

Il web trabocca di dati e, nel 2026, la corsa per trasformare quel caos in valore per il business è più intensa che mai. Ho visto team di sales, ecommerce e operations rivoluzionare i propri flussi di lavoro automatizzando attività che prima richiedevano ore di copia e incolla ripetitivo. Oggi, se non usi un software per l’estrazione di dati dal web, non stai solo restando indietro: probabilmente sei ancora bloccato in un purgatorio di fogli di calcolo mentre i tuoi concorrenti si stanno già bevendo il secondo caffè.
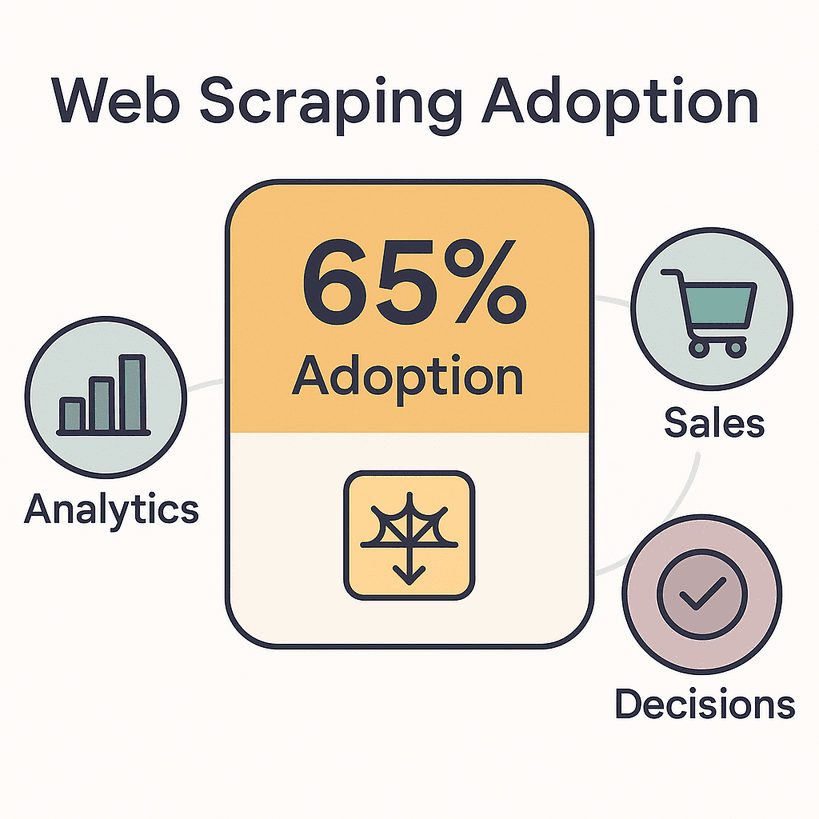
Ecco la realtà: il 65% delle aziende usa ormai strumenti di web scraping per alimentare analisi, vendite e processi decisionali. Il mercato globale dell’estrazione di dati dal web vale già oltre 1 miliardo di dollari ed è destinato a raddoppiare entro il 2030. I commerciali arrivano a spendere fino al 70% del loro tempo in attività non direttamente legate alla vendita, come inserimento dati e ricerca. È tantissimo tempo che potrebbe essere usato per chiudere trattative davvero — o almeno per godersi la pausa pranzo.

Quindi, qual è il miglior software per l’estrazione di dati dal web nel 2026? Ho analizzato a fondo i cinque strumenti migliori che stanno cambiando le regole del gioco per team di ogni dimensione e con diversi livelli di competenze tecniche. Che tu sia un non-coder che vuole solo cliccare e via, oppure uno sviluppatore in cerca della massima flessibilità, qui c’è qualcosa che fa per te.
Cosa rende migliore un software per l’estrazione di dati dal web?
Cos’è l’estrazione di dati e come farla nel 2025 Get Started Free
Diciamolo chiaramente: non tutti i web scraper sono uguali. Il miglior software per l’estrazione di dati dal web nel 2026 si distingue perché rende l’estrazione dei dati veloce, affidabile e accessibile a tutti — non solo a chi pensa in Python.
Ecco i criteri principali che considero io (e quelli che contano di più per chi usa questi strumenti in azienda):
- Facilità d’uso: gli utenti non tecnici possono configurare un’estrazione in pochi minuti? Per la maggior parte dei team servono interfacce no-code e basate su AI.
- Flessibilità delle fonti dati: gestisce pagine web, PDF, immagini e contenuti dinamici (come infinite scroll o AJAX)? Più fonti supporta, meglio è.
- Automazione e pianificazione: puoi programmare estrazioni ricorrenti, gestire la paginazione e automatizzare la navigazione tra sottopagine? L’automazione è ciò che separa il “impostalo e dimenticatene” dal “impostalo e poi controllalo di continuo”.
- Integrazione ed export: esporta direttamente in Excel, Google Sheets, Notion, Airtable o tramite API? Meno lavoro manuale significa un team più felice.
- Competenze tecniche richieste: è davvero no-code, o devi comunque ripassare le regex? I migliori strumenti parlano sia ai non-coder sia agli utenti esperti.
- Scalabilità: riesce a gestire l’estrazione da centinaia o migliaia di pagine senza battere ciglio?
- Supporto e community: ci sono documentazione valida, assistenza reattiva e una base utenti attiva?
Questi criteri non sono semplici optional: fanno la differenza tra strumenti che ti fanno risparmiare ore e quelli che ti fanno perdere giorni. Nel 2026, con quasi metà del traffico Internet generato dai bot, avere il giusto scraper è un vantaggio competitivo.
Ora tuffiamoci nei cinque migliori.
I 5 migliori software per l’estrazione di dati dal web nel 2026
- Thunderbit per estrazione no-code, basata su AI e multi-sorgente
- Import.io per pipeline dati integrate e di livello enterprise
- Scrapy per la massima flessibilità open source guidata dagli sviluppatori
- Octoparse per estrazione visiva no-code con pianificazione
- ParseHub per un’estrazione dati intuitiva, punto e clic
1. Thunderbit: il software più semplice per l’estrazione di dati dal web con AI
Estrai dati da qualsiasi sito web usando l’AI Get Started Free
Thunderbit è il mio consiglio di riferimento per chiunque voglia estrarre dati dal web senza scrivere nemmeno una riga di codice. E sì, sono un po’ di parte: ho aiutato a costruirlo. Ma ascoltami: Thunderbit è pensato per utenti business che vogliono risultati, non mal di testa.
Cosa rende Thunderbit speciale?
- AI Suggest Fields: basta cliccare su “AI Suggest Fields” e l’AI di Thunderbit legge la pagina, suggerisce cosa estrarre e configura lo scraper per te. Niente selettori, niente template, niente drammi.
- Estrazione multi-sorgente: puoi estrarre non solo pagine web, ma anche PDF e immagini. Thunderbit può recuperare testo, link, email, numeri di telefono e immagini — tutto in due clic.
- Automazione di sottopagine e paginazione: devi raccogliere i dettagli di ogni prodotto o profilo? Lo scraping delle sottopagine di Thunderbit segue i link, estrae le informazioni extra e le unisce nella tua tabella. Gestisce anche infinite scroll e paginazione da vero professionista.
- Estrazione in batch e pianificata: incolla una lista di URL, programma job ricorrenti e lascia che Thunderbit faccia il lavoro pesante — che si tratti di monitorare i prezzi ogni giorno o aggiornare i lead ogni settimana.
- Export immediato: esporta direttamente in Excel, Google Sheets, Airtable, Notion, CSV o JSON. Niente più maratone di copia e incolla.
- Prompt AI personalizzati: vuoi classificare, tradurre o etichettare i dati mentre li estrai? Aggiungi un’istruzione personalizzata e l’AI di Thunderbit se ne occupa.
- Modalità cloud o browser: esegui le estrazioni nel cloud per la massima velocità (50 pagine alla volta) oppure in locale per i siti che richiedono l’accesso.
Thunderbit è usato da oltre 30.000 utenti in tutto il mondo, dai team commerciali agli agenti immobiliari fino ai piccoli shop ecommerce indipendenti. Il piano gratuito consente di estrarre fino a 6 pagine (o 10 con un boost di prova), e paghi solo ciò che usi: un credito per ogni riga di output.
Perché mi piace: Thunderbit è l’unico strumento che ho visto in cui un utente non tecnico può passare da “mi servono questi dati” a “ecco il mio foglio di calcolo” in meno di cinque minuti. L’interfaccia è davvero intuitiva (ci abbiamo lavorato in modo ossessivo), e l’AI si adatta ai cambiamenti dei siti web, così non devi continuamente sistemare scraper rotti.
Ideale per: vendite, ecommerce, operations e chiunque voglia un’estrazione no-code, basata su AI e senza manutenzione.
Prova l’estensione Chrome di Thunderbit
Scopri il blog di Thunderbit per altre guide.
2. Import.io: estrazione di dati dal web e integrazione di livello enterprise
Import.io è il campione dei pesi massimi per le aziende che hanno bisogno di dati dal web su larga scala e di collegarli direttamente ai sistemi di business.
Cosa distingue Import.io?
- Pipeline pronte per l’enterprise: Import.io non è solo uno scraper; è una piattaforma completa per l’integrazione dei dati web. Pensa a un modello “data-as-a-service” con feed continui e automatizzati.
- AI auto-riparante: se un sito cambia, l’AI di Import.io prova a rimappare automaticamente i campi, così le tue pipeline non si rompono da un giorno all’altro.
- Automazione robusta: programma estrazioni ogni ora, ogni giorno o a intervalli personalizzati. Ricevi avvisi se qualcosa va storto o se i dati sembrano strani.
- Workflow interattivi: gestisce siti con login, moduli o navigazione multi-step. Import.io può registrare e riprodurre sequenze complesse.
- Compliance e governance: rilevamento automatico dei dati personali, mascheramento e audit log — fondamentali nei settori regolamentati.
- API e integrazione: trasmette i dati direttamente a Google Sheets, Excel, Tableau, Power BI, database o alle tue app via API.
Import.io è usato da brand come Unilever, Volvo e RedHat. È la scelta giusta per casi d’uso come il monitoraggio dei prezzi su migliaia di siti ecommerce, l’analisi di mercato o l’alimentazione di modelli AI/ML con dati web freschi.
Prezzo: Import.io è una soluzione premium, con prezzi che partono da circa 299 dollari al mese per i piani self-service. C’è una prova gratuita, ma non un livello free di lungo periodo. Se i dati web sono mission-critical, il ritorno sull’investimento c’è.
Ideale per: aziende e organizzazioni data-centric che hanno bisogno di affidabilità, scalabilità, compliance e integrazione profonda.
3. Scrapy: framework open source per l’estrazione di dati dal web per sviluppatori
Scrapy è una potenza open source per gli sviluppatori che vogliono flessibilità e controllo assoluti. Se tu (o il tuo team) sapete programmare in Python, Scrapy è il coltellino svizzero del web scraping.
Perché gli sviluppatori amano Scrapy:
- Personalizzazione totale: scrivi spider (script) per esplorare, analizzare e processare i dati esattamente come vuoi. Gestisci flussi multi-pagina, logiche personalizzate e pulizia dati complessa.
- Asincrono e veloce: l’architettura di Scrapy è progettata per velocità e scalabilità — puoi estrarre centinaia di pagine al minuto, o milioni con crawler distribuiti.
- Estensibile: enorme ecosistema di plugin e middleware per proxy, browser headless (Splash/Playwright) e integrazioni.
- Gratis e open source: nessun costo di licenza. Lo puoi eseguire su hardware tuo o nel cloud, e scalarlo quanto vuoi.
- Supporto della community: oltre 55.000 stelle su GitHub e una base utenti enorme. Se incappi in un problema, è probabile che qualcuno l’abbia già risolto.
Limiti: Scrapy richiede competenze Python e dimestichezza con la riga di comando. Qui non c’è alcuna interfaccia point-and-click: si parte dal codice. Ma per progetti personalizzati, dati di training per AI o crawling su larga scala, è difficile fare meglio.
Ideale per: organizzazioni con sviluppatori interni, pipeline dati personalizzate o esigenze di scraping complesse e di grandi dimensioni.
4. Octoparse: estrazione visiva di dati dal web semplice e immediata
Octoparse è uno dei preferiti dai non-coder che vogliono uno scraping potente con un’interfaccia visiva, punto e clic.
Perché Octoparse è così popolare:
- Visual workflow builder: clicca sugli elementi in un browser integrato e Octoparse rileva automaticamente i pattern. Niente codice: clicchi ed estrai.
- Gestisce contenuti dinamici: puoi estrarre siti con AJAX, infinite scroll e aree protette da login. Simula clic, scroll e invio di moduli.
- Cloud scraping e pianificazione: esegui le attività nel cloud (più veloce, in parallelo) e programma job ricorrenti per dati sempre aggiornati.
- Template predefiniti: centinaia di modelli per siti popolari (Amazon, Twitter, Zillow, ecc.) ti permettono di iniziare subito.
- Export e API: scarica i risultati come CSV, Excel, JSON oppure recupera i dati via API. Integrazione con Google Sheets o database.
Octoparse viene spesso descritto come “super facile da usare, anche per i principianti”. Il piano gratuito è limitato, ma quelli a pagamento (a partire da circa 83 dollari al mese) sbloccano esecuzioni cloud, pianificazione e più velocità.
Ideale per: utenti non tecnici, marketer, ricercatori e piccoli team che hanno bisogno di raccolta dati regolare e automatizzata senza programmare.
5. ParseHub: estrazione di dati semplice e alla portata di tutti
ParseHub è un altro favorito del no-code, soprattutto per piccole imprese e freelance che vogliono automatizzare attività dati di tutti i giorni.
Cosa rende ParseHub interessante:
- Semplicità punto e clic: selezioni i dati cliccando sugli elementi in una vista browser. Costruisci i workflow in modo visuale — non serve programmare.
- Gestisce siti JS e dinamici: estrae pagine pesanti in JavaScript, infinite scroll e navigazione multi-step.
- Esecuzioni cloud e locali: puoi eseguire le estrazioni sul desktop o nel cloud. Programma job ricorrenti e accedi ai risultati via API (nei piani superiori).
- Opzioni di export: scarica i dati in CSV, Excel o JSON. Accesso API per l’automazione.
- Cross-platform: disponibile per Windows, Mac e Linux.
Il piano gratuito di ParseHub è limitato (200 pagine per esecuzione), ma i piani a pagamento (a partire da circa 189 dollari al mese) sbloccano più potenza, velocità e accesso API.
Ideale per: piccole imprese, freelance e team con esigenze di scraping semplici che vogliono uno strumento affidabile e visuale.
Tabella comparativa: i migliori software per l’estrazione di dati dal web in sintesi
| Strumento | Facilità d'uso | Fonti dati | Automazione e pianificazione | Integrazione ed export | Competenze tecniche | Prezzo |
|---|---|---|---|---|---|---|
| Thunderbit | No-code, basato su AI | Web, PDF, immagini | Sottopagine, paginazione, pianificato, batch | Excel, Sheets, Notion, Airtable, CSV, JSON | Nessuna | Freemium (paghi per riga) |
| Import.io | Interfaccia punto e clic | Web (statico/dinamico, login) | Auto-riparante, pianificato, avvisi | API, strumenti BI, Sheets, Excel, DB | Basso–medio | 299+ $/mese |
| Scrapy | Serve codice | Web, API, (JS tramite add-on) | Automazione completa via codice | Qualsiasi cosa (tramite codice) | Sviluppatori Python | Gratis (open source) |
| Octoparse | Visuale, no-code | Web (dinamico, login) | Pianificazione cloud, template | CSV, Excel, JSON, API | Nessuna | 83+ $/mese |
| ParseHub | Visuale, no-code | Web (JS, dinamico) | Cloud/local, pianificato | CSV, Excel, JSON, API | Nessuna | 189+ $/mese |
Come scegliere il miglior software per l’estrazione di dati dal web per la tua azienda
Non sai quale strumento faccia al caso tuo? Ecco il mio schema rapido:
- Utenti non tecnici, risultati rapidi: scegli Thunderbit o Octoparse. Thunderbit è imbattibile per estrazioni immediate, basate su AI, e per il supporto multi-sorgente (web, PDF, immagini). Octoparse è ottimo per estrazioni visuali e pianificate.
- Integrazione enterprise, compliance e scala: Import.io è la scelta migliore. È costruito per pipeline dati continue, affidabili e profondamente integrate.
- Sviluppatori, progetti personalizzati o crawling massiccio: Scrapy è la strada giusta. Serve saper usare Python, ma la flessibilità è praticamente illimitata.
- Piccole imprese, freelance o attività quotidiane: ParseHub è una scelta solida e intuitiva per scraping punto e clic e automazione moderata.
Consigli per scegliere lo strumento giusto:
- Abbina lo strumento alle competenze tecniche del tuo team e alle esigenze sui dati.
- Considera la complessità dei siti che devi estrarre (contenuti dinamici? login?).
- Pensa a come userai i dati: ti serve un export diretto in Sheets o un’integrazione API profonda?
- Parti con una prova gratuita o un piano freemium per testare scenari reali.
- Non sottovalutare il valore di un supporto e di una documentazione di qualità.
Inizia a estrarre dati con Thunderbit
Conclusione: sbloccare valore per il business con il miglior software per l’estrazione di dati dal web
I dati web sono il carburante per decisioni di business più intelligenti nel 2026. Il software giusto per l’estrazione di dati dal web può farti risparmiare ore, ridurre gli errori e dare al tuo team un vantaggio concreto — che tu stia costruendo liste di lead, monitorando i concorrenti o alimentando il tuo motore di analytics.
In sintesi:
- Thunderbit è lo scraper no-code più semplice e basato su AI per gli utenti business.
- Import.io è la soluzione di livello enterprise per pipeline dati continue e integrate.
- Scrapy è il toolkit open source per sviluppatori che vogliono il pieno controllo.
- Octoparse e ParseHub rendono l’estrazione visiva no-code accessibile a tutti.
La maggior parte di questi strumenti offre prove gratuite o piani freemium, quindi vale la pena testarli. Automatizza le attività noiose, sblocca nuove insight e lascia che il tuo team si concentri su ciò che conta davvero.
Buona estrazione — e che i tuoi dati siano sempre aggiornati, strutturati e pronti all’azione.
FAQ
1. A cosa serve un software per l’estrazione di dati dal web?
Il software per l’estrazione di dati dal web automatizza il processo di estrazione di informazioni da siti web, PDF e immagini. Si usa per generazione di lead, monitoraggio prezzi, ricerche di mercato, aggregazione di contenuti e molto altro.
2. L’estrazione di dati dal web è legale?
Lo scraping del web è legale quando si raccolgono dati pubblicamente disponibili e si rispettano i termini di servizio del sito e le leggi sulla privacy. Controlla sempre le policy del sito e usa i dati in modo responsabile.
3. Devo saper programmare per usare un software per l’estrazione di dati dal web?
Non necessariamente. Strumenti come Thunderbit, Octoparse e ParseHub sono progettati per chi non programma. Per progetti più complessi o personalizzati, potrebbero servire strumenti per sviluppatori come Scrapy.
4. Come esporto i dati estratti in Excel o Google Sheets?
La maggior parte degli scraper moderni (Thunderbit, Octoparse, ParseHub) offre export con un clic in Excel, Google Sheets, CSV o persino integrazione diretta con Notion e Airtable.
5. Il software per l’estrazione di dati dal web può gestire siti dinamici o login?
Sì: strumenti di punta come Import.io, Octoparse e ParseHub gestiscono contenuti dinamici (AJAX, infinite scroll) e siti protetti da login. Anche Thunderbit supporta l’estrazione da pagine dinamiche e sottopagine.
Vuoi vedere come si presenta il web scraping moderno? Scarica l’estensione Chrome di Thunderbit oppure esplora il blog di Thunderbit per altri consigli, tutorial e approfondimenti sul mondo dell’estrazione dati potenziata dall’AI.
Prova AI Web Scraper Get Started Free




