

Immagina la scena: davanti a te c’è un sito pieno zeppo di prodotti e il tuo capo (o la tua anima da smanettone dei dati) vuole tutti quei prezzi, nomi e recensioni in un file Excel... per ieri. Potresti passare ore a copiare e incollare, oppure lasciare che Python faccia il lavoro sporco per te. Qui entra in gioco l’estrazione dati dal web, e credimi: non è roba solo da nerd con la felpa o da ingegneri della Silicon Valley. Oggi, il web scraping è una skill fondamentale per chi lavora in ambito commerciale, immobiliare o nella ricerca di mercato. Il mercato globale dei software per l’estrazione dati dal web vale già più di $1 miliardo e si prevede che raddoppierà entro il 2032. Un mare di dati... e di opportunità.
Da co-fondatore di Thunderbit, da anni aiuto aziende a rendere la raccolta dati una passeggiata. Prima che strumenti AI come Thunderbit rendessero l’estrazione web un gioco da ragazzi, ho imparato le basi con il classico trio Python: BeautifulSoup, requests e tanta pazienza. In questa guida ti spiego cos’è BeautifulSoup, come si installa e si usa, e perché è ancora uno strumento di riferimento. Poi ti mostro come soluzioni AI come Thunderbit stanno rivoluzionando il settore (e risparmiando un sacco di grattacapi). Che tu sia alle prime armi con Python, un utente business o solo curioso, partiamo insieme.
Cos’è BeautifulSoup? Introduzione al Web Scraping con Python
Partiamo dalle fondamenta. BeautifulSoup (spesso chiamata BS4) è una libreria Python che ti permette di estrarre dati da file HTML e XML. Pensa a lei come a un detective dell’HTML: le dai una pagina web incasinata e lei la trasforma in una struttura ordinata e facile da esplorare. Così, recuperare il nome di un prodotto, un prezzo o una recensione diventa semplice come chiedere il tag o la classe giusta.
BeautifulSoup non scarica le pagine web da sola (per quello serve una libreria come requests), ma una volta che hai l’HTML, cercare, filtrare ed estrarre i dati che ti servono è davvero una passeggiata. Non a caso, in un recente sondaggio, oltre il 43% degli sviluppatori ha scelto BeautifulSoup come strumento preferito per il web scraping—più di qualsiasi altra libreria.
BeautifulSoup viene usata per tutto: dalla ricerca accademica alle analisi e-commerce, fino alla generazione di lead. Ho visto team marketing creare liste di influencer, recruiter estrarre offerte di lavoro e persino giornalisti automatizzare le loro indagini. È flessibile, tollerante agli errori e—se mastichi un po’ di Python—abbastanza accessibile.
Perché Usare BeautifulSoup? Vantaggi e Applicazioni Pratiche
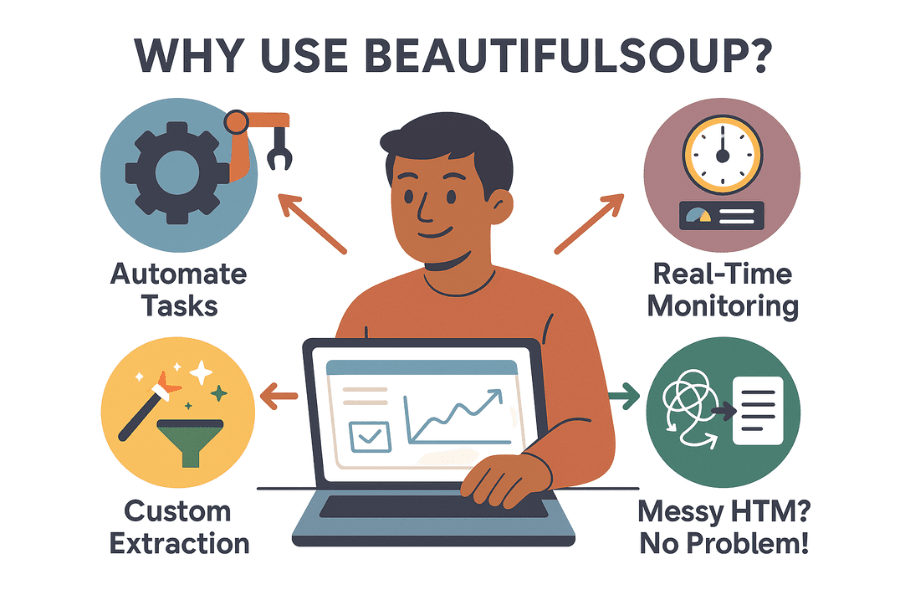
Perché così tante aziende e appassionati di dati scelgono BeautifulSoup? Ecco cosa la rende un must nel mondo dell’estrazione dati:
- Automatizza le attività ripetitive: Perché perdere tempo a copiare e incollare quando puoi lasciare tutto a uno script? BeautifulSoup può raccogliere migliaia di dati in pochi minuti, liberando il tuo team per attività più strategiche.
- Monitoraggio in tempo reale: Puoi programmare script che tengono d’occhio prezzi dei concorrenti, disponibilità o notizie. Niente più sorprese: se un rivale abbassa i prezzi, lo scopri prima del caffè.
- Estrazione dati su misura: Vuoi i 10 prodotti più di tendenza, con valutazioni e recensioni? BeautifulSoup ti dà il pieno controllo su cosa raccogli e come lo gestisci.
- Gestisce HTML disordinato: Anche se il codice di un sito è un casino, BeautifulSoup di solito riesce a interpretarlo senza problemi.
Ecco qualche esempio concreto:
| Caso d'Uso | Descrizione | Risultato |
|---|---|---|
| Generazione Lead | Estrai email e numeri da directory aziendali o LinkedIn | Crea liste di vendita mirate |
| Monitoraggio Prezzi | Tieni traccia dei prezzi dei concorrenti su siti e-commerce | Aggiorna i tuoi prezzi in tempo reale |
| Ricerca di Mercato | Raccogli recensioni, valutazioni o dettagli prodotto dagli store online | Individua trend e guida lo sviluppo prodotto |
| Dati Immobiliari | Aggrega annunci da siti come Zillow o Realtor.com | Analizza trend di prezzo o opportunità di investimento |
| Aggregazione Contenuti | Raccogli articoli, post o menzioni social | Alimenta newsletter o analisi di sentiment |
E il ritorno sull’investimento? Un retailer inglese ha usato il web scraping per monitorare i concorrenti e ha aumentato le vendite del 4%. ASOS ha raddoppiato le vendite internazionali adattando il marketing ai prezzi locali estratti. In breve: i dati raccolti guidano decisioni di business reali.
Come Iniziare: Installare BeautifulSoup in Python
Pronto a sporcarti le mani? Ecco come installare e configurare BeautifulSoup:
Passo 1: Installa BeautifulSoup (nel modo giusto)
Assicurati di installare la versione più recente—BeautifulSoup 4 (bs4). Occhio a non confonderti con il vecchio nome del pacchetto!
pip install beautifulsoup4
Se usi macOS o Linux, potresti dover usare pip3 o aggiungere sudo:
sudo pip3 install beautifulsoup4
Tip: Se lanci pip install beautifulsoup (senza il “4”), installerai la vecchia versione non compatibile. Parola di chi ci è cascato!
Passo 2: Installa un Parser (opzionale ma consigliato)
BeautifulSoup può usare il parser HTML integrato di Python, ma per prestazioni migliori conviene installare anche lxml e html5lib:
pip install lxml html5lib
Passo 3: Installa Requests (per scaricare le pagine web)
BeautifulSoup analizza l’HTML, ma prima devi scaricarlo. La libreria requests è la scelta più gettonata:
pip install requests
Passo 4: Controlla l’Ambiente Python
Assicurati di usare Python 3. Se lavori in un IDE (PyCharm, VS Code), controlla l’interprete. Se hai errori di import, potresti aver installato i pacchetti nell’ambiente sbagliato. Su Windows, py -m pip install beautifulsoup4 aiuta a indirizzare la versione giusta.
Passo 5: Testa la Configurazione
Fai una prova veloce:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Se vedi stampato il tag <title>, sei pronto a partire.
BeautifulSoup: Concetti Chiave e Sintassi Essenziale
Vediamo gli oggetti e i concetti principali che userai con BeautifulSoup:
- Oggetto BeautifulSoup: È la radice dell’albero HTML analizzato. Si crea con
BeautifulSoup(html, parser). - Tag: Rappresenta un tag HTML o XML (come
<div>,<p>,<span>). Puoi accedere ad attributi, figli e testo. - NavigableString: È il testo contenuto in un tag.
Capire la Parse Tree
Immagina l’HTML come un albero genealogico: il tag <html> è il capostipite, <head> e <body> sono i figli, e così via. BeautifulSoup ti permette di navigare questa struttura con una sintassi semplice.
Esempio:
html = """
<html>
<head><title>My Test Page</title></head>
<body>
<p class="story">Once upon a time <b>there were three little sisters</b>...</p>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
# Accedi al tag title
print(soup.title) # <title>My Test Page</title>
print(soup.title.string) # My Test Page
# Accedi al primo tag <p> e alla sua classe
p_tag = soup.find('p', class_='story')
print(p_tag['class']) # ['story']
# Ottieni tutto il testo dentro il tag <p>
print(p_tag.get_text()) # Once upon a time there were three little sisters...
Navigazione e Ricerca
- Accesso agli elementi:
soup.head,soup.body,tag.parent,tag.children - find() / find_all(): Cerca tag per nome o attributi.
- select(): Usa i selettori CSS per ricerche più complesse.
Esempio:
# Trova tutti i link
for link in soup.find_all('a'):
print(link.get('href'))
# Esempio con selettore CSS
for item in soup.select('div.product > span.price'):
print(item.get_text())
Pratica: Crea il Tuo Primo Estrattore Web con BeautifulSoup
Passiamo alla pratica. Supponiamo di voler estrarre titoli e prezzi dei prodotti da una pagina di risultati e-commerce (ad esempio Etsy). Ecco come si fa:
Passo 1: Scarica la Pagina Web
import requests
from bs4 import BeautifulSoup
url = "https://www.etsy.com/search?q=clothes"
headers = {"User-Agent": "Mozilla/5.0"} # Alcuni siti richiedono uno user-agent
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'html.parser')
Passo 2: Analizza ed Estrai i Dati
Supponiamo che ogni prodotto sia in un blocco <li class="wt-list-unstyled">, con il titolo in <h3 class="v2-listing-card__title"> e il prezzo in <span class="currency-value">.
items = []
for item in soup.find_all('li', class_='wt-list-unstyled'):
title_tag = item.find('h3', class_='v2-listing-card__title')
price_tag = item.find('span', class_='currency-value')
if title_tag and price_tag:
title = title_tag.get_text(strip=True)
price = price_tag.get_text(strip=True)
items.append((title, price))
Passo 3: Salva in CSV o Excel
Con il modulo csv di Python:
import csv
with open("etsy_products.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["Titolo Prodotto", "Prezzo"])
writer.writerows(items)
Oppure, con pandas:
import pandas as pd
df = pd.DataFrame(items, columns=["Titolo Prodotto", "Prezzo"])
df.to_csv("etsy_products.csv", index=False)
Ora hai un file pronto per analisi, report o semplicemente per fare bella figura con i colleghi.
Limiti di BeautifulSoup: Manutenzione, Anti-Bot e Altri Ostacoli
Qui arriva la parte sincera: per quanto BeautifulSoup sia potente, ha anche qualche limite—soprattutto se vuoi scalare o lavorare su tanti siti.
1. Fragilità ai Cambi di Sito
I siti web cambiano spesso layout, nomi delle classi o l’ordine degli elementi. Il tuo script BeautifulSoup? Funziona solo finché i selettori sono giusti. Se il sito cambia HTML, lo script può smettere di funzionare—magari senza nemmeno avvisarti. Se estrai dati da decine (o centinaia) di siti, aggiornare tutto può diventare un incubo.
2. Difese Anti-Scraping
I siti moderni usano ogni tipo di protezione: CAPTCHA, blocchi IP, limiti di frequenza, contenuti caricati via JavaScript e altro ancora. BeautifulSoup da sola non può gestirli. Servono proxy, browser headless o persino servizi esterni per risolvere i CAPTCHA. È una lotta continua con gli amministratori dei siti.
3. Scalabilità e Prestazioni
BeautifulSoup è perfetta per script singoli o raccolte dati moderate. Ma se devi estrarre milioni di pagine o lavorare in parallelo, dovrai scrivere codice extra per gestire concorrenza, errori e infrastruttura. Si può fare, ma richiede tempo.
4. Barriera Tecnica
Diciamolo: se non hai confidenza con Python, HTML e debugging, BeautifulSoup può sembrare ostica. Anche per chi è esperto, spesso si tratta di ispezionare, scrivere codice, testare, correggere e ripetere.
5. Aspetti Legali ed Etici
L’estrazione dati può entrare in zone grigie dal punto di vista legale, soprattutto se ignori robots.txt o i termini d’uso. Con il codice, la responsabilità di rispettare le regole è tua: limita le richieste, rispetta le policy e tratta i dati in modo etico.
Oltre BeautifulSoup: Come gli Strumenti AI come Thunderbit Semplificano il Web Scraping
Estrai dati da qualsiasi sito con l’AI Get Started Free
Qui arriva la vera svolta. Con l’arrivo dell’AI, strumenti come Thunderbit rendono l’estrazione dati accessibile a tutti, non solo agli sviluppatori.
Thunderbit è un’estensione Chrome con AI che ti permette di estrarre dati da qualsiasi sito in due click. Niente Python, niente selettori, niente manutenzione. Basta aprire la pagina, cliccare su “AI Suggerisci Campi” e l’AI di Thunderbit individua automaticamente i dati più utili (nomi prodotti, prezzi, recensioni, email, numeri di telefono, ecc.). Poi clicchi su “Estrai” e il gioco è fatto.
Thunderbit vs. BeautifulSoup: Confronto Diretto
| Funzionalità | BeautifulSoup (con codice) | Thunderbit (AI senza codice) |
|---|---|---|
| Difficoltà di Setup | Richiede conoscenze Python, HTML e debugging | Nessun codice—AI rileva i campi, interfaccia intuitiva |
| Velocità di Estrazione | Ore (tra scrittura e test del codice) | Minuti (2–3 click) |
| Adattabilità ai Cambi | Si rompe se l’HTML cambia; serve aggiornare a mano | L’AI si adatta a molti cambi; template aggiornati per i siti più usati |
| Paginazione/Sottopagine | Loop manuali e richieste per ogni pagina | Paginazione e sottopagine integrate—basta attivare un’opzione |
| Gestione Anti-Bot | Devi aggiungere proxy, gestire CAPTCHA, simulare browser | Molte difese anti-bot gestite internamente; il browser aiuta a evitare blocchi |
| Elaborazione Dati | Controllo totale via codice, ma devi scriverlo tu | AI integrata per riassumere, categorizzare, tradurre e pulire i dati |
| Esportazione | Codice personalizzato per CSV, Excel, database, ecc. | Esportazione con un click su CSV, Excel, Google Sheets, Airtable, Notion |
| Scalabilità | Illimitata se costruisci l’infrastruttura; ma gestisci errori e scaling | Alta—cloud/estensione gestisce carichi paralleli, pianificazione e grandi volumi (limiti in base al piano/crediti) |
| Costo | Gratis (open-source), ma richiede tempo e manutenzione | Freemium (gratis per piccoli lavori, piani a pagamento per grandi volumi), ma risparmia tantissimo tempo |
| Flessibilità | Massima—puoi fare tutto via codice, se sei disposto a scriverlo | Copre la maggior parte dei casi d’uso standard; per casi particolari serve codice |
Per approfondire, dai un’occhiata al blog di Thunderbit e alla documentazione delle funzionalità.
Passo dopo Passo: Estrarre Dati con Thunderbit vs. BeautifulSoup
Confrontiamo i flussi di lavoro per estrarre dati prodotto da un sito e-commerce.
Con BeautifulSoup
- Analizza la struttura HTML del sito con gli strumenti per sviluppatori del browser.
- Scrivi codice Python per scaricare la pagina (
requests), analizzarla (BeautifulSoup) ed estrarre i campi desiderati. - Affina i selettori (classi, percorsi tag) finché non ottieni i dati giusti.
- Gestisci la paginazione scrivendo loop per seguire i link “Successivo”.
- Esporta i dati in CSV o Excel con altro codice.
- Se il sito cambia, ripeti i passaggi da 1 a 5.
Tempo richiesto: 1–2 ore per un sito nuovo (di più se incontri blocchi anti-bot).
Con Thunderbit
- Apri il sito target in Chrome.
- Clicca sull’estensione Thunderbit.
- Clicca su “AI Suggerisci Campi”—l’AI propone colonne come Nome Prodotto, Prezzo, ecc.
- Modifica le colonne se necessario, poi clicca su “Estrai”.
- Attiva la paginazione o l’estrazione da sottopagine con un’opzione, se serve.
- Visualizza l’anteprima dei dati in tabella ed esporta nel formato che preferisci.
Tempo richiesto: 2–5 minuti. Niente codice, niente debugging, niente manutenzione.
In più: Thunderbit può anche estrarre email, numeri di telefono, immagini e persino compilare moduli in automatico. È come avere un assistente super veloce che non si lamenta mai dei lavori ripetitivi.
Prova gratis Thunderbit Estrattore Web AI
Conclusioni & Cosa Portarsi a Casa
Cos’è il Data Scraping e come farlo nel 2025 Get Started Free
L’estrazione dati dal web è passata da trucco da hacker a strumento essenziale per il business, dalla generazione lead alla ricerca di mercato. BeautifulSoup resta un ottimo punto di partenza per chi conosce un po’ di Python, offrendo flessibilità e controllo per progetti su misura. Ma con siti sempre più complessi e utenti business che vogliono risultati rapidi e senza codice, strumenti AI come Thunderbit stanno cambiando le regole del gioco.

Se ti piace smanettare con il codice e vuoi soluzioni su misura, BeautifulSoup è ancora la scelta migliore. Ma se vuoi evitare la programmazione, la manutenzione e ottenere risultati in pochi minuti, Thunderbit è la strada giusta. Perché passare ore a scrivere codice quando puoi risolvere tutto con l’AI?
Vuoi provarlo? Scarica l’estensione Chrome di Thunderbit, oppure scopri altri tutorial sul blog di Thunderbit. E se vuoi continuare a sperimentare con Python, divertiti con BeautifulSoup—ma ricordati di fare stretching alle mani dopo tutto quel codice!
Buona estrazione dati!
Prova Thunderbit Estrattore Web AI Get Started Free
Per Approfondire:
- Documentazione ufficiale Beautiful Soup
- Cos’è il Data Scraping e come farlo nel 2025
- Come estrarre dati da siti web in Excel con l’AI
- Canale YouTube di Thunderbit
Hai domande, esperienze o vuoi raccontare le tue avventure di scraping? Lascia un commento qui sotto o scrivici. Probabilmente ho rotto più estrattori di quanti ne abbia mai scritti la maggior parte delle persone.




