
Data web sekarang benar-benar “meledak”—dan tekanan buat ngikutin ritmenya juga makin kencang. Saya sering banget lihat tim sales dan operasional malah habis waktu buat “berantem” sama spreadsheet, copy-paste dari website, dan beresin format data, ketimbang fokus ambil keputusan yang berdampak. Menurut Salesforce, sales rep saat ini menghabiskan , dan Asana juga bilang . Intinya, banyak jam kerja kebakar buat ngumpulin data manual—padahal jam segitu bisa dipakai buat closing atau ngegas campaign.
Kabar baiknya: web scraping sekarang sudah jadi praktik yang lumrah, dan kamu nggak harus jadi developer dulu untuk memakainya. Ruby dari dulu memang jadi andalan buat otomatisasi ekstraksi data web. Tapi begitu digabung dengan AI Web Scraper modern seperti , kamu dapat dua benefit sekaligus—fleksibel buat yang bisa ngoding, dan super gampang (web scraper tanpa coding) buat semua orang. Mau kamu marketer, manajer ecommerce, atau siapa pun yang sudah capek copy-paste tanpa ujung, panduan ini bakal bantu kamu paham web scraping dengan ruby dan AI—tanpa perlu nulis kode.
Apa Itu Web Scraping dengan Ruby? Pintu Masuk ke Otomatisasi Data
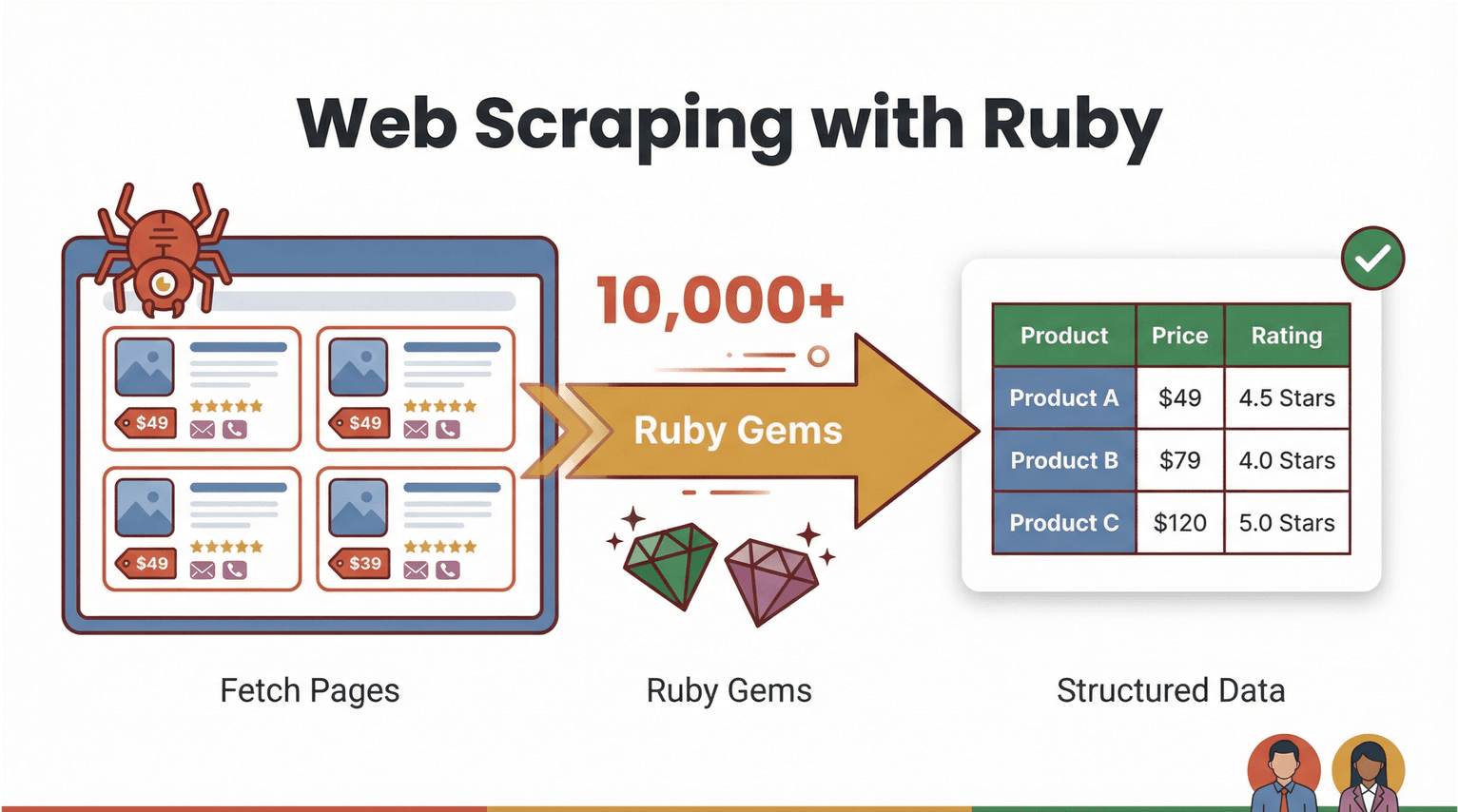
Kita mulai dari fondasinya dulu. Web scraping itu proses memakai software untuk mengambil halaman web lalu mengekstrak informasi tertentu—misalnya harga produk, info kontak, atau ulasan—ke format yang rapi dan terstruktur (seperti CSV atau Excel). Dengan Ruby, web scraping terasa powerful tapi tetap approachable. Ruby terkenal dengan sintaks yang enak dibaca dan ekosistem “gem” (library) yang luas banget, jadi urusan otomatisasi terasa lebih ringan ().
Terus, seperti apa “web scraping dengan ruby” di dunia nyata? Bayangin kamu mau narik semua nama produk dan harga dari sebuah situs ecommerce. Dengan Ruby, kamu bisa bikin script yang:
- Mengunduh halaman web (menggunakan library seperti )
- Mem-parsing HTML untuk menemukan data yang dibutuhkan (dengan )
- Mengekspor hasilnya ke spreadsheet atau database
Tapi yang bikin makin menarik: kamu nggak selalu harus nulis kode. AI web scraper tanpa kode seperti sekarang bisa ngerjain bagian paling “nyebelin”—membaca halaman, mendeteksi field, dan mengekspor tabel data yang bersih cuma dengan beberapa klik. Ruby tetap jadi “lem” otomatisasi yang mantap untuk workflow kustom, sementara AI Web Scraper membuka jalan supaya pengguna bisnis juga bisa ikut menikmati manfaat web scraping.
Kenapa Web Scraping dengan Ruby Penting untuk Tim Bisnis

Jujur aja: nggak ada yang pengin seharian kerja cuma buat copy-paste data. Kebutuhan ekstraksi data web otomatis lagi naik gila-gilaan—dan alasannya jelas. Ini beberapa cara web scraping dengan ruby (plus tool AI) bisa ngubah operasional bisnis:
- Lead Generation: Tarik info kontak dari direktori atau LinkedIn buat ngisi pipeline sales.
- Monitoring Harga Kompetitor: Pantau perubahan harga ratusan SKU ecommerce—tanpa harus cek manual.
- Membangun Katalog Produk: Kumpulkan detail produk dan gambar untuk toko atau marketplace kamu.
- Riset Pasar: Ambil ulasan, rating, atau artikel berita untuk analisis tren.
ROI-nya kerasa banget: tim yang mengotomatiskan pengumpulan data web bisa hemat jam kerja tiap minggu, mengurangi error, dan dapat data yang lebih fresh serta lebih bisa dipercaya. Di manufaktur misalnya, , padahal volume data sudah dobel hanya dalam dua tahun. Ini jelas peluang besar buat otomatisasi.
Berikut ringkasan cepat gimana web scraping dengan ruby dan tool AI memberi nilai:
| Use Case | Masalah Saat Manual | Manfaat Otomatisasi | Hasil Umum |
|---|---|---|---|
| Lead Generation | Menyalin email satu per satu | Scrape ribuan dalam hitungan menit | Lead 10x lebih banyak, kerja repetitif berkurang |
| Monitoring Harga | Cek situs setiap hari | Penarikan harga terjadwal & otomatis | Insight harga real-time |
| Membangun Katalog | Input data manual | Ekstraksi massal & format otomatis | Launch lebih cepat, error lebih sedikit |
| Riset Pasar | Baca ulasan satu-satu | Scrape & analisis dalam skala besar | Insight lebih dalam dan lebih up-to-date |
Dan ini bukan cuma soal lebih cepat—otomatisasi juga berarti lebih minim salah input dan data lebih konsisten, yang krusial ketika .
Menjelajahi Solusi Web Scraping: Script Ruby vs. Tool AI Web Scraper
Jadi, mending kamu nulis script Ruby sendiri atau pakai AI Web Scraper yang web scraper tanpa coding? Yuk kita bedah dua opsinya.
Scripting Ruby: Kontrol Penuh, Perawatan Lebih Tinggi
Ekosistem Ruby itu kaya banget gem untuk berbagai kebutuhan scraping:
- : Jagoan buat parsing HTML dan XML.
- : Buat ngambil halaman web dan API.
- : Buat situs yang butuh cookie, form, dan navigasi.
- / : Buat otomasi browser beneran (pas untuk situs yang berat JavaScript).
Dengan script Ruby, kamu bebas ngatur logika kustom, pembersihan data, sampai integrasi ke sistem internal. Tapi konsekuensinya kamu juga harus siap maintenance: begitu layout website berubah, script bisa langsung “ngambek”. Dan kalau kamu belum nyaman ngoding, kurva belajarnya lumayan.
AI Web Scraper & Tool Tanpa Kode: Cepat, Ramah Pengguna, dan Lebih Adaptif
Tool web scraper tanpa coding seperti bikin pendekatannya beda total. Alih-alih nulis kode, kamu cukup:
- Buka ekstensi Chrome
- Klik “AI Suggest Fields” biar AI mendeteksi data apa yang perlu diekstrak
- Klik “Scrape” lalu ekspor datanya
AI Thunderbit bisa adaptasi saat layout web berubah, bisa handle subpage (misalnya halaman detail produk), dan ekspor langsung ke Excel, Google Sheets, Airtable, atau Notion. Pas banget buat pengguna bisnis yang pengin hasil cepat tanpa ribet.
Perbandingan singkatnya:
| Pendekatan | Kelebihan | Kekurangan | Paling Cocok Untuk |
|---|---|---|---|
| Scripting Ruby | Kontrol penuh, logika kustom, fleksibel | Belajar lebih menantang, perlu maintenance | Developer, pengguna advanced |
| AI Web Scraper | Tanpa kode, setup cepat, adaptif terhadap perubahan | Kontrol lebih terbatas, ada batasan tertentu | Pengguna bisnis, tim ops |
Trennya makin jelas: saat website makin kompleks (dan makin “defensif”), AI Web Scraper makin sering jadi pilihan utama untuk workflow bisnis.
Mulai dari Nol: Menyiapkan Environment Web Scraping Ruby
Kalau kamu pengin coba scripting Ruby, kita siapin environment-nya dulu. Enaknya, Ruby gampang dipasang dan jalan di Windows, macOS, maupun Linux.
Langkah 1: Instal Ruby
- Windows: Unduh lalu ikuti instruksinya. Pastikan menyertakan MSYS2 untuk membangun native extension (dibutuhkan oleh gem seperti Nokogiri).
- macOS/Linux: Pakai untuk manajemen versi. Di Terminal:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(Cek untuk versi stabil terbaru.)
Langkah 2: Instal Bundler dan Gem Penting
Bundler membantu ngatur dependency:
1gem install bundlerBuat Gemfile untuk project kamu:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'Lalu jalankan:
1bundle installIni bikin environment kamu konsisten dan siap buat scraping.
Langkah 3: Uji Setup
Coba di IRB (interactive shell Ruby):
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONKalau keluar nomor versi, berarti aman.
Step-by-Step: Membuat Web Scraper Ruby Pertama Anda
Sekarang kita pakai contoh yang nyata—ngambil data produk dari , situs yang memang dibuat buat latihan scraping.
Ini script Ruby sederhana untuk mengekstrak judul buku, harga, dan status stok:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #{res.code} for #{url}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#{BASE_URL}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #{rows.length} rows to books.csv"Script ini bakal ambil setiap halaman, parsing HTML, ekstrak data, lalu nulisnya ke file CSV. Kamu bisa buka books.csv di Excel atau Google Sheets.
Kendala yang sering kejadian:
- Kalau muncul error gem tidak ditemukan, cek lagi Gemfile kamu lalu jalankan
bundle install. - Untuk situs yang memuat data lewat JavaScript, kamu butuh tool otomasi browser seperti Selenium atau Watir.
Meningkatkan Scraping Ruby dengan Thunderbit: AI Web Scraper dalam Praktik
Sekarang kita masuk ke bagian yang bikin kerjaan makin sat-set: gimana bisa bikin scraping kamu jauh lebih ngebut—tanpa coding.
Thunderbit adalah yang memungkinkan kamu mengekstrak data terstruktur dari website apa pun cuma dalam dua klik. Alurnya begini:
- Buka ekstensi Thunderbit di halaman yang mau kamu scrape.
- Klik “AI Suggest Fields.” AI Thunderbit memindai halaman dan menyarankan kolom terbaik untuk diekstrak (misalnya “Product Name,” “Price,” “Stock”).
- Klik “Scrape.” Thunderbit ngambil data, handle pagination, dan bahkan ngikutin subpage kalau kamu butuh detail tambahan.
- Ekspor data langsung ke Excel, Google Sheets, Airtable, atau Notion.
Kekuatan Thunderbit ada di kemampuannya menangani halaman web yang kompleks dan dinamis—tanpa selector yang rapuh atau kode yang gampang patah. Dan kalau kamu mau workflow hybrid, kamu bisa pakai Thunderbit buat ekstraksi, lalu lanjut proses/enrichment pakai Ruby.
Tips pro: Fitur subpage scraping Thunderbit itu penyelamat buat tim ecommerce dan properti. Kamu bisa scrape daftar link produk, lalu biarkan Thunderbit buka satu-satu untuk narik spesifikasi detail, gambar, atau ulasan—otomatis bikin dataset kamu makin kaya.
Contoh Nyata: Scraping Data Produk & Harga Ecommerce dengan Ruby dan Thunderbit
Sekarang kita satukan semuanya jadi workflow yang realistis buat tim ecommerce.
Skenario: kamu mau memantau harga kompetitor dan detail produk untuk ratusan SKU.
Langkah 1: Gunakan Thunderbit untuk Scrape Daftar Produk Utama
- Buka halaman listing produk kompetitor.
- Jalankan Thunderbit, klik “AI Suggest Fields” (misalnya Product Name, Price, URL).
- Klik “Scrape” lalu ekspor hasilnya ke CSV.
Langkah 2: Perkaya Data dengan Subpage Scraping
- Di Thunderbit, pakai fitur “Scrape Subpages” untuk mengunjungi halaman detail tiap produk dan mengambil field tambahan (misalnya deskripsi, stok, atau gambar).
- Ekspor tabel yang sudah diperkaya.
Langkah 3: Olah atau Analisis dengan Ruby
- Pakai script Ruby untuk bersihin, transform, atau analisis data. Contohnya:
- Konversi harga ke mata uang standar
- Filter produk yang stoknya habis
- Bikin statistik ringkas
Ini snippet Ruby sederhana untuk memfilter produk yang masih tersedia:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6endHasil:
Kamu pindah dari halaman web mentah ke tabel data yang rapi dan siap dipakai—buat analisis harga, perencanaan stok, atau campaign marketing. Dan semuanya bisa dilakukan tanpa nulis satu baris pun kode scraping.
Tanpa Coding? Bukan Masalah: Otomatisasi Ekstraksi Data Web untuk Semua Orang
Salah satu hal yang paling saya suka dari Thunderbit adalah gimana tool ini bikin pengguna non-teknis jadi “berdaya”. Kamu nggak perlu ngerti Ruby, HTML, atau CSS—cukup buka ekstensi, biarkan AI kerja, lalu ekspor datanya.
Kurva belajar: Kalau pakai script Ruby, kamu perlu paham dasar pemrograman dan struktur web. Kalau pakai Thunderbit, setup-nya hitungan menit, bukan hari.
Integrasi: Thunderbit bisa ekspor langsung ke tool yang sudah dipakai tim bisnis—Excel, Google Sheets, Airtable, Notion. Kamu juga bisa menjadwalkan scraping berkala untuk monitoring rutin.
Pengalaman pengguna: Saya sering lihat tim marketing, sales ops, dan manajer ecommerce pakai Thunderbit buat otomatisasi banyak hal—dari bikin daftar lead sampai tracking harga—tanpa harus minta bantuan IT.
Best Practice: Menggabungkan Ruby dan AI Web Scraper untuk Otomatisasi yang Skalabel
Kalau kamu pengin workflow scraping yang kuat dan gampang diskalakan, ini beberapa tips utama:
- Antisipasi perubahan website: AI Web Scraper seperti Thunderbit biasanya bisa menyesuaikan otomatis, tapi kalau kamu pakai script Ruby, siap-siap update selector saat situs berubah.
- Jadwalkan scraping: Pakai fitur penjadwalan Thunderbit untuk penarikan data rutin. Untuk Ruby, pakai cron job atau task scheduler.
- Proses bertahap (batch): Untuk dataset besar, pecah scraping jadi beberapa batch biar nggak gampang diblokir atau membebani sistem.
- Rapikan format data: Selalu bersihkan dan validasi data sebelum analisis—ekspor Thunderbit sudah terstruktur, tapi script Ruby kustom mungkin butuh pengecekan tambahan.
- Kepatuhan: Hanya scrape data yang tersedia publik, hormati
robots.txt, dan perhatikan aturan privasi (terutama di UE—). - Strategi cadangan: Kalau situs terlalu kompleks atau memblokir scraping, pertimbangkan API resmi atau sumber data alternatif.
Kapan pakai yang mana?
- Pakai script Ruby saat kamu butuh kontrol penuh, logika kustom, atau integrasi ke sistem internal.
- Pakai Thunderbit saat kamu butuh cepat, mudah, dan adaptif—terutama untuk tugas bisnis sekali jalan atau rutin.
- Gabungkan keduanya untuk workflow tingkat lanjut: biarkan Thunderbit menangani ekstraksi, lalu gunakan Ruby untuk enrichment, QA, atau integrasi.
Penutup & Poin Penting
web scraping dengan ruby dari dulu memang “superpower” buat otomatisasi pengumpulan data—dan sekarang, berkat AI Web Scraper seperti Thunderbit, kekuatan itu jadi bisa diakses siapa saja. Mau kamu developer yang butuh fleksibilitas, atau pengguna bisnis yang pengin hasil cepat, kamu bisa mengotomasi ekstraksi data web, hemat banyak jam kerja manual, dan ambil keputusan lebih baik serta lebih cepat.
Ini poin-poin utama yang perlu kamu ingat:
- Ruby adalah tool yang sangat kuat untuk web scraping dan otomatisasi—terutama dengan gem seperti Nokogiri dan HTTParty.
- AI Web Scraper seperti Thunderbit membuat ekstraksi data mudah untuk non-coder, lewat fitur seperti “AI Suggest Fields” dan subpage scraping.
- Menggabungkan Ruby dan Thunderbit memberi kamu dua keuntungan sekaligus: ekstraksi cepat tanpa kode + otomatisasi dan analisis kustom.
- Otomatisasi pengumpulan data web adalah strategi jitu untuk tim sales, marketing, dan ecommerce—mengurangi kerja manual, meningkatkan akurasi, dan membuka insight baru.
Siap mulai? , coba script Ruby sederhana, dan rasakan sendiri berapa banyak waktu yang bisa kamu hemat. Kalau mau belajar lebih dalam, mampir ke untuk panduan, tips, dan contoh nyata lainnya.
FAQ
1. Apakah saya harus bisa coding untuk memakai Thunderbit untuk web scraping?
Tidak. Thunderbit dibuat untuk pengguna non-teknis. Cukup buka ekstensi, klik “AI Suggest Fields,” dan biarkan AI mengerjakan sisanya. Kamu bisa mengekspor data ke Excel, Google Sheets, Airtable, atau Notion—tanpa coding.
2. Apa keunggulan utama Ruby untuk web scraping?
Ruby punya library kuat seperti Nokogiri dan HTTParty untuk workflow scraping yang fleksibel dan bisa dikustomisasi. Cocok untuk developer yang ingin kontrol penuh, logika khusus, dan integrasi ke sistem lain.
3. Bagaimana cara kerja fitur “AI Suggest Fields” di Thunderbit?
AI Thunderbit memindai halaman web, mengenali field data yang paling relevan (misalnya nama produk, harga, email), lalu menyarankan tabel terstruktur. Kamu bisa menyesuaikan kolom sebelum scraping.
4. Bisakah saya menggabungkan Thunderbit dengan script Ruby untuk workflow yang lebih advanced?
Tentu. Banyak tim memakai Thunderbit untuk mengekstrak data (terutama dari situs yang kompleks atau dinamis), lalu memproses atau menganalisisnya lebih lanjut dengan script Ruby. Pendekatan hybrid ini cocok untuk reporting kustom atau data enrichment.
5. Apakah web scraping legal dan aman untuk kebutuhan bisnis?
Web scraping legal jika kamu mengambil data yang tersedia publik serta mematuhi ketentuan layanan situs dan aturan privasi. Selalu cek robots.txt dan hindari scraping data personal tanpa persetujuan yang tepat—terutama untuk pengguna UE di bawah GDPR.
Penasaran gimana web scraping bisa ngerombak workflow kamu? Coba paket gratis Thunderbit atau eksperimen dengan script Ruby hari ini. Kalau kamu ketemu kendala, dan punya banyak tutorial dan tips biar kamu makin jago otomatisasi data web—tanpa perlu coding.
Pelajari Lebih Lanjut