

Mengoptimalkan query list di Apollo bukan cuma urusan teknis—ini adalah kemampuan penting buat siapa pun yang mengandalkan data berita real-time, ekstraksi berita otomatis, atau alur kerja sales dan operasional dengan volume tinggi. Saya sudah lihat sendiri bagaimana query list yang lambat bisa mengubah dashboard yang mulus jadi hambatan, bikin tim sales menatap loading yang muter terus, dan tim ops sibuk cari jalan pintas di spreadsheet. Di dunia yang di mana 60% waktu tenaga penjualan sudah habis untuk tugas non-penjualan, setiap milidetik itu sangat berarti.
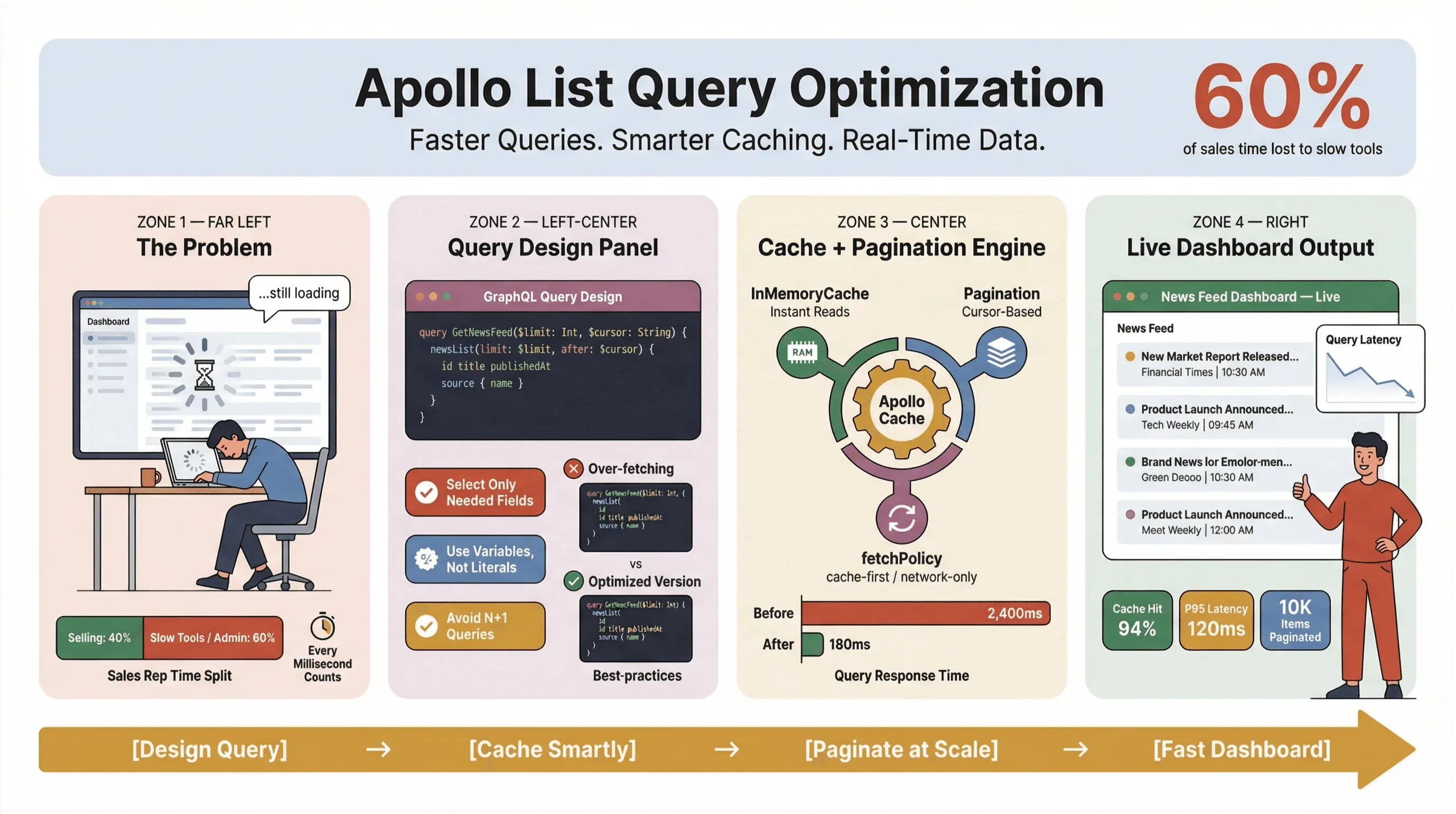
Jadi, gimana caranya supaya query list di Apollo Client tetap cepat, andal, dan konsisten saat skala makin besar — terutama ketika kamu sedang scraping berita, melacak lead, atau menjalankan dashboard yang kritis? Di panduan ini, saya akan bahas praktik yang sudah terbukti aman di lingkungan produksi: desain query, caching, pagination, dan integrasi alat no-code seperti Thunderbit untuk mengotomatiskan pekerjaan ekstraksi berita yang repetitif.
--- Baik kamu seorang developer, product manager, atau orang yang paling sering disalahkan saat dashboard terasa lambat, ini adalah playbook kamu untuk performa list Apollo GraphQL.
Coba Thunderbit untuk Ekstraksi Berita Otomatis
Kenapa Query Apollo List Perlu Dioptimalkan? (apollo client list performance, optimize apollo list queries)
Jujur saja: tidak ada yang suka nunggu headline berita atau lead penjualan selesai dimuat. Dalam lingkungan bisnis — terutama yang mengandalkan ekstraksi berita otomatis atau data real-time — query list Apollo yang lambat bukan cuma bikin kesal; itu juga bisa bikin biaya membengkak, keputusan tertunda, dan orang balik lagi ke kerjaan manual. Riset berulang dari Slack Workforce Lab secara konsisten menunjukkan pekerja kantor menghabiskan sekitar sepertiga — dan dalam laporan yang lebih baru, mendekati 40% — dari hari mereka untuk tugas repetitif bernilai rendah, sering kali karena alat yang mereka pakai memecah pekerjaan di permukaan yang lambat.
Inilah yang terjadi saat query list tidak dioptimalkan:
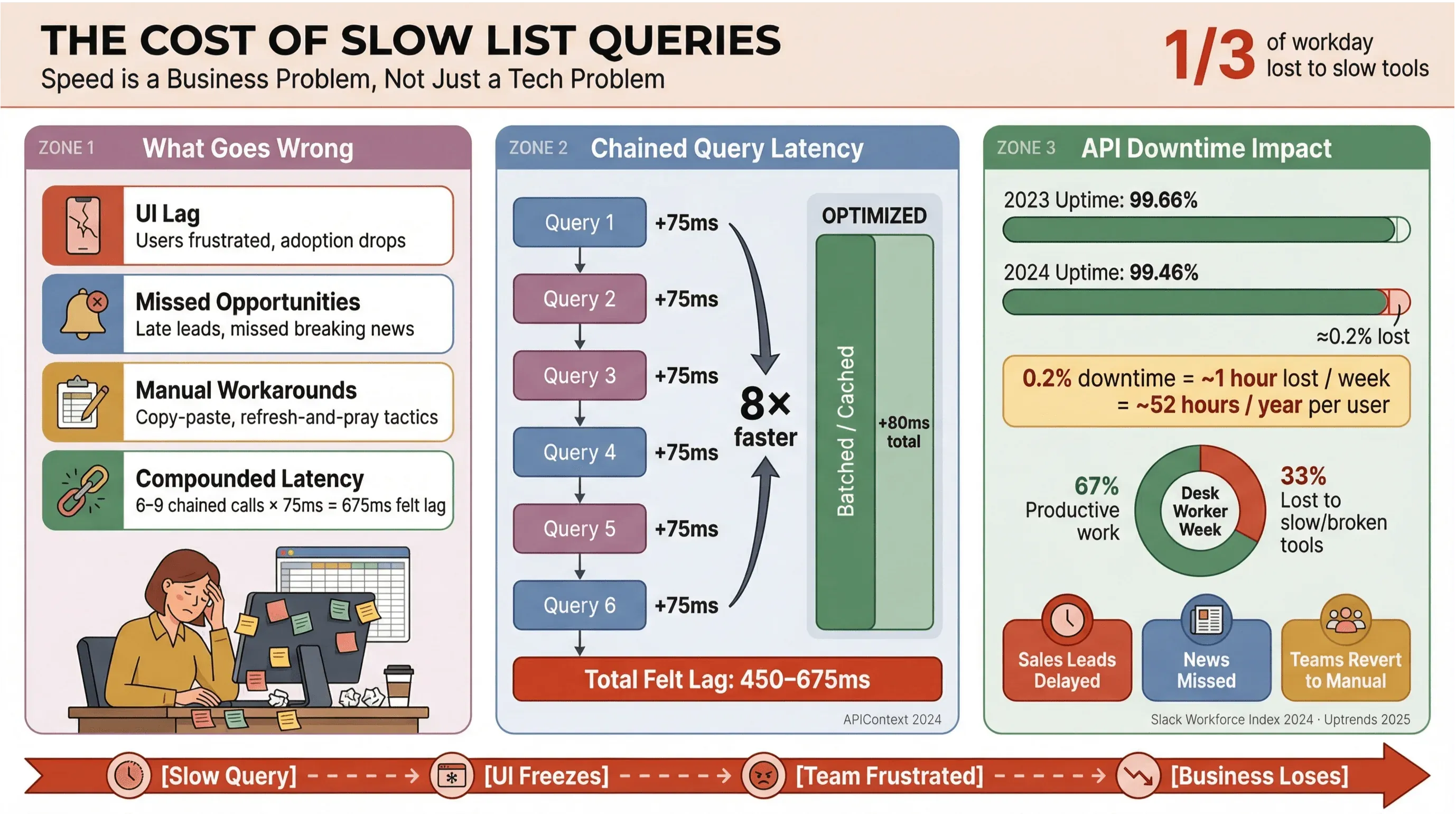
- UI Lambat: Pengguna merasakan jeda, yang ujungnya bikin frustrasi dan adopsi jadi lebih rendah.
- Peluang Terlewat: Dalam sales atau pemantauan berita, telat beberapa detik saja bisa berarti kehilangan lead panas atau breaking news.
- Solusi Manual: Tim balik lagi ke copy-paste, spreadsheet, atau taktik “refresh lalu berdoa”.
- Latensi yang Menumpuk: Setiap panggilan API yang lambat saling menambah; kalau alur kerja kamu memicu 6–9 query yang saling bergantung, keterlambatan 75ms per panggilan bisa berubah jadi lag yang terasa 450–675ms (APIContext).
Dan ini bukan cuma soal kecepatan. Downtime API sedang meningkat, dengan rata-rata uptime turun dari 99,66% menjadi 99,46% hanya dalam satu tahun—artinya hampir satu jam produktivitas hilang setiap minggu untuk aplikasi yang sangat bergantung pada list. Kalau bisnis kamu bergantung pada data berita real-time, risikonya terlalu besar untuk diabaikan.
Memilih Struktur Data dan Field yang Tepat (apollo graphql list best practices)
Salah satu kesalahan paling umum yang saya lihat (dan ya, saya juga pernah melakukannya) adalah memperlakukan semua query list seperti query detail. Di GraphQL, kamu punya kendali untuk mengambil data yang benar-benar dibutuhkan—jadi manfaatkan itu. Mengambil terlalu banyak data adalah musuh performa, terutama di alat scraping berita dan dashboard real-time.
Menyesuaikan Field untuk Ekstraksi Berita Otomatis
Misalnya kamu sedang membangun news feed. Apa kamu benar-benar butuh isi artikel lengkap, semua tag, komentar, dan bio penulis di query list? Kemungkinan besar tidak. Perbedaannya seperti ini:
Query List yang Efisien:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Query List yang Tidak Efisien (Jangan Ditiru):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Query pertama itu ringan dan efisien—pas banget untuk ranking, filtering, dan merender baris data. Query kedua? Itu sebenarnya query detail yang menyamar, menarik payload besar dan bikin semuanya melambat (spesifikasi GraphQL, Apollo best practices).
Tips pro: Pakai pendekatan dua lapis—ambil field ringan saja di list, lalu muat detail berat (seperti full text atau enrichment NLP) hanya saat pengguna membuka item atau mengarahkan kursor ke item tersebut.
Memanfaatkan Apollo Client Cache untuk Query yang Lebih Cepat (apollo client list performance)
Cache di Apollo Client adalah pengungkit terbesar yang bisa kamu manfaatkan untuk performa query list. Kalau dikonfigurasi dengan benar, cache memungkinkan kamu:
- Menyajikan query berulang secara instan (tanpa bolak-balik ke jaringan)
- Mengurangi beban server dan biaya API
- Mendukung navigasi maju/mundur dan perubahan filter yang mulus
Tapi caching bukan sihir—tetap perlu pengaturan dan disiplin.
Menetapkan Kebijakan Cache yang Efektif
Apollo mendukung beberapa fetch policy:
| Kebijakan | Fungsinya | Kasus Penggunaan Terbaik untuk News List |
|---|---|---|
| cache-first | Membaca dari cache, lalu ambil dari jaringan jika belum ada | Membuka ulang list, ganti filter, navigasi maju/mundur |
| network-only | Selalu mengambil dari jaringan | Refresh manual, “headline terbaru” |
| cache-and-network | Menampilkan cache terlebih dahulu, lalu memperbarui dari jaringan | Tampilan awal cepat + update di latar belakang (bagus untuk news feed) |
| no-cache | Selalu ambil, tidak pernah disimpan di cache | Query sensitif sekali jalan (jarang untuk list) |
Untuk data berita real-time, saya suka cache-and-network—hasil tampil cepat, lalu diperbarui di latar belakang. Hanya saja, hati-hati dengan UI yang berkedip kalau data kamu berubah urutan saat refresh (GitHub issue).
Tips konfigurasi cache:
- Gunakan ID yang stabil (
idatau_id) untuk normalisasi (Apollo cache docs). - Sesuaikan ukuran cache dan garbage collection untuk list besar (memory management).
- Hindari menyimpan blob besar yang tidak ternormalisasi di bawah
ROOT_QUERY—ini bisa bikin aplikasi melambat (laporan komunitas).
Menerapkan Pagination dan Membatasi Jumlah Item (apollo graphql list best practices)
Kalau kamu memuat ratusan atau ribuan artikel berita atau lead penjualan sekaligus, kamu sedang mengundang masalah. Pagination bukan cuma fitur UX—ini kebutuhan performa.
Apollo mendukung offset-based dan cursor-based pagination. Berikut perbandingannya:
| Jenis Pagination | Kelebihan | Kekurangan | Paling Cocok Untuk |
|---|---|---|---|
| Offset-based | Sederhana, mudah diimplementasikan | Bisa melewatkan/menduplikasi item jika data berubah | List kecil atau yang relatif tetap |
| Cursor-based | Stabil, lebih tahan terhadap perubahan data | Sedikit lebih kompleks | News feed, list besar |
Untuk sebagian besar list berita real-time atau lead, cursor-based pagination adalah pilihan terbaik. Metode ini menjaga konsistensi data meskipun item baru terus masuk atau item lama dihapus (GraphQL Foundation).
Tips pagination di Apollo:
- Konfigurasikan
keyArgsuntuk mengontrol cache key pada field yang dipaginasi (docs). - Implementasikan fungsi
mergeuntuk menggabungkan halaman data di cache. - Gunakan
fetchMoreuntuk memuat halaman tambahan tanpa menimpa hasil sebelumnya.
Pola Pagination Praktis untuk Alat Scraping Berita
UI scraping berita yang umum biasanya akan:
- Menampilkan 20–50 headline terbaru saja (field ringan)
- Memuat lebih banyak saat scroll atau klik “next page”
- Mengambil detail hanya saat diperlukan
Dengan cara ini, UI tetap cepat, API tetap sehat, dan pengguna tetap produktif.
Mengintegrasikan Thunderbit untuk Ekstraksi Berita Otomatis
Sekarang, mari bahas inti persoalannya: dari mana sebenarnya data berita terstruktur ini berasal? Di sinilah Thunderbit berperan.
Dapatkan Ekstensi Chrome Thunderbit Get Started Free
Thunderbit adalah Chrome Extension AI web scraper tanpa kode yang bisa mengekstrak headline berita, URL, sumber, penulis, tanggal publikasi, ringkasan, dan gambar dari hampir semua website—tanpa perlu coding. Saya sudah lihat tim memakai Thunderbit untuk mengotomatisasi seluruh proses ekstraksi berita, mengubah halaman web yang tidak terstruktur menjadi data yang rapi dan siap pakai, lalu langsung mengirimnya ke database atau GraphQL API.
Menggabungkan Thunderbit dengan Apollo untuk Data Berita Real-Time
Berikut alur kerja yang saya suka untuk tim sales dan ops yang butuh berita terbaru:
- Lapisan Ekstraksi: Gunakan template News Scraper dari Thunderbit untuk menarik data berita terstruktur dari situs target sesuai jadwal.
- Lapisan Penyimpanan: Simpan data hasil scraping di database yang dioptimalkan untuk pengambilan cepat.
- Lapisan GraphQL: Sajikan field list
newsFeeddan field detailnewsArticle(id)melalui API kamu. - Lapisan Client: Gunakan Apollo Client untuk mengambil list (field ringan, dipaginasi), lalu ambil detail hanya saat perlu.
Pipeline “scrape → store → query” ini memastikan query Apollo kamu selalu bekerja dengan data yang segar dan terstruktur—tanpa copy-paste manual atau script rapuh.
Bonus: Thunderbit juga bisa memperkaya list kamu dengan field tambahan (seperti sentimen atau kategori) lewat saran field berbasis AI, sehingga news feed kamu jadi lebih pintar.
Panduan Langkah demi Langkah: Mengoptimalkan Query Apollo List
Siap menerapkannya? Ini checklist andalan saya untuk optimasi query list Apollo:
-
Ringankan Query Kamu
- Hanya minta field yang dibutuhkan untuk merender list (title, URL, timestamp, dan sebagainya).
- Pindahkan field berat (full text, gambar, enrichment) ke query detail.
-
Terapkan Pagination
- Gunakan cursor-based pagination untuk list besar atau yang berubah dinamis.
- Konfigurasikan fungsi
keyArgsdanmergeagar cache tetap akurat.
-
Manfaatkan Apollo Cache
- Normalisasi entitas dengan ID yang stabil.
- Pilih fetch policy yang tepat (
cache-and-networksangat bagus untuk berita). - Sesuaikan ukuran cache dan garbage collection dengan volume data kamu.
-
Integrasikan Ekstraksi Otomatis
- Gunakan Thunderbit untuk mengotomatiskan scraping berita dan menjaga data tetap segar.
- Ekspor data terstruktur langsung ke database atau spreadsheet kamu.
-
Pantau dan Selesaikan Masalah
- Gunakan Apollo Client Devtools untuk memeriksa query, cache, dan performa.
- Waspadai penulisan cache yang terlalu besar, watched queries yang berlebihan, dan UI yang tersendat.
- Lacak p95/p99 latency dan error rate (New Relic, Uptrends).
Memantau dan Menangani Masalah Performa Query
Devtools Apollo sangat membantu di sini. Kamu bisa:
- Memeriksa query aktif dan status cache
- Menemukan query duplikat atau watcher yang berlebihan
- Mengidentifikasi blob cache besar atau masalah normalisasi
Kalau kamu melihat UI melambat atau update terasa berat, cek hal-hal berikut:
- Query list yang terlalu besar (ringankan isinya)
- Normalisasi cache yang buruk (perbaiki ID kamu)
- Masalah merge pagination (audit
keyArgsdanmergekamu)
Dan jangan lupa ukur tail latency—not just average. Di situlah rasa sakit pengguna yang sebenarnya tersembunyi.
Perbandingan Pendekatan Scraping Berita Tradisional vs Berbasis AI
Jujur saja: dulu scraping data berita berarti nulis script khusus, bergelut dengan headless browser, dan berharap layout situs tidak berubah semalaman. Sekarang, dengan alat berbasis AI seperti Thunderbit, kamu bisa mengotomatiskan seluruh prosesnya—tanpa kode, tanpa drama.
| Pendekatan | Kekuatan | Keterbatasan untuk Pengguna Bisnis |
|---|---|---|
| Scraping berbasis script | Sangat bisa dikustomisasi, murah dalam skala besar | Perlu pemeliharaan tinggi, butuh waktu engineer |
| Platform scraping terkelola | Cepat untuk mulai, menangani anti-bot | Tetap butuh konfigurasi, biaya naik seiring penggunaan |
| Ekstraksi berbasis AI (Thunderbit) | Tangguh terhadap layout berantakan, tanpa coding | Output tetap perlu QA, integrasi ke skema kamu |
| Visual scraper no-code | Mudah diakses non-engineer | Bisa rusak saat UI berubah, skala terbatas |
| Infrastruktur proxy/unlocker | Lewati blokir, mendukung throughput tinggi | Tetap butuh logika ekstraksi, ada risiko kepatuhan |
Catatan hukum: Scraping data publik umumnya legal, tetapi tetap hormati terms of service dan rate limit (Reuters).
Poin-Poin Penting untuk Best Practice Apollo GraphQL List
Mari rangkum hal-hal yang paling penting:
- Optimalkan untuk kecepatan dan kejelasan: Ringankan query list, gunakan pagination, dan manfaatkan cache secara agresif.
- Struktur itu penting: Ambil hanya data yang kamu butuhkan—pindahkan field berat ke query detail.
- Cache adalah teman kamu: Gunakan normalisasi dan fetch policy Apollo untuk menyajikan data secara instan.
- Otomatiskan ekstraksi: Alat seperti Thunderbit membuat scraping berita dan enrichment list bisa diakses semua orang.
- Pantau dan iterasi: Gunakan Devtools dan dashboard observabilitas untuk menemukan bottleneck lebih awal.
Bagi tim sales, ops, dan news, praktik terbaik ini berarti lebih sedikit waktu menunggu, lebih banyak waktu untuk bertindak—dan jauh lebih sedikit pesan Slack bernada, “kenapa ini lambat banget?”
Kesimpulan: Langkah Berikutnya untuk Mengoptimalkan Query Apollo List Kamu
Kalau saat ini kamu masih menjalankan query list yang berat, tanpa pagination, atau tidak ramah cache, sekarang saatnya audit dan upgrade. Mulailah dari yang kecil: rapikan field, tambahkan pagination, dan sesuaikan cache kamu. Setelah itu, tingkatkan lagi dengan mengintegrasikan alat ekstraksi otomatis seperti Thunderbit agar data kamu tetap segar dan bisa langsung ditindaklanjuti.
Ingin mendalami lebih jauh? Baca dokumentasi Apollo, Thunderbit Blog, atau bergabung dengan Apollo Community untuk tips praktis dan cara mengatasi masalah di dunia nyata. Dan kalau kamu siap mengotomatiskan ekstraksi berita, coba template News Scraper dari Thunderbit—ini benar-benar mengubah permainan bagi siapa pun yang butuh data real-time tanpa repot.
Gunakan Template Thunderbit News Scraper
Kalau setelah membaca ini kamu cuma melakukan satu hal: ringankan field selection di query list, tambahkan cursor-based pagination, dan pilih fetch policy yang masuk akal. Tiga perubahan ini saja biasanya sudah cukup mengubah query list dari lag yang “terasa” menjadi nyaris “tak terlihat” — dan bikin kamu bisa fokus ke datanya, bukan ke status loading.
FAQ
1. Kenapa query Apollo list bisa melambat di dashboard berita real-time atau sales?
Query list bisa menjadi lambat kalau mengambil terlalu banyak data, tidak punya pagination, atau tidak di-cache dengan benar. Dalam alur kerja berfrekuensi tinggi seperti pemantauan berita, jeda kecil saja akan menumpuk, bikin UI lag dan produktivitas turun.
2. Apa cara terbaik menyusun query Apollo list untuk ekstraksi berita otomatis?
Minta hanya field yang dibutuhkan untuk menampilkan list kamu (misalnya title, URL, timestamp). Pindahkan field berat (seperti isi artikel lengkap atau gambar) ke query detail, lalu paginate hasilnya supaya payload tetap kecil dan cepat.
3. Bagaimana cache Apollo Client meningkatkan performa list?
Cache Apollo menyimpan data yang sudah pernah diambil, jadi query berulang bisa langsung dijawab. Normalisasi cache yang tepat dan fetch policy seperti cache-and-network dapat mempercepat tampilan list secara signifikan dan mengurangi beban server.
4. Bagaimana Thunderbit membantu scraping berita dan integrasi dengan Apollo?
Thunderbit adalah AI web scraper tanpa kode yang mengekstrak data berita terstruktur dari situs web apa pun. Kamu bisa memakainya untuk mengotomatiskan ekstraksi berita, lalu mengirim data tersebut ke database atau GraphQL API untuk dipakai bersama Apollo Client.
5. Alat apa yang bisa saya pakai untuk memantau dan menyelesaikan masalah performa query Apollo list?
Apollo Client Devtools memungkinkan kamu memeriksa query, status cache, dan performa secara real time. Gabungkan dengan dashboard observabilitas (seperti New Relic atau Uptrends) untuk melacak latency dan error rate, lalu iterasikan desain query kamu agar hasilnya optimal.
Ingin lebih banyak tips tentang web scraping, automasi, dan alur kerja data real-time? Lihat Thunderbit Blog untuk pembahasan mendalam, tutorial, dan perkembangan terbaru produktivitas berbasis AI.
Coba Thunderbit AI Web Scraper Get Started Free
Pelajari Lebih Lanjut
- Cara Mengoptimalkan Apollo Lists untuk Manajemen Lead yang Lebih Efektif
- Enrichment Data Apollo: Fitur, Manfaat, dan Dorongan AI
- Cara Menguasai Apollo Prospecting: Panduan Langkah demi Langkah
- Cara Menggunakan Pagination Web Scraper untuk Ekstraksi yang Efisien
- Cara Menggunakan Pagination Web Scraper untuk Ekstraksi yang Efisien




