
Ada sensasi yang nggak pernah basi saat kamu buka terminal, ketik satu perintah, lalu data web mentah langsung “ngalir” di layar—rasanya kayak baru aja nge-unlock Matrix. Buat developer dan pengguna teknis, itu semacam 마법 지팡이: tool command-line yang kelihatannya simpel, tapi diam-diam hidup di miliaran perangkat—dari server cloud sampai kulkas pintar. Dan bahkan di 2026, ketika tool scraping no-code dan AI makin menjamur, web scraping dengan curl tetap jadi andalan buat siapa pun yang butuh serba cepat, kontrol penuh, dan gampang di-script.
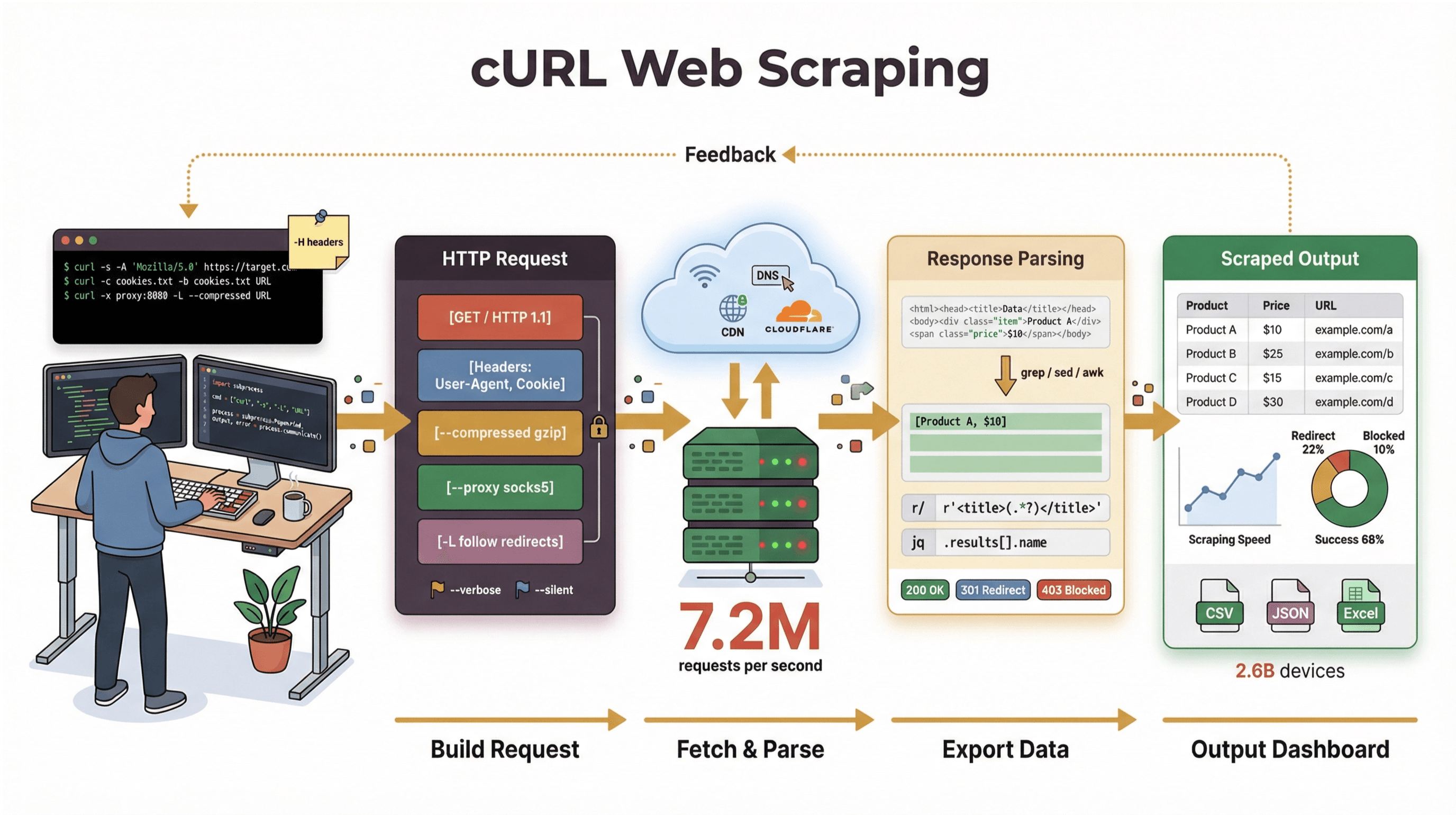 Saya sudah bertahun-tahun bikin tool otomasi dan bantu tim “menjinakkan” data web, dan sampai sekarang saya masih mengandalkan cURL saat perlu ambil halaman, debug API, atau bikin prototipe alur scraping. Di panduan ini, saya bakal ngajak kamu ngikutin tutorial web scraping curl dari nol sampai trik level 고수—lengkap dengan contoh perintah yang beneran kepakai, tips praktis, plus penjelasan jujur kapan cURL itu super unggul (dan kapan mentok). Dan kalau kamu lebih condong sebagai pengguna bisnis yang ogah ribet sama command line, saya juga bakal tunjukin gimana , web scraper bertenaga AI kami, bisa mengubah “saya butuh data ini” jadi “ini spreadsheet-nya” cuma dalam dua klik—tanpa coding.
Saya sudah bertahun-tahun bikin tool otomasi dan bantu tim “menjinakkan” data web, dan sampai sekarang saya masih mengandalkan cURL saat perlu ambil halaman, debug API, atau bikin prototipe alur scraping. Di panduan ini, saya bakal ngajak kamu ngikutin tutorial web scraping curl dari nol sampai trik level 고수—lengkap dengan contoh perintah yang beneran kepakai, tips praktis, plus penjelasan jujur kapan cURL itu super unggul (dan kapan mentok). Dan kalau kamu lebih condong sebagai pengguna bisnis yang ogah ribet sama command line, saya juga bakal tunjukin gimana , web scraper bertenaga AI kami, bisa mengubah “saya butuh data ini” jadi “ini spreadsheet-nya” cuma dalam dua klik—tanpa coding.
Yuk mulai, dan kita lihat kenapa cURL masih relevan untuk web scraping di 2025, cara pakainya biar efektif, dan kapan waktunya pindah ke sesuatu yang lebih kuat.
Apa itu cURL? Fondasi Web-Scraping-with-curl
Pada intinya, adalah tool command-line sekaligus library buat mindahin data lewat URL. Umurnya hampir 30 tahun (iya, beneran), dan ada di mana-mana—nempel di sistem operasi, dipakai di berbagai script, dan diam-diam ngurus transfer data di lebih dari . Kalau kamu pernah jalanin perintah cepat buat ngambil halaman web, ngetes API, atau download file, kemungkinan besar kamu sudah pernah pakai cURL.
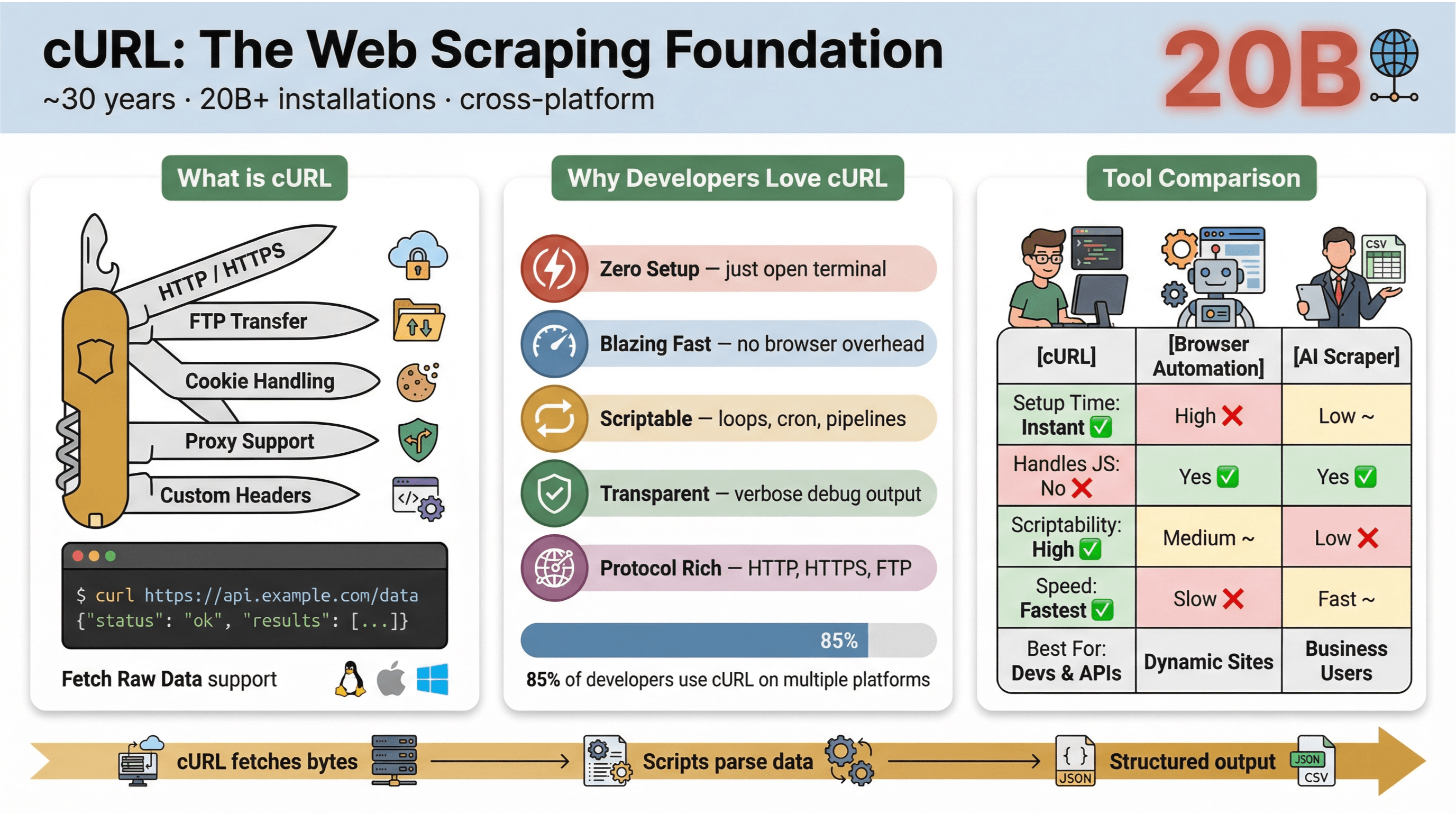 Ini yang bikin cURL populer buat web scraping:
Ini yang bikin cURL populer buat web scraping:
- Ringan dan lintas platform: Jalan di Linux, macOS, Windows, bahkan perangkat embedded.
- Dukungan protokol: Bisa nangani HTTP, HTTPS, FTP, dan lainnya.
- Mudah di-script: Cocok buat otomasi, cron job, dan “glue code”.
- Tanpa interaksi pengguna: Memang didesain non-interaktif—pas buat batch job dan pipeline.
Tapi perlu digarisbawahi: kerja utama cURL itu ngambil data mentah—HTML, JSON, gambar, apa pun. cURL nggak mem-parsing, nggak me-render, dan nggak nyusun data itu jadi format rapi. Anggap cURL sebagai “kilometer pertama” web scraping: dia nganterin byte-nya, tapi kamu butuh tool lain (misalnya script Python, grep/sed/awk, atau AI web scraper) buat ngubahnya jadi data terstruktur.
Kalau mau lihat dokumentasi resminya, cek .
Kenapa Pakai cURL untuk Web Scraping? (curl web scraping tutorial)
Dengan seabrek tool baru, kenapa developer dan pengguna teknis masih balik lagi ke cURL buat web scraping? Ini alasan utamanya:
- Nyaris tanpa setup: Nggak perlu instal tambahan, nggak ada dependency—buka terminal, langsung gas.
- Cepat: Ambil data seketika tanpa nunggu browser loading.
- Mudah diotomasi: Gampang loop URL, otomasi request, dan ngerangkai perintah.
- Fitur HTTP lengkap: Bisa ngatur cookie, proxy, redirect, header kustom, dan banyak lagi.
- Transparan: Kamu bisa lihat detail proses lewat output verbose/debug.
Dalam , lebih dari 85% responden bilang mereka pakai tool command-line cURL, dan hampir semuanya memakainya di lebih dari satu platform. cURL masih jadi “pisau Swiss” buat request HTTP, tarik data cepat, dan troubleshooting.
Berikut perbandingan singkat cURL vs metode scraping lain:
| Fitur | cURL | Otomasi Browser (mis. Selenium) | AI Web Scraper (mis. Thunderbit) |
|---|---|---|---|
| Waktu Setup | Instan | Tinggi | Rendah |
| Kemudahan di-script | Tinggi | Sedang | Rendah (tanpa kode) |
| Menangani JavaScript | Tidak | Ya | Ya (Thunderbit: via browser) |
| Dukungan Cookie/Sesi | Manual | Otomatis | Otomatis |
| Penyusunan Data | Manual (parse belakangan) | Manual (parse belakangan) | Berbasis AI/Template |
| Paling Cocok Untuk | Dev, tarik cepat | Situs dinamis/kompleks | Pengguna bisnis, ekspor terstruktur |
Intinya: cURL itu nggak ada lawan untuk pengambilan data cepat yang bisa di-script—terutama buat halaman statis, API, atau otomasi sederhana. Tapi begitu kamu butuh parsing HTML yang ribet, harus nangani JavaScript, atau pengin ekspor data terstruktur, kamu bakal butuh tool yang lebih spesifik.
Mulai Cepat: Contoh Perintah Dasar cURL untuk Web Scraping
Sekarang praktik. Berikut cara pakai cURL untuk tugas web scraping dasar, step-by-step.
Mengambil HTML Mentah dengan cURL
Kasus paling simpel: ambil HTML sebuah halaman.
1curl https://books.toscrape.com/Perintah ini ngambil homepage , situs demo publik untuk web scraping. Kamu bakal lihat output HTML mentah di terminal—cari tag seperti <title> atau potongan teks seperti “In stock.”
Menyimpan Output ke File
Mau simpan HTML buat diparse nanti? Pakai flag -o:
1curl -o page.html https://books.toscrape.com/Sekarang kamu punya file page.html berisi HTML lengkap. Ini ideal buat dianalisis atau diparse pakai tool lain.
Mengirim Request POST dengan cURL
Perlu submit form atau interaksi dengan API? Gunakan flag -d untuk POST. Contoh berikut pakai , situs buat pengujian HTTP:
1curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"Kamu bakal dapat respons JSON yang “memantulkan” data yang kamu kirim—mantap buat testing dan prototyping.
Melihat Header dan Debugging
Kadang kamu perlu lihat header respons atau nge-debug request:
-
Header saja (request HEAD):
1curl -I https://books.toscrape.com/ -
Header + body:
1curl -i https://httpbin.org/get -
Output verbose/debug:
1curl -v https://books.toscrape.com/
Flag ini bantu kamu paham apa yang terjadi “di balik layar”—penting banget buat troubleshooting.
Berikut tabel ringkasnya:
| Tugas | Contoh Perintah | Catatan |
|---|---|---|
| Ambil HTML | curl URL | Menampilkan HTML di terminal |
| Simpan ke file | curl -o file.html URL | Menulis output ke file |
| Cek header | curl -I URL atau curl -i URL | -I untuk HEAD saja, -i menyertakan header bersama body |
| POST data form | curl -d "a=1&b=2" URL | Mengirim data form-encoded |
| Debug request/response | curl -v URL | Menampilkan detail request/response |
Untuk contoh lain, lihat .
Naik Level: Web Scraping Lanjutan dengan cURL (web-scraping-with-curl)
Setelah kamu nyaman dengan dasar-dasarnya, cURL punya banyak fitur lanjutan buat kebutuhan scraping yang lebih kompleks.
Menangani Cookie dan Sesi
Banyak situs butuh cookie buat menjaga sesi login atau tracking pengguna. Dengan cURL, kamu bisa simpan dan pakai ulang cookie antar request:
1# Simpan cookie setelah login
2curl -c cookies.txt https://example.com/login
3# Gunakan cookie untuk request berikutnya
4curl -b cookies.txt https://example.com/accountIni bikin kamu bisa meniru sesi browser dan akses halaman di balik login (selama nggak ada tantangan JavaScript).
Menyamarkan User-Agent dan Header Kustom
Sebagian website ngasih konten beda tergantung User-Agent atau header. Secara default, cURL ngenalin diri sebagai “curl/VERSION”, yang bisa memicu blokir atau konten alternatif. Buat meniru browser:
1curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/Kamu juga bisa nambah header kustom, misalnya preferensi bahasa:
1curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/Ini bantu kamu dapat konten yang sama seperti yang dilihat browser beneran.
Menggunakan Proxy untuk Web Scraping
Perlu lewat proxy (buat uji lokasi/geo atau ngurangin risiko IP diblokir)? Gunakan flag -x:
1curl -x http://proxy.example.org:4321 https://remote.example.org/Pastikan kamu pakai proxy secara bertanggung jawab dan sesuai ketentuan layanan situs.
Mengotomasi Scraping Multi-Halaman
Mau scrape banyak halaman—misalnya listing produk yang dipaginasi? Pakai loop shell sederhana:
1for p in $(seq 2 5); do
2 curl -s -o "books-page-${p}.html" \
3 "https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
4 sleep 1
5doneIni ngambil halaman 2 sampai 5 dari katalog Books to Scrape dan nyimpennya ke file terpisah. (Halaman 1 adalah homepage.)
Keterbatasan Web-Scraping-with-curl: Hal yang Wajib Anda Tahu
Walau saya suka cURL, ini bukan solusi buat semua kasus. Ini titik lemahnya:
- Tidak menjalankan JavaScript: cURL nggak bisa nangani halaman yang butuh JavaScript buat render konten atau menyelesaikan tantangan anti-bot ().
- Parsing harus manual: Kamu cuma dapat HTML/JSON mentah, dan harus parsing sendiri—biasanya pakai script atau tool tambahan.
- Manajemen sesi terbatas: Ngatur login kompleks, token, atau form multi-langkah bisa cepat jadi ruwet.
- Tidak ada penyusunan data bawaan: cURL nggak otomatis ngubah halaman web jadi baris, tabel, atau spreadsheet.
- Rentan terdeteksi anti-bot: Banyak situs pakai pertahanan bot canggih (JavaScript, fingerprinting, CAPTCHA) yang nggak bisa ditembus cURL ().
Tabel perbandingan singkat:
| Keterbatasan | cURL Saja | Tool Scraping Modern (mis. Thunderbit) |
|---|---|---|
| Dukungan JavaScript | Tidak | Ya |
| Penyusunan Data | Manual | Otomatis (AI/Template) |
| Penanganan Sesi | Manual | Otomatis |
| Bypass Anti-Bot | Terbatas | Lanjutan (berbasis browser/AI) |
| Kemudahan Penggunaan | Teknis | Non-teknis |
Untuk halaman statis dan API, cURL itu luar biasa. Buat situs yang dinamis atau terlindungi, kamu perlu naik kelas ke tool lain.
Thunderbit vs. cURL: Pendekatan Web Scraping Terbaik untuk Pengguna Non-Teknis
Sekarang kita bahas , Chrome Extension web scraper bertenaga AI kami. Kalau kamu sales, marketer, atau tim operasional yang cuma pengin mindahin data dari website ke Excel, Google Sheets, atau Notion—tanpa nyentuh command line—Thunderbit dibuat buat kamu.
Perbandingan Thunderbit vs cURL:
| Fitur | cURL | Thunderbit |
|---|---|---|
| Antarmuka | Command line | Point-and-click (Chrome Extension) |
| Saran Field oleh AI | Tidak | Ya (AI membaca halaman, menyarankan kolom) |
| Pagination/Subpage | Script manual | Otomatis (AI mendeteksi dan melakukan scraping) |
| Ekspor Data | Manual (parse + simpan) | Langsung ke Excel, Google Sheets, Notion, Airtable |
| Halaman JavaScript/Terlindungi | Tidak | Ya (scraping berbasis browser) |
| Tanpa Kode | Tidak (perlu scripting) | Ya (siapa pun bisa pakai) |
| Paket Gratis | Selalu gratis | Gratis hingga 6 halaman (10 dengan trial boost) |
Dengan Thunderbit, kamu tinggal buka extension, klik “AI Suggest Fields”, dan biarkan AI nentuin data apa yang perlu diambil. Kamu bisa scrape tabel, daftar, detail produk, bahkan otomatis buka subpage. Habis itu, ekspor langsung ke tool bisnis favorit—tanpa parsing, tanpa pusing.
Thunderbit dipercaya lebih dari , dan populer banget di tim sales, ecommerce, dan real estate yang butuh data terstruktur dengan cepat.
Mau coba? .
Menggabungkan cURL dan Thunderbit: Strategi Web Scraping yang Fleksibel
Kalau kamu pengguna teknis, kamu nggak harus pilih salah satu. Bahkan, banyak tim pakai cURL dan Thunderbit barengan biar lebih fleksibel:
- Prototipe dengan cURL: Pakai cURL buat ngetes endpoint cepat, ngecek header, dan memahami respons situs.
- Scale dengan Thunderbit: Saat butuh data terstruktur, scraping multi-halaman, atau workflow yang bisa diulang, pindah ke Thunderbit buat ekstraksi point-and-click dan ekspor langsung.
Contoh alur kerja untuk riset pasar:
- Gunakan cURL untuk mengambil beberapa halaman dan mengamati struktur HTML.
- Tentukan field data yang dibutuhkan (mis. nama produk, harga, ulasan).
- Buka Thunderbit, klik “AI Suggest Fields”, dan biarkan AI menyiapkan scraper.
- Scrape semua halaman (termasuk subpage atau daftar berpaginasi) lalu ekspor ke Google Sheets.
- Analisis, bagikan, dan ambil tindakan—tanpa parsing manual.
Tabel keputusan cepat:
| Skenario | Pakai cURL | Pakai Thunderbit | Pakai Keduanya |
|---|---|---|---|
| Ambil API/halaman statis dengan cepat | ✅ | ||
| Butuh data terstruktur di spreadsheet | ✅ | ||
| Debug header/cookie | ✅ | ||
| Scrape halaman dinamis/berat JavaScript | ✅ | ||
| Membuat workflow no-code yang bisa diulang | ✅ | ||
| Prototipe lalu scale | ✅ | ✅ | Workflow hybrid |
Tantangan Umum dan Jebakan Saat Web Scraping dengan cURL
Sebelum kamu “gaspol” dengan cURL, ini tantangan nyata yang biasanya muncul:
- Sistem anti-bot: Banyak situs pakai pertahanan canggih (tantangan JavaScript, CAPTCHA, fingerprinting) yang nggak bisa dilewati cURL ().
- Masalah kualitas data: Perubahan HTML, field hilang, atau layout nggak konsisten bisa bikin script ambyar.
- Beban maintenance: Tiap kali situs berubah, kamu harus update logika parsing.
- Risiko legal dan kepatuhan: Selalu cek terms of service, robots.txt, dan hukum yang relevan sebelum scraping. Data publik bukan berarti bebas dipakai (, ).
- Batas skala: cURL oke buat kerja kecil, tapi buat skala besar kamu perlu ngatur proxy, rate limit, dan error handling.
Tips untuk troubleshooting dan tetap patuh:
- Mulailah dari situs demo atau yang mengizinkan (seperti ).
- Hormati rate limit—jangan ngebomb endpoint.
- Hindari scraping data pribadi kecuali kamu punya dasar hukum yang jelas.
- Kalau mentok di JavaScript atau CAPTCHA, pertimbangkan pindah ke tool berbasis browser seperti Thunderbit.
Ringkasan Langkah demi Langkah: Cara Scrape Website dengan cURL
Checklist cepat web-scraping-with-curl:
- Tentukan URL target: Mulai dari halaman statis atau endpoint API.
- Ambil halaman:
curl URL - Simpan output ke file:
curl -o file.html URL - Cek header/debug:
curl -I URL,curl -v URL - Kirim data POST:
curl -d "a=1&b=2" URL - Kelola cookie/sesi:
curl -c cookies.txt ...,curl -b cookies.txt ... - Atur header/User-Agent:
curl -A "..." -H "..." URL - Ikuti redirect:
curl -L URL - Gunakan proxy (jika perlu):
curl -x proxy:port URL - Otomasi scraping multi-halaman: Pakai loop shell atau script.
- Parse dan susun data: Gunakan tool/script tambahan sesuai kebutuhan.
- Beralih ke Thunderbit untuk scraping terstruktur tanpa kode atau halaman dinamis.
Penutup & Poin Penting: Memilih Tool Web Scraping yang Tepat
Web-scraping-with-curl tetap jadi skill yang kuat buat pengguna teknis di 2026—terutama untuk tarik data cepat, prototyping, dan otomasi. Kecepatan, kemudahan di-script, dan ketersediaannya di mana-mana bikin cURL jadi perlengkapan wajib di toolbox developer. Tapi, seiring web makin dinamis dan terlindungi, serta pengguna bisnis makin menuntut data terstruktur tanpa kode, tool seperti ikut mendefinisikan ulang batas kemungkinannya.
Poin penting:
- Gunakan cURL untuk halaman statis, API, dan prototyping cepat—terutama saat kamu butuh kontrol penuh.
- Beralih ke Thunderbit (atau AI web scraper sejenis) saat kamu butuh data terstruktur, harus menangani halaman dinamis/berat JavaScript, atau pengin workflow no-code yang ramah pengguna bisnis.
- Gabungkan keduanya untuk fleksibilitas maksimal: prototipe dengan cURL, lalu scale dan rapikan dengan Thunderbit.
- Selalu lakukan scraping secara bertanggung jawab—patuhi ketentuan situs, rate limit, dan batasan hukum.
Penasaran betapa gampangnya web scraping? dan rasakan ekstraksi data bertenaga AI. Kalau mau belajar lebih dalam, mampir ke buat tutorial, tips, dan insight industri lainnya. Kamu mungkin juga suka:
Selamat scraping—semoga data kamu selalu bersih, rapi, dan tinggal satu perintah (atau satu klik) lagi.
FAQs
1. Apakah cURL bisa menangani halaman web yang dirender oleh JavaScript?
Tidak. cURL tidak dapat menjalankan JavaScript. cURL hanya mengambil HTML mentah yang dikirim server. Jika sebuah halaman membutuhkan JavaScript untuk menampilkan konten atau menyelesaikan tantangan anti-bot, cURL tidak akan bisa mengakses datanya. Untuk kasus seperti itu, gunakan tool berbasis browser seperti .
2. Bagaimana cara menyimpan output cURL langsung ke file?
Gunakan flag -o: curl -o filename.html URL. Ini akan menulis body respons ke file, bukan menampilkannya di terminal.
3. Apa bedanya cURL dan Thunderbit untuk web scraping?
cURL adalah tool command-line untuk mengambil data web mentah—cocok untuk pengguna teknis dan otomasi. Thunderbit adalah Chrome Extension bertenaga AI yang dirancang untuk pengguna bisnis yang ingin mengekstrak data terstruktur dari website mana pun, menangani halaman dinamis, dan mengekspor langsung ke tool seperti Excel atau Google Sheets—tanpa coding.
4. Apakah scraping website dengan cURL itu legal?
Scraping data publik umumnya legal di AS setelah putusan pengadilan terbaru, tetapi kamu tetap harus memeriksa terms of service situs, robots.txt, dan hukum yang relevan. Hindari scraping data pribadi atau data yang dilindungi tanpa izin, serta patuhi rate limit dan pedoman etika (, ).
5. Kapan saya sebaiknya beralih dari cURL ke tool yang lebih canggih seperti Thunderbit?
Kalau kamu perlu scrape halaman dinamis/berat JavaScript, pengin data terstruktur di spreadsheet, atau lebih suka workflow no-code, Thunderbit adalah pilihan yang lebih pas. Pakai cURL untuk tugas teknis yang cepat; pakai Thunderbit untuk ekstraksi data yang ramah pengguna bisnis dan gampang diulang.
Untuk tips dan tutorial web scraping lainnya, kunjungi atau lihat .