

Temu raggiunge ormai oltre 416 milioni di utenti attivi mensili in più di 50 mercati. Il suo catalogo va dai gadget da cucina agli accessori per animali, fino alle strisce LED. Se lavori nell’ecommerce, nel dropshipping o nella competitive intelligence, probabilmente hai già pensato di portare i dati di Temu in un foglio di calcolo — e poi hai scoperto che Temu non lo rende affatto semplice.
Ho dedicato molto tempo a cercare e testare strumenti di scraping per siti ecommerce protetti. Temu è uno dei bersagli più difficili in assoluto. La maggior parte delle guide online ti mette davanti a un tutorial Python che si rompe nel giro di una settimana, oppure ti indirizza verso API enterprise che costano più del tuo budget pubblicitario mensile.
La realtà è che la maggior parte degli utenti business — dropshipper, operatori indipendenti, team marketing — vuole semplicemente un foglio di calcolo pulito con nomi dei prodotti, prezzi, immagini, valutazioni e informazioni sul venditore. Non vuole fare debug di script Playwright alle 2 di notte.
Questa guida nasce proprio da questo divario: una panoramica pratica, organizzata per livello di competenza, dei migliori Temu Scraper che funzionano davvero nel 2026, più le best practice che trasformano uno scraping grezzo in competitive intelligence continua. Che tu sia un principiante totale o uno sviluppatore che sta costruendo una pipeline dati, qui troverai una sezione adatta a te.
Prova Thunderbit per lo scraping di Temu
Perché fare scraping di Temu? I principali casi d’uso per i team business
I dati di Temu non sono solo interessanti: sono strategicamente utili.
La piattaforma è diventata un riferimento per i prezzi nelle categorie di prodotto di fascia bassa e media. Anche se non vendi su Temu, i tuoi clienti confrontano comunque i tuoi prezzi con quelli che vedono lì. Ecco come diversi team usano i dati di Temu:
| Caso d’uso | Dati necessari | Perché è importante |
|---|---|---|
| Ricerca prodotti per dropshipping | Titolo, prezzo, immagine, valutazione, numero di recensioni, numero di vendite, varianti | Trova prodotti a basso costo con segnali di domanda, da confrontare su Amazon, Shopify, AliExpress e TikTok Shop |
| Prezzi competitivi | Prezzo attuale, prezzo originale, sconto %, valuta, spedizione, timestamp | Crea una base per la strategia di prezzo e la pianificazione promozionale |
| Sourcing prodotti | Specifiche, immagini, varianti, venditore/negozio, ID articolo, categoria | Individua tipologie di prodotto e inserzioni in stile fornitore da verificare più a fondo |
| Analisi delle tendenze di mercato | Parola chiave di ricerca, categoria, numero di vendite, numero di recensioni, valutazione | Mostra quali prodotti stanno guadagnando trazione nelle varie categorie |
| Ricerca marketing e creatività | Titolo, immagine, numero di recensioni, valutazione, descrizioni, etichette di categoria | Evidenzia messaggi, spunti visivi, bundle e claim usati dalle inserzioni con volumi elevati |
| Monitoraggio stock e disponibilità | URL prodotto, disponibilità, stima spedizione, prezzo, timestamp | Rileva esaurimenti, cambiamenti nel magazzino locale e variazioni di prezzo nel tempo |
Chi cerca "i migliori Temu Scraper" tende a dividersi in tre gruppi. Gli utenti non tecnici vogliono un’estensione Chrome che esporti in un foglio di calcolo. Gli operatori semi-tecnici vogliono uno strumento visuale con template e pianificazione. Gli sviluppatori vogliono un’API, uno script Playwright e una strategia proxy.
Questo articolo copre tutti e tre i casi — ma parte dal gruppo più grande: chi ha bisogno di dati, non di codice.
Cosa distingue i migliori Temu Scraper nel 2026
Uno scraper che gestisce Amazon o Shopify non sopravvivrà necessariamente su Temu. I criteri di valutazione per questo articolo sono:
- Affidabilità su Temu — Restituisce davvero dati puliti, oppure viene bloccato, produce righe vuote o si rompe dopo un cambio di layout?
- Facilità d’uso — Un utente business non tecnico può iniziare senza scrivere codice?
- Completezza dei dati — Supporta l’arricchimento delle subpage (visitando ogni pagina dettaglio prodotto per specifiche, varianti, informazioni sul venditore)?
- Carico di manutenzione — Si adatta quando Temu cambia la struttura delle pagine?
- Pianificazione e monitoraggio — Può eseguire scraping ricorrenti ed esportare verso una destinazione dati sempre aggiornata?
- Destinazioni di export — CSV, Excel, Google Sheets, Airtable, Notion, JSON?
- Chiarezza dei costi — Quanto costa davvero al mese un flusso di lavoro realistico per lo scraping di Temu?
Le segnalazioni della community su r/webscraping di Reddit descrivono costantemente Temu come uno dei siti ecommerce più difficili da scrappare. Un utente ha scritto che "non riesce nemmeno a vedere un prezzo da acquirente", mentre un altro ha notato che Temu e Shopee hanno team che rafforzano continuamente i meccanismi anti-bot. Non esistono benchmark pubblici specifici sul tasso di fallimento di Temu, ma il 2025 Imperva Bad Bot Report ha rilevato che il traffico automatizzato ha superato quello umano, con i bot che rappresentano il 51% di tutto il traffico Internet. Questo è l’ambiente da cui Temu si sta difendendo.
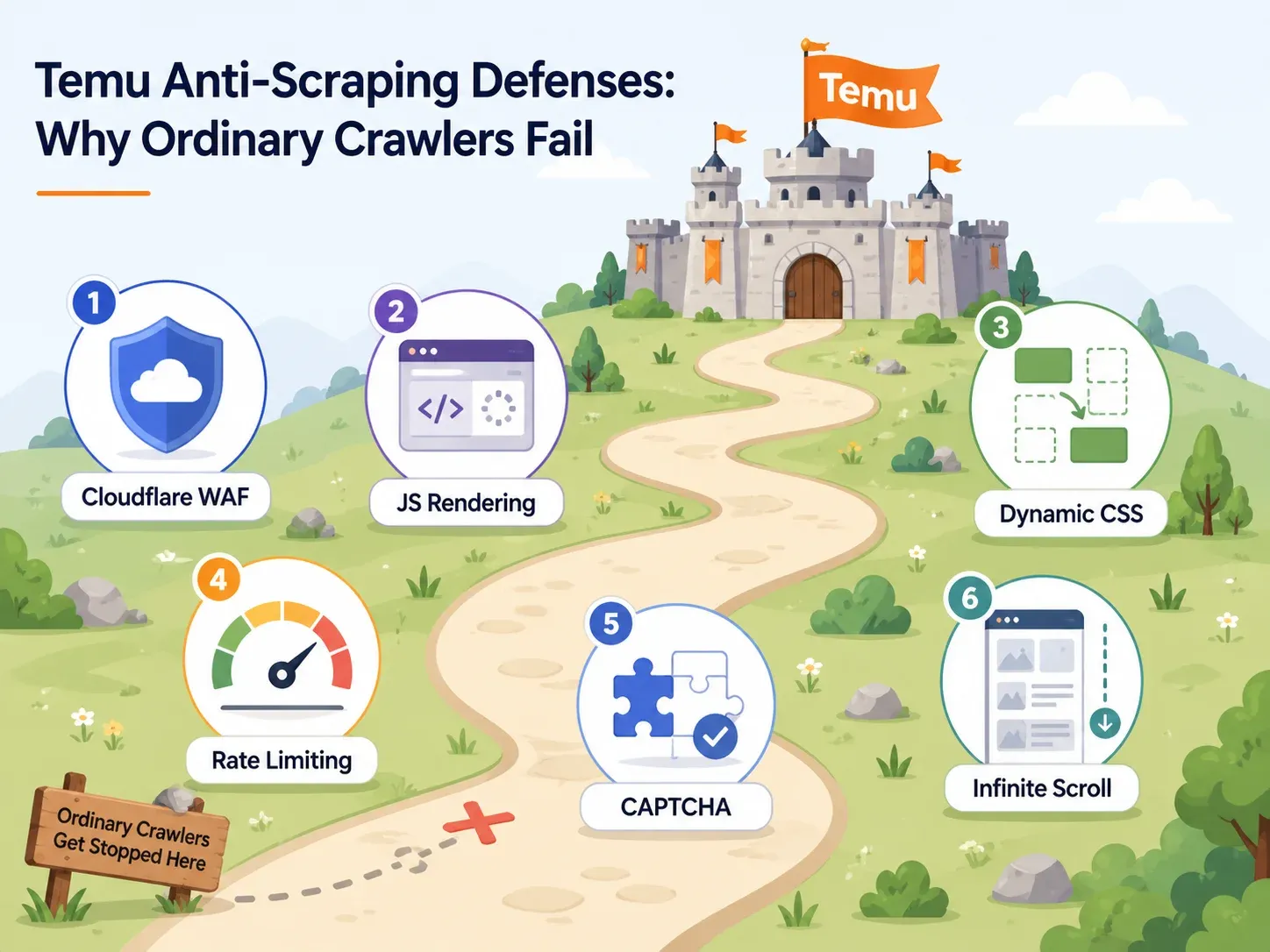
Difese anti-bot di Temu: perché la maggior parte degli scraper fallisce
La maggior parte degli articoli sullo scraping di Temu dedica una sola frase alle misure anti-bot: "Temu usa un sistema anti-bot." Non serve a nulla.
Se stai scegliendo uno strumento, devi sapere quali difese usa Temu e quali funzionalità dello strumento le aggirano. Ecco la mappa pratica:
| Difesa di Temu | Cosa fa | Funzionalità necessaria nello strumento | Esempi di strumenti |
|---|---|---|---|
| Cloudflare WAF / controlli del browser | Blocca user-agent automatizzati, identifica i bot tramite fingerprint, restituisce pagine di challenge | Infrastruttura cloud con IP residenziali rotanti e fingerprint di browser reali | Thunderbit (scraping cloud), Bright Data, Oxylabs, ScraperAPI |
| Rendering JavaScript pesante | I dati del prodotto vengono caricati via JS; l’HTML grezzo è vuoto | Browser headless o rendering completo del browser | Thunderbit (modalità browser), Playwright, Selenium, ParseHub, actor browser di Apify |
| Selettori CSS dinamici | I nomi delle classi cambiano tra un deployment e l’altro, rompendo gli scraper basati su CSS | Rilevamento campi basato su AI (non dipendente da selettori fissi) | Thunderbit (l’AI legge la pagina da zero ogni volta), Bright Data AI scraper builder |
| Rate limiting | Limita le richieste sequenziali troppo rapide | Richieste cloud simultanee con throttling intelligente | Thunderbit (fino a 50 pagine alla volta via cloud), ScraperAPI, Bright Data |
| Challenge CAPTCHA | Interrompe le sessioni dopo comportamenti sospetti | Soluzione CAPTCHA integrata o strategia a basso trigger | Bright Data, Oxylabs, ScraperAPI premium/ultra-premium |
| Infinite scroll / lazy loading | Mostra solo i primi prodotti senza interazione | Scrolling intelligente, rilevamento paginazione, automazione delle interazioni | Thunderbit paginazione, scrolling intelligente di Apify, workflow builder di Octoparse |
Cloudflare WAF e blocco IP
La porta d’ingresso di Temu è protetta da controlli di integrità del browser in stile Cloudflare. Le richieste HTTP di base — quelle che farebbe un semplice requests.get() in Python — vengono sfidate, restituite con errore 403 oppure servite con dati incompleti.
Gli strumenti che funzionano qui hanno bisogno di IP residenziali o mobili rotanti e di fingerprint reali del browser. La Cloudflare Radar review 2025 ha riportato che, all’inizio del 2025, i bot non AI erano responsabili di circa metà delle richieste alle pagine HTML. Questa è la scala dell’automazione da cui piattaforme come Temu si stanno difendendo.
Rendering JavaScript e selettori dinamici
Qui falliscono in silenzio la maggior parte degli scraper per principianti.
Se apri il sorgente della pagina di Temu, spesso trovi solo un guscio vuoto — le schede prodotto, i prezzi e le immagini reali vengono inseriti da JavaScript dopo il caricamento della pagina. Uno scraper che legge solo l’HTML grezzo non restituirà nulla di utile. Inoltre, i nomi delle classi CSS e le strutture DOM di Temu cambiano tra un deployment e l’altro. Uno scraper che si basa su un selettore CSS fisso come .product-card__price oggi funzionerà, ma domani potrebbe restituire colonne vuote.
Gli scraper basati su AI (come Thunderbit) leggono semanticamente la pagina ogni volta, quindi non dipendono dal fatto che nomi di classi specifici restino identici.
Rate limiting e challenge CAPTCHA
Se colpisci Temu troppo rapidamente o troppe volte dallo stesso IP, attiverai il rate limiting o le challenge CAPTCHA. Alcuni strumenti gestiscono tutto questo con throttling intelligente e soluzione CAPTCHA integrata. Altri lasciano il problema a te — e, per un utente non tecnico, questo è praticamente un vicolo cieco.
Per lo scraping cloud, la chiave è avere richieste simultanee distribuite su IP puliti con logica di retry automatica.
I migliori Temu Scraper per livello di competenza: panoramica completa
Trova la tua riga e vai alla sezione più adatta:
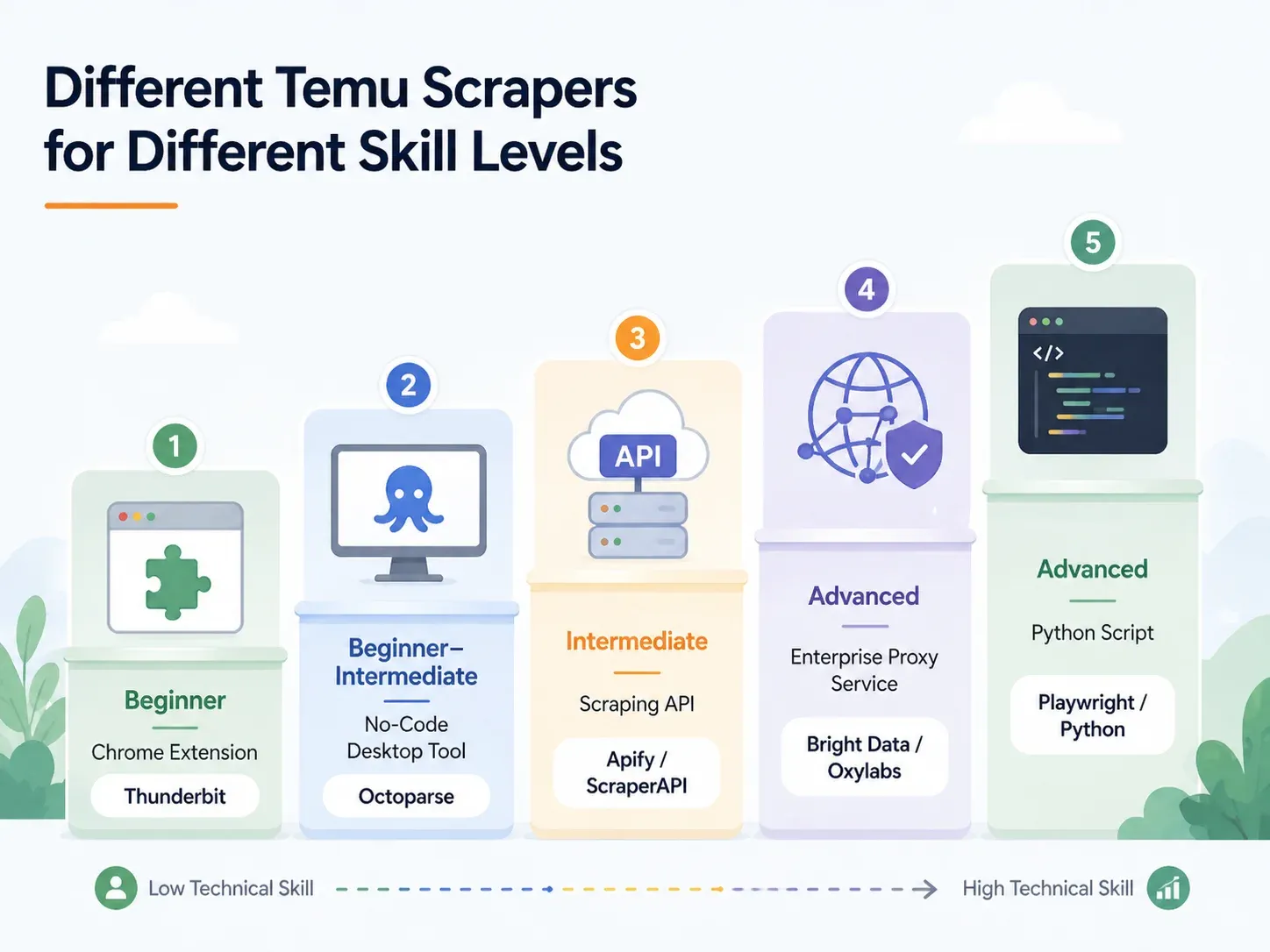
| Approccio | Livello di competenza | Tempo di configurazione | Gestione anti-bot | Ideale per |
|---|---|---|---|---|
| Estensione Chrome AI (es. Thunderbit) | Principiante | < 2 min | Gestita (cloud o browser) | Dropshipper, marketer, operazioni ecommerce |
| Strumento desktop no-code (es. Octoparse, ParseHub) | Principiante–Intermedio | 10–60 min | Parziale (serve configurazione proxy) | Scraping regolare con template |
| API/servizio di scraping (es. ScraperAPI, Apify) | Intermedio | 15–45 min | Integrata | Sviluppatori che la integrano in pipeline |
| Proxy gestito/Enterprise (es. Bright Data, Oxylabs) | Avanzato/Enterprise | Ore–Giorni | Infrastruttura completa | Volumi elevati, consegna a data warehouse |
| Script Python personalizzato (Playwright/Selenium) | Avanzato | 1–4 ore+ | Manuale (proxy + configurazione CAPTCHA) | Controllo totale, personalizzazione per casi limite |
Thunderbit: il miglior Temu Scraper per utenti non tecnici
Thunderbit è un’estensione Chrome basata su AI pensata per utenti business — team sales, operatori ecommerce, dropshipper, marketer — che hanno bisogno di dati strutturati dai siti web senza scrivere codice. Lavoro nel team Thunderbit, quindi conosco bene il prodotto. Sarò diretto su ciò che fa e sul suo posizionamento.
Il flusso base richiede due clic: apri una pagina Temu, clicca AI Suggest Fields, rivedi le colonne suggerite (nome prodotto, prezzo, immagine, valutazione, ecc.), poi clicca Scrape.
L’AI di Thunderbit legge la struttura della pagina e propone automaticamente nomi delle colonne e tipi di dati. Non si basa su selettori CSS fissi, quindi quando Temu cambia i nomi delle classi o il layout delle schede, lo scraper si adatta.
Funzionalità chiave per Temu:
- Modalità cloud scraping: più veloce per le pagine pubbliche, elabora fino a 50 pagine alla volta. Ideale per pagine categoria, risultati di ricerca e inserzioni prodotto che non richiedono login.
- Modalità browser scraping: usa la tua sessione Chrome corrente, inclusi cookie, localizzazione e stato di login. Ideale quando regione, popup o contenuti riservati agli utenti loggati influenzano ciò che la pagina mostra.
- Scrape Subpages: dopo aver estratto una pagina elenco, clicca "Scrape Subpages" per visitare ogni pagina dettaglio prodotto e aggiungere colonne come descrizione completa, varianti, informazioni sul venditore, stima di spedizione e specifiche — senza alcuna configurazione extra.
- Field AI Prompts: categorizza, traduci o riformatta i dati durante lo scraping. Per esempio: "Classifica questo prodotto in Kitchen Utensils, Small Appliances, Storage o Other."
- Scraping pianificato: imposta una pianificazione in linguaggio naturale ("ogni lunedì alle 9"), inserisci gli URL e Thunderbit esegue lo scraping nel cloud esportando verso Google Sheets, Airtable o un’altra destinazione.
- Export gratuiti: Excel, CSV, Google Sheets, Airtable, Notion, JSON — nessun paywall sull’export. Le immagini vengono esportate come allegati reali in Airtable e Notion.
Prezzi: piano gratuito con fino a 6 pagine (o 10 con un trial boost); i piani a pagamento partono da circa $15/mese (mensile) o $9/mese (annuale) per 500 crediti, con 1 credito = 1 riga di output.
Estrai dati Temu con l'AI Get Started Free
Confronto diretto: Thunderbit vs. script Python sulla stessa pagina Temu
Il contrasto è netto:
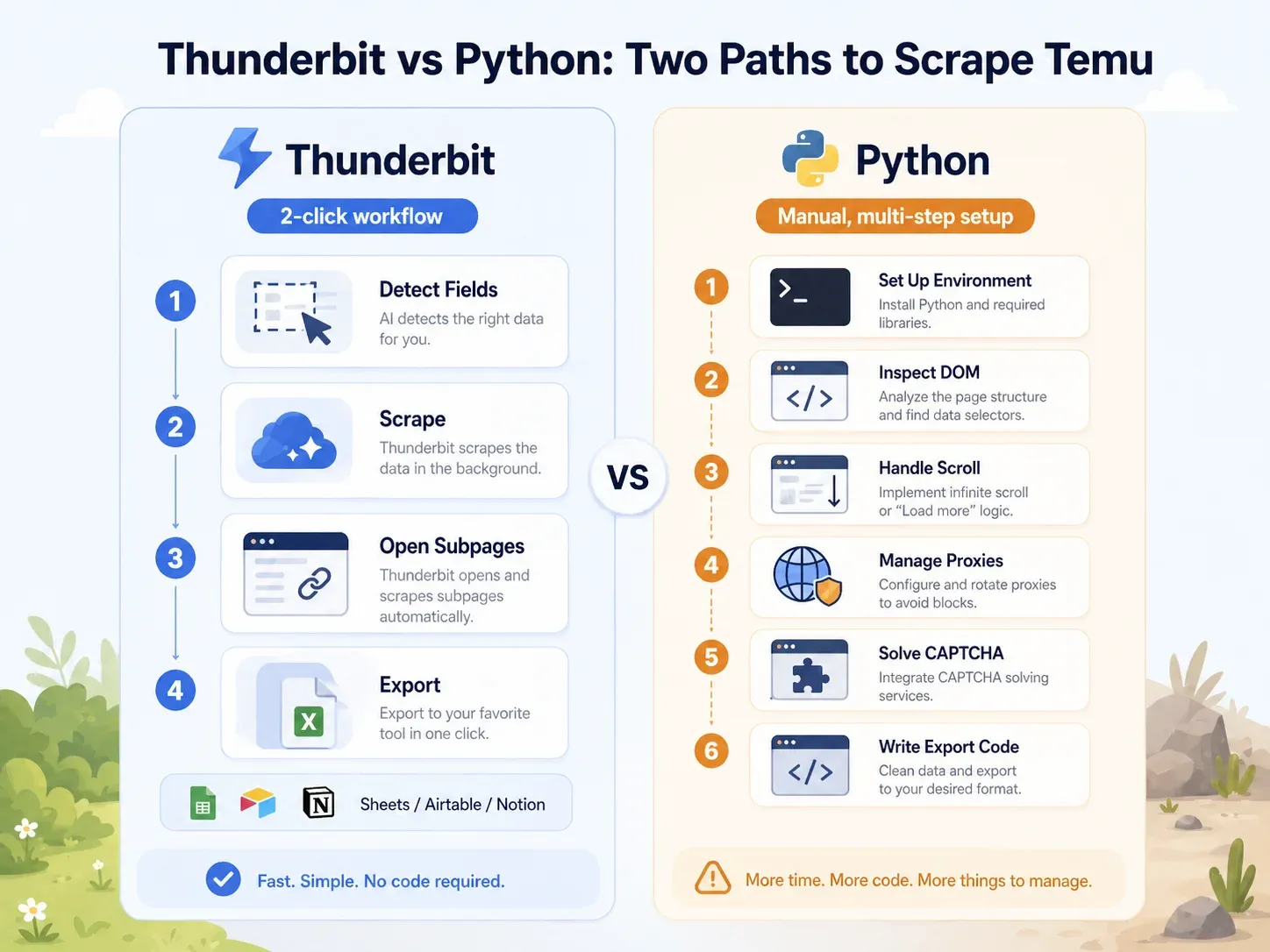
| Attività | Thunderbit | Python (Playwright) |
|---|---|---|
| Aprire la pagina categoria di Temu | Apri la pagina in Chrome | Configura l’ambiente Python, installa Playwright, installa i browser |
| Identificare i campi | Clicca "AI Suggest Fields" | Ispeziona DOM, chiamate di rete, payload JSON |
| Gestire il caricamento dinamico | Modalità browser/cloud + paginazione | Scrivi logica di scroll/attesa, intercetta le richieste |
| Gestire blocchi | Prova la modalità cloud o browser | Aggiungi proxy, header, fingerprinting, retry, CAPTCHA |
| Estrarre i campi dell’inserzione | Clicca "Scrape" | Scrivi selettori o logica di parsing API |
| Arricchire le pagine prodotto | Clicca "Scrape Subpages" | Costruisci un crawler PDP separato |
| Export | Clicca Sheets/Airtable/Notion/Excel | Scrivi codice di integrazione CSV/JSON/Sheets |
| Configurazione tipica per un utente business | In meno di 2 minuti | Almeno 1–4 ore; manutenzione continua |
Un prototipo minimo in Playwright per Temu potrebbe apparire così (pseudocodice — non pronto per la produzione):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# Il codice di produzione richiede ancora selettori, proxy, retry,
# gestione CAPTCHA, crawling delle PDP e logica di export.
print(cards.count())
Sono già 10+ righe prima di aver estratto un singolo campo, e non hai ancora affrontato proxy, CAPTCHA, arricchimento PDP o export. Per un utente non tecnico, Thunderbit comprime l’intero flusso in un paio di clic. Per uno sviluppatore, il percorso Python offre più controllo — ma con un costo di manutenzione molto più alto.
Octoparse e ParseHub: Temu Scraper desktop no-code
Se vuoi più controllo di un’estensione Chrome ma non vuoi scrivere codice, Octoparse e ParseHub sono le opzioni principali.
Octoparse ha un template pubblico Temu Details Scraper. Il suo output di esempio include ID prodotto, titoli, prezzi, dati del venditore/negozio, URL delle immagini, sconti, URL dei negozi e specifiche dettagliate. Questo è un vero vantaggio — puoi partire da un template invece di costruire un workflow da zero. Octoparse supporta anche estrazione cloud, pianificazione e costruzione visuale dei workflow.
I limiti per Temu:
- I componenti anti-bot aggiuntivi (proxy residenziali a $3/GB, soluzione CAPTCHA a $1–$1.50 per mille) possono far lievitare i costi.
- I template possono rompersi quando Temu cambia il layout. Potresti dover aggiornare i selettori o attendere che Octoparse mantenga il template.
- La configurazione richiede 10–60 minuti, a seconda della complessità della pagina.
Prezzi di Octoparse: piano gratuito con 10 task e 50K di export dati mensile; Standard intorno a $75/mese con fatturazione annuale; Professional intorno a $108/mese con fatturazione annuale. I componenti aggiuntivi per proxy, CAPTCHA e servizi gestiti hanno un costo extra.
ParseHub è uno scraper desktop/web visuale che gestisce bene le pagine dinamiche (gira su un browser Chromium completo). Tuttavia, i piani a pagamento partono da $189/mese, una cifra alta per un operatore singolo. Nella mia ricerca non ho trovato un template pubblico Temu particolarmente forte. ParseHub è più adatto a team già abituati a costruire progetti di scraping visuale.
| Strumento | Punti di forza su Temu | Punti deboli su Temu | Prezzi |
|---|---|---|---|
| Octoparse | Template Temu pubblico, workflow visuale, estrazione cloud, pianificazione | Manutenzione dei template, gli add-on anti-bot aumentano i costi | Free; Standard ~$75/mese annuale; Pro ~$108/mese annuale; add-on extra |
| ParseHub | Gestione delle pagine dinamiche, builder di workflow di progetto, rotazione IP nei piani a pagamento | Prezzo d’ingresso più alto, nessun template pubblico Temu trovato | Piani a pagamento da $189/mese |
API di scraping: ScraperAPI, Apify e Bright Data per Temu
I servizi di scraping basati su API gestiscono proxy, rendering e logica anti-bot, così gli sviluppatori possono concentrarsi sul parsing e sul salvataggio dei dati. Sono perfetti quando stai costruendo una pipeline, non quando devi fare un’esportazione spot in un foglio di calcolo.
ScraperAPI è un’API per sviluppatori per la rotazione dei proxy e il rendering. La pagina prezzi riporta una prova di 7 giorni con 5.000 crediti, Hobby a $49/mese per 100.000 crediti, e livelli superiori da lì in avanti. Il problema con Temu: il rendering JavaScript e i pool proxy premium consumano da 10 a 75 crediti per richiesta, a seconda del livello. Questa moltiplicazione dei crediti significa che il costo effettivo per riga può essere molto più alto del prezzo in vetrina.
Apify è una piattaforma con un marketplace di "actor" predefiniti (scraper). Esistono diversi actor per Temu. Un Temu Scraper gestito dalla community indica un pricing pay-per-event intorno a $5 per 1.000 prodotti nel piano gratuito. Un altro Temu Products Scraper indica $4 per 1.000 risultati. Il rischio: la qualità degli actor varia, la manutenzione dipende dalla community e alcuni actor possono diventare obsoleti o rompersi quando Temu si aggiorna. Controlla sempre la data dell’ultimo aggiornamento e le valutazioni degli utenti prima di impegnarti.
Bright Data è l’opzione enterprise. La sua pagina Temu scraper dice che i job vengono eseguiti sull’infrastruttura Bright Data con rotazione proxy, geo-targeting, logica CAPTCHA/unblocking e autoscaling. I formati di output includono JSON, CSV, Parquet e consegna diretta a S3, GCS, Azure Blob, BigQuery e Snowflake. Le recensioni di settore riportano un pay-as-you-go per la Web Scraper API intorno a $2.5 per 1.000 record, con piani impegnati a partire da circa $499/mese. Potente, ma con un prezzo pensato per team con budget reali.
Oxylabs dispone anche di una pagina dedicata Temu Scraper API. I piani partono da $49/mese, con una prova gratuita fino a 2.000 risultati. È una valida alternativa a Bright Data per i team di sviluppatori che vogliono dati Temu strutturati via API.
| API/Piattaforma | Evidenza specifica per Temu | Punto di forza | Debolezza | Ideale per |
|---|---|---|---|---|
| ScraperAPI | Non trovata una pagina specifica per Temu, ma le funzionalità anti-bot ecommerce sono documentate | Endpoint semplice, rendering JS, proxy premium | Moltiplicatori di crediti per le funzioni premium; gli sviluppatori devono fare il parsing dei dati | Pipeline per sviluppatori |
| Apify | Diversi actor Temu nel marketplace | Il percorso più veloce per gli sviluppatori, se l’actor corrisponde ed è mantenuto | La qualità degli actor varia; alcuni sono obsoleti | Sviluppatori che vogliono marketplace di actor + pianificazione |
| Bright Data | Pagina Temu scraper dedicata | Infrastruttura enterprise, unblocking, consegna a warehouse | Costoso; servono comunque concetti di web scraping | Team dati su scala enterprise |
| Oxylabs | Pagina dedicata Temu Scraper API | Prezzo chiaro per risultato, gestione JS, supporto IP/CAPTCHA dichiarato | Flusso di lavoro da API per sviluppatori | Team di sviluppo che necessitano accesso API a Temu |
Script Python personalizzati (Playwright/Selenium): controllo totale, grande impegno
Gli scraper Python personalizzati offrono la massima flessibilità — questo è il lato positivo. In generale, Playwright è un punto di partenza migliore di Selenium per Temu, grazie al modello di auto-waiting e alla migliore gestione delle pagine molto ricche di JavaScript.
Ma il compromesso è pesante.
Un prototipo richiede 1–4 ore. Uno scraper di produzione ha bisogno di rotazione proxy, fingerprint del browser realistici, strategia CAPTCHA, retry, validazione dello schema, storage dell’output, monitoraggio, alert e revisione legale.
E si rompe. Le community di scraping su Reddit descrivono ripetutamente lo scraping moderno dell’ecommerce come instabile quando i siti usano Cloudflare, rendering JavaScript e fingerprint anti-bot.
| Modalità di guasto | Causa tipica | Mitigazione |
|---|---|---|
| HTML vuoto / prodotti mancanti | Il JS carica le schede prodotto dopo l’HTML iniziale | Usa Playwright, attendi rete e DOM |
| Solo i primi prodotti | Infinite scroll / lazy loading | Loop di scroll, attesa network idle, soglie sul numero di schede |
| Prezzi mancanti o incoerenti | Stato regione/sessione/valuta o risposta anti-bot | Imposta localizzazione, cookie, proxy geotargettizzato |
| 403 / challenge / CAPTCHA | Reputazione IP, fingerprint headless, frequenza richieste | Proxy residenziali, browser stealth, rate più basso |
| Selettori che si rompono | Cambiamenti DOM/classi, A/B test | Estrazione semantica o parsing API, se disponibile |
Gli script personalizzati non sono l’opzione "gratis". Spostano il costo dalle fee di abbonamento al tempo degli sviluppatori, alle bollette dei proxy, ai costi CAPTCHA e al rischio di manutenzione. Se hai un ingegnere dello scraping in squadra e hai bisogno di logiche insolite, questa è la strada giusta. Per tutti gli altri, in pratica, è l’opzione più costosa.
Best practice: scraping delle subpage per dati completi dei prodotti Temu
Questa è la best practice più importante dell’articolo — e quasi nessun’altra guida la tratta.
Una pagina categoria o di ricerca di Temu mostra le basi: titolo, miniatura, prezzo, valutazione approssimativa. Ma i campi che rendono davvero utilizzabile una riga — descrizioni dettagliate, elenco varianti, numero completo di recensioni, stime di spedizione, nomi dei venditori, tabelle specifiche — si trovano nella pagina dettaglio prodotto (PDP).
Se scrappi solo la pagina elenco, stai lavorando con un dataset parziale.
Il flusso in due passaggi:
- Step 1 — Scrape della pagina elenco (PLP): estrai nome prodotto, prezzo, miniatura e valutazione da una pagina di ricerca o categoria Temu.
- Step 2 — Arricchimento tramite scraping delle subpage: visita ogni PDP del prodotto e aggiungi colonne come descrizione completa, numero di recensioni, opzioni di variante, tempi di spedizione e informazioni sul venditore.
Ecco come appare il dato prima e dopo:
| Campo | Dalla PLP (Step 1) | Aggiunto dalla PDP (Step 2) |
|---|---|---|
| Titolo prodotto | ✅ | — |
| Prezzo | ✅ | ✅ (verificato / % sconto) |
| Miniatura | ✅ | — |
| Valutazione a stelle | ✅ | ✅ (con numero di recensioni) |
| Descrizione completa | ❌ | ✅ |
| Varianti (taglie, colori) | ❌ | ✅ |
| Nome venditore | ❌ | ✅ |
| Stima di spedizione | ❌ | ✅ |
| Specifiche dettagliate | ❌ | ✅ |
In Thunderbit, questo si fa con un clic: dopo lo scraping iniziale, clicca "Scrape Subpages". L’AI visita ogni URL prodotto e aggiunge le colonne extra — nessuna configurazione aggiuntiva, nessun spider separato, nessuna manutenzione dei selettori. Il template Temu Details di Octoparse e l’actor Temu di Apify supportano anch’essi i campi a livello PDP, ma richiedono più configurazione e manutenzione. In Python, dovresti costruire un crawler PDP separato, mantenerne i selettori e gestire la paginazione all’interno delle pagine dettaglio — un investimento aggiuntivo significativo.
Best practice: scraping programmato di Temu per il monitoraggio continuo di prezzi e stock
Gli scraping una tantum sono utili per scoprire prodotti. La competitive intelligence richiede osservazione ripetuta.
I prezzi cambiano, i prodotti si esauriscono, nuovi articoli appaiono ogni giorno e la profondità degli sconti varia con le promozioni. Uno scraping settimanale o giornaliero crea una tabella storica su cui il tuo team può davvero agire.
Tre casi d’uso che vale la pena automatizzare:
- Monitoraggio prezzi: traccia ogni settimana i 50 SKU Temu più importanti di un concorrente. Ricevi i prezzi aggiornati esportati automaticamente in Google Sheets per un confronto immediato con i tuoi prezzi.
- Monitoraggio stock e disponibilità: rileva quando un prodotto di tendenza va esaurito, compare una nuova variante o cambiano le stime di spedizione.
- Individuazione di nuovi prodotti/tendenze: programma uno scraping giornaliero della sezione "New Arrivals" di Temu o di una categoria prioritaria. Ordina per numero di vendite o recensioni per individuare in anticipo i prodotti in crescita.
In Thunderbit, configuri tutto descrivendo l’intervallo in linguaggio naturale ("ogni lunedì alle 9"), inserendo gli URL di destinazione e cliccando "Schedule". Lo scraping gira nel cloud ed esporta verso la destinazione che scegli. Poiché l’AI legge la pagina da zero ogni volta, gli scraping pianificati si adattano automaticamente ai cambiamenti di layout di Temu — non devi aggiornare i selettori quando Temu ridisegna una scheda prodotto.
L’alternativa: impostare un cron job, mantenere uno script Python, configurare la rotazione proxy, costruire una pipeline di output e correggere i selettori ogni volta che Temu cambia il layout. Per un team non tecnico, non è proprio fattibile. Per uno sviluppatore, è overhead continuo. Anche Apify e Bright Data supportano esecuzioni pianificate, ma con una configurazione più tecnica e costi minimi più alti.
Best practice: workflow dati Temu end-to-end (scrape → pulizia → export → azione)
La maggior parte delle guide sullo scraping si ferma a "scarica CSV".
Ma gli utenti business hanno bisogno dei dati dentro gli strumenti che usano davvero — Google Sheets per la collaborazione, Airtable per i database prodotto, Notion per le dashboard del team. La vera best practice è un workflow end-to-end:
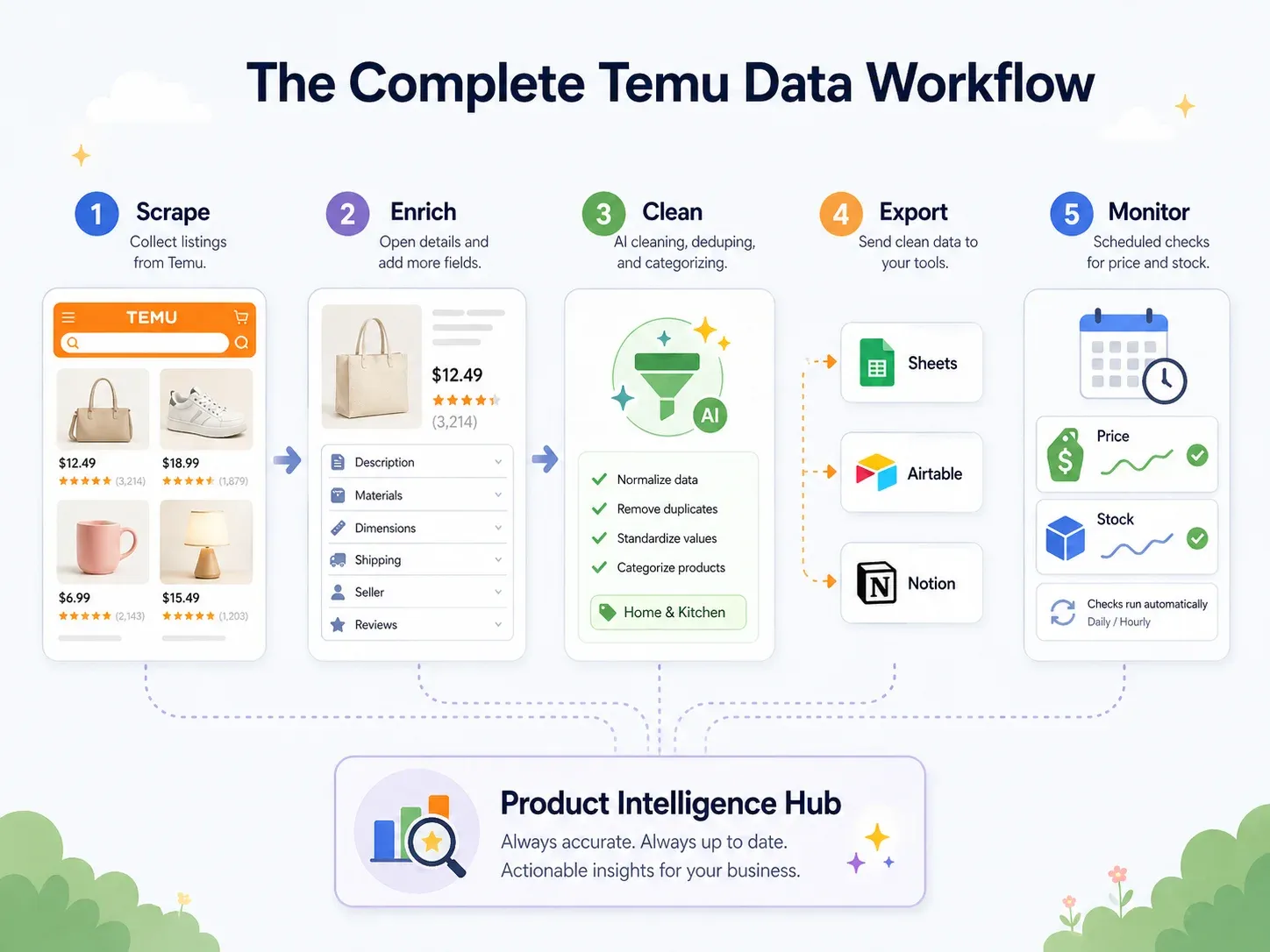
| Fase del workflow | Cosa succede | Funzionalità Thunderbit |
|---|---|---|
| Scrape | Estrai dati dalle pagine Temu | AI Suggest Fields → Scrape (2 clic) |
| Arricchimento | Visita la pagina dettaglio di ogni prodotto | Scrape Subpages (1 clic) |
| Pulizia ed etichettatura | Categorizza i prodotti, normalizza i prezzi, traduci i titoli | Field AI Prompt — etichetta, formatta, traduci durante lo scraping |
| Export | Invia i dati agli strumenti business | Export gratuito a Excel, Google Sheets, Airtable, Notion; download CSV/JSON |
| Monitoraggio | Traccia i cambiamenti nel tempo | Scheduled Scraper con intervalli in linguaggio naturale |
Ecco un esempio concreto: esegui lo scraping di 200 prodotti da cucina di Temu. Durante lo scraping, un Field AI Prompt classifica automaticamente ogni prodotto in "Utensili / Piccoli elettrodomestici / Organizzazione / Pulizia / Decorazioni". I prezzi vengono normalizzati in valori numerici USD. I titoli dei prodotti in cinese vengono tradotti in inglese. I dati vengono esportati direttamente in una base Airtable con le immagini prodotto intatte (non solo URL — allegati immagine reali, come descritto nella guida Thunderbit allo scraping di immagini). Uno scraping pianificato aggiorna i dati ogni settimana.
Alcune istruzioni utili di Field AI Prompt per i dati Temu:
- "Classifica questo prodotto in una delle seguenti categorie: Kitchen Utensils, Small Appliances, Storage, Cleaning, Decor, Other. Restituisci solo la categoria."
- "Traduci il titolo del prodotto in inglese conciso mantenendo nomi brand, quantità, dimensioni e numeri di modello."
- "Normalizza il prezzo come numero senza simboli di valuta."
- "Assegna alla domanda il livello High, Medium o Low in base a valutazione, numero di recensioni e numero di vendite. Se mancano dati, restituisci Unknown."
Questo flusso trasforma uno scraping grezzo in un database vivo di product intelligence — senza che uno sviluppatore debba costruire una pipeline ETL separata.
Confronto tra i migliori Temu Scraper: tabella affiancata
| Strumento | Livello di competenza | Tempo di configurazione | Gestione anti-bot | Scraping subpage | Pianificazione | Opzioni di export | Fascia di prezzo | Ideale per |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Principiante | Minuti | Modalità browser, modalità cloud, rilevamento campi AI | Sì (Scrape Subpages) | Sì (pianificazioni in linguaggio naturale) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | Gratis 6 pagine; piani a pagamento da circa $9–15/mese per 500 crediti | Team ecommerce non tecnici, dropshipper |
| Octoparse | Principiante–Intermedio | 10–60 min | Estrazione cloud, add-on proxy/CAPTCHA | Sì (workflow con template) | Sì (piani a pagamento/cloud) | Excel, CSV, JSON, HTML, XML, database, Google Sheets | Gratis; Standard ~$75/mese annuale; add-on extra | Operatori che vogliono workflow visuali + template Temu |
| ParseHub | Principiante–Intermedio | 30–60 min | Rendering dinamico, rotazione IP nei piani a pagamento | Sì (flussi di progetto) | Piani a pagamento | CSV/JSON, Dropbox/S3 nei piani a pagamento | Da $189/mese | Team che costruiscono progetti visuali per siti dinamici |
| ScraperAPI | Sviluppatore | Ore | Rotazione proxy, rendering JS, pool premium | Codificato su misura | DataPipeline/scheduler | HTML/JSON/CSV | Trial 5K crediti; Hobby $49/mese; livelli superiori disponibili | Sviluppatori che costruiscono pipeline Temu personalizzate |
| Apify | Intermedio | 10–30 min se l’actor è adatto | Logica browser/proxy specifica per actor | Dipende dall’actor | Sì | JSON, CSV, Excel, API/dataset | Piattaforma gratuita; actor Temu ~ $4–5/1K prodotti | Sviluppatori/operatori che sanno valutare la qualità degli actor |
| Bright Data | Avanzato/Enterprise | Ore–Giorni | Proxy completo, CAPTCHA, unblocking, autoscaling | Personalizzato via scraper/API | Sì | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | Circa $2.5/1K record PAYG; contratti da circa $499/mese | Team dati enterprise, estrazione ad alto volume |
| Oxylabs | Avanzato | Ore | Gestione JS, supporto IP/CAPTCHA dichiarato | Personalizzato via API | Sì | JSON/output API | Da $49/mese; prova fino a 2K risultati | Team di sviluppatori che necessitano accesso API a Temu |
| Python personalizzato (Playwright) | Avanzato | 1–4 ore+; manutenzione continua | Proxy manuali, CAPTCHA, fingerprint | Completamente personalizzato | Cron/code manuale | Personalizzato | Tempo di sviluppo + costi proxy/CAPTCHA/hosting | Casi limite, team con ingegneri dello scraping |
Quale Temu Scraper dovresti scegliere? Raccomandazioni rapide
- Dropshipper che ha bisogno di fare ricerca prodotti velocemente? Inizia con il piano gratuito di Thunderbit. È il modo più rapido per passare da "voglio dati Temu" a "ho un foglio di calcolo". Se funziona sulle tue pagine target (e dovrebbe funzionare sulla maggior parte delle categorie pubbliche e delle pagine prodotto), hai finito.
- Operatore che vuole controllo visuale e template riutilizzabili? Octoparse ha un template pubblico Temu Details e un builder di workflow visuale. Aspettati 10–30 minuti di configurazione e un po’ di setup proxy/CAPTCHA.
- Sviluppatore che sta costruendo una pipeline dati o uno strumento interno? ScraperAPI o Apify ti offrono workflow API/actor che si integrano con il codice e i job pianificati. Valuta con attenzione gli actor Apify — controlla stato di manutenzione e valutazioni degli utenti.
- Team enterprise che ha bisogno di grandi volumi di dati Temu e consegna a warehouse? Bright Data è la soluzione infrastrutturale. Costosa, ma gestisce scala, unblocking e consegna a S3/BigQuery/Snowflake.
- Ingegnere dello scraping che ha bisogno di logiche insolite? Un Playwright/Selenium personalizzato ti dà il controllo totale. Metti però a budget manutenzione continua, costi proxy e gestione CAPTCHA.
Per la maggior parte degli utenti business non tecnici, consiglierei di testare prima il piano gratuito di Thunderbit. La domanda immediata è sempre: "posso ottenere le righe che mi servono da questa pagina Temu esatta?" — e puoi rispondere in meno di due minuti senza spendere nulla. Per gli sviluppatori, esegui un benchmark del costo per riga riuscita tra Apify, ScraperAPI e un piccolo prototipo Playwright prima di impegnare budget.
Prova Thunderbit gratis per lo scraping di Temu
FAQ sullo scraping di Temu
È legale fare scraping di Temu?
Dipende dalla giurisdizione, dai dati che raccogli, dal metodo di accesso e da come usi i dati. I Termini di utilizzo di Temu limitano esplicitamente l’accesso automatizzato, incluso crawling, scraping o spidering di pagine o dati. I tribunali statunitensi hanno offerto alcuni precedenti favorevoli per l’accesso a dati pubblicamente disponibili (la decisione hiQ v. LinkedIn della Ninth Circuit), ma sentenze successive hanno anche confermato pretese di violazione contrattuale e trespass. In breve: lo scraping di dati pubblicamente disponibili per ricerca può essere difendibile in alcuni contesti, ma contano i Termini di servizio, la normativa sulla privacy, il copyright e il modo in cui usi i dati. Non è consulenza legale — per uso commerciale consulta un legale.
Quanto spesso Temu cambia il layout del sito?
Non è stata documentata una cadenza pubblica. Le segnalazioni della community e l’ecosistema degli strumenti trattano Temu come un bersaglio dinamico, aggiornato di frequente. Presumi che i selettori CSS possano rompersi in qualsiasi momento e preferisci l’estrazione AI/semantica o template mantenuti attivamente rispetto a selettori hard-coded.
Posso fare scraping di Temu senza essere bloccato?
Per pagine pubbliche limitate e con un ritmo responsabile, sì — soprattutto usando strumenti con rendering reale del browser, supporto sessione e throttling. Nessuno strumento può essere considerato una garanzia universale. Lo scraping cloud con IP rotanti funziona bene per le pagine catalogo pubbliche; lo scraping browser con la tua sessione corrente funziona meglio quando regione, login o popup influenzano i dati.
Quali dati posso estrarre dalle pagine prodotto di Temu?
I campi pubblici più comuni includono titolo prodotto, URL, prezzo attuale, prezzo originale, percentuale di sconto, URL delle immagini, valutazione a stelle, numero di recensioni, numero di vendite, nome venditore/negozio, informazioni di spedizione, categoria, specifiche prodotto, varianti (colori, dimensioni) e timestamp dello scraping. I campi esatti disponibili dipendono dal tipo di pagina (elenco vs dettaglio) e dalla regione.
Mi servono proxy per fare scraping di Temu?
Per piccole estrazioni manuali in modalità browser (qualche pagina alla volta), forse no. Per raccolte cloud, pianificate o ad alto volume, in genere sì: servono proxy o un’infrastruttura anti-blocco gestita. Strumenti come Thunderbit, Bright Data e ScraperAPI includono la gestione proxy nella piattaforma, così non devi configurarla separatamente.
Se vuoi approfondire argomenti correlati, dai un’occhiata alle nostre guide su web scraping per il confronto prezzi, i migliori web scraper per ecommerce, estrarre dati da siti web in Excel e come fare scraping in Google Sheets. Puoi anche guardare le guide passo-passo sul canale YouTube di Thunderbit.
Prova Thunderbit per lo scraping di Temu Get Started Free
Scopri di più




