Studi berbasis crawling tentang bagaimana situs web dengan trafik tinggi mempublikasikan panduan yang bisa dibaca mesin untuk model bahasa besar, seperti apa implementasi awalnya, dan mengapa mengukur adopsi butuh lebih dari sekadar menghitung respons HTTP 200.
- Dataset:
data/llms_probe_results_top_10000.csv - Daftar Tranco diunduh: 6 Mei 2026
- Cakupan:
/llms.txtdan/llms-full.txtdi level root
Metrik Utama
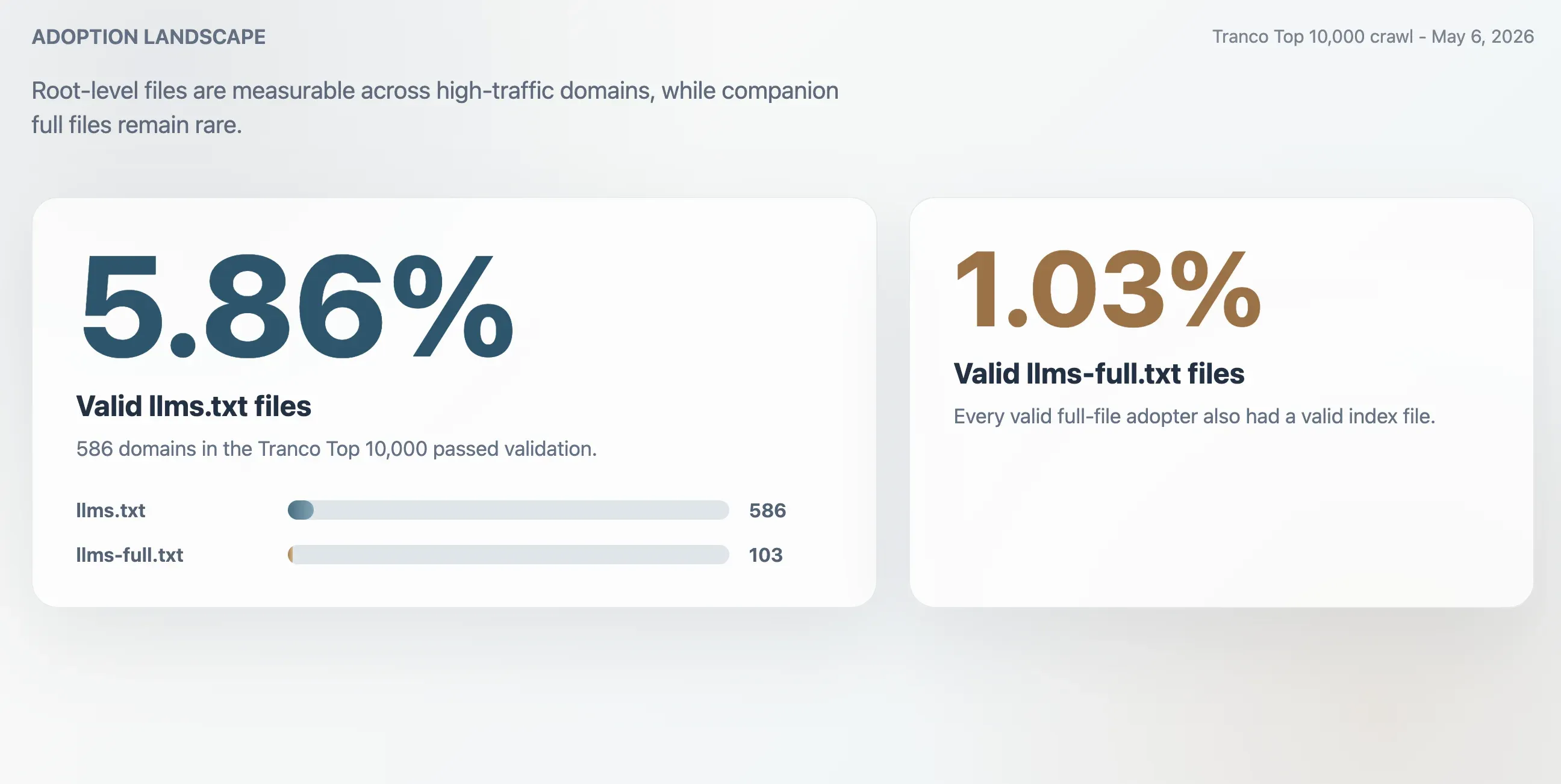
- 5,86%: Adopsi valid
llms.txtdi Tranco Top 10.000, setara dengan 586 domain. - 1,03%: Adopsi valid
llms-full.txt, setara dengan 103 domain. Setiap pengadopsi full-file yang valid juga memiliki file indeks yang valid. - 63,51%: Proporsi respons HTTP 200 untuk
/llms.txtyang gagal validasi. - 2,74x: Perkiraan pembesaran angka jika adopsi diukur hanya dari respons HTTP 200 mentah.
Ringkasan Eksekutif
llms.txt masih merupakan konvensi web yang baru, tetapi sudah bukan eksperimen pinggiran lagi. Dalam crawling Tranco Top 10.000 pada 6 Mei 2026, studi ini menemukan 586 file llms.txt yang valid, dengan tingkat adopsi teramati 5,86%. File pendamping llms-full.txt jauh lebih jarang: 103 domain memiliki file full yang valid, dengan tingkat adopsi 1,03%.
Temuan metodologis terpenting adalah bahwa kode status merupakan proksi yang buruk untuk adopsi. Crawler mencatat 1.606 respons HTTP 200 untuk /llms.txt, tetapi hanya 586 yang lolos validasi. Sisanya, 1.020, sebagian besar berupa pengalihan ke halaman yang tidak relevan, halaman HTML generik, body kosong, atau respons tidak valid lainnya. Crawler naif yang menghitung setiap respons 200 sebagai adopsi akan melebih-lebihkan adopsi valid sekitar 2,74 kali.
Di antara para pengadopsi valid, kualitas implementasi lebih tinggi daripada yang disiratkan narasi sekadar placeholder. Ukuran median file valid sekitar 7,1 KB, 61,77% file valid lebih besar dari 5 KB, 70,82% berisi enam atau lebih bagian Markdown, dan 77,47% berisi 11 atau lebih tautan Markdown. Kelompok pengadopsi awal mencakup Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog, dan Cloudinary.
llms.txtpaling tepat dipahami sebagai sinyal penjelas dan navigasi untuk sistem AI, bukan sebagai penggantirobots.txt. Nilainya bukan sekadar file itu ada, melainkan apakah file tersebut membantu mesin menemukan informasi yang otoritatif, ringkas, dan mutakhir.
Konteks: Web Menambahkan Sinyal untuk AI
Situs web sudah lama memakai robots.txt untuk menyatakan preferensi crawler, sitemap.xml untuk membantu penemuan URL, dan data terstruktur untuk membantu mesin pencari serta platform memahami halaman. Generative AI menghadirkan masalah yang berbeda. Konten bisa dipakai untuk training, retrieval, ringkasan, penjelajahan agenik, bantuan coding, dukungan pelanggan, dan pembuatan jawaban. Itu menciptakan dua kebutuhan sekaligus: penerbit ingin kontrol lebih atas penggunaan otomatis, tetapi mereka juga ingin sistem AI menemukan informasi kanonik yang tepat saat sistem itu memang berinteraksi dengan situs mereka.
, yang diperkenalkan oleh Jeremy Howard pada 2024, memosisikan file ini sebagai dokumen Markdown di root situs untuk menyediakan informasi yang ramah LLM pada saat inferensi. Proposal tersebut berargumen bahwa halaman HTML sering berisi navigasi, iklan, skrip, dan noise lain yang membuatnya lebih sulit diproses model bahasa. File Markdown yang ringkas dapat mengarahkan model ke halaman, dokumentasi, API, contoh, kebijakan, dan informasi produk yang paling penting.
Riset web eksternal memberikan latar yang lebih luas. menggambarkan lonjakan cepat pembatasan terkait AI di robots.txt dan terms of service, serta berargumen bahwa mekanisme persetujuan web yang ada tidak dirancang untuk penggunaan ulang data AI dalam skala besar. juga membuat pola crawler AI dan robots.txt terlihat pada level Top 10.000 domain. Dalam lingkungan itu, llms.txt berada di sisi konstruktif dari penandaan AI: bukan “jangan crawl ini,” melainkan “kalau kamu perlu memahami situs ini, mulai dari sini.”
Bukti Eksternal dan Perdebatan Adopsi
Perdebatan publik soal llms.txt terbagi antara dua klaim. Klaim optimistisnya adalah bahwa file ini memberi sistem AI jalur yang lebih bersih dan efisien menuju konten otoritatif. Klaim skeptisnya adalah bahwa belum ada penyedia LLM besar yang secara publik berkomitmen memakai file ini sebagai sinyal peringkat, crawling, atau sitasi, sehingga penerbit sebaiknya tidak mengharapkan kenaikan trafik hanya dari file tersebut. Tiga referensi eksternal yang ditinjau untuk pembaruan ini mendukung kesimpulan yang lebih bernuansa: llms.txt adalah infrastruktur yang berguna, tetapi bukti dampak trafik langsung masih terbatas dan bergantung pada konteks.
Tolok Ukur Adopsi Eksternal Bergerak Cepat
melaporkan tingkat adopsi 0,3% di 1.000 situs teratas per 22 Juni 2025, atau 3 dari 1.000 situs. Mereka menjelaskan pemindaian otomatis bulanan ke domain.com/llms.txt, dengan validasi yang mengecualikan redirect dan respons HTML. Metodologi ini secara arah serupa dengan pendekatan validasi konservatif dalam studi ini.
Perbedaannya besar: studi ini menemukan 75 file llms.txt valid di Tranco Top 1.000 pada 6 Mei 2026, atau 7,50%. Kedua angka ini tidak boleh diperlakukan sebagai deret waktu yang ketat karena sumber peringkat, detail implementasi, logika validasi, dan waktu crawling bisa berbeda. Namun, kontrasnya menunjukkan bahwa adopsi berubah secara material antara pertengahan 2025 dan Mei 2026, terutama di situs yang berfokus pada developer, SaaS, cloud, keamanan, dan dokumentasi.
| Sumber | Snapshot | Sampel | Adopsi valid yang dilaporkan | Interpretasi |
|---|---|---|---|---|
| Rankability | 22 Juni 2025 | 1.000 situs teratas | 0,3% | Tolok ukur publik awal yang menunjukkan adopsi sangat minim di pertengahan 2025. |
| Studi ini | 6 Mei 2026 | Tranco Top 1.000 | 7,50% | Crawling yang lebih baru menunjukkan adopsi yang terlihat di situs dengan trafik tinggi. |
| Studi ini | 6 Mei 2026 | Tranco Top 10.000 | 5,86% | Sampel yang lebih luas menunjukkan adopsi bisa diukur, tetapi belum arus utama. |
Eksperimen Trafik Masih Beragam
menerbitkan analisis 10 situs pada Januari 2026 yang melacak situs selama 90 hari sebelum dan 90 hari sesudah implementasi. Artikel itu melaporkan dua situs mengalami kenaikan trafik AI sebesar 12,5% dan 25%, delapan tidak menunjukkan peningkatan yang terukur, dan satu turun 19,7%. Interpretasi utamanya adalah kehati-hatian kausal: dua kisah sukses yang tampak itu juga meluncurkan template baru, membangun ulang resource center, menambahkan tabel perbandingan yang mudah diekstrak, mendapat liputan pers, memperbaiki isu teknis, atau menerbitkan konten FAQ baru. Dalam kerangka itu, llms.txt mendokumentasikan pekerjaan konten dan teknis yang lebih kuat; file itu tampaknya tidak menyebabkan pertumbuhan sendirian.
mencapai kesimpulan yang lebih positif dari observasi skala situs yang lebih kecil. Ia membandingkan dua periode empat bulan di Yandex.Metrica setelah menambahkan llms.txt dan llms-full.txt. Sesi rujukan dari LLM naik dari 75 menjadi 92, kenaikan 23%, sementara pengguna naik dari 51 menjadi 64. Sesi dari Perplexity naik dari 29 menjadi 55, sedangkan sesi dari ChatGPT turun dari 31 menjadi 26. Post yang sama juga mencatat trafik rujukan total tumbuh lebih cepat, dari 160 menjadi 290 sesi, sehingga porsi sesi LLM turun dari 47% menjadi 32%.
This paragraph contains content that cannot be parsed and has been skipped.
Apa yang Dijelaskan Perdebatan Ini
Bukti eksternal mempertajam interpretasi dataset ini. File llms.txt yang terstruktur dengan baik dapat mengurangi friksi parsing mesin, terutama untuk dokumentasi developer, referensi API, dan konten knowledge base. Tetapi kasus trafik terkuat tetap tampaknya bergantung pada konten yang berguna, mudah diekstrak, otoritatif, dan bisa ditemukan di luar file tersebut. Karena itu, pertanyaan praktisnya bukan “apakah llms.txt penting?” secara terpisah. Yang penting adalah apakah file itu menjadi bagian dari sistem konten yang dapat dibaca AI yang lebih luas.
Interpretasi yang diperbarui:
llms.txtsebaiknya diimplementasikan sebagai infrastruktur berbiaya rendah untuk AI. File ini tidak boleh diposisikan sebagai pengganti dokumentasi yang lebih baik, konten terstruktur, aksesibilitas teknis, sitasi, tautan, atau otoritas merek.
Metodologi
Studi ini menggunakan domain Tranco Top 10.000 sebagai sampel. Tranco adalah peringkat situs teratas yang berorientasi riset dan dirancang agar lebih stabil serta lebih tahan manipulasi dibandingkan banyak daftar top-site tradisional. File sumber Tranco diunduh pada 6 Mei 2026, dengan timestamp Last-Modified sumber pada 5 Mei 2026 pukul 22:17:59 GMT.
Crawler memeriksa dua path di level root untuk setiap domain:
https://example.com/llms.txt, dengan fallback HTTP bila diperlukan.https://example.com/llms-full.txt, dengan fallback HTTP bila diperlukan.
Untuk setiap probe, crawler mencatat kode status, URL akhir, metode fetch, byte respons, content type, pesan error, waktu berlalu, dan hasil validasi. Body respons yang sukses disimpan di bawah raw_llms_txt/ untuk ditinjau dan dianalisis lebih lanjut.
Aturan Validasi
Sebuah respons dihitung sebagai file valid hanya jika ia mengembalikan body yang sukses dan tidak tampak seperti fallback web generik. Path URL akhir harus tetap /llms.txt atau /llms-full.txt. Body kosong ditolak. Dokumen HTML yang jelas dan app shell ditolak. Content type diperlakukan sebagai bukti pendukung, bukan satu-satunya aturan, karena sejumlah kecil file yang valid dan mirip teks disajikan dengan content type yang tidak biasa.
Lanskap Adopsi
Crawling menemukan 586 file llms.txt valid di Tranco Top 10.000. Ini menghasilkan tingkat adopsi valid 5,86%. File pendamping llms-full.txt yang lebih kecil hadir dan valid di 103 domain, atau 1,03% dari sampel.
| Metrik | Jumlah | Porsi Top 10.000 |
|---|---|---|
| Domain yang di-crawl | 10.000 | 100,00% |
| File llms.txt valid | 586 | 5,86% |
| File llms-full.txt valid | 103 | 1,03% |
| Respons HTTP 200 untuk /llms.txt | 1.606 | 16,06% |
| Respons HTTP 200 yang ditolak sebagai tidak valid | 1.020 | 10,20% |
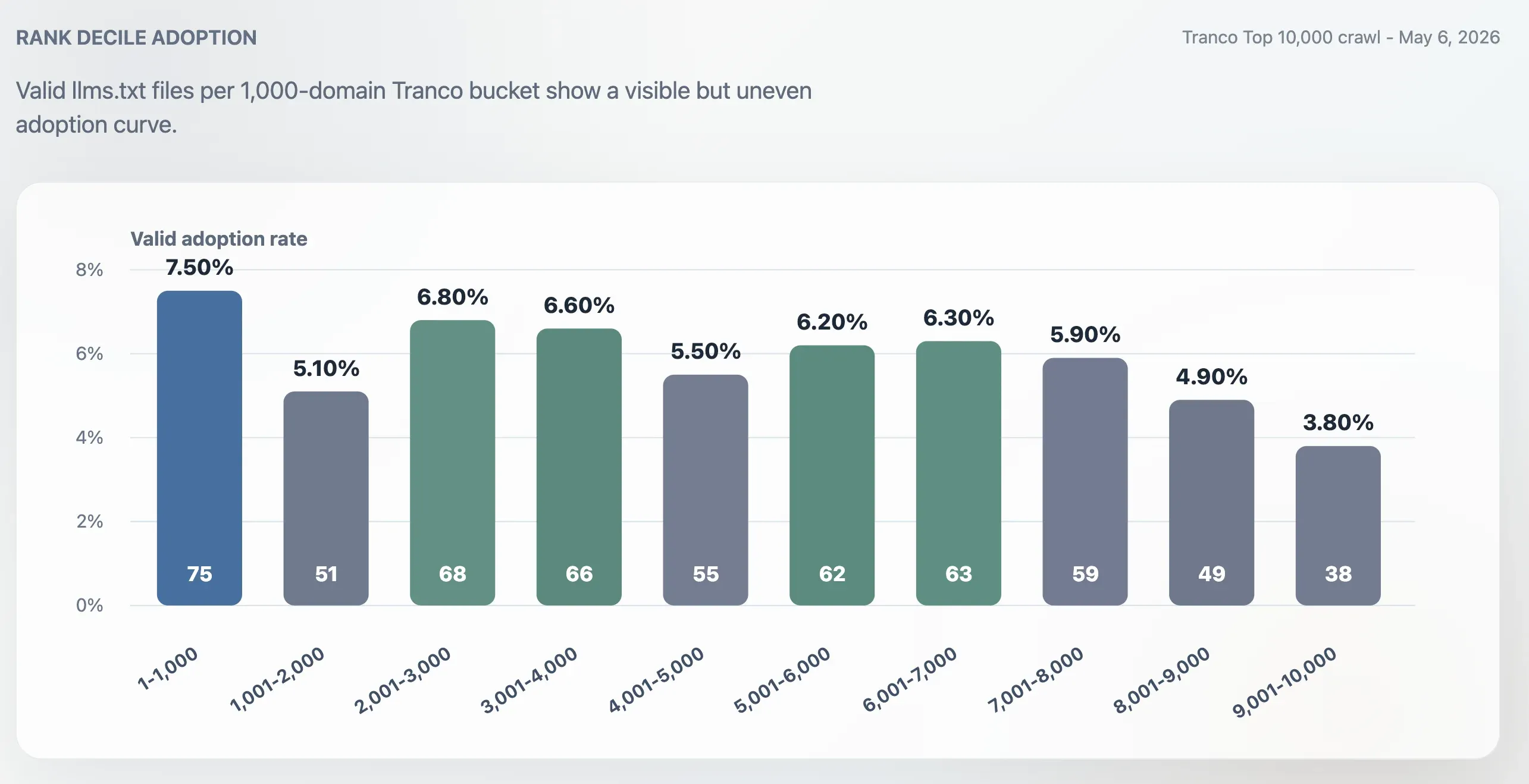
Adopsi Tidak Murni Bertumpu di Puncak
Adopsi lebih tinggi di Top 1.000 dibandingkan seluruh Top 10.000, tetapi tidak terbatas pada situs-situs terbesar. Tingkat adopsi Top 1.000 adalah 7,50%. Kelompok 1.000 domain terakhir, peringkat 9.001-10.000, turun menjadi 3,80%. Bagian tengah peringkat tetap aktif: bucket 2.001-3.000, 3.001-4.000, 5.001-6.000, dan 6.001-7.000 semuanya berada di sekitar 6%.
Pengadopsi Awal
Pengadopsi valid dengan peringkat tertinggi adalah Cloudflare di peringkat Tranco 4. Pengadopsi peringkat tinggi lainnya termasuk Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink, dan OneSignal.
Para pengadopsi ini bukan acak. Mereka cenderung memiliki permukaan dokumentasi yang besar, lini produk yang butuh penjelasan, API atau ekosistem developer, konten dukungan, halaman harga, materi keamanan dan privasi, serta otoritas merek yang cukup untuk peduli bagaimana sistem AI menafsirkan situs mereka.
| Peringkat | Domain | Ukuran file | Pola yang diamati |
|---|---|---|---|
| 4 | cloudflare.com | 4.225 B | Indeks ringkas untuk produk, developer, perusahaan, dan harga. |
| 26 | azure.com | 47.037 B | Tool developer, AI, komputasi, penyimpanan, keamanan, pemantauan, dan resource opsional. |
| 28 | github.com | 27.108 B | Akses programatik, Copilot, MCP, REST API, Actions, repositori, dan tautan CLI. |
| 248 | stripe.com | 64.229 B | Pembayaran, Connect, Checkout, Billing, Tax, Atlas, Radar, dan dokumentasi developer. |
| 265 | salesforce.com | 1,02 MB | Katalog link produk dan Agentforce yang sangat besar, tanpa heading bagian Markdown. |
Kategori Pengadopsi Top 1.000
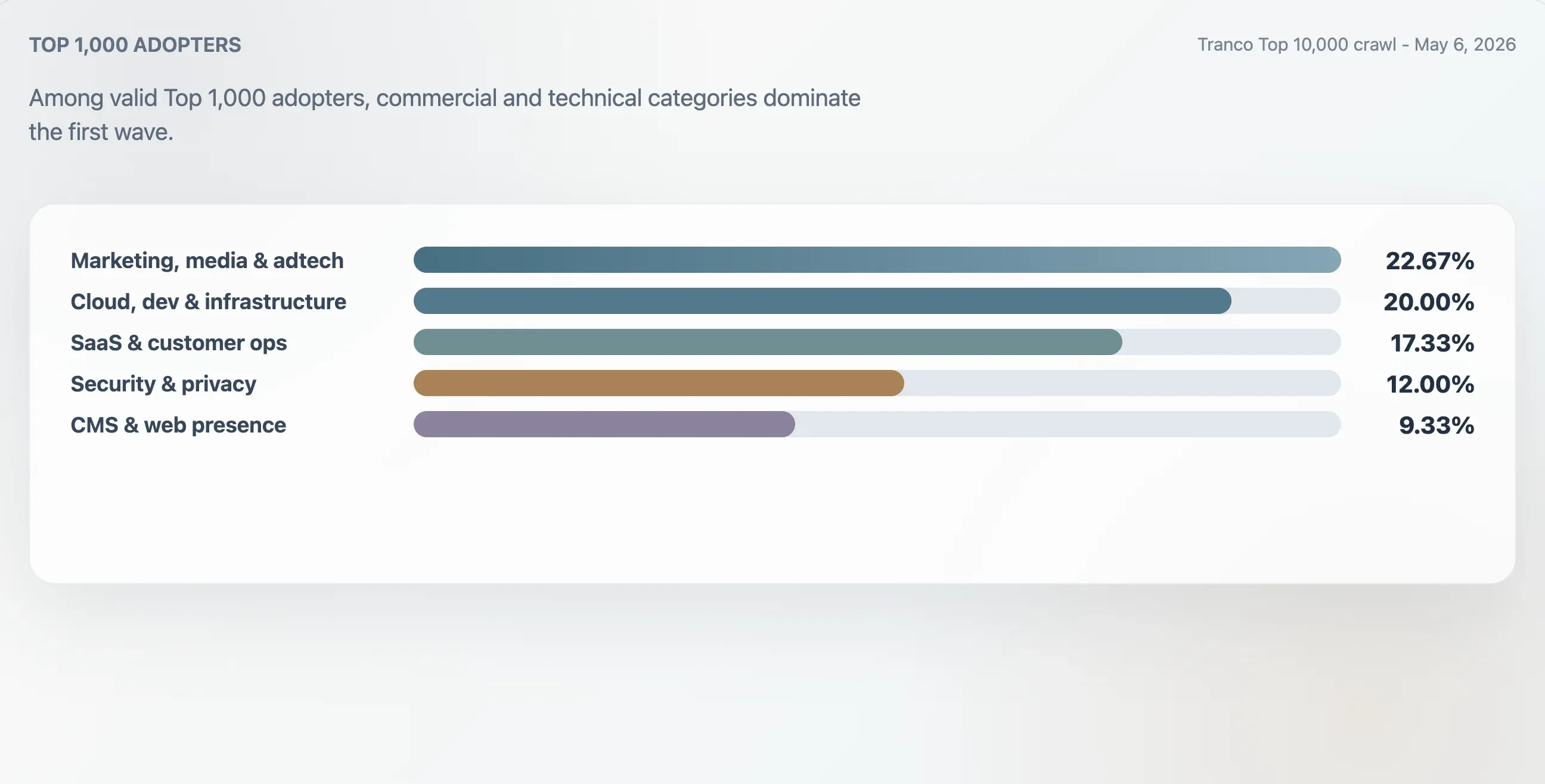
Studi ini mengelompokkan 75 pengadopsi valid di Tranco Top 1.000 menggunakan konteks domain, heading pertama, struktur file mentah, dan kata kunci konten. Kelompok terbesar adalah marketing, media, dan adtech sebesar 22,67%. Situs cloud, developer, dan infrastruktur mencakup 20,00%. Situs SaaS, produktivitas, dan operasional pelanggan mencakup 17,33%. Situs keamanan, identitas, dan privasi mencakup 12,00%.
| Kategori | Domain | Porsi pengadopsi Top 1.000 | Skor kualitas median | Tautan median |
|---|---|---|---|---|
| Marketing, media & adtech | 17 | 22,67% | 94 | 25 |
| Cloud, dev & infrastructure | 15 | 20,00% | 94 | 62 |
| SaaS, productivity & customer ops | 13 | 17,33% | 94 | 46 |
| Security, identity & privacy | 9 | 12,00% | 98 | 78 |
| CMS, hosting & web presence | 7 | 9,33% | 100 | 24 |
Pola TLD
Top-level domain bukan label industri, tetapi berguna sebagai sinyal arah. Di antara TLD dengan setidaknya 50 domain dalam sampel, .io memiliki tingkat adopsi valid tertinggi di 14,44%. .com menyusul di 8,19%. Adopsi yang lebih rendah pada .gov, .edu, dan .net menunjukkan bahwa basis pengadopsi awal lebih bersifat komersial dan teknis daripada institusional.
Kualitas Implementasi
Adopsi valid tidak berarti kualitas implementasi seragam. Ada file yang ringkas, terstruktur, dan berfungsi sebagai indeks yang baik. Ada yang kebanyakan berisi narasi. Ada yang hanya katalog tautan mentah. Ada yang hampir kosong dan sekadar placeholder. Ada juga dump konten berukuran beberapa megabyte yang mungkin lengkap tetapi mahal untuk diambil dan diurai.
Di antara file llms.txt yang valid, 362 berukuran lebih besar dari 5 KB, atau 61,77% dari pengadopsi valid. Ukuran median file sekitar 7,1 KB. Ukuran file pada P90 adalah 156 KB, P95 adalah 356 KB, P99 adalah 2,54 MB, dan file terbesar yang diamati adalah 7,97 MB.
Sinyal Konten Umum
Pemindaian level kata kunci pada file valid menemukan bahwa banyak situs bukan sekadar mempublikasikan deklarasi; mereka mengarahkan model ke materi yang berguna secara operasional. Istilah dukungan atau bantuan muncul di 70,31% file valid. Istilah blog, panduan, atau tutorial muncul di 67,92%. Istilah keamanan, privasi, kepatuhan, atau terms muncul di 61,43%. Harga muncul di 53,92%, dokumentasi di 52,22%, istilah API di 33,96%, dan sinyal changelog atau rilis di 27,30%.
Skoring Kualitas dan Arketipe
Untuk bergerak dari keberadaan ke kematangan, studi ini membuat skor implementasi ringan. Skor mempertimbangkan tipe konten, ukuran file, struktur Markdown, jumlah tautan, cakupan topik, dan tanda bahaya seperti heading yang hilang, tidak ada tautan Markdown, content type yang tidak biasa, file yang terlalu kecil, file yang sangat besar, dan perilaku seperti link dump. Ini bukan standar formal. Ini adalah model skoring riset untuk membandingkan implementasi yang diamati.
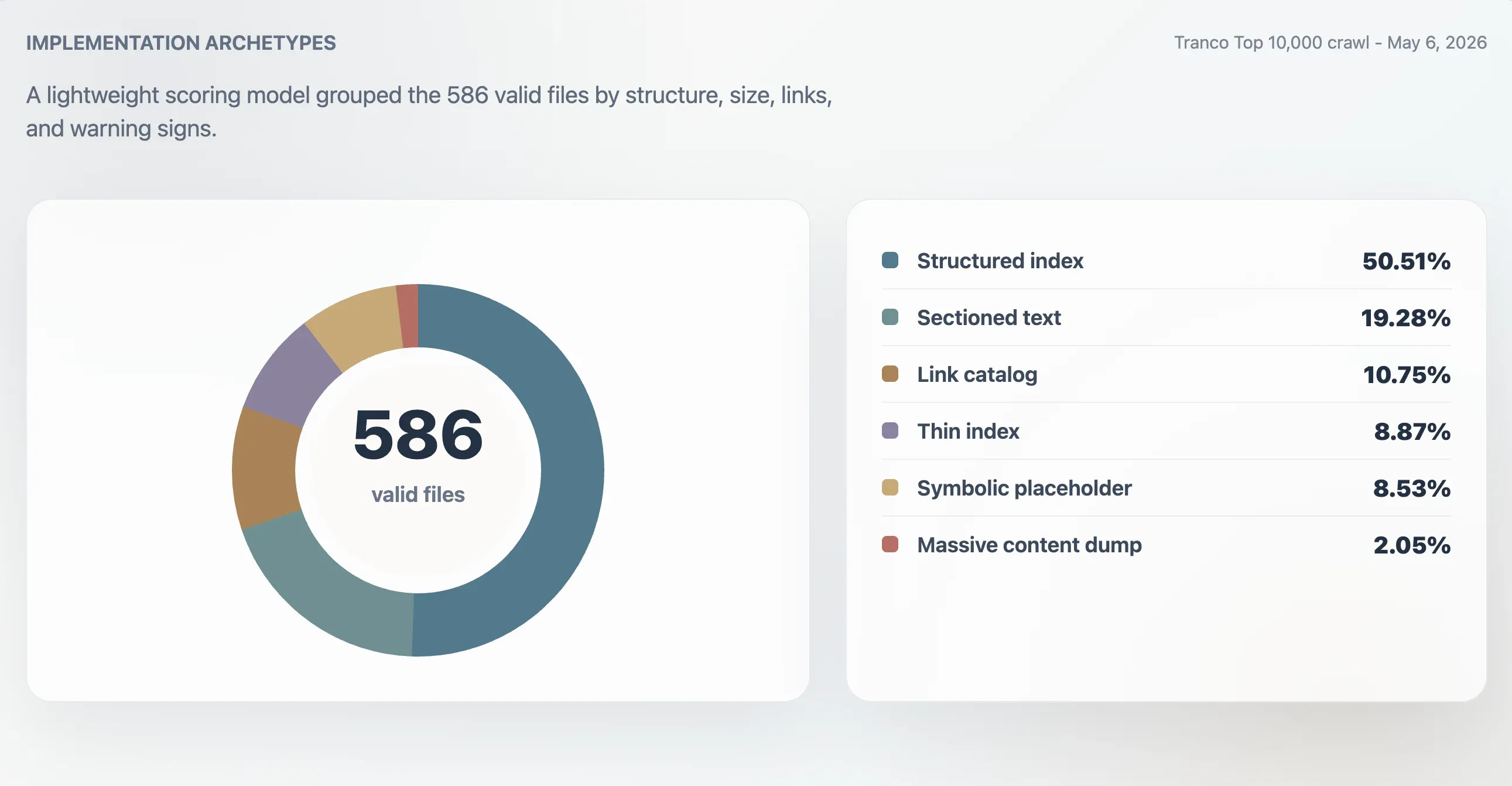
Dengan model ini, 416 file valid diklasifikasikan sebagai indeks terstruktur yang kuat, 107 sebagai indeks yang dapat dipakai, 24 sebagai tipis atau tidak beraturan, dan 39 sebagai simbolik atau utilitas rendah. Analisis arketipe terpisah menemukan 296 indeks terstruktur, 113 file teks terbagian, 63 katalog tautan, 52 indeks tipis, 50 file simbolik atau placeholder, dan 12 dump konten masif.
| Arketipe | Domain | Porsi file valid | Skor median | Ukuran file median | Tautan median |
|---|---|---|---|---|---|
| Indeks terstruktur | 296 | 50,51% | 98 | 11.241 B | 61,5 |
| Teks terbagian | 113 | 19,28% | 78 | 4.718 B | 0 |
| Katalog tautan | 63 | 10,75% | 86 | 4.160 B | 23 |
| Indeks tipis | 52 | 8,87% | 66 | 2.814 B | 0 |
| Simbolik atau placeholder | 50 | 8,53% | 27 | 15 B | 0 |
| Dump konten masif | 12 | 2,05% | 74 | 2,84 MB | 7.259,5 |
Pengadopsi Teratas Memiliki Implementasi yang Lebih Padat
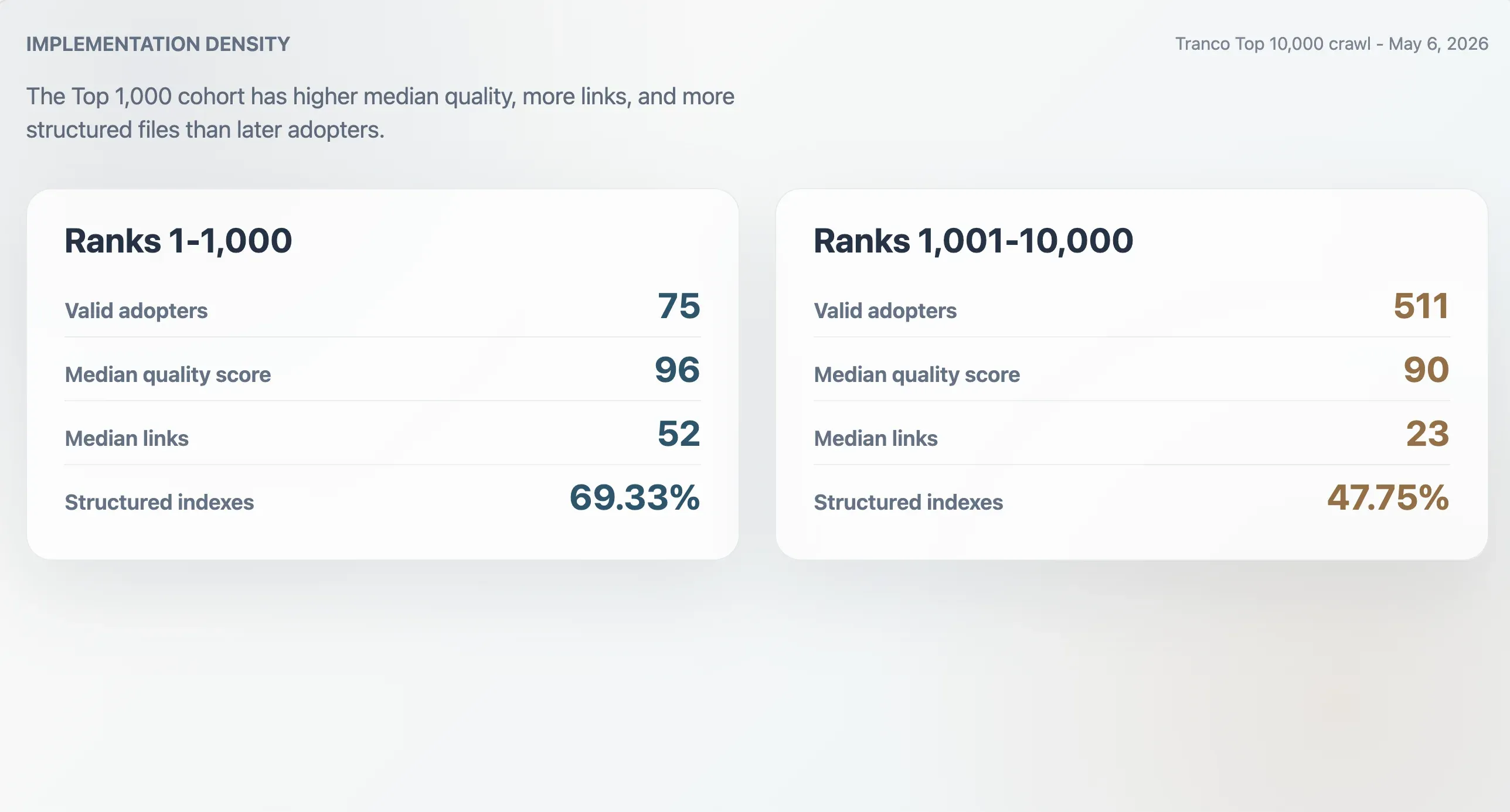
75 pengadopsi valid di Tranco Top 1.000 memiliki skor kualitas median 96, ukuran file median 9.068 byte, jumlah tautan Markdown median 52, dan jumlah bagian median 11. 511 pengadopsi yang berada di peringkat 1.001-10.000 memiliki median yang lebih rendah: skor 90, ukuran file 6.506 byte, 23 tautan Markdown, dan 9 bagian. Pengadopsi Top 1.000 juga lebih mungkin berupa indeks terstruktur: 69,33% versus 47,75% pada kohort yang lebih akhir.
Masalah False Positive

Risiko pengukuran terbesar adalah false positive. Dari 1.606 domain yang mengembalikan HTTP 200 untuk /llms.txt, 1.020 gagal validasi. Alasan invalid yang paling umum adalah pengalihan ke tujuan yang salah, dengan 618 kasus. Ada 367 respons HTML generik. Dua puluh sembilan mengembalikan body kosong, dan enam adalah respons invalid lain atau tak terkategorikan.
Ini penting karena banyak situs besar mengarahkan path yang tidak dikenal ke halaman login, homepage, app shell, halaman regional, permukaan consent, atau fallback marketing. Respons ini bisa tampak sehat bagi crawler berbasis kode status, tetapi tidak mengandung sinyal llms.txt yang valid.
llms-full.txt: Lebih Langka dan Lebih Tidak Merata
File pendamping llms-full.txt jauh lebih jarang daripada llms.txt. Crawling menemukan 103 full file yang valid, setara dengan 17,58% dari pengadopsi llms.txt valid dan 1,03% dari sampel Top 10.000 secara keseluruhan.
Implementasi full-file tidak merata. Di antara 103 pengadopsi dua-file, 57 memiliki file llms-full.txt yang lebih besar daripada file indeks, tetapi 46 lainnya memiliki file full yang tidak lebih besar dari file indeks atau file full di bawah 100 byte. Rasio ukuran full terhadap indeks median adalah 1,43, tetapi kasus ekstrem jauh lebih tinggi. File full Supabase kira-kira 7.139 kali ukuran file indeksnya. Made-in-China.com memiliki file full berukuran 89,89 MB.
| Domain | llms.txt | llms-full.txt | Rasio |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7.139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Rekomendasi: publikasikan
llms-full.txthanya ketika situs sudah memiliki pipeline dokumentasi yang stabil, disiplin versioning, dan alasan yang jelas untuk mengekspos volume konten besar dalam satu file yang bisa dibaca mesin.
llms.txt, robots.txt, dan sitemap.xml
llms.txt tidak boleh diperlakukan sebagai robots.txt yang baru. Keduanya sama-sama file yang bisa dibaca mesin di level root, tetapi keduanya mengomunikasikan hal yang berbeda. robots.txt adalah sinyal preferensi crawler dan kontrol akses. sitemap.xml adalah sinyal penemuan URL. llms.txt adalah sinyal penjelas dan navigasi.
This paragraph contains content that cannot be parsed and has been skipped.
Rekomendasi
Bagi situs yang mempertimbangkan llms.txt, implementasi terkuat dalam dataset ini dan bukti trafik eksternal menunjukkan pola yang pragmatis:
- Publikasikan
/llms.txtdi root dan pastikan dapat diakses tanpa login, eksekusi JavaScript, consent wall, atau redirect ke path lain. - Sajikan sebagai
text/plainatautext/markdownjika memungkinkan. - Mulailah dengan deskripsi singkat situs, lalu kelompokkan tautan menurut produk, dokumentasi, API, harga, changelog, contoh, dukungan, kebijakan, dan resource perusahaan.
- Utamakan tautan kanonik daripada daftar URL yang terlalu panjang.
- Hindari file simbolik kosong; paling-paling itu hanya sinyal yang lemah.
- Hindari dump masif yang tidak terbedakan kecuali ada use case konsumsi mesin yang kuat dan pipeline generasi yang andal.
- Validasi URL akhir, body respons, content type, struktur Markdown, jumlah tautan, dan ukuran file setelah publikasi.
Tim juga harus mengatur ekspektasi dengan hati-hati. Eksperimen publik yang tersedia belum membuktikan bahwa llms.txt secara mandiri meningkatkan trafik rujukan AI. Jika tim ingin menguji dampak bisnis, mereka perlu melacak rujukan LLM, halaman yang disitasi, request bot, freshness indeks, dan perubahan konten secara bersamaan. Eksperimen yang berguna akan membandingkan grup halaman yang cocok, menjaga pembaruan konten tetap konstan jika memungkinkan, dan memisahkan trafik spesifik platform seperti Perplexity, ChatGPT, Gemini, Claude, dan Bing/Copilot.
Keterbatasan
Ini adalah snapshot berbasis crawling, bukan kebenaran permanen. Situs web dapat menambahkan, menghapus, atau mengubah file llms.txt kapan saja. Sebagian domain mungkin memblokir request otomatis atau berperilaku berbeda berdasarkan geografi, konfigurasi TLS, logika redirect, user agent, atau mitigasi bot. Studi ini hanya menguji file di level root dan tidak mencari subdomain atau path nonstandar.
Skor kualitas dan arketipe adalah alat riset, bukan label kepatuhan resmi. Analisis topik berbasis kata kunci dan harus dibaca sebagai petunjuk arah. Studi ini tidak membuktikan bahwa platform AI tertentu saat ini membaca, mematuhi, atau menggunakan llms.txt dalam produksi.
Bukti trafik eksternal yang ditinjau dalam versi ini juga memiliki keterbatasan. Analisis Search Engine Land lebih kuat sebagai observasi multi-situs yang bersifat peringatan daripada sebagai eksperimen acak. Hasil Alimbekov berguna sebagai studi kasus level situs yang transparan, tetapi tidak memiliki grup kontrol dan mencakup periode ketika trafik rujukan total naik cukup signifikan. Referensi ini membantu membingkai perdebatan, tetapi tidak mengubah crawling ini menjadi studi trafik kausal.
File dan Reproduksibilitas
| File | Tujuan |
|---|---|
crawl_llms_txt.py | Crawler untuk /llms.txt dan /llms-full.txt. |
analyze_llms_txt.py | Analisis adopsi utama dan pembuatan grafik. |
deep_analyze_llms_txt.py | Analisis sekunder untuk desil peringkat, TLD, sinyal topik, skor kualitas, arketipe, dan perilaku dua-file. |
deep_dive_early_quality.py | Klasifikasi pengadopsi awal dan pendalaman kualitas implementasi. |
data/llms_probe_results_top_10000.csv | Dataset utama hasil crawling. |
data/deep_analysis_top_10000.json | Ringkasan analisis sekunder. |
data/deep_early_quality_analysis.json | Kategori pengadopsi awal, perbandingan kohort kualitas, detail arketipe, dan studi kasus. |
Sumber
- , Jeremy Howard, 2024.
- .
- .
- .
- , Data Provenance Initiative.
- .
- , Search Engine Land, Januari 2026.
- , Rankability, Juni 2025.
- , Renat Alimbekov.
Koreksi metodologi, isu dataset, dan analisis lanjutan sangat kami sambut di support@thunderbit.com. Laporan ini diterbitkan secara independen dari posisi komersial apa pun yang dipegang Thunderbit. Data dalam laporan ini berdiri sendiri. — Tim riset Thunderbit, Mei 2026.