
Walmart mengubah harga beberapa itemnya . Kalau Anda pernah mencoba melacaknya secara programatis, Anda tahu rasanya: skrip jalan 20 menit, lalu diam-diam mulai mengembalikan halaman CAPTCHA yang menyamar sebagai respons 200 OK normal.
Saya sudah banyak menghabiskan waktu mengatasi pertahanan anti-bot Walmart sebagai bagian dari pekerjaan ekstraksi data kami di , dan saya ingin membagikan semua yang saya pelajari — metode yang benar-benar berhasil di 2025, kegagalan diam-diam yang merusak data, dan kompromi jujur antara menulis scraper sendiri, membayar API scraping, atau sekadar memakai alat no-code. Panduan ini membahas tiga metode ekstraksi (parsing HTML, JSON __NEXT_DATA__, dan intersepsi API internal), penanganan error siap produksi yang sering dilewati tutorial, serta kerangka keputusan yang jujur untuk memilih pendekatan yang tepat. Ada sesuatu di sini, baik Anda menulis Python atau hanya ingin spreadsheet berisi harga sebelum makan siang.
Mengapa Scrape Walmart dengan Python?
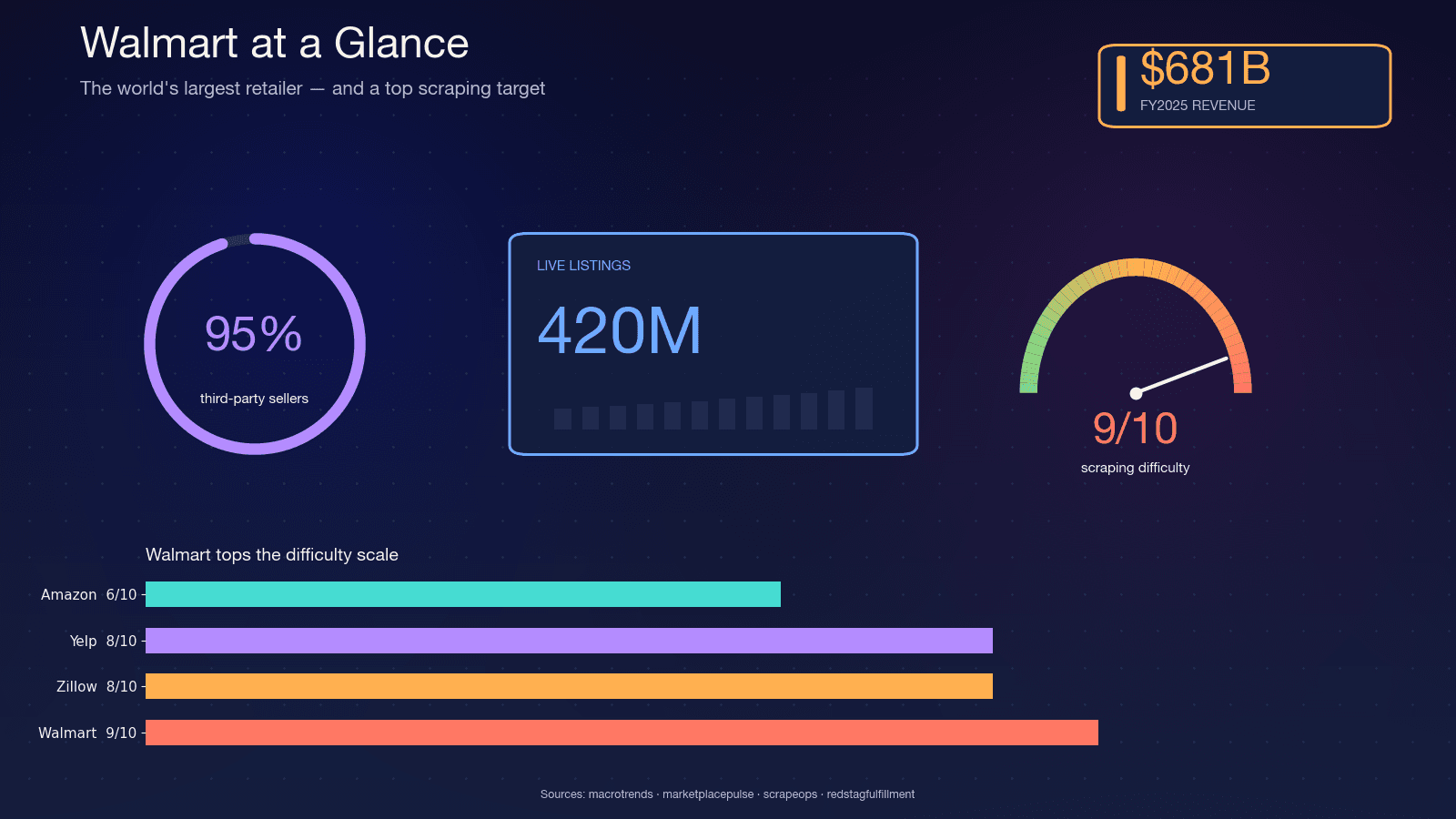
Walmart adalah pengecer terbesar di dunia berdasarkan pendapatan — pada FY2025, dan telah mempertahankan . Situs ini menampung sekitar , dengan CFO Walmart menyebut ada di marketplace. Sekitar , yang berarti katalognya sangat dinamis — penjual masuk dan keluar, varian berubah, dan stok berganti setiap hari.
Dinamika itulah yang membuat scraping penting. Laporan kuartalan tidak bisa menangkap apa yang bisa ditangkap oleh scraping harian. Berikut kasus penggunaan yang paling sering saya lihat:
| Kasus Penggunaan | Siapa yang Membutuhkan | Apa yang Diekstrak |
|---|---|---|
| Pemantauan harga kompetitor | Operasional e-commerce, alat repricing | Harga, promosi, kepatuhan MAP |
| Pengayaan katalog produk | Tim sales & merchandising | Deskripsi, gambar, spesifikasi, varian |
| Pelacakan ketersediaan stok | Rantai pasok, dropshipper | Status inventaris, info penjual |
| Riset pasar & analisis tren | Marketing, manajer produk | Rating, ulasan, variasi kategori |
| Generasi prospek | Tim sales | Nama penjual, jumlah produk, kategori |
Pasar dan diproyeksikan mencapai $5,09 miliar pada 2033. Perilaku konsumen mendorong pengeluaran ini: , dan 83% membandingkan harga di berbagai situs.
Python adalah bahasa default untuk pekerjaan ini. Laporan Infrastruktur Apify 2026 menempatkan , dan library inti (requests) mendapat . Kalau Anda melakukan scraping dalam skala apa pun, hampir pasti Anda melakukannya dengan Python.
Mengapa Walmart Jadi Salah Satu Situs Tersulit untuk Di-Scrape
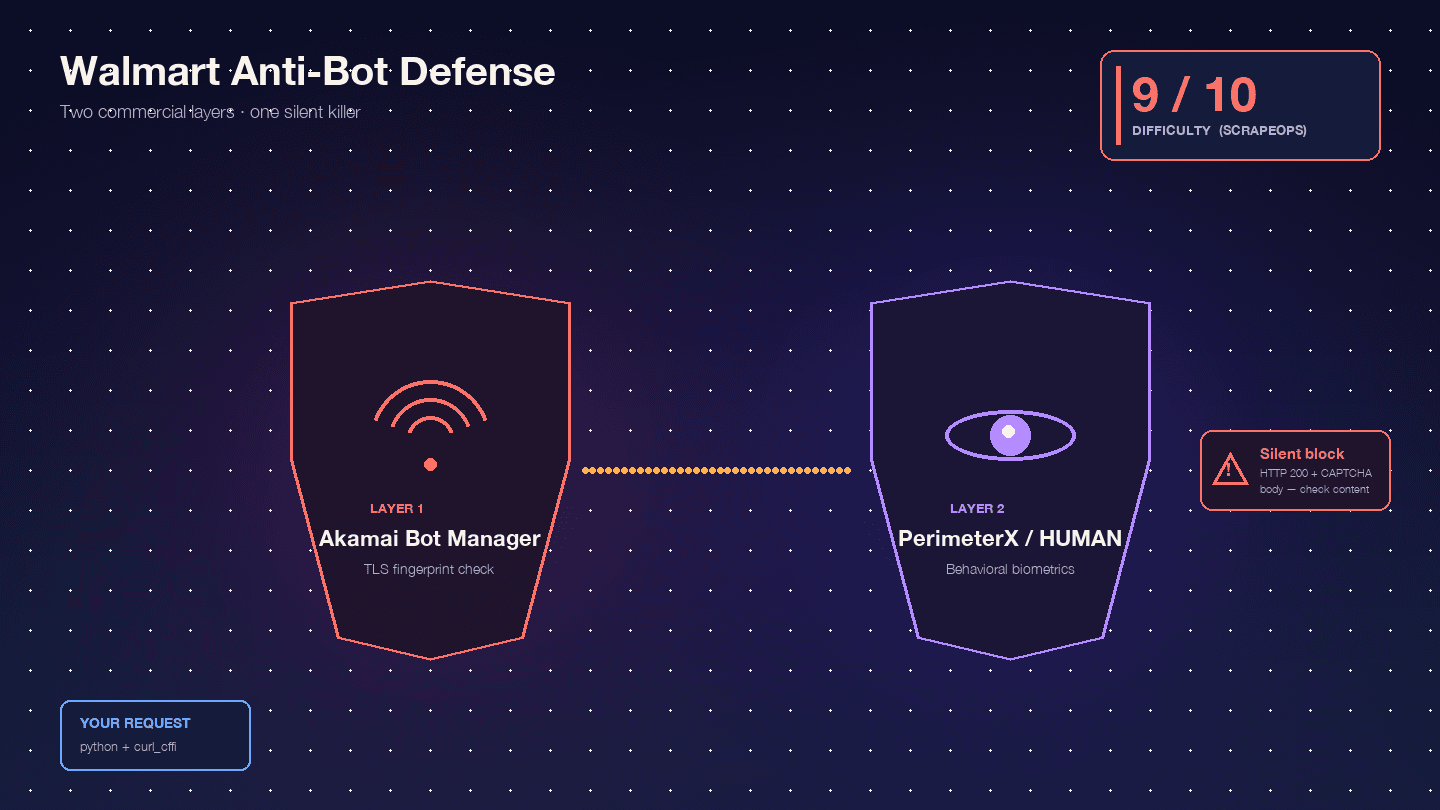
Walmart memang sengaja sulit karena menjalankan dua produk anti-bot komersial secara berurutan: sebagai lapisan WAF di edge dan fingerprinting TLS, lalu sebagai lapisan tantangan JavaScript berbasis perilaku. Scrape.do menyebut kombinasi ini "langka dan sangat sulit dilewati."
, dengan Akamai saja di angka 9/10. Dari pengalaman saya, itu cukup tepat.
Berikut sebenarnya yang harus Anda hadapi:
Akamai Bot Manager memeriksa fingerprint TLS Anda (hash JA3/JA4), urutan frame HTTP/2, urutan dan kapitalisasi header, serta cookie sesi (_abck, ak_bmsc). Panggilan Python requests standar menghasilkan fingerprint TLS yang tidak pernah diproduksi browser sungguhan — Akamai memblokirnya bahkan sebelum request Anda mencapai server Walmart.
PerimeterX/HUMAN berjalan setelah Akamai, menjalankan fingerprinting JavaScript (px.js) yang memeriksa properti navigator, rendering canvas, WebGL, konteks audio, dan biometrik perilaku (gerakan mouse, kecepatan scroll, dinamika ketikan). Kegagalan yang terlihat adalah tantangan terkenal — tombol yang harus Anda tahan sekitar 10 detik sementara sinyal perilaku dikumpulkan. Oxylabs blak-blakan: "Walmart menggunakan model CAPTCHA 'Press & Hold' yang disediakan oleh PerimeterX, yang dikenal hampir mustahil diselesaikan dari kode Anda."
Perilaku yang benar-benar berbahaya adalah blokir diam-diam. Walmart mengembalikan HTTP 200 dengan body CAPTCHA alih-alih 403. : "Walmart mengembalikan kode status 200 OK bahkan ketika menyajikan halaman CAPTCHA. Anda tidak bisa hanya mengandalkan status code untuk mengetahui apakah request berhasil." Skrip Anda dengan senang hati mem-parsing HTML CAPTCHA sebagai "produk tidak ditemukan" lalu lanjut. Setengah dataset Anda jadi sampah, dan Anda tidak menyadarinya.
Lalu ada masalah data yang bergantung pada toko. Harga dan inventaris Walmart spesifik lokasi, dikendalikan oleh cookie seperti locDataV3 dan assortmentStoreId. Tanpa cookie yang tepat, Anda mendapat data "nasional default" yang mungkin terlihat lengkap tetapi tidak cocok dengan apa yang dilihat pembeli sungguhan. Cookie yang hilang tidak menghasilkan halaman blokir — mereka menghasilkan data yang salah tanpa kegagalan yang terlihat, dan itu lebih buruk.
Tiga Metode untuk Mengekstrak Data dari Walmart (dan Perbandingannya)
Sebelum langkah demi langkah, berikut tiga pendekatan ekstraksi utama. Sebagian besar tutorial pesaing hanya membahas satu atau dua. Saya akan membahas semuanya agar Anda bisa memilih yang paling cocok untuk situasi Anda.
| Metode | Keandalan | Kelengkapan Data | Tingkat Kesulitan Anti-Bot | Beban Pemeliharaan |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ Rendah (selector berubah tiap deploy) | Sedang | Tinggi | Tinggi |
JSON __NEXT_DATA__ | ✅ Baik | Tinggi | Sedang-Tinggi | Sedang |
| Intersepsi API internal | ✅ Terbaik | Tertinggi (varian, stok, ulasan) | Sedang-Tinggi | Rendah (JSON terstruktur) |
| Thunderbit (no-code) | ✅ Baik | Tinggi | Rendah (ditangani AI) | Tidak ada |
Parsing HTML adalah pilihan terburuk untuk Walmart — situs ini mengirim bundle Next.js dengan nama class CSS yang di-hash dan berubah pada setiap deploy. Metode JSON __NEXT_DATA__ adalah pilihan pragmatis yang dipakai oleh setiap scraper Walmart open-source serius dari 2024–2026. Intersepsi API internal adalah yang paling kuat tetapi punya banyak catatan yang sering diabaikan tutorial. Dan Thunderbit adalah pilihan tepat saat Anda sama sekali tidak butuh pipeline kustom.
Menyiapkan Lingkungan Python Anda untuk Scrape Walmart
Berikut yang Anda butuhkan:
- Tingkat kesulitan: Menengah
- Waktu yang dibutuhkan: ~30 menit untuk setup, plus waktu coding
- Yang perlu disiapkan: Python 3.10+, pip, editor kode, dan (untuk penggunaan produksi) layanan proxy atau scraping API
Buat folder proyek dan virtual environment:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # Di Windows: venv\Scripts\activateInstal library yang dibutuhkan:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi adalah standar 2025 untuk scraping target yang sulit. Ini adalah binding libcurl yang bisa meniru fingerprint TLS browser secara presisi. : "Walmart menggunakan fingerprinting TLS sebagai bagian dari deteksi bot, dan bahkan mengatur User-Agent agar tampak seperti browser asli tidak akan melewatinya." requests atau httpx biasa tidak bisa lolos dari Akamai, apa pun header yang Anda set. curl_cffi dengan impersonate="chrome124" adalah pembeda utamanya.
Anda juga akan membutuhkan json (bawaan), csv (bawaan), time, random, dan logging untuk pola produksi yang akan dibahas nanti.
Langkah demi Langkah: Scrape Halaman Produk Walmart dengan Python
Langkah 1: Ambil Halaman Produk Walmart
Tugas pertama Anda adalah membuat HTTP request yang tidak langsung diblokir. Berikut set header kanonis yang dipakai di Scrapfly, Scrapingdog, Oxylabs, dan ScrapeOps pada 2024–2026:
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)Parameter impersonate="chrome124" di sini melakukan pekerjaan beratnya. Ini memberi tahu curl_cffi untuk meniru ClientHello TLS, urutan frame HTTP/2, dan urutan pseudo-header Chrome 124 secara persis. Tanpa itu, Akamai melihat hash JA3 khas Python dan memblokir Anda bahkan sebelum request mencapai lapisan aplikasi Walmart.
Seperti apa respons yang diblokir: Jika Anda melihat "Robot or human?" di judul HTML respons, atau jika respons mengarahkan ke walmart.com/blocked, Anda sudah tertangkap. Triknya adalah Walmart sering mengembalikan status 200 dengan body CAPTCHA — jadi memeriksa response.ok saja tidak cukup.
Untuk penggunaan produksi atau berulang, Anda akan membutuhkan proxy residential. IP datacenter langsung dibakar oleh sistem reputasi IP Akamai. Saya akan membahas strategi penanganan error dan proxy secara lengkap di bagian produksi di bawah.
Langkah 2: Parse Data Produk dari JSON __NEXT_DATA__
Walmart.com adalah aplikasi Next.js, dan HTML yang dirender server menyisipkan payload hydration lengkap di dalam satu tag script: <script id="__NEXT_DATA__" type="application/json">. Ini adalah tambang emasnya.
: "Pada 2026, Walmart menggunakan Next.js dengan JSON terstruktur di tag script __NEXT_DATA__, sehingga ekstraksi data tersembunyi lebih andal daripada parsing selector CSS tradisional." Setiap scraper Walmart open-source terkenal — , , — memakai metode ini.
Begini cara mengekstraknya:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})Sebagian besar tutorial berhenti di sini. Di bawah ini ada peta path JSON lengkap untuk field yang benar-benar Anda butuhkan — sudah diverifikasi pada halaman Walmart live di 2024–2026:
| Field Data | Path JSON (di bawah initialData) | Tipe | Catatan |
|---|---|---|---|
| Nama Produk | data > product > name | String | — |
| Merek | data > product > brand | String | — |
| Harga Saat Ini (angka) | data > product > priceInfo > currentPrice > price | Float | Bisa berbeda tergantung cookie toko |
| Harga Saat Ini (string) | data > product > priceInfo > currentPrice > priceString | String | Format misalnya "$9.99" |
| Deskripsi Singkat | data > product > shortDescription | String HTML | Parse dengan BeautifulSoup untuk teks |
| Deskripsi Lengkap | data > idml > longDescription | String HTML | Berada di idml, BUKAN di dalam product — ini jebakan yang sering salah di tutorial lama |
| Semua Gambar | data > product > imageInfo > allImages | Array | Daftar objek {id, url} |
| Rating Rata-rata | data > product > averageRating | Float | Kuncinya averageRating, bukan rating lama |
| Jumlah Ulasan | data > product > numberOfReviews | Integer | — |
| Varian | data > product > variantCriteria | Array | Grup opsi (ukuran, warna) |
| Ketersediaan | data > product > availabilityStatus | String | IN_STOCK, OUT_OF_STOCK, LIMITED_STOCK |
| Penjual | data > product > sellerDisplayName | String | — |
| Produsen | data > product > manufacturerName | String | — |
Path longDescription adalah jebakan yang paling sering menjebak orang. Postingan ScrapeHero tahun 2023 menaruhnya di product.longDescription, tetapi sumber 2024+ secara konsisten menaruhnya pada key saudara idml. Selalu baca idml.longDescription terlebih dahulu dan fallback ke product.longDescription untuk halaman lama.
Berikut pola ekstraksi aman dengan rantai .get():
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }Bagi pengguna yang tidak ingin repot menavigasi path JSON sama sekali, secara otomatis mengenali dan menyusun field-field ini — tanpa perlu pemetaan path manual. Anda klik "AI Suggest Fields," AI membaca halaman, dan Anda langsung mendapat tabel. Tetapi jika Anda membangun pipeline kustom, peta di atas adalah referensi Anda.
Langkah 3: Intersepsi Endpoint API Internal Walmart untuk Data yang Lebih Kaya
Tidak ada artikel pesaing yang membahas metode ini dengan benar. Ini adalah jalur ekstraksi paling kuat — dan paling rumit.
Frontend Walmart memanggil . Endpoint-nya berada di bawah www.walmart.com/orchestra/*:
/orchestra/pdp/graphql/...— hydration detail produk + perpindahan varian/orchestra/snb/graphql/...— paginasi search-n-browse/orchestra/reviews/graphql/...— ulasan berpaginasi
Ini mengembalikan JSON yang rapi dan terstruktur dengan data yang kadang dipotong oleh __NEXT_DATA__ — harga per varian, jumlah stok real-time, paginasi ulasan penuh.
Bagian yang sering dihindari posting blog: Walmart menggunakan . Body request hanya mengirim hash SHA-256 (persistedQuery.sha256Hash), bukan teks query. Kalau hash-nya tidak dikenal server, Anda akan mendapat PersistedQueryNotFound. Walmart memutar hash ini setiap deploy. Itulah sebabnya tidak ada scraper Walmart open-source populer yang mempublikasikan kode /orchestra/ yang bisa langsung di-copy-paste.
Versi praktis dan jujurnya dari metode ini adalah latihan DevTools:
- Buka halaman produk Walmart di Chrome
- Buka DevTools → tab Network, filter "Fetch/XHR"
- Jelajahi halaman seperti biasa — klik varian, scroll ke ulasan, ubah lokasi toko
- Perhatikan request ke endpoint
/orchestra/*yang mengembalikan JSON berisi data produk - Klik kanan request → "Copy as cURL"
- Ubah perintah cURL ke Python menggunakan
curl_cffi
Begini contoh panggilan API yang diputar ulang:
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# Pertama, hangatkan sesi dengan mengunjungi halaman produk
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# Lalu putar ulang panggilan API internal (disalin dari DevTools)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "your-copied-correlation-id",
14}
15payload = {
16 # Tempel body request persis dari DevTools
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "the-hash-you-copied"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()Langkah pemanasan sesi sangat penting. Cookie PerimeterX Walmart (_px3, _pxhd, ACID) harus di-set oleh fetch HTML awal sebelum panggilan API bisa berhasil. Tanpa itu, Anda akan mendapat 412 atau 403.
Kapan metode ini dipakai: Saat Anda butuh data yang tidak ada di __NEXT_DATA__ — harga varian yang lebih dalam, ulasan berpaginasi setelah batch pertama, atau jumlah inventaris real-time. Untuk sebagian besar kasus, __NEXT_DATA__ sudah cukup dan jauh lebih sederhana.
Scrape Hasil Pencarian Walmart dan Beberapa Halaman
Hasil pencarian mengikuti pola __NEXT_DATA__ yang mirip, tetapi dengan path JSON berbeda:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# Saring produk bersponsor
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))Pagination bekerja dengan menaikkan parameter page: &page=1, &page=2, dan seterusnya. Tapi ada batas tak terdokumentasi: Walmart membatasi hasil pencarian menjadi 25 halaman tanpa memandang total sebenarnya. : "Walmart menetapkan jumlah maksimum halaman hasil yang bisa diakses menjadi 25, tanpa memandang total halaman yang tersedia."
Cara mengakalinya agar cakupannya lebih dalam:
- Flip urutan sort: Jalankan kueri yang sama dengan
&sort=price_lowlalu&sort=price_highuntuk mendapat cakupan sekitar 50 halaman - Pecah rentang harga: Tambahkan
&min_price=X&max_price=Yuntuk memecah katalog menjadi jendela yang lebih kecil - Pecah per kategori: Cari dalam kategori spesifik, bukan seluruh situs
Perhatikan bahwa itemStacks adalah sebuah array. Scrapfly meng-hardcode [0] di repo mereka, tetapi halaman kategori dan browse kadang berisi beberapa stack ("Top picks," "More results"). Pola yang robust adalah mengiterasi semua stack:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # proses item
5 passHal lain yang penting: robots.txt Walmart . Halaman detail produk (/ip/...) dan sebagian besar halaman kategori (/cp/...) tidak dilarang. Jika Anda khawatir soal kepatuhan, mulailah dari halaman produk dan pohon kategori, bukan pencarian.
Jangan Biarkan Blokir Diam-Diam Merusak Data Anda: Penanganan Error Siap Produksi
Sebagian besar tutorial runtuh di sini. Mereka menunjukkan cara mengambil satu halaman, mem-parsing satu produk, lalu selesai. Di produksi, Anda akan mengambil ribuan halaman, dan Walmart aktif mencoba menghentikan Anda. Perbedaan antara scraper demo dan scraper yang benar-benar bekerja adalah cara menangani kegagalan.
Deteksi Blokir Diam-Diam Sebelum Merusak Data Anda
Fungsi paling penting dalam scraper Walmart adalah pendeteksi blokir. Berdasarkan konsensus vendor di , , , dan , Anda butuh empat pemeriksaan independen:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. Redirect ke endpoint blokir khusus
10 if "/blocked" in str(response.url):
11 return True
12 # 2. Kode status keras
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK dengan body CAPTCHA (kasus blokir diam-diam)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. Pemeriksaan kewajaran panjang respons — PDP nyata biasanya 300–900 KB
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return FalsePemeriksaan keempat — panjang respons — menangkap kasus ketika Walmart mengembalikan halaman yang dipangkas, tanpa marker CAPTCHA yang jelas tetapi juga tanpa data produk yang Anda butuhkan.
Logika Retry dengan Exponential Backoff dan Jitter
Saat request gagal, Anda tidak ingin langsung membombardir Walmart lagi. Pola standar memakai exponential backoff dengan jitter untuk menyebarkan ulang percobaan:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttled: {response.status_code}")
12 if is_walmart_blocked(response):
13 raise Exception("Silent block detected")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"Attempt {attempt + 1} failed: {e}. Mencoba lagi dalam {wait:.1f} detik")
20 time.sleep(wait)
21 return NoneJitter (random.uniform(0, 3)) bukan hiasan — itu menyinkronkan ulang worker agar armada scraper tidak retry dalam detik yang sama dan memicu detektor kecepatan Akamai.
Pembatasan Kecepatan
Baik maupun sama-sama menyarankan delay acak 3–6 detik per request untuk Walmart: "batasi request Anda dengan menunggu 3–6 detik antar pemuatan halaman dan acak waktu tunda Anda."
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return responsePada skala besar, pertimbangkan menggunakan aiolimiter untuk pembatasan kecepatan async:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 10 request per menitValidasi Data
Bahkan ketika respons tidak diblokir, data yang diparse bisa saja salah (toko salah, payload terdegradasi). Validasi sebelum menulis ke output:
1def validate_product(product):
2 """Mengembalikan True jika data produk terlihat sah."""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return TrueLogging Sesi
Lacak tingkat keberhasilan per sesi. Ketika turun di bawah 80% selama 10 menit, berarti ada yang berubah — entah IP Anda sudah terbakar, cookie kedaluwarsa, atau Walmart menerapkan aturan anti-bot baru.
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"Tingkat keberhasilan turun ke {self.success_rate:.1f}% — pertimbangkan rotasi proxy atau jeda")Tidak glamor. Tapi inilah yang menjaga data Anda tetap bersih.
Python DIY vs. Scraping API vs. No-Code: Memilih Pendekatan yang Tepat untuk Scrape Walmart
Banyak developer langsung menulis scraper kustom tanpa bertanya apakah itu keputusan yang tepat. . Pengguna forum menggambarkannya sebagai "pada dasarnya 9/10" dan bertanya apakah "API web scraping khusus akan berlebihan." Jawabannya tergantung volume, anggaran, dan kapasitas engineering.
| Faktor | Python DIY (requests + proxy) | Scraping API (Oxylabs, Bright Data, dll.) | Alat No-Code (Thunderbit) |
|---|---|---|---|
| Waktu setup ke baris pertama | Jam | 15–60 menit | ~2 menit |
| Waktu setup ke produksi | 40–80 jam | 4–16 jam | ~30 menit |
| Penanganan anti-bot | Anda yang mengelola (sulit) | Ditangani penyedia | Ditangani otomatis |
| Biaya skala kecil (<1K halaman/bulan) | Rendah (biaya proxy ~$4–8/GB) | Tier awal $40–$49/bulan | Gratis–$15/bulan |
| Biaya skala besar (100K+ halaman/bulan) | Lebih rendah per request | Lebih tinggi per request | Bervariasi |
| Kustomisasi | Kontrol penuh | Parameter API | Terbatas oleh UI/field |
| Pemeliharaan berkelanjutan | 4–8 jam/bulan | Hampir nol | Tidak ada (AI beradaptasi) |
| Paling cocok untuk | Developer yang membangun pipeline kustom | Scraping produksi skala menengah | Pengguna bisnis, ekstraksi cepat satu kali |
Kapan Python DIY Masuk Akal
DIY menang ketika Anda sudah punya kontrak proxy, butuh kontrol ketat atas header, targeting kode pos, atau cohort penjual, sedang mengindeks jutaan halaman per bulan di mana biaya API per record menumpuk, atau butuh jaminan on-prem atau kepatuhan. Komprominya adalah waktu engineering yang nyata: spider Scrapy siap produksi dengan pagination, retry, rotasi proxy, impersonasi TLS, dan schema untuk beberapa tipe halaman membutuhkan , plus 4–8 jam pemeliharaan per bulan saat Walmart memutar fingerprint.
Kapan Scraping API Menghemat Waktu Anda
Scraping API menangani lapisan anti-bot sehingga Anda tidak perlu melakukannya. menunjukkan tingkat keberhasilan dan 98% untuk Scrape.do di Walmart. Harga entry tier berada di $40–$49/bulan untuk alat seperti , , dan . Kalau Anda tim berisi 2–5 engineer dan volume scraping Anda 10K–1M halaman per bulan, API hampir selalu pilihan yang tepat. Anda menukar biaya per request dengan nol pemeliharaan.
Kapan No-Code adalah Pilihan yang Tepat
cocok untuk profil yang berbeda sepenuhnya. Kalau Anda PM, analis, atau operator e-commerce yang butuh data produk Walmart ke spreadsheet sore ini — bukan sprint berikutnya — alat no-code adalah jawaban jujurnya.
Alurnya: instal , buka halaman produk atau pencarian Walmart, klik "AI Suggest Fields," lalu AI Thunderbit membaca halaman dan menyarankan kolom (nama produk, harga, rating, dll.). Klik "Scrape," dan data masuk ke tabel. Ekspor ke Excel, Google Sheets, Airtable, atau Notion — semuanya gratis, tanpa paywall.
Thunderbit menangani anti-bot di cloud, jadi Anda tidak perlu berurusan dengan CAPTCHA, proxy, atau fingerprinting TLS. AI menyesuaikan otomatis saat layout berubah, jadi tidak ada pemeliharaan. Bagi pengguna yang sama sekali tidak ingin menavigasi path JSON, ini adalah jalan dengan hambatan paling kecil.
Keterbatasan yang jujur: Thunderbit bukan untuk 100K+ halaman per hari. Anggaran kredit dan batas cloud membuat ingest volume tinggi jadi kurang ekonomis dibanding API mentah. Anda juga tidak bisa mengunci kode pos atau ASN tertentu kecuali alatnya mendukung itu. Untuk pipeline berkelanjutan dengan volume tinggi, DIY atau scraping API tetap lebih tepat.
Perkiraan harga kasar: 1.000 baris produk Walmart di Thunderbit biayanya sekitar 2.000 kredit (~$0,60–$1,10 pada paket Starter/Pro). Itu sebanding dengan Walmart API milik Oxylabs dan lebih murah daripada kebanyakan scraping API level hobi pada volume rendah. untuk detail terbaru.
Mengekspor Data Walmart yang Sudah Di-Scrape
Setelah Anda punya datanya, Anda perlu menyimpannya di tempat yang berguna. Tiga format ini mencakup sebagian besar kebutuhan:
CSV — format paling umum yang benar-benar dibuka analis:
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Gunakan encoding utf-8-sig agar kompatibel dengan Excel. Penanda BOM mencegah Excel merusak karakter khusus.
JSONL — format produksi untuk pipeline scraping:
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(tulisan yang terputus hanya kehilangan baris terakhir), bisa di-stream dengan memori konstan, dan menjaga data bertingkat seperti varian dan ulasan tetap utuh.
Excel — untuk serah-terima singkat ke analis:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["Nama", "Harga", "Ketersediaan", "Rating", "Ulasan", "Penjual"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)Thunderbit mencakup alur ekspor untuk pengguna non-Python: ekspor sekali klik ke Google Sheets, Airtable, Notion, Excel, CSV, dan JSON — semuanya gratis di tier dasar. Untuk pemantauan berkelanjutan, fitur scheduled scraper Thunderbit bisa menjalankan ekstraksi berulang secara otomatis.
Satu catatan soal penjadwalan: . Runner GitHub Actions berada di rentang IP Azure yang langsung diblokir oleh anti-bot Walmart. Gunakan APScheduler di VPS, atau arahkan semua traffic melalui proxy residential.
Panduan Legal dan Etika untuk Scraping Walmart
Pengguna forum secara eksplisit mengutarakan kekhawatiran ini: "Saya tidak masalah bermain kucing-kucingan dengan developer, tapi ragu bermain dengan tim legal mereka."
Ketentuan Penggunaan Walmart penggunaan "robot, spider… atau perangkat manual maupun otomatis lainnya untuk mengambil, mengindeks, 'scrape,' 'data mine' atau mengumpulkan Materials apa pun" tanpa "persetujuan tertulis sebelumnya secara eksplisit."
robots.txt Walmart /search, /account, /api/, dan puluhan endpoint internal lainnya. Halaman detail produk (/ip/...) dan ulasan (/reviews/product/) tidak dilarang.
Preseden hiQ v. LinkedIn (Sirkuit ke-9, ) menetapkan bahwa scraping data yang tersedia publik kecil kemungkinan melanggar CFAA federal. Namun pengadilan yang sama kemudian memutus bahwa dan menjatuhkan terhadapnya. Putusan 2024 yang lebih baru (, ) semakin mempersempit CFAA dan membuka pembelaan preemption hak cipta, tetapi putusan-putusan itu bergantung pada bahasa ToU spesifik yang tidak sepenuhnya cocok dengan Walmart.
Pedoman praktis: Jangan membebani server. Hormati rate limit. Jangan scrape data personal atau data pengguna. Gunakan data secara bertanggung jawab. Scraping halaman produk Walmart yang publik dengan laju moderat untuk riset pribadi adalah profil risiko yang sangat berbeda dari scraping skala komersial yang melanggar ketentuan Walmart. Jika Anda membangun produk berbasis data Walmart, bicaralah dengan pengacara dan pertimbangkan .
Disclaimer: Ini adalah informasi edukatif, bukan nasihat hukum.
Kesimpulan dan Poin Penting
Scraping Walmart dengan Python adalah tantangan karena stack anti-bot ganda Akamai + PerimeterX. Bukan mustahil — tetapi Anda memerlukan alat dan pola yang tepat.
Poin penting:
- Ekstraksi JSON
__NEXT_DATA__adalah pilihan pragmatis untuk sebagian besar kasus. Ini yang dipakai semua scraper Walmart open-source serius dari 2024–2026. Path dasarnya adalahprops.pageProps.initialData.data.productuntuk PDP dansearchResult.itemStacksuntuk search/browse. curl_cffidenganimpersonate="chrome124"wajib digunakan.requestsatauhttpxbiasa tidak bisa melewati fingerprinting TLS Akamai apa pun header yang Anda set.- Blokir diam-diam adalah bahaya sebenarnya. Walmart mengembalikan 200 OK dengan body CAPTCHA. Periksa konten respons, bukan hanya status code.
- Scraper produksi butuh lebih dari kode happy-path. Exponential backoff dengan jitter, deteksi blokir dengan empat sinyal, rate limiting 3–6 detik per request, validasi data, dan pemantauan kesehatan sesi semuanya penting.
- Intersepsi API internal via
/orchestra/*kuat tetapi rapuh. Gunakan sebagai latihan DevTools untuk kebutuhan data spesifik, bukan metode ekstraksi utama. - Walmart membatasi hasil pencarian hingga 25 halaman. Perluas cakupan dengan flip urutan sort dan pemecahan rentang harga.
- Pilih pendekatan Anda secara jujur: Python DIY untuk developer dengan kebutuhan kustom dan volume tinggi. Scraping API untuk tim skala menengah tanpa engineer scraping. untuk pengguna bisnis yang ingin data masuk ke Google Sheets sore ini.
Kalau Anda ingin mencoba jalur no-code, punya tier gratis — Anda bisa scrape beberapa halaman Walmart dan melihat hasilnya sendiri. Kalau Anda memilih jalur Python, pola kode dalam artikel ini sudah teruji produksi. Apa pun pilihannya, sekarang Anda punya peta pertahanan Walmart dan tiga jalan untuk melewatinya.
Untuk info lebih lanjut tentang teknik web scraping, lihat panduan kami tentang , , dan . Anda juga bisa menonton tutorial di .
FAQ
Apakah legal melakukan scrape data produk Walmart?
Ketentuan Penggunaan Walmart melarang scraping otomatis tanpa persetujuan tertulis. Putusan hiQ v. LinkedIn dari Sirkuit ke-9 (2022) menetapkan bahwa CFAA federal kecil kemungkinan berlaku untuk scraping halaman publik, tetapi kasus yang sama berakhir dengan terhadap pihak scraper. Scraping halaman produk publik dengan laju moderat untuk riset pribadi membawa profil risiko yang sangat berbeda dibanding ekstraksi skala komersial. Konsultasikan dengan pengacara jika Anda membangun bisnis berbasis data Walmart.
Mengapa scraper Walmart saya terus diblokir?
Penyebab paling umum adalah: memakai requests atau httpx biasa (yang menghasilkan fingerprint TLS khas Python yang langsung ditandai Akamai), header yang hilang atau salah, tidak ada rotasi proxy, laju request lebih cepat dari 3–6 detik per halaman, dan cookie sesi yang hilang (_px3, _abck, locDataV3). Beralihlah ke curl_cffi dengan impersonate="chrome124", gunakan proxy residential, dan terapkan pola deteksi blokir serta retry yang dijelaskan dalam artikel ini.
Data apa yang bisa saya scrape dari Walmart dengan Python?
Nama produk, harga (current dan rollback), gambar, deskripsi singkat dan panjang, rating, jumlah ulasan, status ketersediaan stok, nama penjual, info produsen, opsi varian (ukuran, warna), dan posisi kategori. Dengan metode __NEXT_DATA__, semua ini tersedia sebagai JSON terstruktur. Intersepsi API internal juga bisa mengembalikan harga per varian, jumlah inventaris real-time, dan data ulasan berpaginasi.
Apakah saya perlu proxy untuk scrape Walmart?
Ya, untuk penggunaan produksi atau berulang. — bahkan dengan header sempurna, IP non-residential akan ditandai oleh sistem reputasi IP Akamai. Proxy residential atau mobile diperlukan. IP datacenter hampir langsung dibakar. Anggarkan sekitar $3–$17 per 1.000 halaman tergantung penyedia proxy dan tier Anda.
Bisakah saya scrape Walmart tanpa menulis kode?
Bisa. adalah ekstensi Chrome bertenaga AI yang men-scrape Walmart dalam dua klik: "AI Suggest Fields" untuk mendeteksi otomatis kolom data produk, lalu "Scrape" untuk mengekstrak datanya. Alat ini menangani tantangan anti-bot di cloud dan mengekspor langsung ke Excel, Google Sheets, Airtable, atau Notion — semuanya gratis. Ini paling cocok untuk analis, PM, dan pengguna bisnis yang butuh data cepat tanpa membangun pipeline kustom. Untuk scraping volume tinggi atau sangat kustom, Python atau scraping API tetap lebih cocok.
Pelajari Lebih Lanjut