
Pada 2015, web scraping itu identik dengan “minta tolong developer bikinin skrip Python” atau rela begadang akhir pekan buat belajar XPath. Di 2026, kamu cukup ngetik “ambil semua nama produk dan harganya”, lalu AI yang beresin sisanya.
Perubahannya ngebut banget. Sekarang lebih dari mengandalkan web scraping. Pasarnya tembus dan diprediksi bakal dobel sebelum 2030.
Pendorong paling besarnya? AI web crawler. Mereka bisa adaptasi saat layout berubah, ngerti isi halaman (bukan cuma tag HTML), dan bisa dipakai orang yang bahkan belum pernah nulis kode.
Saya habiskan berbulan-bulan buat ngetes 15 tool. Ini rangkuman temuan saya—termasuk kenapa Thunderbit (iya, perusahaan yang saya ikut dirikan) ada di posisi paling atas.
Mengapa AI Mengubah Cara Scraping Halaman Web: Era Baru Tool Web Scraper
Jujur aja: web scraping tradisional itu memang bukan dibuat buat kebanyakan pengguna bisnis. Isinya kode, selector, dan doa supaya skripnya nggak “pecah” pas website ganti tampilan. Tapi AI dan LLM bener-bener ngebalik permainan.
Begini cara kerjanya:
- Instruksi Bahasa Natural: Daripada ribet ngoding, kamu cukup jelasin kebutuhanmu. Tool seperti paham instruksi bahasa sehari-hari dan nyiapin proses ekstraksinya buat kamu ().
- Pembelajaran Adaptif: Scraper berbasis AI bisa jadi beban maintenance jauh lebih ringan.
- Menangani Konten Dinamis: Website modern doyan pakai JavaScript dan infinite scroll. Tool bertenaga AI bisa “ngoprek” elemen-elemen ini dan nangkep data yang sering kelewat sama scraper “jadul”.
- Output Terstruktur lewat Parsing AI: Scraper berbasis LLM beneran dan ngeluarin data yang rapi serta terstruktur.
- Evasion Anti-Bot Otomatis: Scraper AI bisa pakai proxy/headless browser biar nggak gampang kena blokir IP.
- Workflow Data Terintegrasi: Tool terbaik bukan cuma ngambil data—mereka langsung ngirim ke tempat yang kamu butuhin, misalnya ekspor sekali klik ke Google Sheets, Airtable, Notion, dan lainnya ().
Hasilnya? Web scraping sekarang rasanya kayak point-and-click (bahkan mirip chat), jadi tim sales, marketing, dan operasional—bukan cuma developer—bisa langsung manfaatin data web.
15 AI Web Crawler yang Layak Anda Perhatikan di 2026
Sekarang kita bedah 15 AI web crawler terbaik, mulai dari Thunderbit. Saya bakal bahas fitur inti, target pengguna, harga, dan apa yang bikin tiap tool punya “nilai jual” sendiri. Dan iya, saya bakal jujur soal kelebihan (dan keterbatasan) masing-masing.
1. Thunderbit: AI Web Scraper untuk Semua Orang
Saya memang agak bias, tapi Thunderbit adalah AI web scraper yang dari dulu saya pengin banget sudah ada. Ini alasan kenapa dia #1 di daftar ini:
- Ekstraksi dengan Bahasa Natural: Kamu bisa “ngobrol” sama Thunderbit. Tinggal jelasin data yang kamu mau—misalnya “scrape semua nama produk dan harga dari halaman ini”—dan AI yang ngerjain sisanya (). Tanpa kode, tanpa selector, tanpa mumet.
- Crawling Subpage & Multi-level: Thunderbit bisa . Contohnya: scrape daftar produk, lalu masuk ke tiap halaman produk buat ambil detail—sekali jalan.
- Output Terstruktur Instan: AI bakal , nyaranin field yang relevan, normalisasi format, bahkan bisa merangkum atau mengategorikan teks.
- Dukungan Sumber yang Luas: Thunderbit bukan cuma buat HTML—dia juga bisa ekstrak dari PDF dan gambar lewat OCR bawaan dan vision AI ().
- Integrasi untuk Kebutuhan Bisnis: Ekspor sekali klik ke Google Sheets, Airtable, Notion, atau Excel (). Kamu juga bisa jadwalkan scraping dan ngalirin data langsung ke workflow tim.
- Template Siap Pakai: Buat situs seperti Amazon, LinkedIn, Zillow, dan lainnya, Thunderbit nyediain biar ekstraksi data tinggal sekali klik.
- Ramah Pengguna & Mudah Diakses: UI-nya point-and-click dengan asisten yang intuitif. Banyak orang bisa mulai dalam hitungan menit.

Thunderbit dipakai oleh , termasuk tim di Accenture, Grammarly, dan Puma. Tim sales memakainya buat , agen properti ngumpulin listing, dan marketer mantau kompetitor—tanpa nulis satu baris kode pun.
Harga: Ada (hingga 100 langkah scraping/bulan), dan paket berbayar mulai dari $14.99/bulan. Bahkan paket pro pun masih masuk akal buat individu maupun tim kecil.
Thunderbit adalah hal terdekat yang pernah saya lihat untuk “mengubah web menjadi database”—dan dibuat untuk semua orang, bukan cuma engineer.
2. Crawl4AI
Cocok untuk: Developer dan tim teknis yang lagi bangun pipeline kustom.
Crawl4AI adalah framework open-source berbasis Python yang dioptimalkan buat kecepatan dan crawling skala besar, dengan . Kenceng banget, dukung headless browser buat konten dinamis, dan bisa menstrukturkan data biar gampang dipakai di workflow AI.
- Paling cocok untuk: Developer yang butuh mesin crawling kuat dan bisa dikustom.
- Harga: Gratis (lisensi MIT). Kamu perlu hosting dan jalanin sendiri.
3. ScrapeGraphAI
Cocok untuk: Developer dan analis yang bikin AI agent atau pipeline data yang kompleks.
ScrapeGraphAI adalah library Python open-source berbasis prompt yang mengubah website jadi “graf” data terstruktur pakai LLM. Kamu bisa nulis prompt kayak “Ambil semua nama produk, harga, dan rating dari 5 halaman pertama,” lalu dia yang nyusun workflow scraping-nya buat kamu ().
- Paling cocok untuk: Pengguna teknis yang pengin scraping fleksibel berbasis prompt.
- Harga: Gratis untuk library open-source; cloud API mulai $20/bulan.
4. Firecrawl
Cocok untuk: Developer yang bikin AI agent atau pipeline data skala besar.
Firecrawl adalah platform crawling dan API yang AI-oriented buat mengubah satu website penuh jadi data “siap LLM” (). Output-nya Markdown atau JSON, bisa nangani konten dinamis, dan nyambung ke framework seperti LangChain dan LlamaIndex.
- Paling cocok untuk: Developer yang perlu “nyuapin” data web terbaru ke model AI.
- Harga: Core open-source gratis; paket cloud mulai $19/bulan.
5. Browse AI
Cocok untuk: Pengguna bisnis, growth hacker, dan analis.
Browse AI adalah platform no-code dengan . Kamu “melatih” robot dengan klik data yang kamu mau, lalu AI belajar polanya buat scraping berikutnya. Dukung login, infinite scroll, dan monitoring perubahan situs.
- Paling cocok untuk: Pengguna non-teknis yang pengin otomatisasi pengumpulan data dan monitoring.
- Harga: Paket gratis (50 kredit/bulan); paket berbayar mulai $19/bulan.
6. LLM Scraper
Cocok untuk: Developer yang pengin parsing ditangani AI.
LLM Scraper adalah library open-source JavaScript/TypeScript yang bikin kamu bisa lalu LLM mengekstrak data itu dari halaman web mana pun. Dibangun di atas Playwright, dukung banyak penyedia LLM, dan bahkan bisa menghasilkan kode yang bisa dipakai ulang.
- Paling cocok untuk: Developer yang pengin ubah halaman web jadi data terstruktur dengan LLM.
- Harga: Gratis (lisensi MIT).
7. Reader (Jina Reader)
Cocok untuk: Developer yang bikin aplikasi LLM, chatbot, atau peringkas.
Jina Reader adalah API yang mengekstrak , lalu balikin Markdown atau JSON yang siap dipakai LLM. Didukung model AI khusus dan bisa bikin caption untuk gambar.
- Paling cocok untuk: Ambil konten yang bersih dan gampang dibaca buat LLM atau sistem tanya-jawab.
- Harga: API gratis (tanpa key untuk penggunaan dasar).
8. Bright Data
Cocok untuk: Enterprise dan pengguna profesional yang butuh skala, kepatuhan, dan reliabilitas.
Bright Data adalah pemain besar di industri web data, dengan jaringan proxy masif dan . Mereka nyediain scraper siap pakai, Web Scraper API umum, plus feed data “siap LLM”.
- Paling cocok untuk: Organisasi yang butuh data web andal dalam skala besar.
- Harga: Berbasis pemakaian, kelas premium. Ada uji coba gratis.
9. Octoparse
Cocok untuk: Pengguna non-teknis sampai semi-teknis.
Octoparse adalah tool no-code yang sudah lama populer, dengan dan auto-detect berbasis AI. Dukung login, infinite scroll, dan ekspor ke banyak format.
- Paling cocok untuk: Analis, pemilik bisnis kecil, atau peneliti.
- Harga: Ada paket gratis; paket berbayar mulai $119/bulan.
10. Apify
Cocok untuk: Developer dan tim teknis yang butuh scraping/otomasi kustom.
Apify adalah platform cloud buat jalanin skrip scraping (“actors”) dan punya . Skalabel, terintegrasi dengan AI, dan dukung manajemen proxy.
- Paling cocok untuk: Developer yang pengin jalanin skrip kustom di cloud.
- Harga: Paket gratis; paket berbayar berbasis pemakaian mulai $49/bulan.
11. Zyte (Scrapy Cloud)
Cocok untuk: Developer dan perusahaan yang butuh scraping kelas enterprise.
Zyte adalah perusahaan di balik Scrapy, menawarkan platform cloud dan . Dukung penjadwalan, proxy, dan proyek skala besar.
- Paling cocok untuk: Tim developer yang jalanin proyek scraping jangka panjang.
- Harga: Dari uji coba gratis sampai paket enterprise kustom.
12. Webscraper.io
Cocok untuk: Pemula, jurnalis, dan peneliti.
adalah buat ekstraksi data point-and-click. Simpel, gratis untuk penggunaan lokal, dan ada layanan cloud buat kerjaan yang lebih gede.
- Paling cocok untuk: Tugas scraping cepat dan sekali pakai.
- Harga: Ekstensi gratis; paket cloud mulai sekitar ~$50/bulan.
13. ParseHub
Cocok untuk: Pengguna non-teknis yang butuh kemampuan lebih dari tool dasar.
ParseHub adalah aplikasi desktop dengan workflow visual buat scraping konten dinamis, termasuk peta dan form. Bisa jalanin proyek di cloud dan nyediain API.
- Paling cocok untuk: Digital marketer, analis, dan jurnalis.
- Harga: Paket gratis (200 halaman/run); paket berbayar mulai $189/bulan.
14. Diffbot
Cocok untuk: Enterprise dan perusahaan AI yang butuh data web terstruktur skala besar.
Diffbot pakai computer vision dan NLP buat dari halaman web mana pun, dan nyediain API untuk artikel, produk, serta knowledge graph besar.
- Paling cocok untuk: Market intelligence, finansial, dan data pelatihan AI.
- Harga: Premium, mulai sekitar ~$299/bulan.
15. DataMiner
Cocok untuk: Pengguna non-teknis, terutama di sales, marketing, dan jurnalisme.
DataMiner adalah buat ekstraksi data web cepat dengan point-and-click. Ada pustaka “resep” siap pakai dan bisa ekspor langsung ke Google Sheets.
- Paling cocok untuk: Tugas cepat kayak ekspor tabel atau daftar ke spreadsheet.
- Harga: Paket gratis (500 halaman/hari); Pro mulai sekitar ~$19/bulan.
Perbandingan Tool AI Web Scraper Teratas: Mana yang Paling Pas untuk Anda?
Berikut perbandingan tingkat tinggi biar kamu cepat nemu yang paling cocok:
| Tool | Penggunaan AI/LLM | Kemudahan Pakai | Output/Integrasi | Paling Cocok Untuk | Harga |
|---|---|---|---|---|---|
| Thunderbit | UI bahasa natural; AI menyarankan field | Paling gampang (chat no-code) | Ekspor ke Sheets, Airtable, Notion | Tim non-teknis | Ada gratis; Pro ~ $30/bln |
| Crawl4AI | Crawling siap AI; integrasi LLM | Susah (kode Python) | Library/CLI; integrasi via kode | Dev butuh pipeline data AI cepat | Gratis |
| ScrapeGraphAI | Pipeline scraping berbasis prompt LLM | Sedang (butuh sedikit coding/API) | API/SDK; output JSON | Dev/analis bangun AI agent | OSS gratis; API $20+/bln |
| Firecrawl | Crawling jadi Markdown/JSON siap LLM | Sedang (pakai API/SDK) | SDK (Py, Node, dll.); integrasi LangChain | Dev ngalirin data web live ke AI | Gratis + cloud berbayar |
| Browse AI | Point & click dibantu AI | Gampang (no-code) | 7000+ integrasi aplikasi (Zapier) | Non-teknis untuk monitoring web | Gratis 50 run; Berbayar $19+/bln |
| LLM Scraper | LLM parsing halaman sesuai skema | Susah (kode TS/JS) | Library kode; output JSON | Dev pengin parsing ditangani AI | Gratis (pakai API LLM sendiri) |
| Reader (Jina) | Model AI ekstrak teks/JSON | Gampang (panggilan API sederhana) | REST API: Markdown/JSON | Dev nambah web search/konten ke LLM | API gratis |
| Bright Data | API scraping ditingkatkan AI; jaringan proxy besar | Susah (API, teknis) | API/SDK; stream data atau dataset | Skala enterprise | Berbasis pemakaian |
| Octoparse | AI auto-detect daftar | Sedang (aplikasi no-code) | CSV/Excel, API hasil | Pengguna semi-teknis | Gratis terbatas; $59–$166/bln |
| Apify | Beberapa fitur AI (Actors, tutorial AI) | Susah (kode skrip) | API lengkap; integrasi LangChain | Dev butuh scraping kustom di cloud | Ada gratis; pay-as-you-go |
| Zyte (Scrapy) | Ekstraksi otomatis berbasis ML; framework Scrapy | Susah (kode Python) | API, UI Scrapy Cloud; JSON/CSV | Tim dev, proyek jangka panjang | Harga kustom |
| Webscraper.io | Tanpa AI (template manual) | Gampang (ekstensi browser) | Unduh CSV, Cloud API | Pemula, scraping sekali pakai | Ekstensi gratis; Cloud ~ $50/bln |
| ParseHub | Tidak eksplisit LLM; builder visual | Sedang (aplikasi no-code) | JSON/CSV; API untuk cloud run | Non-dev scraping situs kompleks | Gratis 200 halaman; Berbayar $189+/bln |
| Diffbot | AI vision/NLP untuk semua halaman; knowledge graph | Gampang (cukup panggil API) | API (Article/Prod/...) + query Knowledge Graph | Enterprise, data web terstruktur | Mulai ~ $299/bln |
| DataMiner | Tanpa LLM; resep komunitas | Paling gampang (UI browser) | Ekspor Excel/CSV; Google Sheets | Non-teknis ke spreadsheet | Gratis terbatas; Pro ~ $19/bln |
Kategori Tool: Dari Andalan Developer hingga Web Scraper Ramah Bisnis
Biar daftar ini lebih gampang dicerna, kita kelompokkan tool-toolnya:
1. Andalan Developer & Open-Source
- Contoh: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Kekuatan: Super fleksibel, skalabel, dan gampang dikustom. Cocok buat bangun pipeline sendiri atau integrasi dengan model AI.
- Kompromi: Butuh skill coding dan konfigurasi lebih.
- Use case: Bangun pipeline data kustom, scraping situs kompleks, atau integrasi ke sistem internal.
2. Agen Scraping yang Terintegrasi AI
- Contoh: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Kekuatan: Menjembatani scraping dan pemahaman data. Antarmuka bahasa natural bikin lebih accessible.
- Kompromi: Sebagian masih berkembang; kontrol detail bisa jadi terbatas.
- Use case: Dapat jawaban/dataset cepat, bangun agen otonom, atau nyuplai data live ke LLM.
3. Scraper No-Code/Low-Code yang Ramah Bisnis
- Contoh: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Kekuatan: Mudah dipakai, minim coding, cocok buat kebutuhan bisnis rutin.
- Kompromi: Bisa kewalahan kalau situsnya super kompleks atau skalanya masif.
- Use case: Lead generation, monitoring kompetitor, riset, dan pengambilan data sesekali.
4. Platform & Layanan Data Enterprise
- Contoh: Bright Data, Diffbot, Zyte
- Kekuatan: Solusi end-to-end, layanan terkelola, compliance, dan reliabilitas di skala besar.
- Kompromi: Biaya lebih tinggi dan onboarding lebih panjang.
- Use case: Pipeline data skala besar yang selalu aktif, market intelligence, dan data pelatihan AI.
Cara Memilih AI Web Crawler yang Tepat untuk Kebutuhan Scraping Halaman Web Anda
Milih tool yang pas kadang bikin kepala ngebul, jadi ini panduan step-by-step versi saya:
- Tentukan Tujuan dan Kebutuhan Data: Situs apa yang mau diambil? Datanya apa? Seberapa sering? Seberapa banyak? Buat apa dipakainya?
- Nilai Kemampuan Teknis Kamu: Tanpa coding? Coba Thunderbit, Browse AI, atau Octoparse. Bisa sedikit scripting? LLM Scraper atau DataMiner. Skill dev kuat? Crawl4AI, Apify, atau Zyte.
- Pertimbangkan Frekuensi dan Skala: Sekali pakai? Manfaatin tool gratis. Berulang? Cari fitur penjadwalan. Skala besar? Tool enterprise atau open-source yang bisa di-scale.
- Anggaran dan Model Harga: Paket gratis cocok buat coba-coba. Pilih langganan vs berbasis pemakaian sesuai kebutuhan.
- Uji Coba dan Proof of Concept: Tes beberapa tool pakai data nyata kamu. Kebanyakan punya paket gratis.
- Maintenance dan Dukungan: Siapa yang bakal benerin kalau situs berubah? Tool no-code dengan AI bisa auto-fix perubahan kecil; open-source ya tergantung kamu/komunitas.
- Cocokkan Tool dengan Skenario: Tim sales scraping prospek? Thunderbit atau Browse AI. Peneliti ngumpulin tweet? DataMiner atau . Model AI butuh artikel berita? Jina Reader atau Zyte. Bangun situs perbandingan? Apify atau Zyte.
- Siapkan Rencana Cadangan: Kadang satu tool nggak cocok buat situs tertentu. Punya alternatif itu penting.
Tool yang “paling tepat” adalah yang ngasih kamu data yang dibutuhkan dengan hambatan paling kecil dan sesuai budget. Seringnya, jawabannya adalah kombinasi.
Thunderbit vs Tool Web Scraper Tradisional: Apa yang Membuatnya Berbeda?
Sekarang kita bahas lebih spesifik soal nilai plus Thunderbit:
- Antarmuka Bahasa Natural: Tanpa kode, tanpa “senam” point-and-click. Tinggal jelasin kebutuhanmu ().
- Tanpa Konfigurasi & Saran Template: Thunderbit bisa deteksi pagination, subpage, dan bahkan nyaranin template buat situs umum ().
- Pembersihan & Enrichment Data Berbasis AI: Ringkas, kategorikan, terjemahkan, dan perkaya data saat scraping ().
- Lebih Minim Drama Maintenance: AI Thunderbit lebih tahan sama perubahan kecil di situs, jadi lebih jarang “pecah”.
- Integrasi Tool Bisnis: Ekspor langsung ke Google Sheets, Airtable, Notion—tanpa ribet urus CSV ().
- Cepat Memberi Hasil: Dari ide ke data dalam hitungan menit, bukan berhari-hari.
- Kurva Belajar Rendah: Kalau kamu bisa browsing web dan jelasin kebutuhan, kamu bisa pakai Thunderbit.
- Fleksibel: Scrape website, PDF, gambar, dan lainnya—pakai tool yang sama.
Thunderbit bukan cuma scraper—dia asisten data yang nyatu sama workflow kamu, entah buat sales, marketing, ecommerce, atau real estate.
Praktik Terbaik Scraping Halaman Web dengan Tool AI Web Scraper
Biar hasilnya maksimal, ini tips utama versi saya:
- Definisikan Kebutuhan Data dengan Jelas: Tentukan field, jumlah halaman, dan format output.
- Manfaatkan Saran AI: Pakai deteksi field dan rekomendasi AI biar data penting nggak kelewat ().
- Mulai dari Skala Kecil dan Validasi: Tes dulu di sampel kecil, cek output, baru sesuaikan.
- Tangani Konten Dinamis: Pastikan tool dukung interaksi (pagination, infinite scroll, dll.).
- Hormati Kebijakan Website: Cek robots.txt, hindari data sensitif, dan patuhi rate limit.
- Integrasikan untuk Otomasi: Gunakan fitur ekspor dan webhook biar data langsung masuk workflow.
- Jaga Kualitas Data: Lakukan sanity check, post-processing, dan pantau error.
- Buat Prompt yang Ringkas dan Spesifik: Instruksi yang jelas biasanya hasilnya lebih bagus.
- Belajar dari Komunitas: Ikuti forum/komunitas buat tips dan troubleshooting.
- Tetap Update: Tool AI berkembang cepat—pantau fitur baru dan improvement.
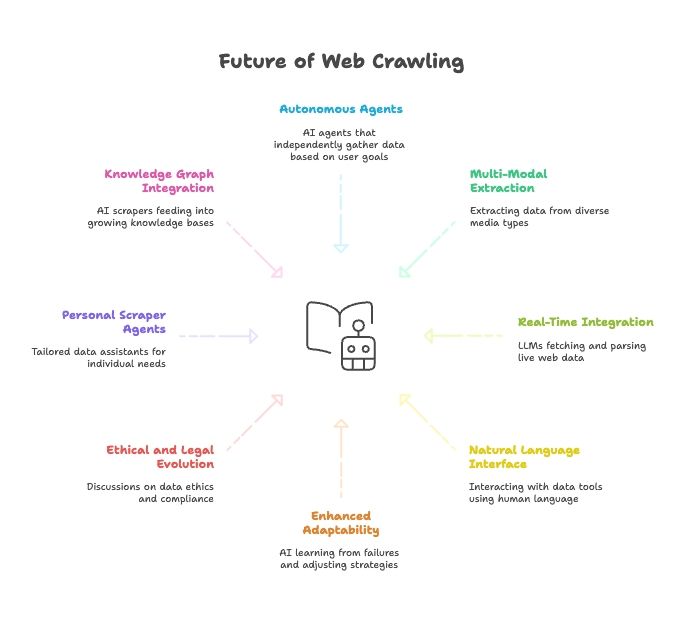
Masa Depan Web Scraping: AI, LLM, dan Munculnya Agen Web Scraper Berbasis Bahasa Natural
Ke depan, konvergensi AI dan web scraping bakal makin ngebut:
- Agen Scraper Sepenuhnya Otonom: Kamu cukup sebut tujuan akhir, agen AI yang nentuin cara ngambil datanya.
- Ekstraksi Data Multi-Modal: Scraper bakal ngambil data dari teks, gambar, PDF, bahkan video.
- Integrasi Real-Time dengan Model AI: LLM bakal punya modul bawaan buat ngambil dan mem-parsing data web secara live.
- Semua Serba Bahasa Natural: Kita bakal “ngomong” sama tool data kayak ngomong sama manusia, bikin pengumpulan dan transformasi data makin gampang.
- Adaptabilitas Lebih Tinggi: Scraper AI bakal belajar dari kegagalan dan otomatis nyesuaiin strategi.
- Evolusi Etika dan Regulasi: Bakal makin banyak diskusi soal etika data, compliance, dan fair use.
- Agen Scraper Personal: Kebayang kan asisten data pribadi yang ngumpulin berita, lowongan kerja, dan lainnya sesuai kebutuhanmu.
- Integrasi dengan Knowledge Graph: Scraper AI bakal terus ngisi basis pengetahuan yang makin gede, jadi AI makin pinter.
Intinya: masa depan web scraping bakal jalan bareng masa depan AI. Tool makin cerdas, makin otonom, dan makin gampang diakses dari hari ke hari.
Kesimpulan: Membuka Nilai Bisnis dengan AI Web Crawler yang Tepat
Web scraping sudah berubah dari skill teknis yang niche jadi kemampuan inti bisnis—berkat AI. Kelima belas tool yang saya bahas mewakili yang terbaik di 2026, dari “mesin” buat developer sampai asisten yang ramah buat tim bisnis.
Kuncinya? Milih tool yang tepat bisa melipatgandakan nilai yang kamu dapet dari data web. Buat tim non-teknis, Thunderbit adalah cara paling gampang buat mengubah web jadi database terstruktur yang siap dianalisis—tanpa kode, tanpa ribet, fokus ke hasil.
Jadi, entah kamu lagi ngumpulin prospek, mantau kompetitor, atau nyuplai data buat model AI generasi berikutnya, luangkan waktu buat evaluasi kebutuhan, coba beberapa tool, dan lihat mana yang paling cocok. Dan kalau kamu pengin ngerasain masa depan web scraping hari ini, . Insight yang kamu butuhin tinggal satu prompt lagi.
Ingin lanjut eksplor? Mampir ke buat bahasan mendalam, tutorial, dan update terbaru seputar ekstraksi data berbasis AI.
Bacaan Lanjutan:
FAQs
1. Apa itu AI web crawler dan apa bedanya dengan web scraper tradisional?
AI web crawler memakai pemrosesan bahasa natural dan machine learning buat memahami, mengekstrak, dan menstrukturkan data web. Beda dengan scraper tradisional yang biasanya butuh coding manual dan selector XPath, tool AI bisa nangani konten dinamis, adaptasi saat layout berubah, serta paham instruksi pengguna dalam bahasa sehari-hari.
2. Siapa yang sebaiknya memakai tool AI web scraping seperti Thunderbit?
Thunderbit dibuat buat pengguna non-teknis maupun teknis. Cocok untuk profesional sales, marketing, operasional, riset, dan ecommerce yang pengin mengekstrak data terstruktur dari website, PDF, atau gambar—tanpa nulis kode.
3. Fitur apa yang membuat Thunderbit menonjol dibanding AI web crawler lain?
Thunderbit punya antarmuka bahasa natural, crawling multi-level, penstrukturan data otomatis, dukungan OCR, serta ekspor mulus ke platform seperti Google Sheets dan Airtable. Selain itu ada saran field berbasis AI dan template siap pakai untuk situs populer.
4. Apakah ada opsi gratis untuk AI web scraping di 2026?
Ada. Banyak tool seperti Thunderbit, Browse AI, dan DataMiner nyediain paket gratis dengan batas pemakaian. Buat developer, opsi open-source seperti Crawl4AI dan ScrapeGraphAI ngasih fungsionalitas penuh tanpa biaya, meski tetap perlu setup teknis.
5. Bagaimana cara memilih AI web crawler yang tepat untuk kebutuhan saya?
Mulai dari nentuin tujuan data, kemampuan teknis, anggaran, dan kebutuhan skala. Kalau kamu pengin solusi no-code yang gampang dipakai, Thunderbit atau Browse AI itu pilihan yang solid. Kalau butuh kustom atau skala besar, tool seperti Apify atau Bright Data biasanya lebih pas.