Il web è diventato un territorio selvaggio, in continuo cambiamento — pensate meno a una “biblioteca digitale” e più a una “giungla di dati”. Nel 2025, se provate a estrarre dati da siti moderni, non vi scontrate solo con una parete di JavaScript: avete davanti una fortezza. Ho visto in prima persona come gli strumenti di scraping tradizionali cedano sotto il peso di contenuti dinamici, infinite scroll e barriere anti-bot. Ecco perché l’ascesa del python headless browser non è solo una moda: è una vera svolta per chiunque abbia bisogno di una estrazione dati web affidabile e scalabile.
E non sono solo i tecnici a interessarsene. Entro il 2025, , e oltre il . Che lavoriate in sales, ecommerce o operations, il giusto python headless browser fa la differenza tra “dati a portata di mano” e “dati irraggiungibili”. Quindi andiamo dritti al punto: ho testato, confrontato e usato questi strumenti, e qui vi presento i 10 migliori python headless browser per lo scraping moderno (con un focus speciale su come l’AI stia cambiando le regole del gioco per chi non programma).
Perché un Python Headless Browser è essenziale per lo scraping moderno?
Facciamo chiarezza sul gergo: un python headless browser è semplicemente un browser web che controllate con codice Python, ma senza la finestra ingombrante che compare sullo schermo. Carica le pagine, esegue JavaScript, clicca pulsanti, compila form — tutto in modo invisibile, in background. Pensatelo come un browser fantasma, che lavora senza sosta mentre sorseggiate il caffè.
Perché è importante? Perché i siti moderni sono costruiti per gli utenti, non per i bot. Nascondono i dati dietro JavaScript, richiedono il login e si aspettano che interagiate come una persona reale. Gli scraper tradizionali che si limitano a scaricare l’HTML restano lì, a guardare gusci vuoti. I headless browser, invece, simulano il comportamento reale di un utente: aspettano le chiamate AJAX, scorrono feed infiniti e prendono il contenuto esattamente come lo vedete in Chrome o Firefox ().
Ma c’è di più:
- Velocità ed efficienza: i headless browser saltano il rendering visivo, quindi sono più rapidi e consumano meno memoria — perfetti per lo scraping su larga scala ().
- Supporto ai contenuti dinamici: eseguono JavaScript, così ottenete i dati reali renderizzati, non solo l’HTML grezzo.
- Superpoteri di automazione: dovete fare login, gestire paginazioni o pop-up? I python headless browser possono automatizzare tutto.
- Scalabilità: potete eseguire centinaia di istanze nel cloud, estrarre migliaia di pagine in parallelo e farlo senza sforzo.
Per chi lavora in azienda, questo significa poter finalmente raccogliere lead, monitorare i concorrenti o tracciare i prezzi, anche se il sito sembra costruito come Fort Knox. E con i più recenti strumenti basati sull’AI, non serve essere programmatori per entrare in gioco.
Come abbiamo scelto i migliori Python Headless Browser
Non ho semplicemente lanciato freccette su un elenco di nomi. Ecco cosa ho valutato:
- Prestazioni e velocità: riesce a gestire siti moderni, ricchi di JavaScript, in modo rapido e affidabile?
- Supporto browser: funziona con Chrome, Firefox, WebKit o persino motori legacy come IE?
- Facilità d’uso: è adatto a chi non programma, o serve un dottorato in Python?
- Funzioni AI e no-code: gli utenti business possono sfruttare l’AI per automatizzare lo scraping senza scrivere script?
- Community e supporto: c’è una community attiva, documentazione solida e sviluppo continuo?
- Funzioni uniche: offre qualcosa di speciale, come template istantanei, scraping nel cloud o navigazione tra sottopagine?
Ho visto team perdere settimane a combattere con la configurazione, per poi bloccarsi quando cambia il layout del sito. I migliori strumenti non si limitano a funzionare: si adattano, scalano e vi semplificano la vita.
I 10 migliori Python Headless Browser per lo scraping moderno
Ecco la mia lista definitiva, con un’analisi approfondita di ciò che fa brillare — o inciampare — ciascuno strumento.
1. Thunderbit
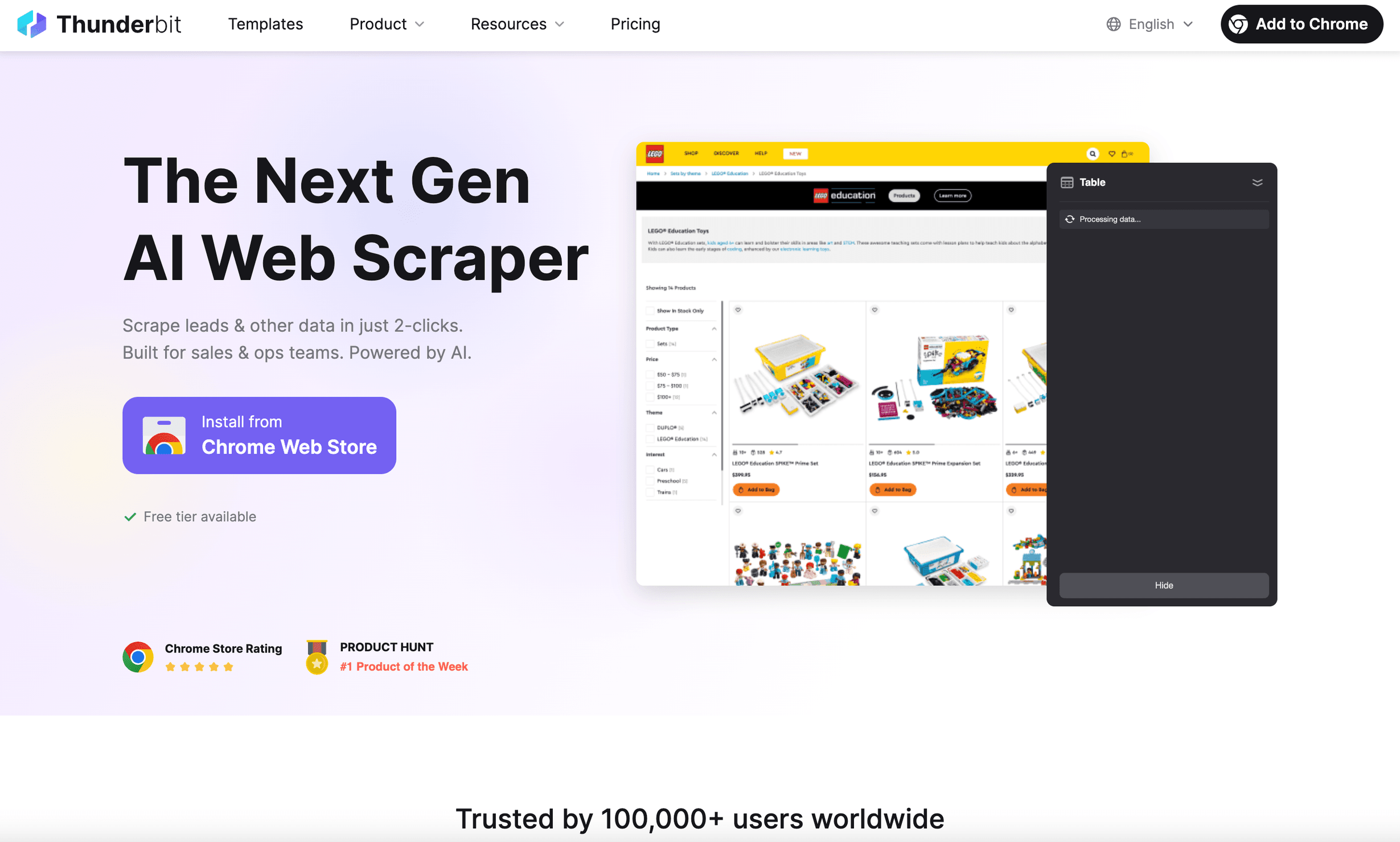 è il python headless browser che avrei voluto avere anni fa. Non è solo uno strumento di automazione browser: è un’estensione Chrome AI-powered web scraper pensata per chi lavora in azienda e vuole risultati, non grattacapi.
è il python headless browser che avrei voluto avere anni fa. Non è solo uno strumento di automazione browser: è un’estensione Chrome AI-powered web scraper pensata per chi lavora in azienda e vuole risultati, non grattacapi.
Perché Thunderbit si distingue:
- AI Suggest Fields: basta cliccare “AI Suggest Fields” e l’AI di Thunderbit legge la pagina, suggerisce quali dati estrarre e configura lo scraper per voi ().
- Template dati istantanei: per i siti più popolari (Amazon, Zillow, LinkedIn, ecc.) avete template con un clic, senza configurazione.
- Scraping di sottopagine e paginazione: Thunderbit può cliccare tra le sottopagine, gestire gli infinite scroll e unire tutti i dati in un’unica tabella.
- Prompt in linguaggio naturale: descrivete ciò che vi serve in inglese semplice; il resto lo fa l’AI di Thunderbit.
- Scraping cloud o nel browser: potete eseguire gli scraping localmente o nel cloud (fino a 50 pagine alla volta per velocizzare).
- Nessun codice richiesto: davvero — se sapete usare un browser, sapete usare Thunderbit.
- Esportazione dati gratuita: esportate in Excel, Google Sheets, Notion o Airtable con un clic.
Ho visto Thunderbit far risparmiare ore a team sales e operations — estrazione di lead, monitoraggio prezzi o aggregazione di dati prodotto senza toccare una riga di codice. È usato da in tutto il mondo, e il feedback è sempre lo stesso: “Non riesco a credere a quanto sia semplice.”
Ideale per: utenti non tecnici, team business, chiunque voglia lasciare il lavoro pesante all’AI.
2. Selenium
 è il capostipite dell’automazione browser. Se avete mai cercato su Google “python headless browser”, probabilmente vi siete imbattuti in Selenium WebDriver.
è il capostipite dell’automazione browser. Se avete mai cercato su Google “python headless browser”, probabilmente vi siete imbattuti in Selenium WebDriver.
Pro:
- Supporta tutti i principali browser: Chrome, Firefox, Safari, Edge, persino Internet Explorer (per i più coraggiosi).
- Community enorme: tantissimi tutorial, plugin e risposte su Stack Overflow.
- Estremamente flessibile: automatizza qualsiasi cosa possa fare un utente — clic, form, navigazione.
Contro:
- La configurazione può essere pesante: dovrete gestire i driver del browser e mantenere le versioni sincronizzate.
- Più lento degli strumenti moderni: il protocollo WebDriver introduce overhead, e scalare a centinaia di browser è macchinoso.
- API verbose: scriverete più codice che con Playwright o Puppeteer.
Ideale per: team con esperienza pregressa in Selenium, test cross-browser o workflow di automazione legacy.
3. Puppeteer
 è la libreria di automazione ad alto livello di Google per Chrome/Chromium. Anche se è nativa di Node.js, chi usa Python può entrarci tramite Pyppeteer.
è la libreria di automazione ad alto livello di Google per Chrome/Chromium. Anche se è nativa di Node.js, chi usa Python può entrarci tramite Pyppeteer.
Pro:
- Ottimizzato per Chrome: veloce, efficiente e strettamente integrato con Chrome DevTools.
- API asincrona: ottima per siti moderni e pesanti di JavaScript.
- Funzioni ricche: screenshot, esportazione PDF, intercettazione del traffico di rete.
Contro:
- Solo Chromium: niente supporto per Firefox o Safari.
- Nativo di Node.js: chi usa Python deve affidarsi a Pyppeteer (che però oggi non è più mantenuto — vedi sotto).
Ideale per: sviluppatori che vogliono un’automazione Chrome veloce e affidabile e non hanno bisogno del supporto cross-browser.
4. Playwright
 è il nuovo arrivato, sviluppato da Microsoft — ed è rapidamente diventato il mio punto di riferimento per lo scraping avanzato.
è il nuovo arrivato, sviluppato da Microsoft — ed è rapidamente diventato il mio punto di riferimento per lo scraping avanzato.
Pro:
- Supporto multi-browser: automatizza Chromium, Firefox e WebKit con una sola API.
- Auto-waiting: niente più tentativi a indovinare quando una pagina è pronta — Playwright aspetta per voi.
- Concorrenza: esegue più browser context in parallelo per una velocità fulminea.
- Python-first: binding Python nativi, sia async sia sync.
Contro:
- Installazione più pesante: include più browser, quindi la configurazione è un po’ più corposa.
- Serve comunque programmare: non è adatto ai non tecnici quanto Thunderbit.
Ideale per: sviluppatori che hanno bisogno di un’automazione solida e moderna, soprattutto per web app complesse e dinamiche.
5. Headless Chrome
 è il motore che alimenta molti degli strumenti qui sopra. Potete controllarlo direttamente tramite il Chrome DevTools Protocol (CDP) per la massima flessibilità.
è il motore che alimenta molti degli strumenti qui sopra. Potete controllarlo direttamente tramite il Chrome DevTools Protocol (CDP) per la massima flessibilità.
Pro:
- Supporto web all’avanguardia: se funziona in Chrome, funziona anche in headless Chrome.
- Controllo granulare: accesso a ogni angolo e anfratto del browser.
Contro:
- Curva di apprendimento ripida: dovrete parlare CDP o usare una libreria wrapper.
- Solo Chrome: nessun supporto cross-browser.
Ideale per: esperti che costruiscono pipeline di automazione personalizzate o integrano Chrome a basso livello.
6. Pyppeteer
 è il port non ufficiale di Puppeteer per Python. Ha portato l’automazione asincrona di Chrome in Python, ma… c’è un problema.
è il port non ufficiale di Puppeteer per Python. Ha portato l’automazione asincrona di Chrome in Python, ma… c’è un problema.
Pro:
- API in stile Puppeteer: se conoscete Puppeteer, vi sentirete subito a casa.
- Automazione Chrome veloce: ottimo per siti dinamici.
Contro:
- Non mantenuto: il progetto originale non viene più aggiornato (gli sviluppatori consigliano di passare a Playwright).
- Solo Chromium: niente Firefox o Safari.
Ideale per: progetti legacy che usano già Pyppeteer. Per i nuovi progetti, usate Playwright.
7. Splash
 è un headless browser leggero e scriptabile con API HTTP, creato dal team Scrapinghub (oggi Zyte).
è un headless browser leggero e scriptabile con API HTTP, creato dal team Scrapinghub (oggi Zyte).
Pro:
- Leggero: usa QtWebKit, quindi consuma meno risorse di Chrome.
- API HTTP: lo controllate da qualsiasi linguaggio, non solo Python.
- Ottimo per Scrapy: si integra senza problemi con gli spider Scrapy per il rendering JavaScript.
Contro:
- Motore WebKit più vecchio: può avere difficoltà con JavaScript all’avanguardia.
- Serve scripting Lua: per interazioni avanzate dovrete imparare un po’ di Lua.
Ideale per: utenti di Scrapy che hanno bisogno di rendering JavaScript occasionale, o per attività leggere di rendering lato server.
8. PhantomJS
 è il primo headless browser scriptabile, basato su WebKit. È stato un pioniere — ma oggi è per lo più superato.
è il primo headless browser scriptabile, basato su WebKit. È stato un pioniere — ma oggi è per lo più superato.
Pro:
- Scripting semplice: facile da automatizzare con JavaScript.
- Supporto legacy: funziona ancora per siti vecchi e statici.
Contro:
- Non mantenuto: nessun aggiornamento dal 2016.
- Motore obsoleto: non riesce a gestire i siti moderni ricchi di JavaScript.
- Rischi di sicurezza: nessuna patch recente.
Ideale per: mantenere script legacy. Per nuovi progetti, migrate a Playwright o Puppeteer.
9. HtmlUnit
 è un headless browser basato su Java che simula il comportamento di un browser. È veloce e leggero, ma non è un vero motore browser.
è un headless browser basato su Java che simula il comportamento di un browser. È veloce e leggero, ma non è un vero motore browser.
Pro:
- Java puro: perfetto per ambienti fortemente orientati a Java.
- Veloce per pagine statiche: non serve avviare un browser completo.
Contro:
- Supporto JS limitato: fatica con siti moderni e dinamici.
- Non nativo per Python: richiede livelli di integrazione (ad esempio HtmlUnitDriver di Selenium).
Ideale per: workflow basati su Java, test di app legacy o scraping di pagine semplici renderizzate lato server.
10. TrifleJS
 è un headless browser per Internet Explorer (IE), pensato per automatizzare vecchie web app su Windows.
è un headless browser per Internet Explorer (IE), pensato per automatizzare vecchie web app su Windows.
Pro:
- Automazione IE: gestisce vecchie app intranet o sistemi che funzionano solo in IE.
- API simile a PhantomJS: servono modifiche minime per gli script PhantomJS.
Contro:
- Solo Windows: nessun supporto multipiattaforma.
- Obsoleto: IE è stato ritirato; TrifleJS è di nicchia e raramente mantenuto.
Ideale per: workflow legacy specializzati in cui l’automazione IE è ancora necessaria.
Tabella comparativa delle funzionalità: i Python Headless Browser in sintesi
| Strumento | Supporto browser | Prestazioni e scala | Facilità d’uso | Funzioni AI/no-code | Community e supporto | Ideale per |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome (estensione/cloud) | Alte (parallelismo nel cloud) | Il più semplice — zero codice | Sì (AI, template) | In crescita, attiva | Non programmatori, sales/ops, estrazione rapida di dati |
| Selenium | Tutti i principali browser | Moderata | Moderata (configurazione) | No | Enorme, matura | Cross-browser, legacy, automazione dei test |
| Puppeteer | Chromium/Chrome | Molto alte | Alta (per sviluppatori) | No | Ampia (Node.js) | Solo Chrome, sviluppatori, automazione veloce |
| Playwright | Chromium, Firefox, WebKit | Molto alte (multi-context) | Alta (per sviluppatori) | No | In rapida crescita | Avanzato, multi-browser, scraping moderno |
| Headless Chrome | Chrome/Edge | Molto alte | Bassa (CDP manuale) | No | N/A (fondamento) | Personalizzato, esperti, controllo a basso livello |
| Pyppeteer | Chromium/Chrome | Alte | Moderata (async) | No | Piccola, non mantenuta | Script Pyppeteer legacy |
| Splash | QtWebKit | Moderata | Moderata (API/Lua) | No | Di nicchia (Scrapy/Zyte) | Utenti Scrapy, rendering JS leggero |
| PhantomJS | WebKit (vecchio) | Basse (ormai obsoleto) | Moderata (JS) | No | Defunto | Solo legacy |
| HtmlUnit | Simulato (Java) | Moderata/alte (statico) | Bassa (Java) | No | Piccola, centrata su Java | Workflow Java, pagine semplici/statiche |
| TrifleJS | Internet Explorer (Trident) | Basse/Moderate | Moderata (JS, Win) | No | Minuscola, legacy | Automazione legacy solo IE |
Come scegliere il giusto Python Headless Browser per la vostra azienda
Ecco il mio foglio rapido per scegliere lo strumento giusto:
- Vi serve uno scraping veloce, no-code, con aiuto dell’AI? Scegliete . È il modo più semplice per chi non programma di ottenere dati affidabili — soprattutto per team sales, ecommerce o ricerca.
- Volete il massimo controllo e supporto cross-browser? è la scelta migliore. È robusto, moderno e progettato per scalare.
- Avete già investito in Selenium? Restate su — resta ancora il re dei workflow legacy e multi-browser.
- State costruendo automazione solo per Chrome come sviluppatori? (o Playwright) è veloce e potente.
- Dovete estrarre pagine semplici e statiche in un ambiente Java? è leggero e facile da integrare.
- Dovete mantenere script legacy o app che funzionano solo su IE? e sono i vostri amici di ultima istanza.
E ricordate: il miglior strumento è quello che si adatta al vostro workflow, alle competenze del team e alle esigenze del business. A volte significa combinare più soluzioni — usare Thunderbit per i lavori rapidi, Playwright per quelli più pesanti e Selenium per i sistemi legacy.
FAQ
1. Cos’è un python headless browser e perché mi serve per lo scraping?
Un python headless browser è un browser web controllato con codice Python, ma che gira in modo invisibile (senza interfaccia grafica). È essenziale per fare scraping di siti moderni, ricchi di JavaScript, perché può eseguire script, gestire interazioni utente ed estrarre contenuti completamente renderizzati — cosa che i tradizionali scraper HTML non possono fare.
2. Qual è il miglior python headless browser per utenti non tecnici?
è la scelta migliore per chi non programma. Usa l’AI per automatizzare la configurazione, offre template istantanei e permette di estrarre dati in un paio di clic — senza scrivere codice.
3. In cosa differiscono Playwright e Puppeteer per chi usa Python?
Playwright supporta più browser (Chromium, Firefox, WebKit) e ha binding Python solidi, quindi è ideale per l’automazione avanzata. Puppeteer è solo per Chrome e nativo di Node.js, ma chi usa Python può usare Pyppeteer (anche se oggi non è più mantenuto). Per nuovi progetti Python, Playwright è la scelta migliore.
4. Selenium è ancora rilevante per lo scraping web moderno?
Sì: Selenium è ancora molto usato, soprattutto per test cross-browser e automazione legacy. Tuttavia è più lento e più complesso da configurare rispetto a strumenti più recenti come Playwright o Thunderbit, ed è meno efficiente per lo scraping su larga scala.
5. Quando dovrei usare strumenti legacy come PhantomJS, HtmlUnit o TrifleJS?
Solo per mantenere o migrare vecchi workflow. PhantomJS e TrifleJS sono obsoleti, mentre HtmlUnit è più adatto ad ambienti Java con pagine semplici. Per i nuovi progetti, scegliete strumenti moderni e ancora mantenuti attivamente.
Se siete pronti a vedere com’è lo scraping moderno potenziato dall’AI, . E per altri approfondimenti sull’automazione web, date un’occhiata al . Buono scraping — che i vostri dati siano sempre freschi e i vostri browser per sempre headless.
Scopri di più