
Il mese scorso, l’integrazione Stripe di un mio amico ha iniziato a restituire in silenzio errori 503 alle 23:00 di un venerdì. Nessuno se n’è accorto fino a sabato mattina, quando nella casella di supporto c’erano oltre 200 email indignate di clienti che non riuscivano a completare il pagamento.
Una storia del genere non è affatto rara. Un stima il downtime medio in 5.600 dollari al minuto, mentre . Il valore reale dipende dal traffico, dal tasso di conversione, dal valore degli ordini, dall’esposizione agli SLA e dai costi di ripristino — ma il punto è chiaro: le API non monitorate sono un rischio per il business, non solo un fastidio tecnico. E con e , il monitoraggio non è più facoltativo. Con questa guida volevo fare qualcosa che non avevo visto altrove: organizzare gli strumenti in base al tuo caso d’uso, valutare la qualità degli avvisi e non solo la loro presenza, mostrare prezzi reali del 2026 e misurare quanto velocemente puoi davvero iniziare. Non la solita lista piatta di loghi.
Un’altra cosa: se il tuo lavoro con le API coinvolge raccolta di dati web, alimentazione di LLM, costruzione di sistemi RAG, monitoraggio di pagine dei concorrenti o estrazione di prezzi/prodotti dai siti web, la conversazione sugli “strumenti API” non dovrebbe fermarsi al solo monitoraggio dell’uptime. Ti serve anche un modo affidabile per trasformare pagine web disordinate in dati strutturati. È qui che entra in questa guida: non è un monitor di uptime, ma è uno dei modi più rapidi per trasformare siti web in Markdown pulito o in JSON basato su schema tramite API.
Che cos’è il monitoraggio delle API (e perché dovrebbe interessare al tuo team)?
Monitorare le API significa controllare in modo continuo che i tuoi endpoint API siano disponibili, veloci e restituiscano i dati corretti. Non si tratta solo di chiedersi “il server è attivo?” — un buon monitor verifica codici di stato HTTP, payload di risposta, latenza, certificati SSL, flussi multi-step (come login → ricerca → checkout) e persino la correttezza dello schema.
È diverso dal monitoraggio generale di un sito web, che controlla se una pagina si carica, e dall’APM (Application Performance Monitoring), che analizza trace a livello di codice, query del database e componenti interni di runtime. Il monitoraggio delle API sta nel mezzo: testa ciò che utenti, partner e integrazioni sperimentano davvero quando chiamano i tuoi endpoint.
Esiste anche una categoria correlata che vale la pena citare: le web data API. Queste non monitorano lo stato della tua API; aiutano il tuo prodotto o il tuo flusso di lavoro a raccogliere in modo affidabile dati web esterni. Per esempio, può trasformare una pagina web in Markdown pulito, estrarre campi strutturati in JSON ed eseguire job batch su molte URL. Se il tuo progetto “API” dipende da dati aggiornati di fornitori, pagine prodotto, elenchi pubblici, pagine di documentazione o fonti di ricerca, questo tipo di API per l’estrazione dei dati può essere importante dal punto di vista operativo tanto quanto i controlli di uptime.
Perché dovrebbe interessare anche ai non tecnici? Perché e . Quando un gateway di pagamento, un servizio di autenticazione o un’API di spedizione va in errore, non è un problema astratto di infrastruttura — significa ricavi persi, contratti con i partner compromessi, impennate di richieste al supporto e fiducia erosa. Product manager, sales, operations e customer success hanno tutti un interesse diretto.
Metriche chiave da tenere d’occhio:
- Percentuale di uptime: quota di tempo in cui un endpoint è disponibile
- Tempo di risposta / latenza: quanto impiega l’endpoint a rispondere (media, p95, p99)
- Tasso di errore: quota di richieste che restituiscono 5xx, timeout o fallimenti di asserzioni
- Throughput: richieste al secondo/minuto
- Correttezza: se l’API restituisce i dati attesi, non solo un 200 OK
Come abbiamo valutato i migliori strumenti di monitoraggio API per il 2026
La maggior parte degli articoli sui “migliori strumenti di monitoraggio API” si limita ad accumulare nomi di vendor e funzionalità. Io volevo essere più rigoroso nei criteri di selezione — in parte perché ho passato molto tempo a leggere forum di sviluppatori, e in parte perché il team Thunderbit mi ha aiutato a dai siti dei vendor per costruire un confronto reale (più avanti spiego meglio il flusso di lavoro).
Ecco come abbiamo pesato i fattori:
| Criterio | Perché conta |
|---|---|
| Facilità di configurazione / tempo al primo avviso | I team piccoli hanno bisogno di copertura oggi, non dopo un progetto di piattaforma |
| Intelligenza degli avvisi e riduzione del rumore | Se gli avvisi sono rumorosi, i team li ignorano e si perdono gli incidenti reali |
| Generosità del piano gratuito | Side project e startup in fase iniziale spesso partono gratis |
| Trasparenza dei prezzi | Le bollette dell’observability possono lievitare tra host, posti, log, run synthetic e ingest dei dati |
| Ampiezza delle integrazioni | Gli avvisi devono arrivare dove il team lavora già (Slack, PagerDuty, ecc.) |
| Scalabilità e profondità dei dati | I team maturi hanno bisogno di trace, log, APM, RBAC, SSO, retention |
| Qualità della community e del supporto | I team open source hanno bisogno di cadenza di rilascio; i team enterprise hanno bisogno di SLA |
| Capacità di estrazione dei dati web | Le app AI, i flussi RAG e gli strumenti di ricerca di mercato spesso hanno bisogno di dati esterni puliti, non solo dell’uptime degli endpoint |
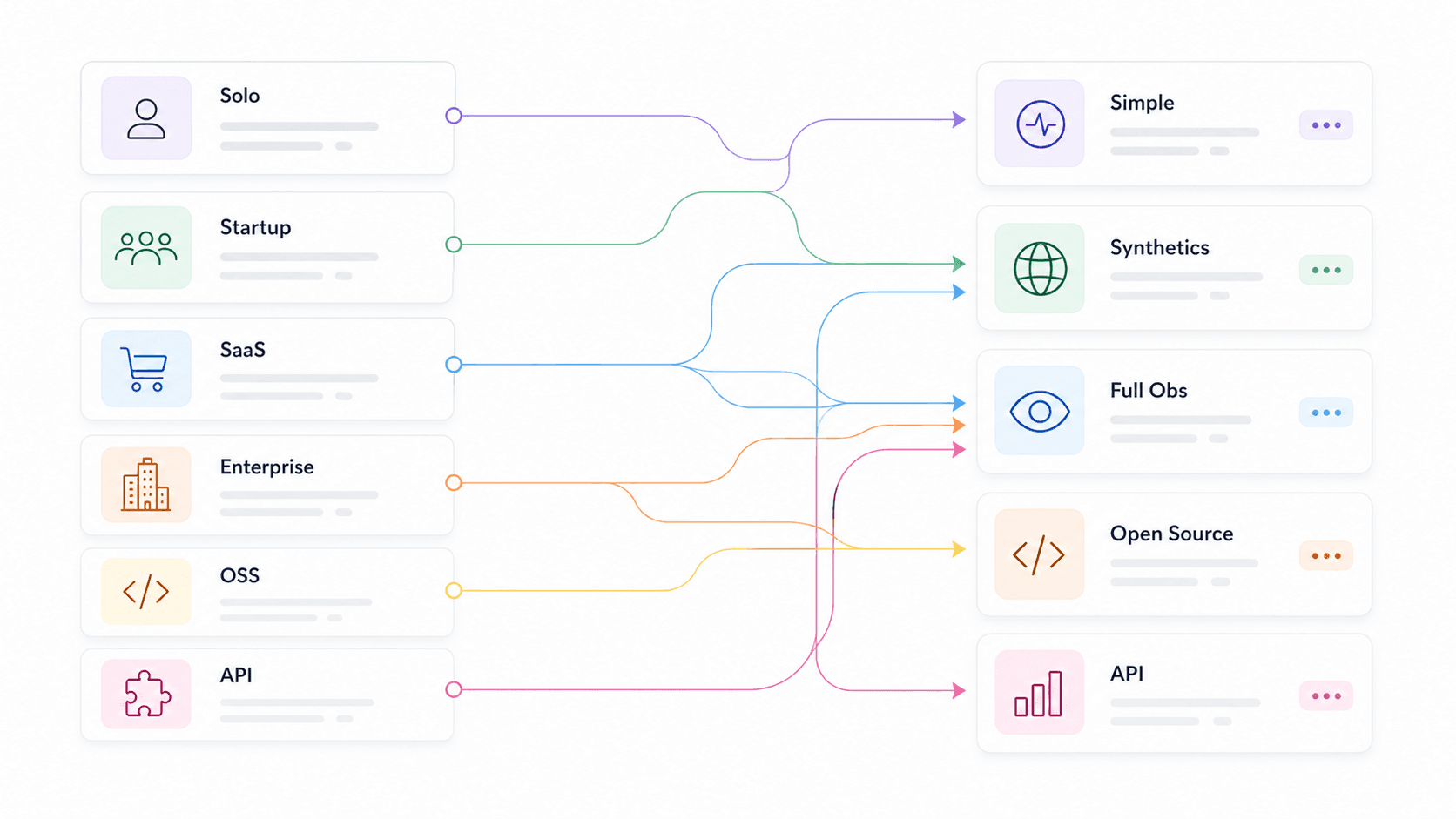
Abbiamo anche segmentato i consigli per caso d’uso — sviluppatore singolo, startup, e-commerce/SaaS, enterprise, purista open source, team prodotto API e team web data/AI — così puoi andare direttamente al tuo contesto invece di leggere 14 riepiloghi sperando di indovinare quello giusto. Il ha rilevato che e come criteri di selezione, il che conferma che non si tratta di semplici optional.
I migliori strumenti di monitoraggio API per caso d’uso: la tabella rapida
Questa è la scorciatoia. Trova la tua riga, poi passa alle sezioni dedicate agli strumenti per il dettaglio completo.
| Caso d’uso | Strumenti consigliati | Differenziatore chiave |
|---|---|---|
| Team web data / app AI | Thunderbit Open API, Moesif, Apitally | Trasforma siti web in Markdown pulito o JSON strutturato per LLM, RAG, prezzi e flussi di ricerca |
| Sviluppatore singolo / side project | UptimeRobot, Uptime Kuma, Gatus | Gratis o self-hosted, configurazione minima, avvio rapido |
| Startup (team di 5–15 persone) | Checkly, Better Stack, Postman | Avvisi intelligenti, setup veloce, costi accessibili, status page |
| E-commerce / SaaS | Datadog, New Relic, Moesif, Checkly | Metriche di business, APM/tracing, profondità SDK, synthetic multi-step |
| Enterprise / multi-cloud | Datadog, New Relic, Splunk, Grafana Cloud | Distributed tracing, compliance, hybrid, RBAC/SSO |
| Puristi open source | Prometheus + Grafana, Uptime Kuma, Gatus, Uptrace | Controllo totale, nativo OTel, nessun lock-in con vendor |
| Team prodotto API | Moesif, Apitally, New Relic | Utilizzo per cliente, trend degli endpoint, avvisi di anomalia |
Il pattern più evidente: gli strumenti più rapidi da configurare tendono ad avere meno analisi, mentre le piattaforme più profonde richiedono più configurazione e disciplina sui costi. Non è un difetto — è un compromesso da conoscere. Thunderbit si colloca in una corsia leggermente diversa: è al massimo della velocità quando il lavoro consiste nel trasformare pagine web in dati pronti per l’API, non nel svegliare gli ingegneri per un downtime.
Thunderbit Open API: il migliore per trasformare siti web in dati API strutturati
è l’API che metterei al primo posto per i team il cui flusso di lavoro di “monitoraggio” o ricerca dipende da dati web esterni. Non è uno strumento tradizionale di monitoraggio dell’uptime come Checkly o UptimeRobot. Invece, Thunderbit trasforma qualsiasi pagina web in dati puliti e strutturati che app, agenti, dashboard e pipeline LLM possono usare davvero.
L’API ha tre flussi di lavoro principali. Distill converte una pagina in Markdown pulito, pronto per gli LLM. Extract prende uno schema e restituisce campi JSON strutturati come nome prodotto, prezzo, disponibilità, dimensione dell’azienda, fase di raccolta fondi o punteggio delle recensioni. Batch permette di elaborare fino a 100 URL in modo asincrono con webhook, utile quando stai monitorando pagine prezzi, cataloghi dei concorrenti, documentazione dei fornitori, fonti di notizie o grandi liste di ricerca.
Il motivo per cui compare in una guida sugli strumenti API è che i team spesso sottovalutano quanta infrastruttura richieda il semplice “estrai questa pagina”. I siti ricchi di JavaScript richiedono rendering. Alcune pagine hanno bisogno di routing geografico. L’HTML deve essere ripulito da menu, annunci, modal e testo di contorno prima di diventare utile a un LLM. I selettori si rompono quando cambia il layout. Rotazione dei proxy, gestione anti-bot, retry, code e polling dei risultati possono trasformare un piccolo flusso dati in un progetto di manutenzione. Thunderbit assorbe gran parte di questo lavoro dietro una sola API.
Ideale per: builder di app AI, team RAG, operations e-commerce, sales operations, growth team, ricercatori di mercato e sviluppatori che hanno bisogno di dati web via API senza costruire e gestire uno stack di scraping.
Prezzi: , incluse fino a 600 pagine Distill o 30 pagine Extract, con 2 richieste concorrenti. Starter è indicato a 16 $/mese con fatturazione annuale per 60.000 unità API/anno e 30 richieste concorrenti. Pro è indicato a 40 $/mese con fatturazione annuale per 600.000 unità API/anno e 50 richieste concorrenti.
Velocità di setup: circa 5–15 minuti per ottenere una API key ed eseguire la prima richiesta Distill o Extract con cURL, SDK o .
Svantaggi: Thunderbit non sostituisce Datadog, New Relic, Better Stack o Checkly per i controlli di uptime, l’escalation degli incidenti, i trace, i log o il routing on-call. Consideralo come l’API che usi per raccogliere e strutturare dati web — inclusi prezzi dei fornitori, documentazione, pagine concorrenti, listing di prodotti o dataset pubblici — non il sistema che allerta il tuo ingegnere reperibile.
Datadog: il migliore per la visibilità full-stack
Datadog è lo strumento che continuo a vedere negli stack enterprise e SaaS mid-market, e per una buona ragione. Non è solo monitoraggio API — è una piattaforma di osservabilità completa che collega test synthetic delle API, trace distribuiti, log, metriche dell’infrastruttura e monitoraggio degli utenti reali in un’unica vista.
Per il monitoraggio API in particolare, Datadog supporta HTTP, SSL, DNS, WebSocket, TCP, UDP, ICMP, gRPC e . I suoi imparano i pattern attesi e avvisano sulle deviazioni invece che su soglie statiche — un passo avanti significativo rispetto al classico “avvisa quando la latenza supera i 500 ms”. Offre anche che prevedono quando una metrica supererà una soglia, oltre a monitor compositi che combinano più condizioni.
Ideale per: team e-commerce, SaaS ed enterprise che vogliono un’unica vista per API, infrastruttura, log e trace.
Prezzi: i dettagli del piano gratuito variano a seconda del prodotto. ; i test API synthetic costano 5 $ ogni 10.000 run. Oltre 800 integrazioni.
Velocità di setup: circa 15–30 minuti per installare l’agent e creare un test synthetic base.
Svantaggi: può diventare costoso su larga scala — il “bill shock” è un tema ricorrente su Hacker News e Reddit. L’enorme numero di SKU (host, log, metriche personalizzate, synthetic, utenti) significa che serve qualcuno che tenga d’occhio il conto, non solo le dashboard. La curva di apprendimento della piattaforma completa è reale.
Checkly: il migliore per i controlli synthetic pensati per gli sviluppatori
Checkly è lo strumento che darei a un team di engineering di una startup che vuole i controlli API vicino al codice. La sua idea centrale è “monitoring as code”: definisci in modo programmatico controlli API e browser, li esegui da località globali, li integri nelle pipeline CI/CD e gestisci tutto tramite Git.
L’angolo della qualità degli avvisi è molto forte. La di Checkly è presentata esplicitamente come la “prima linea di difesa” contro i falsi positivi — puoi configurare retry fissi, lineari o esponenziali, retry dallo stesso luogo o da luoghi diversi e durata massima dei retry prima che scatti un avviso. Inoltre distingue tra stati degradato, fallito e recuperato, riducendo così gli alert rumorosi.
Ideale per: startup e team di sviluppo che vogliono controlli API programmabili, , integrazione CI/CD e setup rapido.
Prezzi: dati pubblici recenti mostrano un piano gratuito con 10 monitor uptime, 1.000 browser check e 10.000 API check. Starter intorno a 24 $/mese con fatturazione annuale — prima dell’acquisto.
Velocità di setup: circa 10–20 minuti per il primo controllo API e il primo canale di avviso.
Svantaggi: è focalizzato sui controlli synthetic. Non sostituisce un APM profondo, l’analisi dei log o il distributed tracing. Se devi correlare un guasto API con un collo di bottiglia del database, ti servirà un altro strumento in parallelo.
UptimeRobot: il migliore per un tracking uptime semplice ed economico
UptimeRobot è l’Honda Civic del monitoraggio API. Fa bene una sola cosa: crei un monitor HTTP, keyword, ping, porta, SSL o heartbeat, scegli un intervallo e ricevi un avviso quando fallisce. Fine.
Ideale per: sviluppatori singoli, piccoli team, agenzie o chiunque abbia bisogno di un tracking base di uptime e latenza senza complessità.
Prezzi: . Piano Solo a circa 7 $/mese con fatturazione annuale. Nessuna carta di credito richiesta per il piano gratuito. Velocità di setup: circa 2–5 minuti — il più veloce in questa lista.
Svantaggi: intelligenza degli avvisi limitata. Avvisi a soglia basilari, niente anomaly detection, niente distributed tracing, niente analisi avanzata. Se devi capire perché un endpoint è lento (e non solo che è lento), UptimeRobot non basta.
Uptime Kuma: il miglior strumento gratuito e self-hosted per il monitoraggio API
Uptime Kuma è il beniamino della community self-hosting, e i numeri GitHub lo confermano: , e alla release 2.3.2 a maggio 2026. È sotto licenza MIT, supporta HTTP(s), keyword, query JSON, WebSocket, TCP, ping, DNS, push, Docker, più status page e oltre 90 servizi di notifica.
Ideale per: sviluppatori singoli e team che vogliono controllo totale, privacy e nessun costo SaaS ricorrente — se hanno un server.
Prezzi: gratis. Il costo reale è la VM/container, i backup, gli aggiornamenti e la garanzia che il monitor stesso resti attivo. Velocità di setup: circa 5–15 minuti con Docker per un controllo base; 15–30 minuti per rifinire notifiche e status page.
Svantaggi: la manutenzione è a tuo carico. E c’è una trappola importante: se ospiti Uptime Kuma sulla stessa infrastruttura che sta monitorando, un guasto cloud o DNS manda giù sia l’app sia il monitor. Ospitalo all’esterno oppure affiancalo a un controllo SaaS.
Better Stack: il migliore per una risposta rapida agli incidenti
Better Stack (spesso ancora chiamato Better Uptime dagli utenti) unisce monitoraggio uptime, gestione incidenti, turni on-call, policy di escalation e status page in un’unica piattaforma. Il suo punto di forza non è tanto l’analisi, quanto il flusso di lavoro sugli incidenti attorno al monitoraggio.
Le definiscono chi riceve l’avviso, in che ordine e con quali ritardi, fino alla conferma. Il routing basato sui metadati invia gli incidenti in base alla gravità o alla titolarità. Si integra con Slack, Teams, webhook e Zapier.
Ideale per: startup e team di medie dimensioni che vogliono monitoraggio + risposta agli incidenti + status page senza dover assemblare tre strumenti separati.
Prezzi: . Team intorno a 29 $/mese con fatturazione annuale. Velocità di setup: circa 5–10 minuti tramite wizard GUI.
Svantaggi: meno profondità nell’analisi dei payload API, nel distributed tracing o nell’analisi dei KPI di business rispetto a Datadog, New Relic o Moesif.
Prometheus + Grafana: il miglior stack open source per il monitoraggio API
Questa è la combinazione open source standard del settore. raccoglie e archivia metriche time-series. (73.705 stelle GitHub, 3.010 contributori) fornisce dashboard e alerting. gestisce routing, grouping, deduplica, silenziamento e inibizione. Per i controlli sugli endpoint API, i team aggiungono per il probing di HTTP, HTTPS, DNS, TCP, ICMP e gRPC.
Ideale per: puristi open source, team Kubernetes/SRE e organizzazioni già standardizzate su metriche Prometheus.
Prezzi: gratuito se self-hosted. ha un piano gratuito (100k esecuzioni di test API/mese) e piani a pagamento basati sull’utilizzo.
Velocità di setup: 1–4 ore per una configurazione base di Blackbox + Prometheus + Grafana + Alertmanager. Giorni per alta disponibilità in produzione e tuning degli alert.
Svantaggi: PromQL, YAML, relabeling, design delle dashboard, retention, storage, HA e tuning degli alert richiedono vero lavoro operativo. Il compromesso ricorrente è “meno UI, più YAML”. Questo è lo stack per i team che pensano già in termini di metriche e vogliono un piano di controllo unico — non per i team che vogliono il monitoraggio pronto per l’ora di pranzo.
New Relic: il migliore per le prestazioni delle applicazioni SaaS
New Relic combina APM, monitoraggio dell’infrastruttura, log, distributed tracing, monitoraggio synthetic, alert, dashboard e analisi degli incidenti assistita dall’IA. Il suo piano gratuito — — è davvero generoso per i team piccoli.
L’intelligenza degli alert è il punto in cui New Relic brilla nella discussione sulla fatigue da notifiche. Le sue funzionalità di includono correlazione degli eventi, anomaly detection, alert predittivi, root cause analysis e soppressione del flapping. New Relic ha pubblicato un esempio in cui — un dato concreto di riduzione del rumore.
Ideale per: team SaaS e piattaforme e-commerce che vogliono un monitoraggio API strettamente integrato con trace applicativi, errori, throughput e impatto sugli utenti.
Prezzi: gratis: 100 GB/mese, 1 utente full. Il piano a pagamento usa prezzi per utente e basati sui dati.
Velocità di setup: circa 15–30 minuti per l’installazione dell’agent e la configurazione guidata.
Svantaggi: i prezzi possono diventare complessi su larga scala. La configurazione degli alert ha una curva di apprendimento — la piattaforma è potente, ma non immediata.
Moesif: il migliore per analytics API e metriche di business
Moesif non è un monitor di uptime tradizionale. È analytics API e product intelligence: aiuta a capire l’utilizzo delle API per cliente, endpoint, cohort, azienda, area geografica, SDK, piano e comportamento. Se la tua domanda è “quale cliente è impattato?” invece di “l’endpoint è attivo?”, Moesif è pensato proprio per questo.
Supporta per metriche API come picchi/cali di traffico, latenza e variazioni di comportamento. Gli avvisi dinamici hanno bisogno di alcuni giorni di comportamento API per costruire un modello, ma una volta addestrati intercettano cambiamenti che le regole statiche non vedono.
Ideale per: team prodotto API, aziende SaaS e piattaforme e-commerce che devono collegare le prestazioni API a ricavi, engagement e retention.
Prezzi: ; i piani a pagamento scalano in base al volume di eventi API. I prezzi self-service non erano completamente estraibili dalla mia ricerca — verifica la pagina attuale.
Velocità di setup: circa 20–45 minuti (l’integrazione SDK/proxy/gateway è più profonda di un ping esterno).
Svantaggi: più orientato all’analytics che al monitoraggio uptime tradizionale. Probabilmente vorrai affiancare Moesif a Checkly, UptimeRobot o Datadog synthetics per i controlli di disponibilità esterna.
Splunk: il migliore per analisi dei log enterprise e compliance
Splunk è lo strumento a cui si ricorre quando aggregazione dei log, ricerca, correlazione, auditabilità pronta per la compliance e supporto ibrido/multi-cloud sono requisiti non negoziabili. copre infrastruttura, APM, synthetic, real user monitoring, log e risposta agli incidenti. può raggruppare eventi rilevanti in episodi e ridurre il rumore tra i silos di monitoraggio.
La di Splunk è sobria ma preoccupante: , e .
Ideale per: team enterprise e multi-cloud con requisiti rigorosi di compliance, sicurezza, audit e ricerca nei log.
Prezzi: basati sull’uso e molto orientati al preventivo. Nessun piano gratuito semplice per la produzione.
Velocità di setup: l’onboarding cloud può essere più rapido, ma nelle implementazioni enterprise spesso servono da giorni a settimane.
Svantaggi: costoso su larga scala. Configurazione complessa. Eccessivo per sviluppatori singoli e piccole startup.
Postman: il migliore per i team che già testano le API
Postman è principalmente una piattaforma di sviluppo e testing API, ma il suo permette ai team di schedulare collection Postman ed eseguirle da location cloud. Il suo punto di forza è il riuso: se il tuo team QA o dev ha già collection Postman con asserzioni, trasformarle in monitor è un passo naturale.
Ideale per: team di sviluppo e QA che già usano collection Postman e vogliono controlli schedulati senza acquistare uno strumento synthetic separato.
Prezzi: esiste un piano gratuito. ; blocco aggiuntivo da 50.000 chiamate a 20 $/mese. Verifica la — il packaging dei piani Postman cambia spesso.
Velocità di setup: circa 10 minuti se le collection esistono già.
Svantaggi: le capacità di monitoraggio sono più leggere rispetto a strumenti dedicati come Checkly, Datadog o New Relic. Le opzioni di alert sono basilari.
Altri strumenti di monitoraggio API che meritano attenzione
: dashboard di salute leggera, self-hosted e guidata dalla configurazione. , supporta HTTP, ICMP, TCP, DNS, metriche compatibili con Prometheus e badge di uptime. Ottimo per sviluppatori singoli che vogliono qualcosa di più semplice di Prometheus ma preferiscono YAML/config-as-code rispetto alla UI di Uptime Kuma.
: strumento più recente focalizzato su analytics del traffico API e tracking della qualità per startup. Dichiara con avvisi personalizzati su 14 metriche. Buono per analytics API leggere senza adottare una piattaforma di osservabilità completa.
: monitoraggio full-stack con log, synthetic e visibilità sull’infrastruttura. . Un’alternativa a Datadog a costo inferiore per i team mid-market.
: backend APM, tracing, metriche e log nativo OpenTelemetry. . Non è un puro controllo di uptime, ma è ideale per i team che standardizzano su OTel e vogliono un backend di tracing compatibile con l’open source.
Build vs. Buy: conviene costruire da soli il monitoraggio API?
“Mi conviene scrivere uno script che pinga i miei endpoint, oppure usare uno strumento dedicato?”
Questa domanda ricorre di continuo nei forum di sviluppatori. Ho letto abbastanza thread su Reddit per vedere chiaramente il pattern: i team partono con curl + cron, funziona bene per un po’, poi passano a una soluzione dedicata quando servono dashboard, dati storici, controlli multi-regione, routing affidabile degli alert o visibilità tra team.
Una matrice decisionale onesta:
| Fattore | Script personalizzato | Strumento specializzato |
|---|---|---|
| Tempo di setup | 1–4 ore (base); giorni (robusto) | 5–30 minuti |
| Manutenzione | È tuo per sempre | Il provider gestisce gli aggiornamenti |
| Qualità degli alert | Base (up/down) | Intelligente (trend di latenza, anomalie, retry) |
| Costo | Gratis (il tuo tempo) | 0–500+ $/mese |
| Dashboard | Da costruire da zero | Preconfezionata, personalizzabile |
| Conviene quando… | ≤3 endpoint, team molto tecnico, progetto hobby | 5+ endpoint, team ops/prodotto, ricavi in gioco |
Il punto chiave che emerge dai forum: chi costruisce da sé spesso se ne pente quando ha bisogno di dashboard, dati storici o visibilità cross-team. E poi c’è il problema meta — “serve monitorare anche il monitoraggio”. Anche un monitor self-hosted, un database, i backup, il percorso di rete e il provider di alert devono essere affidabili.
Costruisci se hai 2 endpoint e ti piace smanettare. Acquista se hai un prodotto da lanciare.
La stessa logica vale per l’estrazione di dati web. Puoi scrivere uno scraper, avviare browser headless, ruotare proxy, mantenere selettori, pulire HTML e costruire una coda. Ma se il compito è alimentare in modo affidabile un prodotto API, un agent AI o un flusso di ricerca con dati web, usare è in genere più veloce che costruire da zero l’infrastruttura di scraping.
Alert fatigue: perché la qualità degli avvisi batte la quantità
Questo potrebbe essere il criterio più sottovalutato nella scelta di uno strumento di monitoraggio API. L’alert fatigue è ciò che succede quando i team ricevono così tanti avvisi rumorosi, duplicati o non azionabili da iniziare a ignorarli tutti — per poi perdersi gli incidenti reali.
I numeri sono impressionanti. Il ha rilevato che l’organizzazione mediana generava e . L’azione reale sugli incidenti era solo — quindi meno di un incidente su cinque derivato da alert era davvero azionabile. Il ha rilevato che e .
Il miglior strumento di monitoraggio è quello di cui ti fidi davvero. Ecco un confronto su come gli strumenti gestiscono l’intelligenza degli avvisi:
| Strumento | Tipo di alert | Metodo di riduzione del rumore | Canali di alert |
|---|---|---|---|
| Datadog | Anomaly ML, forecast, composite | Fasce storiche di anomalia, baseline dinamiche, Watchdog AI | Slack, PagerDuty, Opsgenie, Teams, 20+ |
| Checkly | Threshold + degradazione | Retry prima del firing, retry dallo stesso/diverso luogo | Slack, PagerDuty, Opsgenie, Teams, incident.io |
| New Relic | Raggruppamento AI dei problemi, anomaly, predittivi | Correlazione degli eventi, soppressione del flapping, contesto root cause | Slack, PagerDuty, Teams, webhook |
| Moesif | Anomalia comportamentale | Modelli dinamici dopo alcuni giorni di comportamento | Slack, PagerDuty, email, SMS |
| Better Stack | Uptime/incident/on-call | Policy di escalation, routing per titolarità, ritardi | Slack, Teams, webhook, Zapier |
| Prometheus + Alertmanager | Alert da regole PromQL | Raggruppamento, deduplica, silenziamento, inibizione | Email, PagerDuty, Opsgenie, webhook |
| Splunk | Eventi, episodi, salute del servizio | ITSI Event Analytics, raggruppamento per episodio, ticketing | Splunk On-Call, ServiceNow, webhook |
| Thunderbit Open API | Non è una piattaforma di alerting | Da usare con il tuo scheduler, workflow tool o stack di monitoraggio | Webhook per job batch; gli alert sono gestiti esternamente |
Consiglio pratico: parti con meno alert ma più affidabili. Usa retry prima del firing, conferma multi-regione, alert sul burn rate degli SLO, deduplica e routing per titolarità. Allerta sull’impatto utente e sui flussi critici per il business (checkout fallito, autenticazione fallita, 5xx nei pagamenti), non su ogni sintomo interno.
Piani gratuiti e prezzi 2026: quanto paghi davvero
Le pagine prezzi cambiano. I piani gratuiti si spostano. I costi nascosti (host, posti, log, run synthetic, ingest dei dati) possono sorprenderti. Questa è la sezione che avrei voluto vedere in ogni articolo sui “migliori strumenti”. Snapshot 2026:
| Strumento | Piano gratuito | Prezzo iniziale del piano a pagamento | Carta di credito richiesta? | Miglior caso d’uso gratuito |
|---|---|---|---|---|
| Thunderbit Open API | 600 unità API una tantum | ~16 $/mese con fatturazione annuale | No | Estrazione di dati web per LLM, RAG, prezzi e ricerca |
| Uptime Kuma | Illimitato (self-host) | — | No | Monitoraggio completo, server proprio |
| UptimeRobot | 50 monitor, intervalli di 5 minuti | ~7 $/mese | No | Controlli base di uptime |
| Better Stack | 10 monitor, 1 status page | ~29 $/mese | No | Uptime da startup + status page |
| Checkly | 10 uptime, 10k API check | ~24 $/mese | Sì | Controlli API synthetic |
| Postman | Account gratuito + quota di monitoraggio | ~14 $/utente/mese | No | Riutilizzo delle collection esistenti |
| Prometheus + Grafana | Illimitato (self-host) | — | No | Metriche + visualizzazione |
| Grafana Cloud | 100k esecuzioni test API/mese | 29 $/mese piattaforma + utilizzo | Verificare | Prova di synthetics gestita |
| New Relic | 100 GB/mese, 1 utente full | Prezzo per utente + dati | Alcuni piani | APM + observability di base |
| Datadog | Prova/varia per prodotto | 15 $/host/mese (Infra Pro) | Spesso sì | Valutazione full-stack |
| Moesif | Gratis/prova disponibile | Basato sul volume | Verificare | Valutazione analytics API |
| Splunk | Prove disponibili | Su preventivo | Flusso commerciale | Proof of concept enterprise |
| Gatus | Illimitato (self-host) | — | No | Dashboard di stato guidata da YAML |
| Apitally | Gratis/prova disponibile | Verificare | Verificare | Analytics API leggere |
| Sematext | Prova/gratuito variabile | ~2 $/monitor HTTP | Verificare | Synthetics/log a costo inferiore |
| Uptrace | Gratis self-hosted | I piani cloud variano | Verificare | Valutazione APM OTel |
Nota sui costi nascosti: gli strumenti self-hosted (Uptime Kuma, Prometheus, Gatus) sono “gratuiti” dal punto di vista della licenza, ma una piccola VM, i backup, il tempo di manutenzione e il failover esterno possono facilmente diventare il costo reale. Per le API di dati web, il costo nascosto è spesso diverso: mantenere browser headless, selettori che si rompono, pool di proxy, workaround anti-bot e pulizia dell’HTML.
Stima per team piccoli: per 10 endpoint API e 3 membri del team, il percorso SaaS più economico è di solito UptimeRobot gratis o a basso costo, Better Stack free/Team, oppure Checkly se il volume di esecuzioni rientra. Datadog e New Relic possono essere accessibili per la valutazione, ma la fattura reale dipende da host, utenti, log, trace e volume di run synthetic. Se il tuo progetto ha bisogno di dati web come API, le unità API gratuite di Thunderbit bastano per testare il flusso prima di passare a un piano a pagamento.
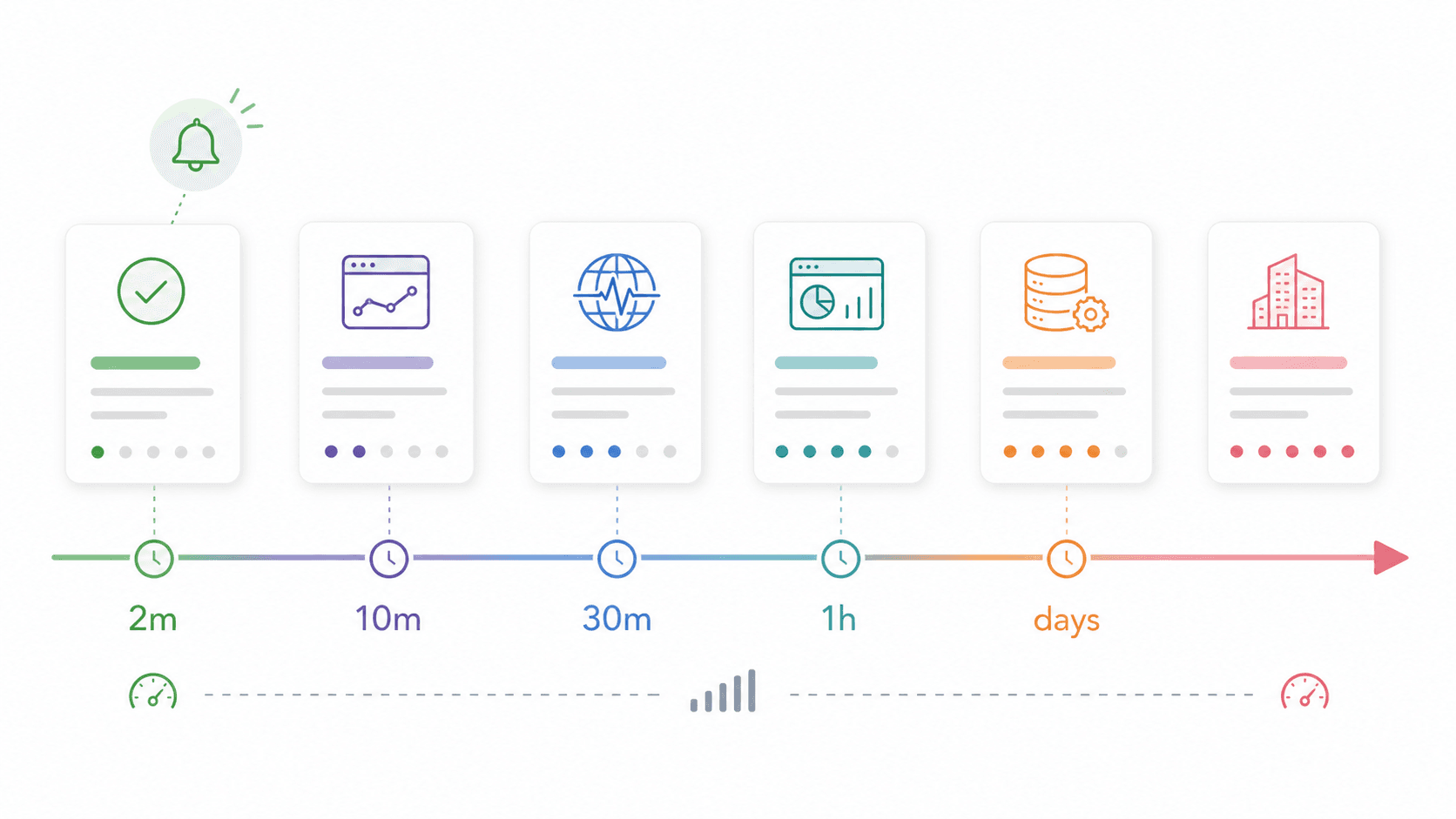
Scorecard della complessità di setup: quanto tempo per il primo avviso
Nessun articolo concorrente che ho trovato valuta il time-to-value — quanto tempo passa dalla registrazione al ricevere il primo avviso davvero significativo. Per i team piccoli, questo conta più della profondità funzionale.
| Strumento | Tempo al primo avviso | Competenze tecniche richieste | Approccio alla configurazione |
|---|---|---|---|
| Thunderbit Open API | ~5–15 minuti | Basso–Medio | API key, cURL/SDK/CLI |
| UptimeRobot | ~2–5 minuti | Basso | GUI, click per aggiungere |
| Better Stack | ~5–10 minuti | Basso | Wizard GUI |
| Checkly | ~10–20 minuti | Basso–Medio | Codice o GUI |
| Postman | ~10 minuti (con collection) | Basso–Medio | Scheduler di collection |
| Uptime Kuma | ~5–30 minuti | Medio | Docker + GUI |
| Gatus | ~15–45 minuti | Medio | YAML + Docker |
| Datadog | ~15–30 minuti | Medio | Installazione agent + GUI |
| New Relic | ~15–30 minuti | Medio | Agent + setup guidato |
| Moesif | ~20–45 minuti | Medio | Integrazione SDK/proxy |
| Grafana Cloud Synthetics | ~15–45 minuti | Medio | GUI, Terraform opzionale |
| Prometheus + Grafana | 1–4 ore | Medio–Alto | YAML, PromQL |
| Uptrace | 30–90 minuti | Medio–Alto | Integrazione SDK OTel |
| Splunk | Da ore a settimane | Alto | Onboarding enterprise |
Se il monitoraggio deve essere attivo entro fine giornata, parti dalla metà superiore della tabella. Se l’obiettivo è una observability di piattaforma duratura, pianifica un progetto separato per la metà inferiore. E se il tuo primo traguardo è “ottenere dati puliti da queste 100 pagine web in un’app”, inizia con Thunderbit prima di costruire un’infrastruttura di scraping personalizzata.
Confronto tra i migliori strumenti di monitoraggio API: la panoramica completa
Una tabella da scorrere prima di decidere:
| Strumento | Caso d’uso migliore | Piano gratuito | Intelligenza degli alert | Tempo di setup | Hosting | Funzionalità distintiva |
|---|---|---|---|---|---|---|
| Thunderbit Open API | Estrazione di dati web/pipeline API data | 600 unità API | Non è uno strumento di alerting | 5–15 min | Cloud | Trasforma pagine in Markdown o estrae JSON basato su schema |
| Datadog | Full-stack enterprise/SaaS | Prova/varia | Anomaly, forecast, AI | 15–30 min | Cloud | Correlazione tra synthetics, log, trace e infrastruttura |
| Checkly | Synthetic per sviluppatori | Generoso, basato sui check | Retry, degradazione | 10–20 min | Cloud | Monitoring as code + Playwright |
| UptimeRobot | Uptime semplice | 50 monitor | Soglie di base | 2–5 min | Cloud | Il monitor base low-cost più veloce |
| Uptime Kuma | Self-host gratuito | Illimitato | Stato/soglia base | 5–30 min | Self-hosted | UI pulita, nessun canone SaaS |
| Better Stack | Risposta agli incidenti/status page | 10 monitor | Escalation, routing | 5–10 min | Cloud | Monitoraggio + on-call + status page |
| Prometheus + Grafana | Stack metriche open source | Illimitato (self-host) | Raggruppamento Alertmanager | 1–4 ore | Self-hosted/cloud | Profondità dell’ecosistema PromQL |
| New Relic | APM SaaS + controlli API | 100 GB/mese, 1 utente | Raggruppamento AI, soppressione flapping | 15–30 min | Cloud | Forte APM + synthetics insieme |
| Moesif | Analytics API/metriche di business | Gratis/prova | Anomalie comportamentali | 20–45 min | Cloud | Analytics del comportamento API per cliente |
| Splunk | Log enterprise/compliance | Prova | Episodi ITSI, AIOps | Giorni+ | Cloud/self-managed | Ricerca log e governance enterprise |
| Postman | Team che già testano API | Account gratuito | Avvisi base di monitoraggio | 10 min | Cloud | Riutilizzo delle collection di test API |
Come Thunderbit può velocizzare la valutazione dei tuoi strumenti API
Dichiarazione di trasparenza: non è uno strumento di monitoraggio API — è uno scraper web AI e una per trasformare pagine web in Markdown pulito o JSON strutturato. Questo lo rende utile in una parte diversa del processo decisionale sugli strumenti di monitoraggio: raccogliere prezzi dei vendor, limiti dei piani, dichiarazioni sulle funzionalità, dettagli della documentazione ed elenchi di integrazioni prima di scegliere una piattaforma.
Invece di aprire manualmente più di 10 pagine prezzi dei vendor, copiare nomi dei piani, limiti di monitoraggio, intervalli di controllo, integrazioni e requisiti di carta di credito in un foglio di calcolo, abbiamo usato la per estrarre dati strutturati dalle pagine prezzi e funzionalità di ciascun strumento. L’IA di Thunderbit legge ogni pagina e suggerisce i campi — nome del piano, dettagli del piano gratuito, prezzo del piano a pagamento, integrazioni supportate — poi struttura l’output in un foglio esportabile.
Per i flussi di lavoro da sviluppatore, ti offre la stessa idea in modo programmatico. Usa Distill quando vuoi Markdown pulito per LLM o RAG. Usa Extract quando ti servono campi specifici restituiti come JSON. Usa Batch quando devi elaborare una lista di pagine prezzi, URL di documentazione, pagine prodotto o pagine dei concorrenti e ricevere i risultati in modo asincrono.
Il flusso di lavoro:
- Apri la pagina prezzi di un vendor (Datadog, Checkly, UptimeRobot, ecc.)
- Clicca “AI Suggest Fields” — Thunderbit propone le colonne in base al contenuto della pagina
- Clicca “Scrape” — i dati vengono popolati in una tabella strutturata
- Usa lo scraping delle sottopagine per raggiungere le pagine prezzi, funzionalità e documentazione di ciascun vendor
- Esporta in Google Sheets, Excel, Airtable, Notion o CSV
Per i team API-first, il flusso via API è altrettanto diretto:
- Ottieni una API key gratuita da Thunderbit
- Chiama l’endpoint Distill per ottenere Markdown pulito da qualsiasi pagina pubblica
- Chiama l’endpoint Extract con descrizioni di schema per ottenere JSON strutturato
- Usa gli endpoint Batch e i webhook per liste di URL più grandi
- Invia l’output alla tua app, al foglio di calcolo, al data warehouse, al vector database o al workflow di monitoraggio
Per un confronto tra più di 10 vendor, il copia-incolla manuale può facilmente richiedere 2–3 ore se includi sottopagine prezzi, documentazione e integrazioni. Thunderbit ha ridotto la nostra estrazione iniziale a circa 15–30 minuti, con il tempo restante speso per verifica e decisioni qualitative. Se il tuo team ops, procurement, ricerca o prodotto AI sta valutando strumenti sotto pressione temporale, è una scorciatoia pratica. Puoi vedere di più su questo tipo di flusso nella nostra guida su , esplorare i o dare un’occhiata al nostro per le walkthrough.
Come scegliere il miglior strumento di monitoraggio API per il tuo team
Lo strumento “migliore” dipende dalle dimensioni del team, dalla profondità tecnica, dal budget e da come si presenta un guasto per il tuo prodotto.
Uno sviluppatore singolo non ha bisogno di Splunk. Un’azienda regolamentata non dovrebbe affidarsi a uno script cron. Un team prodotto API potrebbe aver bisogno di analytics sui clienti in stile Moesif più che di semplici ping di uptime. Un team e-commerce dovrebbe dare priorità ai controlli critici per login, ricerca, aggiunta al carrello, checkout e autorizzazione dei pagamenti. Un team AI o data product potrebbe aver bisogno prima dell’estrazione di dati web in stile Thunderbit, e solo dopo di una observability completa.
Tre principi che hanno retto in tutta la mia ricerca:
- Abbina lo strumento al caso d’uso. La tabella rapida esiste per un motivo — parti da lì.
- Dai priorità alla qualità degli alert, non alla quantità. Se il team ignora gli avvisi, non hai monitoraggio. Hai rumore.
- Non sottovalutare la velocità di setup. Un monitor che va live oggi e invia avvisi affidabili è meglio di un piano di piattaforma perfetto che lascia il checkout non monitorato per un altro mese.
Se stai confrontando più strumenti contemporaneamente e vuoi accelerare la ricerca, prova per estrarre in massa i dati dei vendor in un unico foglio di calcolo. Se stai costruendo un prodotto API, una pipeline RAG, un agent AI o un flusso di market intelligence che richiede dati web puliti, inizia con . Non sceglierà al posto tuo lo strumento di monitoraggio — ma ti porterà più velocemente alla decisione e può dare al tuo prodotto un livello affidabile di dati web.
FAQ sui migliori strumenti di monitoraggio API
Qual è il miglior strumento gratuito di monitoraggio API nel 2026?
Per la semplicità in ambito SaaS, UptimeRobot offre 50 monitor gratuiti a intervalli di 5 minuti senza richiedere carta di credito. Per il controllo self-hosted, Uptime Kuma è open source, illimitato e ha una UI pulita con oltre 90 servizi di notifica. Per i team che vogliono profondità nelle metriche e hanno già competenze tecniche, Prometheus + Grafana + Alertmanager è il miglior stack open source — anche se il setup richiede ore, non minuti.
Se il tuo obiettivo non è il monitoraggio uptime ma l’estrazione di dati web tramite API, Thunderbit Open API ha un piano gratuito con 600 unità API una tantum, sufficienti per testare la distillazione da pagina a Markdown o l’estrazione JSON basata su schema prima di scalare.
Qual è la differenza tra monitoraggio API e APM?
Il monitoraggio API controlla disponibilità dell’endpoint, tempo di risposta, errori e correttezza dall’esterno — simula ciò che sperimenta un utente o un’integrazione. L’APM (Application Performance Monitoring) va più a fondo nell’applicazione: trace a livello di codice, query del database, errori di runtime, latenza nelle code e dipendenze dei servizi. Strumenti come Datadog e New Relic offrono entrambi; UptimeRobot e Uptime Kuma si concentrano sui controlli di uptime esterni.
Thunderbit Open API è diverso da entrambi: è un’API per l’estrazione di dati web. Ti aiuta a trasformare siti esterni in Markdown o JSON strutturato, utile per app LLM, flussi di ricerca, intelligence sui prezzi e pipeline dati.
Con quale frequenza dovrei monitorare le mie API?
Le API di produzione critiche per i ricavi (checkout, autenticazione, pagamenti) dovrebbero essere controllate tipicamente ogni 1 minuto. Le API interne o a basso traffico possono spesso essere controllate ogni 5 minuti. Ma la frequenza da sola non basta — usa retry, più regioni e asserzioni significative così ogni controllo sia veloce e affidabile. Un controllo ogni minuto che genera falsi allarmi è peggio di un controllo ogni 5 minuti di cui ti puoi fidare.
Per i flussi di estrazione di dati web, la frequenza dipende da quanto spesso cambia la fonte. Le pagine prezzi potrebbero richiedere estrazione giornaliera o settimanale. I dati di inventario, travel o marketplace che cambiano rapidamente possono richiedere aggiornamenti orari o più frequenti. L’API batch e i webhook di Thunderbit sono utili quando devi elaborare molte URL secondo una pianificazione.
Posso monitorare le API senza scrivere codice?
Sì. UptimeRobot, Better Stack e Uptime Kuma possono essere usati interamente via GUI. Checkly supporta sia la configurazione GUI sia quella basata su codice. Postman usa un’interfaccia basata sulle collection. Prometheus/Grafana richiede di solito YAML e PromQL. Datadog e New Relic possono partire con un setup guidato, ma diventano più potenti con un’osservabilità più profonda.
Se vuoi estrarre dati da siti web senza scrivere codice, l’estensione Chrome di Thunderbit è il percorso no-code. Se vuoi automatizzare lo stesso flusso da un’applicazione, offre agli sviluppatori gli endpoint Distill, Extract e Batch.
Come riduco l’alert fatigue nel monitoraggio API?
Scegli strumenti con alert intelligenti: anomaly detection (Datadog, New Relic), retry prima del firing (Checkly), anomalie comportamentali (Moesif) o grouping/silencing (Prometheus Alertmanager). Parti con meno alert ma più affidabili e focalizzati sull’impatto visibile all’utente. Usa alert basati sul burn rate degli SLO invece di soglie statiche, deduplica tra servizi, instrada per titolarità e misura l’azionabilità — se meno del 20% dei tuoi alert porta ad azioni reali, riduci prima il rumore.
Scopri di più