Link rusak. Halaman yatim (orphan). Bahkan ada halaman “test” dari 2019 yang entah gimana bisa ikut keindeks Google. Kalau kamu ngurus website, kamu pasti ngerti banget rasanya—bikin geregetan.
crawler website yang bagus bisa “nangkep” semua masalah itu—sekalian memetakan seluruh situs biar kamu benar-benar bisa beresin dari akar. Tapi masalahnya, banyak orang masih nyamain “web crawler” dengan “web scraping”. Padahal, dua hal ini beda banget.
Saya ngetes 10 crawler gratis di berbagai situs beneran. Ada yang jago buat audit SEO. Ada juga yang lebih cocok buat ekstraksi data. Ini yang works—dan yang zonk.
Apa Itu Website Crawler? Memahami Dasar-Dasarnya
Kita beresin dulu dari awal: website crawler itu bukan hal yang sama dengan web scraping. Memang istilahnya sering ketuker-tuker, tapi fungsinya jauh berbeda. Bayangin crawler website itu kayak kartografer (pembuat peta) buat situs kamu—dia keliling ke tiap sudut, ngikutin setiap link, lalu bikin peta semua halaman. Fokus utamanya adalah menemukan: ngumpulin URL, memetakan struktur situs, dan mengindeks konten. Ini juga yang dilakukan mesin pencari seperti Google lewat bot mereka, dan yang dipakai tool SEO buat ngecek “kesehatan” situs ().
Sementara itu, web scraping itu lebih kayak penambang data. Dia nggak terlalu peduli peta lengkap—yang dicari justru “harta karunnya”: harga produk, nama perusahaan, ulasan, email, dan lain-lain. Scraper mengekstrak field tertentu dari halaman yang sudah ditemukan crawler ().
Biar gampang kebayang:
- Crawler: Orang yang nyusurin semua lorong supermarket buat mendata semua produk.
- Scraper: Orang yang langsung cus ke rak kopi dan nyatet harga semua varian organik.
Kenapa ini penting? Karena kalau tujuan kamu cuma pengin nemuin semua halaman di situs (misalnya buat audit SEO), kamu butuh crawler. Tapi kalau kamu pengin narik semua harga produk dari situs kompetitor, kamu butuh scraper—atau idealnya, tool web crawler yang bisa ngerjain dua-duanya.
Kenapa Perlu Web Crawler Online? Manfaat Utama untuk Bisnis
Kenapa harus repot pakai web crawling? Karena web makin hari makin “gede” dan kompleks. Bahkan, lebih dari buat optimasi situs mereka, dan beberapa tool SEO bisa crawl sampai .
Berikut hal-hal yang bisa kamu dapetin dari crawler:
- Audit SEO: Nemuin link rusak, title yang hilang, konten duplikat, halaman orphan, dan lain-lain ().
- Pengecekan Link & QA: Nangkep 404 dan redirect loop sebelum user kamu yang duluan nemu ().
- Pembuatan Sitemap: Bikin sitemap XML otomatis buat mesin pencari dan kebutuhan planning ().
- Inventaris Konten: Nyusun daftar semua halaman, hierarki, dan metadata.
- Kepatuhan & Aksesibilitas: Ngecek tiap halaman untuk WCAG, SEO, dan kepatuhan legal ().
- Performa & Keamanan: Nandain halaman lambat, gambar kegedean, atau isu security ().
- Data untuk AI & Analisis: Masukin hasil crawl ke tool analitik atau AI ().
Berikut tabel singkat yang memetakan use case ke peran bisnis:
| Use Case | Ideal For | Benefit / Outcome |
|---|---|---|
| SEO & Site Auditing | Marketing, SEO, Small Biz Owners | Find technical issues, optimize structure, improve rankings |
| Content Inventory & QA | Content Managers, Webmasters | Audit or migrate content, catch broken links/images |
| Lead Generation (Scraping) | Sales, Biz Dev | Automate prospecting, fill CRM with fresh leads |
| Competitive Intelligence | E-commerce, Product Managers | Monitor competitor prices, new products, stock changes |
| Sitemap & Structure Cloning | Developers, DevOps, Consultants | Clone site structure for redesigns or backups |
| Content Aggregation | Researchers, Media, Analysts | Gather data from multiple sites for analysis or trend monitoring |
| Market Research | Analysts, AI Training Teams | Collect large datasets for analysis or AI model training |
()
Cara Kami Memilih Tool Website Crawler Gratis Terbaik
Saya ngabisin banyak malam (dan kopi lebih banyak dari yang mau saya akui) buat bongkar satu-satu tool web crawler, baca dokumentasi, dan jalanin crawl uji coba. Ini patokan yang saya pakai:
- Kemampuan Teknis: Bisa ngadepin situs modern (JavaScript, login, konten dinamis)?
- Kemudahan Pakai: Ramah buat non-teknis, atau harus jago command line?
- Batas Paket Gratis: Beneran gratis, atau cuma “umpan” trial?
- Akses Online: Berbasis cloud, aplikasi desktop, atau library kode?
- Fitur Unik: Ada nilai tambah kayak ekstraksi AI, sitemap visual, atau crawling berbasis event?
Saya coba tiap tool, cek feedback pengguna, dan bandingin fiturnya side-by-side. Kalau ada tool yang bikin saya pengin lempar laptop keluar jendela, ya jelas nggak masuk list.
Tabel Perbandingan Cepat: 10 Website Crawler Gratis Terbaik Sekilas
| Tool & Type | Core Features | Best Use Case | Technical Needs | Free Plan Details |
|---|---|---|---|---|
| BrightData (Cloud/API) | Enterprise crawling, proxies, JS rendering, CAPTCHA solving | Large-scale data collection | Some tech skill helpful | Free trial: 3 scrapers, 100 records each (about 300 records total) |
| Crawlbase (Cloud/API) | API crawling, anti-bot, proxies, JS rendering | Devs needing backend crawl infra | API integration | Free: ~5,000 API calls for 7 days, then 1,000/month |
| ScraperAPI (Cloud/API) | Proxy rotation, JS rendering, async crawl, prebuilt endpoints | Devs, price monitoring, SEO data | Minimal setup | Free: 5,000 API calls for 7 days, then 1,000/month |
| Diffbot Crawlbot (Cloud) | AI crawl + extraction, knowledge graph, JS rendering | Structured data at scale, AI/ML | API integration | Free: 10,000 credits/month (about 10k pages) |
| Screaming Frog (Desktop) | SEO audit, link/meta analysis, sitemap, custom extraction | SEO audits, site managers | Desktop app, GUI | Free: 500 URLs per crawl, core features only |
| SiteOne Crawler (Desktop) | SEO, performance, accessibility, security, offline export, Markdown | Devs, QA, migration, documentation | Desktop/CLI, GUI | Free & open-source, 1,000 URLs in GUI report (configurable) |
| Crawljax (Java, OpenSrc) | Event-driven crawl for JS-heavy sites, static export | Devs, QA for dynamic web apps | Java, CLI/config | Free & open-source, no limits |
| Apache Nutch (Java, OpenSrc) | Distributed, plugin-based, Hadoop integration, custom search | Custom search engines, large-scale crawl | Java, command-line | Free & open-source, infra cost only |
| YaCy (Java, OpenSrc) | Peer-to-peer crawl & search, privacy, web/intranet indexing | Private search, decentralization | Java, browser UI | Free & open-source, no limits |
| PowerMapper (Desktop/SaaS) | Visual sitemaps, accessibility, QA, browser compatibility | Agencies, QA, visual mapping | GUI, easy | Free trial: 30 days, 100 pages (desktop) or 10 pages (online) per scan |
BrightData: Website Crawler Cloud Kelas Enterprise

BrightData ini “alat beratnya” dunia web crawling. Platform cloud dengan jaringan proxy gede, rendering JavaScript, pemecahan CAPTCHA, plus IDE buat crawl kustom. Kalau kamu jalanin pengumpulan data skala besar—misalnya mantau harga di ratusan situs e-commerce—infrastruktur BrightData susah ditandingi ().
Kelebihan:
- Tangguh buat situs yang proteksinya anti-bot
- Gampang diskalakan untuk kebutuhan enterprise
- Ada template siap pakai untuk situs-situs populer
Kekurangan:
- Nggak ada paket gratis permanen (cuma trial: 3 scraper, masing-masing 100 record)
- Kebesaran buat audit sederhana
- Ada learning curve buat pengguna non-teknis
Kalau kamu butuh crawling skala besar, BrightData itu ibarat nyewa mobil Formula 1. Tapi jangan berharap tetap gratis setelah test drive kelar ().
Crawlbase: Web Crawler Gratis Berbasis API untuk Developer

Crawlbase (dulunya ProxyCrawl) fokus ke crawling yang programatik. Kamu tinggal panggil API pakai sebuah URL, lalu mereka balikin HTML—sementara proxy, geotargeting, dan CAPTCHA diurus di belakang layar ().
Kelebihan:
- Success rate tinggi (99%+)
- Bisa ngadepin situs JavaScript yang berat
- Cocok buat diintegrasi ke aplikasi atau workflow kamu
Kekurangan:
- Perlu integrasi API atau SDK
- Paket gratis: ~5.000 panggilan API selama 7 hari, lalu 1.000/bulan
Kalau kamu developer yang pengin crawling (dan mungkin web scraping) skala besar tanpa ribet ngurus proxy, Crawlbase ini opsi yang solid ().
ScraperAPI: Membuat Crawling Web Dinamis Jadi Lebih Praktis

ScraperAPI itu API “tolong ambilin aja”. Kamu kirim URL, mereka yang ngurus proxy, headless browser, dan anti-bot, lalu balikin HTML (atau data terstruktur untuk beberapa situs). Cocok banget buat halaman dinamis dan punya paket gratis yang lumayan longgar ().
Kelebihan:
- Super gampang buat developer (cukup satu panggilan API)
- Nanganin CAPTCHA, pemblokiran IP, JavaScript
- Gratis: 5.000 panggilan API selama 7 hari, lalu 1.000/bulan
Kekurangan:
- Nggak ada laporan crawl visual
- Kamu perlu nulis logika crawl sendiri kalau mau ngikutin link
Kalau kamu pengin nyolokin web crawling ke codebase dalam hitungan menit, ScraperAPI pilihan yang aman.
Diffbot Crawlbot: Penemuan Struktur Website Secara Otomatis

Diffbot Crawlbot berasa “lebih pinter”. Dia bukan cuma crawling—Diffbot pakai AI buat ngelabelin halaman dan mengekstrak data terstruktur (artikel, produk, event, dll.) ke format JSON. Rasanya kayak punya intern robot yang beneran ngerti apa yang dia baca ().
Kelebihan:
- Ekstraksi berbasis AI, bukan sekadar crawling
- Support JavaScript dan konten dinamis
- Gratis: 10.000 kredit/bulan (sekitar 10 ribu halaman)
Kekurangan:
- Lebih cocok buat developer (integrasi API)
- Bukan tool SEO visual—lebih pas buat proyek data
Kalau kamu butuh data terstruktur skala besar buat AI atau analitik, Diffbot ini kuat banget.
Screaming Frog: Crawler SEO Desktop Gratis

Screaming Frog adalah crawler desktop “legendaris” buat audit SEO. Versi gratisnya bisa crawl sampai 500 URL per scan dan nampilin semuanya: link rusak, meta tag, konten duplikat, sitemap, dan lain-lain ().
Kelebihan:
- Cepat, detail, dan dipercaya komunitas SEO
- Tanpa coding—tinggal masukin URL dan jalanin
- Gratis sampai 500 URL per crawl
Kekurangan:
- Cuma desktop (nggak ada versi cloud)
- Fitur lanjutan (rendering JS, scheduling) butuh lisensi berbayar
Kalau kamu serius soal SEO, Screaming Frog itu wajib punya—tapi jangan berharap bisa crawl situs 10.000 halaman secara gratis.
SiteOne Crawler: Ekspor Situs Statis dan Dokumentasi

SiteOne Crawler itu “pisau lipat” buat audit teknis. Open-source, lintas platform, bisa crawl, audit, bahkan ekspor situs ke Markdown buat dokumentasi atau dipakai offline ().
Kelebihan:
- Nge-cover SEO, performa, aksesibilitas, keamanan
- Bisa ekspor situs buat arsip atau migrasi
- Gratis & open-source, tanpa batas pemakaian
Kekurangan:
- Lebih teknis dibanding beberapa tool GUI
- Laporan audit di GUI dibatasi 1.000 URL secara default (bisa diubah)
Kalau kamu developer, QA, atau konsultan yang butuh insight dalem (dan demen open source), SiteOne ini “hidden gem”.
Crawljax: Web Crawler Java Open Source untuk Halaman Dinamis
Crawljax itu spesialis: dibuat buat crawling web app modern yang berat JavaScript dengan nyimulasikan interaksi user (klik, isi form, dll.). Dia berbasis event dan bahkan bisa bikin versi statis dari situs dinamis ().
Kelebihan:
- Jago banget buat SPA dan situs berat AJAX
- Open-source dan gampang diperluas
- Tanpa batas pemakaian
Kekurangan:
- Butuh Java dan sedikit pemrograman/konfigurasi
- Nggak cocok buat pengguna non-teknis
Kalau kamu perlu crawling aplikasi React atau Angular “seperti user beneran”, Crawljax itu partner terbaik.
Apache Nutch: Website Crawler Terdistribusi yang Skalabel

Apache Nutch adalah “sesepuh” crawler open-source. Dibuat buat crawling masif dan terdistribusi—misalnya kamu mau bikin mesin pencari sendiri atau ngindeks jutaan halaman ().
Kelebihan:
- Bisa diskalakan sampai miliaran halaman dengan Hadoop
- Sangat bisa dikonfigurasi dan diperluas
- Gratis & open-source
Kekurangan:
- Learning curve tajam (Java, command line, konfigurasi)
- Nggak cocok buat situs kecil atau pemakaian santai
Kalau kamu pengin crawling skala web dan nggak takut main command line, Nutch ini tool-nya.
YaCy: Web Crawler dan Mesin Pencari Peer-to-Peer
YaCy adalah crawler dan mesin pencari terdesentralisasi yang unik. Setiap instance melakukan crawl dan indexing, dan kamu bisa gabung ke jaringan peer-to-peer buat berbagi indeks dengan pengguna lain ().
Kelebihan:
- Fokus privasi, tanpa server pusat
- Cocok buat bikin pencarian privat atau intranet
- Gratis & open-source
Kekurangan:
- Kualitas hasil tergantung cakupan jaringan
- Perlu setup (Java, UI via browser)
Kalau kamu tertarik desentralisasi atau pengin punya mesin pencari sendiri, YaCy seru buat dicoba.
PowerMapper: Generator Sitemap Visual untuk UX dan QA

PowerMapper fokus ke visualisasi struktur situs. Dia melakukan crawl lalu bikin sitemap interaktif, sekaligus ngecek aksesibilitas, kompatibilitas browser, dan basic SEO ().
Kelebihan:
- Sitemap visual sangat ngebantu agensi dan desainer
- Ngecek aksesibilitas dan compliance
- GUI gampang, nggak perlu skill teknis
Kekurangan:
- Cuma trial (30 hari, 100 halaman desktop/10 halaman online per scan)
- Versi penuh berbayar
Kalau kamu perlu presentasi peta situs ke klien atau ngecek compliance, PowerMapper ini cukup praktis.
Memilih Web Crawler Gratis yang Tepat untuk Kebutuhan Anda
Dengan pilihan sebanyak ini, gimana cara milihnya? Ini panduan cepat versi saya:
- Untuk audit SEO: Screaming Frog (situs kecil), PowerMapper (visual), SiteOne (audit mendalam)
- Untuk web app dinamis: Crawljax
- Untuk skala besar atau pencarian kustom: Apache Nutch, YaCy
- Untuk developer yang butuh akses API: Crawlbase, ScraperAPI, Diffbot
- Untuk dokumentasi atau arsip: SiteOne Crawler
- Untuk skala enterprise dengan trial: BrightData, Diffbot
Faktor penting yang perlu kamu pertimbangkan:
- Skalabilitas: Seberapa besar situs atau kerjaan crawl kamu?
- Kemudahan penggunaan: Kamu nyaman ngoding, atau maunya tinggal klik-klik?
- Ekspor data: Butuh CSV, JSON, atau integrasi ke tool lain?
- Dukungan: Ada komunitas atau dokumentasi saat kamu mentok?
Saat Web Crawling Bertemu Web Scraping: Kenapa Thunderbit Lebih Cerdas
Faktanya, kebanyakan orang nggak melakukan web crawling cuma buat bikin peta yang rapi. Ujung-ujungnya biasanya pengin data terstruktur—entah itu daftar produk, info kontak, atau inventaris konten. Nah, di sinilah masuk.
Thunderbit bukan sekadar crawler atau scraper—ini ekstensi Chrome berbasis AI yang ngegabungin dua-duanya. Cara kerjanya:
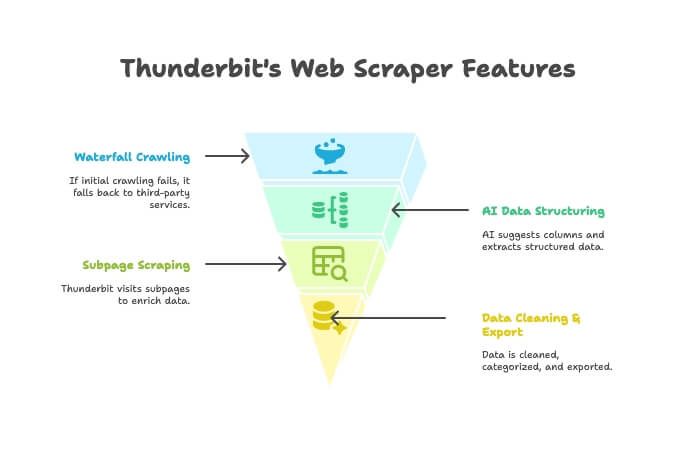
- AI Crawler: Thunderbit menjelajahi situs seperti crawler.
- Waterfall Crawling: Kalau mesin Thunderbit nggak bisa ngambil halaman (misalnya karena tembok anti-bot yang kuat), dia otomatis pindah ke layanan crawling pihak ketiga—tanpa setup manual.
- AI Data Structuring: Setelah HTML didapat, AI Thunderbit nyaranin kolom yang pas dan mengekstrak data terstruktur (nama, harga, email, dll.) tanpa kamu nulis selector.
- Subpage Scraping: Perlu detail dari tiap halaman produk? Thunderbit bisa ngunjungin tiap subpage otomatis dan memperkaya tabel kamu.
- Pembersihan & Ekspor Data: Bisa merangkum, mengelompokkan, menerjemahkan, lalu ekspor ke Excel, Google Sheets, Airtable, atau Notion dalam sekali klik.
- Sederhana Tanpa Kode: Kalau kamu bisa pakai browser, kamu bisa pakai Thunderbit. Tanpa coding, tanpa proxy, tanpa pusing.
Kapan sebaiknya pakai Thunderbit dibanding crawler tradisional?
- Saat tujuan akhir kamu adalah spreadsheet yang rapi dan siap dipakai—bukan cuma daftar URL.
- Saat kamu pengin otomatisin semuanya (crawl, ekstrak, bersihin, ekspor) dalam satu tempat.
- Saat kamu menghargai waktu dan kewarasan.
Kamu bisa dan buktiin sendiri kenapa makin banyak pengguna bisnis mulai pindah.
Kesimpulan: Memaksimalkan Website Crawler Gratis
Website crawler berkembang cepat banget. Mau kamu marketer, developer, atau sekadar pengin jaga situs tetap “sehat”, selalu ada tool gratis (atau minimal gratis buat dicoba) yang cocok. Mulai dari platform kelas enterprise seperti BrightData dan Diffbot, “permata” open-source seperti SiteOne dan Crawljax, sampai pemetaan visual seperti PowerMapper—opsinya makin variatif.
Tapi kalau kamu nyari cara yang lebih cerdas dan terintegrasi buat bergerak dari “saya butuh data ini” jadi “ini spreadsheet saya”, coba Thunderbit. Dibuat buat pengguna bisnis yang ngejar hasil, bukan sekadar laporan.
Siap mulai crawling? Ambil salah satu tool, jalanin scan, dan lihat apa aja yang selama ini kelewat. Dan kalau kamu pengin pindah dari crawling ke data yang bisa ditindaklanjuti cuma dalam dua klik, .
Buat pembahasan yang lebih dalem dan panduan praktis lainnya, mampir ke .
FAQ
Apa bedanya website crawler dan web scraper?
Crawler bertugas menemukan dan memetakan semua halaman di sebuah situs (ibarat bikin daftar isi). Scraper mengekstrak field data tertentu (misalnya harga, email, atau ulasan) dari halaman-halaman itu. Crawler menemukan, scraper menggali ().
Web crawler gratis mana yang paling cocok untuk pengguna non-teknis?
Untuk situs kecil dan audit SEO, Screaming Frog cukup ramah pengguna. Untuk pemetaan visual, PowerMapper bagus (selama masa trial). Thunderbit paling gampang kalau target kamu data terstruktur dan kamu pengin pengalaman tanpa kode langsung dari browser.
Apakah ada website yang memblokir web crawler?
Ada—sebagian situs pakai robots.txt atau proteksi anti-bot (kayak CAPTCHA atau pemblokiran IP) buat ngehalangin crawler. Tool seperti ScraperAPI, Crawlbase, dan Thunderbit (dengan waterfall crawling) sering bisa ngelewatin hambatan ini, tapi tetap lakukan crawling secara bertanggung jawab dan patuhi aturan situs ().
Apakah website crawler gratis punya batas halaman atau fitur?
Kebanyakan iya. Contohnya, versi gratis Screaming Frog dibatasi 500 URL per crawl; trial PowerMapper 100 halaman. Tool berbasis API biasanya punya batas kredit bulanan. Tool open-source seperti SiteOne atau Crawljax umumnya nggak punya batas keras, tapi tetap dibatasi kemampuan hardware kamu.
Apakah penggunaan web crawler legal dan sesuai privasi?
Secara umum, crawling halaman publik itu legal, tapi selalu cek terms of service dan robots.txt situs terkait. Jangan pernah crawl data privat atau yang diproteksi password tanpa izin, dan perhatikan regulasi privasi kalau kamu mengekstrak data personal ().