

Web dipenuhi data berharga—baik Anda bergerak di bidang sales, ecommerce, maupun riset pasar, web scraping adalah senjata rahasia untuk lead generation, pemantauan harga, dan analisis kompetitor. Tapi ini tantangannya: semakin banyak bisnis memanfaatkan scraping, situs web juga semakin agresif melawan. Perubahannya nyata: sebuah analisis ppc.land 2024 menemukan bahwa lebih dari sepertiga dari 1.000 situs teratas sudah memblokir crawler OpenAI saja — dan rangkaian alat pemblokiran IP, CAPTCHA, dan browser fingerprinting yang lebih luas kini sudah jadi hal umum, bukan pengecualian.
Kalau Anda pernah melihat skrip Python berjalan mulus selama 20 menit—lalu tiba-tiba mentok di deretan error 403—Anda pasti tahu betapa frustrasinya hal itu.
Saya sudah bertahun-tahun berkecimpung di SaaS dan automation, dan saya melihat langsung bagaimana proyek scraping bisa berubah dari “wah, gampang juga” menjadi “kok saya diblokir di mana-mana?” dalam sekejap. Jadi, mari kita bahas secara praktis: saya akan memandu Anda melakukan web scraping tanpa diblokir di Python, berbagi teknik terbaik dan cuplikan kode, serta menunjukkan kapan saatnya mempertimbangkan alternatif berbasis AI seperti Thunderbit. Baik Anda pro Python atau baru coba-coba scraping, Anda akan pulang dengan toolkit untuk ekstraksi data yang andal dan bebas blokir.
Apa Itu Web Scraping Tanpa Diblokir di Python?
Pada dasarnya, web scraping tanpa diblokir berarti mengekstrak data dari situs web dengan cara yang tidak memicu pertahanan anti-bot mereka. Di dunia Python, ini bukan sekadar membuat loop requests.get()—ini tentang menyatu dengan pola pengguna asli, meniru perilaku manusia, dan selalu selangkah di depan sistem deteksi.
Kenapa Python? Python adalah bahasa paling populer untuk web scraping—berkat sintaksnya yang sederhana, ekosistemnya yang besar (misalnya: requests, BeautifulSoup, Scrapy, Selenium), dan fleksibilitasnya untuk segala hal mulai dari skrip cepat sampai crawler terdistribusi. Tapi popularitas ada harganya: banyak sistem anti-bot kini disetel untuk mengenali pola scraping berbasis Python.
Jadi, kalau Anda ingin scraping secara andal, Anda harus melampaui dasar-dasarnya. Artinya memahami bagaimana situs mendeteksi bot, dan bagaimana Anda bisa mengakalinya—tanpa melewati batas etika atau hukum.
Kenapa Menghindari Blokir Itu Penting untuk Proyek Web Scraping Python
Diblokir bukan cuma gangguan teknis—itu bisa merusak seluruh alur kerja bisnis. Mari kita uraikan:
| Kasus Penggunaan | Dampak Jika Diblokir |
|---|---|
| Lead Generation | Daftar prospek tidak lengkap atau usang, penjualan hilang |
| Pemantauan Harga | Perubahan harga kompetitor terlewat, keputusan harga jadi buruk |
| Agregasi Konten | Ada celah dalam data berita, ulasan, atau riset |
| Intelijen Pasar | Titik buta dalam pelacakan kompetitor atau industri |
| Listing Properti | Data properti tidak akurat atau kedaluwarsa, peluang terlewat |
Saat scraper diblokir, Anda bukan cuma kehilangan data—Anda juga membuang sumber daya, berisiko melanggar kepatuhan, dan berpotensi membuat keputusan bisnis yang salah karena informasi tidak lengkap. Di dunia di mana 79% bisnis mengandalkan web scraping untuk lead generation, keandalan adalah segalanya.
Bagaimana Situs Web Mendeteksi dan Memblokir Web Scraper Python
Situs web sekarang jauh lebih canggih dalam mendeteksi bot. Berikut pertahanan anti-scraping yang paling umum akan Anda temui (Medium, Bright Data):
- Pemblokiran IP Address: Terlalu banyak permintaan dari satu IP? Diblokir.
- Pemeriksaan User-Agent dan Header: Permintaan dengan header yang hilang atau generik (misalnya default Python
python-requests/2.25.1) terlihat mencolok. - Rate Limiting: Terlalu banyak permintaan dalam waktu singkat memicu throttling atau pemblokiran.
- CAPTCHA: Teka-teki “buktikan Anda manusia” yang tidak bisa diselesaikan bot (setidaknya tidak dengan mudah).
- Analisis Perilaku: Situs mengamati pola yang terlalu mekanis—misalnya mengklik tombol yang sama dengan interval yang sama.
- Honeypot: Tautan atau field tersembunyi yang hanya akan disentuh bot.
- Browser Fingerprinting: Mengumpulkan detail browser dan perangkat untuk mendeteksi alat otomasi.
- Pelacakan Cookie dan Sesi: Bot yang tidak menangani cookie atau sesi dengan benar akan ditandai.
Anggap saja seperti pemeriksaan keamanan bandara: kalau Anda terlihat, bergerak, dan bertindak seperti orang lain, Anda bisa lewat mulus. Kalau Anda datang pakai jas panjang dan kacamata hitam, jangan kaget kalau ditanya lebih banyak.
Teknik Python Esensial untuk Web Scraping Tanpa Diblokir
Sekarang bagian yang penting: bagaimana cara benar-benar menghindari blokir saat scraping dengan Python. Berikut strategi inti yang perlu diketahui setiap scraper:

Proxy dan IP Address Bergantian
Kenapa penting: Kalau semua permintaan datang dari IP yang sama, Anda jadi target empuk untuk pemblokiran IP. Proxy bergantian memungkinkan Anda menyebarkan permintaan ke banyak IP, sehingga jauh lebih sulit diblokir.
Cara melakukannya di Python:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...proxy lainnya
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# proses response
Anda bisa memakai layanan proxy berbayar (misalnya residential atau rotating proxy) untuk keandalan yang lebih baik (ScrapingBee).
Mengatur User-Agent dan Header Kustom
Kenapa penting: Header default Python teriak “bot”. Tiru browser asli dengan mengatur user-agent dan header lainnya.
Contoh kode:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Ganti-ganti user-agent untuk penyamaran tambahan (ZenRows).
Mengacak Waktu dan Pola Permintaan
Kenapa penting: Bot itu cepat dan dapat ditebak; manusia lambat dan acak. Tambahkan jeda dan variasikan pola navigasi Anda.
Tips Python:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # Tunggu 2–7 detik
Anda juga bisa mengacak jalur klik dan pola scroll jika memakai Selenium.
Mengelola Cookie dan Sesi
Kenapa penting: Banyak situs memerlukan cookie atau token sesi untuk mengakses konten. Bot yang mengabaikannya akan diblokir.
Cara mengelolanya di Python:
import requests
session = requests.Session()
response = session.get(url)
# session akan menangani cookie secara otomatis
Untuk alur yang lebih kompleks, gunakan Selenium untuk menangkap dan memakai ulang cookie.
Meniru Perilaku Manusia dengan Headless Browser
Kenapa penting: Beberapa situs memakai JavaScript, pergerakan mouse, atau scroll sebagai sinyal pengguna asli. Headless browser seperti Selenium atau Playwright bisa meniru aksi ini.
Contoh dengan Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
Ini membantu Anda melewati analisis perilaku dan konten dinamis (ScrapingBee).
Strategi Lanjutan: Mengatasi CAPTCHA dan Honeypot di Python
CAPTCHA dirancang untuk menghentikan bot di tempat. Walau ada library Python yang bisa menyelesaikan CAPTCHA sederhana, sebagian besar scraper serius mengandalkan layanan pihak ketiga (seperti 2Captcha atau Anti-Captcha) untuk menyelesaikannya dengan biaya tertentu (Medium).
Contoh integrasi:
# Pseudocode untuk memakai API 2Captcha
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Tunggu solusinya, lalu kirim bersama request Anda
Honeypot adalah field atau tautan tersembunyi yang hanya akan disentuh bot. Hindari mengklik atau mengirim apa pun yang tidak terlihat di browser sungguhan (ZenRows).
Mendesain Header Request yang Kuat dengan Library Python
Selain user-agent, Anda bisa mengganti dan mengacak header lain (seperti Referer, Accept, Origin, dll.) agar makin menyatu.
Dengan Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# Header lainnya
}
}
Dengan Selenium: Gunakan profil browser atau ekstensi untuk mengatur header, atau sisipkan lewat JavaScript.
Jaga agar daftar header Anda selalu diperbarui—salin request browser asli lewat DevTools browser untuk dijadikan acuan.
Saat Scraping Python Tradisional Tidak Cukup: Naiknya Teknologi Anti-Bot
Inilah kenyataannya: semakin populer scraping, semakin canggih juga peningkatan anti-bot. Situs-situs besar kini tidak hanya memblokir bot yang jelas-jelas bot, tetapi juga headless browser dan proxy bergantian yang canggih. Deteksi berbasis AI, ambang permintaan dinamis, dan browser fingerprinting membuat skrip Python tingkat lanjut pun makin sulit lolos tanpa terdeteksi (Medium).
Kadang, sehebat apa pun kode Anda, Anda tetap akan mentok. Saat itulah Anda perlu mempertimbangkan pendekatan lain.
Thunderbit: Alternatif AI Web Scraper untuk Scraping dengan Python
Saat Python mencapai batasnya, Thunderbit hadir sebagai web scraper tanpa kode berbasis AI yang dibuat untuk pengguna bisnis—bukan hanya developer. Alih-alih bergulat dengan proxy, header, dan CAPTCHA, agen AI Thunderbit membaca situs web, menyarankan field terbaik untuk diekstrak, dan menangani semuanya mulai dari navigasi subhalaman sampai ekspor data.
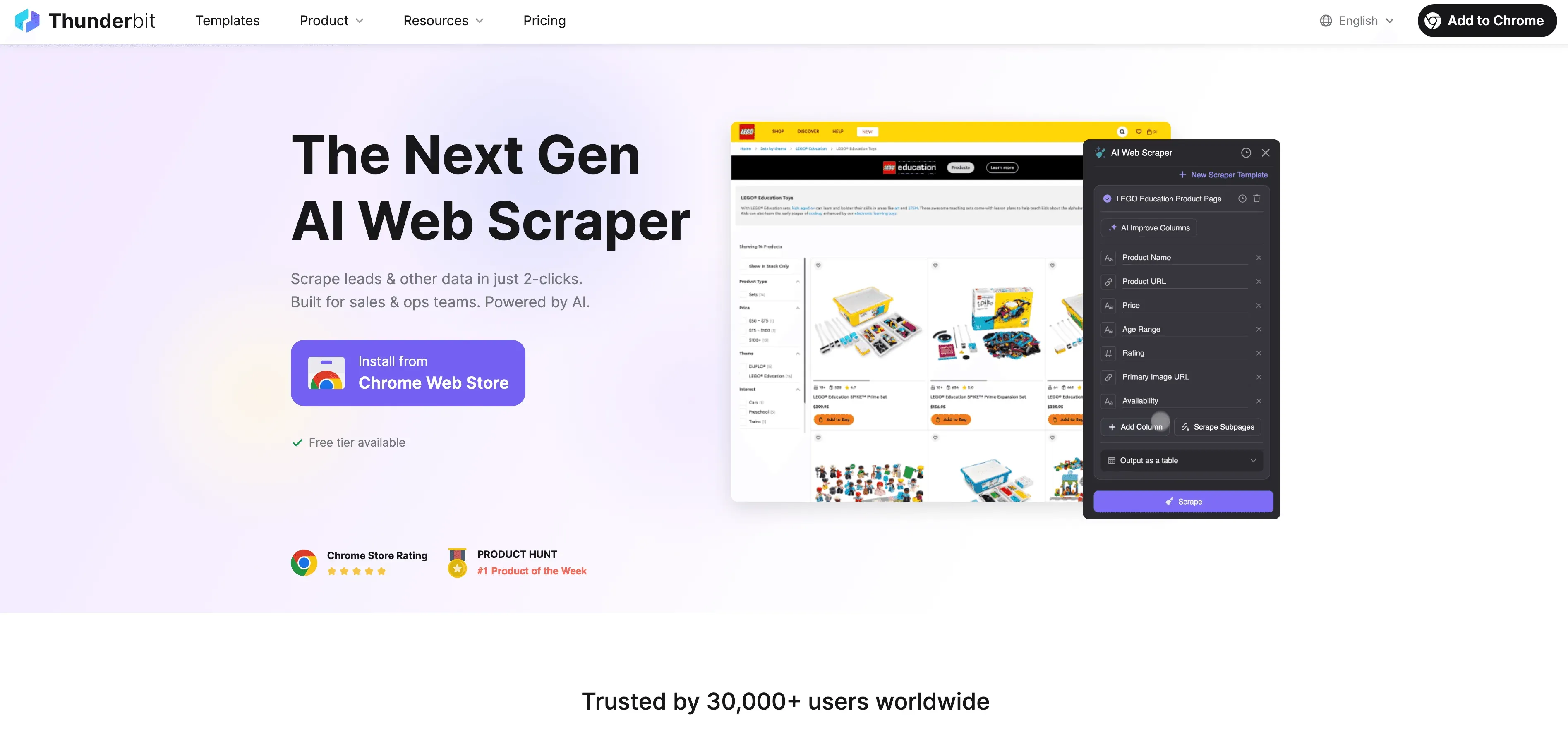
Apa yang membuat Thunderbit berbeda?
- Saran Field AI: Klik “AI Suggest Fields” dan Thunderbit memindai halaman, merekomendasikan kolom, bahkan menghasilkan instruksi ekstraksi.
- Scraping Subhalaman: Thunderbit bisa membuka setiap subhalaman (misalnya detail produk atau profil LinkedIn) dan memperkaya tabel Anda secara otomatis.
- Scraping Cloud atau Browser: Pilih opsi tercepat—cloud untuk situs publik, browser untuk halaman yang dilindungi login.
- Scraping Terjadwal: Setel sekali lalu biarkan—Thunderbit bisa scraping sesuai jadwal, jadi data Anda selalu segar.
- Template Instan: Untuk situs populer (Amazon, Zillow, Shopify, dll.), Thunderbit menyediakan template 1 klik—tanpa setup.
- Ekspor Data Gratis: Ekspor ke Excel, Google Sheets, Airtable, atau Notion—tanpa biaya tambahan.
Thunderbit dipercaya oleh lebih dari 100.000 pengguna di seluruh dunia, dan Anda tidak perlu menulis satu baris kode pun.
Ekstrak data dari situs web apa pun menggunakan AI Get Started Free
Bagaimana Thunderbit Membantu Pengguna Menghindari Blokir dan Mengotomatiskan Ekstraksi Data
AI Thunderbit tidak sekadar meniru perilaku manusia—ia menyesuaikan diri dengan setiap situs secara real time, sehingga risiko diblokir jadi lebih kecil. Inilah caranya:
- AI menyesuaikan perubahan tata letak: Lebih sedikit kerja ulang saat situs memperbarui desain — Anda tidak perlu menyetel ulang selector setiap minggu.
- Penanganan subhalaman dan pagination: Thunderbit mengikuti tautan dan daftar berhalaman untuk Anda, seperti orang yang mengklik satu per satu.
- Scraping cloud secara batch: Jalankan pekerjaan dari cloud Thunderbit, bukan dari laptop Anda, dengan ukuran batch yang disesuaikan per paket (lihat halaman harga untuk batas terbaru).
- Lebih sedikit kode yang harus dipelihara: Anda tidak perlu mengejar selector yang rusak tengah malam saat situs berubah; AI akan membaca ulang halaman.
Untuk pembahasan lebih dalam, lihat Cara Melakukan Scraping Situs Apa Pun dengan AI.
Membandingkan Scraping Python vs. Thunderbit: Mana yang Harus Dipilih?
Mari kita bandingkan berdampingan:
| Fitur | Scraping Python | Thunderbit |
|---|---|---|
| Waktu Setup | Sedang–Tinggi (skrip, proxy, dll.) | Rendah (2 klik, AI mengerjakan sisanya) |
| Keahlian Teknis | Perlu coding | Tidak perlu coding |
| Keandalan | Bervariasi (mudah rusak) | Tinggi (AI menyesuaikan perubahan) |
| Risiko Diblokir | Sedang–Tinggi | Rendah (AI meniru pengguna, beradaptasi) |
| Skalabilitas | Perlu kode kustom/setup cloud | Scraping cloud/batch bawaan |
| Pemeliharaan | Sering (perubahan situs, blokir) | Minimal (AI otomatis menyesuaikan) |
| Opsi Ekspor | Manual (CSV, DB) | Langsung ke Sheets, Notion, Airtable, CSV |
| Biaya | Gratis (tapi menghabiskan waktu) | Paket gratis, paket berbayar untuk skala besar |
Kapan memakai Python:
- Anda butuh kontrol penuh, logika kustom, atau integrasi dengan alur kerja Python lain.
- Anda scraping situs dengan pertahanan anti-bot yang minim.
Kapan memakai Thunderbit:
- Anda ingin cepat, andal, dan tanpa setup.
- Anda scraping situs yang kompleks atau sering berubah.
- Anda tidak mau repot dengan proxy, CAPTCHA, atau kode.
Coba Thunderbit AI Web Scraper Gratis
Panduan Langkah demi Langkah: Menyiapkan Web Scraping Tanpa Diblokir di Python
Mari kita lihat contoh praktis: scraping data produk dari situs contoh, sambil menerapkan praktik terbaik anti-blokir.
1. Instal Library yang Diperlukan
pip install requests beautifulsoup4 fake-useragent
2. Siapkan Skrip Anda
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Ganti dengan URL Anda
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Ekstrak data di sini
print(soup.title.text)
else:
print(f"Diblokir atau error pada {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Jeda acak
3. Tambahkan Rotasi Proxy (Opsional)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Proxy lainnya
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...lanjutan kode
4. Tangani Cookie dan Sesi
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...lanjutan kode
5. Tips Troubleshooting
- Jika Anda melihat banyak error 403/429, perlambat permintaan Anda atau coba proxy baru.
- Jika terkena CAPTCHA, pertimbangkan memakai Selenium atau layanan pemecah CAPTCHA.
- Selalu periksa
robots.txtdan ketentuan layanan situs.
Kesimpulan & Poin Penting
Web scraping di Python itu kuat—tetapi diblokir selalu menjadi risiko seiring berkembangnya teknologi anti-bot. Cara terbaik untuk menghindari blokir? Gabungkan praktik teknis terbaik (proxy bergantian, header cerdas, jeda acak, penanganan sesi, dan headless browser) dengan kepatuhan terhadap aturan dan etika situs.
Namun, kadang trik Python terbaik pun belum cukup. Di situlah alat AI seperti Thunderbit berperan — tanpa kode, dirancang untuk menangani perubahan tata letak dan pagination yang sering menjatuhkan skrip kaku, dan ditujukan untuk pengguna bisnis yang tidak ingin menghabiskan malam mereka menjaga job Selenium.
Ingin melihat betapa mudahnya scraping? Unduh Ekstensi Chrome Thunderbit dan coba sendiri—atau cek blog kami untuk tips dan tutorial scraping lainnya.
FAQ
1. Kenapa situs web memblokir web scraper Python?
Situs web memblokir scraper untuk melindungi data mereka, mencegah server overload, dan menghentikan bot otomatis yang menyalahgunakan layanan mereka. Skrip Python mudah dikenali jika memakai header default, tidak menangani cookie, atau mengirim terlalu banyak permintaan terlalu cepat.
2. Apa cara paling efektif untuk menghindari blokir saat scraping dengan Python?
Gunakan proxy bergantian, atur user-agent dan header yang realistis, acak waktu permintaan, kelola cookie/sesi, dan tirukan perilaku manusia dengan alat seperti Selenium atau Playwright.
3. Bagaimana Thunderbit membantu menghindari blokir dibandingkan skrip Python?
Thunderbit menggunakan AI untuk menyesuaikan diri dengan tata letak situs, meniru kebiasaan browsing manusia, dan menangani subhalaman serta pagination secara otomatis. Risiko blokir jadi lebih kecil karena ia menyatu dengan pola normal dan memperbarui pendekatannya secara real time—tanpa perlu coding atau proxy.
4. Kapan saya harus memakai scraping Python vs. alat AI seperti Thunderbit?
Gunakan Python kalau Anda butuh logika kustom, integrasi dengan kode Python lain, atau sedang scraping situs sederhana. Gunakan Thunderbit untuk scraping yang cepat, andal, dan bisa diskalakan—terutama saat situsnya kompleks, sering berubah, atau agresif memblokir skrip.
5. Apakah web scraping legal?
Web scraping legal untuk data yang tersedia secara publik, tetapi Anda harus menghormati ketentuan layanan, kebijakan privasi, dan hukum yang relevan dari tiap situs. Jangan pernah melakukan scraping terhadap data sensitif atau pribadi, dan selalu lakukan scraping secara etis dan bertanggung jawab.
Siap scraping lebih cerdas, bukan lebih keras? Coba Thunderbit, dan tinggalkan blokir di belakang.
Pelajari Lebih Lanjut:
- Scraping Google News dengan Python: Panduan Langkah demi Langkah
- Bangun Tool Pelacak Harga Best Buy dengan Python
- 14 Cara Melakukan Web Scraping Tanpa Diblokir
- 10 Tips Terbaik Agar Tidak Diblokir Saat Web Scraping
Coba AI Web Scraper Get Started Free




