

Oggi quasi un click su due, sul web, non lo fa una persona: lo fa un bot. E gran parte di queste automazioni serve a una cosa sola — rastrellare link, dati e URL a ritmo industriale. Se tu invece raccogli ancora tutto a mano, parti già con il fiato corto.
Mi sono messo a provare 12 strumenti per estrarre link — dalle estensioni Chrome con l’AI fino alle librerie Python — per scoprire quali tengono davvero botta quando ti servono migliaia di URL e ti servono in fretta.
Ecco quello che è venuto fuori.
Perché gli Estrattori di Link Contano Davvero
Mettiamola così: il web trabocca di dati, e le aziende fanno a gara per trasformare quel caos in qualcosa di concreto su cui decidere. Estrattori di link ed estrattori di URL sono ormai pane quotidiano per i team che vogliono:
- Generare lead: in pochi minuti il team sales recupera i link ai profili aziendali da una directory o da LinkedIn, e li passa subito ad altri strumenti per tirar fuori i contatti. Addio click a non finire.
- Aggregare contenuti e curare la SEO: chi fa marketing può mettere insieme tutti gli URL degli articoli di un blog, tenere d’occhio i backlink dei concorrenti o passare al setaccio la struttura di un sito per stanare i link rotti.
- Sorvegliare i concorrenti e fare ricerche di mercato: il team operations raccoglie in automatico i link a nuovi prodotti, pagine prezzi o comunicati stampa, tenendo sott’occhio la concorrenza senza alzare un dito.
- Automatizzare i flussi e guadagnare tempo: gli scraper di link moderni macinano URL a blocchi, si infilano nelle sottopagine ed esportano tutto in formati ordinati (CSV, Excel, Google Sheets, Notion e altro ancora). Tradotto: niente più sessioni infinite di copia-incolla e niente file di testo da ripulire a mano.
E visto che ogni giorno vengono scansionate decine di miliardi di pagine web, pensare di farlo a mano non sta in piedi. Un buon estrattore di link è come un assistente con il turbo: non si stanca, non si lascia sfuggire un URL e non ti chiede mai la pausa caffè.
Come Abbiamo Scelto i Migliori Estrattori di Link
Con tutti gli strumenti che girano là fuori, trovare quello giusto può sembrare uno speed dating a una conferenza tech: promettono tutti di essere “l’anima gemella”, ma solo pochi mantengono la parola. Ecco i criteri con cui ho stretto il campo ai 12 migliori:
- Facilità d’uso: lo può usare anche chi non scrive una riga di codice, senza una laurea in regex? Le soluzioni no-code e low-code hanno guadagnato punti.
- Estrazione in massa e su più livelli: regge centinaia di URL in un colpo solo? Sa entrare nelle sottopagine e seguire i link da solo?
- Esportazione e integrazioni: butta fuori i dati su CSV, Excel, Google Sheets, Notion, Airtable o via API? Meno lavoro manuale resta, meglio è.
- Tipo di utente e flessibilità: è tagliato su chi fa business, su analisti o su sviluppatori? Alcuni vanno bene per chiunque, altri sono più di nicchia.
- Funzioni avanzate: riconoscimento con AI, pianificazione, scalabilità in cloud, pulizia dei dati e template per i siti più diffusi.
- Prezzo e scalabilità: c’è un piano gratis, un pay-as-you-go o una proposta enterprise? Ho guardato cosa offre davvero ciascuno strumento rispetto a quanto chiede.
Ho messo dentro un po’ di tutto, dalle estensioni del browser alle piattaforme enterprise: quindi, che tu sia un founder che fa tutto da solo o un team dati dentro una Fortune 500, qui trovi lo strumento che fa per te.
Thunderbit: L’Estrattore di Link Più Intelligente per Chi Fa Business
Cominciamo dalla cima della lista. Thunderbit è la mia prima scelta per estrarre link — e non solo perché ci ho messo le mani anch’io. Thunderbit è un’estensione Chrome per il web scraping con AI pensata per chi lavora in azienda e vuole risultati, in fretta.
Cosa lo rende così diverso? È come avere un tirocinante AI che ti ascolta sul serio. Gli descrivi a parole quello che ti serve (“Prendimi tutti i link ai prodotti e i prezzi da questa pagina”) e ci pensa l’AI di Thunderbit. Niente selettori da aggiustare, niente script da scrivere.
E la cosa non finisce qui:
- URL in massa: incolli un singolo URL o un elenco da centinaia di link — Thunderbit li digerisce tutti in una passata.
- Navigazione nelle sottopagine: devi pescare link da una pagina elenco e poi visitare ogni scheda di dettaglio per recuperarne altri? La logica di scraping multilivello di Thunderbit è fatta apposta per questo.
- Esportazione ordinata: una volta presi i link, rinomini i campi, li classifichi e li mandi dritti su Google Sheets, Notion, Airtable, Excel o CSV. Zero rogne di post-produzione.
Estrai link da qualsiasi sito web con l’AI Get Started Free
A Thunderbit si affidano oltre 30.000 utenti in tutto il mondo: team sales, agenti immobiliari, piccoli e-commerce che lavorano in proprio. E sì, c’è anche un piano gratuito (fino a 6 pagine, o 10 con il boost di prova), così lo metti alla prova senza rischiare nulla.
Prova gratis l’Estrattore di Link Thunderbit
Le Funzioni che Fanno la Differenza in Thunderbit
Andiamo a vedere da vicino cosa sposta davvero l’ago:
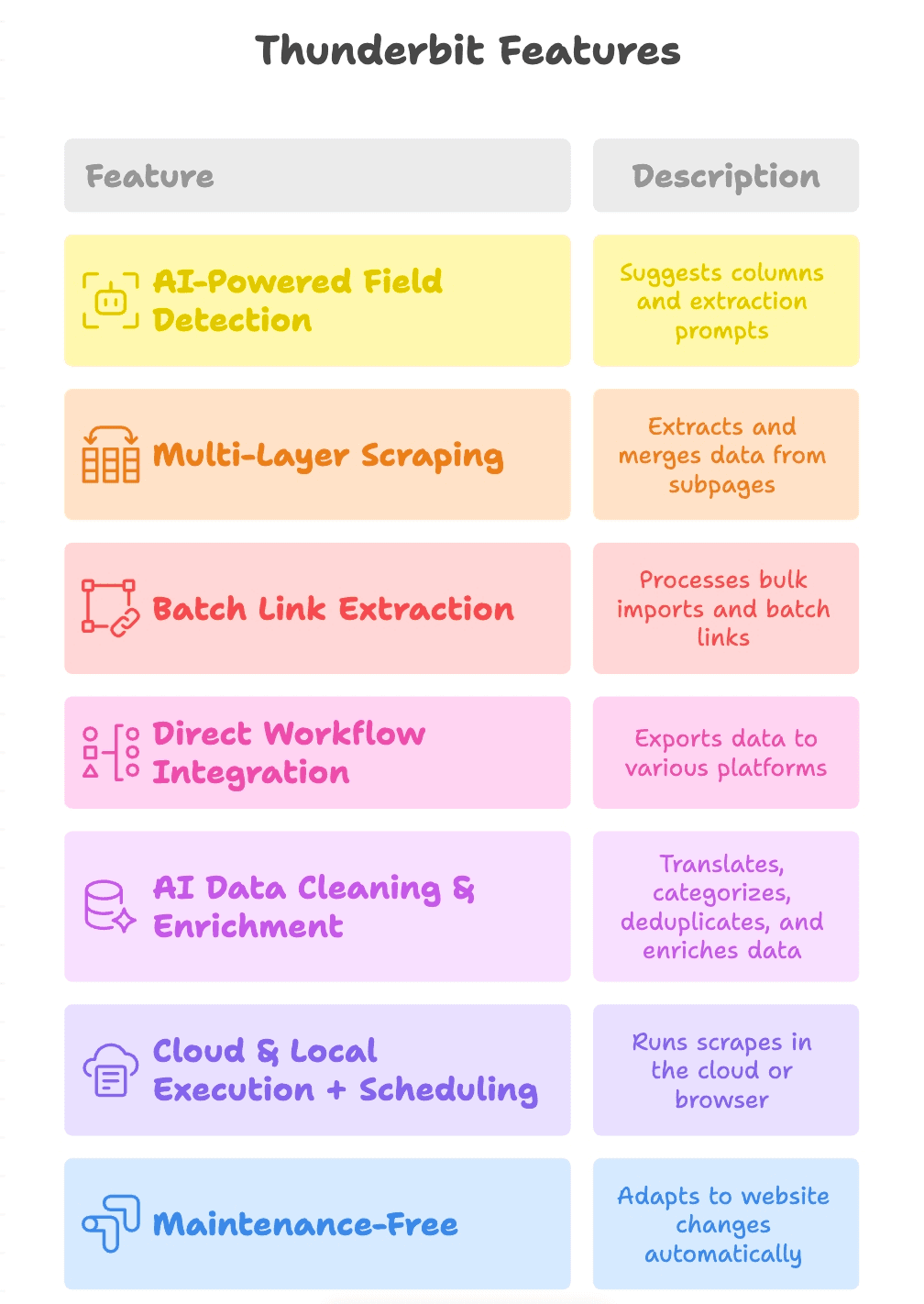
- Rilevamento dei campi con AI: clicchi su “AI Suggest Fields” e Thunderbit legge la pagina, ti propone le colonne (tipo “Link Prodotto”, “URL PDF”, “Email Contatto”) e ti prepara persino i prompt di estrazione per ogni campo.
- Scraping multilivello: Thunderbit segue i link da una pagina madre alle sottopagine (schede prodotto, download PDF e simili), tira fuori altri link e ricuce tutto in un’unica tabella.
- Estrazione link in batch: che tu stia lavorando su una pagina o su mille, Thunderbit gestisce import massicci ed estrazioni in blocco senza scomporsi.
- Aggancio diretto ai tuoi flussi: esporti i risultati su Google Sheets, Notion, Airtable, oppure scarichi in CSV/Excel. I dati arrivano esattamente dove servono al tuo team.
- Pulizia e arricchimento con AI: Thunderbit può tradurre, categorizzare, eliminare i doppioni e perfino arricchire i dati mentre li estrae — così l’output è già pronto all’uso, non un mucchio di roba grezza.
- Esecuzione cloud e locale + pianificazione: lanci gli scraping nel cloud quando vuoi velocità, oppure nel browser per i siti che chiedono il login. E puoi programmare attività ricorrenti per tenere i dati sempre freschi.
- Manutenzione zero: l’AI di Thunderbit si adatta quando i siti cambiano, così perdi meno tempo a rattoppare scraper rotti e più tempo a portare a casa risultati.
Octoparse: Estrattore di Link No-Code per Tutti
Octoparse è un veterano del mondo no-code. È un’app desktop (Windows/Mac) con un’interfaccia visiva point-and-click. Carichi una pagina, clicchi i link che ti interessano e al resto pensa lui.
- Perfetto per cominciare: niente codice. Clicchi, estrai, fine.
- Gestisce paginazione e contenuti dinamici: Octoparse preme i pulsanti “Next”, scorre la pagina e fa anche il login nei siti.
- Scraping in cloud e pianificazione: con i piani a pagamento esegui i job nel cloud e automatizzi le attività ricorrenti.
- Opzioni di esportazione: scarichi in CSV, Excel, JSON o mandi tutto a un database.
Il piano gratuito è davvero generoso per i lavori piccoli (fino a 10 task e 50.000 righe al mese), ma chi ha bisogno di più dovrà passare a pagamento (si parte da circa 75 $ al mese).
Apify: Estrattore di URL Flessibile per Flussi su Misura
Apify è il coltellino svizzero dello scraping. Ti mette a disposizione un marketplace di “actor” già pronti (mini-strumenti di scraping) e, se vuoi, ti lascia scrivere script personalizzati in JavaScript o Python.
- Pronto all’uso o su misura: prendi gli actor della community per le attività più comuni, oppure ti cuci addosso una soluzione tutta tua.
- Scraping in massa e programmato: accodi gli URL, fai girare più job in parallelo e pianifichi estrazioni ricorrenti.
- API-first: esporti in JSON, CSV, Excel o Google Sheets e infili tutto nella tua pipeline dati.
- Pay-as-you-go: crediti gratis ogni mese, poi paghi in base a quanto usi.
Apify è perfetto per team semi-tecnici e sviluppatori che vogliono flessibilità e scala.
Bright Data URL Scraper: Estrazione Link di Livello Enterprise
Bright Data è tagliato sulle aziende che fanno scraping su larga scala. Il loro Data Collector include un URL Scraper già configurato per i lavori ad alto volume.
- Regge volumi enormi: estrai migliaia o milioni di pagine, con un’infrastruttura proxy solida che ti tiene lontano dai blocchi.
- Template preimpostati: scraper già pronti per e-commerce, social, immobiliare e altro.
- Funzioni enterprise: strumenti per la compliance, supporto di esperti e anti-blocco avanzato.
- Prezzi: si parte da circa 350 $ per 100.000 caricamenti di pagina — chiaramente roba da grandi aziende.
Per una startup può essere troppo. Ma per scraping mission-critical e ad alto volume, Bright Data è una corazzata.
WebHarvy: Estrattore di Link Visivo, Semplice come Cliccare
WebHarvy è un’app desktop (Windows) che ti fa estrarre link semplicemente cliccandoci sopra dentro il browser integrato.
- Semplicissimo: clicchi un link e WebHarvy ti evidenzia tutti gli elementi simili da estrarre.
- Supporto alle espressioni regolari: pattern già pronti per le attività comuni, senza scrivere codice.
- Esportazione in Excel, CSV, JSON, XML, SQL: comodo per chi fa business e vuole i dati in formati che già conosce.
- Licenza una tantum: paghi una volta e lo usi per sempre.
Ottimo per piccole imprese, ricercatori o chiunque voglia un modo rapido e senza grane per recuperare link senza programmare.
Web Scraper (estensione Chrome): Link al Volo, Dentro al Browser
La Web Scraper Chrome Extension è uno strumento gratuito e open source che trasforma il browser in uno scraper.
- Definisci le sitemap: spieghi al tool come muoversi e cosa estrarre.
- Gestisce paginazione e crawling multilivello: passa da categorie a sottocategorie fino alle pagine di dettaglio.
- Esporta in CSV/XLSX: scarichi i dati direttamente dal browser.
- Template della community: un mucchio di sitemap condivise per i siti più gettonati.
Perfetta per lavoretti rapidi e saltuari, o per studenti e piccoli team a budget ridotto.
ScraperAPI: Estrattore di Link Scalabile per Sviluppatori
ScraperAPI è pensato per gli sviluppatori che vogliono scaricare pagine web su larga scala senza impazzire con proxy, blocchi o CAPTCHA.
- Basato su API: mandi un URL e ti torna l’HTML o i dati già estratti.
- Scala e anti-bot: rotazione dei proxy, rendering JavaScript e risoluzione dei CAPTCHA, tutto integrato.
- Si incastra nel tuo codice: gira con Python, Node.js o qualunque altro linguaggio.
- Prezzi: piano gratuito (circa 1000 chiamate API), poi paghi a richiesta.
Ottimo per crawler su misura o quando ti serve affidabilità e velocità su grandi numeri.
ParseHub: Estrattore di Link Visivo con Selezione Avanzata
ParseHub è un’app desktop (Windows, Mac, Linux) che ti fa montare progetti di scraping in modo visuale.
- Selezione e navigazione avanzate: clicchi, cicli ed estrai link in modo condizionale, anche da elementi dinamici o nascosti.
- Gestisce pagine annidate: prima le categorie, poi le pagine di dettaglio, poi recuperi altri link.
- Esporta in CSV, Excel, JSON: esecuzioni cloud e accesso API nei piani a pagamento.
- Piano gratuito: 5 progetti, fino a 200 pagine per esecuzione.
ParseHub è molto amato da chi fa marketing e ricerca e vuole potenza senza mettere mano al codice.
Scrapy: Estrattore di Link in Python per Sviluppatori
Scrapy è il punto di riferimento per gli sviluppatori Python che vogliono il controllo totale.
- Code-first: ti costruisci spider su misura per esplorare ed estrarre link su qualsiasi scala.
- Crawling distribuito: efficiente, asincrono e personalizzabile fin nei dettagli.
- Esportazione in CSV, JSON, XML o database: l’output lo decidi tu.
- Open source e gratuito: ma l’ambiente te lo gestisci da solo.
Se con Python ci sguazzi, Scrapy è una delle soluzioni più potenti che esistano.
Diffbot: Estrattore di Link con AI per Dati Strutturati
Diffbot è il “cervello AI” dello scraping. Legge le pagine e ti restituisce dati strutturati — link compresi — senza che tu debba configurare niente a mano.
- Riconoscimento automatico dei contenuti: gli passi un URL e ti torna roba strutturata (articoli, prodotti, link e così via).
- Crawlbot e Knowledge Graph: passa al setaccio interi siti oppure interroghi il loro gigantesco indice del web.
- Basato su API: lo agganci ai tuoi strumenti BI o alla pipeline dati.
- Prezzi enterprise: da circa 299 $ al mese, ma la qualità si paga.
Perfetto per le aziende che vogliono dati puliti e ordinati senza dover badare agli scraper.
Cheerio: Estrattore di Link Leggero per Node.js
Cheerio è un parser HTML veloce, in stile jQuery, per Node.js.
- Velocissimo: macina l’HTML in pochi millisecondi.
- Sintassi familiare: se conosci jQuery, Cheerio lo conosci già.
- Ottimo per pagine statiche: non fa rendering del JS, ma per i contenuti renderizzati lato server è perfetto.
- Open source e gratuito: lo abbini ad axios o fetch per le richieste.
Ideale per sviluppatori che scrivono script su misura e vogliono velocità e semplicità.
Puppeteer: Automazione del Browser per Scraping Avanzato di Link
Puppeteer è una libreria Node.js per pilotare Chrome in modalità headless.
- Automazione completa del browser: carica pagine, clicca, scorre e interagisce come farebbe una persona vera.
- Gestisce contenuti dinamici e login: perfetto per siti pieni di JavaScript o con flussi complicati.
- Controllo al millimetro: attesa degli elementi, screenshot, intercettazione delle richieste di rete.
- Open source e gratuito: ma più esoso di risorse e più lento rispetto agli strumenti leggeri.
Tira fuori Puppeteer quando devi estrarre link da siti che agli scraper più semplici fanno le bizze.
Confronto Lampo: Quale Estrattore di Link Fa per Te?
Ecco un raffronto veloce dei 12 strumenti:
| Strumento | Ideale per | Supporto batch e sottopagine | Opzioni di esportazione | Prezzo |
|---|---|---|---|---|
| Thunderbit | Non programmatori, business | Sì (AI, multilivello) | Excel, CSV, Sheets, Notion, Airtable | Prova gratuita, da circa 9 $/mese |
| Octoparse | Utenti no-code, analisti | Sì | CSV, Excel, JSON, cloud storage | Piano gratuito, da circa 75 $/mese |
| Apify | Semi-tech, sviluppatori | Sì | CSV, JSON, Sheets via API | Crediti gratuiti, pay-per-use |
| Bright Data | Enterprise | Sì (alto volume) | CSV, JSON, NDJSON via API | Circa 350 $/100k pagine |
| WebHarvy | Non programmatori, desktop | Sì | Excel, CSV, JSON, XML, SQL | Licenza a pagamento |
| Web Scraper Extension | Chiunque, rapido/gratuito | Sì | CSV, XLSX | Gratis, open source |
| ScraperAPI | Sviluppatori, utenti API | Sì | JSON (HTML via API) | 1000 richieste gratis, piani a pagamento |
| ParseHub | Non programmatori, avanzato | Sì | CSV, Excel, JSON, API | 5 progetti gratis, poi a pagamento |
| Scrapy | Sviluppatori, Python | Sì | CSV, JSON, XML, DB | Gratis, open source |
| Diffbot | Enterprise, AI | Sì (crawl AI) | JSON (dati strutturati via API) | Da circa 299 $/mese+ |
| Cheerio | Sviluppatori, Node.js | Sì (codice personalizzato) | Personalizzato (JSON, ecc.) | Gratis, open source |
| Puppeteer | Sviluppatori, siti complessi | Sì (automazione completa) | Personalizzato (output da script) | Gratis, open source |
Come Scegliere lo Scraper di Link Giusto per la Tua Azienda
E allora, come ti decidi? Ecco la mia bussola veloce:
- Zero competenze di programmazione? Parti da Thunderbit, Octoparse, ParseHub, WebHarvy o dall’estensione Web Scraper.
- Ti servono flussi su misura? Apify, ScraperAPI o Cheerio sono pane per gli sviluppatori.
- Punti alla scala enterprise? Bright Data o Diffbot nascono apposta.
- Sviluppi in Python o Node.js? Scrapy (Python) oppure Cheerio/Puppeteer (Node.js) ti danno il controllo pieno.
- Vuoi esportare dritto su Sheets/Notion? Qui Thunderbit è probabilmente la mossa migliore.
Scegli in base alla tua dimestichezza tecnica, al volume di dati e alle integrazioni che ti servono. Quasi tutti offrono una prova gratuita, quindi non aver paura di sperimentare.
Esplora altre guide sul web scraping Get Started Free
Il Valore Unico di Thunderbit per l’Estrazione di Link nel 2026
Torniamo al nocciolo: cos’è che rende Thunderbit davvero diverso?
- Semplicità guidata dall’AI: descrivi in italiano spiccio cosa vuoi — al resto pensa l’AI di Thunderbit.
- Scraping multilivello: estrai link dalle pagine madri, segui le sottopagine e recuperi altri URL — tutto in un solo flusso.
- Import in massa ed elaborazione batch: incolli centinaia di URL, estrai i link in blocco ed esporti subito dati ordinati.
- Aggancio ai tuoi flussi: esporti dritto su Google Sheets, Notion, Airtable oppure scarichi in CSV/Excel.
- Manutenzione zero: l’AI di Thunderbit si adatta ai cambiamenti dei siti, così non resti incollato a rattoppare scraper rotti.
Thunderbit colma quello spazio tra “estrarre dati” e “avere dati che usi sul serio”. È lo strumento che avrei voluto anni fa, quando annegavo nelle attività manuali sui dati.
Inizia gratis con l’estrazione di link di Thunderbit
In Conclusione: Estrai Link in Modo Più Intelligente e Sblocca il Tuo Flusso di Lavoro
I dati del web sono il carburante della crescita aziendale — e il giusto estrattore di link è il motore che ti porta avanti. Che tu stia costruendo liste di lead, tenendo d’occhio i concorrenti o automatizzando le ricerche, qui c’è uno strumento tagliato sulle tue esigenze e sul tuo livello tecnico.
Se vuoi toccare con mano come funziona l’estrazione di link oggi, prova la versione gratuita di Thunderbit. Scommetto che ti stupirai di quanto combini con pochi click. E se Thunderbit non dovesse calzarti a pennello, dai una possibilità anche ad altri strumenti di questa lista: non c’è mai stato momento migliore per togliersi di dosso le attività noiose e concentrarsi su quello che conta.
Buon scraping — e che i tuoi link siano sempre puliti, ordinati e pronti all’uso. Se vuoi andare più a fondo nel web scraping, fai un salto sul Thunderbit Blog per altre guide e dritte.
Prova gratis l’Estrattore di Link Thunderbit Get Started Free
FAQ
1. Perché gli estrattori di link sono essenziali?
Con quasi metà del traffico internet generato dai bot e le aziende che raccolgono dati a tappeto, gli estrattori di link sono diventati indispensabili per trasformare il caos del web in qualcosa di concreto. Ti aiutano ad automatizzare attività come la generazione di lead, l’aggregazione di contenuti, gli audit SEO e il monitoraggio della concorrenza, facendoti risparmiare una montagna di tempo e fatica.
2. Cosa distingue Thunderbit dagli altri estrattori di link?
Thunderbit usa l’AI per togliere ogni complicazione allo scraping: descrivi l’obiettivo in linguaggio naturale e al resto pensa lui. Regge input di URL in massa, scraping multilivello, riconoscimento intelligente dei campi ed esportazione fluida verso piattaforme come Google Sheets e Notion. È perfetto per chi non programma e per chi fa business e vuole risultati potenti senza grattacapi tecnici.
3. Esistono strumenti di estrazione link adatti agli sviluppatori e ai flussi su misura?
Sì. Strumenti come Apify, ScraperAPI, Cheerio, Puppeteer e Scrapy sono pensati proprio per gli sviluppatori. Offrono scripting, integrazione via API e la flessibilità per gestire scraping complessi, job su larga scala e automazioni avanzate.
4. Quali strumenti sono migliori per chi non sa programmare?
Thunderbit, Octoparse, ParseHub, WebHarvy e l’estensione Chrome Web Scraper sono tra le scelte migliori per chi non ha competenze tecniche. Offrono interfacce visive, template già pronti e funzioni con AI che rendono l’estrazione di link alla portata di tutti.
5. Come scelgo l’estrattore di link più adatto a me?
Pesa le tue competenze tecniche, il volume di dati e le esigenze di esportazione. Chi non programma farebbe bene a puntare su strumenti come Thunderbit o Octoparse, mentre gli sviluppatori potrebbero preferire Scrapy o Puppeteer. Le aziende, invece, possono guardare a Bright Data o Diffbot per operazioni su larga scala. Parti sempre da una prova gratuita per capire quale strumento si incastra meglio nel tuo caso.




