Dasbor OpenRouter saya menunjukkan biaya $47 sudah habis sebelum makan siang di hari Selasa. Saya baru menjalankan belasan tugas coding — bukan yang aneh-aneh, cuma refactoring dan beberapa perbaikan bug. Di titik itu saya sadar kalau default OpenClaw diam-diam mengarahkan setiap interaksi, termasuk ping heartbeat di latar belakang, ke Claude Opus yang biayanya $15+ per satu juta token.
Kalau kamu pernah kaget dengan tagihan yang mirip — dan dari forum, ternyata banyak juga yang ngalamin (“Saya sudah keluar 40 dolar dan bahkan belum banyak dipakai,” tulis seorang pengguna) — panduan ini akan membawamu lewat proses audit dan optimasi lengkap yang saya pakai buat memangkas pengeluaran bulanan sekitar 90%. Ini bukan sekadar “ganti ke model yang lebih murah”, tapi bedah sistematis ke mana token benar-benar lari, cara memantaunya, model hemat biaya mana yang tetap kuat untuk kerja agentic sungguhan, dan tiga konfigurasi siap-tempel yang bisa langsung kamu pakai hari ini. Seluruh prosesnya cuma makan waktu satu sore.
Apa Itu Pemakaian Token OpenClaw (dan Kenapa Default-nya Sangat Mahal)?
Token adalah satuan penagihan untuk setiap interaksi AI di OpenClaw. Anggap saja sebagai potongan teks kecil — kira-kira 4 karakter bahasa Inggris per token. Setiap pesan yang kamu kirim, setiap respons yang kamu terima, setiap proses latar belakang yang jalan: semuanya ditagih dalam token.
Masalahnya, default OpenClaw memang dirancang untuk performa maksimal, bukan biaya minimal. Saat baru dipasang, model utamanya disetel ke anthropic/claude-opus-4-5 — opsi paling mahal yang tersedia. Heartbeat ping? Itu juga dijalankan di Opus. Sub-agent yang muncul buat ngerjain tugas sampingan? Juga Opus. Memakai Opus buat heartbeat ping itu ibarat nyewa ahli bedah saraf cuma buat pasang plester. Secara teknis bisa, tapi biayanya kelewatan.
Banyak pengguna tidak sadar bahwa mereka membayar tarif premium untuk tugas latar belakang yang sebenarnya sepele. Konfigurasi default pada dasarnya mengasumsikan kamu ingin model terbaik untuk semuanya, setiap saat — lalu menagihnya sesuai itu.
Kenapa Mengurangi Pemakaian Token OpenClaw Menghemat Lebih dari Sekadar Uang
Manfaat yang paling kelihatan tentu penghematan biaya. Tapi ada manfaat lanjutan yang numpuk seiring waktu.
Model yang lebih murah sering kali lebih cepat. Gemini 2.5 Flash-Lite berjalan di sekitar dibanding Opus sekitar 51 — artinya peningkatan kecepatan 4x untuk setiap interaksi. GPT-OSS-120B di Cerebras mencapai , kira-kira 35x lebih cepat daripada Opus. Dalam loop agentic dengan 50+ putaran panggilan tool, beda kecepatan itu berarti selesai dalam menit, bukan nunggu waktu ke token pertama Opus yang nyebelin, 13,6 detik, di tiap bolak-balik.
Kamu juga dapat ruang lebih besar sebelum kena rate limit, sesi yang lebih jarang ditahan, dan ruang buat memperbesar penggunaan tanpa ikut membesarkan rasa waswas lihat tagihan.
Proyeksi penghematan untuk berbagai profil penggunaan:
| Profil Pengguna | Perkiraan Pengeluaran Bulanan (Default) | Setelah Optimasi Penuh | Penghematan Bulanan |
|---|---|---|---|
| Ringan (~10 kueri/hari) | ~$100 | ~$12 | ~88% |
| Menengah (~50 kueri/hari) | ~$500 | ~$90 | ~82% |
| Berat (~200+ kueri/hari) | ~$1,750 | ~$220 | ~87% |
Ini bukan angka kira-kira. Seorang developer mendokumentasikan penurunan dari — pemangkasan nyata 90% — dengan menggabungkan routing model dan perbaikan kebocoran tersembunyi yang akan dibahas nanti di panduan ini.
Anatomi Pemakaian Token OpenClaw: Ke Mana Sebenarnya Token Itu Pergi
Bagian ini paling sering dilewati panduan optimasi, padahal justru ini yang paling penting. Kamu nggak bisa memperbaiki apa yang nggak kelihatan.
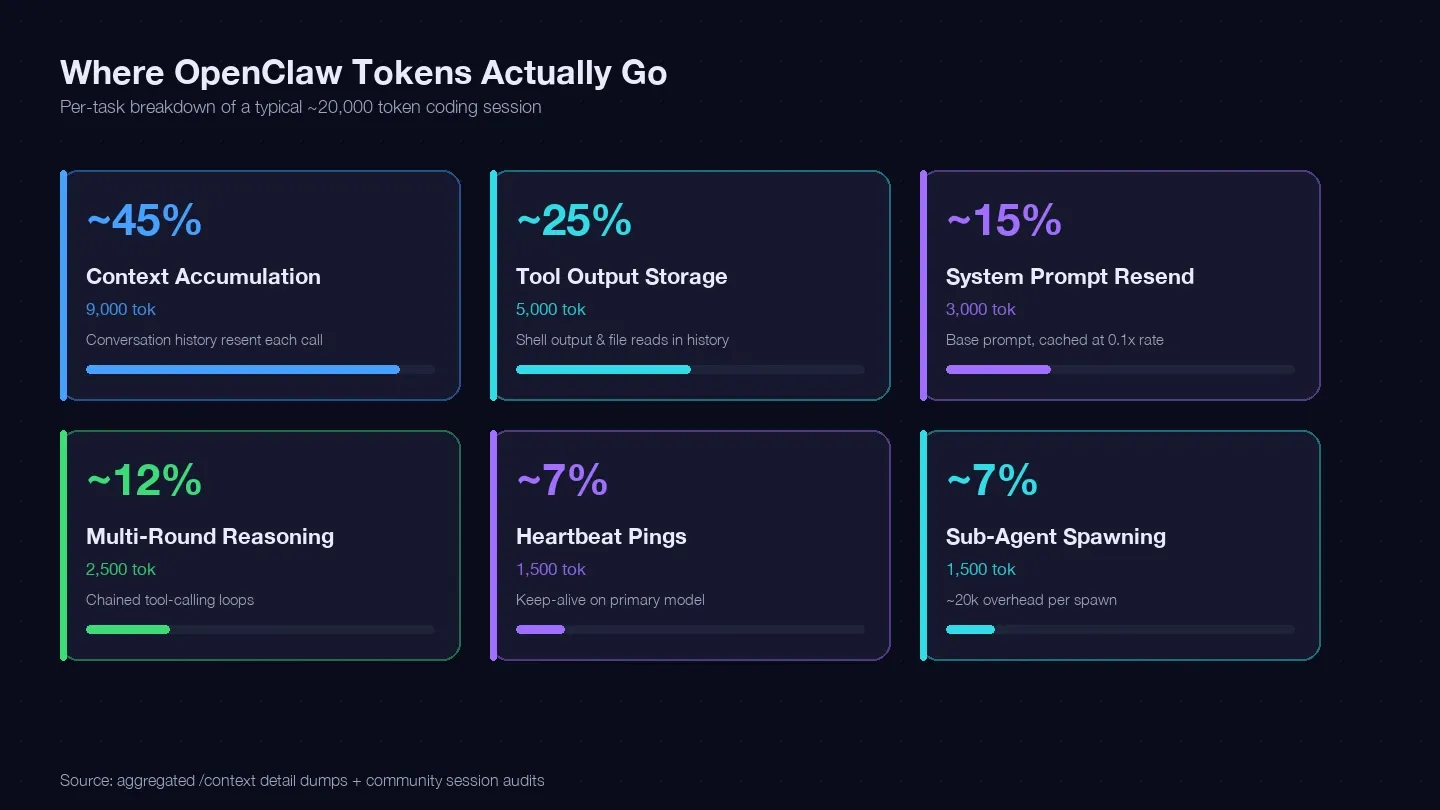
Saya mengaudit beberapa sesi dan membandingkannya dengan serta dump /context dari komunitas untuk menyusun ledger token pada satu tugas coding umum. Kurang lebih 20.000 token habis ke sini:
| Kategori Token | Persentase Tipikal dari Total | Contoh (1 tugas coding) | Bisa Dikontrol? |
|---|---|---|---|
| Akumulasi konteks (riwayat percakapan dikirim ulang setiap panggilan) | ~40–50% | ~9.000 token | Ya — /clear, /compact, sesi lebih pendek |
| Penyimpanan output tool (output shell, pembacaan file disimpan di histori) | ~20–30% | ~5.000 token | Ya — baca lebih kecil, ruang lingkup tool lebih sempit |
| Pengiriman ulang system prompt (~15K dasar) | ~10–15% | ~3.000 token | Sebagian — cache read dengan tarif 0,1x |
| Reasoning multi-putaran (loop panggilan tool berantai) | ~10–15% | ~2.500 token | Pilihan model + prompt yang lebih baik |
| Heartbeat / keep-alive ping | ~5–10% | ~1.500 token | Ya — ubah konfigurasi |
| Panggilan sub-agent | ~5–10% | ~1.500 token | Ya — routing model |
Bucket terbesar — akumulasi konteks — adalah riwayat percakapanmu yang dikirim ulang di setiap API call. Satu menunjukkan 185.400 token cuma di bucket Messages, bahkan sebelum model sempat membalas. System prompt dan tools nambah overhead tetap sekitar ~35.800 token di atasnya.
Intinya: kalau kamu tidak membersihkan sesi di antara tugas yang tidak saling berkaitan, kamu bayar untuk mengirim ulang seluruh riwayat percakapan di setiap putaran.
Cara Memantau Pemakaian Token OpenClaw (Kamu Tidak Bisa Memotong yang Tidak Terlihat)
Sebelum mengubah apa pun, pastikan dulu kamu tahu tokenmu pergi ke mana. Langsung lompat ke “pakai model lebih murah” tanpa monitoring sama saja seperti mau diet tapi tidak pernah menimbang berat badan.
Periksa Dasbor OpenRouter Kamu
Kalau kamu merutekan lewat OpenRouter, halaman adalah dasbor paling gampang tanpa setup. Kamu bisa memfilter berdasarkan model, provider, API key, dan periode waktu. Tampilan Usage Accounting memecah prompt, completion, reasoning, dan cached token untuk tiap request. Ada tombol Export (CSV atau PDF) untuk analisis jangka lebih panjang.
Yang perlu diperhatikan: model mana yang paling banyak menghabiskan token, dan apakah request heartbeat atau sub-agent muncul sebagai item biaya yang lebih besar dari seharusnya.
Audit Log API Lokal Kamu
OpenClaw menyimpan data sesi di ~/.openclaw/agents.main/sessions/sessions.json, yang berisi totalTokens per sesi. Kamu juga bisa menjalankan openclaw logs --follow --json untuk logging request secara real-time.
Satu catatan penting: , jadi dasbor bisa menampilkan nilai lama sebelum compaction. Lebih percaya /status dan /context detail daripada total yang tersimpan.
Gunakan Tracking Pihak Ketiga (Untuk Pengguna Menengah sampai Berat)
LiteLLM proxy memberi kamu endpoint yang kompatibel dengan OpenAI di depan 100+ provider dan . Fitur andalannya: budget keras per key yang tetap berlaku meski pakai /clear — sub-agent yang lepas kendali tidak bisa melewati batas yang kamu tetapkan.
Helicone bahkan lebih sederhana — dan kamu langsung mendapat tampilan Sessions yang mengelompokkan request terkait. Satu prompt “perbaiki bug ini” yang menyebar ke 8+ panggilan sub-agent akan tampil sebagai satu baris sesi dengan total biaya sebenarnya. .
Cek Cepat Langsung di Dalam OpenClaw
Untuk pemantauan harian, empat perintah di dalam sesi ini sudah cukup:
/status— menampilkan penggunaan konteks, token input/output terakhir, estimasi biaya/usage full— footer penggunaan per respons/context detail— rincian token per file, per skill, per tool/compact [guidance]— paksa compaction dengan string fokus opsional
Jalankan /context detail sebelum dan sesudah mengubah konfigurasi. Itu cara kamu mengukur apakah optimasi yang dilakukan benar-benar berhasil.
Adu Model Termurah OpenClaw: LLM Hemat Biaya Mana yang Benar-benar Mampu untuk Kerja Agentic
Kebanyakan panduan salah di sini. Mereka menampilkan tabel harga, menunjuk baris termurah, lalu selesai. Benchmark nggak bisa memprediksi performa agentic di dunia nyata — dan komunitas sudah berkali-kali bilang itu terang-terangan. Seperti yang ditulis seorang pengguna: “benchmark sama sekali tidak cukup untuk memahami mana yang paling bagus untuk agentic AI.”
Insight pentingnya: model termurah belum tentu menghasilkan outcome termurah. Model yang gagal lalu retry empat kali justru lebih mahal daripada model kelas menengah yang . Dalam sistem agent produksi, siapkan — dan kalau lima panggilan LLM berantai lalu langkah keempat gagal, retry naif akan menjalankan ulang kelima langkah itu semuanya.
Berikut matriks kemampuan saya, dengan “Skor Agentic Nyata” berdasarkan laporan pengguna sungguhan, bukan benchmark sintetis:
| Model | Input $/1M | Output $/1M | Keandalan Tool-Calling | Reasoning Multi-Langkah | Skor Agentic Nyata (1–5) | Paling Cocok Untuk |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Campuran — kadang loop | Dasar | ⭐2.5 | Heartbeat, lookup sederhana |
| GPT-OSS-120B | $0.04 | $0.19 | Cukup | Cukup | ⭐3.0 | Eksperimen hemat, kerja yang sangat butuh kecepatan |
| DeepSeek V3.2 | $0.26 | $0.38 | Tidak konsisten (6 issue terbuka) | Bagus | ⭐3.0 | Reasoning berat, minim tool calling |
| Kimi K2.5 | $0.38 | $1.72 | Bagus (via :exacto) | Cukup | ⭐3.5 | Coding sederhana hingga menengah |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Bagus | Bagus | ⭐4.0 | Driver harian untuk coding umum |
| Claude Haiku 4.5 | $1.00 | $5.00 | Sangat baik | Bagus | ⭐4.5 | Fallback kelas menengah yang andal |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Sangat baik | Sangat baik | ⭐5.0 | Tugas multi-langkah yang kompleks |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Sangat baik | Sangat baik | ⭐5.0 | Hanya untuk masalah tersulit |
Peringatan soal DeepSeek dan Gemini Flash untuk Tool Calling
DeepSeek V3.2 kelihatannya hebat di atas kertas — 72–74% di , 11–36x lebih murah dari Sonnet. Dalam praktiknya, di Cline, Roo Code, Continue, dan NVIDIA NIM mendokumentasikan perilaku tool-calling yang rusak. Putusan head-to-head dari Composio: “.” Kalimat singkat Zvi Mowshowitz: “.”
Gemini 2.5 Flash punya celah serupa. Thread di Google AI Developers Forum berjudul “Very frustrating experience with Gemini 2.5 function calling performance” dibuka dengan: “.”
OpenRouter menyoroti nuansa penting: “.” Kalau kamu merutekan model murah lewat OpenRouter, perhatikan tag :exacto — pergantian provider yang diam-diam bisa mengubah model murah yang andal jadi loop retry mahal dalam semalam.
Kapan Memakai Setiap Model
- Gemini Flash-Lite: Heartbeat, keep-alive ping, Q&A sederhana. Jangan pernah dipakai untuk tool calling multi-langkah.
- MiniMax M2.5/M2.7: Driver harian untuk tugas coding umum. dengan harga cuma sebagian kecil dari Sonnet.
- Claude Haiku 4.5: Fallback andal saat model murah kesulitan memanggil tool. Keandalan tool-calling sangat bagus dengan harga sekitar 3x lebih murah daripada Sonnet.
- Claude Sonnet 4.6: Kerja agentic multi-langkah yang kompleks. Di sinilah kamu benar-benar dapat nilai sepadan dengan uangnya.
- Claude Opus: Simpan untuk masalah paling sulit. Jangan jadikan ini default untuk apa pun.
(Harga model sering berubah — cek tarif terbaru di atau halaman provider langsung sebelum mengunci konfigurasi.)
Kebocoran Token Tersembunyi yang Sering Dilewatkan Panduan Lain
Pengguna forum melaporkan bahwa menonaktifkan fitur tertentu bisa memangkas biaya secara drastis, tapi sejauh yang saya temukan belum ada panduan yang menyatukan semua kebocoran tersembunyi beserta dampak token sebenarnya. Berikut bedah lengkapnya:
| Kebocoran Tersembunyi | Biaya Token per Kemunculan | Cara Memperbaiki | Kunci Konfigurasi |
|---|---|---|---|
| Heartbeat default di Opus | ~100.000 token/run tanpa isolasi | Override ke Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Pembuatan sub-agent | ~20.000 token per spawn sebelum kerja apa pun | Arahkan sub-agent ke Haiku | subagents.model |
| Pemuatan konteks seluruh codebase | ~3.000–15.000 token per auto-explore | .clawignore untuk node_modules, dist, lockfile | .clawrules + .clawignore |
| Auto-summarize memory | ~500–2.000 token/sesi | Nonaktifkan atau kurangi frekuensi | memory: false atau memory.max_context_tokens |
| Akumulasi history percakapan | ~500+ token/putaran (kumulatif) | Mulai sesi baru antara tugas yang tidak berkaitan | Disiplin /clear |
| Overhead tool MCP server | ~7.000 token untuk 4 server; 50.000+ untuk 5+ | Jaga MCP seminimal mungkin | Hapus MCP yang tidak dipakai |
| Inisialisasi skill/plugin | 200–1.000 token per skill yang dimuat | Nonaktifkan skill yang tidak dipakai | skills.entries.<name>.enabled: false |
| Agent Teams (mode plan) | ~7x biaya sesi standar | Pakai hanya untuk kerja yang benar-benar paralel | Lebih baik sekuensial |
Kebocoran heartbeat pantas diberi sorotan khusus. Secara default, heartbeat berjalan di model utama (Opus) setiap 30 menit. Menyetel isolatedSession: true menurunkannya dari sekitar ~100.000 token per run — pengurangan 95–98% di satu bucket saja.
Tiga Quick Win yang Menghemat Token Paling Banyak Kurang dari Dua Menit
Ketiganya tanpa risiko dan kurang dari dua menit:
-
/cleardi antara tugas yang tidak saling berhubungan (5 detik). Ini penyelamat token terbesar. Konsensus forum menempatkannya pada cuma dengan membersihkan histori sesi sebelum mulai pekerjaan baru. Ingat bucket Messages berisi 185k token dari dump /context tadi?/clearmenghapusnya. -
/model haiku-4.5untuk pekerjaan kasar (10 detik). Ganti model secara taktis menghasilkan untuk tugas rutin. Haiku sangat cukup untuk coding sederhana, lookup file, dan pesan commit. -
Pangkas
.clawruleske <200 baris + tambahkan.clawignore(90 detik). File rules kamu dimuat di setiap pesan. Pada 200 baris, itu sekitar ~1.500–2.000 token per putaran; pada 1.000 baris, sekitar 8.000–10.000 token yang terus membebani tiap request. Ditambah.clawignoreyang mengecualikannode_modules/,dist/, lockfile, dan kode yang dihasilkan, satu developer mengklaim hanya dari disiplin ini.
Langkah Demi Langkah: Tiga Konfigurasi Siap Salin untuk Memangkas Pemakaian Token OpenClaw

Berikut tiga konfigurasi openclaw.json lengkap dengan anotasi — dari “mulai dulu” sampai “stack optimasi penuh.” Masing-masing dilengkapi komentar inline dan estimasi biaya bulanan.
Sebelum Memulai:
- Tingkat Kesulitan: Pemula (Config A) → Menengah (Config B) → Lanjutan (Config C)
- Waktu yang Dibutuhkan: ~5 menit untuk Config A, ~15 menit untuk Config C
- Yang Kamu Perlukan: OpenClaw terpasang, editor teks, akses ke
~/.openclaw/openclaw.json
Config A: Pemula — Fokus Hemat Biaya
Lima baris. Tanpa ribet. Mengganti model default dari Opus ke Sonnet, mematikan overhead memory, dan mengisolasi heartbeat ke Haiku.
1// ~/.openclaw/openclaw.json
2{
3 "agents": {
4 "defaults": {
5 "model": { "primary": "anthropic/claude-sonnet-4-6" }, // sebelumnya Opus — langsung hemat 3-5x
6 "heartbeat": {
7 "every": "55m", // sejajarkan dengan TTL cache 1 jam untuk hit cache maksimal
8 "model": "anthropic/claude-haiku-4-5", // Haiku untuk ping, bukan Opus
9 "isolatedSession": true // ~100k → 2-5k token per run
10 }
11 }
12 },
13 "memory": { "enabled": false } // hemat ~500-2k token/sesi
14}Yang seharusnya kamu lihat setelah menerapkan ini: Jalankan /status sebelum dan sesudah. Biaya per request harus turun cukup terasa, dan entri heartbeat di halaman Activity OpenRouter kamu harus menampilkan Haiku, bukan Opus.
| Tingkat Penggunaan | Default (Opus) | Config A (Sonnet + heartbeat Haiku) | Penghematan |
|---|---|---|---|
| Ringan (~10 q/hari) | ~$100 | ~$35 | 65% |
| Menengah (~50 q/hari) | ~$500 | ~$250 | 50% |
| Berat (~200 q/hari) | ~$1,750 | ~$900 | 49% |
Config B: Menengah — Routing Cerdas Tiga Lapisan
Sonnet utama untuk kerja serius. Haiku untuk sub-agent dan compaction. Gemini Flash-Lite sebagai fallback hemat saat Claude sedang ditahan. Rantai fallback menangani gangguan provider secara otomatis.
1{
2 "agents": {
3 "defaults": {
4 "model": {
5 "primary": "anthropic/claude-sonnet-4-6",
6 "fallbacks": [
7 "anthropic/claude-haiku-4-5", // jika Sonnet sedang throttled
8 "google/gemini-2.5-flash-lite" // opsi terakhir super murah
9 ]
10 },
11 "models": {
12 "anthropic/claude-sonnet-4-6": {
13 "params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
14 }
15 },
16 "heartbeat": {
17 "every": "55m", // 55 menit < TTL cache 1 jam = cache hit
18 "model": "google/gemini-2.5-flash-lite", // biaya per ping sangat kecil
19 "isolatedSession": true,
20 "lightContext": true // konteks minimal untuk heartbeat
21 },
22 "subagents": {
23 "maxConcurrent": 4, // turun dari default 8
24 "model": "anthropic/claude-haiku-4-5" // sub-agent tidak butuh Sonnet
25 },
26 "compaction": {
27 "mode": "safeguard",
28 "model": "anthropic/claude-haiku-4-5", // ringkasan compaction via Haiku
29 "memoryFlush": { "enabled": true }
30 }
31 }
32 }
33}Hasil yang diharapkan: Entri sub-agent di log kamu sekarang harus menampilkan harga Haiku. Heartbeat harus nyaris nol biaya. Rantai fallback bikin sesi tetap jalan saat Claude bermasalah — sistem akan turun mulus ke Gemini.
| Tingkat Penggunaan | Default | Config B | Penghematan |
|---|---|---|---|
| Ringan | ~$100 | ~$20 | 80% |
| Menengah | ~$500 | ~$150 | 70% |
| Berat | ~$1,750 | ~$500 | 71% |
Config C: Power User — Stack Optimasi Penuh
Penugasan model per sub-agent, compaction konteks dipatok ke Haiku, routing vision ke Gemini Flash, .clawrules + .clawignore yang ketat, skill yang tidak dipakai dimatikan. Inilah konfigurasi yang membawa kamu ke kisaran penghematan 85–90%.
1{
2 "agents": {
3 "defaults": {
4 "workspace": "~/clawd",
5 "model": {
6 "primary": "anthropic/claude-sonnet-4-6",
7 "fallbacks": [
8 "openrouter/anthropic/claude-sonnet-4-6", // provider berbeda sebagai cadangan
9 "minimax/minimax-m2-7", // fallback murah untuk kerja harian
10 "anthropic/claude-haiku-4-5" // opsi terakhir
11 ]
12 },
13 "models": {
14 "anthropic/claude-sonnet-4-6": {
15 "params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
16 },
17 "minimax/minimax-m2-7": {
18 "params": { "maxTokens": 8192 }
19 }
20 },
21 "heartbeat": {
22 "every": "55m",
23 "model": "google/gemini-2.5-flash-lite",
24 "isolatedSession": true,
25 "lightContext": true,
26 "activeHours": "09:00-19:00" // tidak ada heartbeat semalaman
27 },
28 "subagents": {
29 "maxConcurrent": 4,
30 "model": "anthropic/claude-haiku-4-5"
31 },
32 "contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
33 "compaction": {
34 "mode": "safeguard",
35 "model": "anthropic/claude-haiku-4-5",
36 "identifierPolicy": "strict",
37 "memoryFlush": { "enabled": true }
38 },
39 "bootstrapMaxChars": 12000, // turun dari default 20000
40 "imageModel": "google/gemini-3-flash" // tugas vision lewat model murah
41 }
42 },
43 "memory": { "enabled": true, "max_context_tokens": 800 }, // memory minimal
44 "skills": {
45 "entries": {
46 "web-search": { "enabled": false },
47 "image-generation": { "enabled": false },
48 "audio-transcribe": { "enabled": false }
49 }
50 }
51}Contoh override per sub-agent — tempelkan ke ~/.openclaw/agents/lint-runner/SOUL.md:
1---
2name: lint-runner
3description: Menjalankan cek lint/format dan menerapkan perbaikan sederhana
4tools: [Bash, Read, Edit]
5model: anthropic/claude-haiku-4-5
6---.clawignore minimal yang layak pakai — ini sendiri sudah memangkas bootstrap tipikal dari 150k karakter ke sekitar 30–50k:
1node_modules/
2dist/
3build/
4.next/
5coverage/
6.venv/
7vendor/
8*.lock
9package-lock.json
10yarn.lock
11pnpm-lock.yaml
12*.min.js
13*.min.css
14**/__snapshots__/
15**/*.snap| Tingkat Penggunaan | Default | Config C | Penghematan |
|---|---|---|---|
| Ringan | ~$100 | ~$12 | 88% |
| Menengah | ~$500 | ~$90 | 82% |
| Berat | ~$1,750 | ~$220 | 87% |
Angka-angka ini sejalan dengan dua laporan pengguna nyata yang independen: dokumentasi Praney Behl tentang penurunan dari (potongan 90%), dan studi kasus LaoZhang yang menunjukkan dengan optimasi parsial.
Menggunakan Perintah /model untuk Mengendalikan Pemakaian Token OpenClaw Secara Dinamis
Perintah /model mengganti model aktif untuk putaran berikutnya sambil tetap mempertahankan konteks percakapan — tidak ada reset, tidak ada histori yang hilang. Ini kebiasaan harian yang lama-lama ngumpulin penghematan.
Alur kerja praktis:
- Lagi ngerjain refactor besar yang bikin pusing dan melibatkan banyak file? Tetap di Sonnet.
- Cuma mau tanya cepat “regex ini ngapain?”?
/model haiku, tanya, lalu/model sonnetbuat balik. - Butuh commit message atau rapihin dokumen?
/model flash-lite, kelar.
Kamu bisa menyiapkan alias di openclaw.json pada commands.aliases untuk memetakan nama pendek (haiku, sonnet, opus, flash) ke string provider lengkap. Hemat beberapa ketikan setiap kali pindah model.
Rumusnya: 50 kueri/hari di Sonnet kira-kira $3/hari. 50 kueri yang dibagi 70/20/10 antara Haiku/Sonnet/Opus jadi sekitar $1,10/hari. Dalam sebulan, itu berubah dari $90 jadi $33 — 63% lebih murah tanpa ganti tool, cuma mengubah kebiasaan.
Bonus: Melacak Harga Model OpenClaw di Berbagai Provider dengan Thunderbit
Dengan begitu banyak model dan provider — OpenRouter, Anthropic API langsung, Google AI Studio, DeepSeek, MiniMax — harga sering berubah. Anthropic pernah memangkas harga output Opus sekitar 67% dalam semalam. Google juga memangkas batas free-tier Gemini pada Desember 2025. Menjaga spreadsheet harga statis tetap akurat secara manual itu perjuangan yang nyaris mustahil.
menyelesaikan ini tanpa perlu kode scraping. Ini adalah AI web scraper yang memang dibuat untuk ekstraksi data terstruktur seperti ini.
Alur kerja yang saya pakai:
- Buka halaman model OpenRouter di Chrome lalu klik Thunderbit “AI Suggest Fields.” Tool ini membaca halaman dan mengusulkan kolom — nama model, harga input, harga output, context window, provider.
- Klik Scrape, lalu ekspor langsung ke Google Sheets.
- Atur scheduled scrape dengan bahasa biasa — “setiap Senin jam 9 pagi, ambil ulang daftar model OpenRouter” — dan prosesnya jalan otomatis di cloud.
Setelah itu, pelacak harga pribadimu akan memperbarui dirinya sendiri. Model apa pun yang tiba-tiba jadi 30% lebih murah — atau provider apa pun yang dapat tag Exacto — akan muncul di spreadsheet Senin pagi tanpa kamu perlu ngapa-ngapain. Kami menulis lebih lanjut tentang di blog kami.
Membandingkan harga di halaman provider langsung (Anthropic, Google, DeepSeek)? Subpage scraping Thunderbit akan mengikuti setiap tautan model ke halaman detailnya dan mengambil tarif per provider — berguna saat kamu ingin tahu apakah merutekan Kimi K2.5 lewat OpenRouter lebih murah daripada langsung lewat . Cek untuk detail paket gratis dan paket berbayar.
Poin Penting untuk Memangkas Pemakaian Token OpenClaw
Kerangkanya: Pahami → Pantau → Rute → Optimalkan.
Tindakan dengan dampak terbesar, diurutkan:
- Jangan default ke Opus. Ganti model utama kamu ke Sonnet atau MiniMax M2.7. Ini saja sudah mengurangi biaya 3–5x.
- Isolasi heartbeat. Set
isolatedSession: truedan arahkan heartbeat ke Gemini Flash-Lite. Ini mengubah kebocoran sekitar 100k token menjadi 2–5k. - Arahkan sub-agent ke Haiku. Setiap spawn memuat ~20k token konteks sebelum melakukan apa pun. Jangan biarkan itu terjadi di Opus.
- Gunakan
/clearsecara disiplin. Gratis, cuma 5 detik, dan konsensus komunitas menyebut ini menghemat lebih banyak daripada tindakan tunggal lainnya. - Tambahkan
.clawignore. Mengecualikannode_modules, lockfile, dan artefak build memangkas konteks bootstrap secara drastis. - Pantau dengan
/context detailsebelum dan sesudah perubahan. Kalau nggak bisa diukur, nggak bisa ditingkatkan.
Model termurah tergantung tugasnya. Gemini Flash-Lite untuk heartbeat. MiniMax M2.7 untuk coding harian. Haiku untuk tool calling yang andal. Sonnet untuk kerja multi-langkah yang kompleks. Opus cuma untuk masalah yang benar-benar paling sulit — dan bukan untuk yang lain.
Sebagian besar pembaca bisa lihat penghematan 50–70% dalam satu sore dengan Config A atau B. Penghematan penuh 85–90% butuh menggabungkan semuanya — routing model, perbaikan kebocoran tersembunyi, .clawignore, disiplin sesi — tapi itu bisa dicapai, dan hasilnya tahan lama.
FAQ
1. Berapa biaya OpenClaw per bulan?
Semuanya tergantung konfigurasi, volume penggunaan, dan pilihan model. Pengguna ringan (~10 kueri/hari) biasanya habis $5–30/bulan dengan optimasi, atau $100+ dengan default. Pengguna menengah (~50 kueri/hari) ada di kisaran $90–400/bulan. Pengguna berat bisa sampai pada default — satu kasus ekstrem yang terdokumentasi bahkan mencapai $5.623 dalam sebulan. Telemetri internal Anthropic sendiri menunjukkan median .
2. Model OpenClaw termurah apa yang masih bagus untuk coding?
adalah pilihan harian terbaik secara umum — keandalan tool-calling bagus, SWE-Pro 56,22, dengan harga kira-kira $0,28/$1,10 per satu juta token. Untuk heartbeat dan lookup sederhana, Gemini 2.5 Flash-Lite di $0,10/$0,40 sulit dikalahkan. Claude Haiku 4.5 di $1/$5 adalah fallback kelas menengah yang andal saat kamu butuh tool-calling bagus tanpa membayar harga Sonnet.
3. Apakah saya bisa memakai model free-tier dengan OpenClaw?
Secara teknis, bisa. GPT-OSS-120B gratis di tag :free OpenRouter dan NVIDIA Build. Gemini Flash-Lite punya free tier (15 RPM, 1.000 request/hari). DeepSeek memberi . Tapi free tier biasanya punya rate limit agresif, kecepatan lebih lambat, dan ketersediaan yang nggak stabil. Model berbayar murah — cuma beberapa sen per satu juta token — jauh lebih andal untuk pemakaian rutin.
4. Apakah ganti model di tengah percakapan dengan /model akan menghilangkan konteks saya?
Tidak. /model mempertahankan seluruh konteks sesi kamu — putaran berikutnya akan memakai model baru dengan riwayat lengkap tetap utuh. Ini sudah diverifikasi di dokumentasi konsep OpenClaw dan bekerja dengan cara yang sama di Claude Code. Kamu bebas bolak-balik antara Haiku untuk pertanyaan cepat dan Sonnet untuk pekerjaan kompleks tanpa kehilangan apa pun.
5. Apa cara tercepat untuk menurunkan tagihan OpenClaw saya hari ini?
Ketik /clear di antara tugas yang tidak saling berhubungan. Gratis, cuma lima detik, dan menghapus riwayat percakapan yang dikirim ulang di setiap API call. Satu sesi nyata menunjukkan riwayat pesan yang terakumulasi — semuanya dikirim ulang dan ditagih ulang di setiap putaran. Membersihkannya sebelum mulai kerja baru adalah kebiasaan dengan ROI tertinggi yang bisa kamu bangun.