

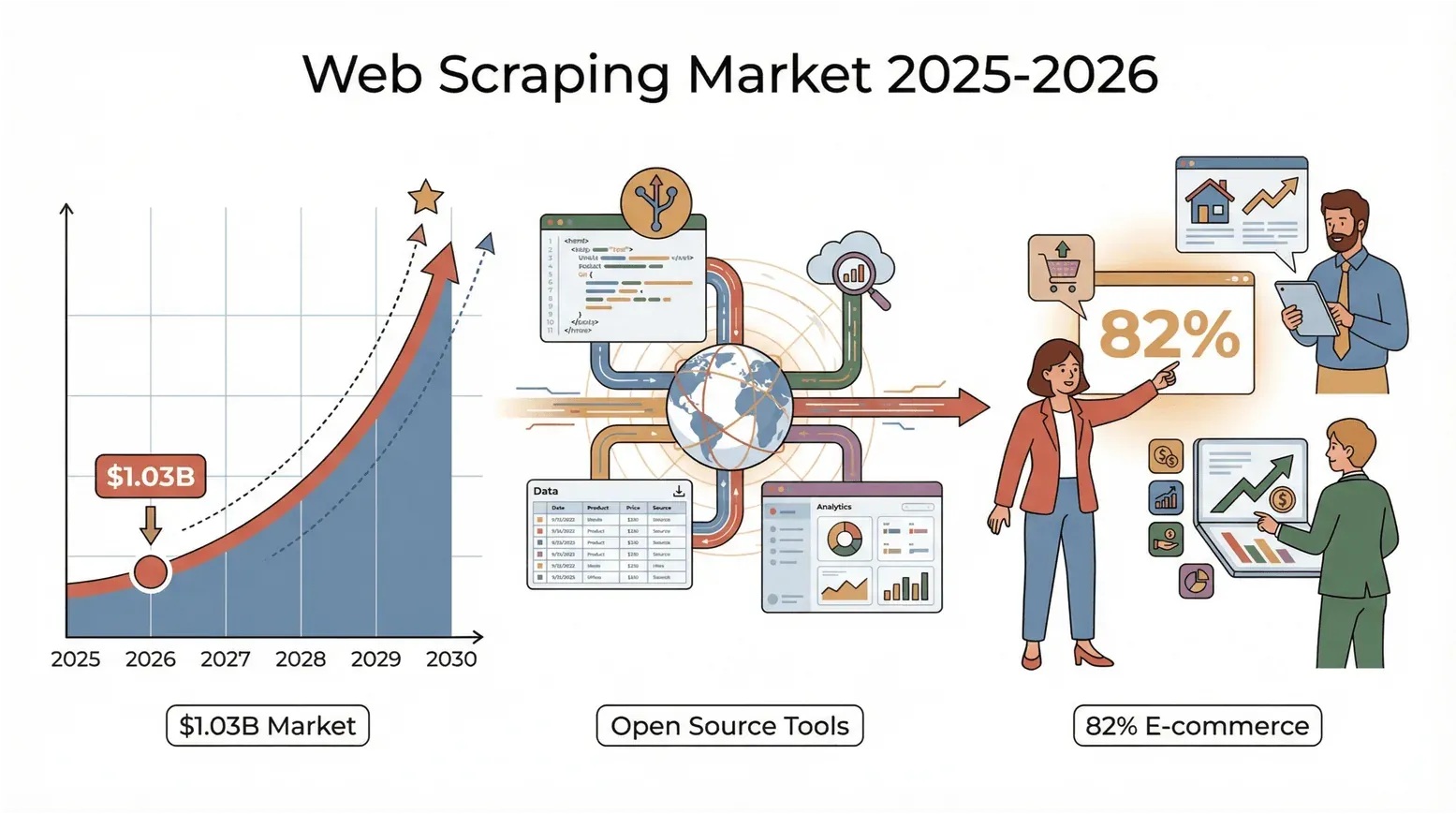
Il web trabocca di dati e, nel 2026, la corsa per trasformare quel caos in insight è più intensa che mai. Che tu lavori nelle vendite, nell’e-commerce, nel real estate, o sia semplicemente un appassionato di dati come me, probabilmente ti sei già accorto che il vecchio rituale del “copia e incolla” non basta più. Ecco un dato impressionante: secondo Mordor Intelligence, il mercato globale del web scraping ha raggiunto 1,03 miliardi di dollari nel 2025 (citato nel report 2026 di PromptCloud sullo stato del web scraping) ed è sulla buona strada per raddoppiare circa entro il 2030.
E non sono solo i colossi tech: l’82% delle aziende e-commerce e oltre un terzo delle società di investimento stanno raccogliendo dati dal web per lead, prezzi e ricerche di mercato (Browsercat). In sintesi: se non stai usando uno strumento di web scraping, probabilmente stai lasciando sul tavolo soldi — e insight.
Ma ecco la buona notizia: gli strumenti open source per il web scraping oggi sono più potenti, accessibili e sostenuti dalla community che mai. Che tu sia un professionista Python, un appassionato di JavaScript o un utente business che vuole i dati senza complicazioni, c’è uno strumento adatto a te. Ho passato anni tra SaaS e automazione e ho visto questo ecosistema evolversi. Quindi, tuffiamoci nei 5 migliori strumenti open source per il web scraping da esplorare nel 2026 — più qualche consiglio su come scegliere quello giusto per le tue esigenze.
Perché scegliere strumenti open source per il web scraping?
Cos’è il data scraping e come farlo nel 2026 Get Started Free
Gli strumenti open source per il web scraping sono i coltellini svizzeri del mondo dei dati. Sono convenienti (niente licenze), flessibili (puoi personalizzare tutto) e trasparenti (vedi esattamente come funzionano). Ma la vera magia? La community. Gli strumenti open source sono sostenuti da migliaia di sviluppatori e utenti che condividono plugin, tutorial e correzioni — così non resti mai da solo (Oreate AI).
Rispetto agli strumenti commerciali, le soluzioni open source ti mettono al volante. Non sei vincolato alla roadmap o ai prezzi di un vendor e puoi adattare i tuoi scraper quando i siti cambiano. Inoltre, molti servizi commerciali di scraping sono costruiti proprio sopra questi motori open source — quindi perché non andare direttamente alla fonte?
Come abbiamo selezionato i migliori strumenti open source per il web scraping
Con così tante opzioni disponibili, mi sono concentrato su alcuni criteri chiave:
- Facilità d’uso: chi non programma può iniziare subito? Ci sono opzioni visuali o basate su AI?
- Scalabilità: lo strumento gestisce progetti grandi o solo lavori una tantum?
- Supporto per linguaggi e piattaforme: Python, JavaScript, browser, desktop — qualcosa per ogni stack.
- Community e manutenzione: lo strumento viene aggiornato attivamente? Ci sono forum, documentazione e plugin?
- Funzionalità uniche: rilevamento dei campi con AI, scraping di sottopagine, pianificazione, supporto cloud e altro.
Ho considerato anche feedback reali e casi d’uso business, perché il miglior strumento è quello che risolve davvero il tuo problema.
I 5 migliori strumenti open source per il web scraping da esplorare
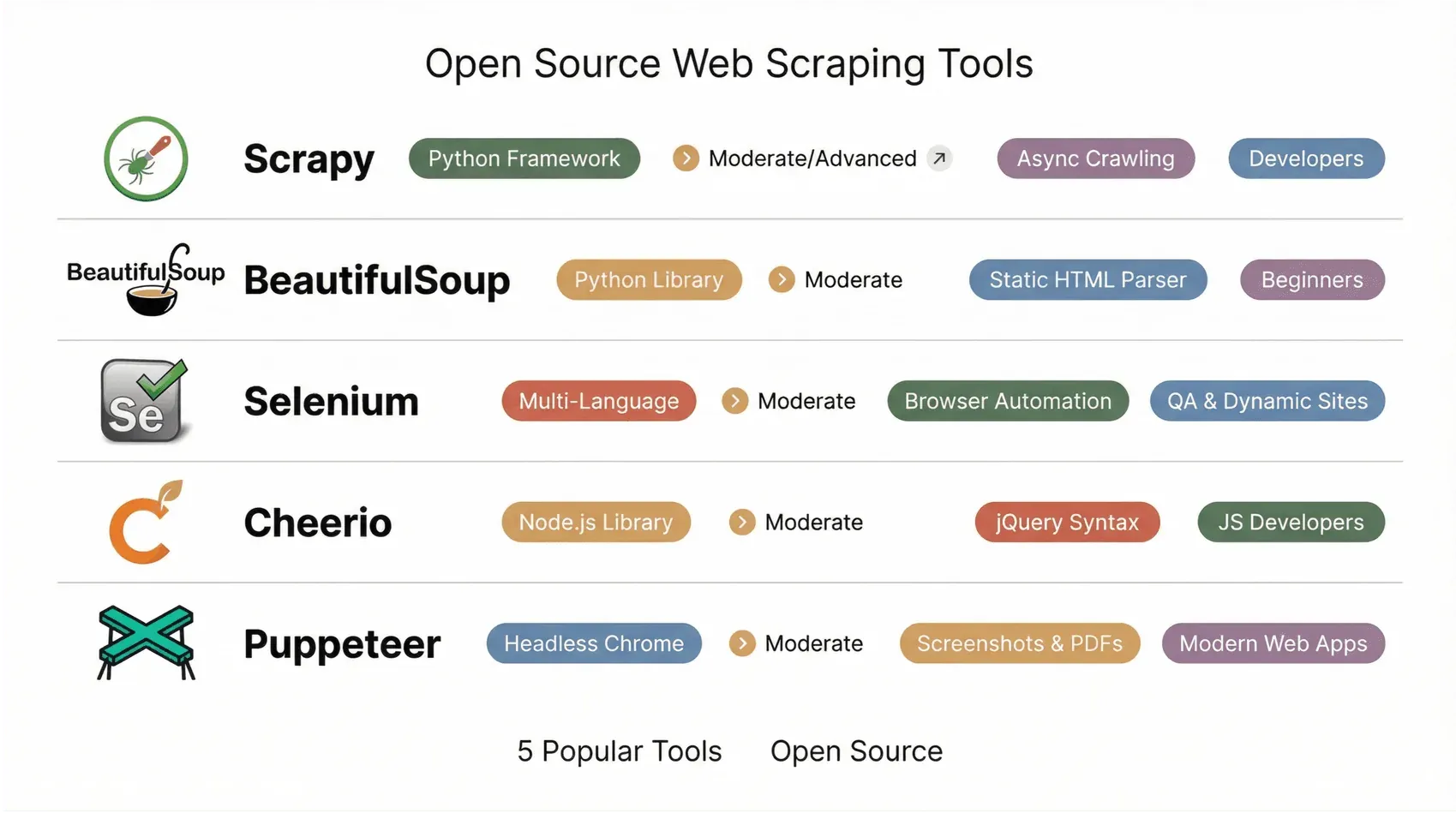
Passiamo al meglio. Ecco la mia selezione, dalla semplicità potenziata dall’AI ai mostri sacri per sviluppatori.
1. Scrapy
Scrapy è il sogno di ogni sviluppatore Python. È un framework collaudato per creare crawler e pipeline dati scalabili e personalizzabili. Definisci gli “spiders” in Python e Scrapy si occupa di coda, throttling ed esportazione in JSON, CSV o XML. Dalla versione 2.14 (ottobre 2025) e dalla patch 2.14.1 (gennaio 2026), una grossa parte dell’infrastruttura interna basata su Twisted Deferred è stata riscritta come coroutine native asyncio, con un nuovo punto di ingresso AsyncCrawlerProcess che si integra bene con il resto dell’ecosistema Python moderno asincrono; inoltre, il reactor asyncio è ora l’impostazione predefinita per i progetti generati di recente. Attenzione: Scrapy 2.14+ richiede Python 3.10 o successivo.
L’ecosistema di plugin è enorme, con middleware per proxy, cookie e persino integrazione con browser headless per siti dinamici. Scrapy è il framework a cui ricorre la maggior parte dei team quando deve fare crawling di interi cataloghi e-commerce o aggregare notizie su larga scala. La curva di apprendimento è ripida per chi non programma, ma se vuoi potenza e flessibilità, Scrapy mantiene le promesse ([Octoparse](https://www.octoparse.com/blog/10-best-open-source-web




