
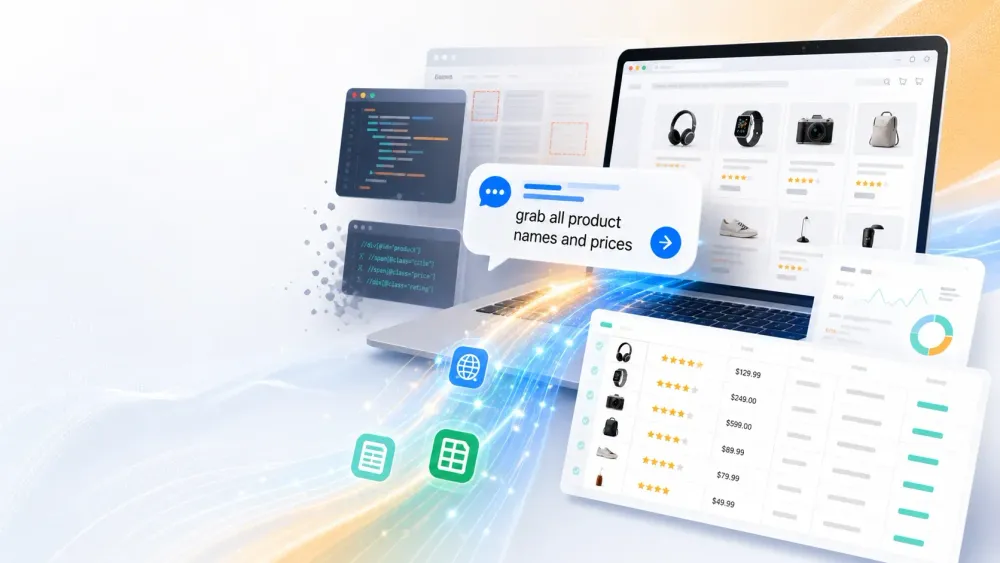
Nel 2015 fare scraping significava implorare uno sviluppatore di scrivere uno script Python oppure passare un weekend a imparare XPath. Nel 2026, scrivi “recupera tutti i nomi e i prezzi dei prodotti” e l’AI fa il resto.
Il cambiamento è arrivato in fretta. Oggi oltre 2 milioni di aziende si affidano al web scraping. Il mercato ha superato 1 miliardo di dollari nel 2024 ed è sulla buona strada per raddoppiare entro il 2030.
Il motore che sta spingendo davvero questa trasformazione? Gli AI web crawler. Si adattano ai cambiamenti di layout. Capiscono il contenuto della pagina, non solo i tag HTML. E funzionano anche per chi non ha mai scritto una riga di codice.
Ho passato mesi a testarli: 15 in tutto. Ecco cosa ho scoperto — incluso il motivo per cui Thunderbit (sì, l’azienda che ho co-fondato) si è guadagnata il primo posto.
Perché l’AI sta trasformando lo scraping delle pagine web: la nuova era degli strumenti Web Scraper
Estrai dati da qualsiasi sito web usando l’AI Get Started Free
Diciamolo chiaramente: lo scraping web tradizionale non è mai stato pensato per l’utente aziendale medio. Ruotava tutto intorno al codice, ai selettori e alla speranza che lo script non si rompesse alla prossima modifica del layout del sito. Ma l’AI e gli LLM hanno ribaltato completamente le regole del gioco.
Ecco come:
- Istruzioni in linguaggio naturale: invece di lottare con il codice, basta dire all’AI cosa ti serve. Strumenti come Thunderbit interpretano le tue istruzioni in inglese semplice e configurano l’estrazione per te (fonte).
- Apprendimento adattivo: gli scraper AI possono adattarsi ai cambiamenti di layout dei siti, riducendo i grattacapi di manutenzione.
- Gestione dei contenuti dinamici: i siti moderni adorano JavaScript e lo scroll infinito. Gli strumenti basati sull’AI interagiscono con questi elementi e catturano dati che gli scraper tradizionali si lascerebbero sfuggire.
- Output strutturato con parsing AI: gli scraper basati su LLM capiscono davvero il contenuto della pagina e restituiscono dati puliti e strutturati.
- Evasione automatica anti-bot: gli scraper AI possono aggirare le misure anti-scraping e usare proxy/browser headless per evitare blocchi IP.
- Flussi di lavoro dati integrati: i migliori strumenti non si limitano a recuperare dati — li portano dove ti servono, con esportazioni in un clic verso Google Sheets, Airtable, Notion e altro ancora (fonte).
Il risultato? Oggi lo scraping web è un’esperienza da puntare e cliccare (o persino simile a una chat), aprendo le porte non solo agli sviluppatori, ma anche ai team di sales, marketing e operations per usare direttamente i dati web.
15 AI Web Crawler che meritano la tua attenzione nel 2026
Analizziamo i 15 migliori AI web crawler, a partire da Thunderbit. Ti darò una panoramica delle funzioni principali di ogni strumento, del pubblico a cui si rivolge, dei prezzi e di ciò che lo distingue. E sì, sarò sincero su dove ciascuno brilla e dove invece può mostrare i suoi limiti.
1. Thunderbit: l’AI Web Scraper per tutti
Sono ovviamente un po’ di parte, ma Thunderbit è l’AI web scraper che avrei voluto avere anni fa. Ecco perché è al primo posto in questa lista:
- Estrazione in linguaggio naturale: con Thunderbit ci fai quasi una “chat”. Ti basta descrivere i dati che vuoi — “estrai tutti i nomi e i prezzi dei prodotti da questa pagina” — e l’AI fa il resto (fonte). Niente codice, niente selettori, niente mal di testa.
- Crawling di sottopagine e multilivello: Thunderbit può seguire i link ed estrarre le sottopagine. Per esempio, puoi estrarre una lista di prodotti e poi aprire ogni scheda per i dettagli, tutto in un’unica operazione.
- Output strutturato istantaneo: l’AI formatta e pulisce i dati al volo, suggerisce i campi rilevanti, normalizza i formati e persino riassume o categorizza i testi.
- Ampio supporto per le fonti: Thunderbit non lavora solo con HTML: può estrarre dati da PDF e immagini grazie all’OCR integrato e alla vision AI (fonte).
- Integrazioni business: esportazione in un clic verso Google Sheets, Airtable, Notion o Excel (fonte). Pianifica le estrazioni e fai fluire i dati direttamente nel workflow del tuo team.
- Template preconfigurati: per siti come Amazon, LinkedIn, Zillow e altri, Thunderbit offre “ricette” di scraping già pronte per l’estrazione dati con un solo clic.
- Facile da usare e accessibile: l’interfaccia è intuitiva e guidata da un assistente semplice. Gli utenti riportano di essere operativi in pochi minuti.

Thunderbit è usato e apprezzato da oltre 30.000 utenti nel mondo, compresi team di Accenture, Grammarly e Puma. I team sales lo usano per creare liste di lead, gli agenti immobiliari aggregano annunci e i marketer monitorano i concorrenti — tutto senza scrivere una sola riga di codice.
Prezzi: c’è un piano gratuito (fino a 100 step/mese), con piani a pagamento a partire da 14,99 $/mese. Anche i piani Pro restano accessibili per singoli e piccoli team.
Thunderbit è la cosa più vicina che abbia visto a “trasformare il web in un database” — ed è pensato per tutti, non solo per gli ingegneri.
Prova l’estensione Chrome di Thunderbit
2. Crawl4AI
A chi è rivolto: sviluppatori e team tecnici che costruiscono pipeline personalizzate.
Crawl4AI è un framework open-source basato su Python, ottimizzato per la velocità e per il crawling su larga scala, con integrazione pensata per gli LLM. È velocissimo, supporta browser headless per i contenuti dinamici e può strutturare i dati estratti per alimentarli facilmente nei flussi AI.
- Ideale per: sviluppatori che hanno bisogno di un motore di crawling potente e personalizzabile.
- Prezzi: gratis (licenza MIT). Va ospitato ed eseguito autonomamente.
3. ScrapeGraphAI
A chi è rivolto: sviluppatori e analisti che costruiscono agenti AI o pipeline dati complesse.
ScrapeGraphAI è una libreria Python open-source guidata da prompt che trasforma i siti web in “grafi” di dati strutturati usando gli LLM. Puoi scrivere prompt come “Estrai tutti i nomi dei prodotti, i prezzi e le valutazioni delle prime 5 pagine” e lui costruisce per te il flusso di scraping (fonte).
- Ideale per: utenti tecnici che vogliono uno scraping flessibile, basato su prompt.
- Prezzi: gratuito per la libreria open-source; la cloud API parte da 20 $/mese.
4. Firecrawl
A chi è rivolto: sviluppatori che costruiscono agenti AI o pipeline dati su larga scala.
Firecrawl è una piattaforma di crawling e API incentrata sull’AI che trasforma interi siti web in dati “pronti per gli LLM” (fonte). Restituisce Markdown o JSON, gestisce contenuti dinamici e si integra con framework come LangChain e LlamaIndex.
- Ideale per: sviluppatori che devono alimentare modelli AI con dati web live.
- Prezzi: il core open-source è gratuito; i piani cloud partono da 19 $/mese.
5. Browse AI
A chi è rivolto: utenti business, growth hacker e analisti.
Browse AI è una piattaforma no-code con un’interfaccia puntuale e intuitiva. “Addestri” un robot cliccando sui dati che ti servono e l’AI generalizza il pattern per le estrazioni future. Gestisce login, scroll infinito e può monitorare i siti per individuare cambiamenti.
- Ideale per: utenti non tecnici che vogliono automatizzare raccolta e monitoraggio dati.
- Prezzi: piano gratuito (50 crediti/mese); i piani a pagamento partono da 19 $/mese.
6. LLM Scraper
A chi è rivolto: sviluppatori che vogliono lasciare il parsing all’AI.
LLM Scraper è una libreria open-source JavaScript/TypeScript che ti permette di definire uno schema dati e far estrarre quei dati da un LLM da qualsiasi pagina web. È costruita su Playwright, supporta diversi provider LLM e può persino generare codice riutilizzabile.
- Ideale per: sviluppatori che vogliono trasformare qualsiasi pagina web in dati strutturati usando gli LLM.
- Prezzi: gratuito (licenza MIT).
7. Reader (Jina Reader)
A chi è rivolto: sviluppatori che costruiscono applicazioni LLM, chatbot o strumenti di riassunto.
Jina Reader è un’API che estrae testo pulito e dati strutturati dalle pagine web (e persino da PDF/immagini), restituendo Markdown o JSON pronti per gli LLM. È alimentato da un modello AI personalizzato e può persino generare didascalie per le immagini.
- Ideale per: recuperare contenuti puliti e leggibili per LLM o sistemi di domande e risposte.
- Prezzi: API gratuita (nessuna chiave richiesta per l’uso base).
8. Bright Data
A chi è rivolto: aziende e utenti professionali che hanno bisogno di scalabilità, conformità e affidabilità.
Bright Data è un colosso nel settore dei dati web, con una rete proxy enorme e strumenti di scraping basati sull’AI. Offre scraper già pronti, una Web Scraper API generalista e feed di dati “pronti per gli LLM”.
- Ideale per: organizzazioni che hanno bisogno di dati web affidabili su larga scala.
- Prezzi: a consumo, premium. Sono disponibili prove gratuite.
9. Octoparse
A chi è rivolto: utenti non tecnici o semi-tecnici.
Octoparse è uno strumento no-code molto affermato, con un designer visuale dei workflow e rilevamento automatico basato sull’AI. Gestisce login, scroll infinito e può esportare i dati in diversi formati.
- Ideale per: analisti, titolari di piccole imprese o ricercatori.
- Prezzi: piano gratuito disponibile; i piani a pagamento partono da 119 $/mese.
10. Apify
A chi è rivolto: sviluppatori e team tecnici che hanno bisogno di scraping/automazione personalizzati.
Apify è una piattaforma cloud per eseguire script di scraping (“actors”) e offre uno store di actor già pronti. È scalabile, si integra con l’AI e supporta la gestione dei proxy.
- Ideale per: sviluppatori che vogliono eseguire script personalizzati nel cloud.
- Prezzi: piano gratuito; i piani a pagamento a consumo partono da 49 $/mese.
11. Zyte (Scrapy Cloud)
A chi è rivolto: sviluppatori e aziende che hanno bisogno di scraping di livello enterprise.
Zyte è l’azienda dietro Scrapy e offre una piattaforma cloud con estrazione automatica basata sull’AI. Gestisce pianificazione, proxy e progetti su larga scala.
- Ideale per: team di sviluppo che portano avanti progetti di scraping a lungo termine.
- Prezzi: dai trial gratuiti ai piani enterprise personalizzati.
12. Webscraper.io
A chi è rivolto: principianti, giornalisti e ricercatori.
Webscraper.io è una popolare estensione Chrome per l’estrazione dati con approccio point-and-click. È semplice, gratuita per l’uso locale e offre un servizio cloud per lavori più grandi.
- Ideale per: attività di scraping rapide e occasionali.
- Prezzi: estensione gratuita; i piani cloud partono da circa 50 $/mese.
13. ParseHub
A chi è rivolto: utenti non tecnici che hanno bisogno di più potenza rispetto agli strumenti base.
ParseHub è un’app desktop con un workflow visuale per estrarre contenuti dinamici, comprese mappe e moduli. Può eseguire i progetti nel cloud e offre una API.
- Ideale per: digital marketer, analisti e giornalisti.
- Prezzi: piano gratuito (200 pagine per esecuzione); i piani a pagamento partono da 189 $/mese.
14. Diffbot
A chi è rivolto: aziende e società AI che hanno bisogno di dati web strutturati su larga scala.
Diffbot usa computer vision e NLP per estrarre automaticamente i dati da qualsiasi pagina web, offrendo API per articoli, prodotti e un enorme knowledge graph.
- Ideale per: market intelligence, finanza e dati di training per l’AI.
- Prezzi: premium, a partire da circa 299 $/mese.
15. DataMiner
A chi è rivolto: utenti non tecnici, soprattutto in sales, marketing e giornalismo.
DataMiner è una estensione Chrome per estrarre rapidamente dati web con approccio point-and-click. Ha una libreria di “ricette” preconfigurate e può esportare direttamente in Google Sheets.
- Ideale per: attività rapide come esportare tabelle o elenchi in fogli di calcolo.
- Prezzi: piano gratuito (500 pagine/giorno); Pro parte da circa 19 $/mese.
Confronto tra i migliori strumenti AI Web Scraper: qual è quello giusto per te?
Ecco un confronto ad alto livello per aiutarti a trovare quello più adatto:
| Strumento | Uso di AI/LLM | Facilità d’uso | Output/Integrazione | Ideale per | Prezzi |
|---|---|---|---|---|---|
| Thunderbit | Interfaccia in linguaggio naturale; l’AI suggerisce i campi | Facilissimo (chat no-code) | Esportazioni in Sheets, Airtable, Notion | Team non tecnici | Piano gratuito; Pro circa 30 $/mese |
| Crawl4AI | Crawling pronto per l’AI; integrazione con LLM | Difficile (codice Python) | Libreria/CLI; integrazione via codice | Dev che hanno bisogno di pipeline AI veloci | Gratis |
| ScrapeGraphAI | Pipeline di prompt LLM per lo scraping | Medio (un po’ di codice o API) | API/SDK; output JSON | Dev/analisti che costruiscono agenti AI | OSS gratis; API da 20 $/mese |
| Firecrawl | Crawling verso Markdown/JSON pronti per LLM | Medio (uso API/SDK) | SDK (Py, Node, ecc.); integrazione LangChain | Dev che integrano dati web live con l’AI | Gratis + cloud a pagamento |
| Browse AI | Point & click assistito dall’AI | Facile (no-code) | Oltre 7000 integrazioni app (Zapier) | Utenti non tecnici che automatizzano il monitoraggio web | 50 esecuzioni gratis; a pagamento da 19 $/mese |
| LLM Scraper | Usa LLM per analizzare la pagina in base allo schema | Difficile (codice TS/JS) | Libreria di codice; output JSON | Dev che vogliono che l’AI faccia il parsing | Gratis (usando la propria API LLM) |
| Reader (Jina) | Modello AI estrae testo/JSON | Facile (semplice chiamata API) | API REST che restituisce Markdown/JSON | Dev che aggiungono contenuti web o ricerca agli LLM | API gratuita |
| Bright Data | API di scraping potenziate dall’AI; grande rete proxy | Difficile (API, tecnico) | API/SDK; flussi di dati o dataset | Scala enterprise | A consumo |
| Octoparse | Rilevamento automatico AI di elenchi | Moderato (app no-code) | CSV/Excel, API per i risultati | Utenti semi-tecnici | Limitato gratis; 59–166 $/mese |
| Apify | Alcune funzioni AI (Actors, tutorial AI) | Difficile (script in codice) | API completa; integrazione con LangChain | Dev che hanno bisogno di scraping personalizzato nel cloud | Piano gratuito; pay-as-you-go |
| Zyte (Scrapy) | Estrazione automatica basata su ML; framework Scrapy | Difficile (codice Python) | API, interfaccia Scrapy Cloud; JSON/CSV | Team di sviluppo, progetti a lungo termine | Prezzi personalizzati |
| Webscraper.io | Nessuna AI (template manuali) | Facile (estensione browser) | Download CSV, Cloud API | Principianti, scraping rapidi e una tantum | Estensione gratuita; Cloud circa 50 $/mese |
| ParseHub | Nessun LLM esplicito; builder visuale | Moderato (app no-code) | JSON/CSV; API per esecuzioni cloud | Non sviluppatori che estraggono siti complessi | 200 pagine gratis; a pagamento da 189 $/mese |
| Diffbot | Visione AI/NLP per qualsiasi pagina; knowledge graph | Facile (solo chiamate API) | API (Article/Prod/...) + query Knowledge Graph | Enterprise, dati web strutturati | Da circa 299 $/mese |
| DataMiner | Nessun LLM; ricette della community | Facilissimo (interfaccia browser) | Esportazione Excel/CSV; Google Sheets | Utenti non tecnici che estraggono dati in fogli di calcolo | Limitato gratis; Pro circa 19 $/mese |
Categorie di strumenti: dai colossi per sviluppatori agli scraper web facili per il business
Per dare un senso a questa lista, possiamo dividere questi strumenti in alcune categorie:
1. Potenze per sviluppatori e open-source
- Esempi: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Punti di forza: grande flessibilità, scalabilità e personalizzazione. Perfetti per costruire pipeline su misura o integrarsi con modelli AI.
- Compromessi: richiedono competenze di programmazione e più configurazione.
- Casi d’uso: costruire una pipeline dati personalizzata, fare scraping di siti complessi o integrarsi con sistemi interni.
2. Agenti di scraping integrati con l’AI
- Esempi: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Punti di forza: riducono il divario tra lo scraping e la comprensione dei dati. Le interfacce in linguaggio naturale li rendono accessibili.
- Compromessi: alcuni sono ancora in evoluzione; possono non offrire un controllo molto granulare.
- Casi d’uso: risposte rapide o dataset, costruzione di agenti autonomi o alimentazione di LLM con dati live.
3. Scraper no-code/low-code adatti al business
- Esempi: Thunderbit, Browse AI, Octoparse, ParseHub, Webscraper.io, DataMiner
- Punti di forza: facili da usare, richiedono poco o nessun codice, ottimi per attività aziendali ricorrenti.
- Compromessi: possono incontrare difficoltà con siti molto complessi o con volumi enormi.
- Casi d’uso: lead generation, monitoraggio dei concorrenti, progetti di ricerca ed estrazioni dati occasionali.
4. Piattaforme e servizi dati enterprise
- Esempi: Bright Data, Diffbot, Zyte
- Punti di forza: soluzioni complete, servizi gestiti, conformità e affidabilità su larga scala.
- Compromessi: costi più elevati, onboarding più impegnativo.
- Casi d’uso: pipeline dati sempre attive su larga scala, market intelligence e dati di training per l’AI.
Come scegliere l’AI Web Crawler giusto per le tue esigenze di scraping web
Che cos’è il data scraping e come farlo Get Started Free
Scegliere lo strumento giusto può sembrare opprimente, quindi ecco la mia guida passo passo:
- Definisci obiettivi e requisiti dei dati: quali siti e quali dati ti servono? Con quale frequenza? In che quantità? Cosa ne farai?
- Valuta le tue competenze tecniche: niente codice? Prova Thunderbit, Browse AI o Octoparse. Hai un po’ di scripting? LLM Scraper o DataMiner. Hai forti competenze da sviluppatore? Crawl4AI, Apify o Zyte.
- Considera frequenza e scala: attività una tantum? Usa strumenti gratuiti. Ricorrenti? Cerca funzioni di pianificazione. Su larga scala? Strumenti enterprise o open-source dimensionati per volumi elevati.
- Budget e modello di prezzo: i piani gratuiti sono ottimi per testare. Abbonamento o pagamento a consumo dipende dalle tue esigenze.
- Prova e proof of concept: testa alcuni strumenti sui tuoi dati reali. La maggior parte ha piani gratuiti.
- Manutenzione e supporto: chi interviene se il sito cambia? Gli strumenti no-code con AI possono correggere automaticamente piccole modifiche; l’open-source dipende da te o dalla community.
- Abbina gli strumenti agli scenari: un team sales che estrae lead? Thunderbit o Browse AI. Un ricercatore che raccoglie tweet? DataMiner o Webscraper.io. Un modello AI che ha bisogno di articoli di news? Jina Reader o Zyte. Un sito di comparazione? Apify o Zyte.
- Prevedi un piano B: a volte uno strumento non funziona su un sito specifico. Conviene avere un’alternativa.
Lo strumento “giusto” è quello che ti dà i dati che ti servono con il minimo attrito e restando nel budget. A volte, è una combinazione di strumenti.
Thunderbit vs. strumenti tradizionali di Web Scraper: cosa lo rende diverso?
Entriamo nel dettaglio del perché Thunderbit è diverso:
- Interfaccia in linguaggio naturale: niente codice, niente acrobazie point-and-click. Descrivi semplicemente ciò che vuoi (fonte).
- Configurazione zero e suggerimenti di template: Thunderbit rileva automaticamente la paginazione, le sottopagine e suggerisce persino template per i siti più comuni (fonte).
- Pulizia e arricchimento dati con l’AI: riassumi, categorizza, traduci e arricchisci i dati mentre li estrai (fonte).
- Meno problemi di manutenzione: l’AI di Thunderbit è resistente ai piccoli cambiamenti del sito, riducendo i guasti.
- Integrazione con gli strumenti business: esportazione diretta in Google Sheets, Airtable, Notion — niente più gestione manuale dei CSV (fonte).
- Rapidità nel creare valore: passi dall’idea ai dati in pochi minuti, non in giorni.
- Curva di apprendimento: se sai navigare sul web e descrivere ciò che ti serve, puoi usare Thunderbit.
- Adattabilità: estrai dati da siti web, PDF, immagini e altro ancora — tutto con lo stesso strumento.
Thunderbit non è solo uno scraper: è un assistente dati che si inserisce nel tuo flusso di lavoro, che tu lavori in sales, marketing, ecommerce o real estate.
Prova l’AI Web Scraper di Thunderbit
Migliori pratiche per lo scraping delle pagine web con strumenti AI Web Scraper
Per ottenere il massimo dagli AI web scraper, ecco i miei consigli principali:
- Definisci chiaramente i dati che ti servono: sai quali campi vuoi, quante pagine e in quale formato.
- Sfrutta i suggerimenti dell’AI: usa il rilevamento dei campi e i suggerimenti automatici degli strumenti per intercettare dati importanti che potresti perdere (fonte).
- Inizia in piccolo e valida: testa su un campione ridotto, controlla l’output e modifica se serve.
- Gestisci i contenuti dinamici: assicurati che lo strumento supporti contenuti e interazioni dinamiche (paginazione, scroll infinito, ecc.).
- Rispetta le policy del sito: controlla robots.txt, evita di estrarre dati sensibili e rispetta i limiti di frequenza.
- Integra per automatizzare: usa le funzioni di esportazione e i webhook per inserire i dati estratti direttamente nel tuo workflow.
- Mantieni alta la qualità dei dati: fai controlli di coerenza, usa post-processing e monitora gli errori.
- Sii conciso nei prompt: quando usi strumenti guidati dall’AI, istruzioni chiare e specifiche portano risultati migliori.
- Impara dalla community: unisciti a forum e community per consigli e troubleshooting.
- Resta aggiornato: gli strumenti AI evolvono rapidamente — tieni d’occhio nuove funzioni e miglioramenti.
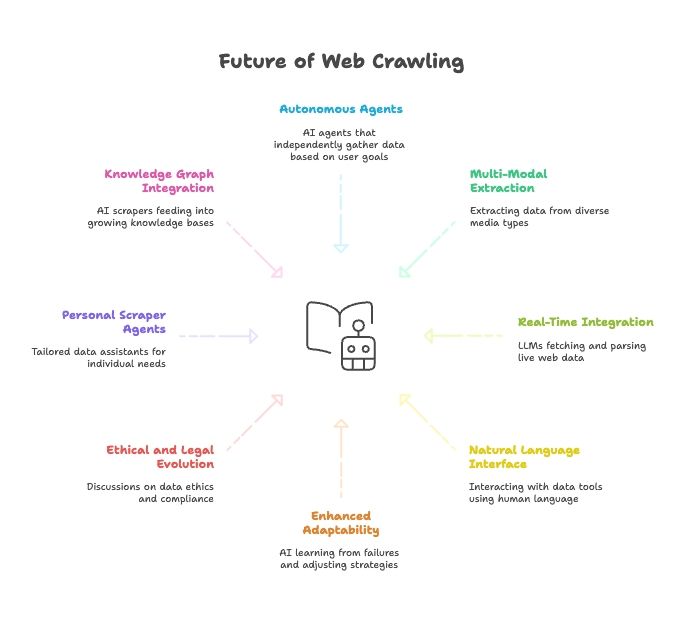
Il futuro dello scraping web: AI, LLM e l’ascesa degli agenti Web Scraper in linguaggio naturale
Guardando avanti, la convergenza tra AI e web scraping sta accelerando sempre di più:
- Agenti scraper completamente autonomi: presto basterà dire a un agente AI qual è l’obiettivo finale, e lui capirà come ottenere i dati.
- Estrazione dati multimodale: gli scraper prenderanno dati da testo, immagini, PDF e persino video.
- Integrazione in tempo reale con i modelli AI: gli LLM avranno moduli integrati per recuperare e analizzare dati web live.
- Tutto in linguaggio naturale: parleremo ai nostri strumenti dati come parliamo alle persone, rendendo raccolta e trasformazione dei dati accessibili a tutti.
- Adattabilità potenziata: gli scraper AI impareranno dai fallimenti e adatteranno automaticamente le strategie.
- Evoluzione etica e legale: aspettati più discussioni su etica dei dati, conformità e fair use.
- Agenti scraper personali: immagina un assistente dati personale che raccoglie notizie, offerte di lavoro e altro ancora, su misura per le tue esigenze.
- Integrazione con i knowledge graph: gli scraper AI alimenteranno in modo continuo knowledge base sempre più grandi, potenziando un’AI più intelligente.
Il punto chiave? Il futuro dello scraping web è intrecciato con il futuro dell’AI. Gli strumenti stanno diventando più intelligenti, più autonomi e più accessibili ogni giorno.
Conclusione: sbloccare valore business con l’AI Web Crawler giusto
Lo scraping web è passato da competenza tecnica di nicchia a capacità aziendale centrale, grazie all’AI. I 15 strumenti che ho presentato qui rappresentano il meglio di ciò che è possibile nel 2026, dai colossi per sviluppatori agli assistenti adatti al business.
Il vero segreto? Scegliere lo strumento giusto può aumentare in modo drastico il valore che ottieni dai dati web. Per i team non tecnici, Thunderbit è il modo più semplice per trasformare il web in un database strutturato e pronto per l’analisi — niente codice, niente complicazioni, solo risultati.
Quindi, che tu stia raccogliendo lead, monitorando i concorrenti o alimentando il tuo modello AI di nuova generazione, prenditi il tempo di valutare le tue esigenze, prova alcuni strumenti e scopri cosa funziona meglio per te. E se vuoi sperimentare oggi il futuro dello scraping web, prova Thunderbit. Le informazioni che ti servono sono a un prompt di distanza.
Vuoi saperne di più? Dai un’occhiata al Thunderbit Blog per approfondimenti, tutorial e le ultime novità sull’estrazione dati con l’AI.
Ulteriori letture:
- Che cos’è il data scraping e come farlo nel 2026
- Come estrarre dati da un sito web in Excel usando l’AI
- I migliori strumenti e software per il web scraping nel 2026
Prova l’AI Web Scraper Get Started Free
FAQ
1. Che cos’è un AI web crawler e in cosa si differenzia dagli scraper web tradizionali?
Un AI web crawler usa l’elaborazione del linguaggio naturale e il machine learning per comprendere, estrarre e strutturare i dati web. A differenza degli scraper tradizionali, che richiedono codifica manuale e selettori XPath, gli strumenti AI possono gestire contenuti dinamici, adattarsi ai cambiamenti di layout e interpretare istruzioni in inglese semplice.
2. Chi dovrebbe usare strumenti di web scraping con AI come Thunderbit?
Thunderbit è pensato sia per utenti non tecnici sia per utenti tecnici. È ideale per professionisti di sales, marketing, operations, ricerca ed ecommerce che vogliono estrarre dati strutturati da siti web, PDF o immagini — senza scrivere codice.
3. Quali funzioni fanno emergere Thunderbit rispetto ad altri AI web crawler?
Thunderbit offre un’interfaccia in linguaggio naturale, crawling multilivello, strutturazione automatica dei dati, supporto OCR ed esportazioni fluide verso piattaforme come Google Sheets e Airtable. Include anche suggerimenti di campi basati sull’AI e template preconfigurati per i siti più popolari.
4. Esistono opzioni gratuite per il web scraping con AI nel 2026?
Sì. Molti strumenti come Thunderbit, Browse AI e DataMiner offrono piani gratuiti con uso limitato. Per gli sviluppatori, opzioni open-source come Crawl4AI e ScrapeGraphAI forniscono funzionalità complete senza costi, anche se richiedono configurazione tecnica.
5. Come scelgo l’AI web crawler giusto per le mie esigenze?
Inizia identificando i tuoi obiettivi dati, le tue capacità tecniche, il budget e le esigenze di scala. Se vuoi una soluzione no-code e facile da usare, Thunderbit o Browse AI sono ottime scelte. Per esigenze su larga scala o personalizzate, strumenti come Apify o Bright Data sono più adatti.




