
Il web trabocca di dati e, diciamolo chiaramente, nessuno ha il tempo di copiare e incollare migliaia di schede prodotto o pagine prezzi dei concorrenti. Se usi Linux (come me per gran parte del mio lavoro di automazione e sviluppo), sai già che questa piattaforma è una potenza per i team data-driven. In effetti, e . Ma ecco il problema: trovare il giusto estrattore Web per Linux che si adatti davvero al tuo flusso di lavoro—che tu sia un utente business non tecnico o uno sviluppatore esperto—può sembrare come cercare un ago in un pagliaio.
Per questo ho raccolto questo approfondimento sui 18 migliori strumenti di web scraping per Linux nel 2026. Dalle soluzioni AI no-code come (sì, quello che abbiamo creato io e il mio team) ai classici framework per sviluppatori come Scrapy e Beautiful Soup, questa lista è la scorciatoia per scegliere il miglior estrattore Web per Linux in base alle tue esigenze—senza il fastidio di tentativi ed errori.
Perché gli strumenti di web scraping per Linux sono importanti per gli utenti business
Diciamolo chiaramente: raccogliere dati a mano uccide la produttività. Gli studi mostrano che i team che si affidano al copia-incolla perdono ore ogni settimana e accumulano tassi di errore vicini al 5%—una ricetta perfetta per sbagli costosi e occasioni mancate (). Linux, con la sua stabilità, sicurezza e flessibilità, è la piattaforma ideale per eseguire scraper che devono funzionare 24/7—che tu sia su desktop, server o cloud.
Casi d’uso business comuni per gli strumenti di web scraping per Linux:
- Generazione di lead: i team sales estraggono contatti freschi da directory, social media o siti di recensioni, evitando il lavoro manuale ().
- Monitoraggio prezzi: i team e-commerce raccolgono automaticamente prezzi e disponibilità dei concorrenti, mantenendo la propria strategia sempre aggiornata e competitiva.
- Analisi competitor: i team marketing e operations monitorano lanci di prodotto, recensioni e keyword SEO—niente più lavoro “al buio”.
- Market intelligence: gli analisti aggregano notizie, forum e dati social per individuare trend in tempo reale.
- Automazione dei workflow: alcuni strumenti (soprattutto quelli AI) possono persino automatizzare flussi web, come compilare moduli o navigare dashboard, direttamente dalla tua macchina Linux.
La parte migliore? Lo strumento giusto per il web scraping su Linux può mettere nelle mani degli utenti non tecnici—non solo dei programmatori—la possibilità di accedere ai dati del web e sfruttarli per decisioni aziendali più intelligenti e rapide.
Come abbiamo selezionato il miglior estrattore Web per Linux
Non tutti gli scraper sono uguali, soprattutto su Linux. Ecco cosa ho cercato:
- Compatibilità con Linux: ogni strumento qui funziona nativamente su Linux, via browser, oppure con un semplice workaround (come Wine o l’accesso cloud).
- Facilità d’uso: dai prompt AI in linguaggio naturale alle interfacce visuali point-and-click, ho dato priorità agli strumenti che permettono anche ai non sviluppatori di ottenere risultati rapidamente—senza dimenticare gli utenti avanzati che vogliono il controllo totale.
- Potenza di estrazione dati: sa gestire contenuti dinamici, paginazione, sottopagine e diversi tipi di dati? Resiste ai trucchi anti-scraping?
- Scalabilità e automazione: pianificazione, scraping cloud, crawling distribuito—sono requisiti fondamentali per progetti dati seri.
- Integrazione ed esportazione: CSV, Excel, Google Sheets, API—se non riesci a estrarre i dati, qual è il punto?
- Prezzo e licenza: gratis, open source o a pagamento—c’è un’opzione per ogni budget, dai fondatori solitari ai team enterprise.
- Community e supporto: una base utenti attiva, buona documentazione e supporto reattivo fanno un’enorme differenza quando incontri un intoppo.
Ho incluso anche feedback reali degli utenti, recensioni del settore e la mia esperienza diretta con questi strumenti. Entriamo nella lista.
1. Thunderbit
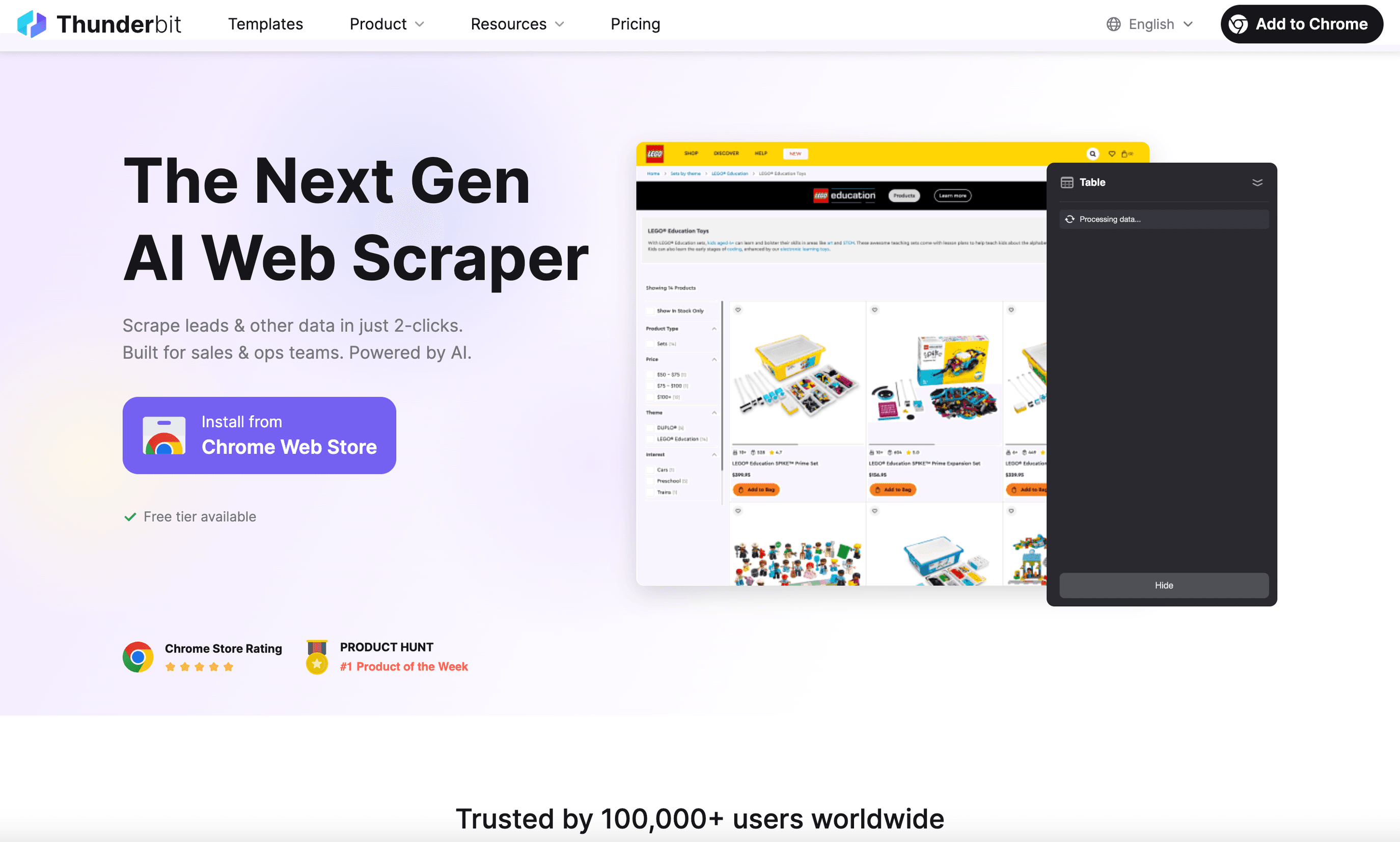 è la mia prima scelta per gli utenti business che vogliono un estrattore Web per Linux davvero facile da usare. Come , funziona perfettamente su Linux (basta aprire Chrome o Chromium) e ti permette di estrarre dati da qualsiasi sito in soli due clic.
è la mia prima scelta per gli utenti business che vogliono un estrattore Web per Linux davvero facile da usare. Come , funziona perfettamente su Linux (basta aprire Chrome o Chromium) e ti permette di estrarre dati da qualsiasi sito in soli due clic.
Cosa distingue Thunderbit:
- Prompt in linguaggio naturale: descrivi semplicemente ciò che vuoi (“Estrai tutti i nomi dei prodotti e i prezzi da questa pagina”) e l’AI di Thunderbit fa il resto.
- Suggerimento campi con AI: fai clic una volta e Thunderbit analizza la pagina, proponendo colonne e tipi di dati—senza selezione manuale dei campi.
- Estrazione di sottopagine e paginazione: ti servono più dettagli? Thunderbit può visitare ogni sottopagina (come le pagine dettaglio prodotto) e arricchire automaticamente la tua tabella.
- Estrazione cloud o locale: estrai fino a 50 pagine alla volta nel cloud, oppure usa la modalità browser per i siti che richiedono l’accesso.
- Esportazione istantanea: export con un clic su Excel, Google Sheets, Airtable, Notion, CSV o JSON—sempre gratis.
- Strumenti extra: estrai email, numeri di telefono e immagini con un solo clic. L’AI autofill può anche automatizzare l’inserimento nei moduli.
Prezzo: piano gratuito (estrae 6–10 pagine), piani a pagamento a partire da 15 $/mese per 500 righe (). Gli utenti adorano il fatto che “non richiede alcuna curva di apprendimento” e che “trasforma ore di lavoro in minuti” (). Per lavori di grandi dimensioni, potrebbe essere necessario suddividerli in esecuzioni più piccole, ma per la maggior parte dei casi d’uso business è un enorme risparmio di tempo.
Compatibilità Linux: 100%. Basta usare Chrome/Chromium sul tuo desktop o server Linux.
Ideale per: utenti business non tecnici (sales, marketing, operations) che vogliono la configurazione più rapida e semplice.
2. Scrapy
 è lo standard di riferimento per gli sviluppatori Python che vogliono un estrattore Web per Linux flessibile e scalabile. È open source, velocissimo (crawling asincrono) e può gestire tutto, dalle estrazioni semplici ai crawling distribuiti su larga scala.
è lo standard di riferimento per gli sviluppatori Python che vogliono un estrattore Web per Linux flessibile e scalabile. È open source, velocissimo (crawling asincrono) e può gestire tutto, dalle estrazioni semplici ai crawling distribuiti su larga scala.
Funzionalità principali:
- Crawling asincrono e ad alta velocità—perfetto per estrarre migliaia di pagine.
- Altamente estensibile: plugin per proxy, CAPTCHA e altro.
- Si integra con lo stack dati Python: output in JSON, CSV, database o pandas.
- Gestisce cookie, sessioni e auto-throttling.
Prezzo: completamente gratis e open source.
Compatibilità Linux: nativa (installazione via pip). Funziona benissimo su server e container.
Ideale per: sviluppatori che costruiscono scraper personalizzati su larga scala.
Nota: per i non sviluppatori c’è una curva di apprendimento, ma se conosci Python, Scrapy è difficile da battere.
3. Beautiful Soup
 è una libreria Python leggera per analizzare HTML e XML. È la soluzione ideale per scraping rapidi e sporchi o per ripulire pagine web disordinate.
è una libreria Python leggera per analizzare HTML e XML. È la soluzione ideale per scraping rapidi e sporchi o per ripulire pagine web disordinate.
Funzionalità principali:
- API semplice e intuitiva—ottima per chi inizia.
- Si abbina bene a requests per recuperare le pagine.
- Gestisce con grazia l’HTML danneggiato.
Prezzo: gratis e open source.
Compatibilità Linux: 100% (Python puro).
Ideale per: sviluppatori e data scientist che fanno task di scraping o parsing di piccole e medie dimensioni.
Limiti: non gestisce JavaScript o contenuti dinamici—abbinala a Selenium o Puppeteer se ti serve.
4. Selenium
 è il classico framework per l’automazione del browser. Ti permette di controllare Chrome, Firefox o altri browser per fare scraping di siti dinamici e ricchi di JavaScript.
è il classico framework per l’automazione del browser. Ti permette di controllare Chrome, Firefox o altri browser per fare scraping di siti dinamici e ricchi di JavaScript.
Funzionalità principali:
- Automatizza browser reali—può fare login, cliccare, scorrere e interagire come un essere umano.
- Supporta Python, Java, C# e altro.
- Modalità headless per l’esecuzione su server Linux.
Prezzo: gratis e open source.
Compatibilità Linux: supporto completo (basta installare il driver del browser giusto).
Ideale per: QA engineer, sviluppatori di scraping e chiunque debba simulare il comportamento di un utente.
Nota: richiede molte risorse ed è più lento dei puri scraper HTTP, ma a volte è l’unico modo per ottenere i dati che ti servono.
5. Puppeteer
 è una libreria Node.js di Google per controllare Chrome/Chromium headless. È simile a Selenium, ma con una moderna API JavaScript e una forte integrazione con le funzionalità di Chrome.
è una libreria Node.js di Google per controllare Chrome/Chromium headless. È simile a Selenium, ma con una moderna API JavaScript e una forte integrazione con le funzionalità di Chrome.
Funzionalità principali:
- Esegue JavaScript, gestisce contenuti dinamici e cattura screenshot.
- Veloce, stabile e facile da usare per gli sviluppatori Node.js.
- Intercetta le richieste di rete e blocca le risorse indesiderate.
Prezzo: gratis e open source.
Compatibilità Linux: installa Chromium automaticamente; funziona headless di default.
Ideale per: sviluppatori che estraggono dati da web app moderne o single-page site.
6. Octoparse
 è un estrattore Web no-code con interfaccia drag-and-drop e tantissimi template predefiniti. Anche se l’app desktop è disponibile solo per Windows/Mac, gli utenti Linux possono accedere alla piattaforma cloud di Octoparse via browser oppure eseguire l’app Windows con Wine.
è un estrattore Web no-code con interfaccia drag-and-drop e tantissimi template predefiniti. Anche se l’app desktop è disponibile solo per Windows/Mac, gli utenti Linux possono accedere alla piattaforma cloud di Octoparse via browser oppure eseguire l’app Windows con Wine.
Funzionalità principali:
- Oltre 100 template di scraping pronti all’uso per siti come Amazon, eBay, Zillow e altri.
- Designer visivo dei workflow—point-and-click per costruire il tuo scraper.
- Scraping e pianificazione nel cloud—lascia che siano i server di Octoparse a fare il lavoro pesante.
- Esporta in Excel, CSV, JSON e database.
Prezzo: piano gratuito (funzioni limitate), piani a pagamento da 75–89 $/mese.
Compatibilità Linux: accesso cloud/web; app desktop tramite Wine.
Ideale per: non sviluppatori che hanno bisogno rapidamente di dati da e-commerce o marketplace.
7. PhantomJS
 è un browser WebKit headless che un tempo era la soluzione di riferimento per l’automazione leggera del browser. Oggi è deprecato, ma funziona ancora su Linux per attività legacy o semplici.
è un browser WebKit headless che un tempo era la soluzione di riferimento per l’automazione leggera del browser. Oggi è deprecato, ma funziona ancora su Linux per attività legacy o semplici.
Funzionalità principali:
- Scriptabile in JavaScript.
- Gestisce una moderata quantità di JavaScript e cattura screenshot/PDF.
- Non serve alcuna GUI.
Prezzo: gratis e open source.
Compatibilità Linux: binario nativo.
Ideale per: progetti legacy o ambienti in cui non è possibile installare Chrome.
Attenzione: non è più mantenuto—i siti moderni potrebbero non funzionare bene.
8. ParseHub
 è un estrattore Web visivo e multipiattaforma con app nativa per Linux. È perfetto per i non sviluppatori che vogliono estrarre siti complessi e dinamici.
è un estrattore Web visivo e multipiattaforma con app nativa per Linux. È perfetto per i non sviluppatori che vogliono estrarre siti complessi e dinamici.
Funzionalità principali:
- Interfaccia point-and-click—seleziona gli elementi e costruisci i workflow in modo visivo.
- Gestisce contenuti dinamici, mappe, scroll infinito e altro.
- Esecuzione nel cloud e pianificazione.
- Esporta in CSV, JSON o tramite API.
Prezzo: piano gratuito (5 progetti), piani a pagamento da 189 $/mese.
Compatibilità Linux: app nativa per Linux, Windows e Mac.
Ideale per: analisti e utenti semi-tecnici che vogliono controllo senza programmare.
9. Kimurai
 è un framework Ruby per il web scraping che supporta Linux in modo nativo. È come Scrapy, ma per gli sviluppatori Ruby.
è un framework Ruby per il web scraping che supporta Linux in modo nativo. È come Scrapy, ma per gli sviluppatori Ruby.
Funzionalità principali:
- Supporto multi-browser: Chrome headless, Firefox, PhantomJS o HTTP puro.
- Elaborazione asincrona per alta concorrenza.
- DSL Ruby pulito per scrivere spider.
Prezzo: gratis e open source.
Compatibilità Linux: 100% (Ruby).
Ideale per: sviluppatori Ruby o team Rails che hanno bisogno di scraping personalizzato ad alta concorrenza.
10. Apify
 è una piattaforma cloud per il web scraping con SDK open source e un marketplace di “actor” già pronti. Puoi eseguire gli scraper sulla tua macchina Linux o nel cloud.
è una piattaforma cloud per il web scraping con SDK open source e un marketplace di “actor” già pronti. Puoi eseguire gli scraper sulla tua macchina Linux o nel cloud.
Funzionalità principali:
- SDK per Node.js, Python e altro.
- Marketplace di scraper predefiniti.
- Esecuzione nel cloud, pianificazione e integrazione API.
Prezzo: piano gratuito, pagamento a consumo per l’uso cloud.
Compatibilità Linux: CLI/SDK funzionano su Linux; piattaforma cloud accessibile via browser.
Ideale per: sviluppatori che vogliono un mix di codice personalizzato e infrastruttura cloud pronta all’uso.
11. Colly
 è un framework Go per il web scraping costruito per velocità ed efficienza. Se sei uno sviluppatore Go, questo è il tuo strumento.
è un framework Go per il web scraping costruito per velocità ed efficienza. Se sei uno sviluppatore Go, questo è il tuo strumento.
Funzionalità principali:
- Scraping super veloce e concorrente—oltre 1.000 richieste/sec su un singolo core.
- Crawling “educato” (rispetta robots.txt), gestione di sessioni e cookie.
- Ingombro di memoria ridotto.
Prezzo: gratis e open source.
Compatibilità Linux: binari Go nativi.
Ideale per: sviluppatori Go che hanno bisogno di scraping ad alte prestazioni.
12. PySpider
 è un sistema Python per il web crawling con interfaccia web. Puoi gestire, pianificare e monitorare i crawl dal browser.
è un sistema Python per il web crawling con interfaccia web. Puoi gestire, pianificare e monitorare i crawl dal browser.
Funzionalità principali:
- Interfaccia web per scripting e monitoraggio.
- Crawling distribuito, pianificazione e retry.
- Si integra con database e code di messaggi.
Prezzo: gratis e open source.
Compatibilità Linux: progettato per il deployment su Linux.
Ideale per: team che gestiscono più progetti di scraping tramite una UI web.
13. WebHarvy
 è un estrattore visuale point-and-click per Windows, ma gli utenti Linux possono eseguirlo tramite Wine. È noto per il rilevamento dei pattern e il modello di acquisto una tantum.
è un estrattore visuale point-and-click per Windows, ma gli utenti Linux possono eseguirlo tramite Wine. È noto per il rilevamento dei pattern e il modello di acquisto una tantum.
Funzionalità principali:
- Naviga e clicca per selezionare i dati—senza programmare.
- Rilevamento automatico dei pattern per le liste.
- Esporta in CSV, JSON, XML, SQL.
Prezzo: licenza una tantum di circa 139 $.
Compatibilità Linux: esegue tramite Wine o VM.
Ideale per: principianti o professionisti solitari che vogliono uno scraper rapido e visuale.
14. OutWit Hub
 è un’applicazione GUI nativa per Linux per il web scraping. Riconosce automaticamente i pattern dei dati e offre potenti funzioni di estrazione e automazione.
è un’applicazione GUI nativa per Linux per il web scraping. Riconosce automaticamente i pattern dei dati e offre potenti funzioni di estrazione e automazione.
Funzionalità principali:
- Rileva automaticamente link, immagini, tabelle, email e altro.
- Editor di script per estrazioni personalizzate.
- Automazione con macro e pianificazione.
Prezzo: versione gratuita (limitata), licenza Pro circa 50–100 $.
Compatibilità Linux: app nativa per Linux, Windows e Mac.
Ideale per: non sviluppatori con una certa inclinazione tecnica che vogliono uno scraper desktop con GUI.
15. Portia
 è un estrattore Web visivo open source di Scrapinghub. Funziona nel browser e ti permette di annotare le pagine per addestrare gli scraper.
è un estrattore Web visivo open source di Scrapinghub. Funziona nel browser e ti permette di annotare le pagine per addestrare gli scraper.
Funzionalità principali:
- Interfaccia basata su browser per l’estrazione visiva.
- Si integra con Scrapy per progetti personalizzati.
- Open source ed estensibile.
Prezzo: gratis e open source.
Compatibilità Linux: basato su browser; funziona su qualsiasi sistema operativo.
Ideale per: utenti che vogliono scraping visivo open source con integrazione Scrapy.
16. Content Grabber
 è un estrattore visuale di livello enterprise per Windows, ma può essere eseguito su Linux tramite Wine o virtualizzazione.
è un estrattore visuale di livello enterprise per Windows, ma può essere eseguito su Linux tramite Wine o virtualizzazione.
Funzionalità principali:
- Editor visuale più scripting C# per logiche avanzate.
- Gestione multi-agent e pianificazione.
- Si integra con database, API e altro.
Prezzo: licenze nell’ordine delle migliaia; edizione server da 69 $/mese.
Compatibilità Linux: tramite Wine o VM.
Ideale per: agenzie e grandi team che gestiscono molti progetti di scraping.
17. Helium
 è una libreria Python che semplifica l’automazione con Selenium. È progettata per rendere lo scripting del browser più intuitivo e umano.
è una libreria Python che semplifica l’automazione con Selenium. È progettata per rendere lo scripting del browser più intuitivo e umano.
Funzionalità principali:
- Comandi intuitivi come
click("Login")owrite("email"). - Automatizza Chrome e Firefox.
- Ottima per scripting rapido e task di automazione.
Prezzo: gratis e open source.
Compatibilità Linux: funziona su Linux (basato su Selenium).
Ideale per: utenti Python che trovano Selenium troppo macchinoso.
18. Dexi.io
 è una piattaforma cloud per l’estrazione e l’automazione dei dati. È accessibile via browser, quindi gli utenti Linux possono usarla senza installare nulla.
è una piattaforma cloud per l’estrazione e l’automazione dei dati. È accessibile via browser, quindi gli utenti Linux possono usarla senza installare nulla.
Funzionalità principali:
- Designer visivo dei workflow per scraping e automazione.
- Pianificazione, trasformazione dei dati e integrazione API.
- Scalabilità e supporto di livello enterprise.
Prezzo: da 119 $/mese (Standard); livelli superiori per esigenze più grandi.
Compatibilità Linux: web app—funziona su qualsiasi sistema operativo.
Ideale per: professionisti e aziende che hanno bisogno di estrazione dati web scalabile e integrata.
Tabella di confronto rapido: strumenti di web scraping per Linux in sintesi
| Strumento | Tipo / Funzionalità chiave | Ideale per | Prezzo | Compatibilità Linux |
|---|---|---|---|---|
| Thunderbit | Estensione Chrome AI, 2 clic, sottopagine, cloud/locale | Utenti business non tecnici | Gratis, da 15 $/mese | ✔ Chrome su Linux |
| Scrapy | Framework Python, async, CLI, altamente estensibile | Sviluppatori, scraper personalizzati su larga scala | Gratis | ✔ Nativo |
| Beautiful Soup | Libreria Python, parsing semplice HTML/XML | Sviluppatori, data scientist, piccoli task | Gratis | ✔ Nativo |
| Selenium | Automazione browser, siti ricchi di JS | QA, sviluppatori, contenuti dinamici | Gratis | ✔ Nativo |
| Puppeteer | Node.js, Chrome headless, rendering JS | Sviluppatori Node, web app moderne | Gratis | ✔ Nativo |
| Octoparse | No-code, drag-and-drop, template cloud | Non sviluppatori, e-commerce | Gratis, da 75 $/mese | ◐ Cloud/Wine |
| PhantomJS | WebKit headless, JavaScript scriptabile | Legacy, leggero, senza Chrome | Gratis | ✔ Nativo |
| ParseHub | Visuale, multipiattaforma, point-and-click | Analisti, utenti semi-tecnici | Gratis, da 189 $/mese | ✔ Nativo |
| Kimurai | Framework Ruby, multi-browser, async | Sviluppatori Ruby, alta concorrenza | Gratis | ✔ Nativo |
| Apify | Piattaforma cloud, SDK, marketplace | Sviluppatori, ibrido custom/cloud | Piano gratuito, a consumo | ✔ Nativo/Cloud |
| Colly | Framework Go, veloce, concorrente | Sviluppatori Go, alte prestazioni | Gratis | ✔ Nativo |
| PySpider | Python, UI web, pianificazione, distribuito | Team, più progetti | Gratis | ✔ Nativo |
| WebHarvy | Visuale, rilevamento pattern, licenza una tantum | Principianti, professionisti singoli | Circa 139 $ una tantum | ◐ Wine/VM |
| OutWit Hub | GUI nativa, rilevamento automatico dati, scripting | Non sviluppatori, GUI desktop | Gratis, Pro 50–100 $ | ✔ Nativo |
| Portia | Open source, visuale, basato su browser | Open source, integrazione con Scrapy | Gratis | ✔ Browser |
| Content Grabber | Enterprise, visuale, scripting, multi-agent | Agenzie, grandi team | $$$, da 69 $/mese | ◐ Wine/VM |
| Helium | Python, Selenium semplificato, API intuitiva | Utenti Python, automazione rapida | Gratis | ✔ Nativo |
| Dexi.io | Cloud, workflow visivo, pianificazione, API | Enterprise, automazione scalabile | Da 119 $/mese | ✔ Browser |
Come scegliere il giusto estrattore Web per Linux: considerazioni chiave
Scegliere lo strumento giusto significa allinearlo alle tue esigenze e competenze:
- Livello di competenza tecnica: i non sviluppatori dovrebbero orientarsi verso Thunderbit, ParseHub, Octoparse o OutWit Hub. Gli sviluppatori possono ottenere più potenza con Scrapy, Puppeteer, Colly o Kimurai.
- Complessità dei dati: per pagine statiche, Beautiful Soup o Colly sono veloci e semplici. Per siti dinamici e ricchi di JavaScript, servono Selenium, Puppeteer o uno strumento visuale che supporti JS.
- Scala e frequenza: per lavori occasionali, vanno bene strumenti no-code o scraper cloud. Per crawl programmati e su larga scala, scegli Scrapy, PySpider o Apify.
- Esigenze di integrazione: ti serve esportare in Excel, Sheets o in un database? Assicurati che lo strumento supporti il tuo flusso di lavoro.
- Budget: per i programmatori ci sono molte opzioni gratuite e open source. Per gli utenti business, Thunderbit e ParseHub offrono punti di ingresso accessibili, mentre i team enterprise possono investire in Dexi.io o Content Grabber.
- Supporto e community: gli strumenti open source hanno grandi community; quelli commerciali offrono supporto dedicato.
Consiglio pro: non aver paura di combinare più strumenti. Usa Thunderbit per fare prototipi e individuare i pattern dei dati, poi passa a Scrapy per i crawl in produzione su larga scala. Oppure usa Selenium per fare login e recuperare i cookie di sessione, quindi passa a Colly o Scrapy per uno scraping ad alta velocità.
Conclusione: trova il miglior strumento di web scraping per Linux nel 2026
Nel 2026 gli utenti Linux hanno l’imbarazzo della scelta. Che tu voglia uno strumento no-code basato su AI che ti dia risultati in pochi minuti (Thunderbit), un robusto framework per sviluppatori (Scrapy, Colly) o una piattaforma di livello enterprise (Dexi.io), esiste un estrattore Web per Linux adatto alle tue esigenze e al tuo flusso di lavoro.
Punti chiave:
- Linux è la spina dorsale dell’infrastruttura dati moderna—la maggior parte dei migliori scraper funziona nativamente o via browser.
- Gli strumenti AI e no-code stanno democratizzando il web scraping per gli utenti business.
- I framework per sviluppatori restano imbattibili per flessibilità, velocità e scalabilità.
- Prova prima di acquistare—la maggior parte degli strumenti offre piani gratuiti o trial.
Pronto a iniziare? oppure visita il per altre guide su web scraping, automazione e crescita data-driven.
FAQ
1. Qual è l’estrattore Web più semplice per Linux se non so programmare?
è la scelta migliore per gli utenti non tecnici. Funziona come estensione Chrome su Linux, usa l’AI per automatizzare tutto e ti permette di estrarre dati in soli due clic.
2. Qual è il miglior estrattore Web per Linux per progetti personalizzati su larga scala?
è la soluzione di riferimento per gli sviluppatori. È veloce, scalabile e altamente personalizzabile—perfetto per crawl grandi e ricorrenti.
3. Posso estrarre siti dinamici o ricchi di JavaScript su Linux?
Sì! Usa o per controllare browser reali ed estrarre contenuti dinamici. Anche strumenti visuali come ParseHub e Thunderbit supportano siti dinamici.
4. Esistono strumenti gratuiti di web scraping per Linux adatti al business?
Assolutamente sì. Scrapy, Beautiful Soup, Selenium, Colly, PySpider e Kimurai sono tutti gratis e open source. Thunderbit e ParseHub offrono piani gratuiti per lavori più piccoli.
5. Come scelgo tra scraper Linux no-code e basati sul codice?
Se vuoi velocità e semplicità, scegli il no-code (Thunderbit, ParseHub, Octoparse). Se ti servono flessibilità, automazione o integrazione con altri sistemi, gli strumenti basati sul codice (Scrapy, Puppeteer, Colly) sono la scelta migliore.
Buon scraping—e che i tuoi progetti dati su Linux girino più fluidi di una nuova installazione di Ubuntu. Se vuoi altri consigli sul web scraping, visita il o iscriviti al nostro per tutorial pratici.
Scopri di più