

Bahasa pemrograman apa yang sebaiknya Anda gunakan untuk web scraping? Jawabannya tergantung pada proyek Anda — dan saya sudah berkali-kali melihat developer frustrasi setelah salah pilih.
Pasar software web scraping mencapai $1,01 miliar pada 2024 dan diperkirakan akan lebih dari dua kali lipat pada 2032. Bahasa yang tepat bisa berarti hasil lebih cepat dan perawatan yang lebih ringan. Kalau salah? Scraper gampang rusak, dan akhir pekan pun habis percuma.
Saya sudah bertahun-tahun membangun alat otomatisasi. Berikut tujuh bahasa yang pernah saya gunakan untuk scraping — lengkap dengan potongan kode, kompromi yang jujur, dan kapan sebaiknya Anda skip coding sama sekali lalu pakai Thunderbit sebagai gantinya.
Cara Kami Memilih Bahasa Terbaik untuk Web Scraping
Dalam web scraping, tidak semua bahasa pemrograman diciptakan sama. Saya pernah melihat proyek melesat — dan juga gagal — karena beberapa faktor utama berikut:
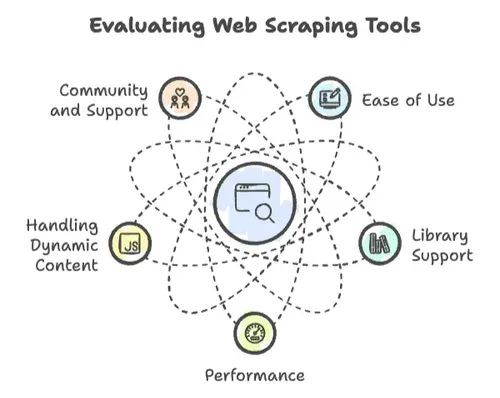
- Kemudahan penggunaan: Seberapa cepat Anda bisa mulai? Apakah sintaksnya ramah, atau Anda perlu gelar PhD ilmu komputer hanya untuk mencetak “Hello, World”?
- Dukungan library: Apakah ada library yang kuat untuk request HTTP, parsing HTML, dan menangani konten dinamis? Atau Anda harus bikin semuanya dari nol?
- Performa: Apakah sanggup menangani scraping jutaan halaman, atau baru menyerah setelah beberapa ratus?
- Menangani konten dinamis: Website modern suka JavaScript. Apakah bahasa Anda bisa mengikuti?
- Komunitas dan dukungan: Saat Anda mentok — dan itu pasti terjadi — adakah komunitas yang bisa membantu?
Berdasarkan kriteria tersebut — dan banyak pengujian larut malam — inilah tujuh bahasa yang akan saya bahas:
- Python: pilihan utama untuk pemula maupun profesional.
- JavaScript & Node.js: rajanya konten dinamis.
- Ruby: sintaks bersih, skrip cepat.
- PHP: kesederhanaan sisi server.
- C++: untuk saat Anda butuh kecepatan mentah.
- Java: siap untuk enterprise dan skalabel.
- Go (Golang): cepat dan konkuren.
Dan kalau Anda berpikir, “Shuai, saya sama sekali tidak mau ngoding,” tunggu sampai bagian Thunderbit di akhir.
Web Scraping dengan Python: Kekuatan Besar yang Ramah Pemula
Kita mulai dari favorit banyak orang: Python. Kalau Anda bertanya ke satu ruangan penuh orang data, “Bahasa pemrograman terbaik untuk web scraping itu apa?” — Anda akan mendengar Python menggema seperti yel-yel di konser Taylor Swift.
Kenapa Python?
- Sintaks ramah pemula: Kode Python bisa dibaca keras-keras dan rasanya hampir seperti bahasa Inggris.
- Dukungan library yang luar biasa: Dari BeautifulSoup untuk parsing HTML, Scrapy untuk crawling skala besar, Requests untuk HTTP, hingga Selenium untuk otomatisasi browser — Python punya semuanya.
- Komunitas sangat besar: Ada lebih dari 33.000 pertanyaan Stack Overflow khusus web scraping.
Contoh Kode Python: Mengambil Judul Halaman
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Judul halaman: {title}")
Kelebihan:
- Pengembangan dan prototyping cepat.
- Banyak sekali tutorial dan tanya-jawab.
- Cocok untuk analisis data — scraping dengan Python, analisis dengan pandas, visualisasi dengan matplotlib.
- Library terus berkembang: rilis Scrapy 2.14 (Januari 2026) menghadirkan
async/awaitnative di seluruh framework, jadi cerita async kini bukan cuma soal Selenium/Playwright.
Keterbatasan:
- Lebih lambat daripada bahasa yang dikompilasi untuk pekerjaan sangat besar.
- Menangani situs yang sangat dinamis bisa terasa kurang rapi (meski Selenium dan Playwright membantu).
- Tidak ideal untuk scraping jutaan halaman dengan kecepatan sangat tinggi.
Kesimpulan singkat:
Kalau Anda baru mulai scraping, atau hanya ingin cepat beres, Python adalah bahasa terbaik untuk web scraping — titik. Baca lebih lanjut kenapa Python mendominasi web scraping.
JavaScript & Node.js: Scraping Website Dinamis dengan Mudah
Kalau Python adalah pisau serbaguna Swiss Army, JavaScript (dan Node.js) adalah bor listrik — terutama untuk scraping website modern yang banyak JavaScript.
Kenapa JavaScript/Node.js?
- Native untuk konten dinamis: Berjalan di browser, jadi bisa melihat apa yang dilihat pengguna — bahkan jika halaman dibuat dengan React, Angular, atau Vue.
- Async secara bawaan: Node.js bisa menangani ratusan request sekaligus.
- Familiar bagi web developer: Kalau Anda pernah membangun website, Anda sudah tahu sebagian JavaScript.
Library Utama:
- Playwright: multi-browser (Chromium, Firefox, WebKit) dengan auto-waiting dan proxy per-context. Kalau Anda memulai scraper Node baru di 2026, ini pilihan default.
- Puppeteer: Headless Chrome lewat Chrome DevTools Protocol. Masih sangat solid untuk pekerjaan khusus Chrome dan dependensi yang lebih ringan.
- Cheerio: parsing HTML ala jQuery untuk Node saat Anda tidak butuh browser sungguhan.
Contoh Kode Node.js: Mengambil Judul Halaman dengan Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Judul halaman: ${title}`);
await browser.close();
})();
Kelebihan:
- Menangani konten yang dirender JavaScript secara native.
- Bagus untuk scraping infinite scroll, pop-up, dan situs interaktif.
- Efisien untuk scraping skala besar secara konkuren.
Keterbatasan:
- Pemrograman async bisa terasa sulit bagi pemula.
- Browser headless memakan memori kalau dijalankan terlalu banyak sekaligus.
- Alat analisis data tidak sebanyak Python.
Kapan JavaScript/Node.js jadi bahasa terbaik untuk web scraping?
Saat target Anda dinamis, atau Anda ingin mengotomatisasi aksi browser. Baca lebih lanjut tentang Node.js untuk scraping konten dinamis.
Ruby: Sintaks Bersih untuk Skrip Web Scraping Cepat
Ruby bukan cuma untuk aplikasi Rails dan prosa kode yang elegan. Ini juga pilihan yang solid untuk web scraping — terutama kalau Anda suka kode yang enak dibaca seperti haiku.
Kenapa Ruby?
- Sintaks mudah dibaca dan ekspresif: Anda bisa menulis scraper Ruby yang hampir semudah daftar belanja.
- Cocok untuk prototyping: Cepat ditulis, mudah diubah.
- Library utama: Nokogiri untuk parsing, Mechanize untuk otomatisasi navigasi.
Contoh Kode Ruby: Mengambil Judul Halaman
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Judul halaman: #{title}"
Kelebihan:
- Sangat mudah dibaca dan ringkas.
- Cocok untuk proyek kecil, skrip sekali pakai, atau jika Anda memang sudah memakai Ruby.
Keterbatasan:
- Lebih lambat daripada Python atau Node.js untuk pekerjaan besar.
- Library scraping dan dukungan komunitas lebih sedikit.
- Tidak ideal untuk situs yang banyak JavaScript (meski Anda bisa memakai Watir atau Selenium).
Paling cocok:
Kalau Anda seorang Rubyist atau hanya ingin membuat skrip cepat, Ruby itu menyenangkan. Untuk scraping besar dan dinamis, cari opsi lain.
PHP: Kesederhanaan Sisi Server untuk Ekstraksi Data Web
PHP mungkin terasa seperti peninggalan web era awal, tapi masih hidup — terutama kalau Anda ingin scraping data langsung di server.
Kenapa PHP?
- Jalan di mana-mana: Sebagian besar web server sudah punya PHP.
- Mudah diintegrasikan dengan web app: Scrape lalu tampilkan di situs Anda dalam satu alur.
- Library utama: cURL untuk HTTP, Guzzle untuk request, Symfony Panther untuk otomatisasi browser headless.
Contoh Kode PHP: Mengambil Judul Halaman
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Judul halaman: $title\n";
?>
Kelebihan:
- Mudah di-deploy ke web server.
- Cocok untuk scraping sebagai bagian dari alur kerja web.
- Cepat untuk tugas scraping sederhana di sisi server.
Keterbatasan:
- Dukungan library terbatas untuk scraping lanjutan.
- Tidak dirancang untuk concurrency tinggi atau scraping skala besar.
- Menangani situs yang banyak JavaScript cukup rumit (meski Panther membantu).
Paling cocok:
Kalau stack Anda sudah PHP, atau Anda ingin scrape dan menampilkan data di situs, PHP adalah pilihan praktis. Baca lebih lanjut PHP vs Python untuk scraping.
C++: Web Scraping Berkinerja Tinggi untuk Proyek Skala Besar
C++ adalah muscle car-nya bahasa pemrograman. Kalau Anda butuh kecepatan mentah dan kontrol penuh, serta tidak takut kerja manual, C++ bisa membawa Anda jauh.
Kenapa C++?
- Sangat cepat: Mengungguli sebagian besar bahasa untuk tugas yang terikat CPU.
- Kontrol sangat detail: Mengelola memori, thread, dan optimasi performa.
- Library utama: libcurl untuk HTTP, htmlcxx untuk parsing.
Contoh Kode C++: Mengambil Judul Halaman
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Judul halaman: " << title << std::endl;
} else {
std::cout << "Tag judul tidak ditemukan" << std::endl;
}
return 0;
}
Kelebihan:
- Kecepatan tak tertandingi untuk pekerjaan scraping besar.
- Cocok untuk mengintegrasikan scraping ke sistem berkinerja tinggi.
Keterbatasan:
- Kurva belajar curam (siapkan kopi).
- Manajemen memori manual.
- Library tingkat tinggi terbatas; tidak ideal untuk konten dinamis.
Paling cocok:
Saat Anda perlu scraping jutaan halaman, atau performa benar-benar kritis. Kalau tidak, Anda mungkin akan menghabiskan lebih banyak waktu untuk debugging daripada scraping.
Java: Solusi Web Scraping Siap Enterprise
Java adalah pekerja andalan dunia enterprise. Kalau Anda membangun sesuatu yang harus jalan terus, menangani banyak data, dan bertahan dari kiamat zombie, Java adalah teman Anda.
Kenapa Java?
- Tangguh dan skalabel: Bagus untuk proyek scraping besar dan jangka panjang.
- Strong typing dan penanganan error yang baik: Lebih sedikit kejutan di produksi.
- Library utama: Jsoup untuk parsing, Selenium WebDriver untuk otomatisasi browser, Apache HttpClient untuk HTTP.
Contoh Kode Java: Mengambil Judul Halaman
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Judul halaman: " + title);
}
}
Kelebihan:
- Performa tinggi dan concurrency yang baik.
- Sangat cocok untuk codebase besar yang harus mudah dirawat.
- Dukungan bagus untuk konten dinamis (via Selenium atau HtmlUnit).
Keterbatasan:
- Sintaks lebih verbose; setup lebih banyak daripada bahasa skrip.
- Berlebihan untuk skrip kecil sekali pakai.
Paling cocok:
Scraping skala enterprise, atau saat Anda butuh keandalan dan skalabilitas yang sangat kuat.
Go (Golang): Web Scraping Cepat dan Konkuren
Go adalah pendatang baru, tapi sudah bikin gebrakan — terutama untuk scraping cepat dan konkuren.
Kenapa Go?
- Kecepatan hasil kompilasi: Hampir secepat C++.
- Concurrency bawaan: Goroutine membuat scraping paralel jadi mudah.
- Library utama: Colly untuk scraping, Goquery untuk parsing.
Contoh Kode Go: Mengambil Judul Halaman
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Judul halaman:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Error:", err)
}
}
Kelebihan:
- Sangat cepat dan efisien untuk scraping skala besar.
- Mudah di-deploy (satu binary).
- Bagus untuk crawling konkuren.
Keterbatasan:
- Komunitas lebih kecil dibanding Python atau Node.js.
- Library scraping tingkat tinggi lebih sedikit.
- Menangani situs yang banyak JavaScript butuh setup tambahan (Chromedp atau Selenium).
Paling cocok:
Saat Anda perlu scraping dalam skala besar, atau Python memang tidak cukup cepat. Go vs Python untuk scraping: perbandingan performa.
Membandingkan Bahasa Pemrograman Terbaik untuk Web Scraping
Mari kita satukan semuanya. Berikut perbandingan berdampingan untuk membantu Anda memilih bahasa terbaik untuk web scraping di 2026:
| Bahasa/Alat | Kemudahan Penggunaan | Performa | Dukungan Library | Penanganan Konten Dinamis | Kasus Penggunaan Terbaik |
|---|---|---|---|---|---|
| Python | Sangat tinggi | Sedang | Luar biasa | Baik (Selenium/Playwright) | Umum, pemula, analisis data |
| JavaScript/Node.js | Sedang | Tinggi | Kuat | Luar biasa (native) | Situs dinamis, scraping async, web dev |
| Ruby | Tinggi | Sedang | Cukup baik | Terbatas (Watir) | Skrip cepat, prototyping |
| PHP | Sedang | Sedang | Lumayan | Terbatas (Panther) | Sisi server, integrasi web app |
| C++ | Rendah | Sangat tinggi | Terbatas | Sangat terbatas | Kritis performa, skala masif |
| Java | Sedang | Tinggi | Baik | Baik (Selenium/HtmlUnit) | Enterprise, layanan jangka panjang |
| Go (Golang) | Sedang | Sangat tinggi | Terus berkembang | Sedang (Chromedp) | Scraping cepat dan konkuren |
Kapan Harus Skip Coding: Thunderbit sebagai Solusi Web Scraping Tanpa Kode
Coba Thunderbit AI Web Scraper Web scraping tanpa kode berbasis AI untuk pengguna bisnis, marketer, dan tim sales. Get Started Free
Baiklah, jujur saja: kadang Anda cuma butuh datanya — tanpa coding, tanpa debugging, dan tanpa drama “kenapa selector ini tidak jalan”. Di situlah Thunderbit masuk.
Sebagai co-founder Thunderbit, saya ingin membangun alat yang membuat web scraping semudah memesan makanan. Inilah yang membuat Thunderbit berbeda:
- Setup 2 klik: Cukup klik “AI Suggest Fields” lalu “Scrape.” Tidak perlu utak-atik request HTTP, proxy, atau trik anti-bot.
- Template cerdas: Satu scraper template bisa menyesuaikan ke banyak layout halaman. Tidak perlu menulis ulang scraper setiap kali situs berubah.
- Scraping browser & cloud: Pilih scraping di browser Anda (bagus untuk situs login) atau di cloud (super cepat untuk data publik).
- Menangani konten dinamis: AI Thunderbit mengontrol browser sungguhan — jadi bisa menangani infinite scroll, pop-up, login, dan lainnya.
- Ekspor ke mana saja: Unduh ke Excel, Google Sheets, Airtable, Notion, atau cukup salin ke clipboard.
- Tanpa perawatan: Kalau situs berubah, cukup jalankan ulang saran AI. Tidak ada lagi sesi debugging larut malam.
- Penjadwalan & otomatisasi: Atur scraper berjalan sesuai jadwal — tanpa cron job, tanpa setup server.
- Extractor khusus: Butuh email, nomor telepon, atau gambar? Thunderbit juga punya extractor sekali klik untuk itu.
Dan bagian terbaiknya? Anda tidak perlu tahu satu baris kode pun. Thunderbit dibuat untuk pengguna bisnis, marketer, tim sales, profesional real estate — siapa saja yang butuh data dengan cepat.
Ingin melihat Thunderbit bekerja? Unduh Ekstensi Chrome atau lihat kanal YouTube kami untuk demo.
Coba Thunderbit AI Web Scraper Gratis
Kesimpulan: Memilih Bahasa Terbaik untuk Web Scraping di 2026
Apa Itu Data Scraping dan Cara Melakukannya Get Started Free
Web scraping di 2026 semakin mudah diakses — dan semakin kuat — daripada sebelumnya. Inilah yang saya pelajari setelah bertahun-tahun berkecimpung di dunia otomatisasi:
- Python masih menjadi bahasa terbaik untuk web scraping kalau Anda ingin mulai cepat dan punya banyak sumber daya di tangan.
- JavaScript/Node.js tak tertandingi untuk scraping situs dinamis yang banyak JavaScript.
- Ruby dan PHP cocok untuk skrip cepat dan integrasi web, terutama jika Anda sudah memakainya.
- C++ dan Go adalah teman Anda saat butuh kecepatan dan skala.
- Java adalah pilihan utama untuk proyek enterprise jangka panjang.
- Dan kalau Anda ingin skip coding sama sekali? Thunderbit adalah senjata rahasia Anda.
Sebelum mulai, tanyakan pada diri sendiri:
- Seberapa besar proyek saya?
- Apakah saya perlu menangani konten dinamis?
- Seberapa nyaman saya dengan teknis?
- Saya ingin membangun sesuatu, atau hanya mendapatkan datanya?
Coba potongan kode di atas, atau pakai Thunderbit untuk proyek Anda berikutnya. Dan kalau ingin mendalami lebih jauh, cek Blog Thunderbit untuk panduan, tips, dan cerita scraping nyata.
Selamat scraping — semoga data Anda selalu bersih, terstruktur, dan hanya sejauh satu klik.
P.S. Kalau Anda pernah terjebak di lubang kelinci web scraping jam 2 pagi, ingat saja: selalu ada Thunderbit. Atau kopi. Atau keduanya.
Coba Thunderbit AI Web Scraper Sekarang Get Started Free
FAQ
1. Apa bahasa pemrograman terbaik untuk web scraping di 2026?
Python tetap menjadi pilihan utama berkat sintaks yang mudah dibaca, library yang kuat (seperti BeautifulSoup, Scrapy, dan Selenium), serta komunitas yang besar. Ini ideal untuk pemula maupun profesional, terutama saat scraping digabung dengan analisis data.
2. Bahasa mana yang terbaik untuk scraping website yang banyak JavaScript?
JavaScript (Node.js) adalah pilihan utama untuk situs dinamis. Alat seperti Puppeteer dan Playwright memberi Anda kontrol penuh atas browser, sehingga Anda bisa berinteraksi dengan konten yang dimuat lewat React, Vue, atau Angular.
3. Apakah ada opsi tanpa kode untuk web scraping?
Ya — Thunderbit adalah AI web scraper tanpa kode yang menangani semuanya, dari konten dinamis hingga penjadwalan. Cukup klik “AI Suggest Fields” lalu mulai scraping. Cocok untuk tim sales, marketing, atau operasi yang butuh data terstruktur dengan cepat.
4. Apakah saya masih perlu memilih bahasa kalau AI coding agent bisa menulis scraper untuk saya?
Pertanyaan yang masuk akal di 2026. Alat seperti Claude Code, Cursor, dan OpenAI Codex dengan senang hati bisa menghasilkan spider Scrapy, skrip Playwright, atau crawler Go + Colly dari prompt satu paragraf — jadi friksi soal “bahasa apa yang harus saya pelajari dulu” memang jauh lebih kecil dibanding dua tahun lalu. Tapi agent itu tetap menulis kode dalam bahasa tertentu, dan Anda (atau siapa pun yang mewarisi proyeknya) tetap harus membaca, debugging, dan me-deploy-nya. Jadi, pilihan bahasa masih penting; hanya saja sekarang lebih penting untuk maintenance daripada untuk 30 baris pertama. Kalau Anda tidak ingin menyentuh kode sama sekali, di situlah Thunderbit cocok — ia melewati pertanyaan bahasa sepenuhnya.
Pelajari Lebih Lanjut:




