
Lasciami raccontarti un segreto: un tempo pensavo che il web scraping fosse roba da hacker col cappuccio o da data scientist con più monitor che buon senso. Oggi, però, estrarre dati da un sito web è normale nel business quanto prendersi un caffè al mattino—solo che, per fortuna, non serve sapere Python né bere tre espressi prima di mezzogiorno. Anzi, con l’arrivo degli strumenti di AI web scraper, persino chi pensa che “HTML” sia un nuovo panino di Subway può estrarre dati strutturati dal web selvaggio.
Se ti è mai capitato di copiare e incollare righe di informazioni sui prodotti, lead commerciali o listini prezzi in un foglio di calcolo, non sei solo. Quasi il 73% delle aziende usa ormai il web scraping per ottenere insight di mercato e monitorare la concorrenza. E con il mercato del software per il web scraping destinato a raggiungere $2,49 miliardi entro il 2032, una cosa è chiara: l’estrazione di dati dal web non è più solo per l’élite tech. Quindi, che tu sia un professionista delle vendite, un marketer o semplicemente qualcuno che vuole smettere di inserire dati a mano, questa guida fa per te. Ti guiderò dalle basi, confronterò gli approcci tradizionali con quelli basati sull’AI e ti mostrerò come iniziare—senza bisogno del cappuccio.
Basi dello Web Scraper: cosa significa estrarre dati da un sito web?
Partiamo dalle basi. Un Estrattore Web non è altro che uno strumento (o uno script, o un’estensione Chrome) che raccoglie automaticamente dati dai siti web. Pensalo come uno stagista super veloce che non si lamenta mai dei compiti ripetitivi. Invece di copiare e incollare informazioni riga per riga, un Estrattore Web fa tutto in pochi secondi e non chiede neppure una pausa caffè.
Ci sono due tipi principali di dati con cui avrai a che fare:
- Dati strutturati: sono quelli ordinati, pronti per il foglio di calcolo—come tabelle di nomi prodotto, prezzi o email. Sono organizzati, etichettati e facili da analizzare.
- Dati non strutturati: questo è il Far West—post di blog, recensioni, immagini o qualsiasi cosa che non si adatti bene a righe e colonne. La maggior parte dei progetti di web scraping mira a trasformare i dati non strutturati in dati strutturati, così puoi davvero usarli.
Se hai mai copiato una tabella da un sito web in Excel, congratulazioni: hai fatto web scraping manuale. Ora immagina di farlo per 10.000 pagine. (Non farlo davvero. È per questo che esistono gli Estrattori Web.)
Perché estrarre dati dai siti web? I principali vantaggi per il business
Quindi, perché darsi la pena di fare scraping dei dati? La risposta breve è questa: le aziende vivono di dati, e il web è il database più grande del mondo. Che tu lavori nelle vendite, nel marketing, nell’ecommerce o nel real estate, l’estrazione di dati dal web può darti un vantaggio concreto.
Ecco alcuni dei casi d’uso aziendali più comuni:
| Caso d'uso | Descrizione | ROI/Vantaggio di esempio |
|---|---|---|
| Generazione di lead | Raccolta di contatti, email o liste di aziende da directory o social network | I team di vendita risparmiano ore e trovano lead più qualificati |
| Monitoraggio prezzi | Tracciamento in tempo reale di prezzi, disponibilità o promozioni dei concorrenti | I retailer adattano i prezzi in modo dinamico, aumentando le vendite del 4% |
| Ricerca di mercato | Raccolta di recensioni, notizie o sentiment sui social per individuare trend | I marketer adattano le campagne agli insight in tempo reale sui consumatori |
| Analisi della concorrenza | Monitoraggio di cataloghi prodotti, lanci o contenuti dei rivali | Le aziende reagiscono più rapidamente ai cambiamenti del mercato |
| Intelligence immobiliare | Raccolta di annunci immobiliari, prezzi e disponibilità | Agenti e investitori individuano opportunità prima del mercato |
Infatti, nel Regno Unito e in Europa, dal 25 al 30% dei retailer usa strategie di pricing dinamico alimentate dallo scraping dei prezzi dei concorrenti. E aziende come John Lewis e ASOS hanno registrato aumenti di vendite misurabili sfruttando i dati del web per prendere decisioni più intelligenti.
Strumenti tradizionali di Web Scraper: come funzionano?
Facciamo un salto indietro al modo “classico” di estrarre dati—prima che l’AI iniziasse a mostrare i muscoli. Gli Estrattori Web tradizionali sono di solito script (spesso scritti in Python) o estensioni del browser che seguono una serie di regole per raccogliere i dati desiderati.
Ecco come funziona in genere il processo:
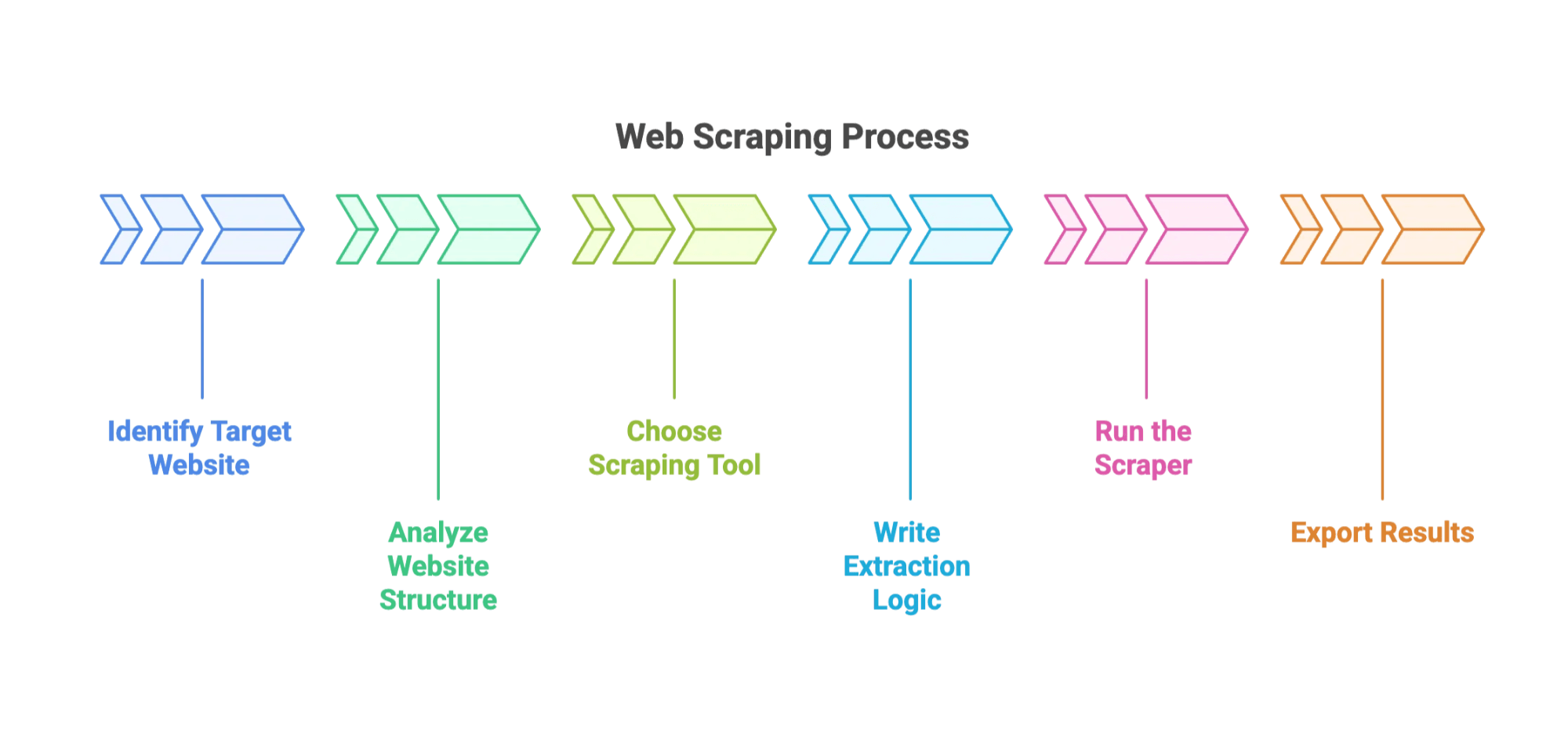
- Individua il sito target e i campi di dati.
- Analizza la struttura del sito. (Significa esplorare l’HTML con gli Strumenti per sviluppatori del browser. È come archeologia digitale.)
- Scegli lo strumento: tra le opzioni più popolari ci sono BeautifulSoup, Scrapy o i plugin del browser.
- Scrivi la logica di estrazione: indica allo strumento come trovare i dati, di solito specificando selettori CSS o XPath.
- Avvia l’Estrattore: guarda mentre raccoglie i dati su più pagine.
- Esporta i risultati: di solito in CSV, JSON o direttamente in Excel.
Passo dopo passo: estrarre dati con un Estrattore Web tradizionale
Mettiamo che tu voglia fare scraping degli annunci prodotto da un sito ecommerce. Ecco una guida semplice per chi inizia:
- Passo 1: installa Python e la libreria BeautifulSoup.
- Passo 2: usa il browser per ispezionare la pagina del prodotto. Trova i tag HTML che contengono il nome e il prezzo.
- Passo 3: scrivi un piccolo script per recuperare la pagina, analizzare l’HTML ed estrarre i campi rilevanti.
- Passo 4: scorri più pagine (gestendo la paginazione).
- Passo 5: esporta i dati in un file CSV.
Sembra tutto lineare, ma fidati: il tuo primo script probabilmente si romperà almeno una volta. (Il mio primo tentativo ha estratto 500 righe di “None” perché avevo sbagliato a scrivere il nome di una classe. Ops.)
Sfide comuni con le soluzioni tradizionali di Web Scraper
Ed è qui che le cose si complicano:
- Cambiamenti del sito: anche una piccola modifica al layout può mandare in crisi il tuo scraper. Il 10–15% degli scraper si rompe ogni settimana a causa dei cambiamenti.
- Misure anti-bot: CAPTCHA, blocchi IP e limiti di frequenza possono fermarti di colpo. Dovrai gestire proxy, ritardi e, a volte, persino risolvere i CAPTCHA.
- Competenze tecniche richieste: serve conoscere almeno un po’ di coding e HTML/CSS.
- Manutenzione: gli scraper hanno bisogno di attenzioni e aggiornamenti continui.
- Dati sporchi: perderai tempo a sistemare formati incoerenti, valori mancanti o codifiche strane.
Per un principiante, può sembrare di provare a preparare una torta mentre la ricetta continua a cambiare e il forno ogni tanto ti blocca fuori.
Entra in scena l’AI Web Scraper: rendere l’estrazione dei dati accessibile
Estrai dati da qualsiasi sito web usando l’AI Get Started Free
Ora viene la parte divertente. Gli AI web scraper stanno cambiando le regole del gioco. Invece di scrivere codice o armeggiare con i selettori, puoi semplicemente dire allo strumento cosa vuoi in inglese semplice. Sarà l’AI a capire il resto.
Thunderbit (cioè noi!) è un ottimo esempio di questa nuova generazione. Con Thunderbit, puoi estrarre dati strutturati da qualsiasi sito web usando il linguaggio naturale—senza scrivere codice. Che tu lavori nelle vendite, nel marketing o nell’ecommerce, puoi raccogliere i dati di cui hai bisogno in pochi minuti, non in giorni.
Thunderbit AI Web Scraper: come semplifica l’estrazione dei dati
Lasciami mostrarti come Thunderbit ti semplifica la vita:
- AI Suggerisci campi: basta cliccare su “AI Suggerisci campi” e Thunderbit legge il sito, propone i nomi delle colonne e suggerisce persino come estrarre ogni campo.
- Scraping delle sottopagine: ti servono più dettagli? Thunderbit può visitare ogni sottopagina (come le singole pagine prodotto) e arricchire automaticamente la tua tabella dati.
- Template istantanei: per siti popolari come Amazon o Zillow, puoi usare template già pronti—nessuna configurazione necessaria.
- Esportazione dati gratuita: esporta i tuoi dati in Excel, Google Sheets, Airtable o Notion. Scarica in CSV o JSON. Nessun costo nascosto.
- Scraping pianificato: imposta estrazioni ricorrenti per mantenere i dati aggiornati—ottimo per il monitoraggio prezzi o gli aggiornamenti dei lead.
- AI Autofill: lascia che l’AI compili per te i moduli online (sì, anche quel modulo di onboarding fornitori da 10 pagine).
- Estrattori Email, Telefono e Immagini: raccogli informazioni di contatto o immagini con un solo clic.
E la parte migliore? Non devi sapere nemmeno una riga di codice. L’estensione Chrome di Thunderbit è disponibile qui, e puoi saperne di più sul nostro sito ufficiale.
Prova gratis Thunderbit AI Web Scraper
Confronto tra soluzioni tradizionali e AI Web Scraper
Vediamo come si confrontano i due approcci:
| Aspetto | Estrattore Web tradizionale | AI Web Scraper (Thunderbit) |
|---|---|---|
| Facilità d'uso | Richiede codice o configurazione complessa | Nessun codice, interfaccia in linguaggio naturale |
| Adattabilità | Si rompe facilmente quando il sito cambia | L’AI si adatta automaticamente ai cambiamenti di layout |
| Manutenzione | Alta—richiede aggiornamenti frequenti | Bassa—l’AI gestisce la maggior parte delle modifiche |
| Competenze tecniche | Richiede conoscenze di programmazione e HTML | Progettato per utenti business |
| Velocità di configurazione | Da ore a giorni | Minuti |
| Elaborazione dati | Serve pulizia manuale | L’AI pulisce e struttura i dati automaticamente |
| Costo | Gratis (open source), ma richiede molto tempo | Piani accessibili, opzioni di esportazione gratuite |
Per la maggior parte degli utenti business, soprattutto i principianti, gli AI web scraper come Thunderbit sono la scelta migliore per velocità, semplicità e affidabilità. Gli strumenti tradizionali hanno ancora il loro posto in progetti molto personalizzati o su larga scala—ma per il 95% dei casi d’uso, l’AI è la strada giusta.
Guida passo dopo passo: come estrarre dati da un sito web da principiante
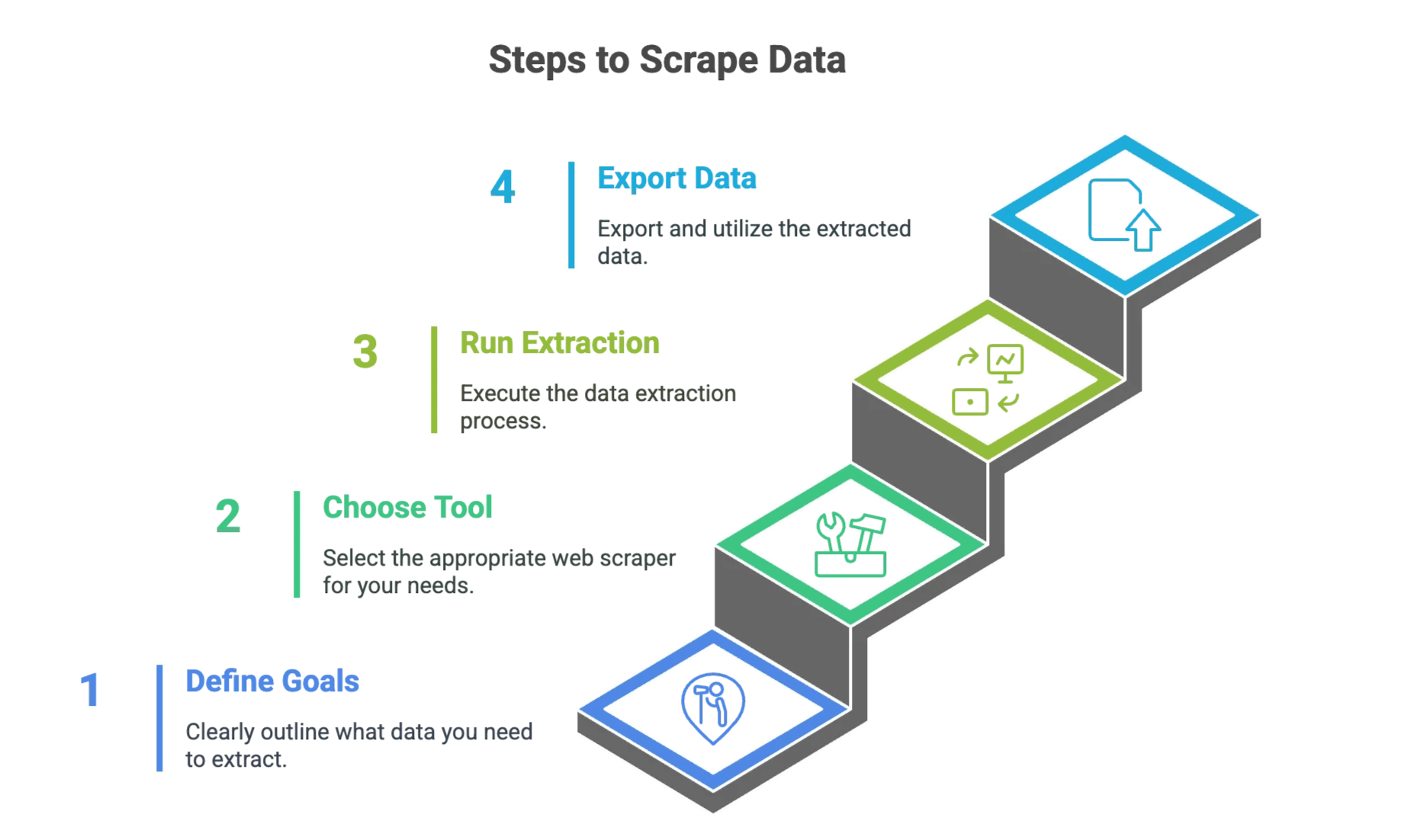
Passo 1: definisci i tuoi obiettivi di estrazione dati
Prima di iniziare, chiarisci bene di cosa hai bisogno. Chiediti:
- Da quale sito o siti voglio estrarre i dati?
- Quali campi sono importanti? (ad esempio nome prodotto, prezzo, email, telefono)
- Con quale frequenza mi servono questi dati? (una tantum o ricorrenti?)
Fai una checklist. Per esempio: “Voglio raccogliere nome prodotto, prezzo e valutazioni dalle prime 5 pagine di XYZ.com.”
Passo 2: scegli lo strumento di Web Scraper giusto
Ecco un rapido percorso decisionale:
- Ti senti a tuo agio con il codice e vuoi il massimo controllo? Prova uno strumento tradizionale come BeautifulSoup o Scrapy.
- Vuoi velocità, semplicità e niente codice? Scegli un AI web scraper come Thunderbit.
Se non sei sicuro, inizia con l’AI. Potrai sempre approfondire più avanti.
Passo 3: configura ed esegui la tua estrazione dati
Approccio tradizionale
- Installa lo strumento: configura Python e le librerie necessarie.
- Ispeziona il sito: usa DevTools del browser per individuare la struttura HTML.
- Scrivi lo script: definisci come trovare ed estrarre ogni campo di dati.
- Prova su una pagina: verifica di ottenere i dati giusti.
- Scala l’estrazione: aggiungi paginazione o cicli per coprire più pagine.
- Esporta i dati: salva in CSV o JSON.
Approccio AI (Thunderbit)
- Installa l’estensione Chrome di Thunderbit: Scaricala qui.
- Apri il sito target: vai alla pagina che vuoi estrarre.
- Clicca “AI Suggerisci campi”: Thunderbit leggerà la pagina e proporrà le colonne.
- Controlla l’anteprima: verifica che i dati siano corretti. Se serve, modifica le colonne.
- Clicca “Estrai”: Thunderbit raccoglie i dati per te.
- Esporta i dati: scarica in Excel, Google Sheets, Airtable o Notion.
Per una guida visiva, dai un’occhiata al nostro canale YouTube di Thunderbit.
Estrai dati dei siti web con Thunderbit
Passo 4: esporta e usa i tuoi dati
Una volta ottenuti i dati:
- Esportali nel tuo strumento preferito: Excel, Google Sheets, Airtable, Notion, CSV o JSON.
- Integrali nel tuo flusso di lavoro: usali per outreach commerciale, analisi dei prezzi, ricerche di mercato o qualunque altra esigenza aziendale.
- Pulisci e valida: anche con l’AI, è intelligente controllare a campione l’accuratezza dei dati.
Consigli per un’estrazione dati efficace: evitare gli errori più comuni
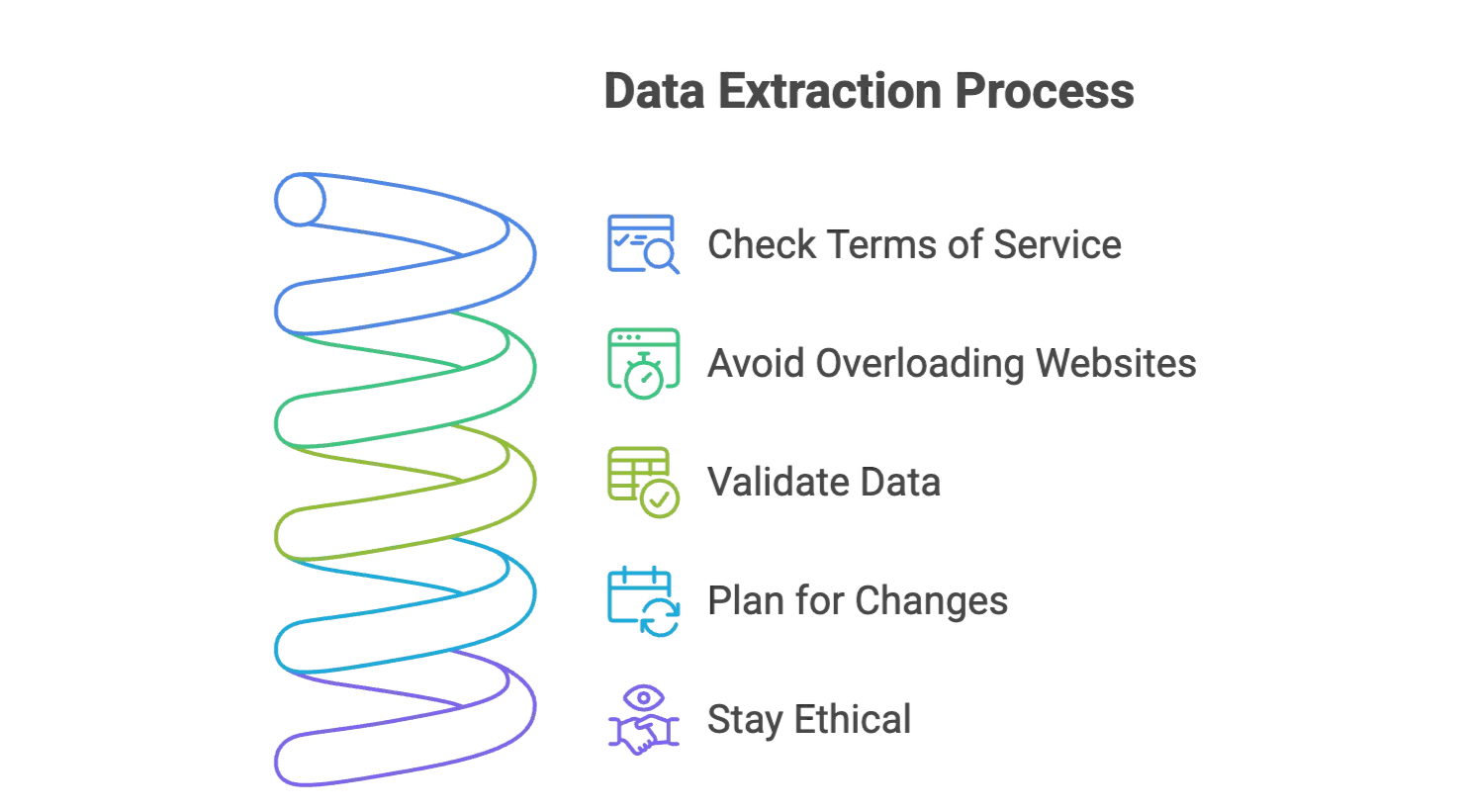
- Controlla i termini di servizio del sito: assicurati di poter estrarre quei dati. Attieniti alle informazioni pubbliche ed evita i dati personali sensibili.
- Non sovraccaricare i siti: inserisci ritardi tra le richieste (con gli strumenti tradizionali) oppure lascia che Thunderbit li gestisca per te.
- Valida i dati: controlla sempre un campione dei risultati per verificarne l’accuratezza.
- Prevedi i cambiamenti: i siti si aggiornano continuamente. Gli AI scraper come Thunderbit si adattano automaticamente, ma è comunque bene monitorare eventuali grandi cambiamenti.
- Mantieni un approccio etico: estrai solo ciò che ti serve e cita la fonte se usi i dati in report o pubblicazioni.
Per altri consigli, consulta Che cos’è il data scraping e come farlo nel 2025 e Come estrarre qualsiasi sito web usando l’AI.
Conclusione e punti chiave
Il web scraping ha fatto molta strada—dai tempi degli script scritti a mano agli strumenti di oggi basati sull’AI e adatti ai principianti. Le differenze principali?

- Gli Estrattori Web tradizionali offrono controllo, ma richiedono codice, manutenzione e pazienza.
- Gli AI web scraper come Thunderbit rendono l’estrazione dei dati accessibile a tutti, con comandi in linguaggio naturale, anteprime istantanee e funzioni robuste come lo scraping delle sottopagine e quello pianificato.
Se sei alle prime armi con il web scraping, non farti intimidire. Oggi gli strumenti non sono mai stati così semplici da usare, e il valore per il business è indiscutibile. Che tu voglia generare lead, monitorare i prezzi o semplicemente smettere di copiare e incollare, gli AI web scraper sono il tuo nuovo migliore amico.
Quindi, la prossima volta che ti ritrovi davanti a una montagna di dati web, ricorda: non ti serve un dottorato in informatica—né tantomeno un cappuccio. Ti serve solo un obiettivo chiaro, lo strumento giusto e magari una buona tazza di caffè.
Pronto a provarlo? Installa Thunderbit e scopri quanto può essere semplice l’estrazione dei dati dal web.
Vuoi saperne di più? Dai un’occhiata al blog di Thunderbit per approfondimenti su scraping di Amazon, Google, PDF e molto altro. Buon scraping!
Prova subito Thunderbit AI Web Scraper Get Started Free
FAQ
Q1: Il web scraping è legale? A: Sì, in molti paesi l’estrazione di dati pubblici è generalmente legale. Tuttavia, controlla sempre i termini di servizio del sito ed evita di estrarre dati sensibili o personali.
Q2: Posso estrarre dati da siti che richiedono il login? A: Sì, ma è più complesso e potrebbe violare le policy del sito. Servono la gestione delle sessioni o strumenti di scraping autenticato, ed è importante valutare le implicazioni legali.
Q3: Come posso estrarre dati da siti web molto pesanti in JavaScript? A: Usa strumenti che supportano il rendering dinamico, come browser headless o scraper AI che simulano le interazioni umane e analizzano i contenuti renderizzati da JavaScript.
Q4: Quali sono le buone pratiche per evitare blocchi? A: Usa il rate limiting, ritardi casuali, la rotazione degli user agent ed evita di fare scraping in modo aggressivo. Gli scraper basati sull’AI spesso gestiscono queste strategie automaticamente.
Leggi di più
-
Comprendere la legalità del web scraping: approfondimenti e statistiche globali Panoramica delle linee guida legali, statistiche di settore e buone pratiche etiche.
-
Rapporto sullo stato del web scraping 2025 Trend, crescita del mercato e ruolo dell’AI nell’estrazione di dati dal web (2024–2025).
-
Che cos’è un file robots.txt? Guida alle buone pratiche e alla sintassi Scopri come interpretare i file robots.txt per guidare uno scraping etico e legale.




