

Beberapa bulan lalu, seorang rekan di tim sales kami bertanya sesuatu yang sudah berkali-kali saya dengar: "Kalau saya scrape harga kompetitor dari situs publik, apa saya benar-benar bisa kena masalah?" Dia menemukan direktori kontak supplier, harga yang tersusun rapi dalam baris-baris, dan yang dia butuhkan cuma spreadsheet. Keraguannya nyata—dan jujur saja, masuk akal.
Inggris memang tidak punya satu "undang-undang web scraping" khusus. Sebaliknya, ada empat kerangka hukum yang saling tumpang tindih untuk menentukan apakah suatu aktivitas scraping itu legal. Jadi, jawabannya hampir selalu "tergantung"—tetapi itu bukan berarti Anda harus panik. Di panduan ini, saya akan membahas apa kata hukum sebenarnya, bagaimana penerapannya dalam skenario nyata, seperti apa hukumannya, dan bagaimana tetap patuh.
Saya sudah banyak meneliti topik ini untuk tim kami di Thunderbit, dan saya ingin membagikan temuan saya supaya Anda tidak perlu merangkumnya dari lima blog firma hukum berbeda dan satu thread Reddit.
Coba Thunderbit untuk Web Scraping
Apa Itu Web Scraping (dan Mengapa Bisnis di Inggris Menggunakannya)
Web scraping adalah penggunaan software untuk mengumpulkan data dari website secara otomatis—menggantikan proses membosankan menyalin dan menempel dari halaman web ke spreadsheet.
Tekniknya sendiri netral. Tidak otomatis legal, tidak otomatis ilegal. Yang menentukan adalah data apa yang di-scrape, bagaimana cara mengaksesnya, dan apa yang Anda lakukan dengan data itu setelahnya.
Bisnis di Inggris menggunakan scraping untuk berbagai tujuan yang sah:
- Perbandingan harga: PriceSpy UK, misalnya, memperbarui harga produk tiga sampai lima kali per hari dengan web scraping otomatis.
- Lead generation: Tim sales mengambil nama perusahaan, email, dan nomor telepon dari direktori publik.
- Riset pasar: Analis memantau listing properti, papan lowongan kerja, atau rentang produk kompetitor.
- Riset akademis: Office for National Statistics mengumpulkan lebih dari 2,2 juta kutipan harga dari situs supermarket antara 2014 dan 2015.
- Pelatihan model AI: Kasus penggunaan yang tumbuh cepat—dan secara hukum masih belum sepenuhnya jelas.
Trennya jelas. Survei Bright Data/Vanson Bourne terhadap 500 pengambil keputusan (termasuk 200 di Inggris) menemukan bahwa 89% menganggap data web publik sangat penting atau penting bagi ekonomi global, dan 38% mengambilnya setidaknya setiap hari.
Namun, 73% juga mengatakan kurangnya regulasi yang jelas membuat organisasi mereka khawatir. Kecemasan itulah alasan artikel ini dibuat.
Apakah Web Scraping Legal di Inggris? Jawaban Langsungnya
Tidak ada hukum Inggris yang secara tegas melarang web scraping. Tetapi ada beberapa hukum yang mengatur bagaimana scraping boleh dilakukan, dan legalitas proyek tertentu bergantung pada empat faktor:
- Data apa yang Anda scrape (data pribadi vs. data faktual/non-pribadi)
- Bagaimana Anda mengaksesnya (halaman publik vs. melewati login wall atau CAPTCHA)
- Apa yang tertulis di ketentuan website (apakah akses otomatis dilarang?)
- Bagaimana Anda menggunakan data itu setelahnya (analisis internal vs. penjualan ulang komersial)
Analogi terbaik yang saya temukan: web scraping itu seperti memotret di ruang publik. Memotret di tempat umum tidak otomatis ilegal—tetapi subjek, lokasi, metode, dan penggunaan tertentu bisa menimbulkan risiko hukum. Scraping juga begitu. Ketersediaan publik itu relevan, tapi bukan satu-satunya hal yang menentukan.
Konsultasi GenAI terbaru dari ICO adalah salah satu pernyataan resmi Inggris yang paling jelas tentang data pribadi hasil scraping. ICO mengatakan legitimate interests tetap menjadi satu-satunya dasar hukum yang tersedia untuk melatih model AI generatif menggunakan data pribadi hasil web scraping—tetapi hanya jika pengembang lolos uji tiga bagian yang ketat. Standarnya tinggi, dan ini menunjukkan seberapa serius regulator Inggris memandang data hasil scraping.
Empat Hukum Inggris yang Berlaku untuk Web Scraping
Ada empat lensa yang saling tumpang tindih—setiap proyek scraping bisa memicu satu, dua, atau bahkan keempatnya.
UK GDPR dan Data Protection Act 2018
Jika Anda meng-scrape data pribadi—nama, email, nomor telepon, alamat IP, profil media sosial—maka UK GDPR berlaku. "Bisa diakses publik" tidak berarti "bebas dipakai."
Data pribadi yang terlihat publik tetaplah data pribadi.
Dasar hukum yang paling relevan untuk scraping komersial adalah legitimate interests (Pasal 6)—tetapi Anda tidak bisa sekadar mengucapkan frasa itu lalu selesai. Anda harus:
- Mengidentifikasi tujuan yang spesifik dan sah
- Menunjukkan bahwa pemrosesan itu memang diperlukan untuk tujuan tersebut
- Menyeimbangkan kepentingan Anda dengan hak individu yang datanya Anda kumpulkan
Respons ICO atas konsultasi GenAI sangat tegas: pengembang tidak boleh berasumsi bahwa manfaat luas bagi masyarakat sudah cukup, harus membuktikan mengapa alternatif selain scraping tidak memadai, dan harus memakai mekanisme transparansi yang membantu individu memahami serta menggunakan hak-hak mereka. Sumber: respons ICO soal GenAI.
Untuk lead generation B2B, logikanya sama. Tim sales bisa saja mengandalkan legitimate interests untuk mengumpulkan info kontak bisnis yang dipublikasikan, tetapi tetap perlu mendokumentasikan kepentingan sahnya, meminimalkan bidang data yang diambil, menghindari data kategori khusus, menyediakan informasi privasi bila memungkinkan, dan menghormati opt-out.
Hak Cipta, Hak Database, dan Pengecualian TDM
Hak cipta melindungi konten asli website: teks, gambar, deskripsi produk, artikel. Data faktual seperti harga biasanya lebih sedikit sensitif terhadap hak cipta jika berdiri sendiri—tetapi menyalin dan menerbitkan ulang ekspresi yang dilindungi bisa masuk ke wilayah pelanggaran.
Hak database lebih penting untuk scraping daripada yang banyak orang sadari. Inggris mempertahankan hak database sui generis ala Uni Eropa setelah Brexit, dan mengekstrak "bagian substansial" dari database yang dilindungi—direktori kurasi, katalog produk, listing marketplace—bisa melanggar meski data individualnya faktual.
Pengecualian Text and Data Mining (TDM) menurut Section 29A CDPA hanya mengizinkan salinan untuk analisis teks dan data jika pengguna memiliki akses yang sah dan tujuannya adalah riset non-komersial. Ini sempit. Scraping komersial, pelatihan AI komersial, dan penjualan ulang dataset komersial tidak tercakup.
Pemerintah Inggris sempat mempertimbangkan memperluas pengecualian ini untuk pelatihan AI, tetapi per laporan Copyright and AI Maret 2026, mereka memutuskan tidak akan melakukan reformasi sampai yakin kebijakan tersebut memenuhi tujuan bagi kreator, pengembang AI, dan ekonomi Inggris. Dalam status quo, izin biasanya tetap dibutuhkan untuk menyalin karya yang dilindungi demi pelatihan AI, kecuali ada pengecualian yang sudah berlaku.
Ketentuan Layanan Website dan Hukum Kontrak
Kebanyakan website memiliki Terms of Service (ToS) yang melarang atau membatasi scraping otomatis. Begitu mengakses situs, Anda mungkin sudah dianggap menyetujui ketentuan tersebut—terutama jika Anda menekan layar persetujuan (clickwrap). Perjanjian browsewrap (ketentuan yang disembunyikan di tautan footer) lebih bergantung pada fakta kasus, tetapi pengadilan Inggris menunjukkan kesediaan menegakkan pembatasan ToS terhadap scraping. Dalam sengketa Ryanair v Billigfluege, pengadilan memperlakukan ketentuan website yang terlihat sebagai mengikat dalam konteks screen scraping.
robots.txt bukan undang-undang. Itu hanya sinyal yang bisa dibaca mesin dari pemilik situs. File tipikalnya seperti ini:
User-agent: *
Disallow: /account/
Disallow: /checkout/
Disallow: /private/
Crawl-delay: 10
Mengabaikan robots.txt tidak otomatis membuat scraping ilegal, tetapi pengadilan dan ICO menganggapnya sebagai bukti niat pemilik website. Mengabaikannya meningkatkan paparan risiko hukum Anda, terutama jika disertai pelanggaran ToS atau volume permintaan yang agresif.
Computer Misuse Act 1990
Yang satu ini sering bikin orang cemas—dan memang ada alasannya. Undang-undang ini menciptakan tindak pidana. Section 1 mencakup akses tanpa izin ke materi komputer (maksimum 2 tahun penjara). Section 3 mencakup tindakan tanpa izin yang mengganggu operasi komputer (maksimum 10 tahun penjara).
Risiko CMA paling rendah jika datanya benar-benar publik dan scraper tidak melewati hambatan teknis. Risikonya naik jika Anda:
- Melewati login wall, CAPTCHA, atau blokir IP
- Menggunakan kredensial curian atau membuat akun palsu
- Mengirim volume trafik yang mengganggu layanan target
Inggris tidak memiliki aturan setegas versi AS yang mengatakan "data publik bebas diambil." Karena itu, saran hukum di Inggris lebih hati-hati: akses publik memang sangat menurunkan risiko CMA, tetapi ketentuan website, kontrol teknis, dan pengetahuan scraper tentang pembatasan tetap bisa jadi faktor penting.
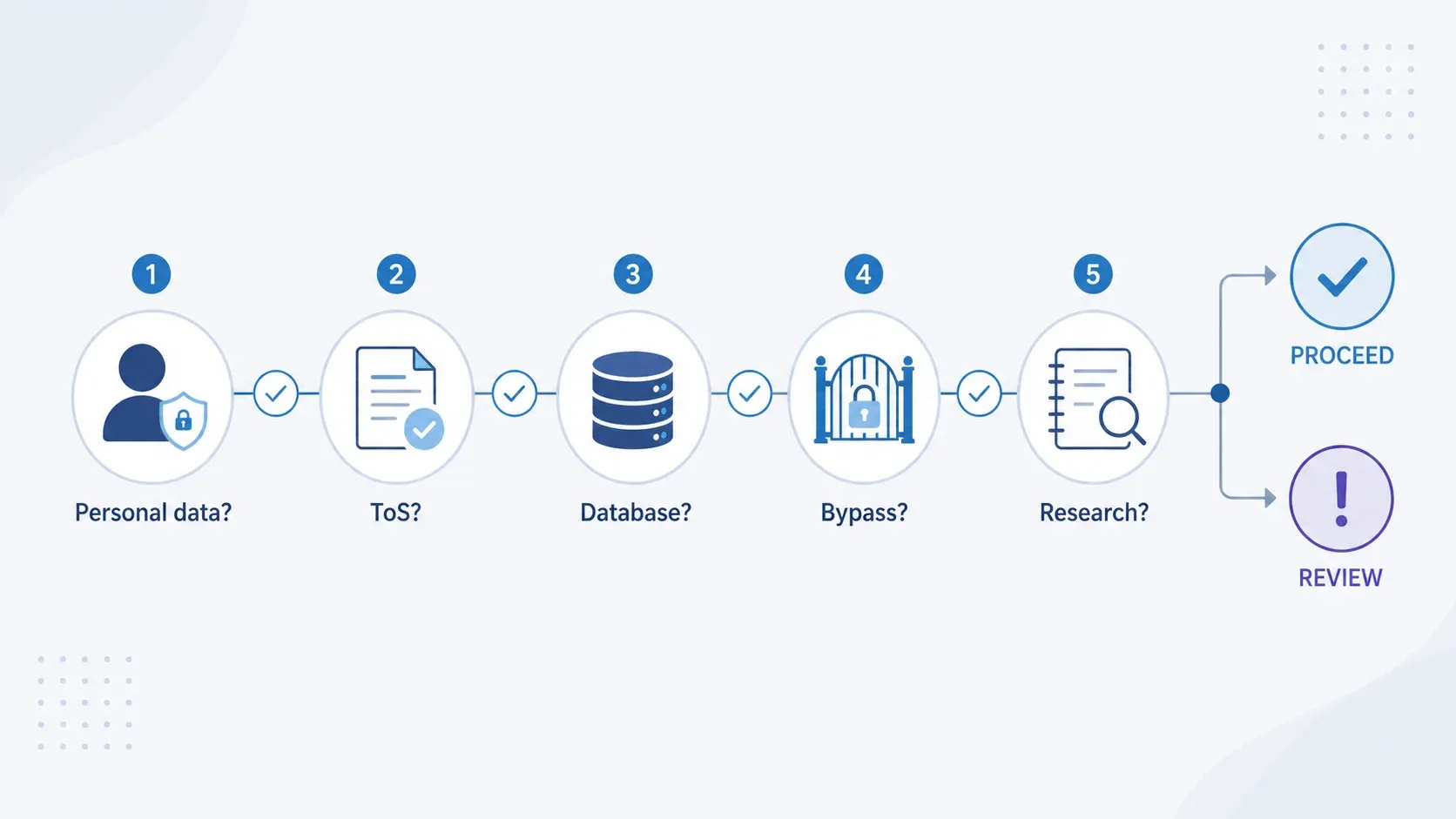
"Bolehkah Saya Scrape Ini Secara Legal?" — Alur Keputusan Singkat
Sebelum Anda mulai scrape apa pun, jalani lima titik keputusan ini. Bukan nasihat hukum—hanya triase risiko 60 detik.
| Poin Keputusan | Jika YA | Jika TIDAK |
|---|---|---|
| Data yang diambil adalah data pribadi (nama, email, dll.)? | UK GDPR berlaku. Tentukan dasar hukum, lakukan LIA, minimalkan bidang data, siapkan transparansi. | Lapisan GDPR mungkin tidak berlaku, tapi lanjutkan pemeriksaan lain. |
| ToS situs secara eksplisit melarang scraping? | Ada risiko pelanggaran kontrak. Pertimbangkan API, lisensi, atau review hukum. | Risiko kontrak lebih rendah, tapi cek robots.txt. |
| Mengambil bagian substansial dari database? | Hak database sui generis kemungkinan dilanggar. Pertimbangkan lisensi atau pengambilan yang lebih sempit. | Hak cipta masih bisa berlaku pada konten individual yang disalin. |
| Melewati login, CAPTCHA, atau kontrol akses? | Potensi tindak pidana menurut CMA 1990. Hentikan dan minta review hukum. | Risiko CMA lebih rendah jika akses benar-benar publik. |
| Tujuannya riset non-komersial? | Pengecualian TDM Section 29A mungkin berlaku jika Anda punya akses sah. | Tidak ada safe harbor TDM komersial yang luas di Inggris. Perlu analisis IP dan kontrak penuh. |
Duh, saya berharap ada yang memberi saya ini saat pertama kali mulai meneliti kepatuhan scraping untuk tim kami. Ini mengubah kompleksitas hukum menjadi self-assessment terstruktur yang bisa Anda jalankan kurang dari semenit.
Skenario Nyata: Apakah Aktivitas Scraping Anda Tertentu Legal di Inggris?
Hukum abstrak itu satu hal. Yang sebenarnya ingin diketahui orang adalah: "Proyek saya akan bikin saya kena masalah atau tidak?"
Masuk akal. Berikut lima use case scraping yang umum di Inggris beserta penilaian risiko hukumnya.
Meng-scrape Harga Produk untuk Perbandingan
Salah satu use case bisnis yang paling umum—dan sering kali risikonya paling rendah. Harga adalah data faktual, dan pengumpulan harga otomatis memang cara situs seperti PriceSpy beroperasi.
Namun risikonya tidak hilang sepenuhnya. Jika situs target melarang scraping dalam ToS, jika Anda menyalin deskripsi produk atau gambar, atau jika Anda mengekstrak bagian substansial dari database produk yang dikurasi, isu kontrak, hak cipta, dan hak database bisa muncul.
Tingkat risiko: RENDAH hingga SEDANG
Langkah kepatuhan utama: Ambil hanya field harga yang faktual, hindari menyalin deskripsi produk secara verbatim, patuhi ToS dan robots.txt, gunakan rate limiting, dan jangan menerbitkan ulang katalog kompetitor secara mentah.
Meng-scrape dan Menjual Ulang Data Secara Komersial
Ini skenario komersial berisiko tertinggi, titik. Anda mengubah investasi data pihak lain menjadi produk yang dijual—dan itu bisa melibatkan keempat pilar hukum sekaligus.
Tingkat risiko: TINGGI
Langkah kepatuhan utama: Review hukum sangat penting. Pertimbangkan perjanjian lisensi dengan pemilik data. Jika produk berisi data pribadi, tambahkan data protection impact assessment.
Mengekstrak Info Kontak Bisnis untuk Lead Generation
Hampir setiap tim sales yang saya ajak bicara melakukan versi ini: scraping email, nomor telepon, dan nama perusahaan dari direktori. Masalahnya? Data kontak bisnis sering kali mencakup data pribadi. Email karyawan yang disebut namanya tetap data pribadi, meski tercantum publik.
Tingkat risiko: SEDANG
Langkah kepatuhan utama: Lakukan Legitimate Interests Assessment, hanya kumpulkan data kontak bisnis (bukan data kehidupan pribadi) bila memungkinkan, dokumentasikan dasar hukum Anda, dan sediakan jalur opt-out. Alat seperti Thunderbit bisa mengurangi risiko akses di sini karena ekstensi Chrome bekerja di browser pengguna—mengakses hanya apa yang memang sudah bisa dilihat pengguna, tanpa melewati kontrol akses.
Analisis Data Akademis atau untuk Portofolio
Jika Anda benar-benar melakukan riset non-komersial, Anda punya jalur pengecualian hak cipta yang paling kuat: Section 29A CDPA, asalkan Anda memiliki akses yang sah.
Tingkat risiko: RENDAH (jika benar-benar non-komersial)
Langkah kepatuhan utama: Dokumentasikan tujuan non-komersial, cantumkan sumber, anonimisasi atau agregasi bila memungkinkan, dan jangan menyebarluaskan ulang konten berhak cipta atau data pribadi.
Scraping Konten untuk Pelatihan Model AI
Ini yang ditanyakan semua orang di 2026—dan jawabannya masih belum memuaskan. ICO memandang data pribadi hasil web scraping untuk pelatihan sebagai pemrosesan tersembunyi berisiko tinggi. Laporan pemerintah Inggris 2026 tidak memperkenalkan pengecualian TDM komersial yang luas.
Tingkat risiko: SEDANG hingga TINGGI
Langkah kepatuhan utama: Lisensi, asal-usul dataset, analisis hak cipta, penyaringan data pribadi, dokumentasi dasar hukum, dan pemantauan ketat atas perubahan kebijakan Inggris.
Tabel Ringkasan Skenario
| Skenario | Hukum Utama yang Terpicu | Tingkat Risiko | Langkah Kepatuhan Utama |
|---|---|---|---|
| Pemantauan harga produk | ToS, hak database, hak cipta | Rendah–Sedang | Ambil field faktual, patuhi sinyal situs |
| Penjualan ulang data komersial | Keempat pilar | Tinggi | Review hukum dan lisensi wajib |
| Lead generation B2B | UK GDPR, ToS | Sedang | Lakukan LIA, minimalkan data pribadi |
| Riset akademis | Hak cipta (pengecualian TDM), GDPR jika ada data pribadi | Rendah | Jaga tujuan non-komersial, jangan terbitkan ulang |
| Pelatihan model AI | UK GDPR, hak cipta, hak database | Sedang–Tinggi | Lisensikan data, dokumentasikan dasar hukum, pantau kebijakan |
Inggris vs. AS vs. Uni Eropa: Perbedaan Hukum Web Scraping
Kalau Anda hanya beroperasi di Inggris, Anda bisa melewati bagian ini. Tapi sebagian besar bisnis yang saya temui melakukan scraping lintas negara—atau setidaknya meng-scrape website yang di-host di yurisdiksi lain. Perbedaannya lebih penting daripada yang banyak orang kira.
| Dimensi Hukum | 🇬🇧 Inggris | 🇺🇸 AS | 🇪🇺 Uni Eropa |
|---|---|---|---|
| Hukum perlindungan data utama | UK GDPR + DPA 2018 | Tidak ada padanan federal (hukum negara bagian bervariasi) | GDPR UE |
| Preseden scraping utama | Clearview AI (denda ICO £7,5 juta) | hiQ v LinkedIn (scraping data publik OK, Ninth Circuit—tetapi hiQ akhirnya dilarang permanen dan membayar $500K dalam final consent judgment) | Ryanair v PR Aviation (CJEU, C-30/14, hak database) |
| Hukum akses komputer | Computer Misuse Act 1990 | CFAA (dipersempit oleh Van Buren, 2021) | Bervariasi per negara anggota |
| Hak cipta / pengecualian TDM | Sempit: hanya riset non-komersial (Section 29A) | Doktrin fair use (lebih luas, tergantung kasus) | DSM Directive Art. 3 & 4 (hak TDM lebih luas dengan reservasi hak) |
| Hak database | Ya (dipertahankan dari EU Database Directive) | Tidak ada hak federal yang setara | Hak sui generis di bawah Database Directive |
| Daya berlaku ToS | Hukum kontrak berlaku; browsewrap masih diperdebatkan | Campuran: browsewrap sering tidak dapat ditegakkan | Bervariasi; Ryanair memperkuat posisi ToS |
Inti praktisnya: jika Anda scraping lintas yurisdiksi, patuhi hukum yang paling ketat yang berlaku. AS lebih permisif terhadap akses data publik di bawah hiQ, tetapi hiQ bukan izin bebas tanpa batas (hiQ pada akhirnya dilarang scraping LinkedIn dan membayar $500K). UE punya arsitektur TDM yang lebih luas lewat DSM Directive. Inggris posisinya ada di tengah—tanpa pengecualian TDM komersial yang luas, hak database yang kuat, dan regulator yang aktif.
Hukuman dan Penegakan: Apa yang Sebenarnya Terjadi Jika Anda Ketahuan
Peringatan samar soal "denda" dan "masalah hukum" tidak membantu siapa pun. Berikut angka-angka nyatanya.
Denda UK GDPR
Denda maksimum: £17,5 juta atau 4% dari omzet global tahunan, mana yang lebih besar.
Contoh nyata: Clearview AI didenda £7.552.800 oleh ICO pada 2022 karena meng-scrape gambar wajah dari media sosial di Inggris. First-tier Tribunal membatalkan putusan itu atas dasar yurisdiksi, tetapi Upper Tribunal pada Oktober 2025 mengabulkan banding ICO dan mengembalikan kasusnya. ICO mencatat bahwa Clearview mendapat izin untuk mengajukan banding ke Court of Appeal per Desember 2025.
Hukuman Pidana Computer Misuse Act
- Section 1 (akses tanpa izin): hingga 2 tahun penjara
- Section 3 (gangguan tanpa izin): hingga 10 tahun penjara
Penuntutan pidana untuk scraping biasa pada halaman publik sangat jarang.
Profil risikonya berubah drastis jika perilakunya menyerupai hacking, penyalahgunaan kredensial, bypass CAPTCHA, atau gangguan layanan.
Hak Cipta dan Hak Database
Ganti rugi perdata plus injunctive relief. Hukuman pidana mungkin ada untuk pelanggaran komersial yang disengaja, tetapi sebagian besar sengketa scraping berjalan sebagai gugatan perdata.
Pelanggaran Kontrak (ToS)
Ganti rugi perdata, penghentian akun, pemblokiran IP. Ini biasanya bentuk penegakan yang paling umum secara praktis—dan sering kali jadi hal pertama yang terjadi.
Ringkasan Tingkat Keparahan Hukuman
| Kerangka Hukum | Hukuman Maksimum | Kemungkinan pada Scraping Bisnis Umum | Contoh di Dunia Nyata |
|---|---|---|---|
| UK GDPR | £17,5 juta atau 4% omzet global | Sedang jika data pribadi dalam skala besar; rendah untuk data non-pribadi | Denda Clearview AI £7,5 juta |
| CMA Section 1 | 2 tahun penjara | Rendah untuk halaman publik; lebih tinggi jika melewati kontrol | Pedoman CPS soal akses tanpa izin |
| CMA Section 3 | 10 tahun penjara | Rendah kecuali trafik mengganggu sistem | Contoh gangguan mirip DDoS |
| Hak cipta/hak database | Ganti rugi dan injunctive relief | Sedang untuk menyalin konten yang dilindungi atau database kurasi | Kasus Ryanair dan BHB |
| Pelanggaran ToS | Ganti rugi, penghentian akun, pemblokiran | Tinggi sebagai jalur penegakan praktis | Sengketa screen-scraping Ryanair |
Bagaimana Alat Scraping yang Tepat Mengurangi Risiko Hukum Anda
Alat yang Anda pilih tidak akan membuat scraping ilegal menjadi legal. Tapi alat yang baik bisa menghilangkan risiko yang sebenarnya bisa dihindari.
Dari pengalaman saya, perbedaan antara alat yang menghormati sinyal situs dan alat yang agresif melewati semuanya sering kali menjadi pembeda antara proyek data biasa dan urusan hukum yang merepotkan.
Menghormati robots.txt dan Sinyal Website
Alat yang bertanggung jawab seharusnya memudahkan Anda memeriksa dan menghormati robots.txt sebelum scraping. Walau tidak mengikat secara hukum, kepatuhan pada robots.txt dipandang pengadilan dan ICO sebagai bukti itikad baik. Dokumentasi Thunderbit menganjurkan pengguna untuk mengambil data yang tersedia publik serta menghormati robots.txt dan ketentuan situs.
Opsi Browser Scraping vs. Cloud Scraping
Perbedaan ini penting secara hukum. Browser scraping hanya mengakses apa yang bisa dilihat pengguna dalam sesi yang sudah diautentikasi—pada dasarnya mengotomatiskan apa yang akan Anda lakukan secara manual. Cloud scraping mengirim permintaan dari server, yang lebih cepat untuk situs publik tetapi bisa terlihat lebih seperti "akses otomatis" dari sudut pandang situs.
Thunderbit menyediakan kedua mode. Browser scraping cocok untuk situs yang memerlukan login (mengurangi risiko "akses tanpa izin" di bawah CMA), sementara cloud scraping bekerja baik untuk halaman ecommerce publik di mana kecepatan penting. Pendekatan ganda ini memungkinkan pengguna menyesuaikan metode scraping dengan profil risiko hukum tiap situs.
Tidak Ada Bypass atas Kontrol Akses
Alat yang bekerja di dalam browser dan tidak memecahkan CAPTCHA atau menerobos login wall secara alami lebih rendah risikonya di bawah Computer Misuse Act. Ekstensi Chrome Thunderbit beroperasi dalam sesi browser pengguna—ia hanya mengakses apa yang memang sudah bisa dilihat pengguna.
Ekspor Data yang Transparan (Mendukung Kepatuhan GDPR)
Thunderbit mengekspor langsung ke Excel, Google Sheets, Airtable, atau Notion. Pengguna mengontrol ke mana data pergi. Ini mendukung transparansi GDPR dan dokumentasi dasar hukum: Anda tahu persis data apa yang dikumpulkan dan ke mana data itu pergi. Tidak ada pemrosesan tersembunyi atau penyimpanan data oleh alat.
Rate Limiting dan Akses yang Bertanggung Jawab
Volume permintaan yang agresif bisa memicu CMA Section 3 (gangguan tanpa izin). Rate limiting bukan sekadar praktik teknis yang baik—ini juga perlindungan hukum. Alat yang bertanggung jawab menghindari membanjiri server, sehingga menurunkan risiko hukum sekaligus mengurangi kemungkinan IP Anda diblokir.

Checklist Kepatuhan Praktis untuk Web Scraping di Inggris
Jalankan ini sebelum Anda meng-scrape apa pun:
- Baca Terms of Service dan Kebijakan Penggunaan yang Diizinkan dari website target.
- Periksa file robots.txt dan dokumentasikan apakah path yang relevan dilarang.
- Tentukan apakah data yang Anda inginkan adalah data pribadi. Jika ya, identifikasi dasar hukum Anda di bawah UK GDPR.
- Nilai apakah Anda mengambil "bagian substansial" dari sebuah database.
- Pastikan Anda tidak melewati kontrol akses teknis apa pun (CAPTCHA, login, rate limit).
- Jika tujuan Anda riset non-komersial, dokumentasikan hal ini agar bisa memanfaatkan pengecualian TDM.
- Gunakan rate limiting. Jangan membanjiri server target.
- Dokumentasikan semuanya: dasar hukum Anda, tinjauan ToS, field data yang dikumpulkan, tujuan ekspor, dan periode retensi.
- Jika ragu, minta nasihat hukum dari solicitor yang spesialis di perlindungan data dan IP.
Checklist ini tidak menggantikan pendapat solicitor—tetapi memberi Anda kerangka awal yang kuat dan menunjukkan itikad baik jika nanti muncul pertanyaan.
Poin-Poin Utama
- Web scraping tidak ilegal di Inggris—tetapi diatur oleh empat kerangka hukum yang saling tumpang tindih: UK GDPR, hak cipta/hak database, hukum kontrak, dan Computer Misuse Act.
- Legalitas scraping apa pun bergantung pada data apa yang Anda scrape, bagaimana Anda mengaksesnya, apa yang tertulis di ketentuan website, dan apa yang Anda lakukan dengan datanya.
- Scraping data pribadi membawa beban kepatuhan tertinggi. Legitimate interests biasanya satu-satunya dasar hukum yang layak, dan itu memerlukan uji penyeimbangan yang terdokumentasi.
- Inggris tidak punya pengecualian TDM komersial yang luas. Pelatihan AI komersial dan penjualan ulang dataset berisiko tinggi tanpa lisensi.
- Gunakan alur keputusan dan tabel skenario di atas untuk menilai situasi spesifik Anda sebelum mulai.
- Pilih alat yang sejalan dengan praktik kepatuhan terbaik: akses berbasis browser, tanpa bypass CAPTCHA, ekspor data yang transparan, dan rate limiting. Thunderbit dirancang dengan prinsip-prinsip ini—tetapi tanggung jawab kepatuhan tetap ada pada pengguna.
- Jika ragu, dokumentasikan alasan Anda dan bicaralah dengan solicitor. Biaya opini hukum hampir selalu lebih rendah daripada biaya investigasi ICO.
Coba AI Web Scraper dengan Thunderbit Get Started Free
FAQ
Apakah legal meng-scrape data yang tersedia publik di Inggris?
Secara umum, ya—scraping data publik risikonya lebih rendah daripada scraping data yang dibatasi atau privat. Tetapi "tersedia publik" tidak berarti "bebas dipakai sesuka hati." UK GDPR tetap bisa berlaku untuk data pribadi publik, hak cipta bisa berlaku pada ekspresi yang disalin, hak database bisa melindungi koleksi yang dikurasi, dan ToS bisa membatasi akses otomatis.
Bolehkah saya meng-scrape email dan nomor telepon dari website Inggris?
Jika datanya merupakan data pribadi (dan email serta nomor telepon biasanya memang demikian), Anda memerlukan dasar hukum di bawah UK GDPR. Legitimate interests adalah dasar yang paling umum untuk lead generation B2B, tetapi Anda harus melakukan uji penyeimbangan, meminimalkan data yang dikumpulkan, dan menyediakan jalur opt-out. Scraping data kontak pribadi (nomor ponsel, email pribadi) jauh lebih berisiko daripada daftar direktori bisnis.
Apa perbedaan web scraping dan web crawling menurut hukum Inggris?
Secara hukum, tidak ada perbedaan yang berarti—hukum peduli pada tindakan, bukan label. Crawling biasanya berarti menemukan atau mengindeks halaman; scraping biasanya berarti mengekstrak data terstruktur. Keduanya melibatkan akses otomatis ke website dan tunduk pada kerangka hukum yang sama.
Apakah robots.txt membuat scraping ilegal?
Tidak. robots.txt tidak mengikat secara hukum. Namun, mengabaikannya meningkatkan paparan risiko hukum karena pengadilan dan ICO menganggapnya sebagai bukti niat pemilik website. Jika Anda mengabaikan robots.txt dan ToS situs juga melarang scraping, Anda menumpuk faktor risiko—dan itu posisi yang jauh lebih sulit dipertahankan.
Bisakah saya diproses pidana karena web scraping di Inggris?
Hanya jika Anda melewati kontrol akses (CAPTCHA, login, blokir IP) atau menyebabkan kerusakan pada sistem komputer di bawah Computer Misuse Act 1990. Scraping biasa atas data publik yang benar-benar publik, dengan volume wajar, tanpa menghindari kontrol teknis, sangat kecil kemungkinan berujung pada tuntutan pidana. Profil risikonya berubah drastis jika perilakunya menyerupai hacking atau gangguan layanan yang disengaja.
Pelajari Lebih Lanjut




