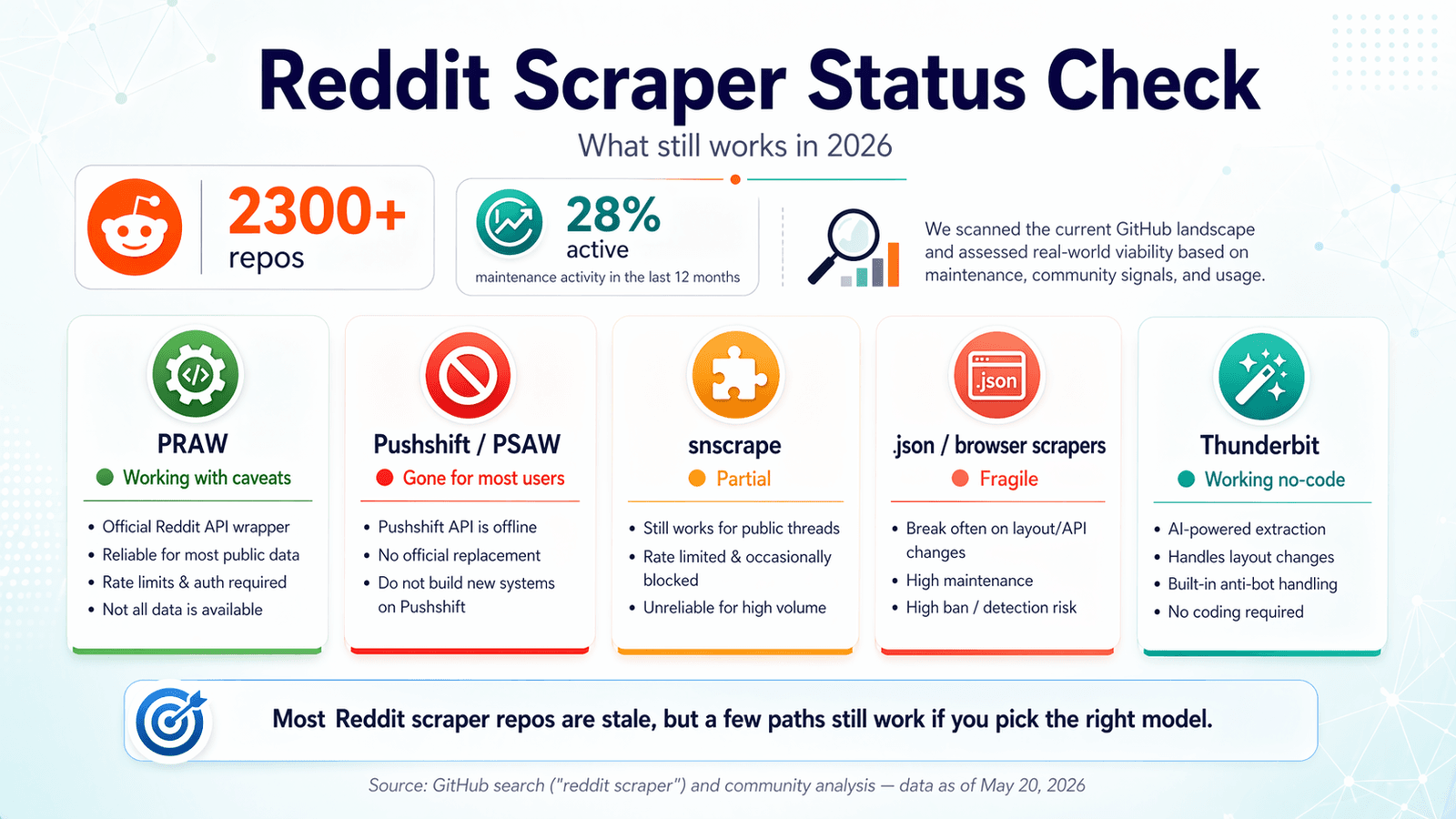
GitHub saat ini menampilkan lebih dari . Kedengarannya seperti prasmanan. Masalahnya: hanya sekitar 28% yang menunjukkan aktivitas pemeliharaan dalam 12 bulan terakhir. Beberapa minggu terakhir saya habiskan untuk membongkar repo-repo ini, menguji endpoint, membaca antrean issue, dan mencocokkan pembaruan kebijakan Reddit sendiri. Tujuannya: menyelamatkan Anda dari clone repo, berurusan dengan OAuth, lalu baru sadar tengah malam bahwa semuanya ternyata sudah rusak diam-diam sejak 2024. Lanskap Reddit scraper GitHub di 2026 adalah kuburan niat baik yang bercampur dengan segelintir alat yang benar-benar berguna. Panduan ini membahas apa yang masih berfungsi, apa yang rusak, kapan sebaiknya skip kode sama sekali, dan bagaimana tetap berada di sisi yang benar dari penegakan Reddit yang makin ketat. Kalau Anda mencari jalan pintas, adalah opsi tanpa kode yang kami buat untuk masalah seperti ini—tapi saya juga akan jujur soal kapan solusi berbasis kode masih lebih masuk akal.
Apa Itu Repo Reddit Scraper GitHub (Dan Mengapa Begitu Banyak yang Rusak)
Repo "reddit scraper github" biasanya adalah proyek Python open-source (atau kadang JavaScript) yang mengotomatiskan pengambilan postingan, komentar, data pengguna, atau media dari Reddit. Secara umum, mereka terbagi ke dalam empat kelompok:
- API wrapper (seperti PRAW): menggunakan API resmi Reddit, membutuhkan OAuth, dan mengikuti aturan Reddit.
- Alat berbasis Pushshift/PSAW: dulu dipakai untuk mengakses arsip Reddit besar milik Pushshift untuk data historis.
- Scraper endpoint
.jsonpublik: menambahkan.jsonke URL Reddit atau memanggil endpoint publik tanpa autentikasi. - Scraper berbasis browser: menggunakan Playwright, Selenium, atau ekstensi browser untuk memuat halaman Reddit dan mengekstrak konten yang sudah dirender.
Mengapa begitu banyak yang rusak? Ada tiga alasan.
- Perombakan harga API Reddit pada pertengahan 2023. Batas gratis API turun menjadi . Penggunaan komersial yang lebih tinggi kini dikenai biaya $0,24 per 1.000 panggilan API. Banyak repo dibangun untuk dunia ketika akses API praktis tak terbatas—dan dunia itu sudah hilang.
- Akses publik Pushshift dicabut. Pushshift dulu menjadi tulang punggung riset historis Reddit. Begitu Reddit membatasi aksesnya, sebagian besar repo "historical scraper" kehilangan sumber data utama. Beberapa README masih membuat alat-alat ini tampak hidup, tetapi dependensi di bawahnya sudah hilang bagi pengguna biasa.
- Reddit memperketat kebijakan dan penegakan. Pembaruan robots.txt 2024, 2025, dan Maret 2026 semuanya menunjukkan bahwa Reddit tidak lagi menganggap scraping massal sebagai kebisingan latar belakang yang tidak berbahaya. Mereka bahkan .
Intinya: cari "reddit scraper github" dan Anda akan mendapat ratusan hasil. Tanggal commit terakhir dan jumlah issue terbuka menceritakan kisah yang sangat berbeda.
Pemeriksaan Status Reddit Scraper GitHub 2026: Apa yang Masih Berfungsi
Sebagian besar artikel pesaing ditulis pada 2023 atau 2024 dan tidak pernah diperbarui. Pengguna forum terus menemui error pada repo yang masih berfungsi setahun lalu—keluhan seorang pengguna, "Terus kena error batasan Reddit API :\ Ada ide bagaimana melewatinya?" pada dasarnya merangkum pengalaman Reddit scraper 2026.
Saya melakukan audit kebaruan, diverifikasi per April 2026. Ini yang saya temukan.
PRAW: Wrapper Python Resmi
Status: ✅ Masih berfungsi, dengan catatan.
(Python Reddit API Wrapper) tetap menjadi fondasi open-source paling andal untuk scraping Reddit. Proyek ini aktif dipelihara—4.099 bintang, terakhir di-push pada 20 April 2026, hanya 6 issue terbuka, dan (rilis Oktober 2024).
Kelebihan: Resmi, terdokumentasi dengan baik, dan menyederhanakan sebagian besar kompleksitas API Reddit.
Keterbatasan 2026:
- Persyaratan OAuth lebih ketat. Anda perlu aplikasi Reddit terdaftar dengan deskripsi penggunaan yang disetujui.
- Batas rate limit lebih rendah sejak 2024 (100 kueri/menit dengan OAuth, 10 tanpa OAuth).
- Batas keras sekitar 1.000 postingan per listing masih berlaku. Thread komunitas di r/redditdev dan Stack Overflow mengonfirmasi: per endpoint listing.
PRAW adalah pilihan paling aman kalau Anda bisa tetap berada di dalam batasan API.
Hanya saja, ini bukan lagi scraper massal yang serba bebas.
Kalau Anda ingin panduan praktis untuk jalur API resmi, tutorial ini cocok untuk bagian ini:
Pushshift / PSAW: Arsip yang Meredup
Status: ❌ Akses publik hilang.
dulu adalah wrapper Python andalan untuk Pushshift, yang sebelumnya menjadi jalur termudah untuk data historis Reddit. Pada 2026, repo ini diarsipkan, README-nya secara literal mengatakan "THIS REPOSITORY IS STALE," dan issue terbuka terbaru berisi judul seperti "Pushshift.io UNABLE to connect" dan "The code not working. Possibly due to pushshift api."
Akses akademik mungkin masih ada lewat jalur tertentu, tetapi bagi siapa pun yang mencari "reddit scraper github" hari ini, Pushshift/PSAW bukan opsi yang layak. Jika Anda membutuhkan data historis Reddit yang mendalam, Anda perlu melihat akses data akademik yang disetujui atau jalur berlisensi.
snscrape (Modul Reddit): Sebagian dan Tidak Andal
Status: ⚠️ Sebagian — sering bermasalah, sebagian besar tidak lagi dipelihara.
punya 5.337 bintang, tetapi push terakhirnya pada 15 November 2023. README-nya masih mengatakan scraping Reddit didukung "via Pushshift." Issue terkait Reddit yang terbuka mencakup "Error reddit scraping" dan "Reddit scraper returns no submissions before 2022-11-03," tanpa aktivitas perbaikan yang berarti belakangan ini.
Alat ini bisa bekerja untuk pengambilan kecil, sekali pakai, di beberapa lingkungan, tetapi tidak andal untuk produksi atau scraping berulang. Anggap saja ini sebagai warisan lama.
Playwright dan Scraper Endpoint .json: Solusi Alternatif yang Berfungsi (Kadang-kadang)
Status: ✅ Berfungsi, tapi rapuh.
Idenya sederhana: gunakan browser tanpa antarmuka (Playwright, Puppeteer) untuk memuat halaman Reddit dan mengekstrak konten yang sudah dirender, atau tambahkan .json ke URL Reddit untuk mendapatkan data terstruktur tanpa API resmi.
Kelebihan: Tidak perlu API key, bisa melewati batas 1.000 postingan, dan bisa mengakses konten yang sudah dirender.
Kekurangan: Rusak saat Reddit mengubah tampilan front-end atau struktur JSON, bisa memicu mekanisme anti-bot, dan butuh setup teknis yang lebih rumit. Dalam pengujian saya bulan ini, permintaan langsung ke endpoint .json publik Reddit menghasilkan respons 403. Itu tidak berarti semua lingkungan akan diblokir, tetapi artinya pintasan .json bukan lagi sesuatu yang bisa Anda asumsikan akan "langsung jalan."
Repo seperti jujur soal ini: README mereka memperingatkan pengguna untuk "Use with rotating proxies, or Reddit might gift you with an IP ban." Itulah cerita April 2026 dalam satu kalimat.
Kalau Anda mengevaluasi jalur workaround otomasi browser, tutorial Playwright ini adalah pendamping yang kuat untuk bagian di bawah:
Thunderbit: Scraping Browser Bertenaga AI (Tanpa Kode, Tanpa API Key)
Status: ✅ Berfungsi — menyesuaikan diri secara otomatis terhadap perubahan halaman.
mengambil pendekatan yang sangat berbeda. Ini adalah yang menggunakan AI untuk membaca halaman Reddit, menyarankan field data (judul postingan, penulis, upvote, timestamp, URL, dll.), lalu mengekstrak data terstruktur dalam dua klik. Tanpa setup OAuth, tanpa registrasi API key, tanpa environment Python, tanpa manajemen dependency. AI membaca ulang halaman setiap kali, jadi saat Reddit mengubah tata letaknya, Thunderbit menyesuaikan secara otomatis alih-alih rusak diam-diam.
Ekspor gratis ke CSV, Google Sheets, Airtable, atau Notion. Mendukung pagination dan scraping subpage (misalnya, mengambil daftar subreddit lalu mengunjungi setiap postingan untuk menarik komentar). Untuk audiens yang ingin data Reddit tanpa harus memelihara repo GitHub, ini adalah jalur yang paling minim hambatan.
(Pengungkapan penuh: kami membangun Thunderbit, jadi saya memang bias—tetapi nanti di artikel ini saya akan tetap jujur tentang kapan solusi berbasis kode masih lebih masuk akal.)
Tabel Ringkasan Status Side-by-Side
| Alat / Kategori | Masih Berfungsi (April 2026)? | Perlu API Key? | Catatan |
|---|---|---|---|
| PRAW | ✅ Ya, dengan catatan | Ya (OAuth) | Fondasi open-source yang paling terawat. Dibatasi rate limit dan batas 1.000 postingan. |
| Pushshift / PSAW | ❌ Tidak (untuk sebagian besar pengguna) | N/A | Akses publik hilang. Repo diarsipkan. |
| snscrape (modul Reddit) | ⚠️ Sebagian / tidak andal | Tidak | Masih mendokumentasikan Reddit "via Pushshift." Pemeliharaan macet sejak 2023. |
| Scraper .json / endpoint publik | ⚠️ Sebagian | Tidak | Bisa berfungsi, tetapi permintaan langsung makin sering diblokir. Bergantung pada proxy. |
| Playwright / scraper browser | ✅ Ya, tapi rapuh | Biasanya tidak | Solusi DIY tanpa API yang paling layak. Perubahan halaman dan pemeriksaan anti-bot tetap berpengaruh. |
| Thunderbit | ✅ Ya | Tidak | Alur kerja AI/browser. Tanpa OAuth, tanpa selector. Paling cocok untuk non-developer. |
Rate Limit, Batas 1.000 Postingan, dan Apa yang Benar-Benar Membantu
Ini adalah titik paling menyakitkan bagi siapa pun yang memakai proyek reddit scraper github. Thread forum penuh dengan keluhan: "capek run mati di tengah jalan karena rate limit," "Kenapa saya cuma dapat sekitar 1.000 item?" Dua batas utama adalah rate limit API Reddit (permintaan per menit) dan batas listing sekitar 1.000 postingan (API hanya mengembalikan sekitar 1.000 postingan terbaru per endpoint listing).
Praktik Terbaik untuk Mengelola Rate Limit
Baseline publik Reddit saat ini: . Berikut cara menanganinya dalam praktik:
- Exponential backoff. Jika Anda mendapat respons rate-limit, tunggu lalu coba lagi dengan jeda yang makin panjang setiap kali (1 detik, 2 detik, 4 detik, 8 detik, ...). Jangan terus menghantam endpoint.
- Baca header
X-Ratelimit-Remaining. Respons API Reddit menyertakan header yang memberi tahu berapa banyak permintaan yang tersisa dan kapan jendelanya di-reset. Atur kecepatan permintaan berdasarkan nilai ini, bukan berdasarkan tebakan. - Rotasi user-agent. Beberapa repo menyarankan ini untuk menghindari deteksi. Ini bisa membantu, tetapi gunakan secara etis—jangan dipakai untuk menghindari ban yang memang pantas Anda terima.
- Log semuanya. Tambahkan logging untuk respons API, header rate-limit, dan error. Saat scraper mati jam 2 pagi, log adalah sahabat terbaik Anda.
Menembus Batas 1.000 Postingan
Workaround paling kredibel untuk batas listing sekitar 1.000 item pada API adalah chunking jendela waktu:
- Query satu irisan waktu menggunakan parameter timestamp
beforedanafter. - Geser jendelanya maju (atau mundur).
- Ulangi.
- Deduplicate berdasarkan ID postingan.
Ini memang tidak elegan, tetapi lebih jujur daripada pura-pura satu loop request bisa menarik histori arbitrer dari endpoint listing. Untuk data yang benar-benar historis, Anda butuh akses akademik yang disetujui atau jalur berlisensi—Pushshift bukan lagi jawaban default.
Scraping berbasis browser (Playwright atau Thunderbit) melewati batas ini sepenuhnya karena mereka men-scrape apa yang dirender di halaman, bukan apa yang dikembalikan API. Fitur pagination Thunderbit memungkinkan Anda klik antarhalaman dan mengumpulkan data sebanyak halaman yang Anda butuhkan.
Deduplikasi dan Pemulihan Error
Kebanyakan repo reddit scraper github tidak menangani deduplikasi atau pemulihan error secara bawaan. Pengguna secara eksplisit mengeluh bahwa "tidak ada yang punya deduping, menghindari rate limit setelah error, atau cek apakah file sudah terunduh." Yang perlu dilakukan:
- Deduplikasi: Hash ID setiap postingan (atau ID + konten). Simpan hash yang sudah pernah dilihat di database SQLite sederhana atau bahkan file datar. Sebelum memasukkan, cek apakah hash itu sudah ada. Ini sangat penting saat membagi jendela waktu atau menjalankan ulang job yang gagal.
- Pemulihan error: Simpan progres ke file checkpoint setiap N record. Kalau proses gagal, mulai lagi dari checkpoint terakhir, bukan dari awal. Ini mengubah job 3 jam yang mati di jam ke-2 menjadi lanjutan 1 jam.
Cara Berbagai Pendekatan Menangani Kendala Ini

| Pendekatan | Penanganan Rate Limit | >1k Postingan? | Auto-Dedup? | Pemulihan Error? |
|---|---|---|---|---|
| PRAW (mentah) | Manual (sleep/retry) | ❌ (batas API) | ❌ | ❌ |
| PRAW + chunking jendela waktu | Manual | ✅ (workaround) | ❌ | ❌ (kecuali Anda menambahkannya) |
| Scraping .json Playwright | N/A (tanpa API) | ✅ | ❌ | ❌ |
| Thunderbit (scraping browser) | Bawaan (AI pacing) | ✅ (pagination) | N/A (review visual) | Bawaan |
Kapan Repo Reddit Scraper GitHub Bukan Jawabannya: Jalur Tanpa Kode
Sebagian besar artikel reddit scraper github mengasumsikan Anda mahir Python. Padahal, banyak pencari solusi scraping Reddit adalah marketer, sales, peneliti, atau founder indie yang tidak menulis Python setiap hari. Untuk audiens ini, repo GitHub menambah biaya tersembunyi:
- Menyiapkan kredensial OAuth dan aplikasi developer Reddit
- Mengelola virtual environment Python dan konflik dependency
- Debugging pesan error yang sulit dipahami saat internal PRAW berubah
- Menangani pencabutan API key jika Reddit menilai use case Anda tidak disetujui
- Memelihara script setiap kali Reddit mengubah sesuatu
Ini bukan sekadar kemungkinan. punya 2.563 bintang dan 107 issue terbuka. Laporan terbaru mencakup "Struggling to install," "PRAW module error," dan "Exception not allowing to even authenticate."
Gunakan Repo GitHub Jika...
- Anda butuh logika scraping khusus (misalnya traversal tree komentar tertentu, integrasi pipeline NLP kustom).
- Anda ingin integrasi ke pipeline data Python yang sudah ada.
- Anda perlu scraping dalam skala sangat besar dengan penyimpanan kustom (database, data warehouse).
- Anda nyaman memelihara kode dan menangani perubahan yang memutus kompatibilitas.
Gunakan Alat Tanpa Kode Jika...
- Anda butuh data Reddit dengan cepat—dalam hitungan menit, bukan berjam-jam setup.
- Anda tidak ingin mengelola API key, aplikasi OAuth, atau environment Python.
- Anda ingin mengekspor langsung ke spreadsheet, Notion, atau Airtable untuk langsung dipakai.
- Anda ingin alat menyesuaikan diri otomatis saat tata letak Reddit berubah.
Thunderbit sangat cocok untuk jalur tanpa kode. Pengguna bisa dalam 2 klik dengan field yang disarankan AI, mengekspor gratis ke CSV/Google Sheets/Airtable/Notion, dan menangani pagination tanpa menulis kode. Scraping berbasis browser berarti tanpa setup OAuth dan tanpa registrasi API key.
Panduan Singkat: Scraping Reddit dengan Thunderbit (Langkah demi Langkah)
- Instal .
- Buka halaman Reddit yang ingin Anda scrape (subreddit, hasil pencarian, profil pengguna).
- Klik "AI Suggest Fields." Thunderbit membaca halaman dan menyarankan kolom—judul postingan, penulis, upvote, timestamp, URL, dll.
- Sesuaikan field jika perlu, lalu klik "Scrape."
- Tinjau tabel data. Opsional, klik "Scrape Subpages" untuk mengunjungi setiap postingan dan menarik komentar atau detail tambahan.
- Ekspor ke tujuan pilihan Anda: Google Sheets, Excel, Airtable, Notion, CSV, atau JSON.
Dua menit. Nol baris kode. Kalau Anda ingin melihatnya bekerja, cek .
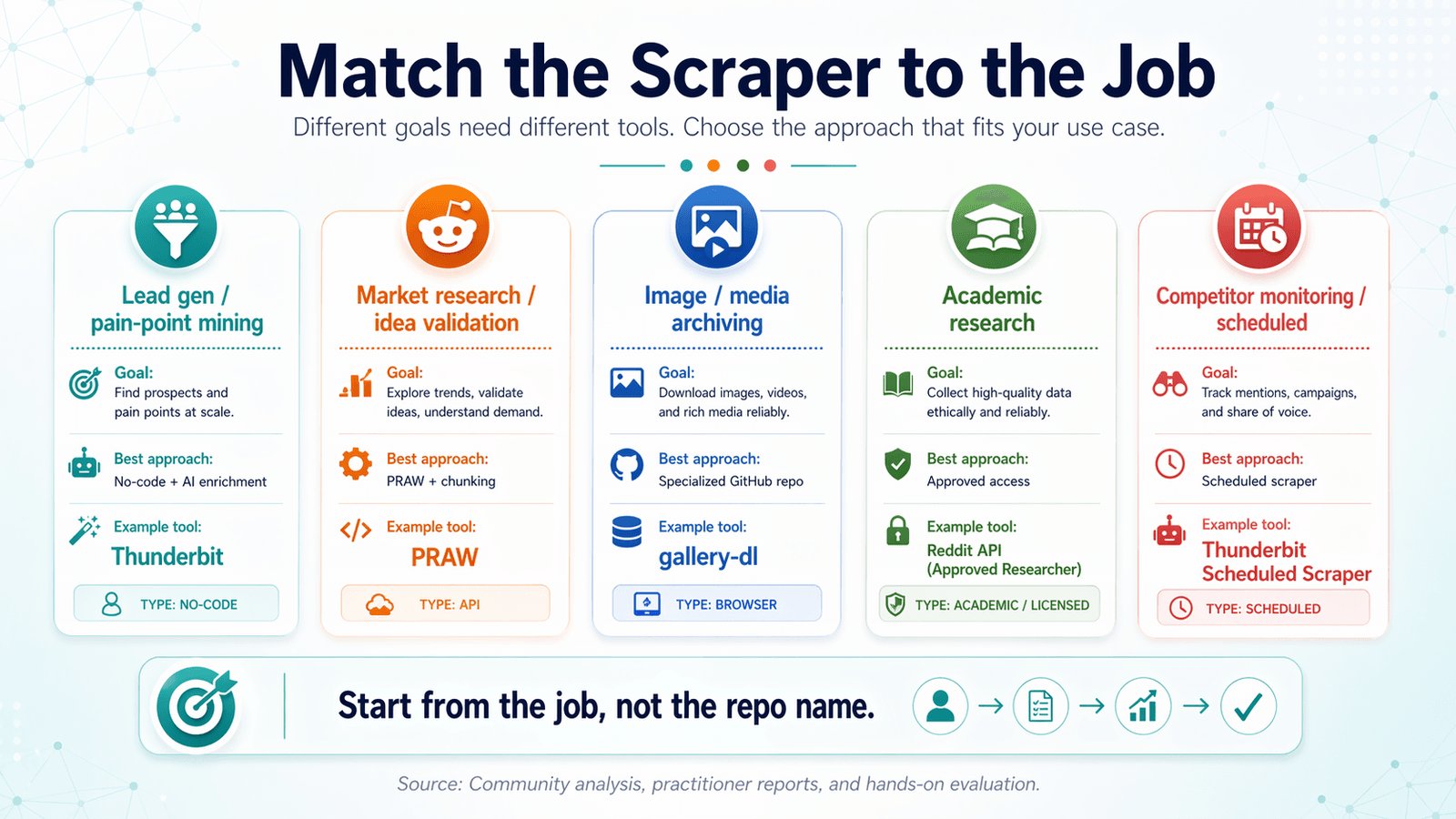
Cocokkan Reddit Scraper dengan Pekerjaannya: Matriks Keputusan Use Case
Sebagian besar artikel reddit scraper github mengatur berdasarkan alat. Itu terbalik.
Mulailah dari tujuan Anda, lalu mundur ke alat yang tepat.
Lead Generation dan Penggalian Pain Point
Yang Anda butuhkan: Postingan + komentar dengan filter kata kunci, pelabelan/tagging AI, ekspor ke format siap CRM.
Pendekatan terbaik: Scraper tanpa kode dengan enrichment AI.
Alat yang direkomendasikan: (pelabelan AI + ekspor ke Google Sheets/Airtable untuk impor CRM).
Contoh alur kerja: Scrape subreddit untuk postingan yang menyebutkan pain point tertentu. Gunakan Field AI Prompt Thunderbit untuk mengategorikan sentimen atau menandai topik. Ekspor ke Airtable atau Google Sheet tim sales Anda.
Riset Pasar dan Validasi Ide
Yang Anda butuhkan: Judul postingan bervolume tinggi + skor, data tren tingkat subreddit.
Pendekatan terbaik: PRAW dengan chunking jendela waktu untuk volume, atau Thunderbit untuk pengambilan cepat.
Contoh: Scraping r/SaaS atau r/startups untuk topik yang sedang tren dan pola upvote selama 90 hari terakhir.
Arsip Gambar dan Media
Yang Anda butuhkan: URL media, deduplikasi, run terjadwal.
Pendekatan terbaik: Repo GitHub khusus (misalnya, ) + cron job.
Catatan: Dedup penting di sini—gambar yang sama diposting di banyak subreddit itu sangat umum.
Riset Akademik dan Data Historis
Yang Anda butuhkan: Data historis, seluruh tree komentar, dataset besar.
Pendekatan terbaik: Akses akademik yang disetujui atau jalur data berlisensi. Pushshift bukan lagi jawaban umum.
Cek realitas: Ini use case paling sulit di 2026 karena pembatasan Pushshift dan kebijakan data Reddit yang semakin ketat.
Pemantauan Kompetitor dan Scraping Terjadwal
Yang Anda butuhkan: Scrape berulang dengan interval tertentu, deteksi perubahan.
Pendekatan terbaik: Thunderbit (jelaskan interval waktunya dalam bahasa Inggris biasa, masukkan URL, klik Schedule) atau cron + script untuk pengguna berbasis kode.
Tabel Matriks Keputusan Use Case
| Use Case | Yang Dibutuhkan | Pendekatan Terbaik | Contoh Alat |
|---|---|---|---|
| Lead gen / penggalian pain point | Postingan + komentar, filter kata kunci, tagging AI | Scraper tanpa kode + enrichment AI | Thunderbit |
| Riset pasar / validasi ide | Judul postingan bervolume tinggi + skor, data tingkat subreddit | PRAW + chunking jendela waktu atau Thunderbit | PRAW atau Thunderbit |
| Arsip gambar/media | URL media, dedup, run terjadwal | Repo GitHub khusus + cron | bulk-downloader-for-reddit |
| Riset akademik | Data historis, seluruh tree komentar | Akses akademik yang disetujui atau Playwright | Pushshift academic API (jika доступible) |
| Pemantauan kompetitor / terjadwal | Scrape berulang, deteksi perubahan | Scheduled scraper | Thunderbit Scheduled Scraper atau cron + script |
Cara Mengevaluasi Repo Reddit Scraper GitHub Apa Pun Sebelum Anda Commit
Sebelum Anda clone repo dan mulai debugging, jalankan pemeriksaan kesehatan 5 menit ini. Ini akan menghemat berjam-jam waktu Anda.
Pemeriksaan Kesehatan Repo 5 Menit
- Tanggal commit terakhir. Jika sudah lebih dari 6 bulan, lanjutkan dengan hati-hati. API Reddit sering berubah.
- Rasio issue terbuka vs. issue tertutup. Jumlah issue yang belum terjawab tinggi adalah tanda bahaya. Periksa apakah issue terbaru menyebut kegagalan autentikasi, 403, atau gangguan Pushshift.
- File LICENSE. Cek apakah ada. Tanpa lisensi = ambigu secara hukum (lebih lanjut di bawah).
- Dependency. Apakah library yang dibutuhkan masih mutakhir? Apakah memakai paket yang sudah deprecated?
requirements.txtpenuh versi yang dikunci dari 2022 adalah tanda peringatan. - Kualitas README. Apakah setup dijelaskan dengan jelas? Apakah ada contoh penggunaan? Dokumentasi buruk = waktu debugging lebih banyak untuk Anda.
- Bintang vs. fork vs. aktivitas terbaru. Bintang tinggi tapi aktivitas terbaru rendah bisa berarti proyek dulu populer tetapi sekarang ditinggalkan. Bandingkan bintang dengan tanggal
pushed_at.
Contoh cepat: punya 364 bintang—sekilas terlihat kredibel. Tapi repo-nya diarsipkan dan README-nya mengatakan "THIS REPOSITORY IS STALE."
Bintang saja tidak menceritakan keseluruhan kisah.
Tips agar Setup Reddit Scraper GitHub Anda Maksimal
Kalau Anda tetap memilih jalur kode, berikut cara menghindari sakit kepala.
Selalu Gunakan Virtual Environment
Virtual environment menjaga dependency scraper Anda tetap terisolasi sehingga tidak bentrok dengan proyek Python lain. Satu perintah: python -m venv venv, lalu aktifkan sebelum menginstal apa pun. Ini kebersihan dasar, tetapi saya sudah melihat cukup banyak issue GitHub berjudul "module not found" untuk tahu bahwa ini layak diulang.
Simpan Kredensial dengan Aman
Jangan pernah menaruh client ID atau secret API Reddit langsung di script. Gunakan environment variables atau file .env, lalu tambahkan .env ke .gitignore. Jika Anda tanpa sengaja push kredensial ke GitHub, segera rotasi—bot memindai API key yang terekspos.
Log Semuanya
Tambahkan logging untuk respons API, header rate-limit, dan error. Saat ada yang rusak, log adalah perbedaan antara "saya tahu persis apa yang terjadi" dan "saya tidak tahu kenapa semuanya berhenti."
Jadwalkan dan Otomatiskan dengan Bijak
Jika menjalankan scraping berulang, gunakan cron (Linux/Mac) atau Task Scheduler (Windows)—tetapi pantau kegagalan. Cron job yang gagal diam-diam selama dua minggu lebih buruk daripada tidak ada otomatisasi sama sekali.
Alternatif: Thunderbit memungkinkan Anda menjelaskan interval dalam bahasa Inggris biasa, tanpa perlu sintaks cron.
Praktik Hukum dan Etika Terbaik untuk Scraping Reddit
Ini bukan penafian asal tempel. Reddit telah menegakkan ketentuannya secara agresif sejak perubahan API 2023, dan scraping data pribadi membawa risiko hukum yang nyata.
Berikut hal yang benar-benar penting.
Ketentuan Layanan Reddit: Apa yang Sebenarnya Mereka Katakan
Reddit (direvisi hingga 31 Maret 2026) secara eksplisit melarang mengakses, mencari, atau mengumpulkan data dari layanan dengan cara otomatis kecuali diizinkan oleh ketentuan atau perjanjian terpisah. dan menambahkan detail: Reddit dapat memantau dan mengaudit penggunaan developer, mengubah atau menghentikan akses, dan memblokir akses secara permanen untuk penggunaan yang berlebihan atau abusif. Penggunaan komersial umumnya memerlukan persetujuan eksplisit.
Maret 2026 melangkah lebih jauh: persetujuan diperlukan sebelum mengakses data Reddit melalui API, komersialisasi yang tidak disetujui serta penggunaan AI/data-mining dilarang, dan penegakan dapat mencakup pencabutan token, penangguhan aplikasi atau akun, serta penangguhan bot atau domain terkait.
Kepatuhan robots.txt
Reddit saat ini sangat restriktif:
1User-agent: *
2Disallow: /Artinya, semua user-agent otomatis diblokir secara menyeluruh. File ini juga merujuk ke . Ini jauh lebih ketat daripada pola robots.txt permisif yang masih diasumsikan sebagian developer dari norma web scraping lama.
Praktik terbaik: selalu cek robots.txt sebelum scraping, bahkan jika alat Anda tidak menerapkannya secara otomatis.
Data Pribadi dan Privasi (GDPR/CCPA)
Jika Anda men-scrape username, riwayat postingan, atau informasi pribadi apa pun yang dapat diidentifikasi, (UE) dan CCPA (California) bisa berlaku. Praktik terbaik: anonimisasi atau agregasikan data pribadi sebelum menyimpannya. Jangan membangun profil pengguna individu tanpa dasar hukum yang sah.
Lisensi Repo GitHub: Cek Sebelum Anda Membangun
Banyak repo reddit scraper github memakai lisensi MIT atau Apache (permisif), tetapi ada juga yang sama sekali tidak punya file lisensi—yang secara hukum berarti "all rights reserved." Sebelum melakukan fork, memodifikasi, atau membangun di atas sebuah repo, selalu cek file LICENSE. Tanpa lisensi = ambigu secara hukum, berapa pun jumlah bintangnya.
Penegakan Itu Nyata di 2025–2026
Kisah penegakan Reddit tidak berhenti di 2023. Reddit mengajukan keluhan terhadap Anthropic pada 2025 dengan tuduhan scraping/penggunaan konten Reddit tanpa izin, dan juga menempuh Reddit v. SerpApi pada akhir 2025. Ini menunjukkan bahwa Reddit bersedia menempuh penegakan hukum, bukan hanya pemblokiran teknis.
Memilih Pendekatan Reddit Scraper GitHub yang Tepat di 2026
Lanskap reddit scraper github telah berubah drastis sejak 2023. Kebanyakan repo sudah usang. Rate limit dan batas 1.000 postingan adalah kendala nyata. Pushshift sudah tidak tersedia bagi pengguna biasa. Dan tumpukan kebijakan Reddit kini lebih eksplisit dan lebih ditegakkan daripada sebelumnya.
Versi singkatnya:
- PRAW masih menjadi fondasi open-source paling andal jika Anda bisa menerima batas API Reddit dan ingin membangun logika kustom.
- Pushshift/PSAW bukan lagi jawaban umum.
- Modul Reddit snscrape sudah menjadi warisan lama dan tidak andal.
- Scraper .json dan endpoint publik rapuh dan sering diblokir pada 2026.
- Alat berbasis browser—baik repo Playwright maupun opsi tanpa kode seperti —adalah jalur paling praktis bagi banyak pengguna, terutama non-developer.
Mulailah dari use case Anda, bukan dari alatnya. Jalankan pemeriksaan kesehatan repo 5 menit sebelum berkomitmen ke proyek GitHub apa pun.
Dan jika Anda lebih ingin melewati setup dan mulai scraping Reddit dalam hitungan menit, .
FAQ
Apa scraper Reddit open-source terbaik di GitHub pada 2026?
tetap menjadi wrapper API paling andal, dengan pemeliharaan aktif dan dokumentasi yang baik. adalah alat CLI terawat yang kredibel dan dibangun di atas PRAW. Scraper berbasis Playwright bekerja untuk scraping non-API, dan modul Reddit milik snscrape berfungsi sebagian tetapi sebagian besar tidak lagi dipelihara. Selalu cek tanggal commit terakhir dan issue terbuka sebelum memakai repo apa pun—sebagian besar dari di GitHub sudah usang.
Apakah legal untuk men-scrape Reddit?
Scraping data yang tersedia untuk umum berada di wilayah abu-abu secara hukum, tetapi ketentuan Reddit sendiri cukup restriktif. , , , , dan semuanya membatasi scraping massal yang tidak diizinkan. Redistribusi komersial data hasil scraping mungkin memerlukan izin eksplisit dari Reddit. Jika Anda men-scrape data pribadi, GDPR dan CCPA juga bisa berlaku.
Bagaimana cara melewati rate limit API Reddit?
Gunakan exponential backoff, pantau header X-Ratelimit-Remaining, dan pertimbangkan chunking jendela waktu untuk tetap berada dalam batas. Scraping berbasis browser (Playwright atau ) melewati rate limit API karena ia men-scrape halaman yang sudah dirender, tetapi punya pertimbangan tersendiri (kecepatan pemuatan halaman, tindakan anti-bot). Tidak ada trik ajaib untuk menghapus rate limit sepenuhnya—semuanya ditegakkan di sisi server.
Bisakah saya men-scrape Reddit tanpa API key?
Bisa. Scraper berbasis Playwright dan trik URL .json tidak memerlukan API key. juga tidak membutuhkan API key karena men-scrape melalui browser. Komprominya: endpoint .json makin sering diblokir (menghasilkan 403 di banyak lingkungan per April 2026), dan scraping berbasis browser lebih lambat serta lebih boros sumber daya daripada panggilan API.
Apa yang terjadi dengan Pushshift untuk scraping Reddit?
Akses API publik Pushshift dihapus setelah perubahan lisensi data Reddit yang dimulai pada 2023. Wrapper diarsipkan dan sudah usang. Akses akademik terbatas mungkin masih ada melalui jalur yang disetujui, tetapi bagi sebagian besar pengguna yang mencari "reddit scraper github" hari ini, Pushshift bukan lagi opsi yang layak. Jika Anda membutuhkan data historis Reddit yang mendalam, lihat jalur data akademik atau berlisensi yang disetujui Reddit.
Pelajari Lebih Lanjut