Substack scraper














Buka akses data Substack dengan Thunderbit
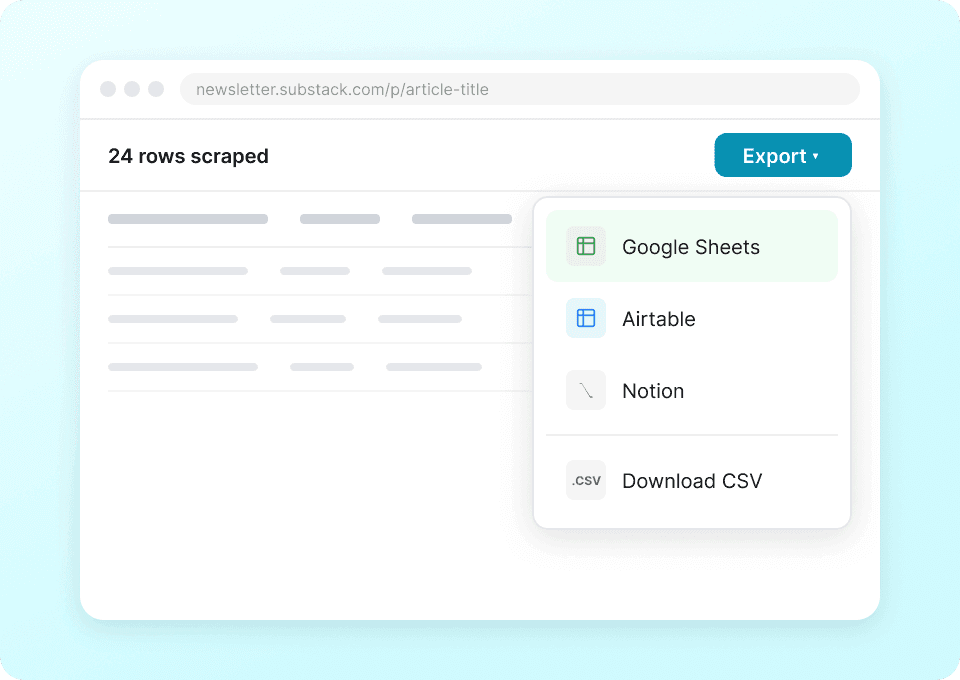
Kirim data Substack langsung ke aplikasi Anda
Tidak perlu lagi copy-paste detail publikasi Substack seperti nama penulis, judul artikel, dan jumlah subscriber secara manual. Dengan Thunderbit, cukup satu klik untuk mengirim data hasil ekstraksi langsung ke Google Sheets, Notion, atau Airtable — sehingga Anda bisa menganalisis tren publikasi dan performa konten tanpa pekerjaan manual yang membosankan.
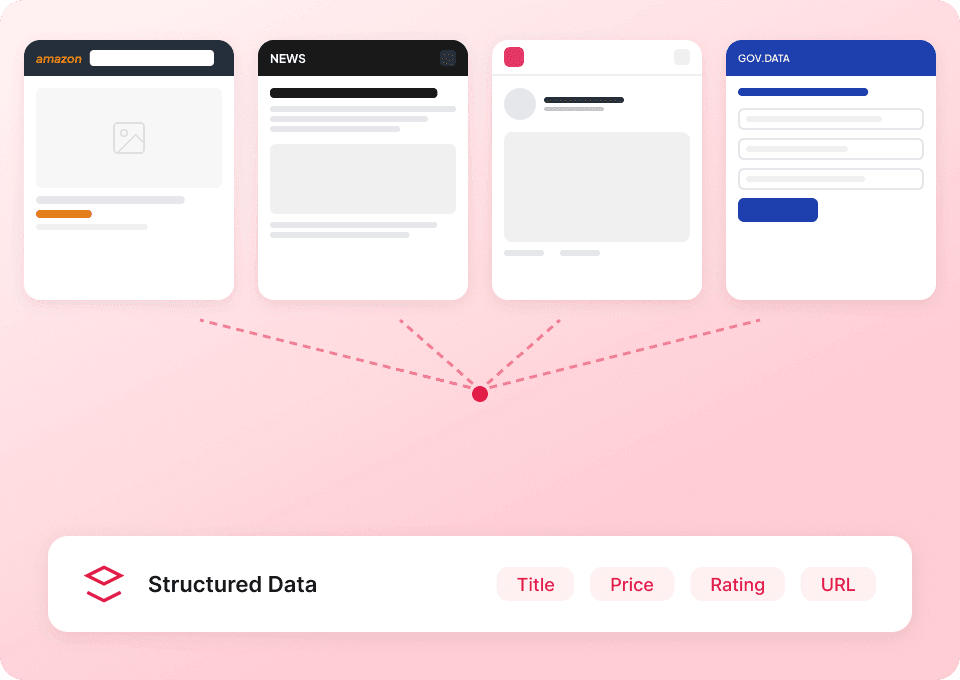
Satu scraper untuk Substack dan banyak situs lainnya
Tidak perlu pusing memakai alat berbeda untuk setiap website. Thunderbit langsung bisa digunakan untuk Substack dan juga menyediakan lebih dari 50 template bawaan untuk platform populer lainnya. Ekstrak deskripsi publikasi, isi artikel, dan lainnya — lalu gunakan alat yang sama untuk mengumpulkan data dari situs web mana pun.
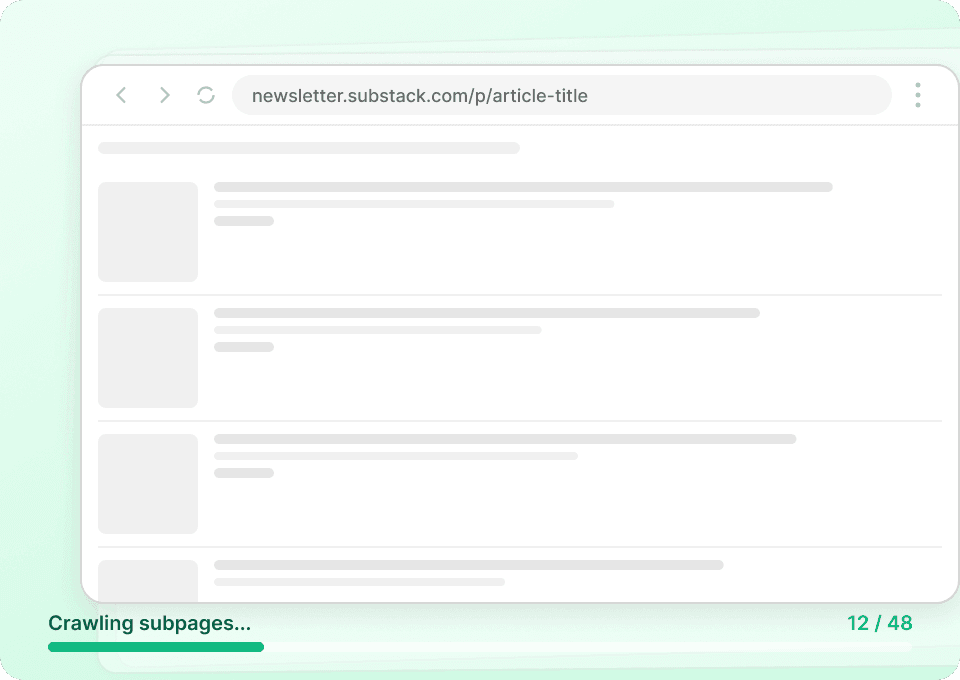
Dapatkan cerita lengkap dari Substack
Halaman daftar Substack hanya menampilkan ringkasan. Thunderbit otomatis mengunjungi setiap subpage artikel untuk mengambil isi lengkapnya, sehingga Anda mendapatkan dataset yang utuh dalam satu proses. Tangkap judul artikel, nama penulis, nama publikasi, dan teks lengkap artikel — semuanya tanpa harus membuka halaman satu per satu secara manual.
Kesulitan scraping Substack dengan efektif?
Lihat mengapa Thunderbit lebih unggul dibanding scraper tradisional untuk data Substack.
Scraper tradisional
Cara lamaThunderbit
Pendekatan yang lebih cerdasJangan hanya percaya kata kami
Lihat apa kata pengguna kami tentang Thunderbit.







Pertanyaan yang sering diajukan
Terkait use case
Jelajahi lebih banyak use case web scraper Thunderbit.

United Airlines scraper
Dalam 2 klik, ekstrak nomor penerbangan, waktu keberangkatan, bandara tujuan, dan harga dari United Airlines — lalu ekspor langsung ke Excel, Google Sheets, atau Notion. Sisanya ditangani oleh Thunderbit AI.
Pelajari lebih lanjut ->Amazon price scraper
Pantau harga Amazon, rating, dan ASIN secara real time — ekspor ke Excel, Google Sheets, atau Notion hanya dalam 2 klik, tanpa perlu coding.
Pelajari lebih lanjut ->
Scraper Nomor Telepon Craigslist
Scraper Nomor Telepon Craigslist dari Thunderbit membantu Anda mengekstrak nomor telepon dan detail listing dari hasil pencarian Craigslist dengan bantuan AI. Ambil data listing, buka tiap posting untuk menangkap info kontak dan kolom tambahan, lalu ekspor ke Excel, Google Sheets, Airtable, Notion, CSV, atau JSON.
Pelajari lebih lanjut ->
UNIQLO Scraper
Ekstrak nama produk, harga, warna, dan ukuran Uniqlo hanya dalam 2 klik dengan ekstensi Chrome bertenaga AI dari Thunderbit. Ekspor langsung ke Google Sheets, Excel, atau Notion, dan jaga riset produk Anda tetap selalu terbaru.
Pelajari lebih lanjut ->
Coupang scraper
Ambil nama produk, harga, dan persentase diskon di Coupang hanya dengan 2 klik — lalu ekspor langsung ke Excel, Google Sheets, atau Notion. Tanpa perlu coding.
Pelajari lebih lanjut ->
Trustpilot scraper
Ekstrak ulasan, rating, dan detail reviewer Trustpilot hanya dalam 2 klik — lalu ekspor langsung ke Google Sheets, Excel, atau Notion. Tanpa coding, tanpa copy-paste, hanya data terstruktur rapi yang siap dianalisis dan dibagikan.
Pelajari lebih lanjut ->Siap meningkatkan ekstraksi datamu?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Uji coba gratis menyediakan kredit tak terbatas untuk 8 halaman web.



