre dati dai siti web in modo programmatico, senza dover costruire da zero i tuoi scraper. Pensala come un robot che puoi mandare a prendere gli ultimi prezzi, le recensioni o gli annunci, e che ti riporta i dati in un formato pulito e strutturato (di solito JSON o CSV).
Come funzionano? La maggior parte delle API di scraping gestisce le parti più scomode — proxy rotanti, risoluzione dei CAPTCHA, rendering di JavaScript — così puoi concentrarti su ciò che ti serve davvero: i dati. Invi una richiesta (di solito con un URL e alcuni parametri) e l’API restituisce il contenuto, pronto per il tuo flusso di lavoro aziendale.
Vantaggi principali:
- Velocità: le API possono estrarre migliaia di pagine al minuto.
- Scalabilità: devi monitorare 10.000 prodotti? Nessun problema.
- Integrazione: collegale al tuo CRM, al tuo strumento BI o al data warehouse con il minimo sforzo.
Ma, come vedremo, non tutte le API sono uguali — e non tutte sono davvero “imposta e dimentica”, come promettono.
Come ho valutato queste API
Ho passato parecchio tempo sul campo — testando, rompendo e a volte persino mandando in DDoS per errore i miei stessi server (non ditelo al mio vecchio team IT). Per questa lista, mi sono concentrato su:
- Affidabilità: funziona davvero, anche su siti difficili?
- Velocità: quanto rapidamente restituisce risultati su larga scala?
- Prezzi: è conveniente per le startup e scalabile per le aziende?
- Scalabilità: regge milioni di richieste o crolla a 100?
- Facilità per gli sviluppatori: la documentazione è chiara? Ci sono SDK ed esempi di codice?
- Supporto: quando qualcosa va storto (e succederà), c’è assistenza?
- Feedback degli utenti: recensioni reali, non solo fumo di marketing.
Mi sono affidato molto anche ai test pratici, all’analisi delle recensioni e ai feedback della community di Thunderbit (siamo un gruppo piuttosto esigente).
Le 10 API da considerare nel 2026
Pronto per il piatto forte? Ecco la mia lista aggiornata delle migliori API e piattaforme di web scraping per utenti business e sviluppatori nel 2026.
1. Oxylabs
 Panoramica:
Panoramica:
Oxylabs è il campione dei pesi massimi per l’estrazione di dati web di livello enterprise. Con un enorme pool di proxy e API specializzate per tutto, dalle SERP all’e-commerce, è la scelta ideale per le aziende Fortune 500 e per chiunque abbia bisogno di affidabilità su larga scala.
Funzionalità principali:
- Enorme rete di proxy (residential, datacenter, mobile, ISP) in oltre 195 paesi
- API di scraping con anti-bot, risoluzione dei CAPTCHA e rendering tramite browser headless
- Geo-targeting, persistenza della sessione e alta accuratezza dei dati (tassi di successo oltre il 95%)
- OxyCopilot: assistente IA che genera automaticamente codice di parsing e query API
Prezzi:
Si parte da circa 49 $/mese per una singola API, 149 $/mese per l’accesso all-in-one. Include una prova gratuita di 7 giorni con fino a 5.000 richieste.
Feedback degli utenti:
Valutato , apprezzato per affidabilità e supporto. Il principale svantaggio? È costoso, ma si ottiene ciò per cui si paga.
2. ScrapingBee
 Panoramica:
Panoramica:
ScrapingBee è il migliore amico degli sviluppatori — semplice, conveniente e mirato. Invia un URL, lui gestisce Chrome headless, proxy e CAPTCHA, e ti restituisce la pagina renderizzata o solo i dati che ti servono.
Funzionalità principali:
- Rendering con browser headless (supporto JavaScript)
- Rotazione automatica degli IP e risoluzione dei CAPTCHA
- Pool di proxy stealth per i siti più ostici
- Configurazione minima — basta una chiamata API
Prezzi:
Piano gratuito con circa 1.000 chiamate/mese. I piani a pagamento partono da circa 29 $/mese per 5.000 richieste.
Feedback degli utenti:
Costantemente . Gli sviluppatori amano la semplicità; chi non programma potrebbe trovarlo un po’ troppo essenziale.
3. Apify
 Panoramica:
Panoramica:
Apify è il coltellino svizzero del web scraping. Puoi creare scraper personalizzati (“Actors”) in JavaScript o Python, oppure usare la sua vasta libreria di actor già pronti per i siti più popolari. È flessibile quanto ti serve.
Funzionalità principali:
- Scraper personalizzati e predefiniti (Actors) per quasi qualsiasi sito
- Infrastruttura cloud, pianificazione ed gestione proxy incluse
- Esportazione dati in JSON, CSV, Excel, Google Sheets e altro ancora
- Community attiva e supporto su Discord
Prezzi:
Piano gratuito per sempre con 5 $/mese di crediti. I piani a pagamento partono da 39 $/mese.
Feedback degli utenti:
. Gli sviluppatori amano la flessibilità; per chi è all’inizio, la curva di apprendimento è ripida.
4. Decodo (ex Smartproxy)
 Panoramica:
Panoramica:
Decodo (rinominato da Smartproxy) punta tutto su valore e semplicità. Combina una solida infrastruttura proxy con API di scraping per il web generale, SERP, e-commerce e social media — tutto sotto un unico abbonamento.
Funzionalità principali:
- API di scraping unificata per tutti gli endpoint (niente più componenti aggiuntivi separati)
- Scraper specializzati per Google, Amazon, TikTok e altro ancora
- Dashboard intuitiva con playground e generatori di codice
- Supporto via chat live 24/7
Prezzi:
Si parte da circa 50 $/mese per 25.000 richieste. Prova gratuita di 7 giorni con 1.000 richieste.
Feedback degli utenti:
Apprezzato per il rapporto qualità-prezzo e per il supporto rapido. .
5. Octoparse
 Panoramica:
Panoramica:
Octoparse è il campione del no-code. Se odi programmare ma ami i dati, questa app desktop point-and-click (con funzioni cloud) ti permette di costruire scraper in modo visuale ed eseguirli in locale o nel cloud.
Funzionalità principali:
- Costruttore visuale dei flussi di lavoro — basta cliccare per selezionare i campi dati
- Estrazione cloud, pianificazione e rotazione automatica degli IP
- Modelli per siti popolari e marketplace per scraper personalizzati
- Octoparse AI: integra RPA e ChatGPT per la pulizia dei dati e l’automazione dei flussi di lavoro
Prezzi:
Piano gratuito fino a 10 task locali. I piani a pagamento partono da 119 $/mese (funzioni cloud, task illimitati). Prova gratuita di 14 giorni per le funzionalità premium.
Feedback degli utenti:
. Amato da chi non programma, ma gli utenti avanzati potrebbero raggiungere i limiti.
6. Bright Data
 Panoramica:
Panoramica:
Bright Data è il grande capo — se ti servono scala, velocità e tutte le funzionalità immaginabili, questa è la tua piattaforma. Con la rete proxy più grande al mondo e un potente IDE per lo scraping, è costruita per l’enterprise.
Funzionalità principali:
- Oltre 150 milioni di IP (residential, mobile, ISP, datacenter)
- Web Scraper IDE, collector di dati preconfigurati e dataset pronti all’acquisto
- Supporto avanzato anti-bot, risoluzione dei CAPTCHA e browser headless
- Forte attenzione alla conformità e agli aspetti legali (iniziativa Ethical Web Data)
Prezzi:
Pay-as-you-go: circa 1,05 $ per 1.000 richieste, proxy da 3–15 $/GB. Prove gratuite per la maggior parte dei prodotti.
Feedback degli utenti:
Apprezzato per prestazioni e funzionalità, ma prezzi e complessità possono essere un ostacolo per i team più piccoli.
7. WebAutomation
 Panoramica:
Panoramica:
WebAutomation è una piattaforma cloud pensata per chi non sviluppa. Con un marketplace di estrattori già pronti e un builder no-code, è perfetta per gli utenti business che vogliono i dati, non il codice.
Funzionalità principali:
- Estrattori preconfigurati per siti popolari (Amazon, Zillow, ecc.)
- Builder no-code con interfaccia point-and-click
- Pianificazione cloud, consegna dei dati e manutenzione incluse
- Prezzi basati sulle righe (paghi ciò che estrai)
Prezzi:
Piano progetto a 74 $/mese (~400k righe/anno), pay-as-you-go a 1 $ per 1.000 righe. Prova gratuita di 14 giorni con 10 milioni di crediti.
Feedback degli utenti:
Gli utenti amano la facilità d’uso e la trasparenza dei prezzi. Il supporto è utile e la manutenzione è gestita dal team.
8. ScrapeHero
 Panoramica:
Panoramica:
ScrapeHero è nato come consulenza per lo scraping su misura e oggi offre una piattaforma cloud self-service. Puoi usare scraper predefiniti per i siti più popolari o richiedere progetti completamente gestiti.
Funzionalità principali:
- ScrapeHero Cloud: scraper preconfigurati per Amazon, Google Maps, LinkedIn e altro
- Operatività no-code, pianificazione e consegna cloud
- Soluzioni personalizzate per esigenze specifiche
- Accesso API per l’integrazione programmatica
Prezzi:
I piani cloud partono da soli 5 $/mese. Progetti personalizzati da 550 $ per sito (una tantum).
Feedback degli utenti:
Apprezzato per affidabilità, qualità dei dati e supporto. Ottimo per passare da soluzioni fai-da-te a soluzioni gestite.
9. Sequentum
 Panoramica:
Panoramica:
Sequentum è il coltellino svizzero per l’enterprise — costruito per conformità, tracciabilità e scala massiccia. Se ti servono certificazione SOC-2, audit trail e collaborazione di team, questo è lo strumento giusto.
Funzionalità principali:
- Designer di agenti low-code (point-and-click più scripting)
- SaaS cloud o distribuzione on-premise
- Gestione proxy, risoluzione CAPTCHA e browser headless integrati
- Audit trail, accesso basato sui ruoli e conformità SOC-2
Prezzi:
Pay-as-you-go (6 $/ora di esecuzione, 0,25 $/GB di export), piano Starter a 199 $/mese. 5 $ di credito gratuiti alla registrazione.
Feedback degli utenti:
Le aziende amano le funzioni di conformità e la scalabilità. La curva di apprendimento c’è, ma supporto e formazione sono eccellenti.
10. Grepsr
 Panoramica:
Panoramica:
Grepsr è un servizio gestito di estrazione dati — devi solo dire cosa ti serve e loro costruiscono, eseguono e mantengono gli scraper per te. Perfetto per le aziende che vogliono i dati senza la fatica tecnica.
Funzionalità principali:
- Estrazione gestita (“Grepsr Concierge”) — impostano e mantengono tutto loro
- Dashboard cloud per pianificazione, monitoraggio e download dei dati
- Molteplici formati di output e integrazioni (Dropbox, S3, Google Drive)
- Pagamento per record dati (non per richiesta)
Prezzi:
Starter pack a 350 $ (estrazione una tantum), gli abbonamenti ricorrenti hanno preventivo personalizzato.
Feedback degli utenti:
I clienti apprezzano l’esperienza hands-off e il supporto reattivo. Ottimo per team non tecnici e per chi dà più valore al tempo che agli esperimenti.
Tabella rapida di confronto: le principali API di Web Scraping
Ecco il riassunto di tutte le 10 piattaforme:
| Piattaforma | Tipi di dati supportati | Prezzo iniziale | Prova gratuita | Facilità d’uso | Supporto | Funzionalità notevoli |
|---|---|---|---|---|---|---|
| Oxylabs | Web, SERP, e-commerce, immobiliare | 49 $/mese | 7 giorni/5k richieste | Orientata agli sviluppatori | 24/7, enterprise | OxyCopilot AI, enorme pool proxy, geo-targeting |
| ScrapingBee | Web generale, JS, CAPTCHA | 29 $/mese | 1k chiamate/mese | API semplice | Email, forum | Chrome headless, proxy stealth |
| Apify | Qualsiasi web, predefinito/personalizzato | Gratis/39 $/mese | Gratis per sempre | Flessibile, complesso | Community, Discord | Marketplace di actor, infrastruttura cloud, integrazioni |
| Decodo | Web, SERP, e-commerce, social | 50 $/mese | 7 giorni/1k richieste | Facile da usare | Chat live 24/7 | API unificata, playground per codice, ottimo valore |
| Octoparse | Qualsiasi web, no-code | Gratis/119 $/mese | 14 giorni | Visuale, no-code | Email, forum | Interfaccia point-and-click, cloud, Octoparse AI |
| Bright Data | Tutto il web, dataset | 1,05 $/1k richieste | Sì | Potente, complesso | 24/7, enterprise | La rete proxy più grande, IDE, dataset pronti |
| WebAutomation | Strutturati, e-commerce, immobiliare | 74 $/mese | 14 giorni/10M righe | No-code, modelli | Email, chat | Estrattori preconfigurati, prezzi basati sulle righe |
| ScrapeHero | E-commerce, mappe, lavoro, personalizzato | 5 $/mese | Sì | No-code, gestito | Email, ticket | Scraper cloud, progetti personalizzati, consegna via Dropbox |
| Sequentum | Qualsiasi web, enterprise | 0 $/199 $/mese | 5 $ di credito | Low-code, visuale | Supporto dedicato | Audit trail, SOC-2, on-prem/cloud |
| Grepsr | Qualsiasi strutturato, gestito | 350 $ una tantum | Esecuzione di esempio | Completamente gestito | Referente dedicato | Configurazione concierge, pagamento per dati, integrazioni |
Scegliere lo strumento di Web Scraping giusto per la tua azienda
Allora, quale strumento dovresti scegliere? Ecco come lo valuterei per i team che seguo:
-
Se vuoi zero codice, risultati immediati e pulizia dei dati basata sull’IA:
Scegli . È la strada più rapida da “mi servono dei dati” a “ho i miei dati” — senza dover sorvegliare script o API.
-
Se sei uno sviluppatore che ama controllo e flessibilità:
Prova Apify, ScrapingBee o Oxylabs. Ti offrono grande potenza, ma dovrai gestire un po’ di configurazione e manutenzione.
-
Se sei un utente business che vuole uno strumento visuale:
WebAutomation è fantastico per lo scraping point-and-click, soprattutto per e-commerce e lead generation.
-
Se ti servono conformità, tracciabilità o funzionalità enterprise:
Sequentum è pensato per te. Costa di più, ma ne vale la pena nei settori regolamentati.
-
Se vuoi solo che qualcun altro gestisca tutto:
I servizi gestiti di Grepsr o ScrapeHero sono la scelta giusta. Paghi un po’ di più, ma la tua pressione sanguigna ti ringrazierà.
E se hai ancora dubbi, la maggior parte di queste piattaforme offre prove gratuite — quindi prova e confronta!
Punti chiave
- Le API di web scraping sono ormai essenziali per le aziende orientate ai dati — il mercato dovrebbe arrivare a .
- Lo scraping manuale è superato — tra anti-bot, proxy e cambiamenti dei siti, le API e gli strumenti IA sono l’unico modo per scalare.
- Ogni API/piattaforma ha i suoi punti di forza:
- Oxylabs e Bright Data per scala e affidabilità
- Apify per la flessibilità
- Decodo per il valore
- WebAutomation per il no-code
- Sequentum per la conformità
- Grepsr per i dati gestiti senza pensieri
- L’automazione basata sull’IA (come Thunderbit) sta cambiando le regole del gioco — offrendo tassi di successo più alti, nessuna manutenzione e un’elaborazione dati integrata che le API tradizionali non possono eguagliare.
- Lo strumento migliore è quello che si adatta al tuo flusso di lavoro, al tuo budget e alle tue competenze tecniche. Non aver paura di sperimentare!
Se sei pronto a lasciarti alle spalle script rotti e debug infiniti, prova — oppure scopri altre guide sul per approfondimenti su come estrarre dati da Amazon, Google, PDF e altro ancora.
E ricorda: nel mondo dei dati web, l’unica cosa che cambia più velocemente dei siti stessi è la tecnologia che usiamo per estrarli. Rimani curioso, resta automatizzato e che i tuoi proxy non vengano mai bloccati.