
Craigslist masih menarik sekitar di ~700 situs lokal — dan sampai sekarang belum punya API publik. Kalau Anda butuh data terstruktur dari listing apartemen, mobil bekas, lowongan kerja, atau iklan jasa, web scraping pada dasarnya jadi satu-satunya jalan.
Namun, sistem anti-bot kustom Craigslist terkenal sangat ketat. Mereka tidak memakai Cloudflare atau DataDome — melainkan rate limiter berbasis nginx buatan sendiri yang sudah disempurnakan lebih dari satu dekade. Salah langkah sedikit saja, Anda bisa langsung kena 403 bahkan sebelum kopi kedua habis. Saya sudah menghabiskan banyak waktu menguji berbagai pendekatan terhadap pertahanan Craigslist, dan panduan ini adalah hasilnya: tutorial Python yang relevan untuk 2025, bisa dipakai di semua kategori, membahas metode ekstraksi JSON-LD (peningkatan terbesar dibanding panduan lama), strategi anti-ban yang realistis, aspek legal, serta alternatif no-code bagi siapa pun yang hanya ingin datanya tanpa menulis satu baris kode pun.
Apa Arti Scrape Craigslist dengan Python?
Web scraping Craigslist berarti memakai skrip Python untuk mengunjungi halaman Craigslist secara otomatis, mengekstrak data terstruktur yang Anda butuhkan — seperti judul, harga, deskripsi, gambar, lokasi, tanggal posting — lalu menyimpannya ke spreadsheet, database, atau file JSON.
Python jadi pilihan utama karena ekosistem library-nya sangat matang. Dengan requests, BeautifulSoup, lxml, dan curl_cffi, Anda bisa membuat scraper Craigslist yang berfungsi dalam kurang dari 100 baris kode. Komunitasnya juga sangat besar, jadi ketika Craigslist mengubah sesuatu (dan itu sering terjadi), biasanya sudah ada yang menemukan solusinya.
Hal penting yang perlu dipahami: Craigslist . Satu-satunya interface programatik resmi adalah Bulk Posting Interface (BAPI), dan itu sifatnya write-only — hanya untuk pengiklan berbayar yang disetujui agar bisa mengirim listing, bukan mengambil data. Jadi, setiap produk bertajuk “Craigslist API” yang Anda lihat di platform pihak ketiga sebenarnya hanyalah scraper tidak resmi, bukan endpoint yang disahkan. Kalau ingin data dalam jumlah besar, Anda perlu scraping.
Kenapa Scrape Craigslist? Contoh Penggunaan Nyata
Craigslist bukan sekadar tempat cari sofa bekas. Ini adalah dataset besar yang terus diperbarui di puluhan kategori. Berikut siapa saja yang benar-benar diuntungkan dari scraping Craigslist:
| Use Case | Who Benefits | What You Extract |
|---|---|---|
| Pemantauan harga apartemen & sewa | Agen properti, penyewa, perusahaan PropTech | Harga, luas, jumlah kamar, lingkungan, lintang/bujur |
| Analisis pasar mobil bekas | Dealer, aplikasi konsumen, peneliti | Harga, merek, model, tahun, odometer, kondisi |
| Riset pasar kerja | Rekruter, ekonom tenaga kerja, analis workforce | Judul, kompensasi, jenis pekerjaan, tanggal posting |
| Lead generation | Tim sales, penyedia layanan | Info kontak, nama bisnis, area layanan |
| Penetapan harga kompetitif | Penyedia layanan lokal, operasional ecommerce | Harga layanan, deskripsi, area yang dilayani |
Contoh akademik yang paling sering dikutip adalah — sekitar 500.000 listing mobil bekas di AS dengan 26 variabel, yang menjadi basis puluhan makalah, termasuk studi ResearchGate 2024 tentang dinamika pasar mobil bekas di AS. Beberapa hedge fund juga membeli data sewa Craigslist yang sudah diagregasi untuk riset tren harga sewa. Sementara itu, tim sales rutin scraping kategori services dan gigs untuk lead generation.
Matematikanya sederhana: 8 jam copy-paste manual versus kira-kira 10 menit dengan scraper yang dibangun dengan baik.
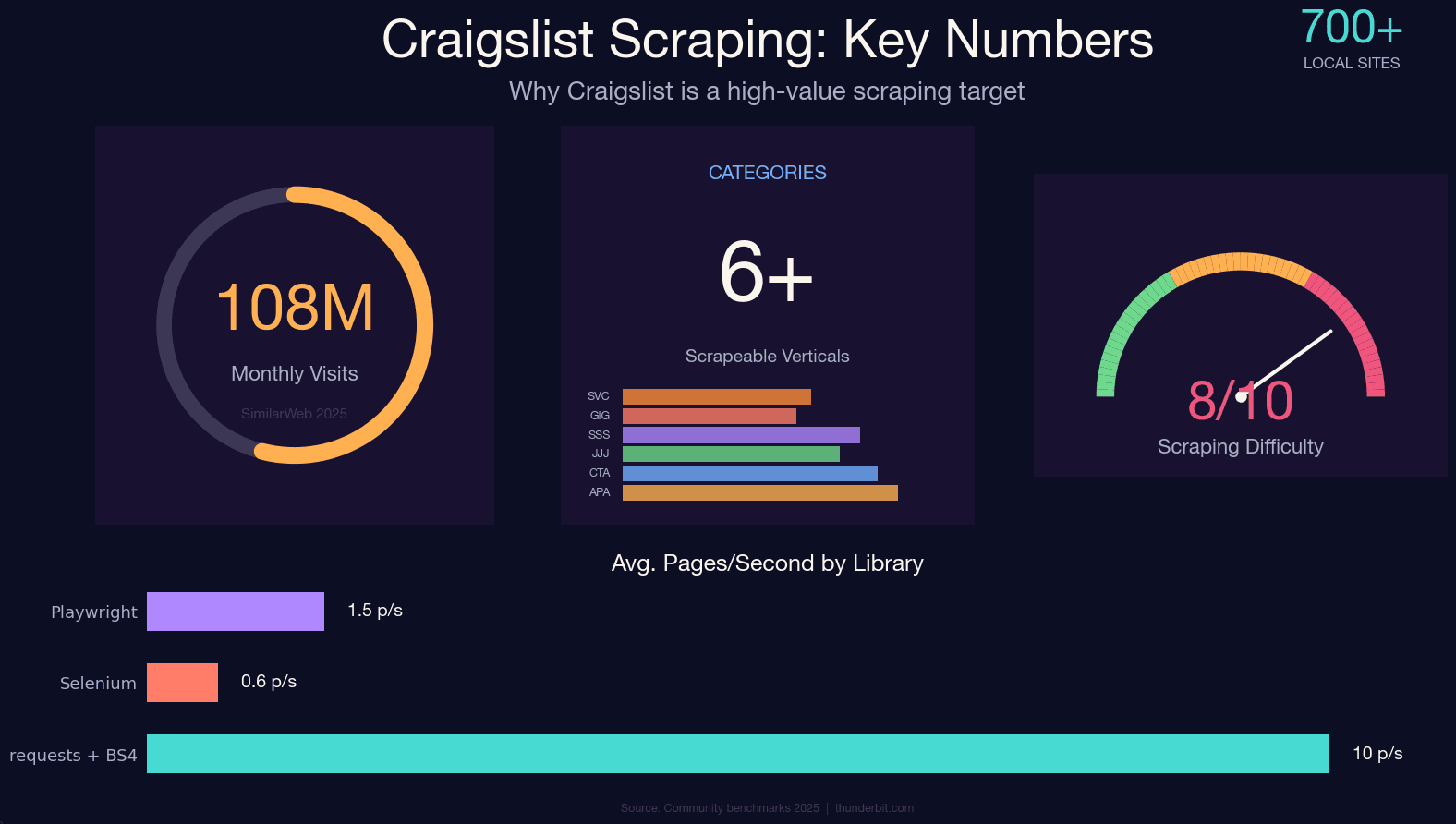
Scrape Craigslist dengan Python: Semua Kategori, Bukan Hanya Mobil
Hampir semua panduan scraping Craigslist yang saya temukan hanya membahas cars-for-sale — seperti menulis tutorial Google yang cuma mengulas pencarian gambar. Craigslist punya puluhan kategori, dan pola URL-nya berbeda untuk masing-masing.
Strukturnya selalu seperti ini: https://{city}.craigslist.org/search/{category_slug}
Ganti subdomain kota dan slug-nya, maka Anda sedang scraping vertikal yang sama sekali berbeda. Berikut tabel referensi kategori paling populer (terverifikasi April 2025):
| Category | URL Slug | Typical Fields to Extract |
|---|---|---|
| Apartemen / Hunian | /search/apa | Harga, luas, kamar tidur, lokasi, aturan hewan peliharaan |
| Mobil & Truk | /search/cta | Harga, merek, model, tahun, odometer |
| Pekerjaan | /search/jjj | Judul, perusahaan, gaji, jenis pekerjaan |
| Layanan | /search/bbb | Judul, deskripsi, nomor telepon, area |
| Gig | /search/ggg | Judul, kompensasi, tanggal, kategori |
| Dijual (umum) | /search/sss | Judul, harga, kondisi, lokasi |
Anda juga bisa menambahkan parameter query untuk filter:
| Parameter | Purpose | Example |
|---|---|---|
query | Kata kunci full-text | ?query=studio |
min_price / max_price | Rentang harga | &min_price=1500&max_price=3000 |
hasPic | Hanya postingan dengan gambar | &hasPic=1 |
postedToday | 24 jam terakhir | &postedToday=1 |
sort | Urutan hasil | &sort=priceasc |
s | Offset pagination (120 per halaman) | ?s=120 |
Jadi URL seperti https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 akan memberi Anda apartemen New York dengan harga antara $1.500 dan $3.000 yang memiliki foto. Semua scraper Python di panduan ini bisa dipakai di semua kategori tersebut — cukup ganti slug-nya.
Selector HTML Craigslist 2025: Lama vs. Baru (dan Shortcut JSON)
Alasan nomor satu scraper Craigslist sering rusak adalah perubahan struktur HTML. Kalau Anda mengikuti tutorial 2022 yang menyuruh menarget .result-row atau .result-info, scraper Anda kemungkinan sudah tidak berguna.
Craigslist menulis ulang markup hasil pencarian pada 2023–2024. Class lama masih ada di dalam wrapper baru, tetapi kalau Anda menargetnya di level atas DOM, hasilnya kosong. Ini yang berubah:
| Element | Legacy Selector (pre-2024) | Current Selector (2025) |
|---|---|---|
| Kontainer listing | .result-info | .cl-search-result |
| Link judul | .result-title | .posting-title a |
| Harga | .result-price | .priceinfo |
| Metadata (area) | .result-hood | .meta |
Tapi inilah insight yang paling penting — dan yang membedakan scraper yang benar-benar relevan di 2025 dari yang lain: Anda tidak perlu parsing HTML sama sekali untuk hasil pencarian.
Craigslist kini menyematkan setiap listing yang tampil ke dalam tag <script id="ld_searchpage_results"> sebagai data terstruktur JSON-LD. Satu panggilan requests.get() sudah mengembalikan schema.org ItemList lengkap untuk semua listing di halaman itu — judul, harga, mata uang, lokasi, URL gambar, tautan halaman detail. Tidak perlu rendering JavaScript. Tidak ada fragility pada CSS selector.
Pendekatan JSON-LD lebih cepat, lebih stabil, dan jauh lebih kecil kemungkinan rusak saat Craigslist mengubah UI. Inilah yang dipakai hampir semua repo GitHub yang masih aktif, dan juga yang akan kita pakai di tutorial di bawah.
Satu catatan: blok JSON-LD ini — apartemen (apa), dijual (sss), mobil (cta), hunian (hhh). Pada kategori pekerjaan (jjj), gig (ggg), komunitas (ccc), dan layanan (bbb), blok ini sering tidak ada atau sangat terbatas karena listing-nya tidak punya pricing schema.org/Offer. Untuk kategori tersebut, gunakan jalur HTML .cl-search-result sebagai fallback.
Memilih Stack Python Anda: Requests + BS4 vs. Selenium vs. Playwright
Ini pertanyaan yang selalu muncul di forum scraping: "Library mana yang harus saya pakai?" Untuk Craigslist, jawabannya jauh lebih jelas dibanding banyak situs lain.
| Factor | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| Kecepatan | 5–15 halaman/detik (terbatas jaringan) | 0,3–1 halaman/detik | 0,5–2 halaman/detik |
| Konten hasil render JS | Tidak | Ya | Ya |
| Memori | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| Kompleksitas setup | Rendah | Sedang | Sedang |
| Ketahanan anti-bot | Rendah (butuh headers/proxy) | Sedang (browser asli) | Sedang-Tinggi |
| Use case Craigslist terbaik | Hasil pencarian (JSON-LD) | Halaman detail dengan konten dinamis | Scraping async skala besar |
| Kurva belajar | Ramah pemula | Menengah | Menengah |
Halaman Craigslist dirender di server. Blok JSON-LD sudah ada di HTML awal. Tidak ada tantangan JavaScript pada path baca. Setiap memakai requests + BeautifulSoup atau Scrapy. Tidak ada Selenium atau Playwright. Itu bukan kebetulan — framework otomasi browser menambah ratusan MB memori, memperlambat 10–100x, dan meninggalkan jejak fingerprint yang lebih mudah dikenali tanpa memberi manfaat berarti.
Rekomendasi saya:
- requests + BS4: Mulailah dari sini. Sangat cocok dengan metode ekstraksi JSON-LD dan mencakup 95% kebutuhan scraping Craigslist.
- Selenium: Hanya jika Anda perlu berinteraksi dengan konten dinamis di halaman detail tertentu (jarang di Craigslist).
- Playwright: Jika Anda menskalakan ke ribuan halaman dengan concurrency async — meskipun jujur, bottleneck-nya tetap rate limiter Craigslist, bukan throughput library Anda.
Kami juga sudah membahas perbandingan dan rangkuman di posting terpisah kalau Anda ingin pembahasan lengkapnya.
Alternatif No-Code: Scrape Craigslist Tanpa Menulis Python
Sedikit belok sebelum masuk ke kode — bagian ini untuk siapa pun yang bukan developer. Agen properti, tim sales, manajer operasional — kalau Anda cuma butuh datanya dan tidak ingin menulis Python, ada cara yang lebih cepat.
adalah AI web scraper yang bekerja sebagai ekstensi Chrome. Dengan sekitar 2 klik, Anda sudah bisa scrape Craigslist tanpa kode sama sekali. Alurnya seperti ini:
- Buka halaman hasil pencarian Craigslist mana pun (apartemen, mobil, pekerjaan — kategori apa pun).
- Klik "AI Suggest Fields" di sidebar Thunderbit. AI akan membaca halaman dan otomatis mengenali kolom seperti judul listing, harga, lokasi, dan link.
- Klik "Scrape" — data akan diekstrak dalam hitungan detik.
- Gunakan Subpage Scraping untuk membuka halaman detail tiap listing dan memperkaya data dengan deskripsi lengkap, nomor telepon, gambar, dan atribut lain.
- Ekspor langsung ke Google Sheets, Excel, Airtable, atau Notion — gratis sepenuhnya.
Untuk kebutuhan berulang — misalnya pemantauan harga apartemen harian atau snapshot listing pekerjaan mingguan — Scheduled Scraper Thunderbit memungkinkan Anda mendeskripsikan jadwal dalam bahasa biasa, lalu sistem akan berjalan otomatis. Tanpa cron job, tanpa setup server.
Thunderbit juga menangani perlindungan anti-bot lewat mode Cloud Scraping, jadi Anda tidak perlu repot mengatur rotating proxy atau menyusun headers secara manual. Kalau ingin mencobanya, unduh dan lihat sendiri.
Kalau Anda ingin kontrol penuh dan kustomisasi, lanjutkan membaca langkah demi langkah dengan Python.
Langkah demi Langkah: Cara Scrape Craigslist dengan Python (Tutorial Lengkap)
- Tingkat kesulitan: Menengah
- Waktu yang dibutuhkan: ~30 menit (setup + scraping pertama)
- Yang Anda perlukan: Python 3.8+, browser Chrome (untuk inspeksi halaman), terminal
Langkah 1: Siapkan Lingkungan Python Anda
Install library yang dibutuhkan:
1pip install requests beautifulsoup4 lxmllxml opsional, tetapi mempercepat parsing BeautifulSoup cukup signifikan. Jika nanti Anda mengalami masalah TLS fingerprinting (lebih lanjut di bagian anti-ban), Anda juga bisa memasang curl_cffi:
1pip install curl_cffiBlok import Anda:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomSekarang Anda punya lingkungan Python yang bersih dengan semua dependency terpasang.
Langkah 2: Bangun URL Craigslist untuk Kategori Apa Pun
Buat URL target secara dinamis menggunakan city + category slug + filter opsional:
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# Contoh: apartemen New York, $1500-$3000, dengan foto
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1Ganti "apa" dengan "cta" (mobil), "jjj" (pekerjaan), "bbb" (layanan), atau slug lain dari tabel kategori di atas. Ganti "newyork" dengan "sfbay", "chicago", "losangeles", dan seterusnya.
Langkah 3: Ambil Halaman dan Ekstrak JSON Tertanam
Kirim request GET dengan headers yang sesuai, lalu parsing blok JSON-LD:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}Jika tag bernilai None, blok JSON-LD tidak tersedia untuk kategori tersebut — gunakan parsing HTML sebagai fallback (lihat tabel selector di atas). Untuk apartemen, mobil, dan kategori dijual, blok JSON-LD biasanya selalu ada.
Langkah 4: Parsing Data Listing Menjadi Record Terstruktur
Iterasi item JSON dan ekstrak field yang Anda butuhkan:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Ditemukan {len(listings)} listing")Anda seharusnya melihat sesuatu seperti "Ditemukan 120 listing" (Craigslist menampilkan 120 hasil per halaman). Beberapa listing mungkin bernilai None pada price jika pemasang tidak mencantumkan harga — tangani ini dengan aman di logika lanjutan Anda.
Langkah 5: Scrape Halaman Detail untuk Data yang Lebih Kaya
Hasil pencarian hanya memberi informasi ringkas. Untuk deskripsi lengkap, atribut (jumlah kamar tidur, luas, aturan hewan peliharaan), koordinat lintang/bujur, dan gambar, Anda perlu mengunjungi URL detail tiap listing.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # penting: jitter anti-bantime.sleep(random.uniform(3, 6)) bukan opsional. Jika dilewati, Anda kemungkinan akan kena 403 dalam beberapa lusin request. Halaman detail dirender di server dengan selector yang stabil (#titletextonly, #postingbody, #map) dan nyaris tidak berubah sejak sekitar 2017 — salah satu hal langka dari Craigslist yang benar-benar konsisten.
Langkah 6: Tangani Pagination untuk Mengambil Semua Hasil
Craigslist memakai parameter offset ?s=120 untuk pagination. Setiap halaman menampilkan 120 hasil, dan offset maksimum biasanya 2999.
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))Jangan mencoba scraping ribuan halaman secara cepat. Rate limiter Craigslist bekerja per IP, dan throughput single-IP yang berkelanjutan biasanya hanya sekitar 0,3–0,5 request/detik, apa pun library yang Anda pakai. Batas itu ditentukan oleh Craigslist, bukan oleh Python.
Langkah 7: Ekspor Data Craigslist ke CSV, JSON, atau Google Sheets
Simpan hasil Anda:
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)Kalau Anda ingin melewati kode ekspor sama sekali, Thunderbit menyediakan ekspor gratis langsung ke Google Sheets, Excel, Airtable, atau Notion dari browser. Namun untuk pipeline Python, CSV dan JSON tetap menjadi output standar. Anda juga bisa mengalirkan data langsung ke pandas untuk analisis atau ke database dengan sqlite3.
Cara Menghindari Banned Saat Scrape Craigslist dengan Python
Banyak tutorial melewatkan bagian ini begitu saja. Sistem anti-bot Craigslist dibuat khusus, bukan produk jadi, dan punya beberapa perilaku unik.

Gunakan Header Request yang Realistis
Craigslist memeriksa urutan dan kelengkapan header. Request yang tidak memiliki Sec-Fetch-Dest atau memakai User-Agent lama akan ditandai sebelum konten sempat dimuat. Set lengkap header Chrome 120+ (ditunjukkan di Langkah 3) adalah minimum. Anda bisa merotasi User-Agent per sesi di antara 5–10 string desktop Chrome/Firefox terbaru — tapi jangan ganti di tengah sesi, karena itu terlihat tidak natural.
Header Sec-Fetch-* yang hilang adalah penyebab paling umum scraper pemula langsung diblokir.
Tambahkan Jeda Acak Antar Request
Konsensus komunitas dari (ScrapingBee, Scraperly, Oxylabs, Multilogin) mengarah pada jeda acak 2–5 detik di antara fetch halaman pencarian dan 3–6 detik untuk halaman detail. Interval yang selalu sama terkesan seperti bot. Gunakan time.sleep(random.uniform(2, 5)) — jangan time.sleep(2) terus-menerus.
Rotasi Proxy (Jika Scraping Skala Besar)
Craigslist memblokir lebih dulu seluruh rentang IP AWS, GCP, dan Azure. Proxy datacenter sering mati sejak awal. Untuk volume lebih dari beberapa ratus halaman, Anda butuh residential rotating proxy, dirotasi setiap 20–30 request. Proxy mobile punya risiko deteksi paling rendah, tetapi biayanya $8–30/GB.
| Proxy Type | Detection Risk on Craigslist | Cost (2025) |
|---|---|---|
| Datacenter | Sangat tinggi — sering diblokir pada request pertama | $0,50–2/GB |
| Residential rotating | Rendah — direkomendasikan | $5–15/GB |
| Mobile | Paling rendah | $8–30/GB |
Mode Cloud Scraping Thunderbit menangani rotasi proxy secara otomatis kalau Anda tidak ingin mengelolanya sendiri.
Tangani CAPTCHA dengan Bijak
CAPTCHA di Craigslist jarang muncul pada path baca — biasanya lebih sering muncul di flow posting atau reply. Jika muncul: berhenti setidaknya 60 detik, ganti IP, hapus cookie, dan perlambat kecepatan. CAPTCHA yang terus muncul adalah tanda ritme Anda terlalu agresif, bukan teka-teki yang bisa dipaksa dengan solver.
Hormati Rate Limit dan Terapkan Backoff
Craigslist mengembalikan 403 (bukan 429) saat Anda melewati rate limit. 403 berarti IP saat ini sudah masuk deny list — jangan retry secara membabi buta. Ganti IP, ubah UA, dan tunggu.
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1.5, 3, 6, 12, 24s
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)Satu tips lagi: laporan komunitas secara konsisten menyebut pukul 2–6 pagi waktu lokal kota target sebagai jendela scraping paling aman, dengan tingkat blok sekitar 30–40% lebih rendah dibanding siang hari.
TLS Fingerprinting — Jebakan yang Sering Tidak Terlihat
Lapisan bot Craigslist memeriksa TLS ClientHello. Library requests milik Python (berbasis OpenSSL) memiliki fingerprint JA3 yang tidak sama dengan browser sungguhan. User-Agent yang sempurna tapi dipadukan dengan fingerprint TLS non-browser adalah mismatch yang mudah dideteksi. Solusinya adalah dengan impersonate="chrome124", yang meniru handshake TLS Chrome:
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")Kalau Anda masih kena 403 tanpa penjelasan meski IP residential bersih dan header sudah benar, TLS fingerprinting hampir pasti penyebabnya.
robots.txt Craigslist, Ketentuan Layanan, dan Scraping yang Etis
Banyak panduan mengabaikan bagian ini, atau hanya menaruh satu kalimat di FAQ. Mengingat Craigslist pernah memenangkan putusan melawan scraper (RadPad, 2017), topik ini jelas pantas dibahas lebih dari sekadar catatan kaki.
Apa Isi Sebenarnya dari robots.txt Craigslist
File ternyata sangat singkat. Hanya ada satu blok User-agent: * dengan tujuh path yang dilarang:
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafKetujuhnya adalah endpoint interaktif/mengubah data: reply, flag, suggest, email-a-friend. Halaman listing (/search/..., URL posting individual) tidak dilarang. Tidak ada directive Crawl-delay, meskipun Craigslist tetap menegakkannya lewat pemblokiran IP.
Subdomain kota juga mempublikasikan sitemap — misalnya https://newyork.craigslist.org/sitemap/index.xml — yang merupakan jalur resmi yang dapat ditemukan untuk listing.
Preseden Hukum: Kasus yang Penting
Craigslist v. 3Taps (2013, selesai 2015): 3Taps melakukan scraping listing Craigslist lalu menjual ulang datanya. Saat Craigslist mengirim surat penghentian dan memblokir IP mereka, 3Taps mengakali blok tersebut dengan rotating proxy. Pengadilan memutuskan bahwa menghindari blok IP setelah revokasi eksplisit berarti tindakan “tanpa otorisasi” menurut CFAA. 3Taps .
Meta v. Bright Data (2024): Putusan yang lebih baru menyatakan bahwa TOS Meta tidak bisa melarang scraping data publik yang dapat diakses saat status logout. Pengadilan menilai scraper yang tidak login “berada pada posisi yang sama seperti pengunjung.” Ini adalah putusan paling penting untuk scraper 2024–2025 — jika Anda tidak pernah membuat akun Craigslist, tidak pernah login, dan hanya mengakses halaman yang terlihat publik, TOS mungkin tidak dapat diberlakukan terhadap Anda sebagai kontrak.
Kesimpulan praktis: Risiko CFAA jauh berkurang setelah Van Buren (2021) dan hiQ v. LinkedIn (2022) untuk halaman yang dapat diakses publik. Namun, klaim tort berdasarkan hukum negara bagian (trespass-to-chattels, misappropriation) masih tetap ada — itulah yang mendorong penyelesaian 3Taps dan putusan $60,5 juta terhadap RadPad.
Ini hanya informasi umum, bukan nasihat hukum. Jika Anda melakukan scraping Craigslist untuk tujuan komersial, bicarakan dengan pengacara.
Checklist Scraping Etis yang Praktis
- ✅ Hormati setiap
Disallowdi robots.txt — terutama tujuh endpoint aksi - ✅ Tetap jauh di bawah 1.000 halaman per 24 jam per IP (TOS Craigslist menetapkan di atas ambang itu sebagai liquidated damages)
- ✅ Tetap logout — jangan pernah membuat akun Craigslist untuk scraping
- ✅ Jangan mengakali blok IP dengan proxy setelah diblokir secara eksplisit (itulah yang menjatuhkan 3Taps)
- ✅ Tambahkan jeda antar request — minimal 2–5 detik
- ✅ Jangan scraping info kontak pribadi untuk spam
- ✅ Jangan mendistribusikan ulang data Craigslist mentah atau mengklaimnya sebagai platform Anda sendiri
- ✅ Gunakan data untuk riset, analisis, atau kebutuhan pribadi yang sah
- ✅ Kalau memungkinkan, pilih sitemap yang dipublikasikan ketimbang crawling brutal
- ✅ Hapus PII (email, nomor telepon) saat ingest jika Anda menyimpan data
Kami juga menulis panduan lebih dalam tentang kalau Anda ingin gambaran lengkapnya.
Python vs. No-Code: Pendekatan Mana yang Tepat untuk Anda?
| Factor | Python (requests + BS4) | Thunderbit (No-Code) |
|---|---|---|
| Waktu setup | 30–60 menit (install, tulis kode) | 2 menit (install ekstensi Chrome) |
| Skill teknis yang dibutuhkan | Python tingkat menengah | Tidak ada |
| Kustomisasi | Kontrol penuh atas logika, field, alur | AI mendeteksi field secara otomatis; pengguna bisa menyesuaikan |
| Skala | Tidak terbatas (dengan proxy, penjadwalan) | Scheduled Scraper untuk tugas berulang |
| Penanganan anti-ban | Manual (headers, jeda, proxy, TLS) | Bawaan (Cloud Scraping) |
| Opsi ekspor | CSV, JSON (buat sendiri dengan kode) | Google Sheets, Excel, Airtable, Notion — gratis |
| Paling cocok untuk | Developer, data scientist, pipeline kustom | Tim sales, agen properti, manajer operasional |
Gunakan Python jika Anda butuh kustomisasi penuh, berencana mengintegrasikannya ke pipeline data yang lebih besar, atau ingin tahu persis apa yang terjadi di balik layar. Gunakan jika Anda ingin hasil cepat tanpa menulis atau memelihara kode. Keduanya valid — semuanya tergantung use case Anda dan apakah Anda lebih suka menghabiskan waktu di terminal atau di browser.
Penutup
Craigslist adalah sumber data yang kaya dan terus diperbarui untuk hunian, mobil, pekerjaan, layanan, gig, dan lain-lain — dan karena tidak ada API publik, scraping adalah satu-satunya cara untuk mendapatkan data terstruktur dalam skala besar. Pendekatan 2025 yang benar-benar bekerja: ambil JSON-LD tertanam dari hasil pencarian (bukan CSS selector rapuh), gunakan requests + BeautifulSoup (bukan Selenium), tambahkan headers realistis dengan field Sec-Fetch-*, acak jeda request, dan pakai residential proxy jika Anda melampaui beberapa ratus halaman.
Metode JSON-LD adalah peningkatan terbesar dibanding panduan lama. Ia lebih cepat, lebih tahan terhadap perubahan tampilan, dan tidak memerlukan rendering JavaScript sama sekali. Padukan dengan strategi anti-ban di atas, dan Anda akan terhindar dari 403 yang sering menjebak scraper pemula.
Kalau Anda ingin melewati kode sepenuhnya, bisa scrape kategori Craigslist apa pun hanya dengan beberapa klik dan mengekspor langsung ke spreadsheet atau database pilihan Anda. Jika ingin mendalami lebih jauh, panduan kami tentang dan membahas fondasinya dengan lebih detail.
FAQ
Apakah legal melakukan scraping Craigslist?
Ketentuan Layanan Craigslist melarang scraping otomatis dan mencantumkan klausul liquidated damages ($0,25/halaman di atas 1.000/hari). Namun, putusan pengadilan terbaru — terutama Meta v. Bright Data (2024) dan hiQ v. LinkedIn (2022) — mempersempit tanggung jawab CFAA untuk scraping data publik saat tidak login. Klaim tort berdasarkan hukum negara bagian (trespass-to-chattels) tetap berisiko, terutama untuk redistribusi komersial. Hormati robots.txt, tetap logout, tambahkan jeda, dan jangan mendistribusikan ulang data mentah. Ini informasi umum, bukan nasihat hukum.
Apakah Craigslist punya API publik?
Tidak. Craigslist hanya menyediakan Bulk Posting Interface (BAPI) yang bersifat write-only untuk pengiklan berbayar yang disetujui. Tidak ada public read API, tidak ada portal developer, dan tidak ada tier terbatas untuk pengambilan data. Semua produk bertajuk “Craigslist API” yang Anda lihat di platform pihak ketiga sebenarnya adalah scraper tidak resmi.
Kenapa scraper Craigslist saya terus rusak?
Hampir selalu karena perubahan struktur HTML. Craigslist menulis ulang markup hasil pencarian pada 2023–2024, dan panduan yang memakai selector lama seperti .result-row atau .result-info sudah tidak berfungsi. Beralihlah ke metode JSON-LD tertanam (mem-parsing script#ld_searchpage_results) agar jauh lebih tahan banting. Pastikan juga headers Anda menyertakan field Sec-Fetch-* — jika tidak, pemblokiran instan sering terjadi.
Bisa scrape Craigslist tanpa Python?
Bisa. Ekstensi Chrome AI web scraper milik Thunderbit bisa dipakai di halaman Craigslist mana pun — apartemen, mobil, pekerjaan, layanan. Klik "AI Suggest Fields" untuk mendeteksi kolom otomatis, klik "Scrape" untuk mengekstrak data, lalu ekspor gratis ke Google Sheets, Excel, Airtable, atau Notion. Tanpa coding, tanpa setup, tanpa manajemen proxy.
Seberapa sering saya bisa scrape Craigslist tanpa kena banned?
Dengan satu IP residential, throughput yang masih aman biasanya sekitar 0,3–0,5 request per detik dengan jeda acak 2–5 detik antar halaman. Tetap di bawah 1.000 halaman per 24 jam per IP agar terhindar dari banned maupun ambang liquidated damages dalam TOS Craigslist. Scraping di jam sepi (pukul 2–6 pagi waktu lokal kota target) menurunkan tingkat blok sekitar 30–40%. Untuk volume yang lebih besar, rotasikan residential proxy setiap 20–30 request.
Pelajari Lebih Lanjut