La domanda di dati etichettati di alta qualità nel machine learning non è mai stata così alta. Ogni volta che parlo con team che sviluppano nuovi modelli di IA — che si tratti di previsione delle vendite, raccomandazioni di prodotto o analisi del sentiment dei clienti — emergono sempre gli stessi problemi: etichettare i dati a mano è lento, costoso e, a dire il vero, un po’ sfiancante per lo spirito. Ho visto progetti bloccarsi per settimane (o mesi) in attesa di avere abbastanza esempi etichettati per addestrare un modello decente. E quando le etichette non sono coerenti? Beh, diciamo solo che le previsioni del tuo modello possono diventare affidabili più o meno quanto i miei tentativi di parcheggio in parallelo.
Ma ecco la buona notizia: l’etichettatura automatica dei dati con il machine learning sta cambiando le regole del gioco. Lasciando che l’IA faccia il lavoro più pesante, le aziende non solo accelerano il processo di etichettatura, ma migliorano anche accuratezza e coerenza — due aspetti che possono determinare il successo o il fallimento di un progetto ML. In questa guida ti mostrerò come funziona l’etichettatura automatica dei dati, perché è così cruciale per costruire modelli robusti e come puoi usare strumenti come per impostare il tuo flusso di lavoro di etichettatura automatica — senza scrivere codice.
Che cos’è l’etichettatura automatica dei dati con il machine learning?
Facciamo un passo indietro. Per etichettatura automatica dei dati con il machine learning si intende l’uso di algoritmi e strumenti di IA per assegnare etichette (come “spam” o “non spam”, “gatto” o “cane”, “positivo” o “negativo”) ai dati grezzi — senza che una persona debba cliccare su ogni singolo esempio. È un po’ come la differenza tra taggare a mano migliaia di foto di vacanze e usare il riconoscimento facciale per organizzarle automaticamente per persona, luogo o persino stato d’animo.
L’etichettatura manuale tradizionale è esattamente quello che sembra: persone che esaminano i dati uno per uno e assegnano l’etichetta corretta. È precisa (a volte), ma lenta, costosa e difficile da scalare. L’etichettatura automatica, invece, utilizza modelli di machine learning — addestrati su un insieme più piccolo di dati etichettati manualmente — per prevedere le etichette del resto del dataset. Il risultato? Un’etichettatura più veloce, coerente e scalabile ().
Per gli utenti business, questo significa poter costruire modelli migliori, più rapidamente e con molto meno lavoro manuale. E nel mondo odierno guidato dai dati, è un vantaggio competitivo notevole.
Perché l’etichettatura automatica dei dati è fondamentale per modelli di machine learning di alta qualità
Il punto è questo: la qualità dei dati etichettati influisce direttamente sulle prestazioni dei modelli di machine learning. Come si dice, “input sbagliato, output sbagliato”. Se le etichette sono incoerenti o errate, il modello imparerà i pattern sbagliati — e le previsioni ne risentiranno ().
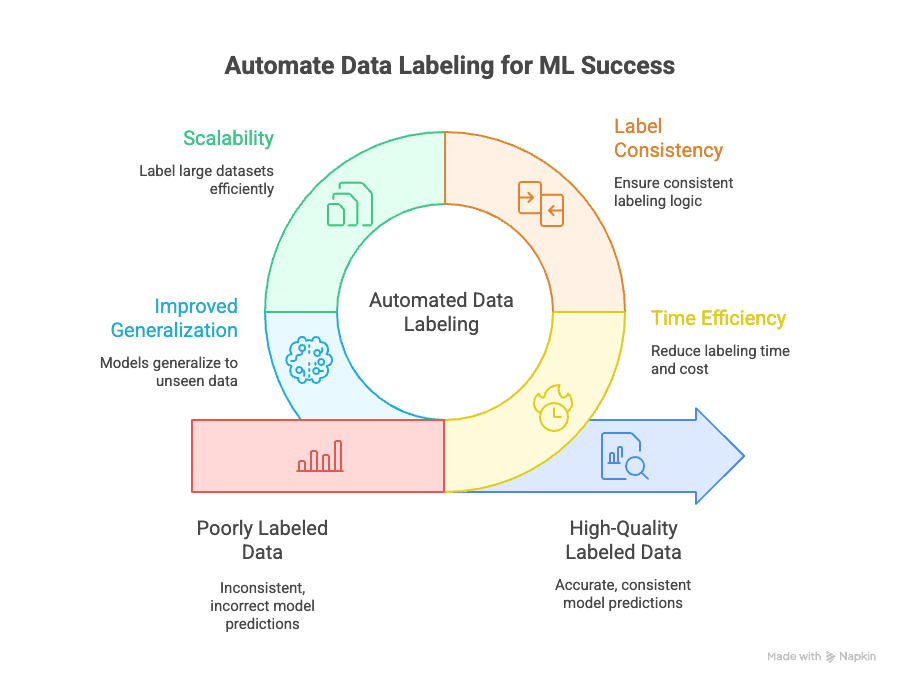
L’etichettatura automatica dei dati affronta diverse sfide chiave:
- Efficienza del tempo: l’etichettatura manuale può assorbire fino al di un progetto ML. L’automazione riduce drasticamente questa quota, permettendoti di iterare e distribuire i modelli più velocemente.
- Coerenza delle etichette: le macchine non si stancano e non si distraggono. L’etichettatura automatica garantisce che ogni dato venga etichettato secondo la stessa logica, riducendo errori umani e bias ().
- Scalabilità: devi etichettare 10.000, 100.000 o persino un milione di punti dati? L’automazione lo rende possibile — senza assumere un esercito di annotatori ().
- Migliore generalizzazione: etichette coerenti e di alta qualità aiutano i modelli a generalizzare meglio su dati nuovi e mai visti, che è l’obiettivo finale nel machine learning ().
E l’impatto sul business è reale: dati etichettati male possono ridurre l’accuratezza del modello fino al , mentre un’etichettatura automatica di qualità porta a uno sviluppo e a un rilascio dei modelli più rapidi.
Confronto tra etichettatura manuale e automatica
Mettiamole a confronto:
| Fattore | Etichettatura manuale | Etichettatura automatica con ML |
|---|---|---|
| Velocità | Lenta (settimane/mesi per dataset di grandi dimensioni) | Rapida (minuti/ore per dataset di grandi dimensioni) |
| Accuratezza | Alta, ma soggetta a errori e incoerenze umane | Alta, con logica coerente e meno errori |
| Scalabilità | Limitata dalle risorse umane | Si estende facilmente a milioni di punti dati |
| Costo | Costosa (richiede molto lavoro manuale) | Costi inferiori nel lungo periodo (Keylabs) |
| Ideale per | Dataset piccoli, complessi o ambigui | Dataset grandi, ripetitivi o ben definiti |
L’etichettatura manuale ha ancora il suo posto — soprattutto per i casi limite o i dati ambigui — ma per la maggior parte delle applicazioni business, l’automazione è la strada da seguire.
I passaggi di base dell’etichettatura automatica dei dati con il machine learning
Allora, come funziona davvero l’etichettatura automatica dei dati? Ecco il flusso end-to-end che consiglio (e che uso personalmente):
- Raccolta e pre-elaborazione dei dati
- Estrazione e preparazione delle feature
- Etichettatura automatica con il machine learning
- Controllo qualità e revisione umana
Analizziamo ogni passaggio.
Passaggio 1: raccolta e pre-elaborazione dei dati
Prima di etichettare qualsiasi cosa, devi raccogliere e ripulire i tuoi dati. Questo può significare estrarre elenchi di prodotti dai siti web, esportare recensioni dei clienti o raccogliere immagini da database interni. Qui la qualità è tutto: dati scadenti portano a etichette scadenti, che a loro volta portano a modelli scadenti ().
Buone pratiche:
- Rimuovi duplicati e voci irrilevanti
- Standardizza i formati (date, valute, ecc.)
- Gestisci i dati mancanti o incompleti
Passaggio 2: estrazione e preparazione delle feature
Poi, identifichi le feature che contano per il tuo compito di etichettatura. Per esempio, se stai etichettando schede prodotto, potresti estrarre attributi come prezzo, brand, categoria e descrizione. Nelle vendite o nel marketing, questo potrebbe voler dire estrarre nomi aziendali, informazioni di contatto o sentiment dalle email.
Esempio business: con , puoi estrarre dati strutturati dalle pagine web — come specifiche prodotto, recensioni o dettagli di contatto — senza scrivere neanche una riga di codice.
Passaggio 3: etichettatura automatica con il machine learning
Qui avviene la magia. Usi modelli di machine learning (addestrati su un dataset più piccolo, etichettato manualmente) per prevedere le etichette del resto dei dati. Le tecniche più comuni includono:
- Modelli supervisionati: addestri un classificatore su esempi etichettati, poi lo usi per etichettare nuovi dati.
- Etichettatura basata su regole: usi regole predefinite (ad esempio, “se il prezzo > 1000 €, etichetta come ‘premium’”) per i casi semplici.
- Active learning: il modello chiede l’intervento umano sui casi incerti, migliorando nel tempo ().
- Transfer learning: usi modelli pre-addestrati per accelerare l’etichettatura in nuovi domini ().
Il risultato? Etichette coerenti e di alta qualità, su larga scala.
Passaggio 4: controllo qualità e revisione umana
Anche i migliori modelli hanno bisogno di un controllo di buon senso. Una revisione umana periodica aiuta a intercettare casi limite, dati ambigui o deriva del modello. I passaggi pratici di QA includono:
- Campionare casualmente i dati etichettati per una revisione manuale
- Confrontare le etichette automatiche con un set “gold standard”
- Usare metriche di accordo tra annotatori per misurare la coerenza ()
Come usare Thunderbit per l’etichettatura automatica dei dati con il machine learning
Adesso passiamo alla pratica. è uno strumento di estrazione Web AI e di etichettatura dei dati pensato per utenti business — senza bisogno di codice. Ecco come puoi usarlo per automatizzare il tuo flusso di lavoro di etichettatura:
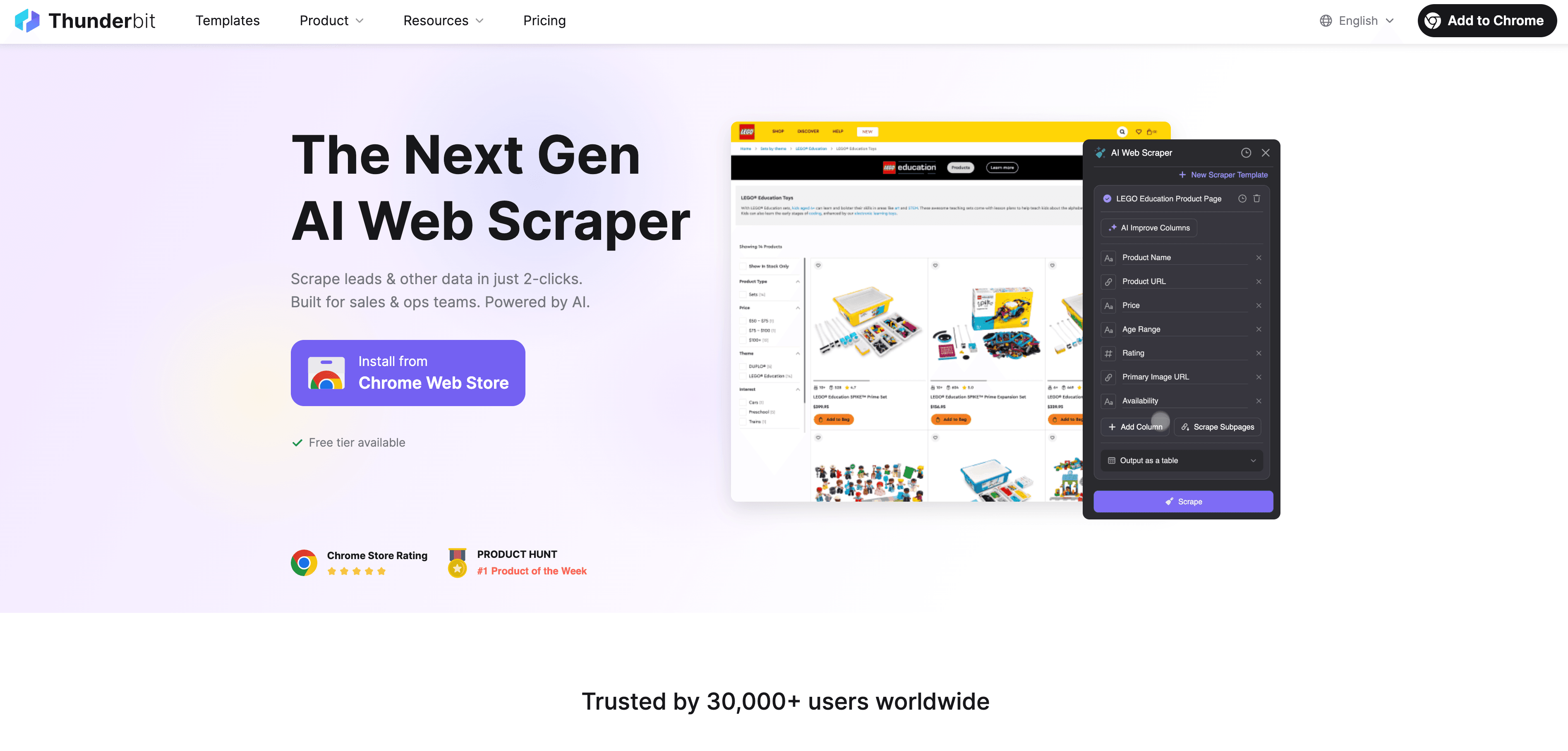
Guida passo passo
- Estrai i dati dal sito web: usa l’ per raccogliere dati strutturati da qualsiasi sito web. Apri l’estensione, seleziona la tua fonte dati e lascia che l’IA di Thunderbit suggerisca i campi migliori da estrarre.
- Definisci le istruzioni per le etichette: usa i prompt in linguaggio naturale di Thunderbit per spiegare all’IA come etichettare i dati. Per esempio: “Etichetta tutti i prodotti sopra i 500 € come ‘premium’” oppure “Tagga le recensioni con sentiment positivo”.
- Applica l’etichettatura automatica: la funzione Field AI Prompt di Thunderbit ti permette di personalizzare e rifinire il modo in cui vengono assegnate le etichette — perfetta per compiti di etichettatura multi-campo o complessi.
- Esporta i dati etichettati: una volta etichettati, esporta i dati direttamente in Excel, Google Sheets, Airtable o Notion — pronti per l’addestramento del modello o per l’analisi.
La parte migliore? Thunderbit è pensato per utenti non tecnici nei settori vendite, marketing, operations e oltre. Non devi scrivere una sola riga di codice né lottare con template complessi.
Prompt in linguaggio naturale e funzionalità Field AI di Thunderbit
Una delle mie funzioni preferite è la possibilità di definire la logica di etichettatura in un inglese semplice. Vuoi classificare i lead per area geografica, taggare i prodotti per categoria o segnalare email con un linguaggio urgente? Ti basta descrivere ciò che vuoi, e l’IA di Thunderbit penserà al resto.
Esempi di prompt:
- “Etichetta tutti i contatti con un’email ‘.edu’ come segmento ‘Education’.”
- “Se la recensione menziona ‘spedizione veloce’, tagga come ‘Positive Shipping Experience’.”
- “Raggruppa i prodotti per brand e fascia di prezzo.”
Il Field AI Prompt di Thunderbit ti consente di essere ancora più preciso — personalizzando la logica di etichettatura per ogni colonna, combinando regole o persino traducendo le etichette in più lingue.
Estrazione di sottopagine ed etichettatura multi-campo
Strutture dati complesse? Nessun problema. La funzione di estrazione delle sottopagine di Thunderbit ti consente di estrarre ed etichettare dati da pagine nidificate (come dettagli prodotto o bio degli autori) e unire tutto in una tabella unica e strutturata. Puoi etichettare più campi in un colpo solo, risparmiando ancora più tempo.
Caso d’uso reale: estrarre le schede prodotto da un sito ecommerce, poi seguire il link di ogni prodotto per estrarre ed etichettare specifiche, recensioni e informazioni sul venditore — tutto in un unico flusso di lavoro.
Integrare più strumenti di etichettatura per maggiore accuratezza ed efficienza
Anche se Thunderbit copre moltissimi casi, a volte servono strumenti specializzati per determinati tipi di dati — come l’annotazione di immagini o l’etichettatura video. È qui che entrano in gioco piattaforme come o .
Consiglio pratico: usa Thunderbit per gestire l’estrazione dei dati web e l’etichettatura iniziale, poi esporta i dati su Label Studio o Supervisely per l’annotazione avanzata (come bounding box sulle immagini o tag video frame per frame). Questo approccio multi-tool ti permette di sfruttare i punti di forza di ogni piattaforma, migliorando sia accuratezza sia efficienza ().
Quando usare strumenti specializzati insieme a Thunderbit
- Annotazione immagini: per attività come object detection o segmentazione, usa Supervisely o Label Studio.
- Etichettatura video: strumenti video specializzati gestiscono annotazione e tracking frame per frame.
- Compiti complessi multi-etichetta: combina l’estrazione di dati strutturati di Thunderbit con strumenti di annotazione avanzati per ottenere i migliori risultati.
Buona pratica: inizia con Thunderbit per un’etichettatura rapida e scalabile di dati strutturati e semi-strutturati, poi aggiungi strumenti specializzati quando serve un’annotazione più approfondita.
Best practice per l’etichettatura automatica dei dati con il machine learning
Vuoi ottenere il massimo dal tuo flusso di etichettatura automatica? Ecco i miei consigli principali:
- Definisci linee guida chiare per le etichette: etichette ambigue portano a dati incoerenti — specifica bene cosa significa ogni etichetta.
- Parti da un seed set di alta qualità: etichetta manualmente un piccolo campione rappresentativo per addestrare il modello iniziale.
- Itera e migliora: usa l’active learning per perfezionare il modello nel tempo, concentrando la revisione umana sui casi più difficili.
- Valida regolarmente: controlla periodicamente un campione casuale di dati etichettati per individuare errori o deriva.
- Integra e automatizza: usa strumenti come Thunderbit per collegare raccolta dati, etichettatura ed esportazione in un unico flusso di lavoro.
Sfide comuni e come superarle
L’etichettatura automatica dei dati non è priva di ostacoli. Ecco come affrontare i più comuni:
- Dati ambigui: usa definizioni di etichetta chiare e dettagliate e fornisci esempi per i casi limite.
- Deriva del modello: riaddestra regolarmente il modello di etichettatura con nuovi dati revisionati manualmente.
- Casi limite: imposta un processo di revisione umana per i dati incerti o nuovi.
- Problemi di integrazione: scegli strumenti (come Thunderbit) che offrano esportazione semplice verso le piattaforme che preferisci.
Conclusione e punti chiave
L’etichettatura automatica dei dati con il machine learning è l’ingrediente segreto alla base dei modelli di IA più efficaci di oggi. Fa risparmiare tempo, riduce i costi e — soprattutto — fornisce le etichette coerenti e di alta qualità di cui i tuoi modelli hanno bisogno per rendere al meglio. Combinando strumenti come con piattaforme di annotazione specializzate, puoi costruire un flusso di lavoro di etichettatura veloce, accurato e scalabile — qualunque sia il tuo livello tecnico.
Pronto a vedere la differenza con i tuoi occhi? , prova l’etichettatura automatica nel tuo prossimo progetto e guarda i tuoi modelli di machine learning diventare più intelligenti e più veloci. E se vuoi altri consigli e best practice, visita il per approfondimenti e tutorial.
FAQ
1. Che cos’è l’etichettatura automatica dei dati con il machine learning?
È il processo di usare modelli di IA e ML per assegnare automaticamente le etichette ai dati, invece di farlo manualmente. Questo approccio accelera l’etichettatura, migliora la coerenza e si adatta a dataset di grandi dimensioni.
2. Perché la qualità dell’etichettatura è importante per il machine learning?
Etichette coerenti e di alta qualità sono essenziali per addestrare modelli accurati. Un’etichettatura scadente può ridurre l’accuratezza del modello fino all’80% e portare a previsioni inaffidabili.
3. In che modo Thunderbit aiuta con l’etichettatura automatica dei dati?
Thunderbit ti permette di estrarre ed etichettare dati web con l’IA, usando prompt in linguaggio naturale e una logica di campo personalizzabile — senza scrivere codice. È ideale per utenti business in sales, marketing e operations.
4. Posso combinare Thunderbit con altri strumenti di etichettatura?
Assolutamente sì. Usa Thunderbit per l’estrazione di dati strutturati e l’etichettatura iniziale, poi esporta verso strumenti come Label Studio o Supervisely per l’annotazione avanzata di immagini o video.
5. Quali sono le best practice per l’etichettatura automatica dei dati?
Definisci linee guida chiare per le etichette, parti da un seed set di qualità, iterare con l’active learning, valida regolarmente e usa strumenti integrati per semplificare il flusso di lavoro.
Pronto ad automatizzare l’etichettatura dei dati e a dare una marcia in più ai tuoi progetti di machine learning? Prova Thunderbit e scopri quanto tempo — e quanta frustrazione — puoi risparmiare.
Scopri di più: