

Apakah web scraping ilegal? Itulah pertanyaan bernilai jutaan dolar yang saya dengar dari para founder, marketer, dan penggemar data setiap minggu.
Dengan 51% dari seluruh lalu lintas internet kini berasal dari bot—untuk pertama kalinya lalu lintas otomatis melampaui aktivitas manusia—dan porsi besar di antaranya dipakai untuk web scraping demi business intelligence, sales, dan pelatihan AI, wajar kalau semua orang ingin tahu di mana batas hukumnya.
Suatu hari, Anda melihat berita soal putusan pengadilan yang menyatakan scraping data publik sah-sah saja. Di lain hari, regulator memperingatkan tentang pengumpulan data dari media sosial yang “melanggar hukum”. Membingungkan, bahkan bagi orang seperti saya yang sehari-hari membangun alat AI web scraping di Thunderbit.
Jadi, apakah web scraping ilegal? Jawabannya tidak sesederhana ya atau tidak. Itu tergantung pada apa yang Anda scrape, dari mana Anda mengambilnya, bagaimana Anda menggunakan datanya, dan apa yang diatur hukum di negara Anda.
Dalam pembahasan mendalam ini, saya akan menguraikan lanskap hukumnya, membongkar beberapa mitos umum, dan membagikan tips praktis (plus beberapa pengalaman lapangan) agar tetap patuh—baik Anda founder tunggal maupun tim data di perusahaan Fortune 500.
Web Scraping dan Hukum: Apakah Ada Batas yang Jelas?
Kalau Anda berharap jawaban satu kalimat, saya akan menghemat waktu Anda: hukum belum menggambar garis yang terang dan jelas untuk web scraping.
Sebaliknya, yang ada adalah kumpulan aturan yang saling tumpang tindih—kepemilikan data, privasi, kekayaan intelektual, undang-undang anti-hacking, dan Terms of Service (ToS) yang terkenal itu. Masing-masing bisa berlaku, dan jawabannya sering bergantung pada situasi spesifik Anda (multilogin.com).
Mari kita pecah menjadi tiga kelompok hukum besar:
- Kepemilikan Data: Secara umum, fakta dan informasi publik (seperti harga atau nomor telepon) tidak bisa dilindungi hak cipta. Namun, konten kreatif (artikel, gambar) dan basis data milik pihak tertentu bisa dilindungi—terutama di Uni Eropa, di mana “database rights” memang ada (cliffordchance.com).
- Privasi: Undang-undang privasi modern (misalnya GDPR di Eropa, PIPL di China) memperlakukan data pribadi sebagai aset yang diatur—meskipun data itu diposting secara publik. Men-scrape nama, email, atau profil media sosial tanpa dasar hukum bisa membuat Anda berurusan dengan masalah serius (ico.org.uk).
- Kontrak (Terms of Service): Banyak situs secara eksplisit melarang scraping dalam ToS mereka. Walaupun ToS bukan undang-undang, pengadilan bisa menganggapnya sebagai kontrak yang mengikat. Melanggarnya bisa berujung gugatan, dan dalam beberapa kasus, bahkan memicu undang-undang anti-hacking jika Anda menerobos pembatasan teknis (cliffordchance.com).
Jadi, apakah web scraping ilegal? Kadang ya, kadang tidak, dan sering kali “tergantung.” Detailnya sangat menentukan.
Membandingkan Perspektif Hukum: AS, UE, Inggris, China
Berikut tabel singkat untuk melihat bagaimana kawasan besar memandang web scraping:
| Wilayah | Scraping Data Publik | Scraping Data Pribadi/Privat | Penegakan & Poin Penting |
|---|---|---|---|
| AS | Umumnya diperbolehkan untuk data publik (lihat hiQ v. LinkedIn). Melanggar ToS bisa berujung gugatan perdata. | Dibatasi/ilegal jika Anda menerobos login atau menyalahgunakan data pribadi. Hukum negara bagian (seperti CCPA) bisa berlaku. | Surat cease-and-desist, pemblokiran IP, gugatan. CFAA berlaku jika Anda melewati penghalang teknis. |
| UE | Diizinkan secara bersyarat untuk data publik non-personal. Hak database bisa berlaku. EU AI Act (2026) menambah syarat transparansi untuk data pelatihan AI. | Sangat diatur di bawah GDPR—bahkan data pribadi publik pun butuh dasar hukum. | Otoritas Perlindungan Data dapat menjatuhkan denda untuk pelanggaran privasi. Hak cipta/database juga ditegakkan. EU AI Act melarang scraping gambar wajah untuk AI. |
| Inggris | Mirip UE. Data publik non-personal bisa di-scrape, tetapi hak data dan kontrak tetap harus dihormati. | Ketat untuk data pribadi—UK GDPR berlaku. Computer Misuse Act mengkriminalkan akses tanpa izin. | ICO bisa memberi sanksi atas pelanggaran perlindungan data. Pengadilan dapat menegakkan ToS. |
| China | Dikendalikan ketat. Data publik non-personal boleh di-scrape untuk penggunaan internal, tetapi lingkungannya tetap hati-hati. | Sangat dibatasi—PIPL mewajibkan persetujuan untuk data pribadi. Hukum anti persaingan tidak sehat juga berlaku. | Kasus pidana untuk scraping skala besar. Pengadilan memakai hukum persaingan tidak sehat untuk menghentikan scraping tanpa izin. |
Apakah Web Scraping Ilegal? Faktor Hukum Utama yang Perlu Dipertimbangkan
Jadi, apa yang sebenarnya menentukan apakah proyek scraping Anda legal atau berisiko? Ini faktor-faktor besarnya:
- Data Publik vs. Privat: Men-scrape data yang bisa dilihat siapa pun di web terbuka umumnya lebih aman. Men-scrape sesuatu yang berada di balik login, paywall, atau penghalang teknis? Itu kemungkinan ilegal (thunderbit.com).
- Jenis Datanya: Data pribadi (nama, email, profil) memicu hukum privasi. Konten berhak cipta (artikel, gambar) tidak bisa disalin bulat-bulat. Fakta murni (harga, cuaca) biasanya boleh diambil (oxylabs.io).
- Tujuan Penggunaan: Analisis internal atau riset biasanya dipandang lebih longgar daripada memublikasikan ulang atau menjual data hasil scrape. Menggunakan data scrape untuk langsung bersaing dengan sumbernya? Itu nyaris pasti mengundang gugatan (thunderbit.com).
- Kepatuhan terhadap Aturan Situs: Selalu periksa robots.txt dan ToS. Robots.txt memang tidak mengikat secara hukum, tetapi sebaiknya dihormati. Pelanggaran ToS bisa berarti gugatan perdata atau lebih buruk (promptcloud.com).
- Langkah Teknis: Scraping dengan kecepatan seperti manusia dan tidak menerobos langkah keamanan adalah kunci. Membombardir server atau menghindari CAPTCHA bisa masuk wilayah hacking (cliffordchance.com).
Apa yang Berubah di 2024–2026: Kasus Pengadilan dan Regulasi Penting
Lanskap hukum web scraping berubah drastis sejak 2023. Berikut perkembangan yang perlu diketahui setiap scraper:
Putusan Pengadilan Besar
-
Meta v. Bright Data (2024): Pengadilan federal AS memutuskan bahwa Terms of Service Meta tidak melarang scraping data publik oleh pengguna yang tidak login. Hakim menyatakan bahwa “pengunjung tidak dianggap sebagai ‘user’ kecuali mereka memiliki akun.” Tak lama kemudian, Meta mencabut sisa tuntutannya. Ini kemenangan bersejarah untuk scraping data publik.
-
X Corp v. Bright Data (2024): Twitter (sekarang X) kalah dalam gugatan serupa, memperkuat prinsip yang sama: scraping data yang dapat diakses publik tanpa login bukan pelanggaran ToS, karena scraper tidak pernah menyetujui syarat itu.
-
Reddit v. Perplexity AI (Oktober 2025): Reddit menggugat Perplexity AI dan beberapa penyedia scraping, dengan mengacu pada DMCA dan menuduh adanya upaya menerobos sistem anti-bot. Ini menandakan strategi hukum baru: platform mulai beralih ke klaim hak cipta dan anti-circumvention alih-alih CFAA.
-
NYT v. OpenAI (Maret 2025): Seorang hakim federal mengizinkan kasus hak cipta New York Times melawan OpenAI untuk berlanjut, menolak permintaan OpenAI untuk menutup perkara. Ini bisa menjadi preseden besar soal apakah scraping konten untuk melatih model AI termasuk “fair use.”
-
Penyelesaian Anthropic (September 2025): Anthropic setuju membayar $1,5 miliar untuk menyelesaikan class action hak cipta di AS terkait penggunaan teks berhak cipta untuk melatih model AI-nya—sebuah sinyal bahwa biaya scraping untuk AI memang sangat nyata.
Tren Besar: Dari CFAA ke Hukum Kontrak dan Hak Cipta
Polanya jelas: CFAA (Computer Fraud and Abuse Act) makin kehilangan daya sebagai senjata melawan scraper data publik. Perusahaan yang mencoba memakai CFAA terhadap scraping data publik—Meta, X, LinkedIn—sebagian besar gagal. Sebaliknya, medan hukumnya bergeser ke:
- Hukum kontrak (pelanggaran ToS—tetapi pengadilan mengatakan non-user tidak terikat ToS)
- Klaim hak cipta (terutama untuk data pelatihan AI)
- Undang-undang anti-circumvention (DMCA Bagian 1201)
Bagi scraper, ini berarti risikonya belum hilang—hanya berpindah tempat.
Perubahan Regulasi
- Pembaruan CCPA 2026: Regulasi CCPA California yang direvisi berlaku mulai 1 Januari 2026, menambah aturan baru untuk teknologi pengambilan keputusan otomatis (ADMT), penilaian risiko, dan kewajiban data broker.
- Undang-Undang Privasi Negara Bagian Baru di AS: Indiana, Kentucky, dan Rhode Island memberlakukan undang-undang privasi komprehensif yang efektif pada 2026.
- EU AI Act: Penegakan penuh dimulai 2 Agustus 2026—mengharuskan pengembang AI mengungkap sumber data pelatihan, menghormati penolakan penggunaan untuk copyright yang bisa dibaca mesin, dan melarang scraping gambar wajah untuk sistem AI.
- AI Accountability for Publishers Act (Februari 2026): Rancangan undang-undang AS yang akan mewajibkan perusahaan AI meminta izin dan membayar penerbit sebelum men-scrape konten mereka.
Kebijakan Scraping dari Platform Besar: Yang Perlu Anda Tahu
Tidak semua situs memperlakukan scraping dengan cara yang sama. Berikut rincian per platform tentang apa yang diizinkan, apa yang diblokir, dan apa kata pengadilan:
| Platform | ToS tentang Scraping | Pertahanan Teknis | Penegakan Hukum | Apa yang Praktis Aman |
|---|---|---|---|---|
| Google (Search & Maps) | Melarang akses otomatis dalam ToS. Maps Platform memiliki klausul eksplisit “No Scraping”. | Tantangan SearchGuard JS, CAPTCHA, pembatasan laju. robots.txt diperbarui pada 2025 untuk memblokir crawler AI. | Menuntut scraper pada Des 2025 menggunakan DMCA. Aktif memblokir crawler AI (Anthropic, Meta, OpenAI). | Men-scrape data bisnis Google Maps yang publik masih bisa dipertahankan secara hukum (preseden hiQ), tetapi bersiaplah menghadapi blok teknis. Gunakan API resmi bila memungkinkan. |
| Amazon | Secara eksplisit melarang semua scraping dalam Conditions of Use (“no robot, spider, scraper, or other automated means”). | Deteksi bot agresif, CAPTCHA, pemblokiran IP. robots.txt memblokir semua bot kecuali Googlebot/Bingbot. Sejak 2025 secara eksplisit memblokir crawler AI. | Menuntut Perplexity AI pada Nov 2025. Rutin mengirim surat cease-and-desist. BSA diperbarui pada Maret 2026 dengan aturan agen AI. | Data produk publik (harga, listing) bersifat faktual dan bisa di-scrape menurut hukum AS, tetapi Amazon melawan dengan keras. Batasi request dan hindari data pribadi. |
| Melarang scraping dalam ToS; mewajibkan persetujuan pengguna untuk mengakses layanan. | Dinding login untuk sebagian besar data profil, deteksi anti-bot, pembatasan laju. | Kasus hiQ menegaskan scraping profil publik bukan pelanggaran CFAA, tetapi LinkedIn menang pada klaim kontrak/persaingan tidak sehat saat akun palsu digunakan. | Profil publik (yang terlihat tanpa login) secara hukum masih bisa dipertahankan untuk di-scrape. Jangan pernah membuat akun palsu atau men-scrape data yang berada di balik login. | |
| Meta (Facebook & Instagram) | ToS melarang scraping; ada aturan terpisah untuk data saat login dan saat tidak login. | Dinding login untuk sebagian besar konten, deteksi bot canggih. | Kalah dari Bright Data pada 2024—pengadilan memutuskan ToS tidak berlaku untuk scraper yang tidak login. Menarik sisa tuntutan. | Data publik (halaman bisnis, posting publik) yang terlihat tanpa login berada di posisi lebih aman. Jangan pernah men-scrape profil privat atau data di balik login. |
| X (Twitter) | ToS diperbarui pada 2023 untuk melarang semua scraping dan crawling tanpa persetujuan tertulis. Klausul pengecualian robots.txt yang lama dihapus. | robots.txt memblokir semua crawler (Disallow: /). Tantangan Cloudflare Turnstile. Batas laju ketat (300 request/jam). Skor reputasi IP. | Kalah dari Bright Data untuk data publik, tetapi tetap sangat membatasi akses teknis. | Tweet dan profil publik masih bisa dipertahankan secara hukum untuk di-scrape, tetapi penghalang teknis X termasuk yang terberat pada 2026. Siapkan diri untuk blok tanpa infrastruktur proxy premium. |
Intinya: Pengadilan secara konsisten memutuskan bahwa scraping data yang terlihat publik tanpa login tidak melanggar CFAA. Namun platform masih bisa mengejar Anda lewat hukum kontrak, hak cipta, atau dasar anti-circumvention—dan mereka akan menyulitkan Anda dengan penghalang teknis. Selalu lakukan scraping secara bertanggung jawab.
Data Pelatihan AI dan Web Scraping: Medan Hukum Baru
Kalau Anda mengikuti berita pada 2026, Anda tahu bahwa scraping data untuk melatih model AI telah menjadi medan perang hukum paling panas. Inilah yang sedang terjadi:
- Gugatan hak cipta bermunculan. New York Times, para penulis, dan penerbit telah menggugat OpenAI, Anthropic, dan lainnya, dengan tuduhan bahwa scraping massal konten berhak cipta untuk melatih LLM bukanlah “fair use.” Anthropic menyelesaikan class action besar senilai $1,5 miliar pada 2025—menandakan bahwa biaya scraping untuk AI benar-benar nyata.
- Pembelaan “fair use” masih rapuh. Pengadilan AS belum mengeluarkan putusan definitif apakah melatih AI dengan data hasil scrape termasuk fair use. Putusan awal menunjukkan bahwa hal ini sangat bergantung pada bagaimana data diperoleh dan apa yang dilakukan terhadap output AI.
- Peraturan baru sedang disiapkan. AI Accountability for Publishers Act (diajukan Februari 2026) bertujuan mewajibkan perusahaan AI meminta izin dan membayar penerbit sebelum men-scrape konten mereka.
- EU AI Act (penegakan penuh Agustus 2026) mewajibkan pengembang AI mengungkap sumber data pelatihan, menghormati penolakan penggunaan hak cipta yang bisa dibaca mesin (di bawah pengecualian TDM dalam Copyright Directive), dan memberi label pada konten yang dihasilkan AI. Aturan ini juga melarang sistem AI yang men-scrape gambar wajah dari internet.
- Crawler AI/LLM meledak. Porsi lalu lintas web dari crawler AI melonjak empat kali lipat dari 2,6% menjadi 10,1% hanya dalam delapan bulan. GPTBot milik OpenAI sendiri tumbuh 305%. Sebagai respons, situs-situs besar (Amazon, Reddit, NYT) memperbarui robots.txt untuk secara eksplisit memblokir crawler AI.
Artinya bagi Anda: Jika Anda men-scrape data untuk kebutuhan bisnis tradisional (lead gen, pemantauan harga, riset pasar), aturan khusus AI ini mungkin tidak langsung berlaku. Tetapi jika data hasil scrape masuk ke model AI, berhati-hatilah—dan dapatkan nasihat hukum.
Hukum Web Scraping di Seluruh Dunia: Perbandingan Singkat
Mari kita lihat gambaran globalnya:
- Amerika Serikat: Tidak ada larangan total. Men-scrape situs yang terlihat publik umumnya sah (hiQ v. LinkedIn), dan putusan Meta serta X Corp pada 2024 semakin memperkuat argumen untuk scraping data publik. Namun scraping di balik login atau penghalang teknis masih bisa memicu CFAA. Tren sekarang mengarah ke penggunaan hukum kontrak dan klaim hak cipta. Hukum privasi juga berkembang cepat: CCPA mendapat pembaruan besar yang berlaku 1 Januari 2026, termasuk aturan baru untuk pengambilan keputusan otomatis dan kewajiban data broker. Indiana, Kentucky, dan Rhode Island juga memberlakukan undang-undang privasi komprehensif pada 2026.
- Uni Eropa: Hukum privasi sangat ketat. GDPR berlaku bahkan untuk data pribadi publik. Hak database bisa menghalangi scraping skala besar terhadap data terstruktur (cliffordchance.com). BARU: EU AI Act berlaku penuh pada 2 Agustus 2026, mewajibkan pengembang AI mengungkap sumber data pelatihan dan menghormati penolakan hak cipta. Undang-undang ini melarang scraping gambar wajah dari internet untuk sistem AI.
- Inggris: Menyerupai aturan UE setelah Brexit. Data publik boleh di-scrape, tetapi scraping informasi pribadi sangat diatur. Computer Misuse Act dapat mengkriminalkan akses tanpa izin.
- China: Sangat ketat. PIPL dan Data Security Law mewajibkan persetujuan untuk data pribadi. Pengadilan memakai hukum persaingan tidak sehat untuk memblokir scraping yang merugikan bisnis (malwarebytes.com).
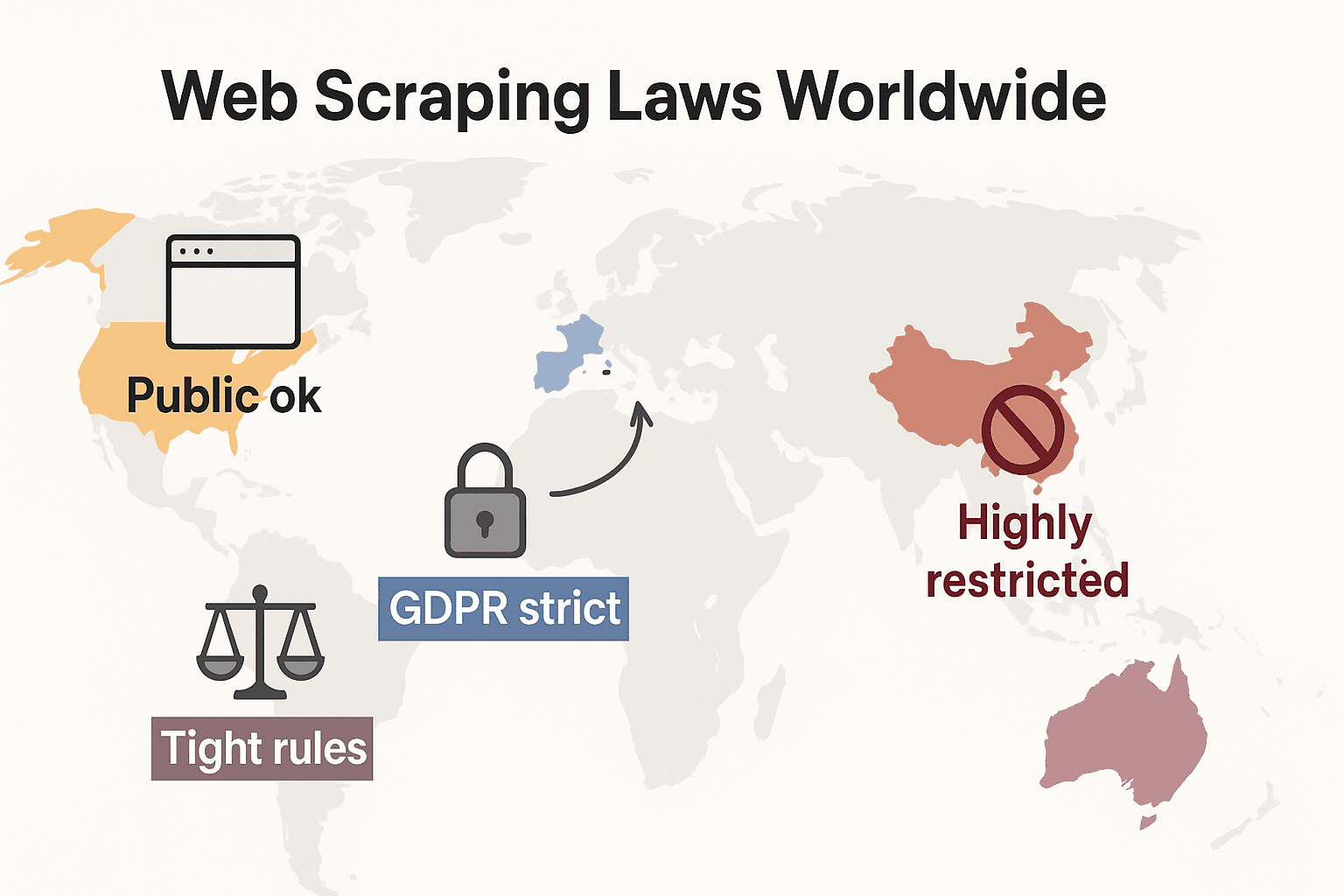
Intinya: men-scrape data publik non-pribadi untuk penggunaan internal umumnya paling aman. Selain itu? Periksa hukum setempat dan melangkahlah dengan hati-hati.
Mitos Umum tentang Legalitas Web Scraping
Mari kita bongkar beberapa mitos yang sering saya dengar:
- Mitos 1: “Web scraping ilegal, titik.”
Salah. Tidak ada hukum yang melarang semua web scraping. Yang penting adalah bagaimana dan apa yang Anda scrape (oxylabs.io). - Mitos 2: “Kalau datanya publik, saya bebas melakukan apa saja dengannya.”
Tidak juga. Data publik tetap bisa dilindungi oleh hukum privasi atau hak cipta, dan ToS dapat membatasi penggunaan tertentu (ico.org.uk). - Mitos 3: “Web scraping sama dengan hacking.”
Tidak. Men-scrape halaman web publik bukan hacking. Menerobos login atau penghalang teknis adalah cerita yang berbeda (calawyers.org). - Mitos 4: “Kalau saya tidak ketahuan, aman.”
Pemikiran yang berisiko. Banyak situs memakai teknologi anti-bot dan akan menyadarinya. Diam bukan berarti izin. - Mitos 5: “Kalau saya memberi kredit atau hanya memakai data secara internal, itu pasti boleh.”
Pencantuman sumber tidak mengalahkan hukum hak cipta atau privasi. Penggunaan internal memang lebih aman, tetapi bukan kartu bebas masalah. - Mitos 6: “Semua web scraping melanggar privasi.”
Tidak semua scraping melibatkan data pribadi. Tetapi men-scrape data pribadi dalam volume besar tanpa pengamanan hampir selalu ilegal (oxylabs.io). - Mitos 7: “Kalau ToS situs melarang scraping, berarti pasti ilegal untuk di-scrape.”
Tidak selalu. Pada 2024, pengadilan dalam Meta v. Bright Data dan X Corp v. Bright Data memutuskan bahwa ToS tidak bisa mengikat pengguna yang tidak pernah menyetujuinya—artinya, jika Anda scraping tanpa login atau membuat akun, ToS situs itu mungkin tidak berlaku untuk Anda. Ini masih area yang berkembang, tetapi perubahannya signifikan.
Cara Men-scrape Data Secara Legal: Praktik Terbaik untuk Kepatuhan
Ini checklist andalan saya untuk web scraping yang legal dan etis:
- Baca dan hormati Terms of Service situs. Kalau mereka bilang “no scraping,” pertimbangkan untuk berhenti atau minta izin (ql2.com).
- Batasi pada data publik. Kalau butuh kata sandi, berarti datanya dibatasi—jangan scrape (thunderbit.com).
- Periksa robots.txt dan lakukan crawling dengan sopan. Memang tidak mengikat secara hukum, tetapi itu etika yang baik. Jangan membebani server—beri jeda antar request (promptcloud.com).
- Hindari data pribadi kecuali Anda punya dasar hukum. Jika harus mengumpulkannya, patuhi GDPR/CCPA dan minimalkan data yang diambil.
- Jangan memublikasikan ulang konten hasil scrape secara utuh. Tambahkan nilai atau analisis, atau minta izin (thunderbit.com).
- Jangan memasukkan konten hasil scrape ke model AI tanpa memeriksa hak cipta. Lanskap hukumnya berubah cepat—minta nasihat jika itu kasus penggunaan Anda.
- Gunakan API resmi atau ekspor data jika tersedia. Itu memang dirancang untuk tujuan ini dan biasanya lebih aman (thunderbit.com).
- Bersikap transparan dan akuntabel. Jika Anda mengumpulkan data pribadi, beri tahu orang-orang dan simpan log aktivitas Anda.
- Minimalkan dan amankan data Anda. Ambil hanya yang diperlukan, jaga keakuratannya, dan simpan dengan aman.
- Tetap update dan cari nasihat hukum untuk kasus abu-abu. Hukum dan putusan pengadilan berubah cepat—terutama EU AI Act dan hukum privasi negara bagian AS. Kalau ragu, tanyakan ke ahlinya.
Coba Ekstensi Chrome Thunderbit untuk Scraping yang Patuh
Menggunakan Alat Web Scraping Secara Legal: Yang Perlu Diketahui Bisnis
Alat web scraping seperti Thunderbit membuat pengumpulan data lebih mudah bagi non-programmer, tetapi Anda tetap harus menggunakannya secara bertanggung jawab:
- Pilih alat yang berfokus pada kepatuhan. Thunderbit, misalnya, hanya men-scrape apa yang bisa Anda lihat di browser—tanpa trik API diam-diam atau akses tanpa izin (thunderbit.com).
- Gunakan hanya untuk kasus yang sah. Analitik internal, riset pasar, dan pemantauan harga kompetitor umumnya aman. Memublikasikan ulang atau menjual data hasil scrape? Jauh lebih berisiko.
- Konfigurasikan alat agar patuh. Atur crawl delay, patuhi robots.txt, dan gunakan template yang hanya mengambil data yang Anda butuhkan.
- Simpan untuk penggunaan internal. Menggunakan data hasil scrape secara internal lebih aman daripada mempublikasikannya ulang.
- Edukasi tim Anda. Pastikan semua orang memahami aturan dan praktik terbaik.
- Manfaatkan fitur kepatuhan bawaan. Thunderbit memperingatkan pengguna tentang situs berisiko, men-scrape dengan kecepatan seperti manusia, dan tidak menyimpan data Anda di server mereka.
- Jangan memaksa. Kalau sebuah alat tidak bisa men-scrape situs tertentu, jangan coba mengakalinya. Tidak semua data bisa diambil tanpa risiko.
Pendekatan Thunderbit: Mendukung AI Web Scraping yang Patuh
Di Thunderbit, kami sudah banyak memikirkan soal kepatuhan. Begini cara AI Web Scraper kami membantu pengguna tetap berada di jalur hukum:
- Hanya men-scrape apa yang bisa Anda lihat. Thunderbit bekerja di sesi browser Anda, jadi ia tidak bisa mengakses data yang tidak bisa Anda salin secara manual.
- Mengarahkan pengguna dengan peringatan. Jika Anda mencoba men-scrape situs dengan kebijakan anti-scraping yang ketat, Thunderbit akan memberi peringatan.
- Kecepatan scraping seperti manusia. Baik scraping secara lokal maupun di cloud, Thunderbit menghindari membanjiri server.
- Pemilihan data yang bisa disesuaikan. AI kami menyarankan kolom yang relevan, membantu Anda mengambil hanya yang diperlukan.
- Penanganan subhalaman dan pagination. Thunderbit menjelajahi situs seperti pengguna sungguhan, sambil menghormati strukturnya.
- Privasi dan keamanan. Data Anda tetap milik Anda—Thunderbit tidak menyimpan atau menggunakannya ulang.
- Ekspor yang ramah kepatuhan. Ekspor langsung ke Google Sheets, Airtable, Notion, atau CSV untuk penggunaan internal yang aman.
- Penjadwalan dan otomatisasi. Atur scraping berulang pada interval yang wajar.
- Dukungan multi-bahasa. UI Thunderbit mendukung 34 bahasa, sehingga kepatuhan lebih mudah diakses secara global.
- Pembaruan template rutin. Template instan kami untuk situs populer selalu diperbarui mengikuti perubahan hukum dan teknis.
Dengan menanamkan kepatuhan ke dalam produk, Thunderbit membantu tim mengumpulkan data yang mereka butuhkan—tanpa pusing urusan hukum.
Selangkah Lebih Maju: Beradaptasi dengan Perubahan Hukum dan Teknis dalam Web Scraping
Jelajahi Lebih Banyak Panduan Web Scraping Get Started Free
Web scraping bukan permainan sekali jadi lalu ditinggal. Hukum dan struktur situs terus berubah. Berikut cara tetap selangkah lebih maju:
- Pantau perkembangan hukum. Laju perubahan makin cepat pada 2024–2026—ikuti berita hukum teknologi, pembaruan regulator, dan blog industri (seperti Thunderbit). Perhatikan penegakan EU AI Act (Agustus 2026), hukum privasi negara bagian baru di AS, dan kasus hak cipta AI yang masih berjalan.
- Beradaptasi dengan perubahan teknis. Situs terus memperbarui tata letak dan pertahanan anti-bot mereka. Platform besar (Amazon, X, Google) memperketat pertahanannya secara signifikan pada 2025–2026. AI dan template Thunderbit dirancang untuk menyesuaikan diri secara otomatis.
- Manfaatkan API resmi bila tersedia. Jika sebuah situs beralih ke model API berbayar, pertimbangkan untuk pindah demi keandalan dan kepatuhan.
- Audit scraping Anda secara rutin. Dokumentasikan sumber, cek perubahan ToS atau kebijakan, dan sesuaikan strategi bila perlu.
- Manfaatkan pembaruan template Thunderbit. Tim kami menjaga template tetap mutakhir, jadi Anda tidak perlu khawatir soal perubahan yang merusak atau persyaratan kepatuhan baru.
- Tetap fleksibel. Jika suatu sumber data menjadi terlalu berisiko, pindah ke sumber lain atau cari kemitraan.
Dengan alat dan pola pikir yang tepat, Anda bisa menjaga aliran data tetap lancar—tanpa menginjak ranjau hukum.
Kesimpulan: Menavigasi Lanskap Hukum Web Scraping
Web scraping pada dasarnya tidak ilegal—ini alat yang sangat berguna untuk bisnis, riset, dan inovasi. Tetapi seperti alat apa pun, ada aturannya. Kuncinya adalah memahami apa yang Anda scrape, bagaimana Anda melakukannya, dan apa yang akan Anda lakukan dengan datanya. Hormati hukum setempat, patuhi kebijakan situs, dan gunakan alat yang berfokus pada kepatuhan seperti Thunderbit agar operasional Anda tetap aman.
Putusan pengadilan 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) memperkuat posisi scraping data publik, tetapi risiko baru bermunculan di sekitar data pelatihan AI, klaim hak cipta, dan EU AI Act. Kebijakan tiap platform juga sangat berbeda—Google, Amazon, LinkedIn, Meta, dan X semuanya menegakkan aturan dengan cara yang berbeda—jadi pahami lanskapnya sebelum Anda scraping.
Kalau Anda ragu, cari nasihat hukum—terutama untuk proyek besar atau sensitif. Dan ingat: lanskap hukumnya selalu berubah, jadi tetap update dan lincah.
Ingin belajar lebih lanjut tentang web scraping, kepatuhan, dan otomatisasi? Kunjungi Thunderbit Blog untuk panduan lainnya, atau coba sendiri Thunderbit's Chrome Extension.
Mulai Web Scraping yang Patuh dengan Thunderbit
FAQ
1. Apakah web scraping ilegal di semua tempat?
Tidak. Web scraping pada dasarnya tidak ilegal, tetapi keabsahannya bergantung pada apa yang Anda scrape, bagaimana Anda melakukannya, dan di mana Anda berada. Men-scrape data publik non-pribadi untuk penggunaan internal umumnya diperbolehkan di sebagian besar wilayah, tetapi men-scrape data pribadi atau berhak cipta, atau melanggar syarat situs, bisa ilegal (oxylabs.io).
2. Apakah robots.txt membuat scraping ilegal jika saya mengabaikannya?
Robots.txt tidak mengikat secara hukum, tetapi sebaiknya dihormati. Mengabaikan robots.txt tidak otomatis membuat Anda dituntut, tetapi bisa membuat Anda terlihat seperti “pelaku buruk” jika terjadi sengketa (promptcloud.com).
3. Bisakah saya men-scrape Google, Amazon, atau LinkedIn?
Ini rumit. Ketiganya melarang scraping dalam ToS, tetapi pengadilan memutuskan bahwa ToS mungkin tidak mengikat pengguna yang tidak login (lihat Meta v. Bright Data dan X Corp v. Bright Data, keduanya 2024). Men-scrape data yang terlihat publik (harga produk, listing bisnis, profil publik) umumnya masih bisa dipertahankan secara hukum di AS. Namun, tiap platform menegakkan aturannya berbeda: Amazon paling agresif secara hukum (mereka menggugat Perplexity AI pada November 2025); LinkedIn mengandalkan penghalang teknis dan klaim kontrak; Google semakin sering memakai penegakan berbasis DMCA. Selalu lakukan scraping secara bertanggung jawab dan bersiaplah menghadapi tindakan balasan teknis.
4. Bisakah saya men-scrape Facebook atau Instagram?
Setelah Meta v. Bright Data (2024), men-scrape data publik dari Facebook dan Instagram tanpa login memiliki dasar hukum yang lebih kuat. Pengadilan memutuskan ToS Meta tidak berlaku untuk non-user. Tetapi jangan pernah membuat akun palsu atau men-scrape data di balik login—itu sudah melewati batas.
5. Bisakah saya men-scrape X (Twitter)?
X memperbarui ToS pada 2023 untuk melarang semua scraping tanpa persetujuan tertulis dan telah menerapkan pertahanan teknis yang agresif (Cloudflare Turnstile, batas 300 request/jam, penilaian reputasi IP). Namun, Bright Data menang di pengadilan dengan dasar serupa—data publik yang di-scrape tanpa akun tidak terikat ToS X. Secara teknis, X adalah salah satu platform tersulit untuk di-scrape pada 2026.
6. Apakah men-scrape data untuk melatih model AI itu legal?
Ini adalah pertanyaan terbuka terbesar pada 2026. Gugatan besar (NYT v. OpenAI, penyelesaian Anthropic senilai $1,5 miliar) menunjukkan risiko hukum yang signifikan. EU AI Act mewajibkan pengungkapan sumber data pelatihan dan penghormatan terhadap penolakan hak cipta. AI Accountability for Publishers Act yang diusulkan akan mewajibkan izin dan pembayaran. Jika Anda men-scrape untuk melatih AI, mintalah nasihat hukum sebelum melangkah.
7. Apa cara paling aman menggunakan alat web scraping seperti Thunderbit?
Batasi pada scraping data publik, hormati syarat situs, hindari informasi pribadi kecuali Anda punya dasar hukum, dan gunakan datanya secara internal. Thunderbit dirancang untuk membantu Anda tetap patuh dengan hanya men-scrape apa yang terlihat di browser Anda dan memberi peringatan tentang situs berisiko (thunderbit.com).
8. Bisakah saya men-scrape data untuk keperluan komersial?
Tergantung. Menggunakan data hasil scrape untuk analitik internal atau riset umumnya lebih aman. Memublikasikan ulang atau menjual data hasil scrape, terutama jika berhak cipta atau bersifat pribadi, jauh lebih berisiko dan mungkin memerlukan izin atau lisensi.
9. Bagaimana cara saya mengikuti perubahan hukum dan teknis dalam web scraping?
Ikuti berita hukum teknologi, pantau situs target Anda untuk perubahan ToS atau kebijakan, dan gunakan alat seperti Thunderbit yang memperbarui template dan fitur kepatuhannya secara rutin. Hal penting yang perlu diawasi pada 2026: penegakan EU AI Act (Agustus), kasus hak cipta AI yang sedang berlangsung, dan undang-undang privasi negara bagian baru di AS. Kalau ragu, konsultasikan dengan profesional hukum.
Coba AI Web Scraper Get Started Free




