

Link rotti. Pagine orfane. Una pagina “test” del 2019 che Google ha indicizzato per chissà quale motivo. Se gestisci un sito, sai benissimo di cosa sto parlando.
Un buon website crawler intercetta tutto questo — e ti mappa l’intero sito, così puoi intervenire davvero dove serve. Però tantissime persone confondono “web crawler” e “web scraper”. Non sono la stessa cosa.
Ho testato 10 crawler gratuiti su siti reali. Alcuni sono fortissimi per gli audit SEO. Altri rendono meglio per l’estrazione dei dati. Qui sotto trovi cosa ha funzionato — e cosa no.
Che cos’è un Website Crawler? Le basi da conoscere
Facciamo subito chiarezza: un website crawler non è la stessa cosa di un web scraper. Lo so, i due termini vengono usati spesso come se fossero sinonimi, ma in realtà sono molto diversi. Immagina il crawler come il cartografo del tuo sito: esplora ogni angolo, segue ogni link e costruisce la mappa di tutte le pagine. Il suo lavoro è la scoperta: trovare URL, ricostruire la struttura del sito e indicizzare i contenuti. È quello che fanno i motori di ricerca come Google con i loro bot, ed è anche ciò che usano gli strumenti SEO per capire lo stato di salute del tuo sito (Thunderbit Blog: What Is a Web Crawler?).
Un web scraper, invece, è lo specialista del dato. Non gli interessa l’intera mappa: vuole solo tirare fuori l’oro, cioè prezzi dei prodotti, nomi aziendali, recensioni, email e molto altro. Gli scraper recuperano campi specifici dalle pagine individuate dai crawler (Thunderbit Blog: How to Web Crawl a Site?).
Facciamo un’analogia:
- Crawler: la persona che gira in ogni corsia di un supermercato e fa l’inventario di tutti i prodotti.
- Scraper: la persona che va dritta allo scaffale del caffè e annota il prezzo di ogni miscela biologica.
Perché conta? Perché se vuoi solo trovare tutte le pagine del tuo sito (per esempio per un audit SEO), ti serve un crawler. Se invece vuoi raccogliere tutti i prezzi dei prodotti dal sito di un concorrente, ti serve uno scraper — oppure, ancora meglio, uno strumento che faccia entrambe le cose.
Perché usare un Web Crawler Online? I vantaggi per il business
Quindi, perché affidarsi a un web crawler? Semplice: il web non diventa certo più piccolo. Anzi, oltre il 54% dei brand enterprise usa piattaforme di crawling dedicate per ottimizzare i propri siti, e alcuni tool SEO arrivano a scansionare 7 miliardi di pagine al giorno.
Ecco cosa può fare un crawler per te:
- Audit SEO: individua link rotti, titoli mancanti, contenuti duplicati, pagine orfane e altro ancora (SEO.ai).
- Controllo link e QA: intercetta errori 404 e loop di redirect prima che lo facciano i tuoi utenti (Screaming Frog).
- Generazione sitemap: crea automaticamente sitemap XML per i motori di ricerca e per la pianificazione (PowerMapper).
- Inventario contenuti: costruisce un elenco completo di tutte le pagine, della loro gerarchia e dei metadati.
- Conformità e accessibilità: verifica ogni pagina in base a WCAG, SEO e requisiti legali (SiteOne Crawler).
- Prestazioni e sicurezza: segnala pagine lente, immagini troppo pesanti o problemi di sicurezza (SiteOne Crawler).
- Dati per AI e analisi: invia i dati raccolti a strumenti di analytics o di intelligenza artificiale (Thunderbit Blog: Crawl4AI Review).
Ecco una tabella rapida che collega i casi d’uso ai ruoli aziendali:
| Caso d'uso | Ideale per | Vantaggio / Risultato |
|---|---|---|
| Audit SEO e del sito | Marketing, SEO, piccoli imprenditori | Individuare problemi tecnici, ottimizzare la struttura, migliorare il posizionamento |
| Inventario contenuti e QA | Content manager, webmaster | Verificare o migrare contenuti, intercettare link/immagini rotti |
| Lead generation (scraping) | Sales, sviluppo business | Automatizzare il prospecting, riempire il CRM con lead aggiornati |
| Competitive intelligence | E-commerce, product manager | Monitorare prezzi concorrenti, nuovi prodotti e variazioni di stock |
| Clonazione di sitemap e struttura | Developer, DevOps, consulenti | Replicare la struttura del sito per redesign o backup |
| Aggregazione contenuti | Ricercatori, media, analisti | Raccogliere dati da più siti per analisi o monitoraggio dei trend |
| Ricerca di mercato | Analisti, team di training AI | Collezionare grandi dataset per analisi o addestramento di modelli AI |
(Thunderbit Blog: How to Web Crawl a Site?)
Come abbiamo scelto i migliori strumenti gratuiti per il Website Crawling
Ho passato parecchie notti a studiare questi tool, leggere documentazione e lanciare crawl di prova. Più caffè di quanti ne voglia ammettere, ma ne è valsa la pena. Ecco cosa ho valutato:
- Capacità tecniche: gestisce siti moderni (JavaScript, login, contenuti dinamici)?
- Facilità d’uso: è adatto anche a chi non è tecnico, oppure serve saper usare il terminale?
- Limiti del piano gratuito: è davvero gratuito o solo una demo molto limitata?
- Accessibilità online: è un tool cloud, un’app desktop o una libreria di codice?
- Funzionalità distintive: offre qualcosa di speciale, come estrazione AI, sitemap visive o crawling guidato da eventi?
Ho testato ogni strumento, confrontato i feedback degli utenti e messo le funzionalità una accanto all’altra. Se un tool mi faceva venire voglia di lanciare il laptop dalla finestra, non entrava nella lista.
Tabella comparativa veloce: i 10 migliori website crawler gratuiti
| Strumento e tipo | Funzioni principali | Caso d'uso ideale | Competenze richieste | Dettagli del piano gratuito |
|---|---|---|---|---|
| BrightData (Cloud/API) | Crawling enterprise, proxy, rendering JS, risoluzione CAPTCHA | Raccolta dati su larga scala | Utile avere competenze tecniche | Prova gratuita: 3 scraper, 100 record ciascuno (circa 300 record totali) |
| Crawlbase (Cloud/API) | Crawling via API, anti-bot, proxy, rendering JS | Sviluppatori che necessitano di infrastruttura backend | Integrazione API | Gratis: circa 5.000 chiamate API per 7 giorni, poi 1.000/mese |
| ScraperAPI (Cloud/API) | Rotazione proxy, rendering JS, crawl asincrono, endpoint predefiniti | Sviluppatori, monitoraggio prezzi, dati SEO | Setup minimo | Gratis: 5.000 chiamate API per 7 giorni, poi 1.000/mese |
| Diffbot Crawlbot (Cloud) | Crawling + estrazione AI, knowledge graph, rendering JS | Dati strutturati su larga scala, AI/ML | Integrazione API | Gratis: 10.000 crediti/mese (circa 10k pagine) |
| Screaming Frog (Desktop) | Audit SEO, analisi link/meta, sitemap, estrazione personalizzata | Audit SEO, webmaster | App desktop, interfaccia GUI | Gratis: 500 URL per crawl, solo funzioni base |
| SiteOne Crawler (Desktop) | SEO, performance, accessibilità, sicurezza, export offline, Markdown | Developer, QA, migrazione, documentazione | Desktop/CLI, GUI | Gratis e open source, 1.000 URL nel report GUI (configurabile) |
| Crawljax (Java, OpenSrc) | Crawling guidato da eventi per siti pesanti in JS, export statico | Developer, QA per web app dinamiche | Java, CLI/config | Gratis e open source, senza limiti |
| Apache Nutch (Java, OpenSrc) | Distribuito, basato su plugin, integrazione Hadoop, ricerca personalizzata | Motori di ricerca personalizzati, crawl su larga scala | Java, riga di comando | Gratis e open source, costa solo l’infrastruttura |
| YaCy (Java, OpenSrc) | Crawling e ricerca peer-to-peer, privacy, indicizzazione web/intranet | Ricerca privata, decentralizzazione | Java, interfaccia browser | Gratis e open source, senza limiti |
| PowerMapper (Desktop/SaaS) | Sitemap visive, accessibilità, QA, compatibilità browser | Agenzie, QA, mappatura visiva | GUI, facile da usare | Prova gratuita: 30 giorni, 100 pagine (desktop) o 10 pagine (online) per scansione |
BrightData: crawler cloud di livello enterprise

BrightData è il “mostro” del web crawling. È una piattaforma cloud con una rete di proxy enorme, rendering JavaScript, risoluzione CAPTCHA e un IDE per crawl personalizzati. Se devi raccogliere dati su larga scala — per esempio monitorare centinaia di siti e-commerce per i prezzi — l’infrastruttura di BrightData è difficile da battere (aimultiple.com).
Punti di forza:
- Gestisce bene i siti con forti misure anti-bot
- Scalabile per esigenze enterprise
- Template già pronti per i siti più comuni
Limiti:
- Nessun piano gratuito permanente, solo una prova: 3 scraper, 100 record ciascuno
- Può essere eccessivo per audit semplici
- Richiede un po’ di apprendimento per chi non è tecnico
Se devi fare crawling su larga scala, BrightData è come noleggiare una Formula 1. Però non aspettarti che resti gratis dopo il test drive (BrightData Pricing).
Crawlbase: crawler web gratuito guidato da API per sviluppatori

Crawlbase (ex ProxyCrawl) punta tutto sul crawling programmabile. Invi un URL alla loro API e ricevi l’HTML, mentre proxy, geotargeting e CAPTCHA vengono gestiti in background (Capterra).
Punti di forza:
- Tassi di successo molto alti (oltre il 99%)
- Gestisce siti pesanti in JavaScript
- Ottimo da integrare nelle proprie app o workflow
Limiti:
- Serve integrare API o SDK
- Piano gratuito: circa 5.000 chiamate API per 7 giorni, poi 1.000/mese
Se sei uno sviluppatore e vuoi fare web crawling — e magari anche web scraping — su larga scala senza occuparti dei proxy, Crawlbase è una scelta solida (Crawlbase Pricing).
ScraperAPI: semplificare il crawling di siti dinamici

ScraperAPI è l’API del “prendilo tu per me”. Tu gli passi un URL, lui gestisce proxy, browser headless e misure anti-bot, e ti restituisce l’HTML (o dati strutturati per alcuni siti). È particolarmente utile per pagine dinamiche e offre un piano gratuito generoso (ScraperAPI Pricing).
Punti di forza:
- Facilissimo per gli sviluppatori: basta una chiamata API
- Gestisce CAPTCHA, ban IP e JavaScript
- Gratis: 5.000 chiamate API per 7 giorni, poi 1.000/mese
Limiti:
- Nessun report visivo del crawl
- Se vuoi seguire i link, devi scrivere tu la logica di crawling
Se vuoi integrare il web crawling nel tuo codice in pochi minuti, ScraperAPI è una scelta quasi automatica.
Diffbot Crawlbot: scoperta automatica della struttura di un sito

Diffbot Crawlbot porta il crawling a un livello più intelligente. Non si limita a esplorare: usa l’AI per classificare le pagine ed estrarre dati strutturati (articoli, prodotti, eventi e così via) in JSON. È come avere un assistente robot che capisce davvero quello che legge (Diffbot Free Plan).
Punti di forza:
- Estrazione guidata dall’AI, non solo crawling
- Gestisce JavaScript e contenuti dinamici
- Gratis: 10.000 crediti/mese (circa 10k pagine)
Limiti:
- Pensato per sviluppatori, con integrazione via API
- Non è uno strumento SEO visuale: è più adatto a progetti dati
Se ti servono dati strutturati su larga scala, soprattutto per AI o analytics, Diffbot è davvero potente.
Screaming Frog: crawler desktop gratuito per SEO

Screaming Frog è il grande classico dei crawler desktop per gli audit SEO. Nella versione gratuita scansiona fino a 500 URL per volta e ti offre praticamente tutto: link rotti, meta tag, contenuti duplicati, sitemap e altro ancora (Screaming Frog User Guide).
Punti di forza:
- Veloce, completo e molto affidabile nel mondo SEO
- Nessun codice richiesto: inserisci l’URL e via
- Gratis fino a 500 URL per crawl
Limiti:
- Solo desktop, niente versione cloud
- Le funzioni avanzate (rendering JS, scheduling) richiedono una licenza a pagamento
Se fai SEO sul serio, Screaming Frog è praticamente indispensabile — solo, non aspettarti che faccia gratis la scansione di un sito da 10.000 pagine.
SiteOne Crawler: export statico e documentazione del sito

SiteOne Crawler è il coltellino svizzero degli audit tecnici. È open source, multipiattaforma e può eseguire crawl, audit e persino esportare il sito in Markdown per documentazione o uso offline (SiteOne Crawler).
Punti di forza:
- Copre SEO, performance, accessibilità e sicurezza
- Esporta i siti per archivio o migrazione
- Gratis e open source, senza limiti di utilizzo
Limiti:
- Più tecnico di altri strumenti con interfaccia grafica
- Il report GUI è limitato a 1.000 URL per impostazione predefinita (ma è configurabile)
Se sei developer, QA o consulente e vuoi andare a fondo, SiteOne è una piccola gemma nascosta.
Crawljax: crawler Java open source per pagine dinamiche
Crawljax è uno specialista: è pensato per esplorare web app moderne e pesanti in JavaScript simulando le interazioni reali dell’utente (click, compilazione di form, ecc.). È guidato da eventi e può persino generare una versione statica di un sito dinamico (Wikipedia: Crawljax).
Punti di forza:
- Perfetto per crawl di SPA e siti ricchi di AJAX
- Open source ed estensibile
- Nessun limite di utilizzo
Limiti:
- Richiede Java e un minimo di programmazione/configurazione
- Non adatto a utenti non tecnici
Se devi esplorare un’app React o Angular come se fossi un vero utente, Crawljax è il tool giusto.
Apache Nutch: crawler distribuito e scalabile

Apache Nutch è il “nonno” dei crawler open source. È progettato per crawl massivi e distribuiti: per esempio, creare il tuo motore di ricerca o indicizzare milioni di pagine (Martechvibe).
Punti di forza:
- Scala fino a miliardi di pagine con Hadoop
- Altamente configurabile ed estensibile
- Gratis e open source
Limiti:
- Curva di apprendimento ripida (Java, riga di comando, configurazioni)
- Non adatto a siti piccoli o utenti occasionali
Se vuoi fare web crawling su larga scala e non hai paura del terminale, Nutch è lo strumento che fa per te.
YaCy: crawler e motore di ricerca peer-to-peer
YaCy è un crawler e motore di ricerca decentralizzato, davvero unico. Ogni istanza scansiona e indicizza siti, e puoi unirti a una rete peer-to-peer per condividere gli indici con altri utenti (TechRadar: YaCy).
Punti di forza:
- Focus sulla privacy, senza server centrale
- Ottimo per creare ricerche private o intranet search
- Gratis e open source
Limiti:
- I risultati dipendono dalla copertura della rete
- Richiede un po’ di setup (Java, interfaccia browser)
Se ti interessa la decentralizzazione o vuoi costruire il tuo motore di ricerca, YaCy è un’opzione davvero interessante.
PowerMapper: generatore di sitemap visive per UX e QA

PowerMapper serve soprattutto a visualizzare la struttura del sito. Esegue il crawl e genera sitemap interattive, oltre a controllare accessibilità, compatibilità browser e le basi della SEO (Slickplan Review).
Punti di forza:
- Le sitemap visive sono perfette per agenzie e designer
- Verifica accessibilità e conformità
- Interfaccia GUI semplice, senza competenze tecniche richieste
Limiti:
- Solo prova gratuita: 30 giorni, 100 pagine per scansione sul desktop / 10 pagine online
- La versione completa è a pagamento
Se devi mostrare una sitemap ai clienti o verificare la conformità, PowerMapper è molto utile.
Come scegliere il crawler giusto per le tue esigenze
Con così tante opzioni, come si fa a scegliere? Ecco la mia guida rapida:
- Per audit SEO: Screaming Frog (siti piccoli), PowerMapper (visuale), SiteOne (audit approfonditi)
- Per web app dinamiche: Crawljax
- Per grandi volumi o ricerca personalizzata: Apache Nutch, YaCy
- Per sviluppatori che vogliono accesso via API: Crawlbase, ScraperAPI, Diffbot
- Per documentazione o archivio: SiteOne Crawler
- Per uso enterprise con prova gratuita: BrightData, Diffbot
Fattori chiave da considerare:
- Scalabilità: quanto è grande il sito o il job di crawl?
- Facilità d’uso: preferisci il codice o un’interfaccia point-and-click?
- Export dei dati: ti servono CSV, JSON o integrazioni con altri strumenti?
- Supporto: c’è una community o documentazione utile se resti bloccato?
Quando il Web Crawling incontra il Web Scraping: perché Thunderbit è una scelta più intelligente
Estrai dati da qualsiasi sito usando l'AI Get Started Free
La realtà è questa: la maggior parte delle persone non usa i crawler solo per creare belle mappe del sito. L’obiettivo reale è quasi sempre ottenere dati strutturati — che siano elenchi di prodotti, contatti o inventari di contenuti. Ed è qui che entra in gioco Thunderbit.
Thunderbit non è solo un crawler o uno scraper: è un’estensione Chrome basata sull’AI che combina entrambe le funzioni. Ecco come funziona:
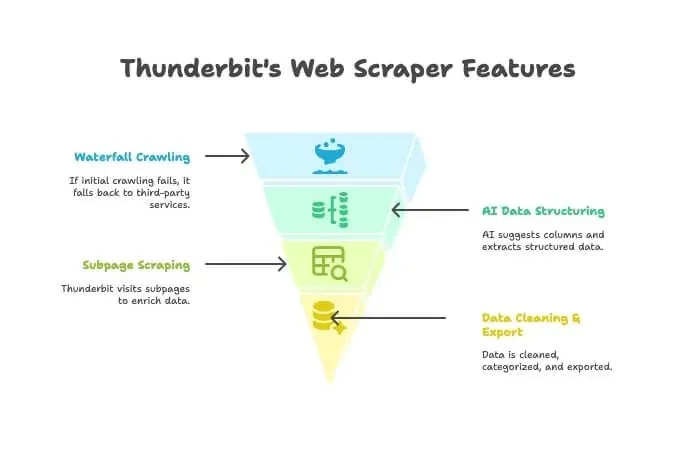
- AI Crawler: Thunderbit esplora il sito proprio come farebbe un crawler.
- Waterfall Crawling: se il motore interno di Thunderbit non riesce ad accedere a una pagina — magari perché c’è un anti-bot particolarmente aggressivo — passa automaticamente a servizi di crawling di terze parti, senza nessuna configurazione manuale.
- Strutturazione dati con AI: una volta ottenuto l’HTML, l’AI di Thunderbit suggerisce le colonne giuste ed estrae i dati strutturati (nomi, prezzi, email e così via) senza che tu debba scrivere selettori.
- Scraping delle sottopagine: ti servono i dettagli di ogni pagina prodotto? Thunderbit può visitare automaticamente tutte le sottopagine e arricchire la tua tabella.
- Pulizia ed export dei dati: può riassumere, categorizzare, tradurre ed esportare i dati in Excel, Google Sheets, Airtable o Notion con un solo clic.
- Semplicità no-code: se sai usare un browser, sai usare Thunderbit. Niente codice, niente proxy, niente stress.
Quando usare Thunderbit al posto di un crawler tradizionale?
- Quando il tuo obiettivo finale è un foglio di calcolo pulito e subito utilizzabile, non solo una lista di URL.
- Quando vuoi automatizzare tutto il processo — crawl, estrazione, pulizia ed export — in un unico posto.
- Quando vuoi risparmiare tempo e fatica mentale.
Puoi scaricare l’estensione Chrome di Thunderbit qui e capire da solo perché così tanti utenti business stanno cambiando approccio.
Prova Thunderbit gratis – AI Web Scraper
Conclusione: ottenere il massimo dai crawler gratuiti
Che cos'è il Data Scraping e come farlo Get Started Free
I website crawler hanno fatto tanta strada. Che tu sia un marketer, uno sviluppatore o semplicemente qualcuno che vuole tenere il proprio sito in ordine, esiste uno strumento gratuito — o almeno provabile gratis — adatto a te. Da piattaforme enterprise come BrightData e Diffbot, a gioielli open source come SiteOne e Crawljax, fino a strumenti di mappatura visiva come PowerMapper, oggi le opzioni sono più varie che mai.
Ma se cerchi un modo più intelligente e integrato per passare da “mi serve questo dato” a “ecco il mio foglio di calcolo”, prova Thunderbit. È pensato per chi lavora nel business e vuole risultati concreti, non solo report.
Pronto a iniziare il crawling? Scarica uno strumento, avvia una scansione e scopri cosa ti stavi perdendo. E se vuoi passare dal crawling ai dati utilizzabili in due clic, dai un’occhiata a Thunderbit.
Per altri approfondimenti e guide pratiche, visita il Thunderbit Blog.
Estrai dati da siti web con l'AI in 2 clic
Prova AI Web Scraper Get Started Free
FAQ
Qual è la differenza tra un website crawler e un web scraper?
Un crawler scopre e mappa tutte le pagine di un sito (in pratica, costruisce un indice o una specie di sommario). Uno scraper estrae campi di dati specifici da quelle pagine, come prezzi, email o recensioni. I crawler trovano, gli scraper scavano (Thunderbit Blog: What Is a Web Crawler?).
Qual è il miglior web crawler gratuito per utenti non tecnici?
Per siti piccoli e audit SEO, Screaming Frog è facile da usare. Per la mappatura visiva, PowerMapper è ottimo durante la prova gratuita. Thunderbit è la soluzione più semplice se il tuo obiettivo è ottenere dati strutturati con un’esperienza no-code e via browser.
Esistono siti che bloccano i web crawler?
Sì, alcuni siti usano file robots.txt o misure anti-bot come CAPTCHA e blocchi IP per impedire il crawling. Strumenti come ScraperAPI, Crawlbase e Thunderbit (con waterfall crawling) spesso riescono ad aggirare questi ostacoli, ma è fondamentale agire in modo responsabile e rispettare le regole del sito (BrightData Pricing).
I crawler gratuiti hanno limiti di pagine o funzionalità?
Sì, nella maggior parte dei casi. Per esempio, la versione gratuita di Screaming Frog è limitata a 500 URL per crawl; la prova di PowerMapper arriva a 100 pagine. Gli strumenti basati su API spesso hanno limiti mensili di crediti. I tool open source come SiteOne o Crawljax, in genere, non hanno limiti rigidi, ma sei comunque vincolato dalle risorse del tuo hardware.
Usare un web crawler è legale e conforme alla privacy?
In generale, il crawling di pagine pubbliche è legale, ma conviene sempre controllare i termini di servizio del sito e il file robots.txt. Non fare mai crawl di dati privati o protetti da password senza autorizzazione e fai attenzione alle normative sulla privacy se estrai dati personali (Crawlbase Guide).




