
Scraping Facebook masih layak dilakukan di 2026, tetapi hanya jika Anda memilih model pengumpulan yang tepat. Pew Research Center melaporkan pada 20 November 2025 bahwa 71% orang dewasa di AS menggunakan Facebook, dan Meta mengatakan pada 29 April 2026 bahwa Family of Apps-nya menjangkau 3,56 miliar pengguna aktif harian pada Maret 2026. Skala sebesar itu membuat Facebook tetap berguna untuk pemantauan Marketplace, riset halaman publik, lead generation, dan pelacakan kompetitor. Bagian yang sulit bukan menemukan use case. Bagian yang sulit adalah mendapatkan data yang bersih tanpa terjebak di login wall, muatan dinamis, blok sementara, atau setup scraping yang rapuh.
Daftar singkat tahunan ini dibuat untuk mempercepat pengambilan keputusan. Saya memeriksa ulang halaman produk resmi, dokumentasi, dan sinyal harga pada 8 Mei 2026, lalu memfokuskan daftar ini pada tools yang masih masuk akal untuk pengguna bisnis nyata. Jika alur kerja Anda sebagian besar adalah “ambil data di halaman ini lalu kirim ke spreadsheet,” mulailah dengan Thunderbit. Jika Anda membutuhkan infrastruktur skala API, Bright Data, Apify, dan Nimble by Nimbleway layak ada di bagian atas daftar. Jika pekerjaan Anda mencakup automasi cloud atau tindakan lanjutan setelah pengumpulan, PhantomBuster patut ditinjau lebih dekat.
Pilihan Cepat לפי Pekerjaan
- Butuh ekspor Facebook atau Marketplace tanpa kode yang paling cepat? Mulai dengan Thunderbit.
- Butuh skala API enterprise dan managed unblocking? Masukkan Bright Data ke daftar pendek.
- Butuh alur scraping cloud yang fleksibel? Lihat baik-baik Apify.
- Butuh pengumpulan web publik API-first dengan beban perawatan scraper yang lebih ringan? Pertimbangkan Nimble by Nimbleway.
- Butuh API hemat biaya untuk pekerjaan yang lebih ringan? ScrapingBot masih relevan.
- Butuh scraping plus automasi workflow? PhantomBuster lebih cocok.
- Butuh pembuat workflow point-and-click dengan penjadwalan? Octoparse tetap menjadi opsi no-code yang solid.
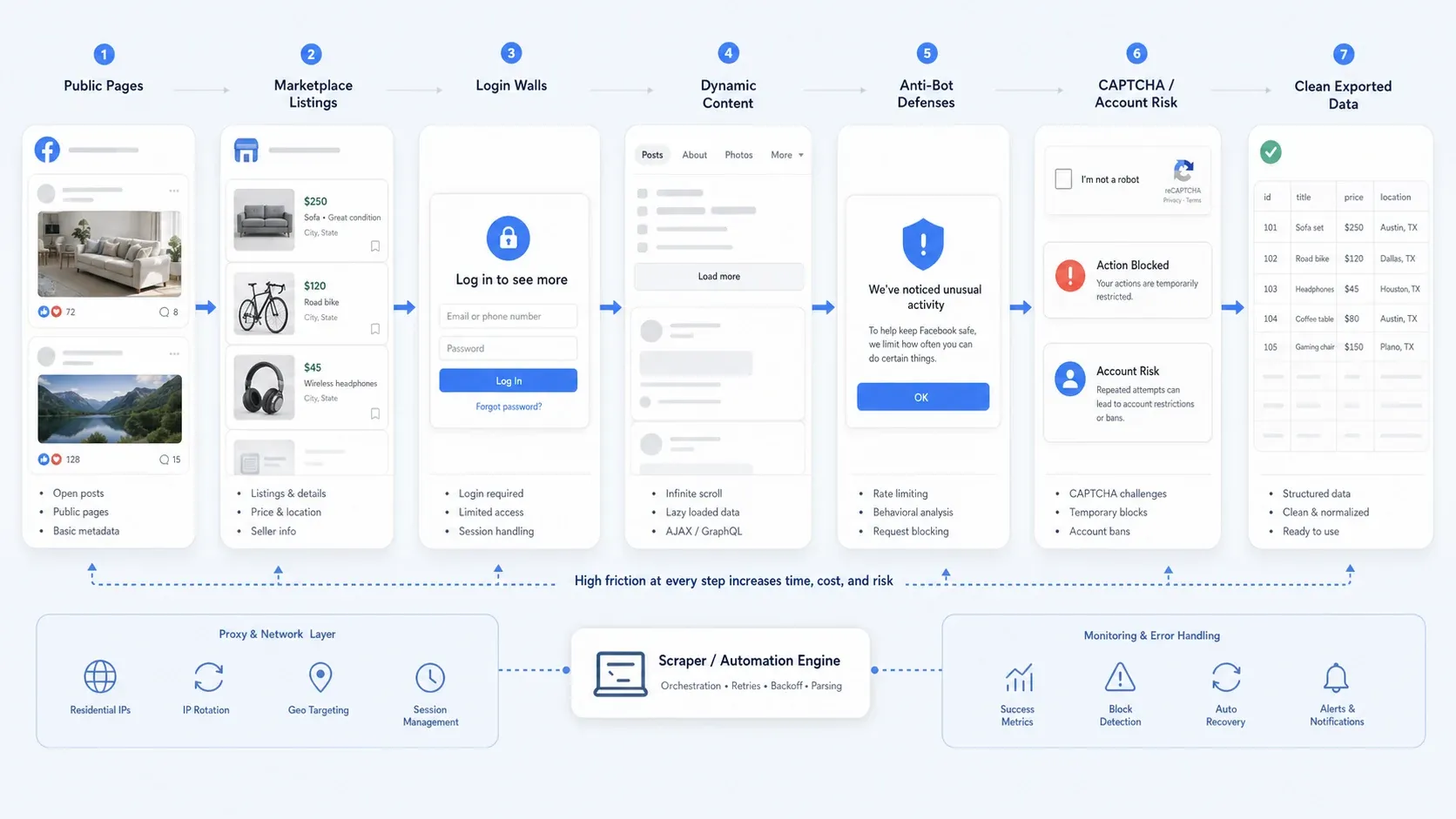
Mengapa Scraping Facebook Masih Sulit di 2026
Pengumpulan data Facebook sekarang jarang hanya soal selector. Dalam praktiknya, sebagian besar tim menghadapi satu atau lebih masalah berikut:
- Akses publik yang parsial: Beberapa halaman tetap publik, sementara alur lain mendorong Anda login untuk melihat detail tambahan.
- Konten dinamis: Tampilan Marketplace, utas komentar panjang, dan konten halaman sering dimuat bertahap.
- Pertahanan anti-bot: Pembatasan laju, pemeriksaan perilaku, CAPTCHA, dan blok tindakan sementara merusak automasi yang naif.
- Risiko operasional: Pengumpulan yang mengharuskan login jauh lebih berisiko daripada scraping halaman publik, terutama jika Anda peduli pada keamanan akun dan konsistensi.
Cara Saya Mengevaluasi Tools Ini
Saya mengoptimalkan halaman ini untuk membantu menyusun shortlist, bukan sekadar menambah daftar fitur. Tools di sini dibandingkan berdasarkan:
- Kesesuaian alur kerja: Apakah produk benar-benar cocok untuk pekerjaan pengumpulan data Facebook dan Marketplace yang dijalankan tim nyata?
- Kemudahan penggunaan: Apakah non-developer atau tim ramping bisa menghasilkan output yang berguna dengan cepat?
- Skala dan keandalan: Apakah tool ini tetap masuk akal saat Anda bergerak melampaui scrape sekali pakai?
- Penanganan anti-bot dan sesi: Seberapa banyak beban infrastruktur yang dihapus oleh produk?
- Kualitas output: Bisakah Anda memasukkan data terstruktur ke CSV, Sheets, atau sistem lanjutan tanpa banyak pembersihan?
- Sinyal harga: Apakah produk ini praktis untuk dievaluasi, atau membutuhkan proses enterprise yang berat?
- Sikap kepatuhan: Apakah tool ini jelas berorientasi pada pengumpulan data publik dan penggunaan yang bertanggung jawab?
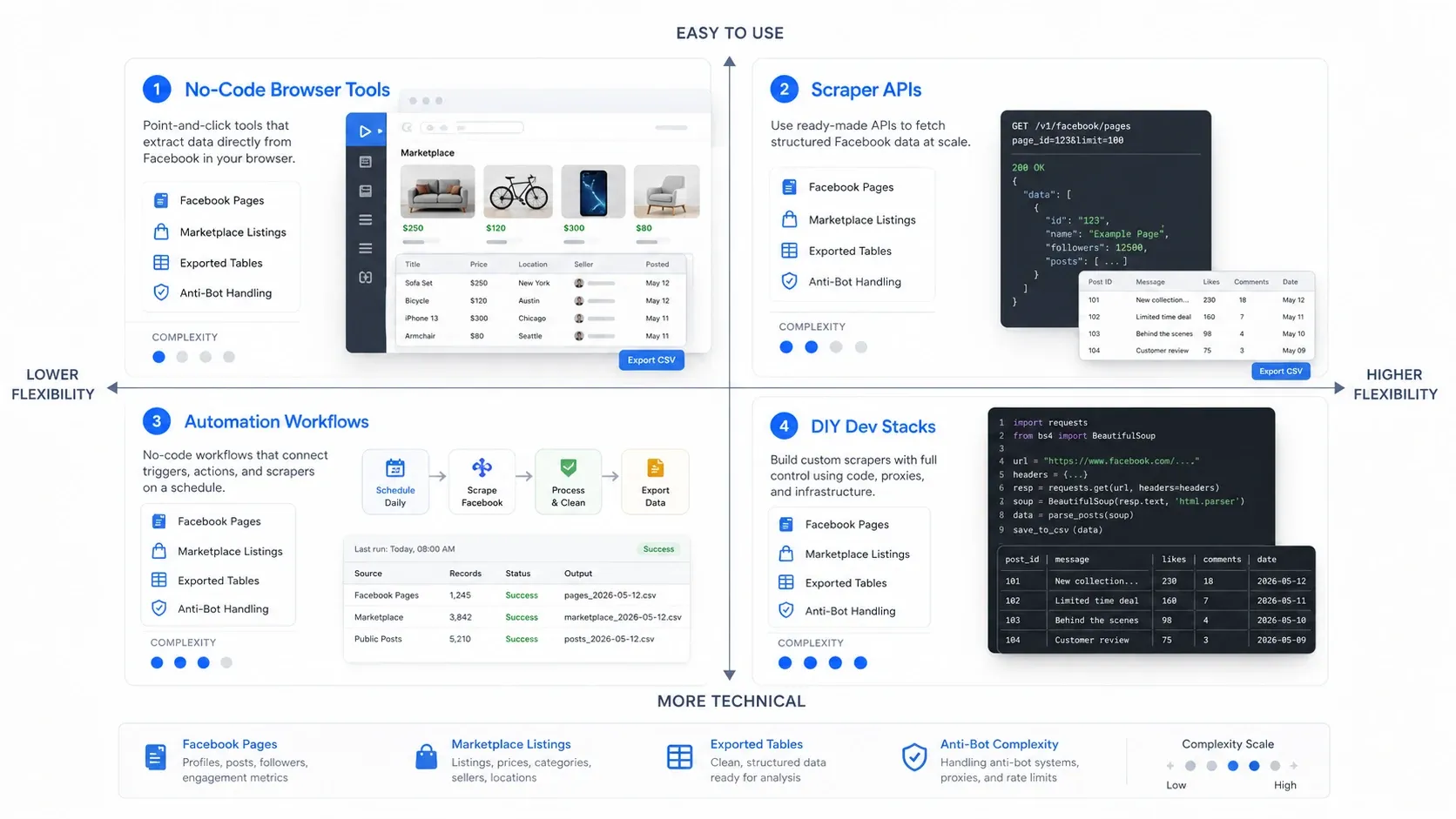
Jenis Facebook Scraper Apa yang Anda Butuhkan?
Cara tercepat memilih dengan tepat adalah memilih kategori yang benar lebih dulu. Tool scraping Facebook biasanya terbagi ke dalam empat model operasional:
- Tool browser no-code: Terbaik saat Anda ingin mengekstrak cepat dari halaman yang sudah terbuka di depan Anda.
- Scraper API: Terbaik saat Anda membutuhkan pengumpulan yang andal dan berulang dalam volume lebih tinggi.
- Workflow automasi: Terbaik saat scraping hanya satu langkah dalam proses go-to-market yang lebih luas.
- Stack DIY untuk developer: Terbaik saat tim Anda ingin kontrol maksimum dan siap menanggung beban perawatan.
Tabel Perbandingan
| Tool | Terbaik Untuk | Mengapa Masuk Daftar Pendek | Sinyal Harga |
|---|---|---|---|
| Thunderbit | Tim non-teknis dan pekerjaan ad-hoc yang cepat | Deteksi field AI, penanganan halaman dinamis native browser, ekspor cepat | Uji coba gratis; paket berbayar berbasis kredit |
| Bright Data | Pipeline data sosial publik skala besar | API scraper media sosial khusus, managed unblocking, skala kuat | Harga berbasis penggunaan dan enterprise |
| Apify | Workflow scraping cloud yang fleksibel | Actor Facebook siap pakai, penjadwalan, akses API, ruang kustomisasi | Paket platform berbayar plus penggunaan terukur |
| Nimble by Nimbleway | Pengumpulan web publik API-first | Alur API berbasis URL dan beban perawatan scraper lebih rendah | Harga melalui sales |
| ScrapingBot | Pekerjaan data publik kecil dan prototipe | API sederhana, dukungan rendering, biaya masuk lebih rendah | Paket gratis; paket berbayar mulai sekitar $22/bulan |
| PhantomBuster | Workflow automasi GTM | Automasi cloud, workflow aksi browser, cocok untuk lead gen | Uji coba gratis; paket berbayar mulai sekitar $56/bulan |
| Octoparse | Scraping terjadwal no-code visual | Builder point-and-click, ekstraksi cloud, workflow berulang | Paket gratis; paket berbayar mulai sekitar $119/bulan |
1. Thunderbit
Thunderbit adalah pilihan terkuat di sini jika tujuan Anda adalah mengubah halaman Facebook atau daftar hasil Marketplace menjadi data terstruktur dengan cepat tanpa membangun atau memelihara scraper. Keunggulan utamanya adalah ekstraksi semantik: tool ini membaca halaman, menyarankan field yang berguna, dan memungkinkan Anda mengekspor hasil tanpa berurusan dengan selector, proxy, atau kode.
Mengapa menonjol:
- AI Suggest Fields: Thunderbit mengidentifikasi field yang kemungkinan relevan seperti judul, harga, penjual, lokasi, detail kontak, dan URL.
- Penanganan native browser: Karena berjalan di tempat halaman dirender, tool ini bekerja baik pada halaman dinamis yang banyak scroll.
- Enrichment subhalaman: Anda bisa mengumpulkan data daftar terlebih dahulu, lalu membuka tiap listing atau halaman untuk detail yang lebih kaya.
- Ekspor yang berguna: Excel, Google Sheets, Airtable, dan Notion semuanya jadi tujuan yang natural.
Jika Anda ingin menonton satu video sebelum mencoba workflow native browser sendiri, walkthrough Thunderbit yang praktis ini adalah tempat terbaik untuk mulai, karena menunjukkan alur ekstraksi yang sebenarnya alih-alih hanya berhenti pada klaim fitur:
Terbaik untuk: pengguna non-teknis, tim sales, operator, dan peneliti yang ingin hasil cepat.
Sinyal harga: Uji coba gratis tersedia; paket berbayar berbasis kredit. Lihat harga resmi.
Jalankan Sampel Data Facebook Gratis
2. Bright Data
Bright Data adalah pilihan yang berfokus pada infrastruktur. Dokumentasi Bright Data sendiri menyebut Social Media Scraper APIs mereka mencakup 10 platform dan 68 endpoint khusus, termasuk Facebook. Jika pekerjaan Anda adalah pengumpulan data publik skala besar, stack API terkelola seperti ini biasanya jauh lebih realistis daripada mencoba menskalakan ekstensi browser atau scraper rakitan sendiri.
Mengapa layak masuk shortlist:
- Endpoint scraping media sosial khusus
- Managed unblocking dan ekstraksi
- Pengiriman output terstruktur untuk pipeline data
- Cocok untuk pekerjaan monitoring dan analitik yang sensitif terhadap keandalan
Terbaik untuk: analis, tim data, proyek monitoring besar, dan dataset sosial publik dalam skala besar.
Sinyal harga: Harga bervariasi menurut produk dan volume. Verifikasi melalui harga Bright Data saat ini.
3. Apify
Apify tetap relevan karena memberi Anda titik tengah yang kuat antara template dan kustomisasi penuh. Actor Facebook Pages Scraper-nya menjadi titik awal yang berguna, sementara platform Apify yang lebih luas menyediakan cloud run, penjadwalan, API, dan ruang untuk memperluas workflow jika kebutuhan Anda makin kompleks.
Mengapa masuk daftar:
- Actor Facebook siap pakai
- Eksekusi cloud dan jadwal berulang
- Ekspor fleksibel dan akses API
- Lebih mudah diperluas daripada workflow browser no-code murni
Terbaik untuk: marketer teknis, agensi, tim operasional, dan pekerjaan pengumpulan berulang di banyak situs.
Sinyal harga: Paket platform berbayar dan penggunaan actor dihitung terpisah. Lihat harga Apify.
4. Nimble by Nimbleway
Nimble by Nimbleway adalah opsi API-first untuk tim yang ingin mengirim URL dan membiarkan platform menangani akses, rendering, dan pengiriman data. Nimble memposisikan Web Scraper API sebagai pengumpulan data web publik end-to-end, yang membuatnya berguna ketika scraping Facebook hanya satu bagian dari stack data yang lebih luas.
Mengapa layak dievaluasi:
- Workflow API berbasis URL
- Beban perawatan scraper lebih rendah untuk tim engineering
- Cocok untuk ekstraksi web publik yang tahan lama
- Berguna saat data hasil scraping menjadi bahan produk internal atau dashboard
Terbaik untuk: tim yang dipimpin engineering, pipeline data produk, dan organisasi yang ingin abstraksi infrastruktur, bukan tool titik.
Sinyal harga: Nimble tidak menonjolkan harga self-serve publik di halaman API intinya, jadi harapkan harga melalui sales dan verifikasi langsung dengan Nimble by Nimbleway.
5. ScrapingBot
ScrapingBot adalah opsi API yang paling hemat anggaran di daftar ini. Platform ini bukan yang paling dalam secara spesialisasi Facebook, tetapi tetap masuk akal untuk pekerjaan data publik skala kecil yang membutuhkan API, dukungan rendering, dan batas biaya awal yang lebih rendah daripada infrastruktur scraping enterprise.
Cocok untuk:
- Scraping publik berbasis API yang sederhana
- Harga masuk yang lebih rendah
- Rendering dan penanganan proxy sudah termasuk
- Lebih cocok untuk prototipe dan tarikan ringan berulang daripada program intel besar
Terbaik untuk: startup, bisnis kecil, dan developer yang menguji use case pengumpulan halaman publik yang ringan.
Sinyal harga: Paket gratis tersedia; halaman harga publik saat ini memulai paket berbayar sekitar US$22/bulan.
6. PhantomBuster
PhantomBuster lebih fokus pada apa yang terjadi setelah pengumpulan, bukan pada infrastruktur scraping mentah. Jika use case Anda adalah “kumpulkan datanya, lalu picu outreach, enrichment, atau tindakan tindak lanjut,” PhantomBuster sering kali lebih berguna daripada extractor biasa karena dirancang untuk automasi cloud dan workflow aksi browser.
Mengapa masih masuk shortlist tim:
- Workflow automasi berbasis cloud
- Berguna untuk lead generation dan operasi GTM
- Lebih cocok saat scraping hanya satu langkah dalam proses yang lebih luas
- Praktis untuk operator yang peduli pada tindakan, bukan sekadar ekspor
Terbaik untuk: tim GTM, tim growth, recruiter, dan operator yang menghubungkan pengumpulan ke tindakan lanjutan.
Sinyal harga: Uji coba gratis tersedia; paket berbayar di halaman harga saat ini mulai sekitar US$56/bulan.
7. Octoparse
Octoparse tetap menjadi salah satu tool scraping visual no-code yang lebih baik bagi pengguna yang menginginkan workflow berulang dan run cloud terjadwal. Tool ini tidak seringan Thunderbit untuk pekerjaan Facebook satu kali yang cepat, tetapi memberi non-developer kontrol yang lebih eksplisit atas bagaimana logika ekstraksi dibangun dan diulang.
Mengapa tetap relevan:
- Builder workflow visual point-and-click
- Ekstraksi cloud dan penjadwalan
- Cocok untuk tugas terstruktur yang berulang
- Lebih pas untuk analis yang menginginkan repeatability tanpa kode
Terbaik untuk: analis non-teknis, tim operasional SMB, dan tugas pengumpulan berulang dengan logika workflow yang lebih eksplisit.
Sinyal harga: halaman harga publik Octoparse mencantumkan paket berbayar mulai sekitar US$119/bulan.
Shortlist Berdasarkan Tim
Kalau Anda sudah tahu tim seperti apa yang akan memegang workflow-nya, mulai dari sini:
- Operator solo atau bisnis kecil: Thunderbit, ScrapingBot, atau Octoparse
- Tim sales / GTM: Thunderbit atau PhantomBuster
- Analis operasional: Thunderbit, Apify, atau Octoparse
- Tim automasi growth: PhantomBuster atau Apify
- Tim data engineering: Bright Data, Nimble, atau Apify

Cara Memilih Facebook Scraper yang Tepat
- Pilih Thunderbit jika kecepatan dan kesederhanaan lebih penting daripada skala maksimum.
- Pilih Bright Data jika Anda membutuhkan skala data publik dan keandalan terkelola.
- Pilih Apify jika Anda menginginkan fleksibilitas platform dan workflow berbasis actor.
- Pilih Nimble jika Anda menginginkan lapisan abstraksi API-first dengan perawatan scraper yang lebih sedikit.
- Pilih PhantomBuster jika scraping hanya satu langkah dalam workflow automasi GTM yang lebih luas.
- Pilih Octoparse jika Anda menginginkan repeatability visual tanpa kode.
- Pilih ScrapingBot jika anggaran penting dan pekerjaannya relatif sederhana.
Kesimpulan Akhir
Pemisahan pasar di 2026 lebih jelas daripada setahun lalu. Anda sebenarnya tidak sedang memilih satu “Facebook scraper terbaik” yang universal. Anda sedang memilih model pengumpulan: ekstraksi no-code yang cepat, skala API terkelola, automasi cloud, atau kontrol workflow visual langsung. Mulailah dari sana, dan daftar pendek Anda akan jauh lebih mudah.
Jika tim Anda ingin jalur tercepat dari halaman Facebook atau listing Marketplace ke data terstruktur yang bisa dipakai, Thunderbit masih menjadi tempat termudah untuk memulai. Jika volume atau kebutuhan engineering Anda jauh lebih berat, Bright Data, Apify, dan Nimble lebih masuk akal. Jika workflow Anda dimulai dengan scraping tetapi diakhiri dengan tindakan tindak lanjut, PhantomBuster adalah shortlist yang lebih cerdas.
FAQ
1. Apa tool scraping Facebook yang paling mudah untuk pengguna non-teknis?
Thunderbit adalah titik awal termudah bagi sebagian besar pengguna non-teknis karena bekerja di browser, menyarankan field secara otomatis, dan mengekspor data dengan cepat tanpa kode.
2. Tool scraping Facebook mana yang terbaik untuk pengumpulan data publik skala besar?
Bright Data adalah pilihan infrastruktur terkuat di daftar ini ketika pekerjaannya adalah pengumpulan data sosial publik skala besar dan keandalan lebih penting daripada kemudahan penggunaan.
3. Bagaimana jika saya membutuhkan scraping plus automasi tindak lanjut?
PhantomBuster adalah pilihan yang lebih baik saat pengumpulan data hanya satu langkah dalam workflow lead generation atau GTM yang lebih luas.
4. Apakah scraping Facebook masih sulit di 2026?
Ya. Konten dinamis, login wall, batas laju, sistem anti-bot, dan risiko akun masih membuat Facebook lebih sulit dibandingkan scraping website publik yang lebih sederhana.
5. Bagaimana seharusnya tim memikirkan kepatuhan?
Tetap fokus pada data publik, gunakan laju yang wajar, hindari penyalahgunaan kredensial, dan tinjau syarat platform serta aturan privasi yang berlaku sebelum menskalakan workflow.
Bacaan lanjutan:
- Cara Mencari Postingan Facebook Berdasarkan Kata Kunci (Panduan 2025)
- 55 Statistik Facebook Penting yang Perlu Anda Ketahui
- Cara Scrape Website Apa Pun Menggunakan AI
Coba Thunderbit untuk Scraping Facebook & Marketplace Get Started Free




