Anda mendaftar ke ScraperAPI, melihat "100.000 credit" di paket Hobby, lalu mulai melakukan scraping. Tiga hari kemudian, dashboard Anda menunjukkan 80% credit sudah habis — padahal Anda baru berhasil mengambil sekitar 6.000 halaman. Apa yang terjadi? Yang terjadi adalah sistem pengali credit, dan inilah satu hal paling penting tentang ScraperAPI yang nyaris tidak pernah dijelaskan oleh ulasan mana pun. Saya menghabiskan waktu berminggu-minggu membongkar dokumentasi ScraperAPI, mengumpulkan data harga nyata dari lima penyedia kompetitor, dan membaca setiap utas Reddit serta ulasan Capterra yang bisa saya temukan. ulasan scraper api ini adalah ulasan yang saya harap sudah ada saat tim kami pertama kali mulai mengevaluasi API scraping. Saya akan menguraikan perhitungan credit yang sebenarnya, menunjukkan di mana ScraperAPI bekerja dengan baik (dan di mana ia benar-benar gagal), merangkum apa kata pengguna sungguhan di G2, Capterra, dan Reddit, dan — sejujurnya — membantu Anda menentukan apakah Anda memang butuh scraping API sama sekali.
Apa Itu ScraperAPI dan Untuk Siapa Produk Ini Dibuat?
ScraperAPI adalah web scraping API yang menangani infrastruktur rumit di balik scraping skala besar: rotasi proxy di seluruh , pemecahan CAPTCHA otomatis, rendering JavaScript, dan percobaan ulang otomatis. Anda hanya perlu mengirim URL lewat panggilan API sederhana, lalu sistem akan mengembalikan HTML (atau JSON yang sudah diparsing kalau Anda memakai endpoint structured data mereka). Perusahaan ini didirikan pada 2018 oleh Daniel Ni, berkantor pusat di Las Vegas, dan kini melayani termasuk Deloitte, Sony, dan Alibaba — dengan pemrosesan .
Target utamanya adalah tim developer dan operasional teknis yang membangun pipeline scraping kustom. Kalau Anda tidak menulis kode, ScraperAPI memang bukan untuk Anda (nanti kita bahas lebih lanjut).
Fitur inti: rotasi proxy, rendering JavaScript, geotargeting, endpoint structured data untuk situs populer, dan retry otomatis untuk permintaan yang gagal.
Namun ada satu hal yang sering dilewatkan banyak ulasan: angka credit besar di halaman harga ScraperAPI sangat menyesatkan kalau Anda tidak paham cara kerja pengalinya. Jadi, kita mulai dari situ.
Cara Kerja Sistem Credit ScraperAPI yang Sebenarnya (Bagian yang Sering Dilewatkan Ulasan)
ScraperAPI memakai sistem penagihan berbasis credit. Konsep dasarnya sederhana: 1 permintaan API = 1 credit. Tapi nyaris tidak pernah sesederhana itu. Biaya credit yang sebenarnya bergantung pada dua hal: domain yang Anda scrape dan fitur yang Anda aktifkan. Dan biaya ini menumpuk dengan cara yang tidak intuitif.
Tabel Pengali Credit yang Seharusnya Dilihat Semua Pengguna Sebelum Daftar

Sebelum Anda mengaktifkan satu parameter pun, jenis situs yang Anda scrape sudah menentukan biaya dasar credit:
| Kategori Domain | Credit Dasar per Permintaan | Contoh |
|---|---|---|
| Situs normal | 1 | Blog, situs berita, HTML sederhana |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (mesin pencari) | 25 | Google, Bing |
| Media sosial | 30 |
Selain itu, fitur tertentu menambah credit ekstra:
| Parameter | Credit Ekstra | Catatan |
|---|---|---|
render=true (rendering JS) | +10 | Semua paket |
screenshot=true | +10 | Semua paket |
premium=true (premium proxy) | +10 | Semua paket |
ultra_premium=true | +30 | Hanya paket berbayar |
| Bypass anti-bot (Cloudflare, DataDome, PerimeterX) | +10 masing-masing | Terdeteksi otomatis — Anda tidak memilih ini |
premium=true + render=true digabung | +25 | BUKAN +20 |
ultra_premium=true + render=true digabung | +75 | BUKAN +40 |
Baris terakhir itu yang paling penting. Menggabungkan fitur ternyata biayanya LEBIH MAHAL daripada penjumlahan biaya masing-masing. Premium proxy (+10) plus rendering JavaScript (+10) secara logis seharusnya hanya menambah +20 credit, tetapi ScraperAPI mengenakan . Ultra-premium (+30) plus rendering JavaScript (+10) seharusnya menjadi +40, tetapi nyatanya — hampir dua kali lipat. Penumpukan non-linear ini tidak dijelaskan secara menonjol, dan inilah alasan utama pengguna merasa credit habis jauh lebih cepat dari yang mereka perkirakan.
Parameter yang tidak menambah credit ekstra: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Apa Saja yang Benar-Benar Didapat di Setiap Paket: Dari Free sampai Enterprise
Berikut dari ScraperAPI:
| Paket | Harga Bulanan | Tahunan (per bln) | API Credit | Concurrent Threads | Geotargeting |
|---|---|---|---|---|---|
| Free | $0 | — | 1.000 | 5 | Tidak |
| Hobby | $49 | $44 | 100.000 | 20 | Hanya AS & Uni Eropa |
| Startup | $149 | $134 | 1.000.000 | 50 | Hanya AS & Uni Eropa |
| Business | $299 | $269 | 3.000.000 | 100 | Level negara (50+ negara) |
| Scaling | $475 | $427 | 5.000.000 | 200 | Level negara |
| Enterprise | Kustom | Kustom | 5.000.000+ | 200+ | Level negara |
Sekarang, mari lihat biaya efektif per 1.000 permintaan di tiap tier dengan memperhitungkan pengali:
| Paket | Standar (1×) | Rendering JS (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0,49 | $4,90 | $2,45 | $12,25 | $36,75 |
| Startup ($149) | $0,15 | $1,49 | $0,75 | $3,73 | $11,18 |
| Business ($299) | $0,10 | $1,00 | $0,50 | $2,49 | $7,48 |
| Scaling ($475) | $0,10 | $0,95 | $0,48 | $2,38 | $7,13 |
Paket $49/bulan yang dipromosikan sebagai "100.000 credit" ternyata hanya menghasilkan 1.333 permintaan nyata kalau Anda melakukan scraping situs yang dilindungi dengan ultra-premium plus rendering JavaScript. Itu setara dengan — lebih mahal daripada banyak layanan scraping fully managed.
Kenapa Credit Habis Lebih Cepat dari yang Anda Kira
Ada tiga hal yang sering mengejutkan pengguna.
Pertama: harga berdasarkan domain diterapkan otomatis. Anda tidak memilih sendiri pengali 5× untuk Amazon atau 25× untuk Google. Begitu ScraperAPI mendeteksi domainnya, biaya itu langsung dikenakan. Hal yang sama berlaku untuk credit bypass anti-bot (+10 untuk Cloudflare, DataDome, PerimeterX) — semuanya ditambahkan otomatis saat terdeteksi.
Kedua: credit TIDAK dibawa ke periode berikutnya. Credit yang tidak terpakai . Tidak ada akumulasi.
Dan ketiga — ini yang paling menyakitkan — Pay-As-You-Go hanya tersedia mulai paket Scaling ($475/bulan) ke atas. Kalau Anda memakai Hobby, Startup, atau Business lalu credit habis di tengah siklus, akses Anda langsung berhenti sampai periode tagihan berikutnya. Satu-satunya opsi adalah naik ke tier yang lebih tinggi.
Seorang pengguna di Reddit melaporkan pernah diberi penawaran $3.600 untuk 60 juta credit pada harga 1 credit per permintaan Amazon, tetapi setelah membayar, pengali 5 credit diterapkan tanpa penjelasan di awal. Paket 60M itu praktis hanya bernilai 12M permintaan — kekurangan dari yang mereka harapkan.
Jebakan Credit DataPipeline
Fitur no-code DataPipeline milik ScraperAPI (scraping terjadwal dengan pengiriman webhook) memakai skema credit terpisah yang jauh lebih mahal. Permintaan dasar normal membutuhkan lewat API standar:
| Jenis Permintaan | Standard API | DataPipeline | Rasio |
|---|---|---|---|
| Permintaan normal dasar | 1 | 6 | 6× |
| E-commerce dasar | 5 | 10 | 2× |
| SERP dasar | 25 | 30 | 1,2× |
| Ultra-premium + JS (normal) | 75 | 80 | 1,07× |
Pengguna yang menyiapkan pipeline no-code dengan asumsi biaya credit standar akhirnya mendapati credit mereka habis 6× lebih cepat untuk permintaan dasar. Ini terdokumentasi, tetapi Anda harus mencarinya cukup dalam.
Biaya Nyata per Permintaan: ScraperAPI vs Kompetitor
Harga yang tertulis di depan tidak ada artinya kalau tidak memperhitungkan pengali. Saya mengambil harga terbaru dari lima penyedia dan menstandarkan perbandingannya pada tier sekitar $300/bulan untuk tiga skenario umum.
Scrape HTML Dasar (Tanpa JS, Tanpa Premium Proxy)
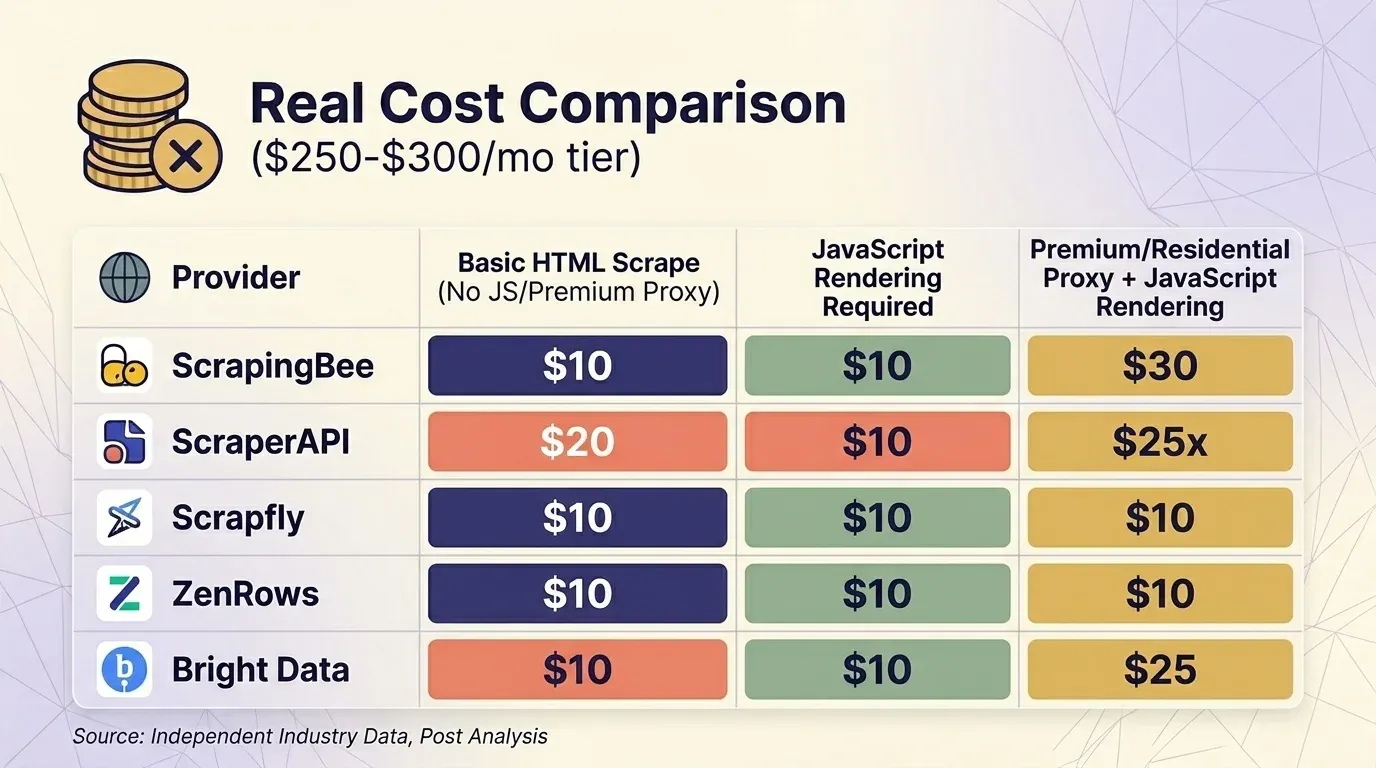
| Penyedia | Paket | Credit per Permintaan | Permintaan Nyata | Biaya per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3.000.000 | $0,08 |
| ScraperAPI | Business $299 | 1 | 3.000.000 | $0,10 |
| Scrapfly | Startup $250 | 1 | 2.500.000 | $0,10 |
| ZenRows | Business $300 | $0,28/1K | ~1.071.000 | $0,28 |
| Bright Data | PAYG | $1,50/1K | ~200.000 | $1,50 |
Dibutuhkan Rendering JavaScript
| Penyedia | Paket | Credit per Permintaan | Permintaan Nyata | Biaya per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (aktif default) | 600.000 | $0,42 |
| Scrapfly | Startup $250 | 6 | 416.667 | $0,60 |
| ScraperAPI | Business $299 | 10 | 300.000 | $1,00 |
| ZenRows | Business $300 | 5× | ~214.000 | $1,40 |
| Bright Data | PAYG | flat | ~200.000 | $1,50 |
Premium/Residential Proxy + Rendering JavaScript (Situs yang Dilindungi)
| Penyedia | Paket | Credit per Permintaan | Permintaan Nyata | Biaya per 1K |
|---|---|---|---|---|
| Bright Data | PAYG | flat | ~200.000 | $1,50 |
| ScrapingBee | Business $249 | 25 | 120.000 | $2,08 |
| ScraperAPI | Business $299 | 25 | 120.000 | $2,49 |
| Scrapfly | Startup $250 | 31 | 80.645 | $3,10 |
| ZenRows | Business $300 | 25× | ~42.857 | $7,00 |
Web Unlocker milik Bright Data adalah satu-satunya penyedia yang — semua permintaan dikenakan tarif flat yang sama. Di tier sekitar $300, ScrapingBee dan ScraperAPI masih kompetitif untuk scraping situs yang dilindungi, sedangkan ZenRows adalah yang paling mahal.
Satu catatan perilaku penting: ScrapingBee dengan biaya 5×. Kalau Anda membandingkan ScrapingBee dan ScraperAPI secara langsung, pastikan pengaturan rendering-nya sama.
Analisis independen dari Scrape.do menemukan bahwa biaya ScraperAPI mencapai — "lebih mahal daripada semua penyedia lain yang diuji" — dengan waktu respons rata-rata , menjadikannya "salah satu penyedia paling lambat yang tersedia." Ini layak diketahui sebelum Anda berkomitmen.
Tingkat Keberhasilan per Situs: Di Mana ScraperAPI Unggul dan Di Mana Ia Tersendat
Tidak ada scraping API yang bekerja sama baiknya di semua situs. Benchmark independen dari Scrapeway (April 2026) menunjukkan pola yang sangat bimodal.
Performa Berdasarkan Kategori Situs
| Situs Target | Tingkat Keberhasilan | Kecepatan Rata-Rata | Biaya per 1K (Business Plan) | |---|---|---|---|---| | Zillow | 100% | 10,5 dtk | $0,49 | | Etsy | 99% | 4,8 dtk | $4,90 | | Amazon | 98% | 6,5 dtk | $2,45 | | LinkedIn | 95% | 17,8 dtk | $14,70 | | Walmart | 93% | 11,4 dtk | $2,45 | | Indeed | 90% | 15,8 dtk | $4,90 | | StockX | 84% | 3,9 dtk | $4,90 | | Realtor.com | 12% | 11,8 dtk | $0,49 | | Instagram | 0% | — | — | | Booking.com | 0% | — | — | | Twitter/X | 0% | — | — |
Rata-rata keberhasilan keseluruhan: , sedikit di atas rata-rata industri 58,2–59,5%. Waktu respons rata-rata: 5,2–7,3 detik, lebih baik dari rata-rata industri 9,8 detik.
Di Mana ScraperAPI Bekerja dengan Baik
ScraperAPI benar-benar kuat untuk e-commerce (Amazon, Walmart, Etsy) dan real estate (Zillow). Endpoint structured data untuk situs-situs ini mengembalikan JSON terurai dengan tingkat keandalan tinggi. Kalau use case utama Anda adalah scraping halaman produk Amazon atau Google SERP, ScraperAPI adalah pilihan yang masuk akal.
Di Mana ScraperAPI Kurang Baik
Media sosial adalah zona mati. Instagram, Twitter/X, dan Booking.com semuanya menunjukkan tingkat keberhasilan 0% dalam pengujian independen. LinkedIn bekerja di 95%, tetapi dengan biaya 30 credit per permintaan, biayanya cukup tinggi.
Situs yang mewajibkan login secara eksplisit tidak didukung. ScraperAPI mendukung session persistence melalui parameter session_number, tetapi . Sistem ini juga tidak bisa menangani pengisian formulir, autentikasi dua faktor, atau alur otorisasi yang kompleks.
Data yang basi pada target terlindungi. ScraperAPI menerapkan , jadi jika Anda mengambil data yang sensitif terhadap waktu (harga, stok), hasil yang Anda terima bisa tertunda hingga 10 menit.
Dalam benchmark Proxyway tahun 2025, ScraperAPI memiliki dengan angka 81,72%.
Ringkasan Performa Berdasarkan Kategori Situs
| Kategori Situs | Performa ScraperAPI | Masalah yang Dikenal | Alternatif Potensial |
|---|---|---|---|
| Amazon / e-commerce | ✅ Kuat (endpoint SDP) | Boros credit saat skala besar | Thunderbit templates (1 klik, tanpa credit per baris untuk template) |
| Google SERP | ✅ Kuat | Geotargeting dikenakan biaya ekstra; tingkat keberhasilan Google terendah di salah satu benchmark | — |
| Real estate (Zillow) | ✅ Sangat baik (100%) | — | — |
| Instagram / media sosial | ❌ 0% berhasil | Gagal total | Playwright + proxy (DIY) |
| SPA berat JS | ⚠️ Sedang | Butuh rendering headless 10× credit | Scrapfly, ZenRows |
| Situs yang butuh login | ❌ Dilarang oleh ToS | Tidak ada dukungan sesi/autentikasi | Thunderbit browser scraping (memakai sesi login Anda) |
| Booking.com / travel | ❌ 0% berhasil | Gagal total | Bright Data |
Apa Kata Pengguna Asli: Ringkasan Sentimen dari G2, Capterra, dan Reddit
Saya mengumpulkan feedback dari tiga platform. Berikut rating saat ini:
| Platform | Rating | Ulasan |
|---|---|---|
| G2 | 4,4/5 | 16 |
| Capterra | 4,6/5 | 62 |
| Trustpilot | 4,5/5 | 43 |
Sub-rating Capterra: Kemudahan Penggunaan 4,9/5, Layanan Pelanggan 4,6/5, Fitur 4,5/5, Nilai untuk Uang 4,5/5.
Ringkasan Sentimen per Tema
| Tema | Sinyal Positif | Sinyal Negatif |
|---|---|---|
| Kemudahan setup / dokumentasi | "Sangat mudah disiapkan. Anda bisa mulai scraping dalam hitungan menit." — komunitas Latenode; Kemudahan Penggunaan Capterra 4,9/5 | — |
| Transparansi harga | "Tier awal yang terjangkau" (beberapa ulasan Capterra) | "Rincian biaya credit bisa membingungkan" — John S., Founder, Capterra (Feb 2025); "Harga naik 1000% dan kualitas menurun" — CTO, Online Media, Capterra (Sep 2022) |
| Keandalan | "Berfungsi sangat baik untuk Amazon/Google" (G2, Capterra) | "ScraperAPI jadi goyah untuk pekerjaan berat" — emcarter, Latenode; "Tingkat kegagalan 80% pada beberapa target" (Reddit) |
| Dukungan pelanggan | "Tim responsif" (Capterra) | Pengguna melaporkan pernah diberi harga tertentu, lalu ditagih 5× lipat tanpa penjelasan di awal (Reddit) |
| Nilai jangka panjang | Hanya menagih permintaan yang berhasil (200/404) | "Kalau Anda menjalankan operasi skala besar, biayanya bisa cepat membengkak" dan membangun infrastruktur sendiri "lebih hemat dalam jangka panjang" — mikezhang, Latenode |
Kesimpulannya: ScraperAPI dihargai karena mudah dipakai di awal dan bekerja cukup andal pada target populer yang didukung dengan baik. Keluhan paling banyak muncul pada kejutan harga (pengali, kenaikan tak terduga) dan keandalan pada target yang lebih sulit.
Endpoint Structured Data ScraperAPI: Layak Tidak Menambah Credit Premium?
ScraperAPI menawarkan di 5 platform, yang mengembalikan JSON terurai alih-alih HTML mentah:
- Amazon (3 endpoint): detail produk berdasarkan ASIN, hasil pencarian, penawaran kompetitor. Mengembalikan 18+ field termasuk harga, rating, deskripsi, ulasan, BSR, gambar, info penjual. Mendukung .
- Google (5 endpoint): (hasil organik, knowledge graph, video, pertanyaan terkait, pagination), Shopping, Maps, News, Jobs.
- Walmart (4 endpoint): Product, Search, Category, Reviews.
- eBay (2 endpoint): Product, Search.
- Redfin (4 endpoint): Search, Agent Details, Rental Properties, For Sale.
SDE tersedia di semua paket, termasuk Free. ScraperAPI mengklaim untuk domain SDE yang didukung — meski benchmark independen menunjukkan hasil yang lebih bervariasi tergantung situsnya.
Kelengkapan Data
Amazon SDP adalah penawaran terkuat dari ScraperAPI. Endpoint ini mengembalikan kumpulan field yang sangat lengkap: harga, ulasan, BSR, variasi, gambar, info penjual, dan lainnya. Google SERP SDP juga mengembalikan hasil organik, iklan, featured snippet, dan People Also Ask. Kelengkapan datanya memang sangat baik untuk dua platform ini.
Efisiensi Credit: SDP vs Parsing DIY
Di paket Business ($299/bulan, 3M credit), scraping 10.000 produk Amazon via SDE menghabiskan 50.000 credit (5 credit per item) — sekitar $5 dari paket tersebut. Membangun parser sendiri dengan permintaan standar (1 credit per item) hanya akan memakan 10.000 credit, tetapi Anda harus menginvestasikan waktu developer untuk membangun dan memelihara parser.
Untuk tim kecil tanpa developer, SDE benar-benar menghemat waktu.
Untuk tim dengan kapasitas engineering yang melakukan scraping skala besar, premium 5× credit sulit dibenarkan.
Perbandingan SDPs dengan Template Scraper No-Code
Perbandingan ini jauh lebih penting daripada yang diakui banyak ulasan. menawarkan template scraper instan untuk Amazon, Shopify, Zillow, dan yang tidak memerlukan coding dan tidak ada biaya credit per baris untuk template itu sendiri.
| Faktor | ScraperAPI SDP (Amazon) | Template Amazon Thunderbit |
|---|---|---|
| Waktu setup | 30–60 menit (kode + integrasi API) | ~2 menit (install ekstensi, buka Amazon, klik template) |
| Biaya per 1.000 produk (Business plan) | ~$5 (50.000 credit pada $0,10/credit) | ~$16,50 (1.000 baris × 1 credit pada $0,0165/credit di Pro) |
| Field yang dikembalikan | 18+ (sangat lengkap) | Nama produk, harga, rating, ulasan, gambar, URL, dan lainnya |
| Opsi ekspor | JSON (butuh kode untuk parsing) | Excel, CSV, Google Sheets, Airtable, Notion — 1 klik |
| Pemeliharaan | ScraperAPI yang memelihara SDP | Tim Thunderbit yang memelihara template |
| Keahlian teknis | Wajib Python/Node.js | Tidak perlu |
Untuk tim developer yang melakukan scraping Amazon volume tinggi, SDP ScraperAPI lebih efisien biaya per produk pada skala besar. Untuk pengguna bisnis yang butuh data Amazon di spreadsheet tanpa menulis kode, Thunderbit jauh lebih cepat disiapkan dan digunakan.
Apakah Anda Benar-Benar Butuh Scraping API? Jalur No-Code yang Sering Diabaikan Ulasan
Banyak orang yang mencari "review Scraper API" sebenarnya belum sepenuhnya memutuskan memakai workflow berbasis API. Mereka masih mencari tahu apakah mereka memang membutuhkannya.
Dan ternyata, banyak yang tidak membutuhkannya. Pasar web scraping API bernilai dengan pertumbuhan 14–18% CAGR, tetapi pertumbuhan itu sebagian besar didorong oleh tim engineering enterprise — bukan oleh sales ops manager yang butuh 500 lead dari sebuah situs.
Scraping API vs Alat No-Code: Kerangka Keputusan Berdampingan
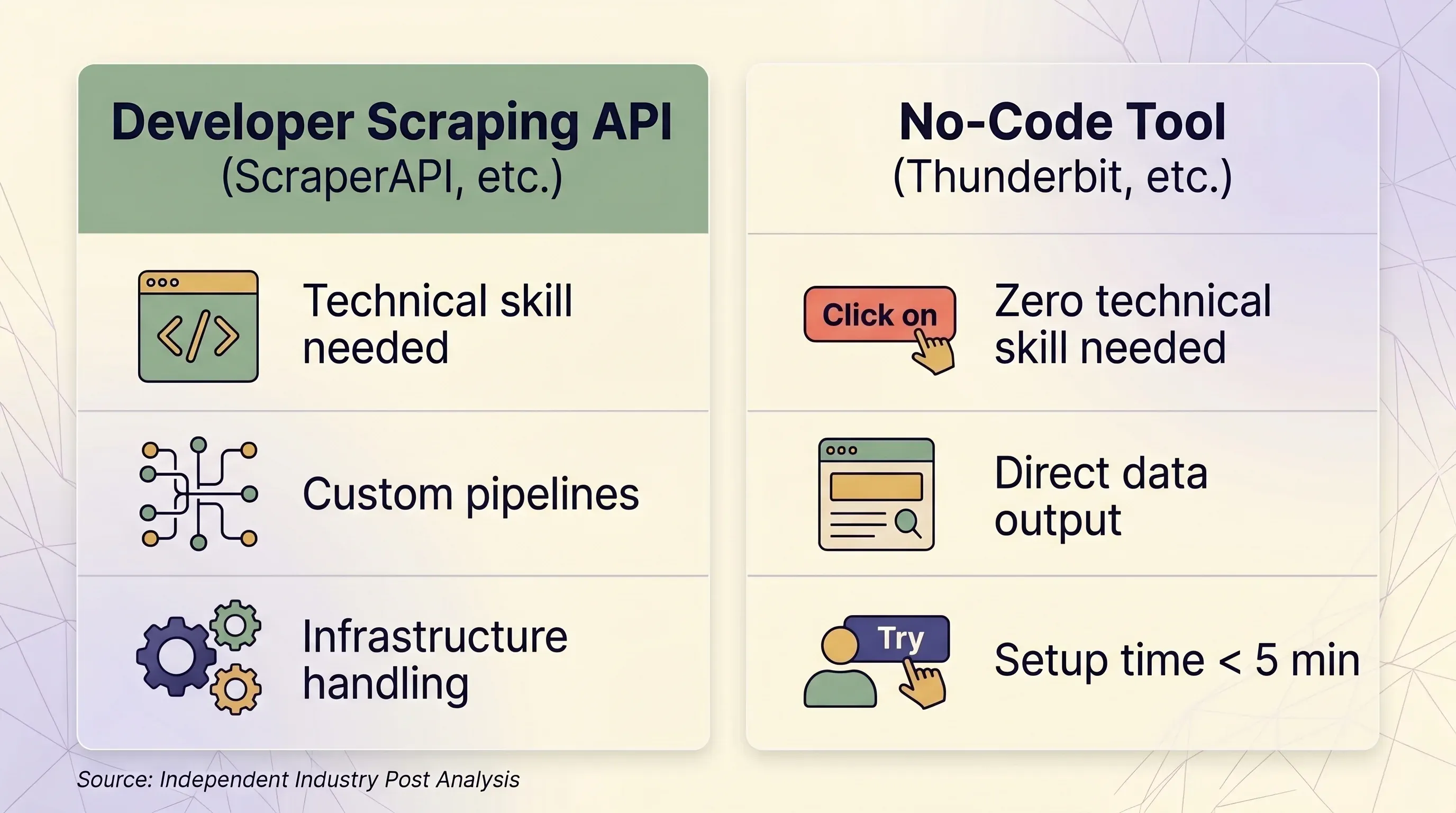
| Faktor | Scraping API (ScraperAPI, dll.) | Alat No-Code (Thunderbit, dll.) | |---|---|---|---| | Paling cocok untuk | Developer yang membangun pipeline data skala besar | Pengguna bisnis, marketer, tim sales, peneliti | | Keahlian teknis yang dibutuhkan | Python/Node.js, konsep HTTP, parsing JSON | Tidak perlu — cukup klik di browser | | Waktu setup | Minimal 1–2 jam (coding + testing + debugging) | Di bawah 5 menit | | Penanganan anti-bot | Premium proxy (10–75 credit/permintaan) | Sesi browser asli — secara alami melewati fingerprinting | | Situs yang butuh login | ❌ Dilarang oleh ToS ScraperAPI | ✅ Browser Scraping memakai sesi Anda yang sudah ada | | Skala (halaman/hari) | 100 ribu–3 juta+ permintaan/bulan | Ad-hoc, biasanya di bawah 1.000 halaman/hari | | Output data | HTML mentah atau JSON (butuh kode parsing) | Baris/kolom terstruktur — siap pakai | | Ekspor | JSON, CSV (melalui kode) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Pemeliharaan | Harus update selector, retry logic, infrastruktur | Tidak ada — AI membaca ulang struktur halaman setiap kali | | Satuan harga | Credit per permintaan (variabel: 1–75 credit/permintaan) | Credit per baris (1 credit = 1 baris, 2 untuk subhalaman) | | Harga masuk | $49/bulan untuk 100K credit | $9/bulan untuk 5.000 credit (tahunan) | | Tier gratis | 1.000 credit/bulan, 5 concurrent | 6 halaman/bulan, 30 credit/halaman | | Prediktabilitas harga | Rendah — pengali memicu biaya tak terduga | Tinggi — 1 baris selalu = 1 credit |
Kapan Scraping API Masuk Akal
- Anda punya developer atau tim engineering
- Anda perlu scraping 100 ribu+ halaman per hari secara programatik
- Anda butuh kustomisasi mendalam pada header request, sesi, dan retry logic
- Target Anda didukung dengan baik (Amazon, Google, Walmart, Zillow)
Kapan Alat No-Code Seperti Thunderbit Lebih Masuk Akal
- Anda bekerja di sales, e-commerce ops, marketing, atau real estate — bukan engineering
- Anda butuh data dari puluhan situs berbeda tanpa membangun parser kustom satu per satu
- Anda ingin ekspor langsung ke Excel, Google Sheets, Airtable, atau Notion
- Anda perlu scraping situs yang mengharuskan login (browser scraping Thunderbit )
- Anda ingin AI membaca halaman secara segar setiap kali — tanpa maintenance kode saat layout situs berubah
- Anda butuh scraping subhalaman: Thunderbit bisa membuka setiap detail page dan memperkaya baris secara otomatis
Alur kerja benar-benar sederhana: instal ekstensi, buka halaman mana pun, klik "AI Suggest Fields," klik "Scrape," lalu ekspor. AI akan mengenali data yang ada di halaman dan menyarankan kolom — Anda tidak perlu menulis selector atau kode. Untuk penjelasan lebih lanjut, lihat .
mengalami pembengkakan biaya cloud pada 2024, dan perusahaan yang memakai harga berbasis penggunaan tanpa perlindungan yang memadai mengalami karena bill shock. Prediktabilitas model credit per baris layak dipertimbangkan kalau Anda pernah rugi akibat biaya API yang berubah-ubah.
Kelebihan dan Kekurangan ScraperAPI Sekilas
| Kelebihan | Kekurangan |
|---|---|
| Infrastruktur proxy kuat (40M+ IP, 50+ negara) | Sistem pengali credit membingungkan — menggabungkan fitur biayanya lebih mahal dari penjumlahan biasa |
| Dokumentasi sangat baik dan setup awal mudah (Kemudahan Penggunaan Capterra: 4,9/5) | Credit TIDAK dibawa ke bulan berikutnya |
| Andal untuk Amazon, Google, Zillow, Etsy | 0% berhasil di Instagram, Twitter/X, Booking.com |
| Hanya menagih permintaan berhasil (200/404) | Respons 404 tetap menghabiskan credit |
| 18 endpoint structured data dengan output JSON terurai | Situs yang butuh login secara eksplisit dilarang |
| Tersedia di semua paket termasuk Free | Pay-As-You-Go hanya di Scaling ($475/bln) ke atas |
| Kebijakan refund 7 hari tanpa tanya | Cache paksa 10 menit pada target sulit — risiko data basi |
| Pertumbuhan pendapatan 30–35% YoY menunjukkan pengembangan aktif | DataPipeline bisa memakai hingga 6× credit API standar |
| — | Geotargeting di luar AS & Uni Eropa butuh paket Business ($299/bln) |
| — | Tidak ada peringatan penggunaan proaktif — harus cek dashboard manual |
Tips Praktis Agar Mendapatkan Hasil Maksimal dari ScraperAPI (Kalau Anda Memutuskan Memakainya)
Pantau Konsumsi Credit Setiap Hari
ScraperAPI menyediakan statistik penggunaan termasuk latensi rata-rata, domain yang di-scrape, dan metrik concurrency. Namun, tidak ada peringatan penggunaan proaktif — tidak ada email atau SMS saat credit menipis. Anda harus cek manual. Riwayat analitik dibatasi 2 minggu untuk paket Hobby/Startup dan 6 bulan untuk Business ke atas.
Pasang pengingat kalender untuk memeriksa dashboard setiap hari selama bulan pertama. Anda perlu membangun intuisi soal seberapa cepat credit habis di target spesifik Anda.
Mulai dari Tier Gratis untuk Menguji Target Anda
Gunakan 1.000 credit gratis (ditambah trial 7 hari dengan 5.000 credit) untuk menguji tingkat keberhasilan di situs target Anda sebelum berkomitmen ke paket berbayar. Catat situs mana yang membutuhkan rendering JavaScript atau premium proxy agar Anda bisa memperkirakan biaya bulanan secara realistis dengan pengali yang diterapkan.
Nonaktifkan Fitur Premium Jika Target Tidak Membutuhkannya
ScraperAPI TIDAK mengaktifkan premium proxy atau rendering JavaScript secara otomatis — Anda harus secara eksplisit mengatur render=true, premium=true, atau ultra_premium=true. Tetapi harga berdasarkan domain memang otomatis: Amazon selalu 5 credit, Google selalu 25, LinkedIn selalu 30. Credit bypass anti-bot (+10 untuk Cloudflare, DataDome, PerimeterX) juga otomatis ditambahkan saat terdeteksi. Pahami ini sebelum menjalankan batch.
Gunakan Endpoint Structured Data untuk Situs yang Didukung
Kalau Anda melakukan scraping Amazon atau Google, SDE bisa menghemat waktu pengembangan meski biayanya lebih besar dalam credit. Untuk situs yang tidak didukung, pertimbangkan apakah akan lebih cepat dan lebih murah daripada membangun parser kustom.
Siapkan Cadangan untuk Target yang Tidak Stabil
Jika tingkat keberhasilan ScraperAPI pada situs tertentu di bawah 90%, pertimbangkan untuk mengalihkan permintaan itu ke penyedia lain atau memakai alat berbasis browser. Untuk situs yang membutuhkan login, ScraperAPI memang tidak akan bekerja — Anda perlu alat seperti yang berjalan di sesi browser Anda.
Pahami Hal-Hal yang Sering Menjebak
- Respons 404 tetap menghabiskan credit — ScraperAPI menagih status code 200 dan 404
- Permintaan yang dibatalkan tetap ditagih jika Anda membatalkan sebelum jendela pemrosesan 70 detik selesai
- Cache paksa 10 menit pada target sulit — Anda bisa menerima data yang sudah usang
- Pay-As-You-Go hanya tersedia di Scaling ($475/bulan) ke atas — pengguna tier lebih rendah yang kehabisan credit akan terputus
- Geotargeting di luar AS & Uni Eropa membutuhkan paket Business ($299/bulan)
Kesimpulan Utama: Apakah ScraperAPI Tepat untuk Anda?
Inilah kesimpulan saya setelah semua riset ini:
- ScraperAPI adalah pilihan solid untuk tim developer yang melakukan scraping volume tinggi pada target yang didukung dengan baik seperti Amazon, Google, Walmart, dan Zillow. Endpoint structured data-nya benar-benar berguna, infrastruktur proxy-nya besar, dan dokumentasinya di atas rata-rata.
- Sistem pengali credit adalah risiko terbesar. Kalau Anda tidak paham cara kerja pengali saat digabung, Anda akan mengeluarkan biaya berlebih. Kesenjangan antara credit yang diiklankan dan permintaan nyata bisa 5–75×. Hitung dulu untuk use case spesifik Anda sebelum berlangganan.
- Keandalan sangat bergantung pada situs. ScraperAPI sangat bagus di e-commerce dan real estate, biasa saja di job board dan media sosial, dan sama sekali tidak berguna di Instagram, Twitter/X, serta Booking.com. Jangan berasumsi performanya seragam.
- Untuk tim non-teknis, ScraperAPI adalah alat yang salah. Kalau Anda bekerja di sales, marketing, atau operasional dan butuh data terstruktur tanpa menulis kode, alat no-code seperti bisa membuat Anda sampai tujuan hanya dengan dua klik — dengan deteksi field berbasis AI, ekspor langsung ke spreadsheet, enrichment subhalaman, dan tanpa beban maintenance. Coba atau tonton tutorial di .
- Untuk developer dengan budget terbatas, uji tier gratis ScraperAPI pada target Anda, lalu bandingkan biaya efektif per permintaan dengan ScrapingBee, Scrapfly, dan Bright Data sebelum memilih. Opsi termurah sepenuhnya bergantung pada use case dan kebutuhan fitur Anda.
Ingin melihat bagaimana hitung-hitungannya untuk kebutuhan scraping Anda sendiri? Mulailah dengan tier gratis ScraperAPI untuk menguji situs target Anda, atau untuk melihat sejauh mana dua klik bisa membawa Anda. Untuk info lebih lanjut soal , cek paket kami.
FAQ
Apakah ScraperAPI gratis?
Ya, ScraperAPI menawarkan tier gratis dengan dan trial 7 hari dengan 5.000 credit. Namun, pengali credit untuk rendering JavaScript, premium proxy, atau domain berbiaya tinggi (Amazon = 5×, Google = 25×, LinkedIn = 30×) berarti kapasitas nyata Anda bisa jauh lebih kecil dari 1.000 permintaan. Pada tier gratis, ultra-premium proxy tidak tersedia.
Berapa biaya ScraperAPI per permintaan?
Sangat bergantung pada flag fitur dan domain target. Permintaan standar ke situs HTML sederhana memakan 1 credit. Permintaan Amazon memakan 5 credit. Permintaan Google SERP memakan 25 credit. Menambahkan rendering JavaScript menambah 10 credit. Menggabungkan ultra-premium proxy dengan rendering JavaScript memakan 75 credit per permintaan. Di paket Hobby ($49/bulan, 100K credit), biayanya berkisar dari $0,00049 per permintaan (standar) hingga $0,0368 per permintaan (ultra-premium + JS). Lihat tabel biaya lengkap di atas untuk detailnya.
Apakah ScraperAPI bagus untuk scraping Amazon?
Endpoint Amazon Structured Data milik ScraperAPI adalah salah satu fitur terkuatnya, dengan dalam benchmark independen dan output JSON terurai yang sangat lengkap (18+ field). Namun, setiap permintaan Amazon minimal memakan 5 credit, jadi biayanya membengkak saat skala besar. Untuk tim kecil yang ingin data Amazon ke spreadsheet tanpa kode, menawarkan alternatif 1 klik dengan ekspor langsung.
Apa alternatif terbaik untuk ScraperAPI?
Untuk developer: (termurah untuk HTML dasar), (bagus untuk rendering JavaScript), (terbaik untuk situs yang dilindungi — tarif flat terlepas dari rendering), dan . Untuk pengguna non-teknis: — ekstensi Chrome no-code berbasis AI dengan ekspor langsung ke Excel, Google Sheets, Airtable, dan Notion. Lihat kami untuk ulasan lebih dalam.
Bisakah ScraperAPI men-scrape situs yang butuh login?
ScraperAPI mendukung session persistence melalui parameter session_number (IP yang sama di beberapa permintaan), tetapi . Ia tidak bisa menangani pengisian formulir, autentikasi dua faktor, atau alur login yang kompleks. Untuk situs yang membutuhkan login, alat berbasis browser seperti — yang menggunakan sesi browser Anda yang sudah ada untuk mengambil data yang bisa Anda lihat — adalah opsi yang lebih andal.
Pelajari Lebih Lanjut