
Ogni AI web scraper sembra fantastico nella sua demo di prodotto. Poi lo punti su un sito reale protetto da Cloudflare e ti restituisce una pagina di verifica, sostenendo con sicurezza di aver trovato 47 schede prodotto.
Negli ultimi mesi ho valutato vari strumenti di scraping per il nostro team in Thunderbit. Il divario tra le prestazioni in demo e l’affidabilità in produzione è, con costanza, la principale fonte di frustrazione che vedo nelle community. Un utente di Reddit lo ha riassunto alla perfezione: Con nella sola categoria web scraping, più decine di estensioni Chrome, fornitori API e marketplace di actor, il paradosso della scelta è reale. Così ne ho testati 12.
Questo articolo valuta 12 strumenti AI web scraper in base a criteri di produzione: gestione anti-bot, scalabilità, qualità dell’output strutturato, efficienza dei costi, supporto per siti dinamici e flessibilità per gli sviluppatori. Niente checklist di funzionalità. Niente screenshot di marketing. Solo ciò che funziona davvero quando la demo è finita.
Perché la maggior parte degli AI Web Scraper fallisce oltre la demo
Il copione è sempre lo stesso. Il sito di marketing di uno strumento mostra l’estrazione di colonne pulite da una semplice pagina di elenco prodotti. Lo installi, lo provi su un sito e-commerce protetto e ottieni uno di questi risultati:
- Una risposta
200 OKche contiene una pagina di sfida Cloudflare invece dei dati reali - Risultati puliti per le prime 5 pagine, poi errori silenziosi o righe inventate
- Estrazione perfetta oggi, selettori rotti la settimana dopo per un piccolo aggiornamento del layout
Non si tratta di casi limite. È la normalità.
Come ha : "Lo scraper restituisce un 200 con una pagina di sfida Cloudflare, il tuo agent prova a ragionarci sopra, inventa dati e non hai idea del perché."
Il problema di fondo è architetturale. La maggior parte delle demo mostra il livello di parsing su pagine pubbliche pulite, mentre il lavoro reale fallisce nel livello di fetching. I siti in produzione aggiungono protezione bot, rendering dinamico, pagine di dettaglio nidificate, scroll infinito, stato di login, varianti locali e layout che cambiano.
Uno strumento può sembrare ottimo in una demo e crollare comunque al primo flusso di lavoro serio di un cliente.
Per questo questo articolo valuta ogni strumento con un’ottica di prontezza alla produzione, invece che con una semplice checklist di funzionalità. I sei criteri che ho usato:
| Criterio | Perché conta |
|---|---|
| Gestione anti-bot/CAPTCHA | I siti protetti falliscono prima ancora che la qualità dell’estrazione conti |
| Scalabilità oltre la demo | I job in batch e le esecuzioni parallele rivelano i limiti operativi |
| Qualità dell’output strutturato | Servono JSON/CSV puliti, non HTML grezzo da ripulire a mano |
| Efficienza di token/costi | L’estrazione AI può costare più dello scraping stesso |
| Supporto per siti dinamici e pesanti in JS | Le pagine moderne richiedono DOM renderizzati, non HTML statico |
| Flessibilità no-code vs API | Team commerciali e data engineer hanno esigenze diverse |
Se vuoi una panoramica rapida del mercato su come è cambiato il web scraping negli ultimi due anni, questo intervento di Browserless è un buon contesto prima di confrontare gli strumenti uno per uno.
Dove l’AI aiuta davvero in una pipeline di scraping (e dove no)
Un mito ancora molto diffuso in questo mercato è che "AI web scraper" significhi che l’AI gestisce tutto dall’inizio alla fine. Il consenso della community è sorprendentemente chiaro: . Il commento diretto di un utente: "Usi l’AI per leggere uno screenshot di una pagina web. Non usi l’AI per scrivere lo scraper stesso."
La pipeline di scraping ha tre livelli distinti e il valore dell’AI cambia molto da uno all’altro:
Crawling e Fetching: il livello infrastrutturale
Qui avvengono le richieste: proxy, browser headless, gestione delle sessioni, risoluzione dei CAPTCHA, retry. L’AI qui fa quasi nulla di utile. Servono comunque pool di proxy, fingerprint del browser e infrastruttura di sblocco. È qui che la maggior parte degli strumenti fallisce per prima in produzione.
Parsing ed Estrazione: dove l’AI dà il meglio
Una volta ottenuto un contenuto pulito della pagina, l’AI eccelle nel trasformare HTML non strutturato in campi strutturati. Estrazione basata su schema, rilevamento adattivo dei campi e gestione delle variazioni di layout senza selettori XPath fragili sono il punto forte dell’AI nello scraping.
Post-elaborazione: etichettare, tradurre, categorizzare
Dopo l’estrazione, l’AI aggiunge valore classificando i prodotti, traducendo il testo, normalizzando i numeri di telefono o riassumendo le descrizioni. È un’ottima applicazione, ma solo se i dati estratti sono già corretti.
Ecco come i 12 strumenti si distribuiscono tra questi livelli:
| Strumento | Crawling/Fetching | Parsing/Estrazione | Post-elaborazione | Descrizione migliore |
|---|---|---|---|---|
| Thunderbit | Forte | Forte | Forte | Scraper AI no-code full-stack |
| Octoparse | Forte | Medio | Basso | Scraper visuale basato su regole con infrastruttura cloud |
| Browse AI | Medio | Medio | Medio | Piattaforma cloud prima di tutto per il monitoraggio |
| Firecrawl | Medio | Forte | Basso-Medio | API di estrazione per sviluppatori |
| Apify | Forte | Medio-Forte | Medio | Marketplace di actor e orchestrazione |
| Gumloop | Medio | Medio | Forte | Automazione dei workflow con nodi scraper |
| Bright Data | Molto forte | Medio | Basso-Medio | Stack infrastrutturale enterprise |
| Bardeen | Medio | Medio | Forte | Automazione browser per workflow GTM |
| Diffbot | Basso-Medio | Molto forte | Medio | Estrazione preaddestrata con knowledge graph |
| ScrapingBee | Forte | Basso-Medio | Basso | API per fetching e sblocco |
| Instant Data Scraper | Basso | Medio (pagine semplici) | Basso | Scraper rapido euristico lato browser |
| ParseHub | Medio | Medio | Basso | Scraper visuale desktop per interazioni complesse |
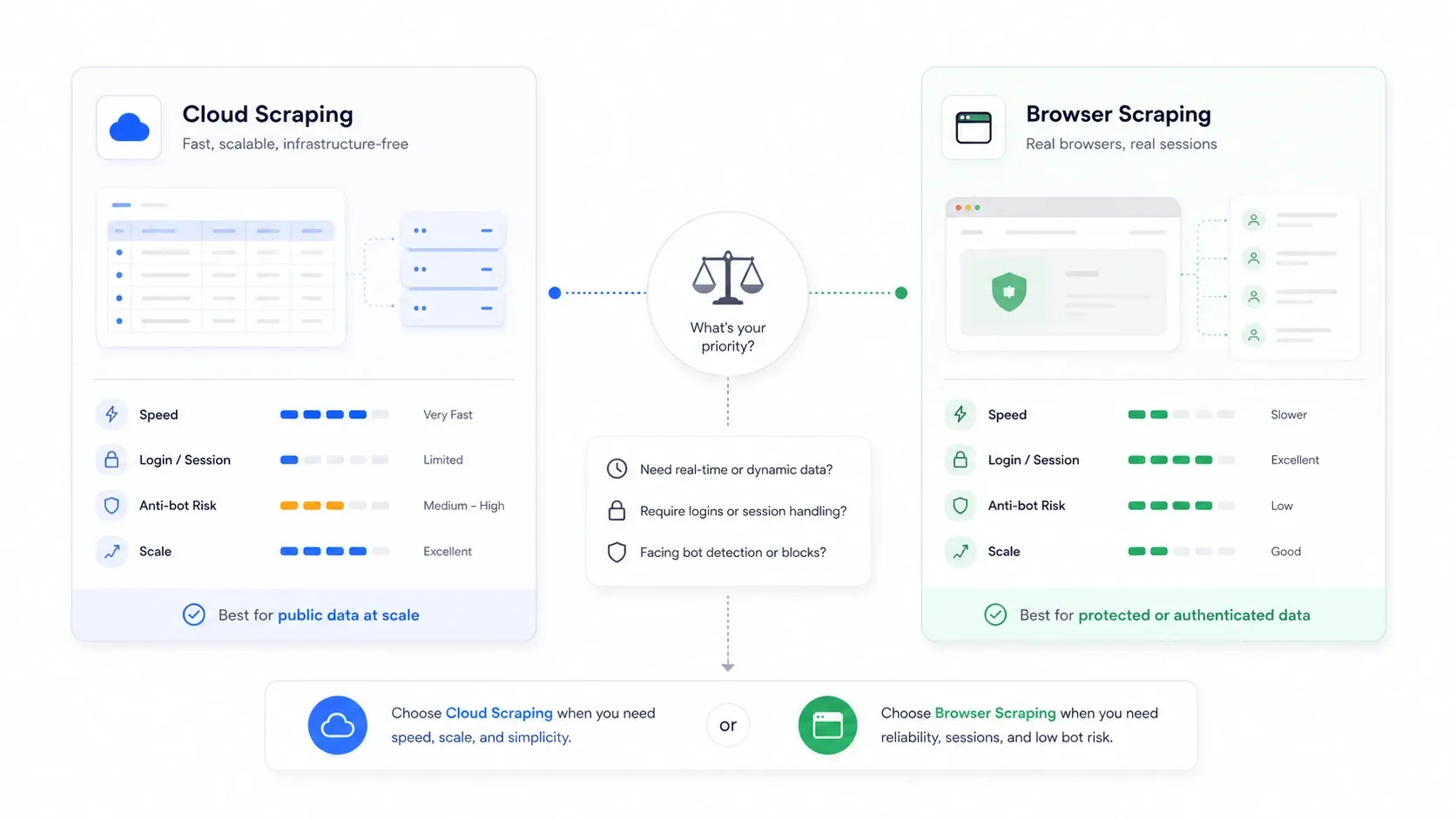
Scraping cloud vs scraping browser: la scelta che nessuno spiega
Questa è la decisione architetturale che la maggior parte degli articoli riassuntivi ignora del tutto, e spesso conta più dello strumento che scegli.
Scraping cloud significa che server remoti recuperano le pagine per conto tuo. Scraping browser significa che l’estrazione avviene nella tua sessione del browser, usando i tuoi cookie, il tuo IP e il tuo stato autenticato.
| Scenario | Modalità migliore | Perché |
|---|---|---|
| Siti e-commerce e directory pubbliche ad alto volume | Cloud | Più parallelismo e nessun collo di bottiglia sul computer locale |
| Siti che richiedono login o autenticazione | Browser | Riutilizza i cookie reali della tua sessione |
| Siti che penalizzano gli IP dei data center | Browser | Sembra traffico normale di un utente |
| Job di monitoraggio ricorrenti di grandi dimensioni | Cloud | Pianificazione e continuità più semplici |
| Job una tantum, fragili e sensibili all’anti-bot | Browser | Più facile vedere cosa ha davvero renderizzato il sito |
Anche economicamente è rilevante. Il report State of Web Scraping 2026 di Apify ha rilevato che il anno su anno, e ha dichiarato spese infrastrutturali più alte. L’anti-bot non è solo un problema tecnico. È un problema di budget.
La maggior parte degli strumenti offre solo una modalità. Ecco la ripartizione:
| Strumento | Cloud | Browser | Entrambi |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (locale) | ✅ |
| Browse AI | ✅ | Solo configurazione | — |
| Firecrawl | ✅ | API per interattivo | — |
| Apify | ✅ | ✅ (tramite actor) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Limitato (pagine pubbliche) | ✅ | Parziale |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (a pagamento) | ✅ (desktop) | ✅ |
I 12 AI Web Scraper in sintesi
Ecco il confronto principale tra tutti e 12 gli strumenti:
| Strumento | Ideale per | Livello gratuito | Cloud/Browser | Accesso API | Scraping pianificato | Gestione anti-bot |
|---|---|---|---|---|---|---|
| Thunderbit | Team non tecnici | ✅ (6 pagine) | Entrambi | ✅ | ✅ | Forte |
| Octoparse | Scraping con molti template | ✅ (limitato) | Entrambi | ✅ | ✅ | Moderata-Forte |
| Browse AI | Monitoraggio dei cambiamenti | ✅ (limitato) | Principalmente cloud | ✅ | ✅ | Moderata |
| Firecrawl | Pipeline di estrazione per sviluppatori | ✅ (1.000 crediti/mese) | Cloud più API browser | ✅ | No | Moderata |
| Apify | Team di sviluppo più marketplace | ✅ (5 $ di uso gratuito) | Entrambi | ✅ | ✅ | Forte con add-on |
| Gumloop | Automazione dei workflow | ✅ (5.000 crediti/mese) | Entrambi | ✅ | ✅ | Media |
| Bright Data | Accesso ai dati enterprise | Prova / crediti | Entrambi | ✅ | Esterno | Molto forte |
| Bardeen | Automazione browser per vendite e operations | ✅ (100 crediti) | Browser-first | Limitato | ✅ | Medio-bassa |
| Diffbot | API di estrazione strutturata | ✅ (10.000 crediti) | Cloud | ✅ | No | Bassa nel fetching / alta nell’estrazione |
| ScrapingBee | Fetching e sblocco per sviluppatori | ✅ (1.000 crediti) | Cloud | ✅ | No | Forte |
| Instant Data Scraper | Scraping gratuito una tantum | ✅ (completamente gratuito) | Solo browser | No | No | Bassa |
| ParseHub | Workflow visivi complessi | ✅ (5 progetti) | Desktop più cloud | ✅ | ✅ (a pagamento) | Media |
1. Thunderbit
è l’AI web scraper che abbiamo costruito appositamente per team non tecnici che hanno bisogno di dati di livello produzione senza scrivere codice né gestire infrastruttura. Il flusso di base è davvero in due clic: AI Suggest Fields legge la pagina e propone le colonne, poi Scrape esegue l’estrazione in modalità cloud o browser.
Ciò che lo distingue dagli altri scraper no-code è l’architettura. Thunderbit separa le esigenze di crawling, come infrastruttura cloud, rotazione dei proxy, gestione anti-bot e rendering JavaScript, dall’estrazione AI che legge l’HTML e restituisce colonne strutturate. Questo rispecchia il pattern consigliato dagli esperti, "scraper prima, LLM dopo", ma in un workflow di estensione Chrome che rappresentanti commerciali e responsabili operations possono davvero usare.
Punti di forza principali
- Scraping cloud e browser insieme in un’unica interfaccia. Puoi passare da una modalità all’altra a seconda che il sito sia pubblico o richieda una sessione autenticata. In modalità cloud gestisce fino a 50 pagine in parallelo.
- L’AI rilegge ogni volta la struttura della pagina. Nessuna manutenzione di XPath. Quando un sito aggiorna il layout, Thunderbit si adatta automaticamente alla corsa successiva.
- Scraping delle sottopagine. L’AI visita le pagine di dettaglio collegate e arricchisce la tabella principale senza configurazioni manuali.
- Prompt AI per campo. Etichettatura, traduzione e categorizzazione personalizzate durante l’estrazione, invece che come passaggio separato di post-elaborazione.
- Esportazioni gratuite verso Google Sheets, Excel, Airtable e Notion.
- Template scraper istantanei per siti popolari come Amazon, Zillow e LinkedIn.
- Pianificazione in linguaggio naturale. Basta dire "esegui lo scraping ogni lunedì alle 9" e il sistema lo converte in una pianificazione ricorrente.
- API aperta con endpoint Distill ed Extract, elaborazione batch fino a 100 URL e concorrenza pubblicata da 2 nella versione gratuita fino a 50 in Pro 1.
Dove può migliorare
- Il piano gratuito è volutamente limitato.
- L’esperienza no-code è fortemente centrata sull’estensione Chrome. Gli sviluppatori che vogliono flussi solo API devono usare separatamente l’Open API.
- Non è lo strumento giusto se il tuo bisogno principale è la pura infrastruttura proxy senza estrazione.
Prezzi
È disponibile un piano gratuito. I piani no-code partono da 9 $/mese con fatturazione annuale o 15 $/mese con fatturazione mensile per Starter. I prezzi API sono separati: 600 unità una tantum gratuite, poi 16 $/mese con fatturazione annuale per Starter API e 40 $/mese con fatturazione annuale per Pro 1 API. Vedi e .
Ideale per: team di vendita, e-commerce e operations che hanno bisogno di dati web strutturati senza supporto ingegneristico.
2. Octoparse
è un costruttore visuale di workflow per il web scraping con una vasta libreria di template predefiniti. Esiste da abbastanza tempo da avere un’infrastruttura cloud matura e gestisce bene la paginazione su siti strutturati e prevedibili.
Punti di forza principali
- Ampi template di scraping predefiniti per siti popolari
- Estrazione cloud con esecuzioni pianificate
- Rotazione IP e risoluzione CAPTCHA come add-on a pagamento
- Accesso API nei piani superiori
Dove può migliorare
- Le capacità AI sono più leggere rispetto agli strumenti nativi LLM. La proposta dei campi si basa ancora più sui template che su una lettura adattiva.
- Layout complessi o insoliti richiedono una notevole messa a punto manuale nell’editor visuale.
- La curva di apprendimento si accentua quando servono logiche condizionali o workaround anti-blocco.
Prezzi
È disponibile un piano gratuito a vita. La pagina ufficiale del centro assistenza indica attualmente prezzi da Standard a partire da 75 $/mese con fatturazione annuale e Professional da 208 $/mese con fatturazione annuale, mentre alcune pagine localizzate e percorsi di upgrade mostrano equivalenti mensili più alti. Il punto importante è che oggi il prezzo di Octoparse combina piani in abbonamento con add-on a pagamento come proxy residenziali e risoluzione CAPTCHA.
Ideale per: analisti e team operations che estraggono dati da siti strutturati e adatti ai template a scala moderata.
3. Browse AI
è una piattaforma no-code basata su cloud costruita principalmente per il monitoraggio nel tempo dei cambiamenti dei siti web, come prezzi dei concorrenti, disponibilità di stock e aggiornamenti di contenuto. Lo scraping fa parte del prodotto, ma il vero elemento distintivo è il sistema di monitoraggio ricorrente e di avvisi.
Punti di forza principali
- Rilevamento dei cambiamenti e avvisi integrati
- Registratore di robot no-code con configurazione point-and-click
- Robot preconfigurati per siti popolari
- Supporto proxy premium nei piani superiori
Dove può migliorare
- Il pricing basato su crediti diventa rapidamente costoso quando si monitorano pagine di dettaglio su larga scala
- Meno convincente per l’estrazione massiva una tantum rispetto agli strumenti API-first
- Gestione anti-bot moderata; alcuni siti richiedono ancora proxy premium o workaround
Prezzi
È disponibile un account gratuito. I piani a pagamento partono da circa 19 $/mese con fatturazione annuale per Starter, con livelli superiori di crediti e monitoraggio.
Ideale per: team che hanno bisogno di monitorare nel tempo prezzi dei concorrenti, cambiamenti di contenuto o livelli di stock, più che fare estrazioni massive una tantum.
4. Firecrawl
è un’API pensata per sviluppatori che converte le pagine web in Markdown pulito o JSON strutturato. Si colloca principalmente nel livello di estrazione ed è eccellente per i team che costruiscono pipeline RAG o alimentano LLM con contenuti web.
Punti di forza principali
- Ottima qualità dell’output Markdown per workflow LLM a valle
- API pulita con scrape, crawl, map, search, extract e azioni browser
- Supporto per elaborazione batch
- Concorrenza da 2 nella versione gratuita fino a 100 in Growth
Dove può migliorare
- Nessuna interfaccia no-code e richiede competenze di sviluppo
- Esistono aiuti integrati per proxy e anti-bot, ma Firecrawl non è posizionato come fornitore di sblocco dedicato
- Nessuno scheduler nativo per job ricorrenti
- Poco conveniente per chi non sviluppa e vuole solo un foglio di dati
Prezzi
Il piano gratuito include 1.000 crediti al mese. I piani a pagamento partono da 16 $/mese con fatturazione annuale per Hobby e crescono con più crediti, concorrenza e uso del browser. Le sessioni browser vengono addebitate separatamente in crediti.
Ideale per: sviluppatori che costruiscono pipeline LLM, sistemi RAG o workflow di estrazione personalizzati e hanno bisogno di Markdown o JSON puliti dalle pagine web.
5. Apify
è una piattaforma con un marketplace di actor di scraping predefiniti e strumenti per crearne di personalizzati. Pensala come uno strato di orchestrazione in cui scegli o costruisci scraper specializzati per siti specifici, poi li pianifichi e gestisci tramite una API unificata.
Punti di forza principali
- Marketplace enorme di actor con scraper creati dalla community per centinaia di siti
- API e SDK robusti per sviluppatori
- Gestione proxy e pianificazione integrate
- Si integra con molti strumenti a valle
Dove può migliorare
- Il "no-code" è solo parzialmente vero quando esci dal marketplace e hai bisogno di logica personalizzata
- L’affidabilità degli actor dipende dalla manutenzione della community
- I costi possono salire perché si sommano calcolo, costi degli actor e proxy
Prezzi
Il livello gratuito include 5 $ di crediti mensili sulla piattaforma. I piani a pagamento partono da 39 $/mese per Starter, con livelli superiori orientati alla scalabilità.
Ideale per: team di sviluppo che vogliono workflow di scraping riutilizzabili e pianificabili con un grande ecosistema di soluzioni già pronte.
6. Gumloop
è una piattaforma no-code di automazione dei workflow che include un nodo per il web scraping. Il vero valore non è lo scraping da solo. È collegare l’estrazione a LLM, Google Sheets, CRM e altri strumenti in un unico canvas visuale.
Punti di forza principali
- Costruttore visuale drag-and-drop
- Integra scraping con LLM e strumenti aziendali a valle in un unico flusso
- Piano gratuito attualmente pubblicizzato con 5.000 crediti/mese
- Pianificazione basata sul tempo per workflow ricorrenti
- Le modalità scraping base e Web Agent interattivo coprono sia flussi semplici sia più ricchi
Dove può migliorare
- Il motore di scraping è meno robusto rispetto agli strumenti AI web scraper dedicati
- Profondità limitata in anti-bot e proxy rispetto ai fornitori specializzati
- I limiti di concorrenza e trigger sono più stretti nei piani gratuiti
- Non è ideale per lo scraping su larga scala e ad alto volume come caso d’uso principale
Prezzi
È disponibile un piano gratuito. Gumloop ha unificato la vecchia struttura Solo e Team in un piano Pro alla fine del 2025, e da allora la comunicazione pubblica si concentra su crediti gratuiti più generosi e livelli a pagamento consolidati, invece che su un pricing incentrato sullo scraper.
Ideale per: team che vogliono lo scraping come uno step in un workflow automatizzato più ampio: estrarre, analizzare e inviare agli strumenti aziendali.
Se vuoi capire come si sente in pratica un workflow di estrazione nativo AI prima di leggere il resto della lista, questa demo di Thunderbit è la più utile per i team non tecnici.
7. Bright Data
è lo stack infrastrutturale di livello enterprise di questa lista. Se il tuo problema è "non riesco a superare la protezione bot di questo sito in nessun modo", Bright Data è probabilmente la risposta, ma porta con sé complessità enterprise e prezzi coerenti.
Punti di forza principali
- Network proxy leader del settore su IP residenziali, data center e mobile
- Web Unlocker per anti-bot e bypass CAPTCHA
- Scraping Browser con sblocco integrato
- Dataset pre-raccolti acquistabili
- Controllo programmatico completo via API e SDK
Dove può migliorare
- Non pensato per utenti non tecnici
- Il prezzo riflette il posizionamento enterprise
- L’estrazione AI non è il motivo principale per acquistare la piattaforma
Prezzi
La Browser API parte da 8 $/GB pay as you go, con tariffe per GB più basse su impegni mensili più grandi. Altri prodotti Bright Data, come Unlocker, Scraper API, dataset e pool di proxy, usano unità di prezzo diverse.
Ideale per: team dati enterprise che devono fare scraping su siti molto protetti su larga scala e dispongono del personale tecnico per gestire l’infrastruttura.
8. Bardeen
è uno strumento di automazione browser focalizzato su clic, compilazione di moduli e scraping con estrazione dati potenziata dall’AI sovrapposta. È più corretto considerarlo uno strumento per workflow GTM che fa anche scraping, non uno strumento di scraping che fa anche GTM.
Punti di forza principali
- Automazione intuitiva in stile playbook con lo scraping come uno step
- Scraper ufficiali mantenuti dal team di Bardeen per siti popolari
- Integrazioni forti con CRM, Google Sheets, Slack e altri strumenti business
- Utile per lead scraping, enrichment ed export verso CRM
Dove può migliorare
- L’architettura browser-first limita lo scraping ad alto volume non presidiato
- Lo scraping cloud funziona solo su pagine pubbliche, non su quelle con accesso limitato
- La gestione anti-bot dipende soprattutto da ciò che la tua sessione browser fornisce già
- L’estrazione AI può avere difficoltà con layout complessi o non standard
Prezzi
Il piano gratuito include 100 crediti mensili. La documentazione pubblica di supporto fa riferimento al vecchio prezzo Pro da 15 $/mese per gli utenti esistenti, mentre il packaging commerciale attuale di Bardeen è più orientato all’enterprise e ai workflow che al classico pricing low-end da scraper.
Ideale per: team di sales e operations che hanno bisogno dello scraping come parte di un workflow più ampio di automazione browser.
9. Diffbot
usa computer vision e NLP per leggere le pagine web come farebbe una persona, producendo dati strutturati per articoli, prodotti, discussioni e organizzazioni. È una delle API di estrazione di qualità più alta disponibili se le tue pagine rientrano nei suoi modelli preaddestrati.
Punti di forza principali
- Modelli di estrazione preaddestrati per articoli, prodotti, discussioni e altro
- Knowledge Graph con miliardi di entità per arricchimento dati
- Qualità elevata dell’output strutturato sui tipi di pagina supportati
- API chiara per sviluppatori con limiti di velocità pubblicati
Dove può migliorare
- Nessuna interfaccia no-code
- Nessun crawling integrato, gestione proxy o anti-bot
- Costoso per i piccoli team
- Meno flessibile su tipi di pagina non standard rispetto agli extractor basati su prompt e schema
Prezzi
Il piano gratuito include 10.000 crediti. Startup costa 299 $/mese per 250.000 crediti, e Plus costa 899 $/mese per 1.000.000 di crediti.
Ideale per: team di sviluppo che hanno bisogno di estrazione strutturata ad alta precisione da tipi di pagina standard e sono disposti a gestire separatamente il fetching.
10. ScrapingBee
è una API di web scraping focalizzata sul livello di fetching e sblocco. Invi una URL, lui gestisce proxy, rendering con browser headless e difese anti-bot, e restituisce HTML o, opzionalmente, dati estratti.
Punti di forza principali
- Rotazione proxy e gestione anti-bot integrate
- Supporto al rendering JavaScript
- API REST semplice
- Endpoint per scraping dei risultati di Google Search
- Concorrenza pubblicata per piano
Dove può migliorare
- Le funzionalità di estrazione AI sono limitate
- Nessuna interfaccia no-code
- Nessuna pianificazione o monitoraggio integrati
- Una risposta
200con una pagina bloccata può comunque essere conteggiata come richiesta riuscita
Prezzi
Il piano gratuito include 1.000 crediti API. I piani a pagamento partono da 49 $/mese e crescono con concorrenza e volume di richieste più alti.
Ideale per: sviluppatori che hanno soprattutto bisogno di recuperare pagine in modo affidabile oltre le difese anti-bot e gestiranno l’estrazione con il proprio codice o con uno strumento separato.
11. Instant Data Scraper
è un’estensione Chrome gratuita con oltre 1.000.000 di utenti che rileva automaticamente i pattern dei dati su una pagina e consente di esportare in CSV o Excel. Non c’è una proposta di campi AI nel senso degli LLM. Usa il rilevamento euristico dei pattern.
Punti di forza principali
- Completamente gratuito, senza account richiesto
- Rilevamento dati in un clic su molte pagine di elenchi e tabelle
- Gestisce la paginazione su alcuni siti
- Barriera d’ingresso estremamente bassa
- Ancora mantenuto, con aggiornamenti nel Chrome Web Store nel 2026
Dove può migliorare
- Nessuna proposta di campi o etichettatura dati potenziata dall’AI
- Nessuno scraping cloud, pianificazione o API
- Fatica con layout complessi, contenuti dinamici e siti pesanti in JS
- Nessuna gestione anti-bot oltre a ciò che il browser può già caricare
- Export limitato a CSV ed Excel
Prezzi
Gratis. Per sempre.
Ideale per: chiunque abbia bisogno di uno scraping veloce e una tantum di una semplice pagina elenco e non voglia creare un account né spendere nulla.
12. ParseHub
è un’app desktop con un’interfaccia visuale point-and-click per costruire progetti di scraping. Sa gestire dati complessi nidificati, contenuti caricati via AJAX, scroll infinito e interazioni con menu a tendina che le estensioni più semplici spesso non catturano.
Punti di forza principali
- Interfaccia visuale con selettori per definire le regole di estrazione
- Gestisce dati nidificati, menu a tendina, scroll infinito e contenuti AJAX
- Piano gratuito con fino a 5 progetti
- Export in JSON, CSV ed Excel
- Pianificazione cloud e rotazione IP nei piani a pagamento
Dove può migliorare
- Workflow solo desktop, senza la comodità di un’estensione browser
- Velocità di esecuzione più lenta rispetto agli strumenti nativi cloud
- I progetti si rompono quando cambiano i layout del sito perché non esiste un livello AI che rilegga la pagina
- Capacità AI limitate e un feeling più da scraper visuale tradizionale
Prezzi
È disponibile un piano gratuito con 5 progetti e 200 pagine per esecuzione. I piani a pagamento partono da 189 $/mese con pianificazione, rotazione IP e limiti più alti.
Ideale per: utenti non tecnici che devono estrarre siti interattivi complessi e sono disposti a investire tempo nella configurazione visuale del workflow.
Come iniziare con un AI Web Scraper in 5 passaggi
Ogni strumento di questa lista ha un flusso di onboarding diverso. Userò Thunderbit come esempio concreto perché corrisponde meglio all’intento di ricerca "mi serve solo che funzioni su una pagina reale".
Passo 1: installa e vai alla pagina
Installa la e vai alla pagina che vuoi estrarre: un elenco prodotti, una directory o un portale immobiliare.
Passo 2: lascia che l’AI suggerisca i campi dati
Fai clic su AI Suggest Fields. L’AI legge la pagina corrente e propone nomi di colonne e tipi di dati. Su una pagina prodotto, potrebbe suggerire Nome prodotto, Prezzo, Valutazione, URL immagine e Descrizione.
Passo 3: personalizza i campi con i prompt AI
Modifica le colonne se quelle predefinite non sono perfette. Aggiungi prompt AI per campo per trasformazioni personalizzate come "traduci la descrizione in spagnolo", "classifica come Electronics, Home o Fashion" oppure "estrae solo il prezzo numerico".
Passo 4: scegli la modalità cloud o browser ed esegui lo scraping
Seleziona lo scraping cloud per siti pubblici o lo scraping browser per target autenticati o fortemente protetti. Poi fai clic su Scrape.
Passo 5: esporta i dati dove vuoi
Esporta i risultati in Google Sheets, Excel, Airtable o Notion. Le esportazioni sono gratuite.
Cosa succede se il layout del sito cambia?
Questo è il principale vantaggio in produzione degli extractor nativi AI rispetto agli strumenti basati su regole. Gli scraper tradizionali come ParseHub e i vecchi workflow di Octoparse si basano su selettori XPath o percorsi CSS. Quando un sito aggiorna la struttura HTML, quei selettori si rompono e devi riconfigurare tutto manualmente.
Gli extractor AI come Thunderbit rileggono ogni volta la struttura della pagina. Questo significa niente manutenzione di XPath e niente selettori fragili. L’AI si adatta automaticamente ai cambiamenti di layout alla corsa successiva.
Scraping pianificato e accesso API: le funzionalità avanzate che nessuno recensisce
Gli scraping una tantum vanno bene per la ricerca. I casi d’uso in produzione, come il monitoraggio dei prezzi, l’aggiornamento di liste lead e il tracking delle scorte, richiedono estrazione ricorrente e accesso programmatico. Sono queste funzioni a separare i giocattoli dagli strumenti.
Supporto alla pianificazione
| Strumento | Pianificazione nativa | Note |
|---|---|---|
| Thunderbit | ✅ | Configurazione in linguaggio naturale |
| Octoparse | ✅ | Esecuzioni cloud pianificate |
| Browse AI | ✅ | Funzione core del prodotto |
| Firecrawl | ❌ | Usa cron esterno |
| Apify | ✅ | Espressioni cron complete |
| Gumloop | ✅ | Trigger workflow basati sul tempo |
| Bright Data | Esterno | Di solito orchestrato tramite i sistemi del cliente |
| Bardeen | ✅ | Pianificazione dei playbook |
| Diffbot | ❌ | API-first, orchestrazione esterna |
| ScrapingBee | ❌ | Solo API |
| Instant Data Scraper | ❌ | Strumento manuale da browser |
| ParseHub | ✅ (a pagamento) | Funzione premium |
Confronto tra API per sviluppatori
| Strumento | Segnale di concorrenza o rate limit | Modello di prezzo |
|---|---|---|
| Thunderbit | 2 → 50 in concorrenza | Basato su crediti |
| Firecrawl | 2 → 100 in concorrenza | Basato su crediti |
| Apify | Dipende dal piano | Unità di calcolo |
| Gumloop | Concorrenza dei workflow limitata dal piano | Basato su crediti |
| Diffbot | 5 chiamate/min → 25 chiamate/sec | Basato su crediti |
| ScrapingBee | 10 → 200 in concorrenza | Crediti API |
| Bright Data | La Browser API pubblicizza richieste concorrenti illimitate | Basato su GB |
Se il tuo caso d’uso è più tecnico e stai cercando di capire quanta infrastruttura vuoi davvero possedere, questo walkthrough di Firecrawl è un complemento utile, orientato all’esecuzione, ai confronti di prodotto sopra.
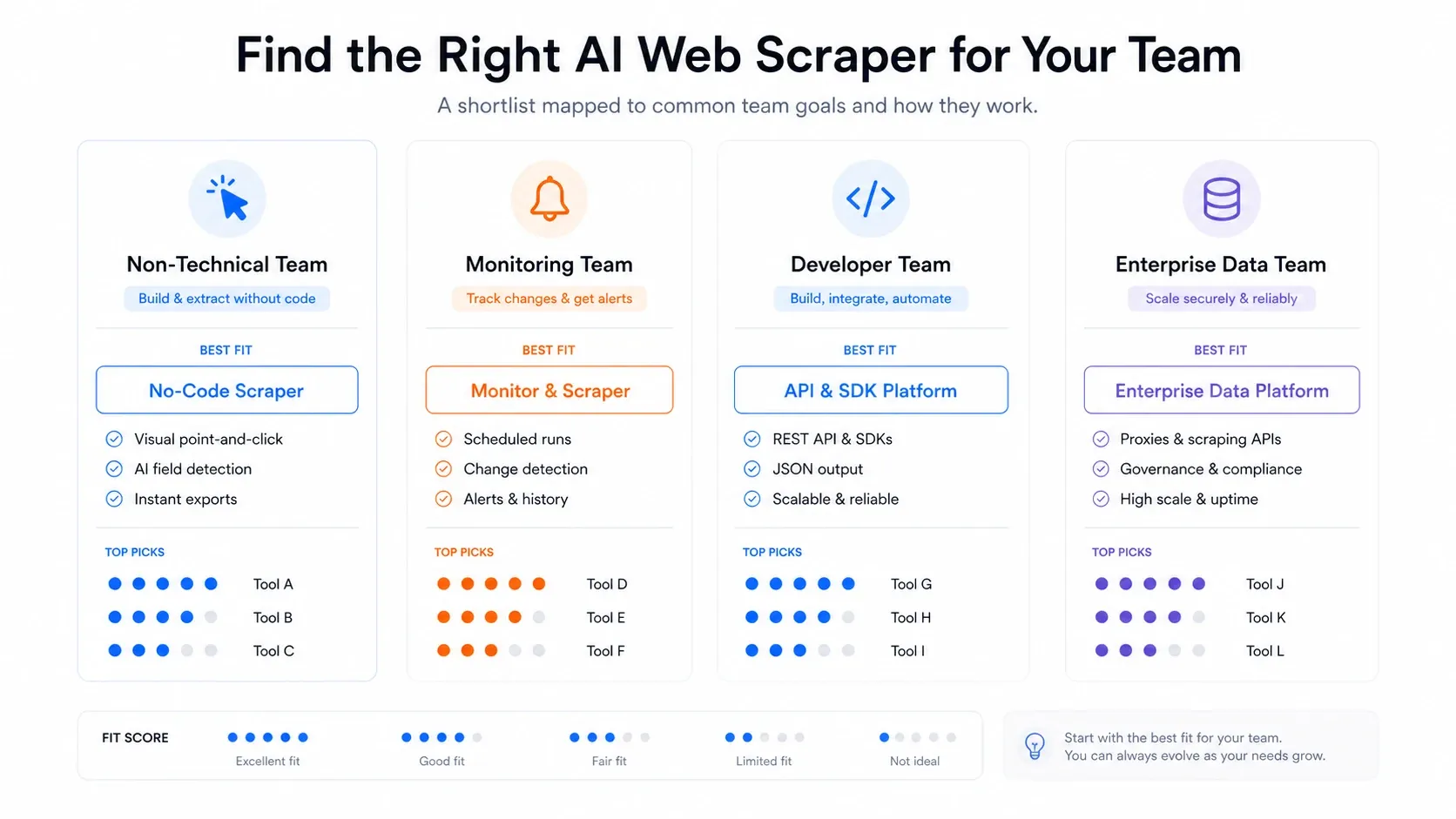
Come scegliere l’AI Web Scraper giusto
Dopo aver testato tutti e 12 gli strumenti, ecco come deciderei io:
- Team non tecnico che ha bisogno di dati rapidamente: parti da Thunderbit. Il flusso in due clic, le esportazioni gratuite e il passaggio browser-cloud coprono la maggior parte delle esigenze di scraping aziendale senza supporto ingegneristico.
- Hai bisogno di monitoraggio continuo e avvisi: Browse AI è progettato apposta per questo. Non è il miglior extractor una tantum, ma il rilevamento dei cambiamenti è una funzione di primo livello.
- Sviluppatore che costruisce una pipeline LLM: Firecrawl per l’estrazione in Markdown o JSON, oppure Diffbot per l’estrazione strutturata preaddestrata. Abbina uno dei due a ScrapingBee o Bright Data se ti serve una gestione anti-bot seria nel livello di fetching.
- Ti serve un marketplace di scraper preconfezionati: Apify ha il più grande ecosistema di actor. Preparati però alla manutenzione quando gli actor si rompono.
- Target enterprise su larga scala e fortemente protetti: Bright Data. Niente altro regge il confronto con la sua infrastruttura proxy, ma adegua budget e personale tecnico di conseguenza.
- Vuoi lo scraping come parte di un’automazione più ampia: Gumloop o Bardeen, a seconda che tu stia automatizzando workflow o task GTM basati sul browser.
- Ti serve solo uno scraping gratuito e rapido: Instant Data Scraper. Nessuna configurazione, nessun costo, nessuna complessità, ma anche niente pianificazione, niente AI e niente cloud.
- Siti interattivi complessi con menu a tendina e AJAX: ParseHub gestisce ancora questi casi meglio della maggior parte delle estensioni, anche se il peso della manutenzione è reale.
Conclusione
Il mercato degli AI web scraper nel 2026 è affollato di strumenti che sembrano impressionanti in demo e deludono in produzione. Il divario tra "funziona in uno screenshot di marketing" e "funziona su un sito e-commerce protetto alle 3 del mattino secondo una pianificazione" è il punto in cui la maggior parte degli acquirenti spreca tempo e denaro.
La lezione chiave emersa valutando tutti e 12 gli strumenti è semplice: il livello di fetching è ancora la parte difficile. L’AI eccelle nell’estrazione e nella post-elaborazione, ma non sostituisce infrastruttura proxy, gestione anti-bot o gestione delle sessioni. Gli strumenti migliori risolvono entrambi i livelli, come Thunderbit e Bright Data, oppure sono onesti su quale livello coprono, come Firecrawl per l’estrazione e ScrapingBee per il fetching.
Se vuoi vedere come appare un AI web scraper pronto per la produzione senza scrivere codice, . Il piano gratuito basta per testare l’intero flusso su pagine reali. Se le tue esigenze sono più orientate allo sviluppo, abbina una API di estrazione a un servizio di fetching dedicato e risparmiati la frustrazione di aspettarti che un solo strumento faccia tutto.
FAQ
Perché la maggior parte degli AI web scraper fallisce sui siti reali dopo aver funzionato bene nelle demo?
Le demo mostrano in genere l’estrazione su pagine pulite e non protette. I siti reali aggiungono protezione Cloudflare, rendering JavaScript dinamico, paginazione, requisiti di login e layout che cambiano spesso. La maggior parte degli strumenti gestisce bene il livello di parsing ed estrazione, ma non ha un’infrastruttura robusta per il livello di fetching.
Qual è la differenza tra scraping cloud e scraping browser, e quando dovrei usare ciascuno?
Lo scraping cloud usa server remoti per recuperare le pagine, quindi è più veloce, parallelo e scalabile. Lo scraping browser gira nella tua sessione browser ed è migliore per siti autenticati o con rilevamento bot aggressivo. Thunderbit è uno dei pochi strumenti che offre entrambe le modalità nella stessa interfaccia.
Posso usare un AI web scraper per attività ricorrenti come il monitoraggio dei prezzi?
Sì, ma solo se lo strumento supporta lo scraping pianificato. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen e ParseHub nei piani a pagamento offrono tutti la pianificazione.
Qual è il miglior AI web scraper se non so programmare?
Thunderbit offre il percorso più rapido verso dati utilizzabili per utenti non tecnici. Instant Data Scraper è completamente gratuito ma limitato alle pagine semplici. Browse AI e Octoparse offrono interfacce visuali con più configurazione. ParseHub è potente per siti interattivi complessi ma ha una curva di apprendimento più ripida.
Quanto costa davvero lo scraping AI di livello produzione?
L’intervallo è ampio. Instant Data Scraper è gratuito. Thunderbit, Firecrawl e Browse AI offrono punti di ingresso gratuiti con piani a pagamento a basso costo. Strumenti di fascia media come Octoparse, ParseHub e ScrapingBee possono costare da circa 49 a 189 $ al mese. Soluzioni enterprise come Bright Data e Diffbot partono molto più in alto.