
Redfin memperbarui setelah masuk ke sistem. Kecepatan seperti ini ibarat magnet buat siapa pun yang membangun pipeline data properti — dan itu juga alasan kenapa begitu banyak scraper mengincar Redfin lalu kena blokir dalam hitungan menit.
Saya sudah bertahun-tahun mengerjakan alat ekstraksi data di , dan saya bisa bilang: jarak antara "scrape Redfin" dan "scrape Redfin tanpa kena blokir" adalah titik di mana kebanyakan tutorial mulai gagal. Mereka nunjukin kode BeautifulSoup, lalu melewatkan bagian saat Cloudflare menghajar request Anda, dan akhirnya Anda cuma menatap halaman 403 sambil bingung apa yang salah. Panduan ini beda. Saya akan memandu Anda lewat tiga pendekatan nyata — parsing HTML, API tersembunyi Redfin, dan jalur tanpa kode dengan Thunderbit — sambil membahas serius pertahanan anti-bot yang benar-benar penting. Di akhir, Anda akan tahu metode mana yang paling cocok dengan level skill, skala kebutuhan, dan seberapa besar toleransi Anda terhadap maintenance.
Apa Itu Redfin, dan Mengapa Datanya Penting?
Redfin adalah broker properti berbasis teknologi dengan agen bergaji tetap yang menarik listing langsung dari feed MLS. Platform ini mencakup dan melayani hampir 50 juta pengunjung bulanan. Berbeda dari portal agregator murni, data Redfin diverifikasi oleh agen, dan Redfin Estimate AVM miliknya mencakup dengan median error hanya 1,96% untuk rumah yang sedang dipasarkan.
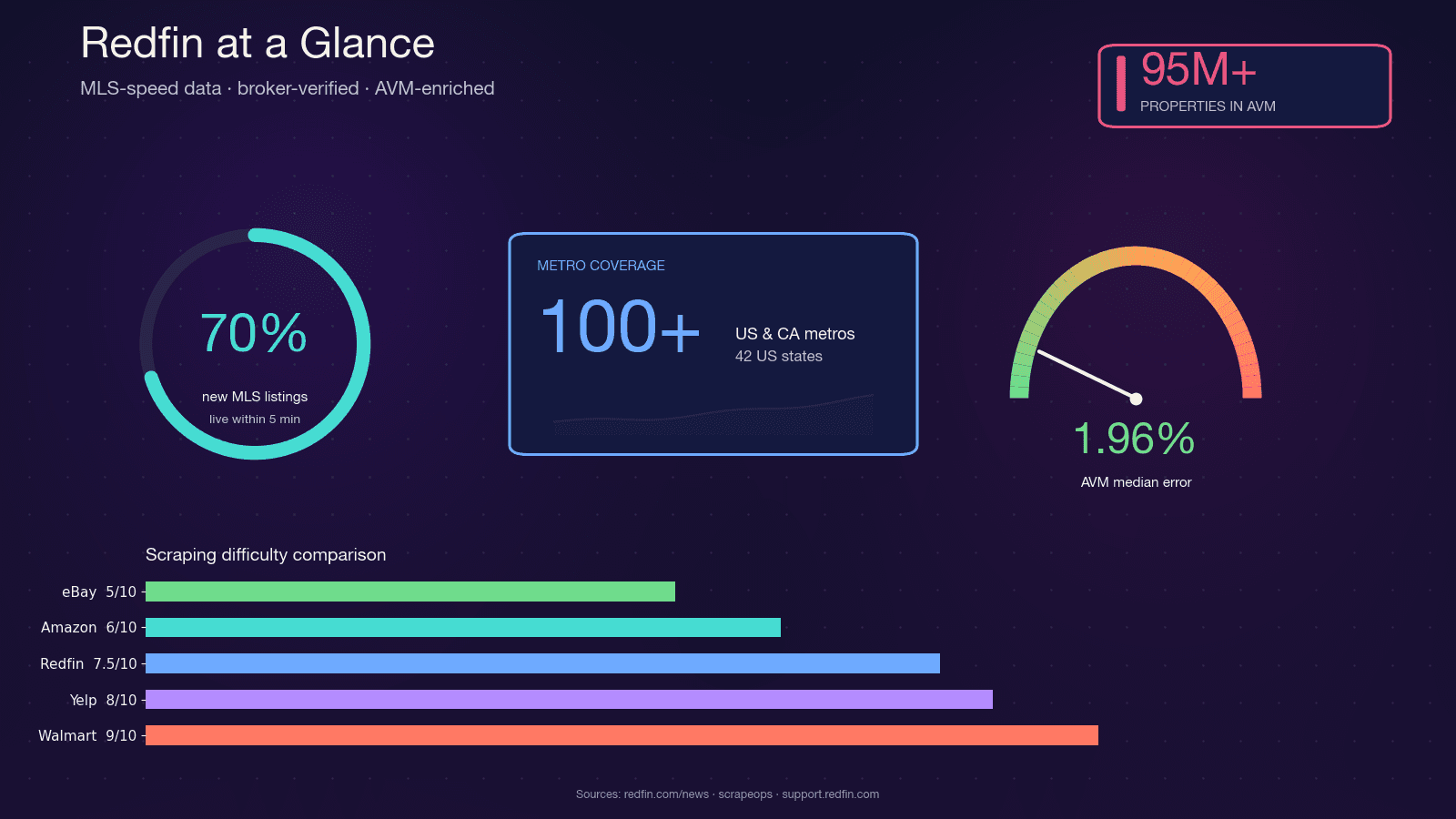
Gabungan ini — data secepat MLS, kualitas terverifikasi broker, dan AVM yang akurat — bikin investor properti, agen, startup proptech, dan analis data sama-sama butuh akses programatik ke data Redfin. Python jadi pilihan alami untuk pekerjaan ini: ekosistem scraping-nya (requests, BeautifulSoup, Selenium, Playwright) sudah matang, dukungan komunitasnya besar, dan gampang disambungkan ke pandas serta Jupyter untuk analisis.
Kenapa Scrape Redfin dengan Python?
Kasus penggunaannya cukup beragam, tergantung siapa yang butuh datanya. Berikut cara berbagai audiens biasanya memanfaatkan data Redfin hasil scraping:
| Audiens | Tujuan Scraping Utama | Contoh Penggunaan |
|---|---|---|
| Agen properti | Lead generation, intel pasar | Listing baru dan listing kedaluwarsa di area layanan; direktori agen untuk benchmarking kompetitif |
| Investor properti | Deal flow, analisis cap rate | Screening yield sewa, deteksi properti undervalued, alert listing baru harian |
| Startup proptech | Pipeline data produk | Data training AVM, dashboard pasar, mesin akuisisi iBuyer |
| Analis data | Riset pasar, BI | Tren median harga per ZIP code, time series days on market, rasio sale-to-list |
| Wholesaler / flipper | Pelacakan properti distress | Deteksi penurunan harga, foreclosure, comps off-market |
Tren yang lebih luas juga mendukung hal ini: kini memakai predictive analytics untuk mengidentifikasi peluang dan mengelola risiko. Pasar PropTech diproyeksikan mencapai dengan CAGR 16,4%. Data properti terstruktur sekarang bukan lagi bonus — itu sudah kebutuhan dasar.
Semua Field Data Redfin yang Bisa Anda Scrape (Referensi Lengkap)
Sebelum nulis satu baris kode pun, Anda perlu tahu apa saja yang benar-benar tersedia. Saya sudah mengaudit halaman hasil pencarian Redfin, halaman detail properti, dan profil agen — lalu membandingkannya dengan wrapper Stingray open-source seperti proyek dan . Totalnya ada 117 field berbeda di berbagai tipe halaman.
Tabel ini layak disimpan. Mengetahui skema data sebelum mulai coding bisa menghemat berjam-jam waktu coba-coba selector.
Field Halaman Hasil Pencarian
Ini field ringan yang tersedia di kartu listing — sering kali bisa diekstrak tanpa rendering JS penuh:
| Field | Tipe Data | Catatan |
|---|---|---|
| Property ID | Number | int internal Redfin, diambil dari /home/{id} di href |
| List price | Number | |
| Full address | Text | |
| Beds / Baths / SqFt | Number | Tiga nilai berurutan |
| Property type | Single Select | SFH, Condo, Townhouse, Multi |
| Status | Text | Active, Pending, Contingent |
| Days on market | Number | |
| Price cut indicator | Number | Selisih dari harga awal |
| Primary photo | Image URL | Satu foto per kartu |
| Hot Home badge | Boolean | |
| Open house date/time | Text | |
| Brokerage attribution | Text |
Field Halaman Detail Properti
Halaman detail adalah tempat info paling dalam berada. Banyak field ini butuh rendering JavaScript atau Stingray API:
| Field | Tipe Data | Catatan |
|---|---|---|
| Redfin Estimate (on-market) | Number | Melalui /stingray/api/home/details/avm |
| Redfin Estimate (off-market) | Number | Melalui /stingray/api/home/details/owner-estimate; median error 7,52% |
| Year built / renovated | Number | |
| Lot size | Number | |
| HOA dues | Number | Bulanan, jika ada |
| Property tax (annual) | Number | |
| Tax assessed value | Number | |
| Sale history table | Table | Harga, tanggal, jenis event |
| Property description | Text | Paragraf marketing |
| Photo URLs (carousel) | Image URLs | 20+ per listing |
| Listing agent name, phone, email | Text / Phone / Email | Nomor telepon sering disamarkan |
| School ratings (elementary/middle/high) | Number | Ditambah nama distrik |
| Walk / Transit / Bike Score | Number | |
| Climate risk scores | Number | Banjir, kebakaran, panas, angin |
| Similar active / sold / nearby homes | URLs | Data carousel |
| Parking, garage, heating, cooling | Text | Kelompok fasilitas |
Field Profil Agen
| Field | Tipe Data | Catatan |
|---|---|---|
| Agent name, photo, brokerage, bio | Text / Image | |
| Phone, contact form | Phone / Text | Klik untuk menampilkan |
| Active listings count | Number | |
| Sales last 12 months / total volume | Number | |
| Avg list-to-sale ratio | Number | |
| Star rating / review count | Number | |
| Years of experience / license # | Text / Number |
Saat Anda memakai fitur AI Suggest Fields Thunderbit di halaman Redfin, sistem ini otomatis mendeteksi sebagian besar kolom tersebut dan menetapkan tipe data yang tepat — tanpa perlu mapping CSS selector manual. Saya akan bahas lagi sebentar lagi.
Cara Kerja Pertahanan Anti-Bot Redfin (Bukan Sekadar "Pakai Proxy")
Saya mau menegaskan satu hal di sini, karena kebanyakan tutorial lewat begitu saja dari masalah blokir lalu langsung lompat ke "beli proxy dari sponsor kami." Itu tidak membantu. Kalau Anda tidak paham apa yang dilakukan Redfin untuk mendeteksi scraper, Anda cuma akan membakar kredit proxy dan tetap kena blokir. , dan — "lebih tidak agresif dibanding WAF enterprise Zillow, mengandalkan rate limiting kustom dan tantangan JavaScript."
Redfin memakai stack berlapis: Cloudflare di edge (tantangan JS, Turnstile, fingerprinting TLS/JA3) plus rate limiter di layer aplikasi khusus Redfin. Di robots.txt mereka tidak ada direktif Crawl-delay karena penegakan terjadi di level WAF.
Kenapa requests + BeautifulSoup Sederhana Gagal di Redfin
Kalau Anda mengirim requests.get() dasar ke halaman properti Redfin dengan header default, biasanya yang terjadi adalah:
- HTTP 403 — tantangan JS Cloudflare tidak berhasil diselesaikan, jadi Anda dapat halaman challenge alih-alih listing.
- Halaman challenge interstitial — body HTML berisi widget Turnstile Cloudflare, bukan data properti.
- HTTP 200 dengan HTML parsial — Anda dapat shell dengan blob JSON besar di bawah
root.__reactServerState.InitialContext, tetapi tidak ada kartu pencarian yang sudah ter-render, tidak ada riwayat harga, tidak ada penilaian sekolah.
Redfin memakai (bukan Next.js), dan hydration key-nya khas Redfin — root.__reactServerState.InitialContext dengan data listing bersarang di ReactServerAgent.cache.dataCache. Ini bukan __NEXT_DATA__ atau window.__INITIAL_STATE__.
Penyebab paling umum dari 403 diam-diam? Header Sec-Fetch-* yang hilang. Redfin/Cloudflare secara eksplisit memvalidasi Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest, dan Sec-Fetch-User. Kalau header ini tidak ada, Anda langsung ditandai.
Playbook Mitigasi: Delay, Header, Proxy, dan Session
Berikut rincian lengkap tiap pertahanan beserta strategi mitigasinya:
| Pertahanan Redfin | Fungsinya | Sinyal Deteksi | Strategi Mitigasi |
|---|---|---|---|
| Tantangan JS Cloudflare | Interstitial yang mengeluarkan cookie cf_clearance | 403 + body HTML Cloudflare | curl_cffi dengan impersonate="chrome120"; hangatkan sesi via homepage; proxy residential AS |
| Cloudflare Turnstile | CAPTCHA interaktif pada sesi berisiko tinggi | 403 + widget Turnstile | Headless browser dengan stealth + proxy residential |
| Cloudflare Error 1020 (ASN ban) | Memblokir IP/ASN yang terdeteksi | Body 403 bertuliskan "Error 1020 Access Denied" | Pindah ke proxy residential/mobile; jangan pernah pakai ASN datacenter |
| TLS/JA3 fingerprinting | Mendeteksi stack TLS non-browser | 403 diam-diam meski header sempurna | Impersonasi curl_cffi atau browser asli |
| HTTP/2 fingerprinting | Memeriksa SETTINGS HTTP/2, urutan HPACK | Blokir diam-diam | curl_cffi berbicara HTTP/2 seperti Chrome |
| Validasi header (UA, Sec-Fetch-*) | Set header yang konsisten dengan browser | 403 pada request pertama | Header Chrome lengkap termasuk Sec-Fetch-Site/Mode/Dest/User, Referer yang realistis |
| Kelangsungan cookie/session | Melacak cf_clearance, RF_BROWSER_ID | Challenge saat langsung membuka URL dalam | Persistent Session; mulai dari homepage dulu |
| Rate limit layer aplikasi | Pembatas request per IP | 429 | Delay 2–5 detik dengan jitter; exponential backoff |
| Reputasi IP datacenter | Memblokir ASN DC yang dikenal | 1020/403 instan | Hanya proxy residential AS atau mobile |
| Deteksi konkurensi | Banyak request paralel dari satu IP | Eskalasi Turnstile mendadak | Maksimal 2 concurrent per IP |
Ambang praktis dari pengujian komunitas:
- Irama aman: 1 request per 2–3 detik per IP
- Laju >20–30 req/menit secara berkelanjutan dari satu IP datacenter memicu challenge dalam hitungan menit
- Soft rate-limit biasanya hilang dalam 5–15 menit jika traffic berhenti
- Ban IP datacenter (AWS, GCP, Azure, OVH) bisa bertahan berjam-jam sampai berhari-hari
Python requests standar (urllib3 + OpenSSL) menghasilkan — dan bisa diblokir diam-diam meski header sudah benar. Solusi industri adalah curl_cffi dengan impersonate="chrome120", yang meniru TLS + HTTP/2 Chrome secara akurat.
Tiga Cara Scrape Redfin dengan Python (dan Mana yang Sebaiknya Dipilih)
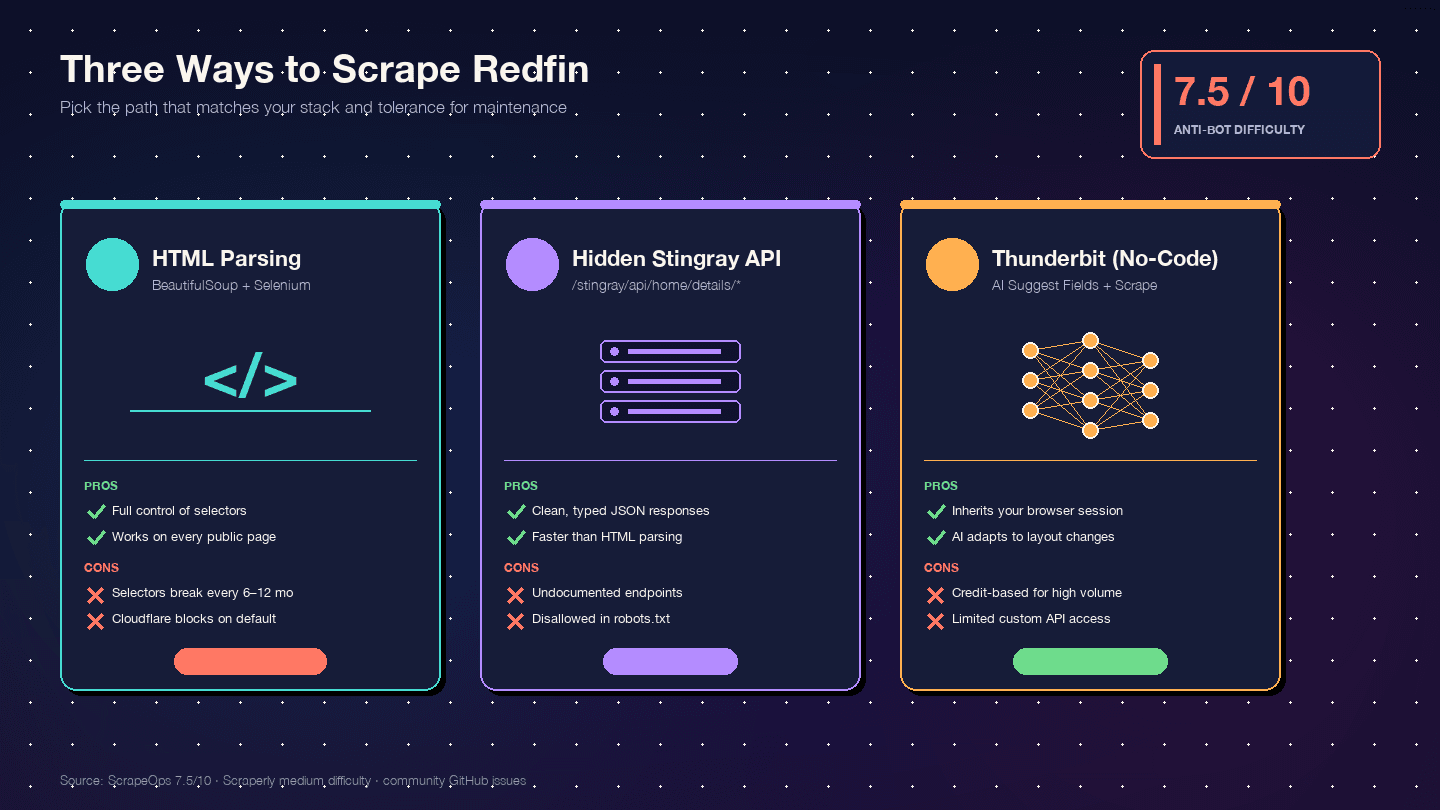
Saya belum menemukan satu pun tutorial pesaing yang membandingkan ketiga pendekatan ini berdampingan. Berikut matriks keputusannya:
| Kriteria | Parsing HTML (BS4 + Selenium) | Hidden API Stingray | Thunderbit (Tanpa Kode) |
|---|---|---|---|
| Tingkat kesulitan setup | Menengah (environment Python + browser driver) | Tinggi (reverse-engineering endpoint) | Rendah (instalasi ekstensi Chrome) |
| Risiko anti-bot | Tinggi (request DOM paling mudah terlihat) | Menengah (request mirip API terlihat lebih bersih) | Paling rendah (memakai sesi browser asli Anda) |
| Kualitas struktur data | Menengah (HTML tidak terstruktur → parsing manual) | Sangat baik (JSON sudah terstruktur) | Tinggi (AI auto-detect field + tipe data) |
| Beban maintenance | Tinggi — perubahan layout kecil bisa merusak selector | Menengah — endpoint bisa berubah tanpa pemberitahuan | Paling rendah — AI menyesuaikan perubahan layout |
| Skala | Rendah–menengah (ratusan dengan proxy) | Menengah–tinggi (ribuan, request lebih bersih) | Menengah (50 halaman/batch via cloud scraping) |
| Paling cocok untuk | Developer yang ingin kontrol penuh | Developer yang butuh JSON bersih | Non-developer, proyek cepat, data berkelanjutan tanpa sumber daya dev |
Aspek maintenance memang layak ditekankan. Redfin sudah merilis dua generasi DOM kartu — versi lama (homecardV2Price) dan versi saat ini (span.bp-Homecard__Price--value). Riwayat issue GitHub komunitas menunjukkan selector CSS biasanya rusak tiap 6–12 bulan. Saat itu terjadi, scraper BeautifulSoup bisa rusak semalam. Detektor field berbasis AI lebih mudah beradaptasi.
Sebelum Memulai
- Tingkat kesulitan: Menengah (Pendekatan 1 & 2), Pemula (Pendekatan 3)
- Waktu yang dibutuhkan: ~30 menit untuk Pendekatan 1 atau 2; ~5 menit untuk Pendekatan 3
- Yang Anda butuhkan:
- Python 3.8+ dengan pip (Pendekatan 1 & 2)
- Browser Chrome (semua pendekatan)
- (Pendekatan 3)
- Proxy residential AS untuk scraping skala besar (Pendekatan 1 & 2)
Pendekatan 1: Scrape Redfin dengan Python Menggunakan Parsing HTML (BeautifulSoup + Selenium)
Ini jalur "kontrol penuh". Anda yang nulis selector-nya, Anda yang ngurus browser-nya, Anda juga yang beresin error-nya.
Ini pendekatan yang paling edukatif. Juga yang paling rapuh.
Langkah 1: Siapkan Environment Python Anda
Buat virtual environment dan instal library yang dibutuhkan:
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # Di Windows: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cfficurl_cffi sangat penting di sini — inilah yang bikin request HTTP Anda bisa meniru fingerprint TLS Chrome asli, bukan fingerprint bawaan Python requests yang langsung diblokir Cloudflare.
Langkah 2: Konfigurasi Header Browser dan Session
Di sinilah banyak pemula kejebak. Anda perlu set header Chrome lengkap, termasuk header Sec-Fetch-* yang secara eksplisit divalidasi Redfin/Cloudflare:
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# Hangatkan sesi — ambil cookie cf_clearance dan RF_BROWSER_ID
17session.get("https://www.redfin.com/")Langkah warming session ini sangat krusial — membuka URL properti secara langsung tanpa cookie sebelumnya dan tanpa Referer akan mendapat skor rendah dari Cloudflare.
Selalu mulai dari homepage.
Langkah 3: Scrape Hasil Pencarian Redfin
Setelah sesi hangat, Anda bisa ambil halaman pencarian kota dan mem-parsing kartu listing. Selector generasi saat ini (2024–2026):
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # Halaman 1-5
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"Diblokir di halaman {page_num}: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # Delay acak 2–5 detik
28 time.sleep(random.uniform(2, 5))
29print(f"Berhasil scrape {len(listings)} listing")Anda seharusnya melihat daftar dictionary yang terus bertambah, masing-masing berisi harga listing San Francisco, alamat, beds/baths/sqft, dan URL detail. Kalau yang muncul 0 kartu, cek status HTTP — 403 berarti Cloudflare menangkap Anda, dan kemungkinan Anda butuh proxy residential.
Langkah 4: Scrape Halaman Detail Properti Satu per Satu
Hasil pencarian memberi dasar. Halaman detail memberi Redfin Estimate, year built, HOA, riwayat penjualan, info agen, dan foto. Halaman ini perlu rendering JavaScript, jadi pakai Selenium:
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # Enrich 10 listing pertama
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # Tunggu rendering JS
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()Setelah langkah ini, 10 listing pertama Anda seharusnya sudah diperkaya dengan nilai Redfin Estimate dan data year built. Selector XPath lebih tahan banting daripada CSS untuk field fasilitas bertingkat seperti ini, tapi tetap rapuh — struktur DOM apa pun yang berubah bisa merusaknya.
Langkah 5: Tangani Blokir dan Error
Implementasikan retry logic dengan exponential backoff:
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"Diblokir ({resp.status_code}). Coba lagi dalam {wait:.1f} detik...")
10 time.sleep(wait)
11 else:
12 print(f"Status tak terduga: {resp.status_code}")
13 break
14 return NoneTanda-tanda Anda diblokir: HTTP 403 dengan HTML Cloudflare di body, HTTP 429 (rate limit eksplisit), body respons kosong, atau "Error 1020 Access Denied" di konten halaman. Kalau ini terus terjadi, saatnya menambahkan proxy residential atau pindah ke pendekatan API.
Pendekatan 2: Scrape Redfin dengan Python Menggunakan Hidden Stingray API
Ini pendekatan favorit saya. Frontend Redfin berbicara ke API JSON internal di /stingray/api/home/details/*, dan responsnya datang dalam bentuk JSON yang bersih dan bertipe — tanpa perlu parsing HTML.
Cara Menemukan Endpoint Hidden API Redfin
Buka Chrome DevTools → tab Network → filter Fetch/XHR → navigasikan ke halaman properti Redfin mana pun. Anda akan melihat request ke endpoint seperti:
api/home/details/initialInfo— menyelesaikan URL → propertyId, listingIdapi/home/details/aboveTheFold— harga, beds, baths, sqft, foto, status, agen, MLS#api/home/details/belowTheFold— fasilitas, HOA, pajak, parkir, year built, lot, riwayatapi/home/details/avm— Redfin Estimate on-marketapi/home/details/owner-estimate— Redfin Estimate off-marketapi/home/details/descriptiveParagraph— deskripsi marketing
Untuk halaman rental, rentalId (UUID 36 karakter) diekstrak dari URL tag <meta property="og:image">.
Scraping Data Properti via Stingray API
Ada satu keanehan penting: respons JSON Stingray diawali string literal {}&& sebagai tindakan anti-CSRF. Anda harus menghapusnya sebelum parsing:
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# Hangatkan session
6session.get("https://www.redfin.com/")
7# Ambil halaman properti untuk mendapatkan cookie dan property ID
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Sekarang panggil Stingray API
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# Hapus prefix anti-CSRF
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# Ekstrak data terstruktur
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))Responsnya berisi field bertipe: harga sebagai integer, beds/baths sebagai angka, URL foto sebagai array, info agen sebagai objek bersarang. Tidak ada parsing BeautifulSoup, tidak ada CSS selector, tidak perlu menebak.
Kelebihan dan Keterbatasan Pendekatan Hidden API
Kelebihan:
- JSON yang sudah terstruktur — jauh lebih bersih daripada parsing HTML
- Lebih cepat per request (payload lebih kecil, tanpa overhead rendering)
- Risiko blokir lebih rendah (request mirip API dengan header yang benar terlihat lebih alami)
Keterbatasan:
- Endpoint bisa berubah tanpa pemberitahuan — tidak ada dokumentasi resmi
robots.txtsecara eksplisit melarang/stingray/untuk wildcard user-agent- Butuh reverse-engineering untuk menemukan endpoint baru
- Tetap memerlukan warming session dan header yang tepat untuk menghindari Cloudflare
Alternatif Tanpa Kode: Scrape Redfin dengan Thunderbit
Kalau Anda butuh data Redfin tapi tidak ingin memelihara script Python — atau Anda cuma ingin hasil dalam lima menit — mulai dari sini. Kami membangun memang untuk ini: ekstraksi data terstruktur dari situs apa pun, tanpa perlu kode.
Langkah 1: Instal Thunderbit dan Buka Redfin
Instal dari Chrome Web Store. Buka Redfin dan masuk ke halaman hasil pencarian — misalnya rumah dijual di San Francisco.
Langkah 2: Klik "AI Suggest Fields"
Klik ikon Thunderbit di toolbar browser, lalu klik "AI Suggest Fields." AI membaca halaman Redfin dan otomatis menyarankan kolom seperti "Address," "Price," "Beds," "Baths," "SqFt," "Property Type," dan "Listing Photo" — lengkap dengan tipe data yang benar.
Anda bisa hapus kolom yang tidak perlu atau tambah kolom kustom dengan klik "+ Add Column" dan jelaskan apa yang Anda mau dengan bahasa biasa (misalnya, "listing agent name" atau "days on market").
Anda akan melihat pratinjau tabel dengan kolom yang sudah dikonfigurasi, siap diisi.
Langkah 3: Klik "Scrape" dan Lihat Datanya Mengalir
Klik tombol "Scrape". Thunderbit memproses listing yang terlihat dan mengisi tabel Anda. Untuk hasil yang berpaginasi, sistem ini menangani pagination secara otomatis — tanpa perlu logika loop.
Dalam pengujian saya, tabel 50 baris terisi sekitar 45 detik. Datanya terstruktur, siap diekspor.
Cara Thunderbit Menangani Perlindungan Anti-Bot Redfin
Karena Thunderbit berjalan di browser Anda sendiri, ia mewarisi cookie Redfin, session, dan browser fingerprint yang sudah ada. Buat Cloudflare, ini terlihat seperti pengguna normal yang sedang browsing Redfin — karena secara teknis memang begitu. Tidak ada headless browser, tidak ada IP datacenter, tidak ada fingerprint TLS yang tidak cocok. Untuk halaman publik, mode cloud scraping Thunderbit bisa memproses 50 halaman sekaligus.
Itu pendekatan yang secara fundamental berbeda dibanding mengirim requests dari script Python di server.
Sesi browser Anda sudah dipercaya.
Scrape Subhalaman Redfin dengan Thunderbit
Setelah hasil pencarian di-scrape, klik "Scrape Subpages" agar AI mengunjungi setiap URL detail properti dan memperkaya tabel Anda dengan field tambahan — Redfin Estimate, year built, HOA dues, info agen, foto properti, dan riwayat penjualan.
Itu setara dengan loop Selenium 40 baris dari Pendekatan 1 — hanya saja cukup satu klik dan tanpa maintenance.
Saat Redfin mengubah DOM dari homecardV2Price menjadi span.bp-Homecard__Price--value, AI menyesuaikan. Selector Python Anda tidak.
Lebih dari CSV: Ekspor Data Redfin ke Google Sheets, Airtable, dan Notion
Kebanyakan tutorial berhenti di df.to_csv(). Itu oke buat analisis sesekali. Tapi kalau Anda kerja dalam tim properti, Anda butuh data yang kolaboratif dan hidup — bukan file statis yang numpuk di desktop seseorang.
Ekspor dengan Python (gspread + Airtable API)
Google Sheets via gspread:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# Tampilkan foto properti inline lewat formula IMAGE()
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')Perlu diingat: Sheets punya batas keras 10 juta sel per spreadsheet, dan API-nya membatasi . Pakai ws.batch_update() alih-alih loop per sel kalau datanya lebih dari beberapa puluh baris.
Airtable via pyairtable:
Perubahan penting di 2024: Airtable . Sekarang Anda harus pakai Personal Access Token (PAT) — tutorial apa pun yang masih menampilkan api_key=... sudah tidak berlaku.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable mengambil & meng-host ulang
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)Batas rate limit Airtable adalah , dengan lockout 30 detik kalau dilanggar. Field attachment menerima payload [{"url": ...}] — server Airtable akan mengambil URL itu, meng-host ulang di CDN mereka, dan membuat thumbnail otomatis.
Ekspor dengan Thunderbit (1-Klik ke Sheets, Airtable, Notion)
Thunderbit punya ekspor 1-klik bawaan ke Google Sheets, Airtable, dan Notion — dan bagian ini memang saya banggakan: foto properti akan diunggah dan ditampilkan sebagai gambar inline di Notion dan Airtable. Tidak perlu trik formula =IMAGE(), tidak ada link CDN yang putus. Anda klik "Export to Airtable," lalu tim Anda dapat database properti visual dengan thumbnail yang bisa mereka lihat di ponsel.
Bagi tim properti yang melakukan triase listing secara visual, ini beda antara alat yang benar-benar berguna dan sekadar tumpukan baris CSV.
Apakah Legal Scrape Redfin? Apa Kata ToS, robots.txt, dan Preseden Hukum?
Saya bukan pengacara, dan ini bukan nasihat hukum. Tapi setelah bertahun-tahun di dunia ekstraksi data, saya bisa bilang: "apakah ini legal?" adalah pertanyaan yang semua orang tanya dan kebanyakan tutorial hindari.
robots.txt Redfin
Redfin sangat detail. Poin penting:
- Bot yang diblokir total:
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent— Redfin secara spesifik menyebut layanan scraping era LLM yang populer - Sorotan
User-agent: *denganDisallow:/stingray/(seluruh namespace API internal),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - Tidak ada direktif
Crawl-delay:untuk user agent apa pun - 50+ sitemap dideklarasikan — sitemap adalah cara paling bersih dan paling ringan WAF untuk menelusuri URL
Terms of Use Redfin
menyatakan: "You may not automatedly crawl or query the Services for any purpose or by any means... unless you have received prior express written permission."
Ini adalah perjanjian browsewrap — penerimaan lewat penggunaan berkelanjutan, bukan clickwrap. Pengadilan AS secara historis skeptis terhadap penegakan browsewrap terhadap pengguna yang tidak punya pemberitahuan nyata (lihat Nguyen v. Barnes & Noble, 9th Cir. 2014).
Preseden Hukum yang Relevan (Singkat)
- Van Buren v. United States (Mahkamah Agung, 2021): klausul CFAA "exceeds authorized access" memakai tes "gates-up-or-down". Menggunakan pintu yang terbuka untuk tujuan yang tidak diinginkan bukan berarti hacking federal.
- hiQ Labs v. LinkedIn (9th Cir., 2022): scraping data yang tersedia publik bukan pelanggaran CFAA. Namun hiQ akhirnya membayar $500.000 dalam penyelesaian atas dasar pelanggaran kontrak — karena hiQ pernah mendaftar akun LinkedIn dan mengeklik "I agree."
- Meta Platforms v. Bright Data (N.D. Cal., Jan. 2024): pengadilan memberi summary judgment untuk Bright Data — scraping data publik saat logged-off tidak menjadikan Bright Data "user" yang terikat ToS Meta.
- X Corp. v. Bright Data (N.D. Cal., Mei 2024): Hakim Alsup menolak klaim X, dengan menyatakan bahwa klaim hukum negara bagian yang mencoba mengontrol penyalinan konten publik dikesampingkan oleh Copyright Act.
Panduan Praktis
- Scrape hanya data yang bisa diakses publik — jangan pernah bikin akun lalu melakukan scraping (itu menimbulkan risiko kontrak clickwrap)
- Hormati rate limit — volume agresif bisa mendukung klaim trespass-to-chattels
- Jangan republish data mentah atau foto dalam skala besar — gugatan (diajukan Juli 2025, potensi ganti rugi lebih dari $1 miliar) mengingatkan bahwa hak cipta foto itu serius
- Pendekatan browser-based Thunderbit — berjalan di sesi autentikasi Anda sendiri — lebih mirip "browsing manual dengan kecepatan mesin" daripada bot datacenter headless, dan itu adalah posture yang paling defensible selain API berlisensi
Tips dan Jebakan Umum
Beberapa pelajaran berharga dari membangun alat ekstraksi dan melihat ribuan pengguna scraping situs properti:
- Selalu hangatkan session Anda. Buka
redfin.com/dulu sebelum URL dalam apa pun. Menembak URL dalam secara langsung adalah pemicu nomor satu untuk tantangan Cloudflare. - Rotasi User-Agent secara realistis. Jangan cuma pakai satu — rotasikan 5–10 UA Chrome/Firefox terbaru. Tapi jangan terlalu agresif juga (UA beda setiap request justru terlihat mencurigakan).
- Dedup berdasarkan property ID. Pagination Redfin kadang saling tumpang tindih. Ambil
/home/{id}dari setiap URL listing dan dedup sebelum enrichment. - Kalau bisa, hindari jam sibuk. Dari pengalaman saya, larut malam / dini hari waktu AS mendapat pengawasan WAF yang lebih longgar.
- Kalau kena 429, mundur secara eksponensial. Jangan retry langsung — itulah cara Anda naik kelas dari soft rate-limit ke hard IP ban.
- Untuk proyek skala besar (1.000+ halaman), siapkan budget untuk proxy residential. IP datacenter (AWS, GCP, Azure, OVH) diblacklist oleh sistem reputasi ASN Cloudflare. Anda hampir pasti kena Error 1020.
Memilih Cara yang Tepat untuk Scrape Redfin
Jadi, pendekatan mana yang sebaiknya Anda pilih? Tergantung siapa Anda dan apa yang Anda butuhkan.
Parsing HTML (BeautifulSoup + Selenium): Paling cocok untuk developer yang ingin kontrol penuh, nyaman memelihara CSS selector, dan tidak keberatan membangun ulang saat Redfin mengubah DOM. Siapkan diri untuk meninjau ulang kode Anda setiap 6–12 bulan.
Hidden Stingray API: Paling cocok untuk developer yang butuh JSON terstruktur yang bersih dan sanggup melakukan reverse-engineering endpoint yang tidak terdokumentasi. Maintenance-nya lebih ringan daripada parsing HTML, tetapi endpoint bisa berubah tanpa pemberitahuan. Ingat bahwa /stingray/ secara eksplisit dilarang di robots.txt.
Thunderbit (Tanpa Kode): Paling cocok untuk non-developer, proyek cepat, dan tim yang butuh data Redfin berkelanjutan tanpa sumber daya developer. AI menyesuaikan perubahan layout, scraping subhalaman memperkaya data hanya dengan satu klik, dan ekspor ke , Airtable, atau Notion sudah tersedia bawaan. Kalau Anda tim properti yang butuh database properti yang hidup — bukan dump CSV sekali pakai — inilah jalur paling gampang.
Apa pun jalur yang Anda pilih: pahami dulu pertahanan anti-bot Redfin sebelum mulai, tahu field apa yang Anda butuh, pilih format ekspor yang cocok dengan alur kerja tim Anda, dan tetap berada di sisi yang aman dari .
Siap coba jalur tanpa kode? memungkinkan Anda bereksperimen dengan scraping Redfin dan melihat hasilnya dalam hitungan menit. Untuk pendekatan Python, cuplikan kode di atas sudah jadi titik awal yang bisa langsung dipakai — tinggal tambahkan proxy dan kesabaran.
FAQ
Apakah Redfin punya API publik?
Tidak. Redfin tidak menyediakan API publik resmi. Hidden Stingray API (/stingray/api/home/details/*) mengembalikan JSON terstruktur dan dipakai oleh frontend Redfin sendiri, tetapi sifatnya tidak resmi, tidak terdokumentasi, bisa berubah tanpa pemberitahuan, dan secara eksplisit dilarang di robots.txt Redfin. Wrapper open-source seperti di PyPI menyediakan akses Python, tetapi gunakan dengan memahami risikonya.
Bisakah saya scrape Redfin tanpa Python?
Bisa. adalah ekstensi Chrome berbasis AI yang mewarisi session browser Anda untuk ketahanan anti-bot — instal, buka Redfin, klik "AI Suggest Fields," lalu ekspor ke Excel, Google Sheets, Airtable, atau Notion. Ada juga alat scraping tanpa kode lain dan penyedia dataset siap pakai di pasar kalau Anda mau menjajaki alternatif.
Seberapa sering Redfin mengubah layout websitenya?
Riwayat issue GitHub komunitas menunjukkan selector CSS biasanya rusak sekitar setiap 6–12 bulan. Redfin sudah merilis dua generasi DOM kartu — versi lama (homecardV2Price, homeAddressV2) dan versi saat ini (bp-Homecard__Price--value, bp-Homecard__Address). Scraper yang matang biasanya mencoba keduanya secara berurutan.
Alat berbasis AI seperti Thunderbit karena mereka mendeteksi field berdasarkan konten, bukan CSS selector.
Jenis proxy terbaik untuk scraping Redfin apa?
Proxy residential AS untuk scraping skala besar — benchmark komunitas menempatkan tingkat keberhasilan sekitar 80%. Proxy datacenter hampir langsung kena Cloudflare Error 1020; rentang IP AWS, GCP, Azure, dan OVH sudah diblacklist. Proxy mobile punya tingkat keberhasilan tertinggi, tetapi biayanya 5–10x lebih mahal.
Untuk scraping pribadi skala kecil (<100 halaman), header yang benar + impersonasi curl_cffi + delay 2–5 detik mungkin bisa jalan tanpa proxy sama sekali.
Bisakah saya scrape data properti sold atau off-market dari Redfin?
Bisa. Data properti sold dan Redfin Estimate off-market (median error ) tersedia di halaman detail menggunakan pendekatan scraping yang sama. Field-nya beda dari listing aktif: halaman off-market menampilkan harga jual, tanggal jual, riwayat properti, dan endpoint owner-estimate, tetapi tidak punya list price saat ini, days on market, dan info open house. Endpoint Stingray API untuk estimasi off-market adalah api/home/details/owner-estimate, bukan api/home/details/avm.
Pelajari Lebih Lanjut