Web berkembang dengan kecepatan yang sejujurnya sulit dibayangkan. Setiap hari, miliaran halaman baru, produk, ulasan, dan dataset dipublikasikan—mendorong segala hal mulai dari riset pasar, pelatihan AI, hingga sesi belanja Amazon Anda berikutnya. Sebagai seseorang yang sudah bertahun-tahun berkecimpung di SaaS dan otomasi, saya melihat langsung bagaimana data yang tepat bisa menentukan sebuah keputusan bisnis berhasil atau gagal. Namun inilah tantangannya: mengumpulkan, memperbarui, dan memahami seluruh data web ini justru makin sulit, bukan makin mudah. Web scraper tradisional kewalahan mengejar perubahan, sementara bisnis butuh cara yang lebih cerdas dan lebih cepat untuk mengubah internet menjadi insight yang bisa ditindaklanjuti. Di sinilah cloud crawler hadir—alat yang diam-diam sedang merevolusi cara organisasi menemukan dan memanfaatkan data web dalam skala besar.
Jadi, sebenarnya apa itu cloud crawler? Apa bedanya dengan web scraper yang mungkin sudah Anda kenal? Dan kenapa tim dari sales sampai operasional begitu percaya pada teknologi ini untuk tetap unggul di dunia yang digerakkan data? Mari kita bahas, kupas istilah-istilahnya, dan lihat bagaimana cloud crawler (terutama solusi dari Thunderbit) mengubah cara kerja bisnis modern.
Apa Itu Cloud Crawler? Langkah Berikutnya dalam Penemuan Data
Mari kita sederhanakan: cloud crawler bukan sekadar web scraper yang dijalankan di cloud. Ia lebih mirip mesin penemuan data—sistem cerdas berbasis cloud yang dirancang untuk secara otomatis menemukan, mengekstrak, dan menganalisis dataset besar dari seluruh internet. Kalau web scraper tradisional mengambil informasi dari beberapa halaman saja (seringnya satu per satu, dan biasanya dari satu perangkat), cloud crawler bekerja di level yang jauh lebih tinggi. Ia berjalan di pusat data cloud yang sangat kuat, merayapi ribuan bahkan jutaan halaman secara bersamaan, dan mampu memproses semuanya mulai dari teks, gambar, hingga PDF—tak peduli seberapa kompleks atau luas situs targetnya.
Bayangkan begini: kalau web scraper ibarat satu pustakawan yang menyalin potongan teks dari sebuah buku, maka cloud crawler adalah tim superkomputer yang memindai seluruh buku di perpustakaan sekaligus, sambil memberi tag, menyusun, dan menganalisis isinya. Hasilnya? Bisnis mendapatkan data yang lebih kaya, lebih segar, dan lebih siap dipakai—tanpa terhambat perangkat lokal atau kerja manual (, ).
Cloud Crawler vs. Web Scraper Tradisional: Apa Bedanya Sebenarnya?
Kalau Anda pernah memakai web scraper, Anda pasti paham dasarnya: arahkan ke sebuah halaman, tentukan data yang ingin diambil, lalu biarkan alat itu menarik datanya. Tapi saat web makin besar dan makin rumit, pendekatan lama mulai kelihatan batasnya. Berikut perbandingan cloud crawler dan web scraper tradisional:
| Fitur/Aspek | Web Scraper Tradisional | Cloud Crawler |
|---|---|---|
| Penerapan | Berjalan di perangkat atau server lokal Anda | Berjalan di cloud (pusat data jarak jauh) |
| Skala | Terbatas oleh daya komputer Anda | Paralel dalam skala besar—ribuan halaman sekaligus |
| Kecepatan | Lebih lambat, terutama untuk pekerjaan besar | Pemrosesan batch berkecepatan tinggi |
| Pemeliharaan | Perlu update sering, mudah rusak saat situs berubah | Berbasis cloud, auto-update, lebih tahan perubahan |
| Jenis Data | Biasanya teks, kadang gambar | Teks, gambar, PDF, layout kompleks |
| Akses | Terikat pada perangkat/jaringan Anda | Bisa diakses dari mana saja, dengan perangkat apa pun |
| Penjadwalan | Manual atau otomatisasi dasar | Penjadwalan lanjutan, pekerjaan berulang |
| Paling Cocok Untuk | Proyek kecil, situs sederhana | Kebutuhan data skala besar, sering, atau kompleks |
Cloud crawler dibuat untuk web modern—di mana data ada di mana-mana, dan kecepatan serta skala bukan lagi pilihan, melainkan keharusan (, ).
Bagaimana Cloud Crawler Meningkatkan Efisiensi Pengumpulan Data
Di sinilah bagian yang benar-benar menarik. Cloud crawler memanfaatkan kekuatan cloud computing untuk memproses ribuan halaman web secara paralel. Artinya, Anda bisa mengambil seluruh katalog ecommerce, memantau harga kompetitor di puluhan situs, atau mengumpulkan listing properti dari semua portal utama—dalam waktu yang jauh lebih singkat dibandingkan scraper tradisional.
Kenapa ini penting? Karena di industri seperti ecommerce, keuangan, dan properti, data yang terbaru adalah segalanya. Harga, stok, dan tren pasar bisa berubah dari menit ke menit. Menunggu berjam-jam atau berhari-hari sampai scraper lokal selesai jelas bukan pilihan. Cloud crawler tidak dibatasi RAM laptop Anda atau Wi‑Fi kantor—skalanya bisa dinaikkan sesuai kebutuhan, jadi Anda bisa menangani pekerjaan besar tanpa pusing (, ).
Industri yang paling merasakan manfaat efisiensi ini antara lain:
- Ecommerce: Pemantauan harga, agregasi katalog produk, analisis ulasan
- Properti: Pengumpulan listing, pelacakan tren pasar, perbandingan properti
- Keuangan: Analisis berita dan sentimen, pemantauan saham/crypto, pelacakan regulasi
- Sales & Marketing: Pencarian lead, riset kompetitor, pemantauan tren
Dan jujur saja, itu baru sebagian kecil. Kalau Anda butuh data web dalam skala besar, cloud crawler adalah sahabat baru Anda.
Solusi Cloud Crawler dari Thunderbit: Cepat, Fleksibel, dan Bertenaga
Izinkan saya pakai topi Thunderbit sebentar (walau sejujurnya, hampir tidak pernah saya lepas). Mode cloud scraping dari adalah jawaban kami untuk tantangan data modern—cloud crawler yang dibuat untuk pengguna bisnis yang menginginkan hasil, bukan kerumitan.
Inilah yang membuat cloud crawler Thunderbit menonjol:
- Scraping Batch Berkecepatan Tinggi: Ambil hingga 50 halaman sekaligus, dengan server cloud di AS, Uni Eropa, dan Asia untuk jangkauan global. Tidak perlu lagi menunggu laptop Anda kerja keras menuntaskan daftar panjang.
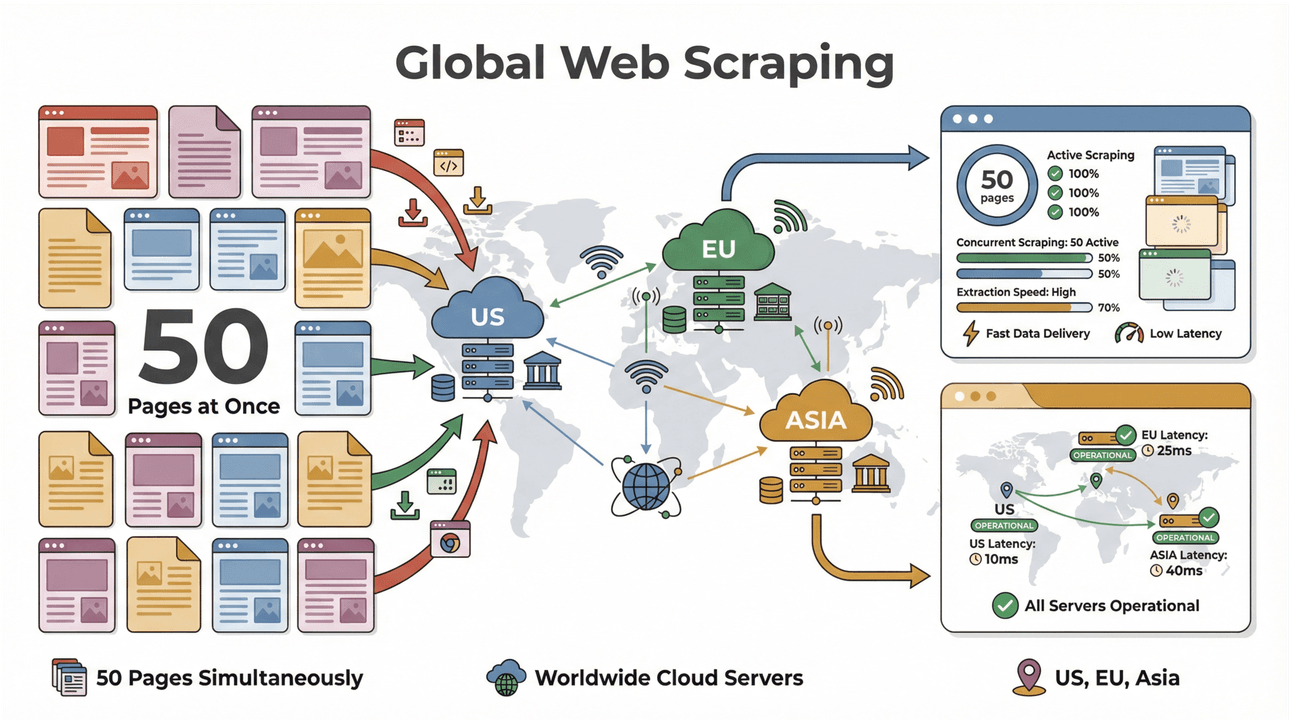
- Dukungan Halaman Kompleks: AI Thunderbit bisa menangani semuanya, mulai dari situs ecommerce dinamis, PDF yang rumit, hingga ekstraksi gambar. Kalau ada di web, besar kemungkinan Thunderbit bisa mengambil datanya ().
- Crawling Subpage: Perlu memperkaya data dengan detail dari subpage, seperti spesifikasi produk atau bio penulis? AI Thunderbit bisa mengunjungi tiap subpage dan menggabungkan hasilnya ke dataset utama Anda ().
- Struktur Data Cerdas: Pakai “AI Suggest Fields” agar Thunderbit membaca situs dan merekomendasikan kolom terbaik—tanpa coding atau bikin template.
- Ekspor ke Mana Saja: Kirim data langsung ke Excel, Google Sheets, Airtable, atau Notion. Atau unduh saja dalam format CSV/JSON—sesuai alur kerja Anda ().
- Tanpa Perlu Maintenance: AI Thunderbit beradaptasi dengan perubahan situs, jadi Anda tidak perlu terus-menerus memperbaiki scraper yang rusak ().
Dan ya, Anda bisa mencoba semuanya lewat —jadi Anda tidak perlu percaya begitu saja pada kata-kata saya.
Penerapan Cloud Crawler: Cloud vs. Lokal—Mana yang Tepat untuk Anda?
Salah satu keunggulan terbesar cloud crawler adalah fleksibilitas penerapannya. Dengan crawler tradisional (lokal), Anda terikat pada perangkat, jaringan, dan sering kali banyak proses setup yang bikin repot. Kalau komputer Anda sleep atau koneksi internet putus, proses scraping ikut berhenti. Untuk skala yang lebih besar, Anda harus beli hardware tambahan atau menjalankan banyak skrip.
Cloud crawler membalik cara kerja itu:
- Tidak Perlu Hardware Khusus: Semua pekerjaan berat dikerjakan di cloud. Anda bisa menjalankan scraping besar dari Chromebook, Mac, bahkan ponsel.
- Bisa Diakses dari Mana Saja: Lagi bepergian? Kerja remote? Tidak masalah—cloud crawler Anda tetap siap dipakai.
- Skalabilitas Mudah: Perlu merayapi 10.000 halaman, bukan 100? Tinggal naikkan ukuran job Anda—tanpa perlu campur tangan tim IT.
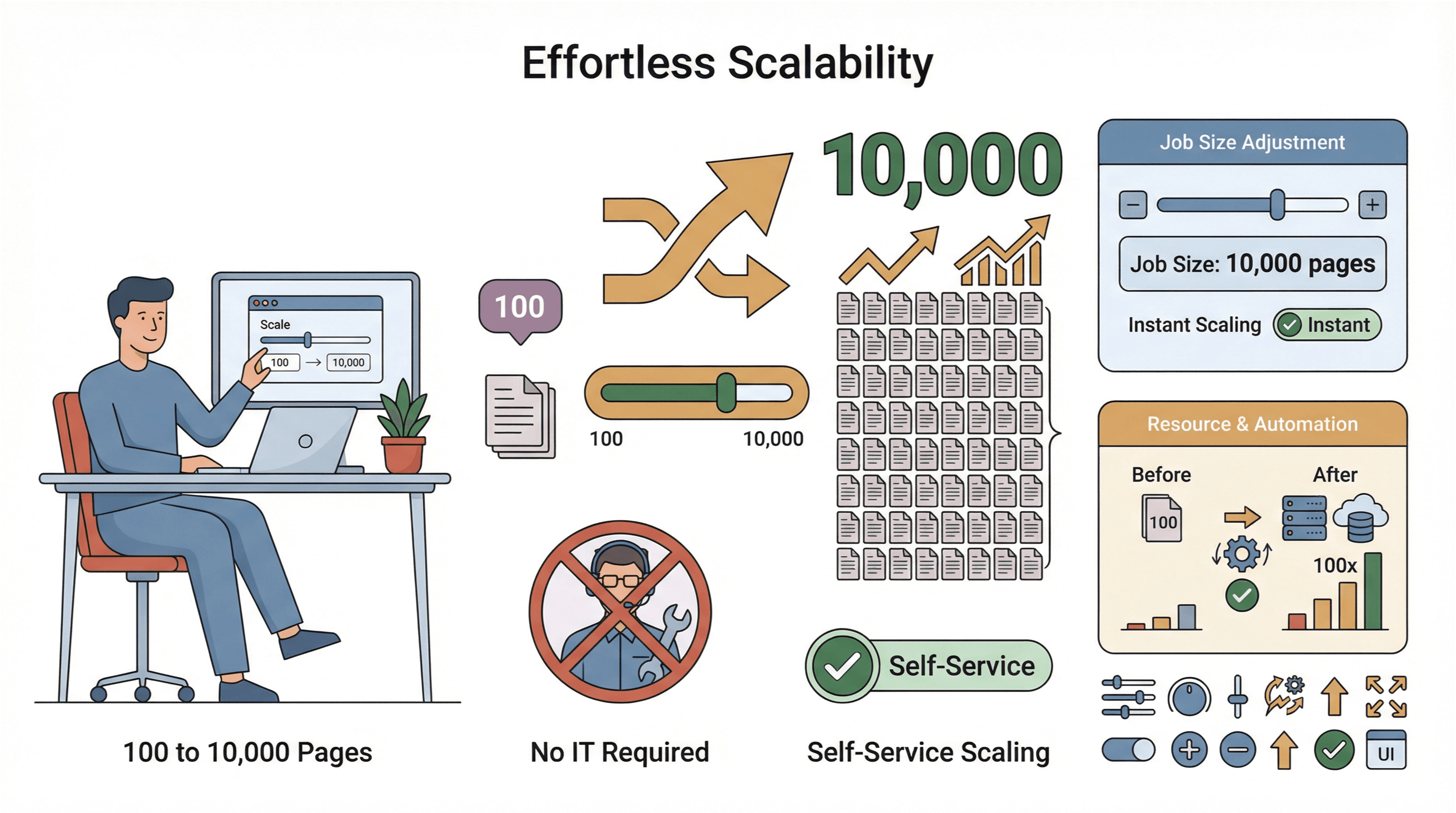
- Pengumpulan Data Global: Dengan server cloud di berbagai wilayah, Anda bisa mengakses konten yang dibatasi secara geografis dan mengelola kepatuhan dengan lebih mudah ().
Tentu saja, keamanan dan kepatuhan selalu jadi perhatian utama. Cloud crawler terbaik (termasuk Thunderbit) menggunakan koneksi terenkripsi, mematuhi ketentuan situs, dan menyediakan fitur untuk membantu Anda mengelola data sensitif secara bertanggung jawab.
Dampak Nyata: Bagaimana Cloud Crawler Mengubah Strategi Berbasis Data
Mari bicara praktis. Kenapa bisnis beralih ke cloud crawler? Karena mereka melihat dampak yang nyata dan terukur:
- Analisis Pasar Real-Time: Retailer menggunakan cloud crawler untuk memantau harga dan stok kompetitor secara langsung, sehingga bisa menerapkan dynamic pricing dan merespons perubahan pasar lebih cepat ().
- Prediksi Tren Konsumen: Brand menggabungkan ulasan, postingan media sosial, dan diskusi forum untuk menangkap tren yang sedang naik daun dan menyesuaikan kampanye dengan cepat.
- Sales & Lead Gen: Tim sales menyusun daftar lead yang selalu terbaru dari direktori, situs event, bahkan PDF—mengisi CRM dengan kontak yang segar dan berkualitas ().
- Operasional & Kepatuhan: Perusahaan keuangan memakai cloud crawler untuk memantau pembaruan regulasi, berita, dan pengajuan dokumen di berbagai yurisdiksi—mengurangi risiko dan tetap selangkah di depan.
Benang merahnya? Cloud crawler membantu tim bergerak lebih cepat, mengambil keputusan lebih cerdas, dan mengungguli kompetitor yang masih bergerak lambat.
Fitur Utama yang Perlu Dicari dalam Cloud Crawler
Tidak semua cloud crawler dibuat sama. Kalau Anda sedang membandingkan opsi, berikut fitur yang paling penting (dan di sinilah Thunderbit unggul):
- Skalabilitas: Apakah bisa menangani ribuan halaman sekaligus? Apakah melambat saat job makin besar?
- Kemudahan Penggunaan: Apakah antarmukanya ramah untuk pengguna non-teknis? Bisakah setup scraping dilakukan hanya dalam beberapa klik?
- Dukungan Multi-Data: Teks, gambar, PDF, subpage—apakah semuanya bisa ditangani?
- Integrasi: Apakah bisa mengekspor ke tools favorit Anda (Excel, Sheets, Notion, Airtable)?
- Penjadwalan: Bisakah Anda membuat job berulang untuk data yang selalu segar?
- Bantuan AI: Apakah tersedia saran field cerdas, enrichment data, dan adaptasi otomatis saat situs berubah?
- Keamanan & Kepatuhan: Apakah data dan kredensial Anda terlindungi? Apakah alat ini membantu Anda tetap patuh pada aturan privasi?
Thunderbit memenuhi semua poin ini, menjadikannya pilihan utama bagi tim yang ingin tenaga besar tanpa ribet.
Cara Memulai: Menggunakan Cloud Crawler untuk Bisnis Anda
Siap mulai? Begini cara pengguna bisnis biasanya memulai dengan cloud crawler seperti Thunderbit:
- Pasang : Setup cepat, tanpa perlu IT.
- Pilih Target Anda: Buka website, daftar, atau dokumen yang ingin Anda scrape.
- Klik “AI Suggest Fields”: Biarkan AI Thunderbit memindai halaman dan merekomendasikan kolom terbaik untuk diekstrak.
- Sesuaikan Sesuai Kebutuhan: Tambah, hapus, atau ubah nama field agar cocok dengan kebutuhan Anda.
- Pilih Mode Cloud Scraping: Untuk pekerjaan besar atau situs kompleks, gunakan mode cloud agar kecepatan maksimal.
- Jalankan Scraping: Thunderbit akan memproses hingga 50 halaman sekaligus di cloud.
- Tinjau dan Ekspor: Pratinjau hasil Anda, lalu ekspor ke Excel, Google Sheets, Notion, atau Airtable.
- Jadwalkan Job Berulang: Untuk kebutuhan berkelanjutan, atur scraping terjadwal—data Anda akan diperbarui otomatis ().
Tips: Mulailah dari job kecil supaya terbiasa, lalu tingkatkan saat Anda sudah nyaman. Dan jangan ragu memakai dukungan atau dokumentasi Thunderbit—memang dibuat untuk membantu.
Masa Depan Pengumpulan Data: Apa Selanjutnya untuk Cloud Crawler?
Revolusi cloud crawler baru saja dimulai. Inilah yang saya lihat dalam beberapa tahun ke depan:
- Ekstraksi AI yang Lebih Cerdas: Cloud crawler makin mampu memahami konteks, hubungan antar data, bahkan sentimen—membuat data yang dikumpulkan jauh lebih bernilai ().
- Dukungan untuk Jenis Data Baru: Akan ada penanganan yang lebih baik untuk video, audio, dan konten interaktif—bukan cuma teks dan gambar statis.
- Otomasi yang Lebih Dalam: Dari penjadwalan otomatis hingga alert real-time, cloud crawler akan makin minim sentuhan manual bagi pengguna bisnis.
- Kepatuhan yang Lebih Kuat: Seiring berkembangnya aturan privasi, cloud crawler akan menanamkan lebih banyak alat untuk membantu tim tetap patuh pada regulasi.
- Integrasi dengan BI dan Tools AI: Pipeline langsung dari cloud crawler ke platform analitik, dashboard, dan machine learning.
Singkatnya, cloud crawler siap jadi tulang punggung strategi bisnis digital—mendorong segala hal mulai dari peluncuran produk hingga forecasting berbasis AI ().
Kesimpulan: Mengapa Cloud Crawler Penting untuk Bisnis Modern
Intinya: web dibanjiri data, dan cara lama untuk mengumpulkannya sudah tidak sanggup mengikuti laju perubahan. Cloud crawler adalah evolusi berikutnya—memberikan kecepatan, skala, dan kecerdasan yang tidak bisa ditandingi scraper tradisional. Alat seperti memungkinkan tim mana pun, teknis maupun non-teknis, memaksimalkan potensi data web—mendorong keputusan yang lebih cerdas, respons yang lebih cepat, dan keunggulan kompetitif yang nyata.
Kalau Anda siap meninggalkan scraping manual dan data yang lambat, sekarang waktunya melihat apa yang bisa dilakukan cloud crawler untuk bisnis Anda. Coba mode cloud scraping Thunderbit, dan rasakan betapa mudahnya penemuan data modern—serta betapa kuat hasilnya. Dan kalau Anda ingin belajar lebih jauh, kunjungi untuk panduan, tips, dan contoh nyata lainnya.
FAQ
1. Apa itu cloud crawler dalam istilah sederhana?
Cloud crawler adalah alat berbasis cloud yang secara otomatis menemukan, mengekstrak, dan menganalisis data dalam jumlah besar dari web. Berbeda dengan scraper tradisional yang berjalan di perangkat lokal, cloud crawler beroperasi di pusat data yang kuat, sehingga mampu bekerja dalam skala besar dan kecepatan tinggi.
2. Apa bedanya cloud crawler dengan web scraper biasa?
Cloud crawler berjalan di cloud, bisa menangani ribuan halaman sekaligus, mendukung jenis data kompleks seperti gambar dan PDF, serta tidak memerlukan maintenance atau hardware lokal. Scraper tradisional dibatasi oleh kekuatan perangkat Anda dan paling cocok untuk pekerjaan yang lebih kecil dan sederhana.
3. Apa manfaat utama menggunakan cloud crawler?
Cloud crawler menawarkan pengumpulan data cepat dalam skala besar, dukungan untuk situs yang kompleks, akses mudah dari mana saja, serta fitur lanjutan seperti penjadwalan dan ekstraksi berbasis AI. Sangat ideal untuk bisnis yang membutuhkan data terbaru dan bisa langsung ditindaklanjuti dengan cepat.
4. Bagaimana cara kerja cloud crawler Thunderbit untuk pengguna bisnis?
Cloud crawler Thunderbit memungkinkan Anda mengatur scraping hanya dalam beberapa klik—tanpa coding. Anda bisa mengekstrak data dari website, PDF, dan gambar, memperkayanya dengan AI, lalu mengekspor langsung ke Excel, Google Sheets, Notion, atau Airtable. Dirancang untuk pengguna non-teknis yang menginginkan hasil, bukan kerumitan.
5. Apakah cloud crawling aman dan sesuai dengan hukum privasi data?
Ya, cloud crawler terkemuka seperti Thunderbit menggunakan koneksi terenkripsi dan praktik terbaik untuk keamanan data. Pastikan selalu hanya melakukan scraping pada data yang tersedia secara publik dan patuhi ketentuan layanan situs serta regulasi privasi.
Siap melihat apa yang bisa dilakukan cloud crawler? dan mulai menjelajahi dunia pengumpulan data berbasis cloud dalam skala besar hari ini.
Pelajari Lebih Lanjut