Executive summary
Abbiamo estratto il file robots.txt di ogni dominio della lista Tranco top 10.000 dei siti web con il traffico più alto al mondo. Poi abbiamo analizzato ogni file con un parser conforme a RFC 9309, classificato il file in base alla policy sui bot AI adottata dal sito, se presente, e contato quanti tra i siti più visitati del mondo provano davvero a bloccare ChatGPT, Claude, Perplexity, Gemini, Common Crawl, Bytespider, Apple Intelligence e gli altri crawler che nel 2026 addestrano e alimentano i grandi modelli linguistici.
I numeri principali, su un campione di 7.248 siti il cui robots.txt era leggibile in modo pulito:
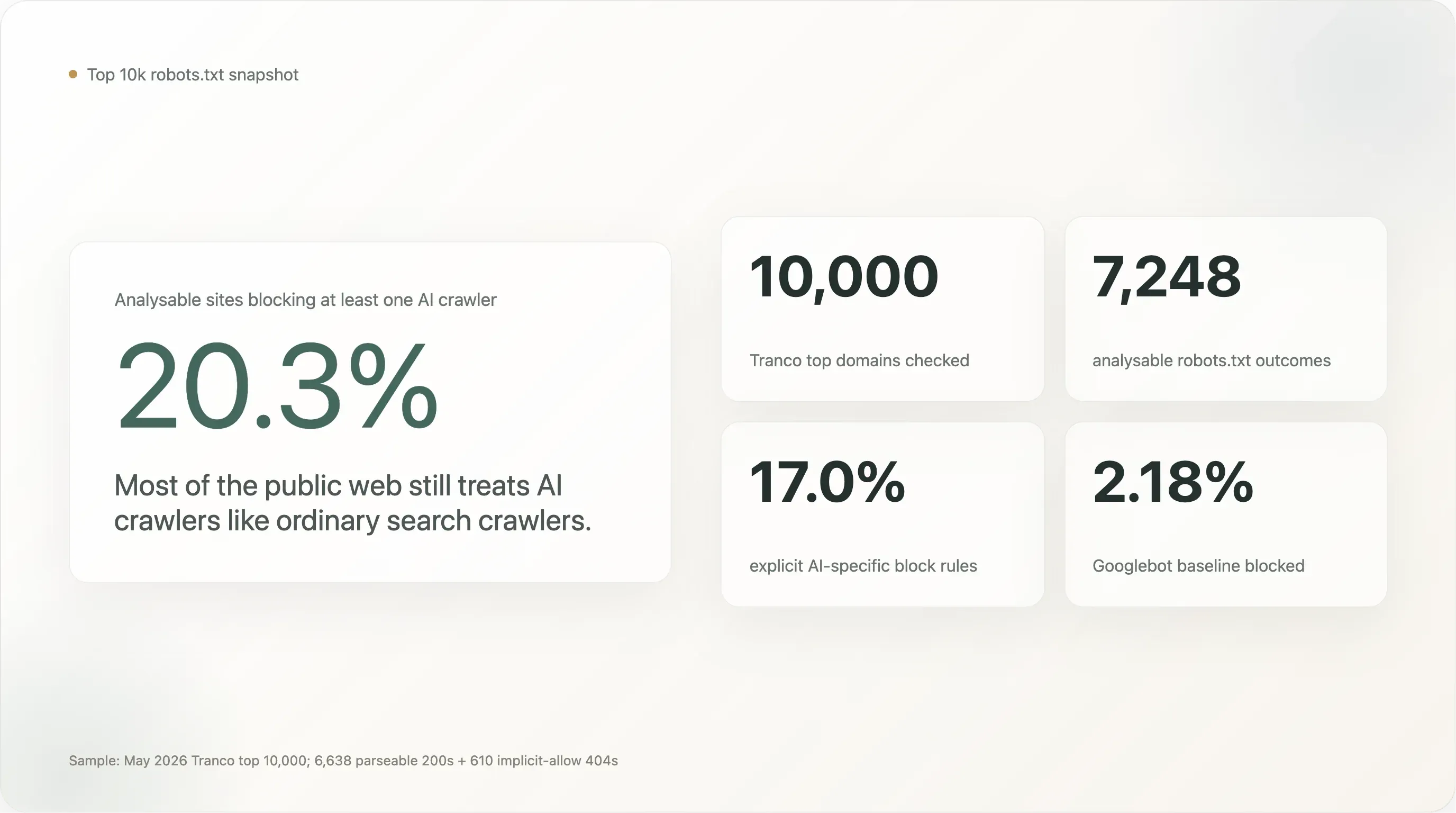
Il 20,3% dei 10.000 siti più visitati al mondo blocca almeno un crawler AI. Il 17,0% ha scritto appositamente una regola esplicita dedicata all’AI. Il restante 80% lascia i crawler AI accolti quanto Googlebot.
Sei risultati che cambiano il quadro della storia:
- Le testate giornalistiche bloccano nel 47% dei casi — il valore più alto tra tutti i settori. La Germania guida con l’88%, la Francia con l’80%, la Russia con lo 0%. Il fattore principale è il regime giuridico, non la tecnologia o l’economia del settore.
CCBot(Common Crawl) è il bot più bloccato, con il 16,3% — davanti aGPTBot(15,8%) eBytespider(14,9%). Gli editori colpiscono il corpus di addestramento, non il brand del modello. La regola selettiva più diffusa è "bloccaCCBot, consentiGooglebot" (14,1% dei siti).- La Francia è prima tra tutti i paesi, con il 50,6% di blocco AI sui siti
.fr; il cluster UE è 16 punti sopra la base globale. 275 filerobots.txtcitano esplicitamente la Direttiva UE 2019/790. L’articolo 4 è l’unico regime giuridico che sta muovendo i numeri in modo visibile. - Il 17,8% ha scritto regole AI proprie; il 4,5% usa il template gestito di Cloudflare; il 75,7% non dice nulla. I grandi siti scrivono da soli; la coda lunga usa il toggle. The Atlantic e lo stesso
cloudflare.comsono nella lista Cloudflare Managed. - 108 siti consentono esplicitamente
GPTBot— WordPress.org, Kaspersky, Norton, Avast, Sophos, The Verge, The Atlantic, NBA.com, The Sun, Branch.io. Sicurezza e strumenti per sviluppatori sono sovrarappresentati. - La policy AI non diventa più aggressiva verso la testa della curva. Top 100, 101–1000, 1001–5000 e 5001–10000 si collocano tutti tra il 19% e il 23%. Il dato principale è una proprietà del web pubblico nel 2026, non un indicatore della grandezza di un singolo sito.
La storia non riguarda più se il web stia "reagendo". Riguarda quali settori, quali paesi, quali regimi giuridici e quali fornitori AI sono bersaglio di policy attive — e quali no.
I. Contesto: come robots.txt è diventato un artefatto di policy AI
Tre forze hanno ridefinito il significato di robots.txt da quando OpenAI ha lanciato GPTBot nell’agosto 2023.
I fornitori AI si sono moltiplicati. Sono arrivati Google-Extended di Google, ClaudeBot di Anthropic, Bytespider di ByteDance, Applebot-Extended di Apple, Amazonbot di Amazon, Meta-ExternalAgent di Meta. Anche il già esistente CCBot di Common Crawl è diventato il singolo bersaglio di blocco con maggiore impatto, perché il suo archivio alimenta la maggior parte dei modelli open-weight. Sono comparsi anche bot non legati a un vendor: AI2Bot, cohere-ai, PerplexityBot, YouBot, DuckAssistBot, Diffbot, Omgili. Una blocklist completa del 2026 arriva a circa 25 nomi.
L’articolo 4 della Direttiva UE 2019/790 sul diritto d’autore ha creato un’eccezione legale per il text and data mining che non si applica se il titolare dei diritti ha "espressamente riservato" i propri diritti in forma "leggibile da macchina". Nel corso del 2024–2025 editori europei e legali hanno convergito su robots.txt come modo canonico per esprimere tale riserva. Il nostro dataset mostra 275 siti che citano esplicitamente la Direttiva 2019/790 e 87 che menzionano "TDM" — concentrati sulle testate europee, dove assumono la forma di un preambolo legale di 4–8 righe.
Cloudflare ha trasformato il toggle in prodotto. Nel 2024–2025 Cloudflare ha rilasciato una dashboard "AI Audit", un toggle "Block AI Bots" e un template robots.txt gestito con la terminologia Content-Signal: search=yes,ai-train=no e il boilerplate sulla Direttiva UE 2019/790. A maggio 2026 il template è attivo sul 4,5% dei top 10k analizzabili. La roadmap di Cloudflare parla pubblicamente di rendere il toggle attivo di default per i nuovi account — cosa che sposterebbe il tasso globale di blocco di 5–8 punti senza che nessun singolo editore prenda una decisione.
Nel 2026 robots.txt non è più il file di configurazione anonimo che era nel 2022. È un meccanismo di riserva dei diritti con sostegno giuridico nell’UE, un artefatto di policy plasmato dal vendor nella coda lunga e la linea del fronte di una negoziazione lenta tra chi gestisce i siti web e chi addestra i modelli.
II. Metodologia
Abbiamo cercato di rendere tutto il più noioso e riproducibile possibile. L’intera pipeline (script Python, CSV analizzati, archivio grezzo di robots.txt, grafici) è pubblicata insieme a questo report.
Campione
Siamo partiti dalla lista Tranco aggiornata a maggio 2026, scaricata come top-1m.csv.zip, e abbiamo preso le prime 10.000 righe. Tranco aggrega quattro ranking a monte (Cisco Umbrella, Majestic, Farsight e Cloudflare Radar), filtra la stabilità su una finestra di 30 giorni e rimuove il rumore evidente di crawler/CDN. La lista che produce è la cosa più vicina a un "top 10k globale del traffico web" canonicamente riconosciuto che esista in forma aperta, ed è il campione standard per la ricerca accademica sul web (usato in oltre 600 articoli peer-reviewed dalla sua introduzione da parte della KU Leuven nel 2018).
La lista contiene un mix di (a) siti principali visitati dagli utenti, (b) domini di infrastruttura / API / DNS / CDN che non servono alcuna homepage su /, e (c) domini usati internamente da grandi piattaforme (ad es. gvt1.com, apple-dns.net, googleusercontent.com). Invece di prefiltrarli, li abbiamo mantenuti tutti e li abbiamo etichettati con una categoria infrastructure nel livello di analisi. Escono naturalmente quando restringiamo il campo a "siti che hanno restituito un robots.txt analizzabile".
Raccolta
Per ciascuno dei 10.000 domini abbiamo eseguito un GET /robots.txt asincrono via HTTPS, con fallback su HTTP, redirect seguiti fino a quattro salti, timeout totale di 12 secondi, limite del corpo a 500 KB e una User-Agent string da browser reale con Accept-Language: en-US. La concorrenza è stata mantenuta a 80 richieste simultanee. Il lavoro è stato eseguito da un singolo IP residenziale a San Francisco.
Esito della raccolta:
| Stato | Conteggio | Interpretazione |
|---|---|---|
200 OK | 6.638 | Il corpo di robots.txt è stato restituito ed è analizzabile. |
404 Not Found | 610 | Non esiste alcun robots.txt. RFC 9309 lo definisce un implicito "consenti tutto." |
403 Forbidden | 563 | L’origine rifiuta attivamente le richieste a robots.txt. Esclusi dall’analisi. |
429 Too Many Requests | 7 | Quasi nessun throttling a livello CDN in questa fascia di ranking. |
fetch_failed (errore TLS / DNS / TCP) | 2.065 | Per lo più domini apex di CDN (akamai.net, cloudfront.net, fastly.net, gtld-servers.net, apple-dns.net) che non eseguono un webserver su /. Non sono "bloccati" — semplicemente non hanno alcun robots.txt da servire. |
| Altro 4xx/5xx | 117 | Misto — errori server, geofencing, risposte malformate. |
Questo ci dà 7.248 siti nel campione analizzabile (6.638 200 + 610 404). I 2.065 fetch_failed sono domini reali, ma sono punti apex CDN/DNS, non siti visitati dagli utenti, e considerarli come aventi una "policy AI" non ha senso. Nel dataset restano come statistica separata di accessibilità.
Parsing
Ogni corpo 200 è stato analizzato con protego, un’implementazione Python di RFC 9309 usata in produzione da Scrapy. Per ogni coppia (sito, bot) abbiamo calcolato tre cose:
can_fetch_root— se il bot può accedere a/, usando la semantica standard dei gruppi di record, la precedenza della regola longest-match e la prevalenza diUser-agent: *da parte di un blocco specifico quando entrambi esistono.has_specific_rule— se il file contiene una rigaUser-agent:che nomina esattamente questo bot (case-insensitive).disallow_count— quante direttiveDisallow:sono presenti nel blocco corrispondente, usato per distinguere divieti totali del sito da restrizioni a livello di percorso.
La combinazione conta perché un tasso di blocco complessivo nasconde due fenomeni completamente diversi: brand che hanno intenzionalmente scritto User-agent: GPTBot \n Disallow: / perché volevano reagire, e brand il cui blocco generico User-agent: * \n Disallow: / (impostato anni fa per staging o manutenzione) finisce per vietare anche ogni bot AI che non esisteva quando la regola fu scritta. In questo report il numero di "any AI block" include entrambi i casi; il numero di "explicit AI block" è il sottoinsieme deliberato.
Bot inclusi
Abbiamo tracciato 25 bot, raggruppati in tre categorie:
- Crawler di training AI (16):
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Meta-ExternalAgent,Bytespider,Applebot-Extended,Diffbot,Amazonbot,ImagesiftBot,FacebookBot,cohere-ai,AI2Bot,Omgili,Omgilibot. - Bot di inference AI / retrieval live (7):
PerplexityBot,Perplexity-User,ChatGPT-User,OAI-SearchBot,ClaudeBot(che serve sia training sia inference),YouBot,DuckAssistBot. - Baseline di ricerca (6):
Googlebot,Bingbot,DuckDuckBot,Slurp(Yahoo),Baiduspider,YandexBot.
Alcuni bot stanno a cavallo tra training e inference. Il caso più evidente è ClaudeBot: Anthropic ha deprecato nel 2024 la vecchia UA anthropic-ai e ora usa ClaudeBot sia per il training sia per il retrieval live, quindi una regola Disallow: ClaudeBot non si traduce più in modo pulito come "blocca il training ma mantieni la visibilità". Abbiamo mantenuto l’assegnazione così com’è e spiegato la conseguenza più avanti.
Classificazione per settore
Abbiamo classificato ogni dominio in uno di 16 bucket di settore (news, social, streaming, ecommerce, search, finance, infrastructure, saas, academia, dev, gov, adult, gambling, travel, telecom, unknown) con un approccio a più livelli:
- Dizionario di domini noti — una mappa curata a mano di circa 500 domini ad alto traffico verso i rispettivi settori.
- Pattern di TLD / suffisso —
.gov→gov,.edue.ac.*→academia, suffissi CDN riconosciuti →infrastructure. - Parole chiave nel nome del dominio — news, post, shop, bank, porn, casino ecc. come segnali di fallback.
- Scrape della homepage — per i siti che i primi tre livelli non riuscivano a classificare e che restituivano un
robots.txt200, abbiamo scaricato l’HTML della homepage, estratto<title>,<meta name="description">,<meta property="og:type">e applicato uno scoring per parole chiave contro indizi di categoria in stile modello linguistico.
Questo ha prodotto 3.407 siti (34%) con tag di settore affidabili e 6.593 lasciati come unknown. Il bucket unknown è dominato da portali regionali non inglesi, siti brand .com aziendali che non rientrano in un singolo bucket e editori tradizionali di mercati linguistici piccoli per i quali non avevamo voci nel dizionario. Quando questo report cita una percentuale per settore, il denominatore è il campione classificato per quel settore, non l’intero 10.000.
III. Risultati
Risultato 1 — Un sito su cinque tra i più visitati blocca almeno un bot AI
Tra i 7.248 siti analizzabili, 1.472 (20,31%) bloccano almeno un bot AI. 1.230 (16,97%) hanno una regola AI deliberata e specifica. La baseline per Googlebot è 2,18% (158 siti — la maggior parte dei quali o bloccava tutto come default di manutenzione o, in tre casi, sono motori di ricerca che bloccano i concorrenti).
Il 20% principale è 9 volte la baseline di Googlebot. È un segnale reale — i siti ad alto traffico hanno una probabilità di bloccare un crawler AI di un ordine di grandezza superiore rispetto a un crawler di ricerca — ma è anche un numero molto più piccolo della narrativa "il blocco dell’AI sta diventando universale" che circola sulla stampa dal 2024. Anche tra i 10.000 siti più visitati del web, la maggioranza dei cinque sesti resta in silenzio sull’AI.
La distinzione tra "any AI block" (20,3%) e "explicit AI block" (17,0%) è piccola in termini assoluti ma importante dal punto di vista concettuale. Il divario di 3,3 punti è la quota di siti che bloccano i bot AI solo perché la loro vecchia regola User-agent: * \n Disallow: / prende tutto ciò che passa, compresi i bot che non esistevano quando la regola fu scritta. Il 17,0% deliberato è la lettura più pulita di "quanti tra i siti più grandi del mondo hanno preso una decisione specifica sull’AI".
Confronto con la letteratura precedente:
| Fonte | Data | Campione | Tasso di blocco |
|---|---|---|---|
| Originality.ai | Mar 2025 | 1.000 news più popolari (inglese) | 35,7% blocca GPTBot |
| Palewire | Ago 2024 | 1.500 testate giornalistiche | 36,0% qualsiasi crawler AI |
| Reuters Institute | Primavera 2025 | 50 marchi news leader, 10 paesi | 78% qualsiasi crawler AI |
| WIRED / NYT | Fine 2023 | Top 50 news USA | 26% blocca GPTBot |
| Questo report (Thunderbit) | Mag 2026 | Tranco top 10.000 (tutti i settori) | 20,3% / 17,0% esplicito |
Il nostro 17,0% esplicito è inferiore a tutti gli studi focalizzati solo sulle news perché due terzi del nostro campione non sono news. Restringendo alle 650 testate giornalistiche otteniamo il 47% — nello stesso intervallo degli studi precedenti, una volta considerata la composizione del campione. Il quadro strutturale è coerente: il cohort news blocca l’AI a un tasso 3–4 volte superiore rispetto al resto del web.
Risultato 2 — Approfondimento per settore: uno spread 12x da news a telecom
Il risultato più citato negli ultimi due anni di copertura sullo "scraping AI" è stato il numero secondo cui l’80% delle testate blocca GPTBot emerso da Originality.ai e Palewire. La nostra analisi produce una cifra più contenuta ma comunque netta: il 47,2% dei siti news nel top 10.000 blocca almeno un bot AI, con il 45,2% che scrive una regola AI esplicita.
Ma "news contro tutto il resto" è una distinzione troppo grossolana. La ripartizione completa (settori con n ≥ 10 nel campione) racconta una storia molto più ricca:
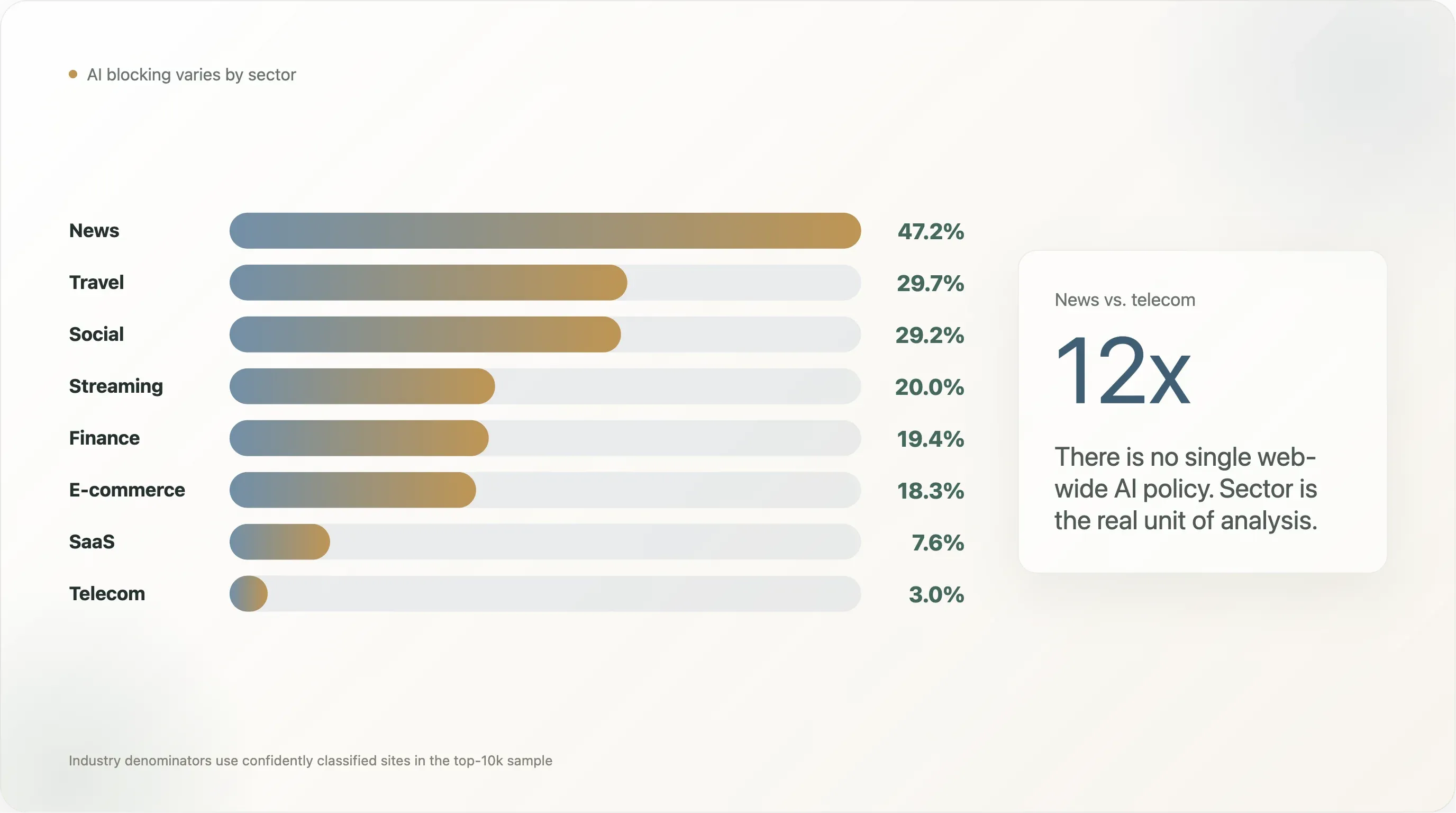
| Settore | n | Any AI block | Esplicito | Googlebot bloccato | Regole fai-da-te | Cloudflare Managed | Silenzio |
|---|---|---|---|---|---|---|---|
| News | 650 | 47,2% | 45,2% | 1,5% | 46,9% | 1,5% | 48,5% |
| Travel | 64 | 29,7% | 29,7% | 0,0% | 35,9% | 3,1% | 54,7% |
| Social | 65 | 29,2% | 23,1% | 4,6% | 23,1% | 6,2% | 66,2% |
| Streaming | 440 | 20,0% | 17,7% | 0,7% | 16,8% | 3,6% | 75,5% |
| Finance | 129 | 19,4% | 12,4% | 0,8% | 14,7% | 2,3% | 75,2% |
| E-commerce | 224 | 18,3% | 17,4% | 0,4% | 24,1% | 1,3% | 66,1% |
| Adult | 254 | 17,3% | 14,6% | 0,4% | 10,2% | 7,9% | 79,5% |
| Search | 12 | 16,7% | 0,0% | 0,0% | 0,0% | 0,0% | 100,0% |
| Academia | 268 | 14,6% | 13,8% | 0,4% | 13,4% | 3,4% | 77,2% |
| Gambling | 100 | 14,0% | 13,0% | 0,0% | 18,0% | 4,0% | 77,0% |
| Dev tools | 129 | 10,1% | 7,8% | 0,0% | 8,5% | 5,4% | 77,5% |
| SaaS | 369 | 7,6% | 6,2% | 0,3% | 9,5% | 0,8% | 87,5% |
| Government | 172 | 5,2% | 3,5% | 0,0% | 4,1% | 0,6% | 83,1% |
| Infrastructure | 47 | 4,3% | 0,0% | 0,0% | 4,3% | 2,1% | 72,3% |
| Telecom | 33 | 3,0% | 3,0% | 0,0% | 12,1% | 0,0% | 78,8% |
Lo spread 12x tra news e telecom è ciò che rende "la policy AI del web" l’unità di analisi sbagliata. Non esiste un solo numero; esistono numeri per settore che divergono di un ordine di grandezza. Di seguito i quattro risultati più distintivi.
News: 47% di blocco, 47% fai-da-te. Le news sono il cohort che ha scritto il manuale operativo. Cloudflare Managed è presente solo nell’1,5% delle news — questi editori non esternalizzano la regola. Il testo è insolitamente ricco: il NYT apre con un preambolo legale di 14 righe che cita "Art. 4 of the EU Directive"; la BBC con "Please use our site like a human, not a robot... TL;DR: Browse, read, watch, enjoy — like a human."; The Sun con "The Sun does not permit the unlicensed use of our content for large language models." Questo è robots.txt come dichiarazione di policy, non come configurazione.
Travel al 30% — la sorpresa. Booking, Expedia, TripAdvisor, Kayak e le principali compagnie aeree bloccano a circa due terzi del tasso delle news. Il pattern selettivo è coerente: il blocker travel medio vieta 5–7 UA di training ma lascia intatti gli UA di inference (PerplexityBot, ChatGPT-User, OAI-SearchBot). Dati di prezzo aggregati e recensioni sono il fossato difensivo; le citazioni verso il sito sono il vantaggio. Questo è il pattern più pulito di "training fuori, inference dentro" in un singolo settore.
Adult al 17% — anche questa è una sorpresa. Campioni più piccoli in passato mostravano lo 0%. I dati del campione completo mostrano che 1 sito adult su 6 vieta almeno un bot AI, con il tasso più alto di Cloudflare Managed di qualsiasi settore (7,9%). Più della metà dei blocchi AI dei siti adult deriva dal toggle di Cloudflare, non da una decisione dell’editore. L’addestramento per la generazione di immagini è la minaccia implicita — i modelli della classe Stable Diffusion apprendono lo stile visivo più in fretta di quanto i modelli testuali apprendano lo stile di scrittura.
SaaS al 7,6% è controintuitivo. I vendor software sono il segmento più rumoroso nel discorso sulla policy AI, ma il loro robots.txt è molto aperto. La lettura corretta: i team marketing SaaS hanno capito che la ricerca AI è un canale di distribuzione. I vendor che ci hanno davvero riflettuto stanno optando per l’ingresso, non per l’uscita — la lista esplicita Allow-GPTBot (Risultato 12) è dominata da security e SaaS per strumenti di sviluppo.
Government 5,2%, telecom 3,0%, infrastructure 4,3%, dev 10,1%. Gli obblighi di accesso ai registri pubblici rendono Disallow: / giuridicamente delicato per i .gov. I siti marketing delle telecom vogliono essere trovati. I domini apex delle CDN non hanno nulla da proteggere. Gli strumenti per sviluppatori, invece, optano esplicitamente per l’ingresso (il loro contenuto acquista valore quando i LLM lo citano).
La conclusione: non esiste un unico numero "il web sta/non sta bloccando l’AI" che non perda più di quanto comunichi. Il reporting per settore è l’unico modo onesto di discutere i dati.
Risultato 3 — Per vendor AI: chi viene bloccato di più?
L’altro taglio naturale del dato è per azienda AI invece che per bot. Diversi vendor gestiscono più bot (OpenAI ne gestisce tre: GPTBot, ChatGPT-User, OAI-SearchBot; Anthropic ne gestisce due: ClaudeBot, anthropic-ai; Meta ne gestisce due: Meta-ExternalAgent, FacebookBot). Aggregare a livello di vendor è il modo più vicino che abbiamo per rispondere a "cosa pensa il web pubblico di ciascuna azienda AI?"
| Vendor AI | Bot aggregati | Siti che bloccano ≥ 1 bot | % del campione analizzabile |
|---|---|---|---|
| Common Crawl | CCBot | 1.178 | 16,25% |
| OpenAI | GPTBot, ChatGPT-User, OAI-SearchBot | 1.172 | 16,17% |
| Anthropic | ClaudeBot, anthropic-ai | 1.111 | 15,33% |
| ByteDance | Bytespider | 1.082 | 14,93% |
| Meta | Meta-ExternalAgent, FacebookBot | 989 | 13,65% |
Google-Extended | 970 | 13,38% | |
| Amazon | Amazonbot | 877 | 12,10% |
| Apple | Applebot-Extended | 859 | 11,85% |
| Webz.io (Omgili) | Omgili, Omgilibot | 731 | 10,09% |
| Cohere | cohere-ai | 717 | 9,89% |
| Perplexity | PerplexityBot, Perplexity-User | 715 | 9,86% |
| Diffbot | Diffbot | 684 | 9,44% |
| You.com | YouBot | 563 | 7,77% |
| AI2 (Allen AI) | AI2Bot | 487 | 6,72% |
| DuckDuckGo | DuckAssistBot | 482 | 6,65% |
Common Crawl è il singolo bersaglio più colpito, anche se è un archivio web non profit, non un operatore di LLM. Il motivo è il leverage: CCBot alimenta quasi tutti i modelli open-weight e una quota consistente di quelli chiusi. Bloccare prima CCBot è la regola a copertura più ampia che un editore possa scrivere.
OpenAI, Anthropic e ByteDance si collocano tra il 14% e il 16%. Il vantaggio di OpenAI è in parte un artefatto di conteggio (tre bot OpenAI contro un singolo bot di ByteDance). Il 14,9% di Bytespider è l’effetto "comportamento Bytespider" — è stato documentato che ignora robots.txt dal 2024, e gli editori lo bloccano come segnale pubblico, non perché temano TikTok.
Meta, Google, Amazon, Apple tra il 12% e il 14% rappresentano la seconda fascia — scritta in chiave difensiva più che come presa di posizione. I vendor minori (Webz.io, Cohere, Perplexity, Diffbot, You.com, AI2, DuckDuckGo) al 6–10% vengono trainati soprattutto dal pavimento del 3,8% delle regole catch-all; le regole esplicite per loro si collocano nell’intervallo 1–4%.
xAI (Grok), Mistral e la maggior parte dei laboratori modello europei/cinesi non compaiono nella tabella — non hanno pubblicato UA documentati per crawler di training. L’attuale ecosistema robots.txt è un dialogo tra vendor USA/cinesi che hanno lanciato UA e publisher USA/UE che hanno scritto regole; i vendor che non hanno lanciato UA restano invisibili alla negoziazione.
Risultato 4 — CCBot è il nuovo fulcro, non GPTBot
L’ordine dei bot nei top-10k è questo:
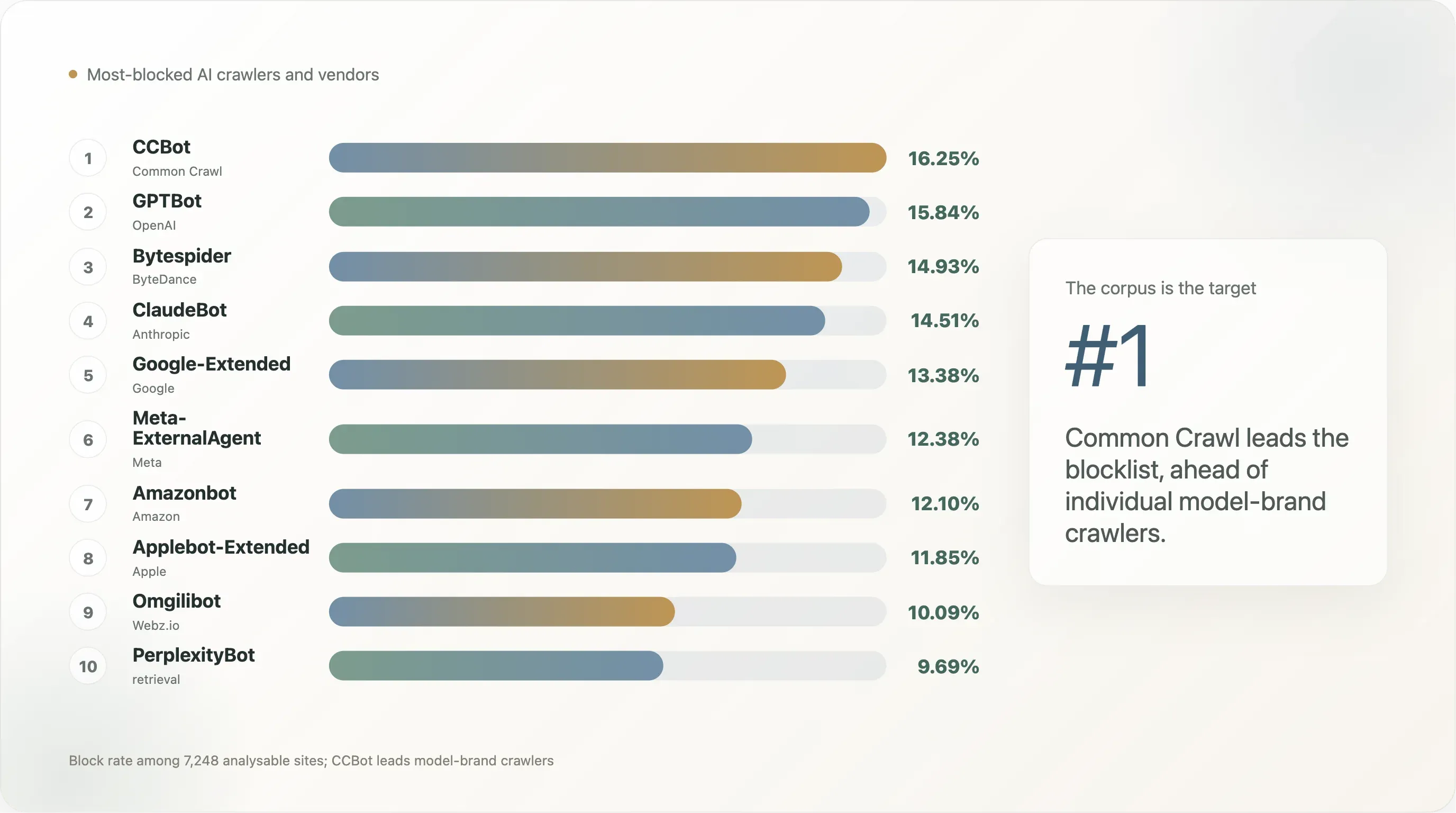
| Posizione | Bot | Tasso di blocco | Tasso di regola esplicita |
|---|---|---|---|
| 1 | CCBot (Common Crawl) | 16,25% | 12,90% |
| 2 | GPTBot (OpenAI) | 15,84% | 12,72% |
| 3 | Bytespider (ByteDance) | 14,93% | 11,35% |
| 4 | ClaudeBot (Anthropic) | 14,51% | 11,13% |
| 5 | Google-Extended | 13,38% | 10,18% |
| 6 | Meta-ExternalAgent | 12,38% | 8,95% |
| 7 | Amazonbot | 12,10% | 8,66% |
| 8 | Applebot-Extended | 11,85% | 8,72% |
| 9 | Omgilibot | 10,09% | 5,31% |
| 10 | anthropic-ai (deprecato) | 9,99% | 6,55% |
| 11 | cohere-ai | 9,89% | 6,42% |
| 12 | PerplexityBot | 9,69% | 6,40% |
| 13 | Diffbot | 9,44% | 5,95% |
| 14 | ChatGPT-User (inference) | 8,90% | 5,73% |
| 15 | YouBot (inference) | 7,77% | 4,29% |
| 16 | OAI-SearchBot (inference) | 6,83% | 3,66% |
| baseline | Googlebot | 2,18% | — |
| baseline | Bingbot | 2,27% | — |
La storia che racconta questa tabella è che il bot che il web pubblico blocca per primo non è il brand del modello — è il corpus. L’archivio Common Crawl da 250 miliardi di pagine è stato il singolo input di training più grande per GPT-3, GPT-4, Llama 1 / 2 / 3, Falcon, Mistral, BLOOM e la maggior parte dei modelli open-weight rilasciati dal 2020 in poi. Un sito che vuole uscire dal "finire nel prossimo frontier model" ottimizza bloccando prima CCBot — una volta fuori da Common Crawl, sei di fatto escluso gratuitamente dalla pipeline di training open-source. GPTBot e ClaudeBot vengono dopo perché sono il front-end visibile di due prodotti commerciali specifici; l’UA a livello di corpus è il bersaglio strutturale.
Anche i bot AI più in basso in classifica sono istruttivi. Omgilibot al 10% è insolitamente alto per un bot di cui la maggior parte dei lettori non avrà mai sentito parlare — è gestito da Webz.io, un broker di contenuti e dati che vende archivi web agli operatori di LLM, e un gruppo consistente di testate ha iniziato a nominarlo esplicitamente nei propri file. AI2Bot al 6,7% (e la corrispondente regola Ai2Bot-Dolma sui siti Squarespace) suggerisce che anche la comunità accademica degli LLM viene segnalata da editori che non distinguono necessariamente tra "crawler di ricerca non profit" e "crawler commerciale".
Il cluster di inference — ChatGPT-User, OAI-SearchBot, YouBot, Perplexity-User — si colloca 4–8 punti percentuali sotto il cluster di training. Quel divario è la risposta a una questione di policy di lungo corso: sì, i siti ad alto traffico distinguono tra un bot che raccoglie dati per il training futuro del modello e un bot che fa retrieval live per rispondere subito alla domanda di un utente. Non sempre fanno la distinzione (le regole catch-all non la fanno), ma una quota significativa scrive regole che colpiscono specificamente il lato training.
Risultato 5 — Il 14% blocca CCBot ma lascia Googlebot benvenuto — il pattern "blocca il corpus, tieni la ricerca"
La regola selettiva più adottata nel top-10k:
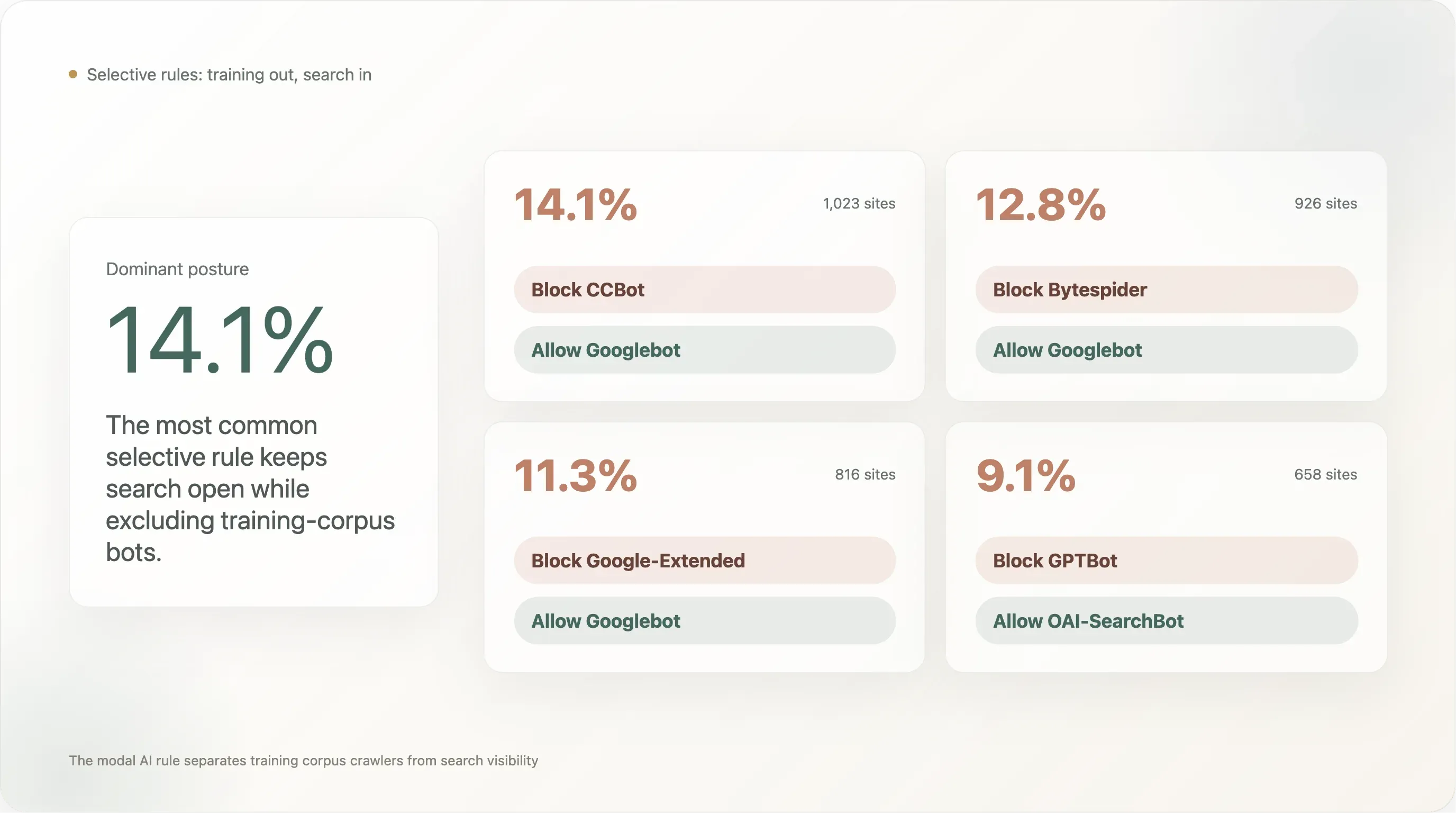
| Pattern di regola | Siti | % del campione analizzabile |
|---|---|---|
Blocca CCBot, consenti Googlebot | 1.023 | 14,11% |
Blocca Bytespider, consenti Googlebot | 926 | 12,78% |
Blocca Google-Extended, consenti Googlebot | 816 | 11,26% |
Blocca GPTBot, consenti OAI-SearchBot | 658 | 9,08% |
Blocca GPTBot, consenti ChatGPT-User | 525 | 7,24% |
Blocca CCBot, consenti PerplexityBot | 519 | 7,16% |
Blocca anthropic-ai, consenti ClaudeBot | 59 | 0,81% |
Il pattern più diffuso (14,1%) è "blocca Common Crawl, mantieni la visibilità su Google Search." Il secondo (12,8%) è "blocca Bytespider, mantieni la visibilità su Google Search" — cioè blocca il crawler di ByteDance segnalato per la reputazione, lasciando intatto il baseline di ricerca legittimo. Il terzo (11,3%) è "blocca la UA di training AI di Google ma tieni la UA di ricerca di Google," che è esattamente la separazione per cui Google ha progettato Google-Extended: l’editore rinuncia al training di Bard / Gemini senza perdere il posizionamento nella ricerca.
Questi tre numeri, insieme, descrivono la postura di policy dominante sul web top-10k: vietare i bot del corpus di training, lasciare intatti i bot di ricerca e di inference. Il pattern minoritario "vietare il training ma consentire la specifica UA di live-retrieval di questo LLM" — GPTBot ✗ / ChatGPT-User ✓ al 7,2% — esiste, ma è più piccolo dei tagli a livello di corpus.
La riga anthropic-ai / ClaudeBot allo 0,81% riflette la deprecazione dell’UA da parte di Anthropic nel 2024: ClaudeBot ora serve sia training sia inference, eliminando la possibilità di espressione pulita "blocca il training, consenti le citazioni" che la vecchia UA anthropic-ai permetteva per Claude. Questa è la decisione di design dell’UA meno discussa del 2024–2025 — ha rimosso un’intera classe di espressioni di policy da robots.txt.
Risultato 6 — News nel dettaglio: per paese e lingua
Quando suddividiamo la categoria news per TLD di country code — tenendo presente che significa .de per news tedesche, .fr per news francesi ecc., non la lingua effettivamente servita — la variazione intra-news è più ampia della variazione tra news e resto del web:
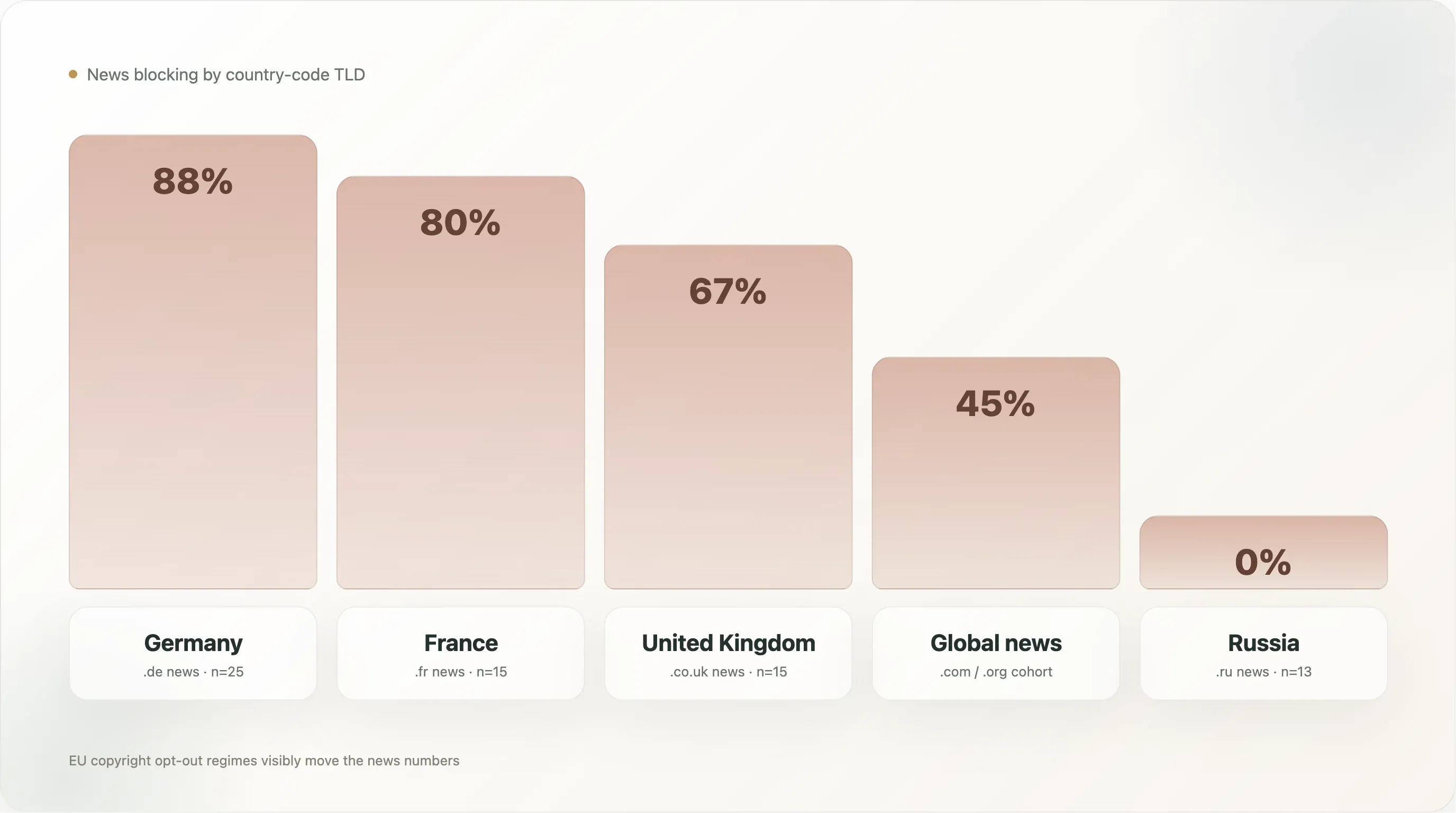
| Paese (solo news) | n | Any AI block | Esplicito |
|---|---|---|---|
🇩🇪 Germania (.de) | 25 | 88,0% | 88,0% |
🇫🇷 Francia (.fr) | 15 | 80,0% | 80,0% |
🇬🇧 Regno Unito (.co.uk) | 15 | 66,7% | 53,3% |
🇪🇸 Spagna (.es) | 5 | 60,0% | 60,0% |
🇮🇹 Italia (.it) | 13 | 53,8% | 53,8% |
News globali (.com/.org/etc) | 500 | 45,0% | 42,8% |
🇵🇱 Polonia (.pl) | 7 | 42,9% | 42,9% |
🇯🇵 Giappone (.jp) | 12 | 25,0% | 25,0% |
🇷🇺 Russia (.ru) | 13 | 0,0% | 0,0% |
🇬🇷 Grecia (.gr) | 6 | 0,0% | 0,0% |
Le news tedesche sono il sotto-segmento con il blocco più alto in tutto il dataset, all’88%, e sono per l’88% esplicite — in pratica non esiste alcuna testata tedesca nel top 10k che lasci i crawler di training AI raggiungere il proprio archivio. Il cohort è guidato da Spiegel, Bild, Welt, Zeit, FAZ, Süddeutsche, Heise, Golem, Stern, Focus — l’intero establishment dell’editoria mainstream tedesca, oltre a publisher tech che hanno scritto regole in autonomia. L’infrastruttura politica alla base è densa: VG Media, l’organizzazione tedesca per i diritti collettivi degli editori, è stata il gruppo di querelanti più aggressivo nel contenzioso UE sul copyright AI, e l’articolo 4 della Direttiva UE è recepito nel diritto tedesco come §44b UrhG con un linguaggio esplicito di opt-out leggibile da macchina. Quando sono arrivati i vendor AI, gli editori tedeschi erano più pronti di qualsiasi altro gruppo nazionale a tradurre quella postura giuridica in regole robots.txt.
Le news francesi all’80% vengono subito dopo. L’ambiente giuridico francese è simile (Direttiva 2019/790 trasposta nel diritto francese), e il comportamento del cohort è simile — lemonde.fr, lefigaro.fr, liberation.fr, lequipe.fr, 20minutes.fr, ouest-france.fr bloccano tutti, con il file di Le Monde che cita inoltre il droit du producteur de base de données francese (articolo L 342-1 del Code de la propriété intellectuelle) come base giuridica domestica parallela. La Francia ha inoltre il vincolo aggiuntivo di una sentenza del tribunale commerciale di Parigi nel 2024 che ha stabilito che gli opt-out basati su robots.txt sono notifica sufficiente ai sensi dell’articolo 4; questo fornisce un sostegno giurisprudenziale diretto che nessun’altra giurisdizione ha ancora eguagliato.
Il Regno Unito al 67% è più basso, e il motivo è che diversi grandi publisher britannici (thesun.co.uk, dailymail.co.uk, mirror.co.uk) usano blocchi deny-all con User-agent: * invece di regole specifiche per AI, abbassando il dato esplicito al 53%. L’effetto aggregato è lo stesso — questi siti non consentono il crawling AI — ma la policy è espressa come "nessun robot tranne questa specifica allowlist di motori di ricerca" piuttosto che come disallow per bot AI nominati. Anche l’impalcatura giuridica è più debole: dopo Brexit, il Regno Unito ha ereditato la logica dell’articolo 4 ma la giurisprudenza domestica corrispondente è più scarna.
Le news russe allo 0% sono la riga più sorprendente. Tredici siti news in dominio russo nel campione (dzen.ru, rbc.ru, ria.ru, kommersant.ru, tass.ru, lenta.ru, gazeta.ru, interfax.ru, kp.ru, tass.com, ecc.) — nessuno blocca alcun crawler AI. La spiegazione più probabile: l’addestramento dei LLM in lingua russa è dominato dai modelli stile GPT di Yandex (che usano crawler interni a Yandex, non Common Crawl), l’ambiente del copyright russo non ha recepito un equivalente dell’articolo 4, e i principali editori russi vedono i LLM occidentali come un non-problema (i controlli alle esportazioni USA limitano già i servizi OpenAI/Anthropic in Russia) e Yandex come stakeholder domestico più che come avversario. La postura di policy è semplicemente diversa.
Le news giapponesi al 25% mostrano un terzo schema. Il Giappone ha eccezioni esplicite per il text and data mining nella legge sul copyright nazionale (articolo 30-4 della Copyright Act giapponese, emendata nel 2018) che sono più permissive dell’articolo 4 della Direttiva UE — consentono il TDM per finalità di "non enjoyment" incluse le attività di training AI senza richiedere il consenso del titolare. Gli editori giapponesi hanno meno leva giuridica per l’opt-out e i corrispondenti tassi robots.txt sono più bassi. Quel 25% che blocca è composto soprattutto dai publisher più grandi e più cosmopoliti (asahi.com, nikkei.com), posizionati come internazionali più che domestici.
I dati cross-country sulle news sono la prova più chiara del report che il regime giuridico, non la tecnologia o l’economia del settore, è il principale motore del blocco AI. I cohort news UE si collocano tra il 54% e l’88%; i cohort news non UE (Russia, Giappone, il cohort globale .com) variano dallo 0% al 45%. Il picco dell’88% è nel paese con l’implementazione più matura dell’articolo 4; il pavimento dello 0% è nel paese con, di fatto, nessuna legge specifica sulla policy AI.
Risultato 7 — UE contro il resto: un gap di 16 punti
Allargando la lente per paese, la divisione UE vs resto è netta:
| Regione | n | Any AI block | Esplicito |
|---|---|---|---|
ccTLD UE (.fr, .de, .es, .it, .nl, .pl, .se, .dk, .fi, .be, .at, .cz, .hu, .ro, .gr, .pt, .ie, .sk, .bg) | 617 | 35,2% | 33,9% |
ccTLD nazionali non UE (.uk, .jp, .kr, .cn, .ru, .br, .in, .au, .mx, .ca, .tr, .ar, .cl, .co, .pe) | 897 | 17,2% | 13,6% |
Globale (.com, .net, .org, ecc.) | 5.734 | 19,2% | 15,7% |
I siti con ccTLD UE bloccano l’AI al doppio del tasso del cohort nazionale non UE e a quasi il doppio del baseline globale .com. La differenza è coerente tra gli stati membri UE (nessun singolo paese guida la media) e coerente tra i settori (.de news all’88%, .de SaaS circa 12%, .de e-commerce circa 25% — tutti valori superiori ai rispettivi equivalenti globali).
Abbiamo trovato 275 file robots.txt nel top-10k che citano esplicitamente la Direttiva 2019/790 nei commenti — circa il 3,8% del campione analizzabile. Il cohort è dominato dagli editori UE ma si estende oltre: diversi brand news statunitensi (in particolare il NYT, che cita direttamente "Art. 4 of the EU Directive"), alcuni siti UK e una manciata di grandi destinazioni e-commerce europee riproducono il linguaggio legale. 87 file menzionano "TDM" o "text and data mining" per nome. 460 file contengono una qualche forma di linguaggio di riserva dei diritti d’autore ("expressly opts out," "all rights reserved," "no commercial use," "no machine learning") anche quando non citano una norma specifica.
Due osservazioni più granulari da questa sezione:
L’effetto UE non riguarda solo le news. Tenendo costante il settore news, anche i siti UE non-news bloccano l’AI a tassi più alti rispetto ai siti non UE non-news (circa 28% contro 14%). Una quota piccola ma reale di SaaS, e-commerce e academia UE ha interiorizzato il frame dell’articolo 4 per i propri settori.
Il linguaggio in stile UE sta diventando un template di fatto anche fuori dall’UE. Il template robots.txt gestito da Cloudflare — adottato a livello globale — cita esplicitamente "ARTICLE 4 OF THE EUROPEAN UNION DIRECTIVE 2019/790" nel proprio boilerplate. Un sito statunitense che attiva l’impostazione "Block AI Bots" di Cloudflare sta, senza necessariamente saperlo, rivendicando una riserva statutaria dei diritti in stile UE. Questo è uno degli artefatti più interessanti di deriva normativa che abbiamo trovato: un concetto giuridico europeo viene globalizzato attraverso l’interfaccia prodotto di un provider infrastrutturale statunitense.
Risultato 8 — Template e origini dei template
La ripartizione dei template tra i 6.638 siti che hanno restituito un robots.txt analizzabile:
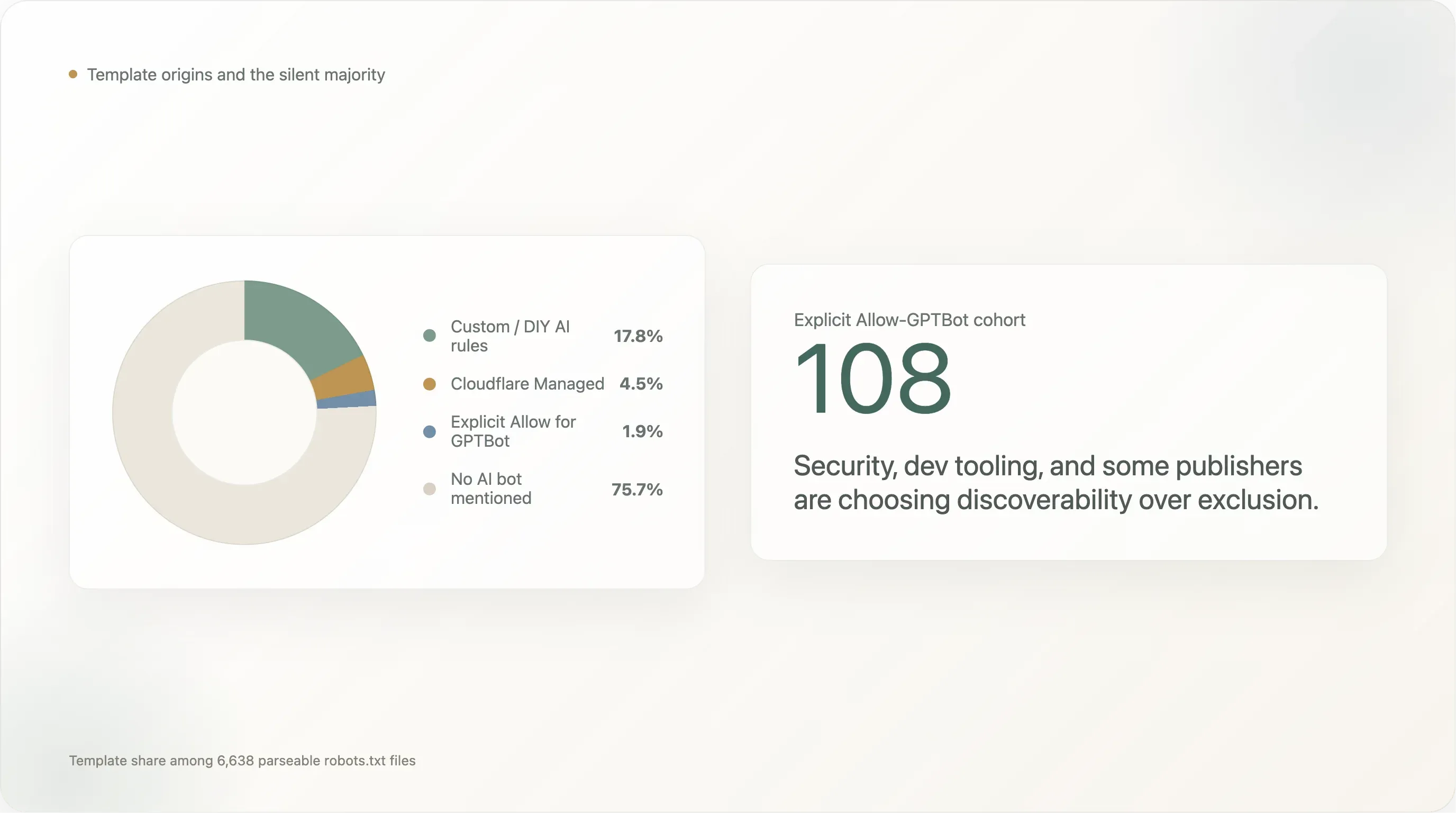
| Template | Siti | Quota |
|---|---|---|
| Nessun bot AI menzionato (default stile Shopify, Yoast, scritto a mano senza considerare l’AI) | 5.024 | 75,7% |
| Regole AI custom / fai-da-te | 1.183 | 17,8% |
Cloudflare Managed (Content-Signal: search=yes,ai-train=no) | 302 | 4,5% |
Allow: / esplicito per GPTBot | 124 | 1,9% |
| Default Squarespace (28 UA AI nel blocco con restrizione per percorso) | 5 | 0,1% |
Le regole fai-da-te dominano con il 17,8%. Il cohort dei blocker scritti in autonomia è guidato da tutte le piattaforme social (facebook.com, twitter.com, linkedin.com, whatsapp.com, tiktok.com, snapchat.com, pinterest.com, x.com, chatgpt.com stesso), dalle maggiori destinazioni e-commerce (amazon.com, amazonvideo.com), dai principali brand news (nytimes.com, cnn.com, bbc.com, theguardian.com, forbes.com, reuters.com, bbc.co.uk, t-online.de, weather.com), dai principali siti streaming/media (netflix.com, vimeo.com, soundcloud.com, imdb.com) e da una lunga coda di siti di servizi professionali (canva.com, medium.com).
Cloudflare Managed è al 4,5% — molto più alto della penetrazione dello stesso template nella parte altissima della curva e più basso della sua penetrazione nella coda lunga fuori dall’intervallo del report. Il template è adottato soprattutto nella fascia 1001–10000 (4–5%) ed è sostanzialmente assente nella parte molto alta della curva (Top 100: 1 sito lo usa; Top 101–1000: 5 siti). I grandi property globali scrivono le proprie regole; la coda lunga usa il toggle.
Alcuni siti Cloudflare Managed specifici da segnalare. cloudflare.com usa il template su se stesso, coerentemente con una logica dogfooding del proprio prodotto sul proprio dominio. theatlantic.com usa il template — l’unico grande brand news USA che abbiamo trovato a non scrivere una regola custom. spankbang.com usa il template — il sito adult con ranking più alto ad adottare un blocco AI iniettato da Cloudflare. linktr.ee usa il template, bloccando il training AI su tutto l’ecosistema creator ospitato da Linktree con una sola decisione di vendor. launchpad.net, nexusmods.com, vinted.fr, cookielaw.org, rustdesk.com e una lunga lista di property media più piccole completano il cohort visibile Cloudflare Managed.
Il pattern di adozione di Cloudflare è la prova più concreta che una larga parte della "policy AI del web" viene decisa dai provider infrastrutturali. La quota assoluta è piccola (4,5%) ma strutturalmente importante: il template è quello che Cloudflare spedisce di default, e la traiettoria del default-on nei prossimi 12 mesi è in salita. Se Cloudflare attiva il toggle di default per i nuovi account, il tasso globale di blocco si muove in modo sostanziale senza che nessun editore prenda una decisione.
Il default Squarespace (5 siti nel top-10k, ma un cohort molto più ampio fuori dal nostro campione) segue un pattern diverso: Squarespace pubblica un robots.txt che nomina 28 bot AI in un unico blocco, ma quei bot ereditano le restrizioni per percorso di User-agent: * invece di ricevere un divieto totale del sito. I crawler AI possono accedere a /, alla homepage, alle pagine prodotto, al blog. Semplicemente non possono accedere a /config o /account. In precedenza abbiamo segnalato questo come fonte di falsi positivi nei report di terze parti sui siti Squarespace; la stessa avvertenza vale anche qui.
Risultato 9 — La policy AI è uniforme lungo la distribuzione di ranking
L’intuizione convenzionale per uno studio di questo tipo è che i siti più visitati avrebbero la policy AI più aggressiva — hanno di più da perdere dallo spiazzamento del training, più capacità legale, più attenzione pubblica. I dati non supportano questa intuizione.
| Fascia di rank | n | Any AI block | Esplicito | Cloudflare Managed |
|---|---|---|---|---|
| Top 100 | 67 | 22,4% | 17,9% | 1 sito |
| Top 101–1.000 | 598 | 22,9% | 19,2% | 5 siti |
| Top 1.001–5.000 | 2.810 | 19,0% | 15,3% | 99 siti |
| Top 5.001–10.000 | 3.773 | 20,8% | 17,8% | 197 siti |
Le quattro fasce stanno tutte tra il 19% e il 23%. Il Top 100 non è più aggressivo della coda lunga tra 5001 e 10000. Il dato principale sembra essere una proprietà del web pubblico nel 2026, non un segnale della dimensione o della notorietà di un singolo sito.
Due fattori contribuiscono. Primo, la testa della curva è dominata da domini di infrastruttura / SaaS / search / portal (Microsoft, Apple, Google, ecc.) che, di per sé, hanno tassi di blocco AI bassi. Secondo, la coda lunga include una quota elevata di editori news regionali e siti sotto giurisdizione UE che — come mostrato nei Risultati 6 e 7 — bloccano l’AI in modo più aggressivo della media globale. I due effetti si compensano grossomodo, e il risultato netto è un headline uniforme.
La colonna Cloudflare Managed invece varia lungo la curva. Il Top 1000 ha 6 siti gestiti da Cloudflare (1,0%); il Top 1001–10000 ne ha 296 (5,7%). I grandi siti scrivono da sé; la coda lunga usa il toggle del vendor. Questo è l’unico segnale realmente dipendente dal rank nel dataset, e suggerisce che scendendo lungo la curva del traffico, dalla testa del web verso la coda lunga, la quota di policy AI decisa dal vendor invece che dall’editore cresce in modo costante. Ci aspettiamo che questo gradiente continui oltre il top 10k, verso il top 100k e oltre.
Risultato 10 — Cinque anatomie: come appare davvero robots.txt quando è una policy
I numeri descrivono la forma del dataset; il carattere reale della "policy AI sul web pubblico" si vede meglio leggendo file specifici. Eccone cinque che meritano attenzione, scelti per coprire l’intero spazio delle policy.
Anatomia 1 — New York Times (nytimes.com)
Le prime 14 righe di nytimes.com/robots.txt:
1# New York Times content is made available for your personal, non-commercial
2# use subject to our Terms of Service here:
3# https://help.nytimes.com/hc/en-us/articles/115014893428-Terms-of-Service.
4# Use of any device, tool, or process designed to data mine or scrape the content
5# using automated means is prohibited without prior written permission from
6# The New York Times Company. Prohibited uses include but are not limited to:
7# (1) text and data mining activities under Art. 4 of the EU Directive on Copyright in
8# the Digital Single Market;
9# (2) the development of any software, machine learning, artificial intelligence (AI),
10# and/or large language models (LLMs);
11# (3) creating or providing archived or cached data sets containing our content to others; and/or
12# (4) any commercial purposes.
13# Contact https://nytlicensing.com/contact/ for assistance.Questo è robots.txt come prova legale. Il file è strutturato per poter essere usato come prova nel contenzioso NYT v. OpenAI di cui è parte. I riferimenti all’"Art. 4 of the EU Directive" — da parte di un editore USA — illustrano l’osservazione del Risultato 7 secondo cui i frame normativi UE stanno filtrando nel discorso globale. Il divieto esplicito di "creating or providing archived or cached data sets" punta dritto a Common Crawl. Il file supera le 60 righe e contiene blocchi User-agent nominati per GPTBot, OAI-SearchBot, ChatGPT-User, anthropic-ai, ClaudeBot, CCBot, Google-Extended, Applebot-Extended, Bytespider, Diffbot, Meta-ExternalAgent, Amazonbot, Omgili, Omgilibot e una mezza dozzina di altri — ogni bot nominato ha il proprio Disallow: /.
Anatomia 2 — Der Spiegel (spiegel.de) — permissioning AI a livello di sezione
Der Spiegel è il robots.txt più sofisticato dal punto di vista operativo che abbiamo trovato nell’intero dataset. Il blocco rilevante:
1# TLP-6507: Testweise Freischaltung der OpenAI-Suchcrawler fuer ausgewaehlte Bereiche
2User-agent: OAI-SearchBot
3Allow: /ausland/
4Allow: /partnerschaft/
5Allow: /gesundheit/
6Allow: /familie/
7Allow: /reise/
8Allow: /psychologie/
9Allow: /stil/
10Disallow: /
11User-agent: ChatGPT-User
12Allow: /ausland/
13Allow: /partnerschaft/
14Allow: /gesundheit/
15Allow: /familie/
16Allow: /reise/
17Allow: /psychologie/
18Allow: /stil/
19Disallow: /Il commento si traduce come "Attivazione sperimentale dei crawler di ricerca OpenAI per sezioni selezionate." Spiegel ha messo in whitelist sette categorie specifiche di contenuto — notizie internazionali, partnership, salute, famiglia, viaggi, psicologia e lifestyle — per le UA di inference OpenAI, bloccando tutto il resto. Le sezioni politiche, le news nazionali tedesche e il giornalismo investigativo sono esplicitamente escluse. Più avanti nel file, Common Crawl, Bytespider, Cohere, Webzio-Extended e le altre UA di training ricevono un Disallow: / completo.
Questo è robots.txt come policy editoriale a livello di sezione. La teoria implicita è che i contenuti lifestyle hanno un rischio più basso di displacement del training e un upside più alto in termini di citazione via inference, quindi Spiegel consente all’AI di attingere a quelle sezioni; la politica e l’investigativo sono il fossato difensivo, quindi l’AI è esclusa. Non abbiamo visto questo pattern altrove. Implica un livello di coordinamento interno tra editoriale, legale e infrastruttura che la maggior parte delle redazioni non ha ancora raggiunto. Ci aspettiamo che questo tipo di espressione granulare, a livello di sezione, si diffonda nel 2026–2027 — il file di Spiegel è sostanzialmente un indicatore anticipatore.
Anatomia 3 — BBC (bbc.com) — la forma della dichiarazione di policy
Il robots.txt della BBC inizia con:
1# version: ec59bd036e5138eb4831a9ed44447b1ff310e235
2# The BBC's Terms of Use: https://www.bbc.co.uk/terms
3# - Explain the rules for using our services
4# - Tell you what you can do with our content
5#
6# In short: Please use our site like a human, not a robot.
7# That means:
8# - No scraping, crawling, or systematic extraction of content
9# - No use of BBC content for training or fine-tuning AI models, including LLMs
10# - No retrieval-augmented generation (RAG), AI-powered search, agentic AI or
11# grounding using BBC content
12# - No creating datasets from BBC content
13# - No text and data mining (TDM) under Article 4 of the EU Directive on Copyright
14# - No using BBC content to create summaries for your own use
15# - No business use without permission
16# - The BBC reserves all rights in its content and expressly opts out of any
17# statutory exceptions in any jurisdiction for text and data mining,
18# as permitted by law
19#
20# TL;DR: Browse, read, watch, enjoy - like a human.La BBC versione e data il proprio robots.txt (# version: ec59bd... è un hash di commit git), proibisce gli otto usi specifici dell’AI che i legali della BBC stanno monitorando e chiude con un riepilogo in una voce che richiama il brand BBC. La frase "expressly opts out of any statutory exceptions in any jurisdiction" è una riserva globale deliberata — sta dicendo non ci fidiamo di un singolo regime giuridico per darci la protezione che vogliamo, quindi stiamo esercitando l’opt-out ovunque in una volta sola. Questo è il robots.txt più redatto del dataset, e si legge più come un comunicato stampa che come un file di configurazione.
Anatomia 4 — WordPress.org — il benvenuto esplicito
Confrontiamo tutto quanto sopra con wordpress.org:
1User-agent: GPTBot
2Allow: /
3User-agent: ClaudeBot
4Allow: /
5User-agent: anthropic-ai
6Allow: /
7User-agent: Google-Extended
8Allow: /
9User-agent: Applebot-Extended
10Allow: /
11User-agent: PerplexityBot
12Allow: /
13User-agent: Bytespider
14Allow: /
15User-agent: CCBot
16Allow: /
17User-agent: Copilot
18Allow: /WordPress.org opta esplicitamente per nove crawler di training AI, inclusi i tre (Bytespider, CCBot, anthropic-ai) che vengono bloccati più spesso altrove. La teoria implicita è che la documentazione e l’ecosistema dei plugin di WordPress siano un bene pubblico il cui valore aumenta quando gli assistenti AI possono rispondere a domande su di esso. Ogni volta che qualcuno chiede a Claude "come configuro i permalink in WordPress?" e Claude è stato addestrato su wordpress.org/documentation/, la missione di WordPress è stata servita. La Foundation sembra aver deciso che essere nel corpus di training di tutti i modelli è un vantaggio strategico, e ha usato la grammatica espressiva del file per dirlo.
Anatomia 5 — The Verge (theverge.com) — il modello ibrido sponsorizzato
Un altro pattern merita di essere mostrato. The Verge struttura le proprie regole AI come Disallow: / \ Allow: /sp/:
1User-agent: GPTBot
2Allow: /
3User-agent: Applebot
4Allow: /
5User-agent: Google-Extended
6Disallow: /
7Allow: /sp/
8User-agent: anthropic-ai
9Disallow: /
10Allow: /sp/
11User-agent: Bytespider
12Disallow: /
13Allow: /sp/
14User-agent: CCBot
15Disallow: /
16Allow: /sp/
17User-agent: ChatGPT-User
18Disallow: /
19Allow: /sp/
20User-agent: ClaudeBot
21Disallow: /
22Allow: /sp/Il path /sp/ è la sezione contenuti sponsorizzati / partner di The Verge. I contenuti editoriali sono bloccati dal training AI; i contenuti sponsorizzati sono consentiti. La logica economica è lineare: gli sponsor pagano perché i loro contenuti siano scopribili, anche tramite l’AI; il flagship editoriale è il fossato difensivo. GPTBot è completamente aperto (presumibilmente per una relazione diretta con OpenAI), Applebot è completamente aperto come baseline di ricerca e gli altri ricevono il trattamento ibrido. Questa è l’unica struttura di "tiered AI access" di questo tipo che abbiamo trovato.
Questi cinque file descrivono il range attuale della policy AI in robots.txt. La maggior parte dei file nel top 10k non assomiglia a nessuno di essi — sono silenziosi oppure usano un template vendor. Quelli che li assomigliano sono scritti da persone che hanno deciso che il file valga la pena di essere letto con attenzione.
Una nota sulla scala dei file: la mediana del corpo robots.txt nel nostro campione è 858 byte — troppo piccola per codificare una policy AI significativa. Il lato destro della distribuzione è dove vivono le regole: 1.005 siti (15,3%) hanno un file più grande di 5 KB, 273 più grande di 20 KB, e il massimo era 248 KB. 460 file contengono linguaggio di riserva dei diritti d’autore; 275 citano la Direttiva UE 2019/790 per nome. Nel 2026 un robots.txt è sempre più spesso un documento versionato e revisionato da legali, non una semplice riga di configurazione.
Risultato 11 — 108 siti danno esplicitamente il benvenuto a GPTBot
Un cohort piccolo ma visibile scrive una regola User-agent: GPTBot \n Allow: / — l’inverso del più discusso "Disallow GPTBot". Il conteggio completo nel nostro campione è 108 siti con un Allow esplicito per GPTBot sulla root path. I primi 25 per rank Tranco:
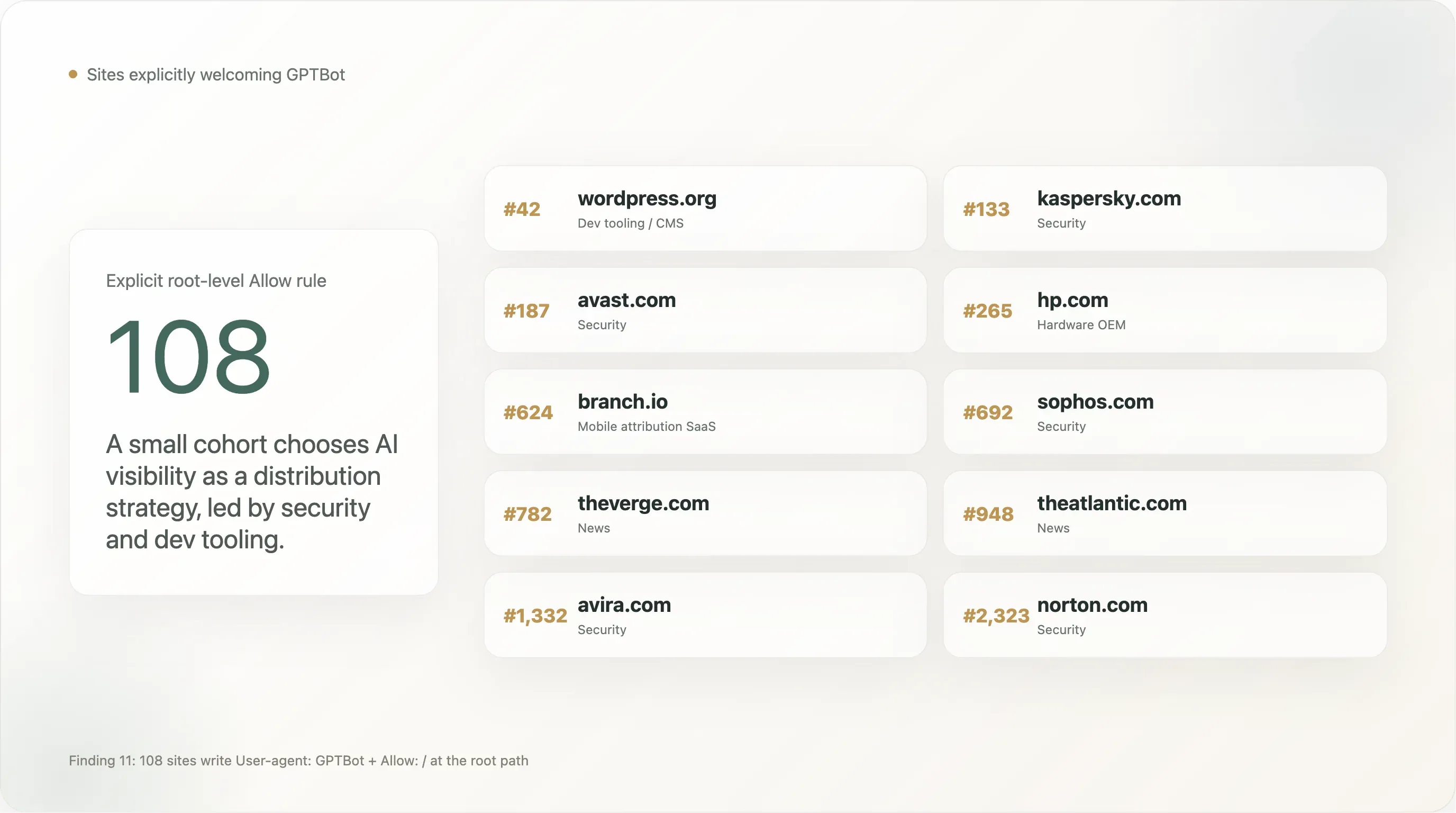
| Rank | Dominio | Settore |
|---|---|---|
| 42 | wordpress.org | Strumenti per sviluppatori / CMS |
| 133 | kaspersky.com | Sicurezza |
| 187 | avast.com | Sicurezza |
| 265 | hp.com | OEM hardware |
| 624 | branch.io | SaaS di attribution mobile |
| 692 | sophos.com | Sicurezza |
| 782 | theverge.com | News |
| 905 | rambler.ru | Portale russo |
| 945 | kleinanzeigen.de | Marketplace tedesco |
| 948 | theatlantic.com | News |
| 1.092 | lge.com | LG Electronics |
| 1.300 | justdial.com | Ricerca locale indiana |
| 1.332 | avira.com | Sicurezza |
| 1.412 | youm7.com | News egiziane |
| 1.530 | goodreturns.in | Finanza indiana |
| 1.621 | publi24.ro | Annunci classificati rumeni |
| 1.807 | geocomply.com | SaaS di compliance |
| 1.908 | nba.com | Sport |
| 1.956 | oneindia.com | News indiane |
| 1.974 | mindbox.ru | SaaS russo |
| 2.009 | thesun.co.uk | News |
| 2.126 | vox.com | News |
| 2.140 | mgid.com | Native advertising |
| 2.314 | ninjarmm.com | SaaS di gestione IT |
| 2.323 | norton.com | Sicurezza |
Alcuni pattern:
Le aziende di sicurezza sono chiaramente sovrarappresentate. Kaspersky, Avast, Sophos, Avira, Norton, NinjaRMM consentono esplicitamente GPTBot. È una mossa di distribuzione deliberata: quando un utente chiede a ChatGPT "qual è il miglior antivirus per il mio PC Windows?", avere il brand nel corpus di training del modello influenza direttamente la raccomandazione. La sicurezza è una delle poche categorie B2C in cui la ricerca AI sta già sostituendo la SEO come canale primario di acquisizione, e questi brand si sono mossi per primi. Ci aspettiamo che il resto del comparto sicurezza segua entro 12 mesi.
Alcuni grandi brand news sono in questa lista, non nella blocklist. The Verge, The Atlantic, Vox, The Sun, NBA.com. Non è una contraddizione — questi publisher sembrano aver deciso che essere citabili dentro la ricerca ChatGPT è più prezioso che essere protetti dal training, e hanno scritto la regola Allow esplicita per difendersi da un futuro blocco eccessivo da parte del loro CDN o CMS. Confrontare con la postura di NYT / Reuters / BBC / Forbes / Guardian di Disallow esplicito. Entrambe le posizioni sono difendibili; l’industria news non è monolitica.
La presenza de The Sun è notevole perché lo stesso sito usa altrove nel file un deny-all con User-agent: *. La policy di The Sun si legge meglio come "il training AI è vietato, la ricerca AI è consentita, e abbiamo esplicitamente inserito GPTBot in whitelist come eccezione al deny-all per assicurarci che ChatGPT possa rispondere alle domande citando The Sun." Questa è la regola GPTBot-Allow più sofisticata dal punto di vista legale — è un opt-out più un opt-in singolo vendor.
La presenza di WordPress.org è la singola voce più rilevante della lista. Una quota non trascurabile dell’ecosistema CMS open source globale punta a WordPress.org per la documentazione o ospita plugin provenienti da lì. Consentendo esplicitamente GPTBot in wordpress.org/robots.txt, la WordPress Foundation ha di fatto detto che l’ecosistema documentale di WordPress è aperto al training — con effetti a catena su quanto bene Claude, Gemini e ChatGPT riescano a rispondere alle domande "come faccio a..." su WordPress.
Le restanti 83 voci della lista completa Allow-GPTBot sono una lunga coda di news regionali, vendor di sicurezza più piccoli, piattaforme di annunci nei mercati non anglofoni e SaaS B2B. Per quanto possiamo dire, non esiste alcun coordinamento di settore equivalente "Allow-GPTBot" — la regola viene adottata sito per sito, da operatori che hanno deciso che stare nel corpus è la posizione strategica.
Risultato 12 — llms.txt è a malapena una voce di corridoio a questa scala
llms.txt, il formato alternativo proposto per la scoperta di contenuti friendly per LLM (promosso da Mintlify, Anthropic, Vercel e una manciata di vendor di tool per sviluppatori dalla fine del 2024), ha un’adozione visibile quasi ovunque assente nel nostro campione.
Dei 6.638 siti che hanno restituito un robots.txt analizzabile, 83 (1,15%) menzionano llms.txt — di solito come riga Sitemap: https://example.com/llms.txt. È un valore di due ordini di grandezza inferiore alla stessa metrica misurata su campioni commerce fortemente orientati agli strumenti per sviluppatori, dove i default di Vercel e Mintlify gonfiano l’adozione.
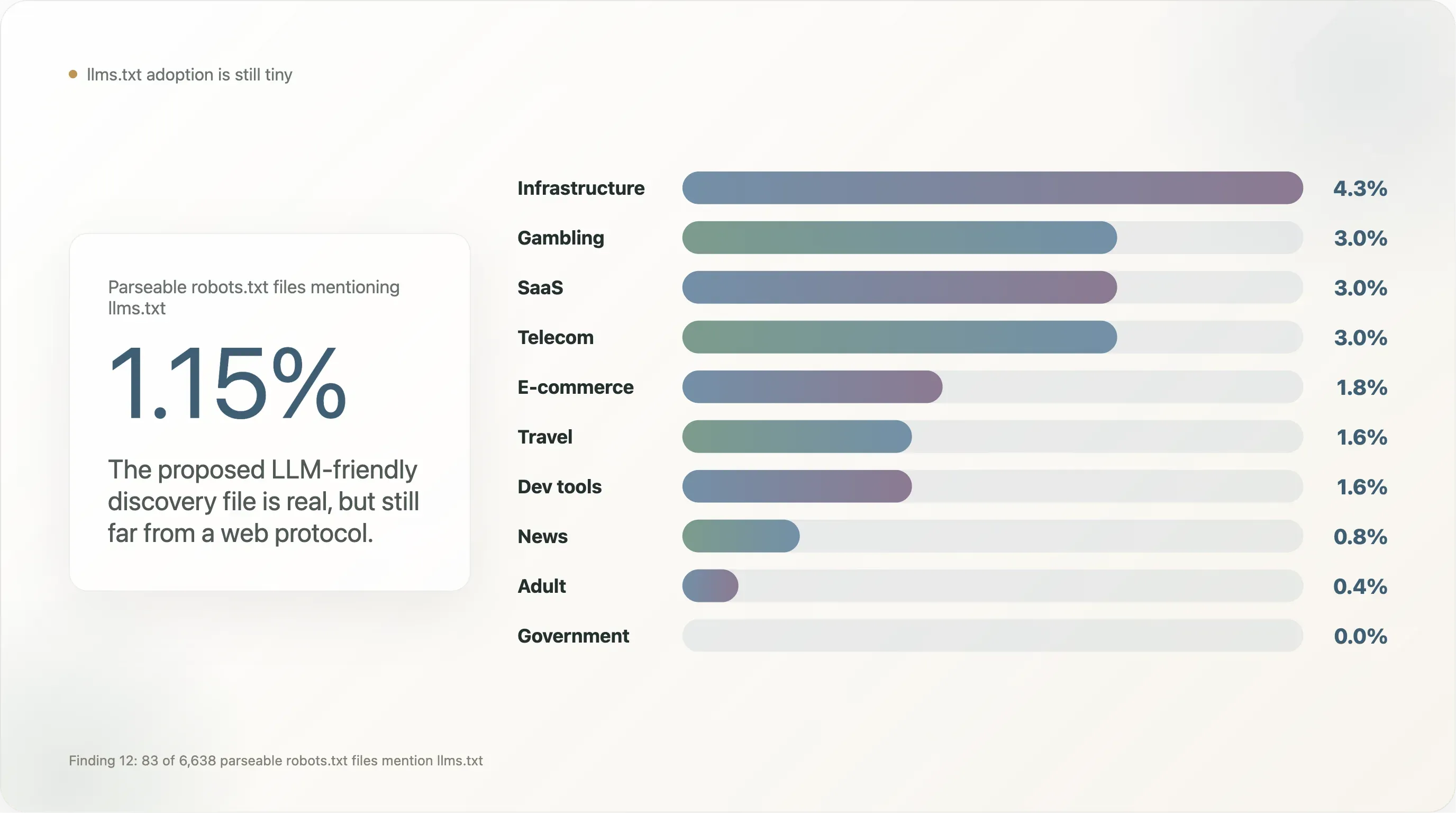
Ripartizione per categoria:
| Settore | n | % che menziona llms.txt |
|---|---|---|
| Infrastructure | 47 | 4,3% |
| Gambling | 100 | 3,0% |
| SaaS | 369 | 3,0% |
| Telecom | 33 | 3,0% |
| E-commerce | 224 | 1,8% |
| Travel | 64 | 1,6% |
| Dev tools | 129 | 1,6% |
| News | 650 | 0,8% |
| Adult | 254 | 0,4% |
| Government | 172 | 0,0% |
| Academia | 268 | 0,0% |
| Search | 12 | 0,0% |
llms.txt è concentrato nel SaaS vicino al mondo dev-tooling, nel gambling (che adotta più rapidamente delle altre industrie regolamentate i nuovi campi robots.txt perché dispone di team di compliance abituati ad aggiungere metadati) e nel B2B e-commerce. È notevolmente assente in news e government — i due segmenti più coinvolti nelle policy AI e quelli la cui adozione sarebbe necessaria per far passare lo standard da "esperimento del vendor" a "protocollo web." Fino ad allora, llms.txt è reale ma piccolo, e un audit di follow-up a fine 2026 sarà un utile test di verifica.
Il problema strutturale di llms.txt è che non è standardizzato da alcun processo IETF e i principali vendor AI non si sono impegnati a rispettarlo. Una regola robots.txt ha 30 anni di infrastruttura crawler costruita attorno; una regola llms.txt non ha nulla. Finché almeno un grande vendor (OpenAI, Anthropic, Google, Cloudflare) non ne dichiara il supporto formale, il file resta essenzialmente un artefatto di marketing dell’ecosistema Mintlify / Vercel. Non ci aspettiamo che cambi nel 2026.
Risultato 13 — Accessibilità: robots.txt è ancora leggibile per due terzi del web principale
Un’osservazione laterale che non doveva diventare un risultato: il 66% dei 10.000 siti principali ha restituito un robots.txt analizzabile a un singolo IP di ricerca, e solo 7 su 10.000 (0,07%) hanno restituito 429 Too Many Requests. È una buona notizia per robots.txt inteso come protocollo pubblico.
Per confronto, la stessa pipeline eseguita due mesi prima su un campione commerce mid-market di 1.008 domini ha ricevuto 429 dal 52% dei domini risolti — CDN Shopify e Cloudflare che limitavano aggressivamente il rate verso qualsiasi UA non assimilabile a un motore di ricerca importante. Il web ad alto traffico è molto più amichevole: i siti più grandi hanno più probabilmente o (a) livelli di bot management meno aggressivi, o (b) allowlist esplicite per crawler di ricerca noti, o entrambe le cose.
Il tasso di fetch_failed del 21% nel top-10k è dominato da domini apex CDN (akamai.net, cloudfront.net, fastly.net, apple-dns.net, gtld-servers.net) che non eseguono un webserver su /. Non ci stanno bloccando; non hanno nulla da servire. Escludendo questi, il tasso reale di errore "abbiamo provato a leggere ma non ci siamo riusciti" è nelle percentuali basse a una cifra.
Questo significa che le future iterazioni di questo report — snapshot trimestrali, confronti anno su anno — possono essere eseguite in modo economico e riproducibile su una sola macchina. La finestra di audit resta aperta nella parte alta della curva. Il caso asimmetrico è la coda lunga e il segmento commerce, dove il throttling a livello CDN ha già di fatto privatizzato robots.txt. Ci aspettiamo che questa divergenza si ampli: i siti top resteranno leggibili perché vengono indicizzati da motori di ricerca che richiedono leggibilità; il commerce della coda lunga diventerà meno leggibile man mano che i tier anti-bot di Cloudflare diventano più aggressivi. L’auditabilità pubblica di robots.txt si sta biforcando lungo la stessa linea che separa "il web visibile" dal "web protetto operativamente".
IV. Cosa significa tutto questo
Quattro affermazioni, in ordine di quanto i dati le sostengono.
1. Internet ha una policy AI per settore, non globale. Lo spread 12x tra news e telecom domina ogni numero aggregato. Riportare "X% del web blocca l’AI" senza una suddivisione settoriale sovrastima SaaS/government/dev e sottostima news/travel/social. Il framing onesto è solo quello per settore.
2. L’articolo 4 della Direttiva UE sul copyright è l’unico regime giuridico che sta muovendo i numeri in modo visibile. I siti ccTLD UE bloccano al 35% contro il baseline globale del 19%. Il contenzioso USA (NYT v. OpenAI, il report del Copyright Office di gennaio 2025) ha spostato il cohort news USA, ma non il web USA più ampio. Il framing UE si sta inoltre diffondendo a livello globale attraverso il template di Cloudflare, che cita la Direttiva 2019/790 nel proprio boilerplate indipendentemente dalla giurisdizione del cliente.
3. Due "policy AI" parallele vengono espresse e non coincidono tra loro. La policy deliberata, scritta a mano (17,8%, soprattutto news/social/travel/e-commerce) e la policy ereditata e gestita da Cloudflare (4,5%) si sovrappongono nella sostanza ma differiscono nella legittimità. In un mondo in cui gli operatori AI cercano copertura legale per ignorare robots.txt, la difesa "l’abbiamo scritta e revisionata" è strutturalmente più forte di "l’ho solo attivata con un toggle." L’incentivo del contenzioso è spostare la policy dalla seconda categoria alla prima.
4. I publisher bloccano il corpus, non il modello. CCBot al 16,3% — più alto di qualsiasi bot con brand di modello — è l’affermazione più chiara di questo fatto. Vietare OpenAI non serve a evitare di essere usati per il training; vietare CCBot sì. Il 14,1% del web top-10k blocca CCBot ma lascia Googlebot benvenuto. Il pattern "blocca il training, tieni la ricerca" è la regola AI più diffusa nel 2026.
Per i siti che valutano il proprio approccio: la postura mediana è il silenzio — l’80% del top 10k non dice nulla sull’AI. Quel 17% che scrive regole si concentra su Disallow, ma un piccolo cohort in crescita (la lista Allow esplicita per GPTBot, 1,5%, guidata dai vendor di sicurezza) sta scegliendo pubblicamente l’opposto. Non c’è consenso di settore e non ce ne sarà uno nei prossimi dodici mesi.
Per gli operatori AI: continuare a sostenere che robots.txt sia un protocollo legacy con semantica ambigua diventa sempre più difficile quando il 17% dei più grandi siti del mondo ha scritto regole esplicite e deliberate nominando a mano i bot, e il 3,8% dei file cita una norma specifica UE per numero di articolo. Se rispettare tali regole sia o meno una decisione di business; se esistano, ormai, è un fatto empirico.
V. Prospettive: cosa ci aspettiamo entro fine 2026
Tre traiettorie visibili nel dataset:
Cloudflare Managed più che raddoppierà la propria quota, con una possibile salita oltre il 10% del top-10k analizzabile. La roadmap di Cloudflare parla pubblicamente di Block AI Bots attivo di default per i nuovi account. Se il toggle parte default-on, il tasso globale di blocco sale di 5–8 punti percentuali senza che nessun editore prenda una decisione. Ce ne accorgeremo quando la quota Cloudflare Managed del bucket 5001–10000 supererà l’attuale 5,7%.
Le policy AI a livello di sezione (stile Spiegel) si diffonderanno tra i principali flagship news. La logica economica — lascia che l’AI citi i contenuti a basso rischio, proteggi quelli-fossato — è abbastanza convincente da farci aspettare almeno altri 10 newsroom di punta con regole a livello di sezione entro fine 2026. Guardate prima la stampa tedesca e francese di fascia media; il quadro giuridico lì premia la sperimentazione.
Il cohort esplicito Allow-GPTBot crescerà, guidato da SaaS B2B e tooling per sviluppatori. Quando la ricerca AI diventa un canale di acquisizione misurabile per i vendor software (come già accade nella sicurezza), il CMO marginale scriverà User-agent: GPTBot \n Allow: / per immunizzarsi da blocchi accidentali eccessivi. Ci aspettiamo che la lista da 108 siti circa raddoppi entro fine anno.
Ciò che non ci aspettiamo: un cambiamento sostanziale nella quota della maggioranza silenziosa. L’80% del web che non dice nulla sull’AI include settori (government, telecom, infrastructure, B2B SaaS) che non hanno motivo economico di scrivere una regola e nessuna pressione giuridica per farlo. Una policy AI universale non arriverà.
VI. Limiti
- Bias da singolo snapshot. La raccolta è avvenuta in una finestra di 36 ore all’inizio di maggio 2026. Il file cambia ogni giorno nei top 100; aspettatevi una deriva di 1–2 punti percentuali per trimestre sui numeri principali.
- Lacune nella classificazione per settore. 6.593 siti su 10.000 sono rimasti
unknowndopo il classificatore a quattro livelli. Le percentuali per settore sono robuste dove n è grande (news: 650, streaming: 440, saas: 369, academia: 268, adult: 254, ecommerce: 224, gov: 172, finance: 129, dev: 129) e più rumorose sotto n=30. Anche il taglio per news per paese ha limiti simili — DE/FR/UK hanno n≥15, Korea/Svezia/Cechia si basano su n=20–25. robots.txtè volontario. UnDisallowè una richiesta, non una barriera.Bytespider,PerplexityBote altri hanno dimostrato di ignorare le regole. Abbiamo misurato dichiarazioni di policy, non la loro applicazione.- Audit single-IP, basato negli USA. Non siamo riusciti a leggere il 21% dei domini risolti. La maggior parte sono punti apex CDN senza webserver; una piccola quota sono siti il cui CDN ci ha segnalato prima di arrivare all’origin. Questo introduce un lieve bias verso infrastrutture più vecchie e contro siti geofenced per paese di origine.
- Semantica della lista Tranco. Tranco filtra per stabilità; non è un ranking basato sul comportamento reale degli utenti. I numeri aggregati sono robusti rispetto alla scelta della lista; le posizioni di rank specifiche no.
- Nessun dato di traffico. Abbiamo misurato la policy di
robots.txt, non il traffico effettivo dei bot AI. Policy e traffico non coincidono sempre.
VII. Riproduci questo
Tutto ciò che è stato usato per produrre questo report si trova nella cartella di consegna.
- tranco_top10k.csv — lista di input
- out/sites.csv — dominio × rank × settore × lingua × stato
robots.txt(10.000 righe) - out/fetch_meta.csv — esito del fetch per dominio (stato, schema, byte, errore)
- out/bot_status.csv — griglia dominio × bot (250.000 righe: bloccato, ha regola, stato fetch)
- out/site_meta.csv — un record analitico per sito (template, booleani di sintesi)
- out/analysis.json — ogni metrica citata nel report
- 01_fetch_robots.py, 02_classify.py, 03_parse_and_analyze.py — pipeline Python completa
Correzioni alla metodologia, problemi del dataset e analisi di follow-up sono benvenuti a support@thunderbit.com. Questo report è pubblicato indipendentemente da qualsiasi posizione commerciale di Thunderbit; costruiamo uno web scraper basato su AI e abbiamo un interesse strutturale nel fatto che robots.txt continui a essere un contratto significativo e leggibile da macchina sul web pubblico. I dati in questo report stanno in piedi da soli. — Il team di ricerca Thunderbit, maggio 2026.