
Kalau boleh jujur, tiap kali ada orang mengirim PDF penuh “data penting” dan berharap saya bisa menyulapnya jadi spreadsheet, mungkin saya sudah cukup kaya untuk beli stok kopi seumur hidup saya (dan mungkin beberapa ekstensi Chrome tambahan). PDF ada di mana-mana—kontrak penjualan, katalog produk, makalah riset, invoice, dan masih banyak lagi. Tapi begitu waktunya benar-benar memakai data di dalam file-file itu? Nah, di situlah serunya berubah jadi pusing.
Saya sudah pernah merasakannya langsung—copy, paste, merapikan format, lalu kadang menyerah begitu saja saat susunannya berantakan atau gambar dan tautan seperti lenyap begitu saja. Tapi kabar baiknya: dunia PDF scraping sudah berubah jauh, terutama dengan hadirnya alat bertenaga AI. Kalau Anda capek menghabiskan berjam-jam mengetik ulang angka atau frustrasi karena tabel yang rusak, Anda ada di tempat yang tepat. Mari kita bahas PDF scraping, kenapa ini penting, dan bagaimana alat seperti Thunderbit membuat semuanya jadi jauh lebih simpel.
Apa Itu PDF Scraping? Memahami Dasar-dasar Ekstraksi Data dari PDF
Mari mulai dari yang paling dasar: PDF scraping pada dasarnya adalah cara keren untuk bilang “mengambil data terstruktur dari file PDF—secara otomatis.” PDF scraper adalah alat (software, ekstensi, atau layanan) yang menarik data yang Anda butuhkan—teks, tabel, gambar, tautan, apa pun—lalu menaruhnya ke format yang benar-benar bisa dipakai, seperti Excel, Google Sheets, atau database.
Tapi ada satu masalah: PDF tidak seperti halaman web atau file Excel. PDF lebih mirip hasil cetak digital, dirancang agar tampilannya sama di mana-mana, bukan agar mudah diurai komputer. Ada PDF yang teksnya bisa dipilih, ada juga yang cuma gambar hasil pindai (yang butuh OCR—optical character recognition), dan formatnya bisa sangat berantakan. Jadi, scraping PDF bukan sekadar menyalin teks—melainkan memecahkan teka-teki tata letak, font, dan kadang metadata tersembunyi.
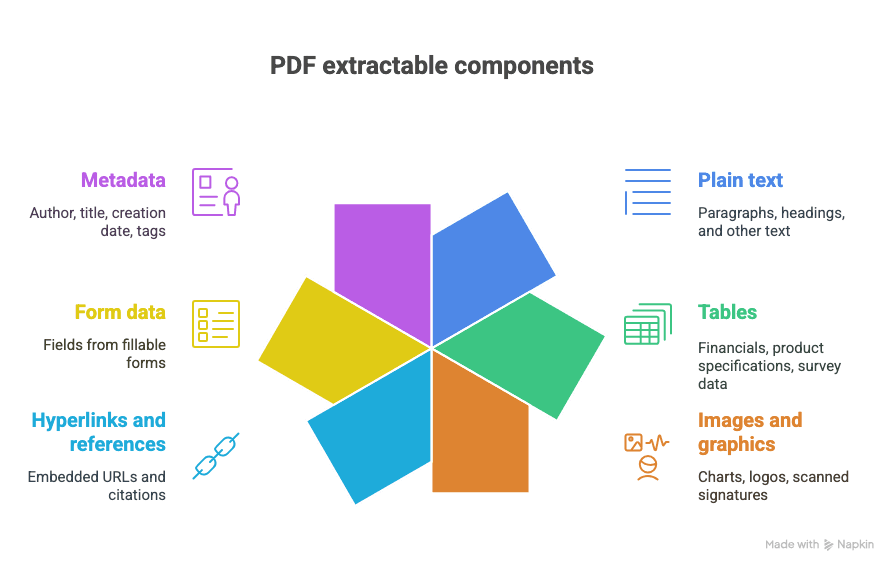
Apa saja yang bisa diekstrak dari PDF?
- Teks biasa (paragraf, judul, dan lain-lain)
- Tabel (misalnya: laporan keuangan, spesifikasi produk, data survei)
- Gambar dan grafik (bagan, logo, tanda tangan hasil pindai)
- Hyperlink dan referensi (URL tertanam, sitasi)
- Data formulir (kolom dari formulir yang bisa diisi)
- Metadata (penulis, judul, tanggal pembuatan, tag)
Dan ya, kadang semuanya bercampur aduk dalam satu dokumen yang benar-benar kacau.
Kenapa PDF Scraping Penting: Contoh Penggunaan di Dunia Nyata dan Manfaat Bisnis
Jadi, kenapa repot-repot scraping PDF? Karena semua orang memakainya, dan data di dalamnya sering kali sangat penting untuk bisnis. Inilah area di mana PDF scraping benar-benar berguna:
| Kasus Penggunaan | Pekerjaan Manual | Dengan PDF Scraper | Penghematan Waktu & Error |
|---|---|---|---|
| Ekstraksi Lead Penjualan | Berjam-jam menyalin kontak dari proposal atau PDF acara, berisiko melewatkan lead | Langsung menarik semua lead ke spreadsheet | 80–90% lebih cepat, lebih sedikit kesalahan |
| Data Produk E-commerce | Berhari-hari memasukkan spesifikasi produk dari PDF pemasok, format berantakan | Ekstraksi massal ke CSV atau Sheets | Hemat waktu 95%+, data konsisten |
| Analisis Data Riset | Berminggu-minggu mengetik ulang tabel dari paper akademik, risiko typo tinggi | Mengekstrak tabel, referensi, bahkan teks hasil pindai | Hemat waktu 80%, akurasi lebih tinggi |
Mari kita lihat angkanya:
- 2,5 triliun PDF dibuat setiap tahun.
- 90% organisasi menggunakan PDF sebagai format utama untuk berbagi informasi.
- Administrasi digital manual (seperti entri data PDF) menyita 40% jam kerja.
- Alat otomatis bisa menurunkan tingkat error dari 5–10% menjadi 1%.
Kalau Anda bekerja di penjualan, e-commerce, atau riset, mengotomatiskan ekstraksi data dari PDF bukan sekadar nice-to-have—ini keunggulan kompetitif.
Metode PDF Scraping Tradisional: Tantangan dan Keterbatasan
Jujur saja: cara lama untuk mengambil data dari PDF itu… tidak ideal. Berikut yang biasanya sudah pernah kita coba (dan kenapa hasilnya bikin frustrasi):

1. Copy-Paste Manual
- Titik sakit: Format jadi kacau, tabel berubah jadi berantakan, gambar dan tautan hilang, dan ujung-ujungnya kepala cenat-cenut.
- Biaya tenaga kerja: Tinggi. Kalau ada 5.000 PDF, bahkan 1 menit per file berarti 80+ jam hidup yang tidak akan kembali.
- Tingkat error: 5–10%. Salah ketik, baris terlewat, terhapus tidak sengaja—sudah pernah, tahu rasanya.
2. Konversi ke Word/Excel, Lalu Dirapikan
- Titik sakit: Kadang berhasil untuk dokumen sederhana, tapi tata letak atau tabel yang rumit biasanya berantakan. Tetap harus bersih-bersih.
- Gambar/tautan: Biasanya hilang entah ke mana.
- Ekstraksi terarah: Lupakan—yang didapat justru seluruh dokumen, bukan cuma data yang Anda butuhkan.
3. Script Kustom (Python, dll.)
- Titik sakit: Anda harus bisa coding (atau punya orang yang bisa dihubungi kapan saja). Setiap format PDF baru berarti script perlu disesuaikan. PDF hasil pindai? Semoga beruntung.
- Pemeliharaan: Tinggi. Setiap vendor mengubah template invoice, script Anda bisa rusak.
- Skalabilitas: Tidak cocok untuk yang mudah menyerah (atau yang non-teknis).
4. Konverter Online
- Titik sakit: Mudah untuk pekerjaan sekali pakai, tetapi Anda harus mengunggah dokumen sensitif ke server pihak ketiga (halo, masalah kepatuhan). Kontrol atas data yang diekstrak juga terbatas.
- Format: Hasilnya tidak selalu konsisten. Kadang waktu yang dihemat habis untuk merapikan hasilnya.
Intinya: Metode tradisional itu lambat, rawan error, dan sulit diskalakan. Itulah sebabnya banyak tim akhirnya cuma “menerimanya saja”—padahal biaya produktivitasnya besar.
Solusi Modern untuk PDF Scraping: Dari Kode ke Alat No-Code
Untungnya, kita sudah tidak terjebak di zaman gelap lagi. Lanskapnya sudah penuh dengan opsi PDF scraping yang lebih cerdas, lebih cepat, dan lebih ramah pengguna.
1. Library Pemrograman (Untuk Developer)
- Contoh: PyPDF2, PDFMiner, Tabula-py.
- Kelebihan: Sangat fleksibel, bisa diotomatisasi untuk batch besar, gratis (open source).
- Kekurangan: Setup lama, butuh kemampuan programming, rapuh (mudah rusak saat format baru muncul), dukungan OCR/gambar terbatas.
2. Konverter PDF Online
- Contoh: Smallpdf, PDF2Go, Zamzar.
- Kelebihan: Tanpa setup, mudah untuk non-teknis, cepat untuk pekerjaan kecil.
- Kekurangan: Kustomisasi terbatas, ada kekhawatiran privasi, kesalahan format, batas ukuran file/jumlah halaman.
3. PDF Scraper Bertenaga AI
- Contoh: Thunderbit, Nanonets, Docparser.
- Kelebihan: Tidak perlu coding, menangani teks/tabel/gambar/tautan, AI menyarankan apa yang perlu diekstrak, mendukung batch job, terintegrasi dengan Sheets/Notion/Airtable.
- Kekurangan: Sebagian punya batas kredit/halaman, mungkin butuh koneksi internet, kadang perlu sedikit pembelajaran untuk dokumen kompleks.
Membandingkan Alat PDF Scraping: Pendekatan Mana yang Cocok untuk Anda?
| Alat/Metode | Setup | Terbaik Untuk | Mengekstrak | Bisa Dikustomisasi? | Biaya |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Menengah (UI/coding) | Tabel dalam PDF | Tabel | Cukup | Gratis |
| PDFMiner | Perlu coding | PDF yang banyak teks | Teks | Ya (kode) | Gratis |
| PyPDF2 | Perlu coding | Teks/metadata sederhana | Teks, metadata | Ya (kode) | Gratis |
| Smallpdf/Konverter Online | Tidak ada (berbasis web) | Konversi cepat | Seluruh dokumen (Word/Excel) | Tidak | Freemium |
| Thunderbit | Instal 2 klik | Pengguna bisnis, tim | Teks, tabel, gambar, tautan | Ya (prompt AI) | Freemium ($16.5/bulan untuk Pro) |
Kenalan dengan Thunderbit: Ekstensi Chrome AI PDF Scraper
Cara Menarik Data dari PDF dengan AI Get Started Free
Sekarang, mari bahas alat yang membuat hidup saya (dan banyak pengguna bisnis lainnya) jauh lebih mudah: Thunderbit.
Apa yang membuat Thunderbit berbeda?
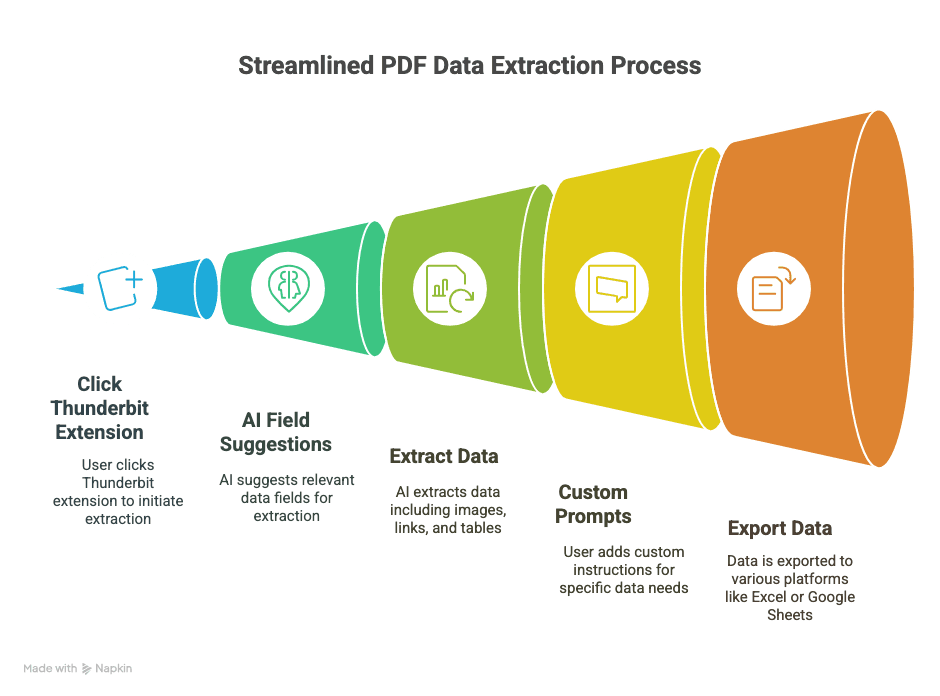
- Ekstraksi 2 klik: Buka PDF di Chrome, klik ekstensi Thunderbit, lalu biarkan AI mengerjakan sisanya.
- Saran field berbasis AI: Fitur “AI Suggest Fields” milik Thunderbit membaca PDF Anda dan merekomendasikan kolom yang kemungkinan Anda butuhkan (misalnya “Nama,” “Email,” “Harga,” dll.).
- Menangani gambar, tautan, dan tabel: Bukan cuma teks biasa—Thunderbit bisa menarik gambar, hyperlink, dan bahkan menjalankan OCR pada dokumen hasil pindai.
- Prompt kustom: Hanya butuh nomor telepon atau spesifikasi produk? Tambahkan instruksi khusus dan Thunderbit akan fokus ke itu saja.
- Ekspor ke mana saja: Kirim data langsung ke Excel, Google Sheets, Airtable, atau Notion. Tidak perlu lagi repot dengan CSV.
- Scraping batch dan subpage: Punya daftar PDF atau tautan? Thunderbit bisa memproses semuanya sekaligus.
- Keandalan kelas bisnis: Dirancang untuk akurasi, privasi, dan alur kerja dunia nyata.
Singkatnya, ini seperti punya asisten digital yang benar-benar suka mengerjakan entri data (dan tidak pernah capek).
Cara Menarik Data dari PDF dengan Thunderbit: Panduan Langkah demi Langkah
Unduh Ekstensi Chrome Thunderbit Get Started Free
Siap melihat betapa mudahnya? Ini cara saya memakai Thunderbit untuk mengubah PDF menjadi data terstruktur yang bisa dipakai:
1. Pasang Thunderbit
- Ambil Ekstensi Chrome Thunderbit.
- Daftar (pakai akun Google atau email—hanya butuh beberapa detik).
2. Buka PDF Anda di Chrome
- Bisa buka PDF dari tautan web atau seret PDF lokal ke tab Chrome.
3. Jalankan Thunderbit pada PDF
- Klik ikon Thunderbit di toolbar browser.
- Pilih “AI Web Scraper”—Thunderbit akan mendeteksi PDF dan siap bekerja.
4. Biarkan AI Menyarankan Field
- Klik “AI Suggest Columns.”
- AI Thunderbit memindai PDF dan merekomendasikan kolom (seperti “Tanggal,” “Jumlah,” “Nama Kontak,” dan sebagainya).
- Pratinjau data yang diekstrak dalam tabel langsung di dalam ekstensi.
5. Sesuaikan Jika Perlu
- Ubah nama kolom, hapus yang tidak perlu, atau tambahkan sendiri (misalnya “Masa Garansi” atau “URL Produk”).
- Untuk data yang rumit, pilih teks di PDF untuk melatih AI agar memahami apa yang Anda inginkan.
6. Pilih Format Ekspor
- Pilih CSV, Google Sheets, Airtable, atau Notion.
- Beri otorisasi agar Thunderbit terhubung (sekali saja).
7. Scrape dan Ekspor
- Klik “Scrape” atau “Export.”
- Thunderbit memproses PDF dan mengirim data ke tempat yang Anda mau—biasanya hanya dalam hitungan detik.
Coba PDF Scraper Thunderbit Sekarang
Selesai. Tanpa coding, tanpa copy-paste, tanpa drama.
Tips Agar Ekstraksi Data PDF dengan Thunderbit Lebih Akurat
- Tinjau field yang disarankan AI: AI memang pintar, tapi cek sekilas tetap penting agar Anda mendapatkan tepat apa yang dibutuhkan.
- Tangani tabel yang kompleks: Untuk tabel multi-halaman atau format yang aneh, gunakan pratinjau untuk menemukan masalah dan sesuaikan kolom seperlunya.
- Ekstrak gambar/tautan: Pastikan field ini ikut dipilih jika PDF Anda memilikinya—Thunderbit juga bisa mengambilnya.
- PDF hasil pindai: OCR bawaan Thunderbit cukup andal, tetapi makin bersih hasil pindai, makin baik hasilnya.
- Prompt kustom: Hanya mau email atau nomor telepon? Tambahkan prompt seperti “Ekstrak semua alamat email” dan Thunderbit akan fokus ke sana.
PDF Scraping Tingkat Lanjut: Mengekstrak Gambar, Tautan, dan Data Kustom
Thunderbit bukan cuma soal teks biasa. Begini cara Anda bisa memaksimalkan PDF Anda:
- Gambar: Ekstrak logo, bagan, atau grafik tertanam apa pun. Thunderbit bahkan bisa OCR teks di dalam gambar.
- Hyperlink: Ambil semua URL atau referensi—sangat berguna untuk makalah riset atau CV.
- Jenis data kustom: Gunakan prompt AI untuk mengekstrak hanya yang Anda butuhkan (misalnya, “Temukan semua SKU produk dan harganya”).
- Ringkasan dan kategorisasi: Tambahkan kolom lalu minta Thunderbit meringkas suatu bagian atau mengkategorikan data secara langsung.
Mengurai Data dari PDF untuk Kebutuhan Bisnis Tertentu
- Penjualan: Ekstrak hanya info kontak dari batch proposal.
- E-commerce: Tarik spesifikasi produk, harga, dan gambar dari katalog pemasok.
- Riset: Ambil tabel, referensi, dan bahkan buat ringkasan dari paper akademik.
Dan setelah datanya Anda dapatkan, susun agar mudah dianalisis di Excel, Google Sheets, atau Notion—Thunderbit yang mengerjakan bagian beratnya, Anda tinggal memakai hasilnya.
Mengekspor dan Memakai Data PDF Anda: Dari Ekstraksi ke Tindakan
Mengambil data hanyalah langkah awal. Berikut cara memanfaatkannya:
- Opsi ekspor: CSV, Excel, Google Sheets, Airtable, Notion—pilih yang paling Anda suka.
- Tips format: Gunakan pengaturan tipe kolom Thunderbit (angka, tanggal, teks) agar data rapi dan siap dianalisis.
- Integrasi alur kerja: Hubungkan data hasil ekspor ke CRM, sistem inventaris, atau dashboard analitik.
- Kolaborasi: Bagikan Google Sheets atau basis Airtable dengan tim Anda—semua orang bekerja dari data yang sama dan selalu terbaru.
Bagian terbaiknya? Tidak perlu lagi kirim-kiriman spreadsheet lewat email atau bertanya-tanya apakah ada baris yang terlewat.
Kesalahan Umum dalam PDF Scraping dan Cara Menghindarinya
Bahkan dengan alat terbaik, beberapa masalah tetap bisa muncul. Inilah yang saya pelajari (kadang dengan cara yang cukup menyakitkan):
- Error OCR: Hasil pindai buram atau font aneh bisa menjatuhkan OCR terbaik sekalipun. Usahakan pakai PDF yang paling bersih, lalu cek lagi field penting.
- Tata letak kompleks: Tabel multi-kolom atau bertingkat mungkin butuh sedikit arahan manual—gunakan seleksi manual atau prompt Thunderbit.
- Jenis data: Angka dengan koma atau tanggal dalam format aneh? Atur tipe kolom sebelum ekspor, atau rapikan di Excel/Sheets.
- Batas ukuran file/halaman: PDF yang sangat besar? Pecah menjadi bagian lebih kecil, atau gunakan mode cloud Thunderbit untuk batch job.
- “Halusinasi” AI: Jarang terjadi, tapi kadang AI bisa menebak nama kolom atau mengisi data yang hilang. Selalu cek hasilnya, terutama untuk angka penting.
- Tinjauan manual: Untuk data yang sangat penting, lakukan validasi cepat—alat otomatis memang akurat, tapi mata manusia tetap berguna.
Kalau Anda mentok, dukungan dan komunitas Thunderbit siap membantu.
Kesimpulan & Poin Penting: Membuat PDF Scraping Bekerja untuk Bisnis Anda
Mari kita tutup. Dulu, scraping data dari PDF adalah mimpi buruk—lambat, rawan error, dan benar-benar membosankan. Tapi dengan alat modern seperti Thunderbit, sekarang prosesnya cepat, akurat, dan—boleh saya bilang—hampir menyenangkan.
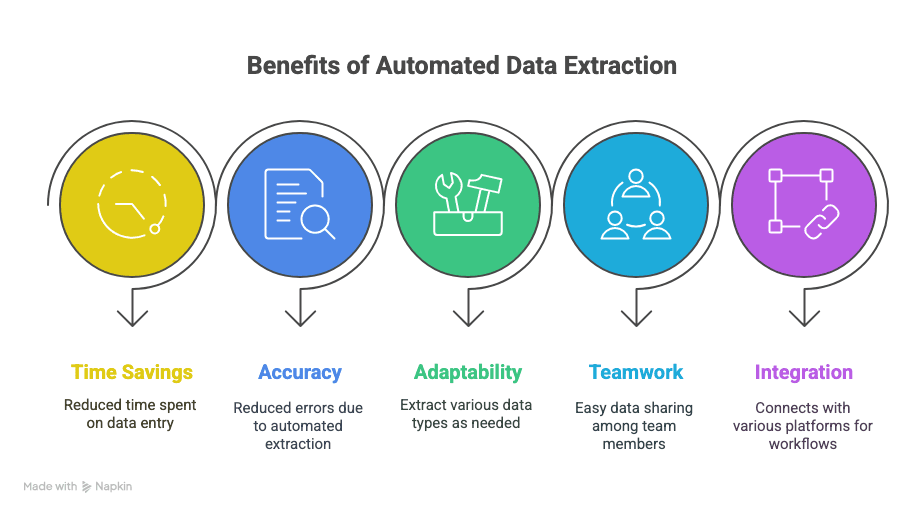
Yang Anda dapatkan:
- Waktu kembali: Hemat berjam-jam (bahkan berminggu-minggu) dari entri data manual.
- Lebih sedikit kesalahan: Ekstraksi otomatis berarti lebih sedikit typo dan baris yang terlewat.
- Fleksibilitas: Ekstrak tepat yang Anda butuhkan—teks, tabel, gambar, tautan, apa saja.
- Kolaborasi: Bagikan data seketika dengan tim Anda, di mana pun mereka berada.
- Alur kerja yang lebih cerdas: Terintegrasi dengan Sheets, Notion, Airtable, dan lainnya.
Siap mencobanya? Unduh Ekstensi Chrome Thunderbit, jalankan pada PDF Anda berikutnya, dan rasakan betapa lebih mudahnya hidup. Diri Anda di masa depan (dan pergelangan tangan Anda) akan berterima kasih.
Untuk tips dan panduan lainnya, cek Blog Thunderbit atau pelajari lebih dalam lewat Cara Menarik Data dari PDF dengan AI.
Mari ubah pusing karena PDF menjadi kemenangan produktivitas—satu klik pada satu waktu.
Shuai Guan, Co-founder & CEO, Thunderbit
Coba Thunderbit AI PDF Scraper Get Started Free




